 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Limits to Reservoir Learning
Jul 26, 2023
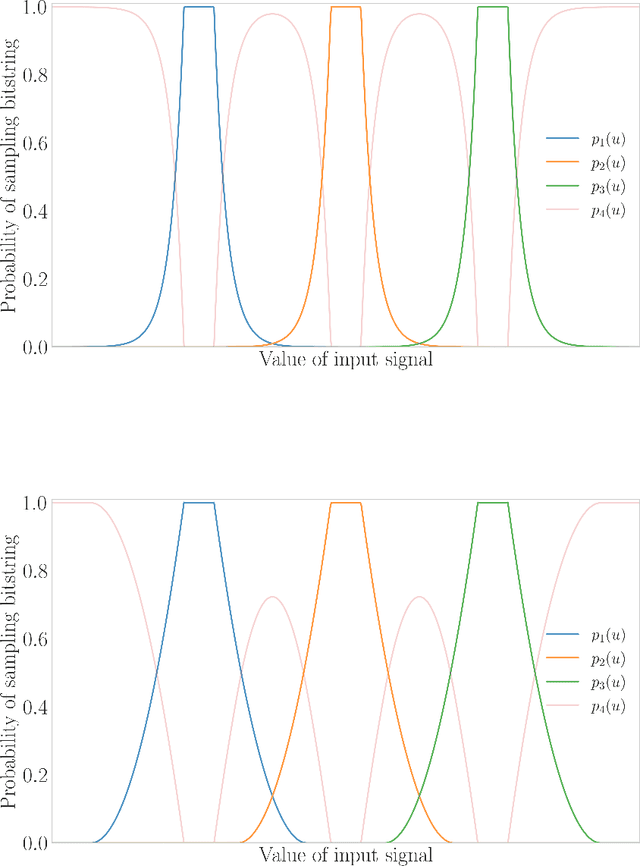
In this work, we bound a machine's ability to learn based on computational limitations implied by physicality. We start by considering the information processing capacity (IPC), a normalized measure of the expected squared error of a collection of signals to a complete basis of functions. We use the IPC to measure the degradation under noise of the performance of reservoir computers, a particular kind of recurrent network, when constrained by physical considerations. First, we show that the IPC is at most a polynomial in the system size $n$, even when considering the collection of $2^n$ possible pointwise products of the $n$ output signals. Next, we argue that this degradation implies that the family of functions represented by the reservoir requires an exponential number of samples to learn in the presence of the reservoir's noise. Finally, we conclude with a discussion of the performance of the same collection of $2^n$ functions without noise when being used for binary classification.
Integrating Offline Reinforcement Learning with Transformers for Sequential Recommendation
Jul 26, 2023
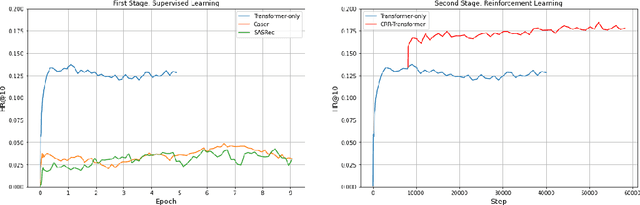

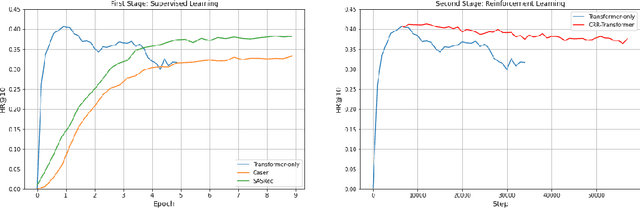
We consider the problem of sequential recommendation, where the current recommendation is made based on past interactions. This recommendation task requires efficient processing of the sequential data and aims to provide recommendations that maximize the long-term reward. To this end, we train a farsighted recommender by using an offline RL algorithm with the policy network in our model architecture that has been initialized from a pre-trained transformer model. The pre-trained model leverages the superb ability of the transformer to process sequential information. Compared to prior works that rely on online interaction via simulation, we focus on implementing a fully offline RL framework that is able to converge in a fast and stable way. Through extensive experiments on public datasets, we show that our method is robust across various recommendation regimes, including e-commerce and movie suggestions. Compared to state-of-the-art supervised learning algorithms, our algorithm yields recommendations of higher quality, demonstrating the clear advantage of combining RL and transformers.
Computational Approaches for Traditional Chinese Painting: From the "Six Principles of Painting" Perspective
Jul 26, 2023
Traditional Chinese Painting (TCP) is an invaluable cultural heritage resource and a unique visual art style. In recent years, increasing interest has been placed on digitalizing TCPs to preserve and revive the culture. The resulting digital copies have enabled the advancement of computational methods for structured and systematic understanding of TCPs. To explore this topic, we conducted an in-depth analysis of 92 pieces of literature. We examined the current use of computer technologies on TCPs from three perspectives, based on numerous conversations with specialists. First, in light of the "Six Principles of Painting" theory, we categorized the articles according to their research focus on artistic elements. Second, we created a four-stage framework to illustrate the purposes of TCP applications. Third, we summarized the popular computational techniques applied to TCPs. The framework also provides insights into potential applications and future prospects, with professional opinion. The list of surveyed publications and related information is available online at https://ca4tcp.com.
Flexible Differentially Private Vertical Federated Learning with Adaptive Feature Embeddings
Jul 26, 2023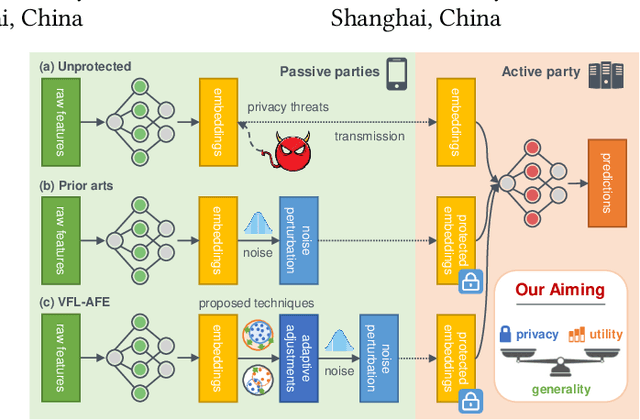
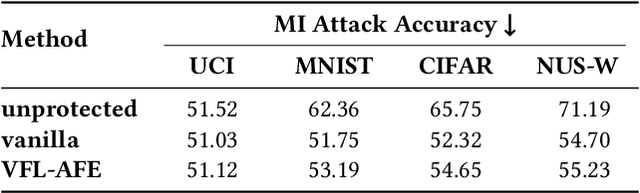
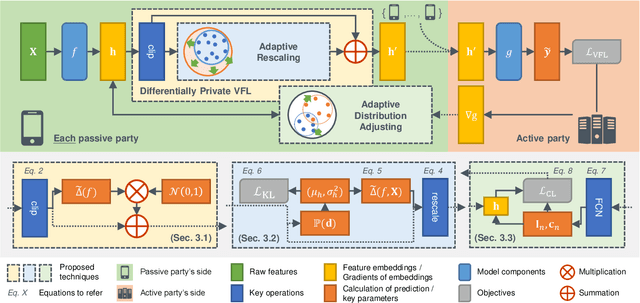
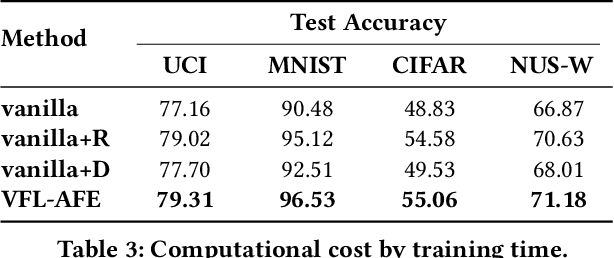
The emergence of vertical federated learning (VFL) has stimulated concerns about the imperfection in privacy protection, as shared feature embeddings may reveal sensitive information under privacy attacks. This paper studies the delicate equilibrium between data privacy and task utility goals of VFL under differential privacy (DP). To address the generality issue of prior arts, this paper advocates a flexible and generic approach that decouples the two goals and addresses them successively. Specifically, we initially derive a rigorous privacy guarantee by applying norm clipping on shared feature embeddings, which is applicable across various datasets and models. Subsequently, we demonstrate that task utility can be optimized via adaptive adjustments on the scale and distribution of feature embeddings in an accuracy-appreciative way, without compromising established DP mechanisms. We concretize our observation into the proposed VFL-AFE framework, which exhibits effectiveness against privacy attacks and the capacity to retain favorable task utility, as substantiated by extensive experiments.
Correlation-Aware Mutual Learning for Semi-supervised Medical Image Segmentation
Jul 12, 2023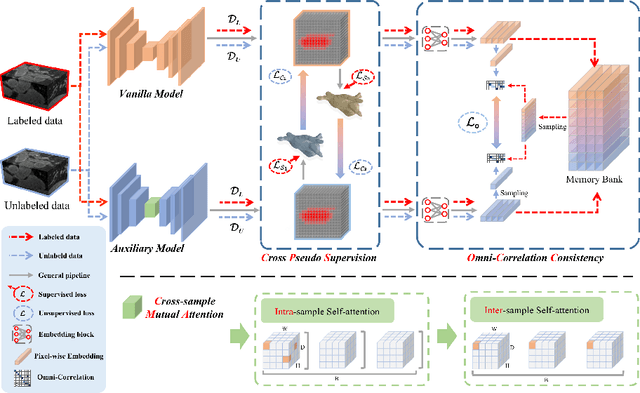
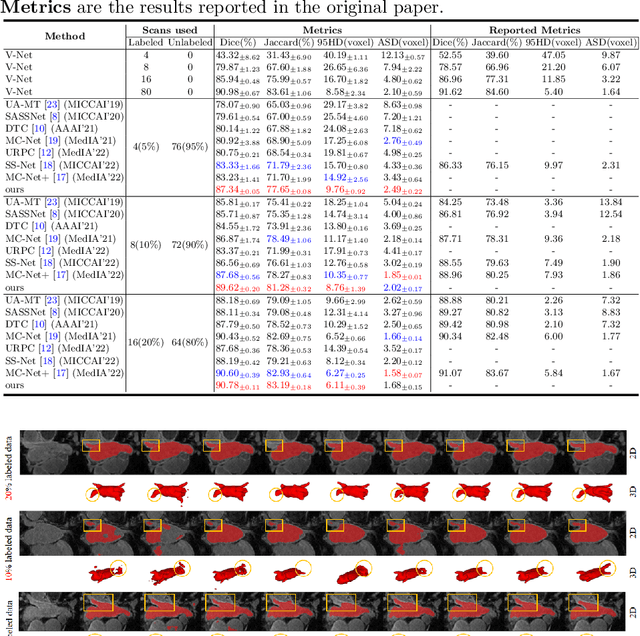
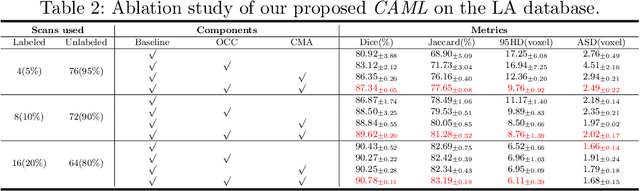
Semi-supervised learning has become increasingly popular in medical image segmentation due to its ability to leverage large amounts of unlabeled data to extract additional information. However, most existing semi-supervised segmentation methods only focus on extracting information from unlabeled data, disregarding the potential of labeled data to further improve the performance of the model. In this paper, we propose a novel Correlation Aware Mutual Learning (CAML) framework that leverages labeled data to guide the extraction of information from unlabeled data. Our approach is based on a mutual learning strategy that incorporates two modules: the Cross-sample Mutual Attention Module (CMA) and the Omni-Correlation Consistency Module (OCC). The CMA module establishes dense cross-sample correlations among a group of samples, enabling the transfer of label prior knowledge to unlabeled data. The OCC module constructs omni-correlations between the unlabeled and labeled datasets and regularizes dual models by constraining the omni-correlation matrix of each sub-model to be consistent. Experiments on the Atrial Segmentation Challenge dataset demonstrate that our proposed approach outperforms state-of-the-art methods, highlighting the effectiveness of our framework in medical image segmentation tasks. The codes, pre-trained weights, and data are publicly available.
Separate Scene Text Detector for Unseen Scripts is Not All You Need
Jul 29, 2023
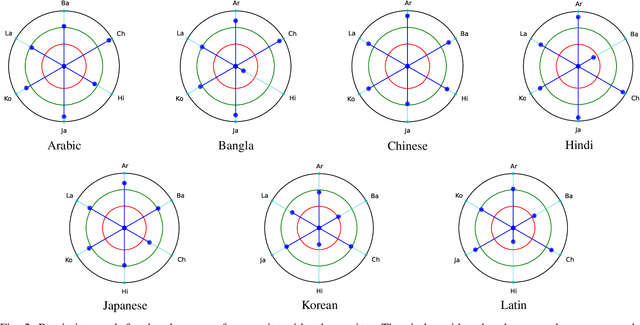
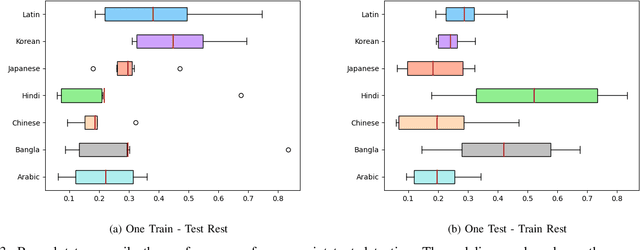
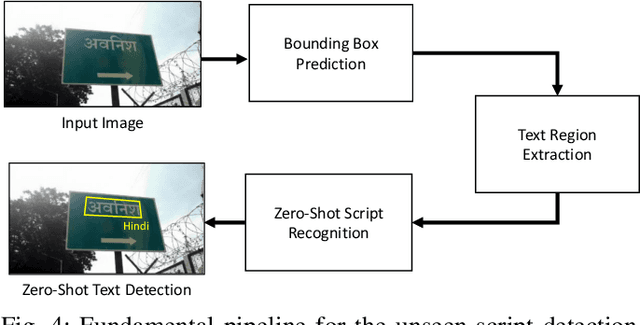
Text detection in the wild is a well-known problem that becomes more challenging while handling multiple scripts. In the last decade, some scripts have gained the attention of the research community and achieved good detection performance. However, many scripts are low-resourced for training deep learning-based scene text detectors. It raises a critical question: Is there a need for separate training for new scripts? It is an unexplored query in the field of scene text detection. This paper acknowledges this problem and proposes a solution to detect scripts not present during training. In this work, the analysis has been performed to understand cross-script text detection, i.e., trained on one and tested on another. We found that the identical nature of text annotation (word-level/line-level) is crucial for better cross-script text detection. The different nature of text annotation between scripts degrades cross-script text detection performance. Additionally, for unseen script detection, the proposed solution utilizes vector embedding to map the stroke information of text corresponding to the script category. The proposed method is validated with a well-known multi-lingual scene text dataset under a zero-shot setting. The results show the potential of the proposed method for unseen script detection in natural images.
Blockchain-empowered Federated Learning for Healthcare Metaverses: User-centric Incentive Mechanism with Optimal Data Freshness
Jul 29, 2023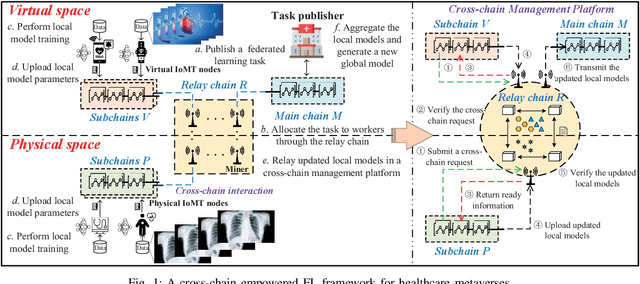
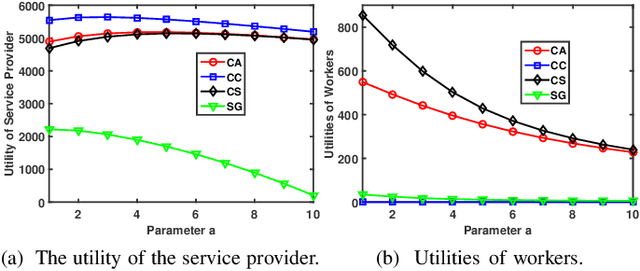
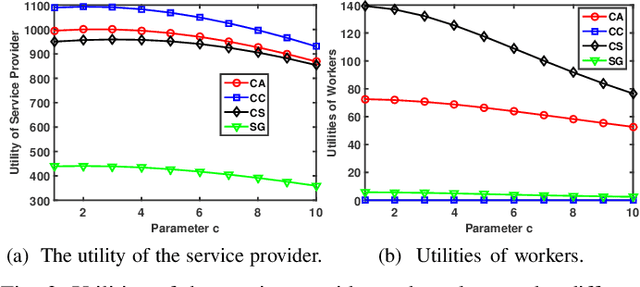
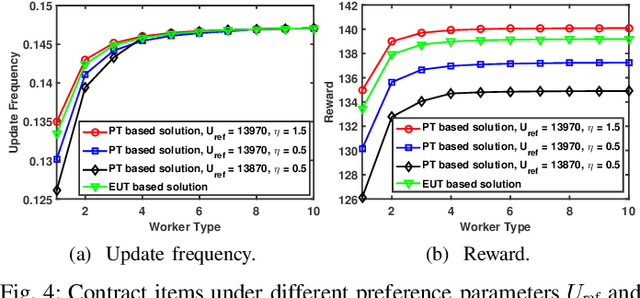
Given the revolutionary role of metaverses, healthcare metaverses are emerging as a transformative force, creating intelligent healthcare systems that offer immersive and personalized services. The healthcare metaverses allow for effective decision-making and data analytics for users. However, there still exist critical challenges in building healthcare metaverses, such as the risk of sensitive data leakage and issues with sensing data security and freshness, as well as concerns around incentivizing data sharing. In this paper, we first design a user-centric privacy-preserving framework based on decentralized Federated Learning (FL) for healthcare metaverses. To further improve the privacy protection of healthcare metaverses, a cross-chain empowered FL framework is utilized to enhance sensing data security. This framework utilizes a hierarchical cross-chain architecture with a main chain and multiple subchains to perform decentralized, privacy-preserving, and secure data training in both virtual and physical spaces. Moreover, we utilize Age of Information (AoI) as an effective data-freshness metric and propose an AoI-based contract theory model under Prospect Theory (PT) to motivate sensing data sharing in a user-centric manner. This model exploits PT to better capture the subjective utility of the service provider. Finally, our numerical results demonstrate the effectiveness of the proposed schemes for healthcare metaverses.
Towards Deeply Unified Depth-aware Panoptic Segmentation with Bi-directional Guidance Learning
Jul 27, 2023
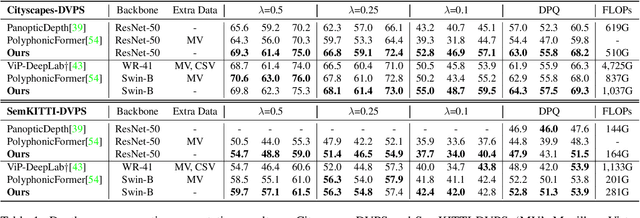
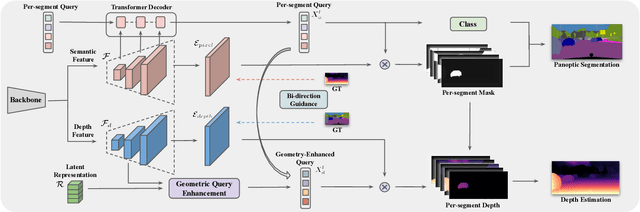
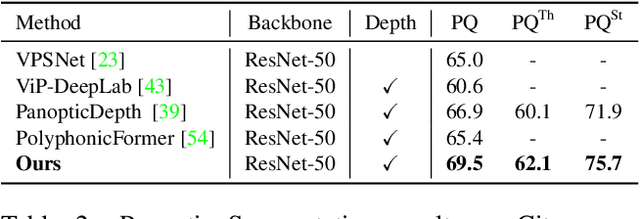
Depth-aware panoptic segmentation is an emerging topic in computer vision which combines semantic and geometric understanding for more robust scene interpretation. Recent works pursue unified frameworks to tackle this challenge but mostly still treat it as two individual learning tasks, which limits their potential for exploring cross-domain information. We propose a deeply unified framework for depth-aware panoptic segmentation, which performs joint segmentation and depth estimation both in a per-segment manner with identical object queries. To narrow the gap between the two tasks, we further design a geometric query enhancement method, which is able to integrate scene geometry into object queries using latent representations. In addition, we propose a bi-directional guidance learning approach to facilitate cross-task feature learning by taking advantage of their mutual relations. Our method sets the new state of the art for depth-aware panoptic segmentation on both Cityscapes-DVPS and SemKITTI-DVPS datasets. Moreover, our guidance learning approach is shown to deliver performance improvement even under incomplete supervision labels.
PromptStyler: Prompt-driven Style Generation for Source-free Domain Generalization
Jul 27, 2023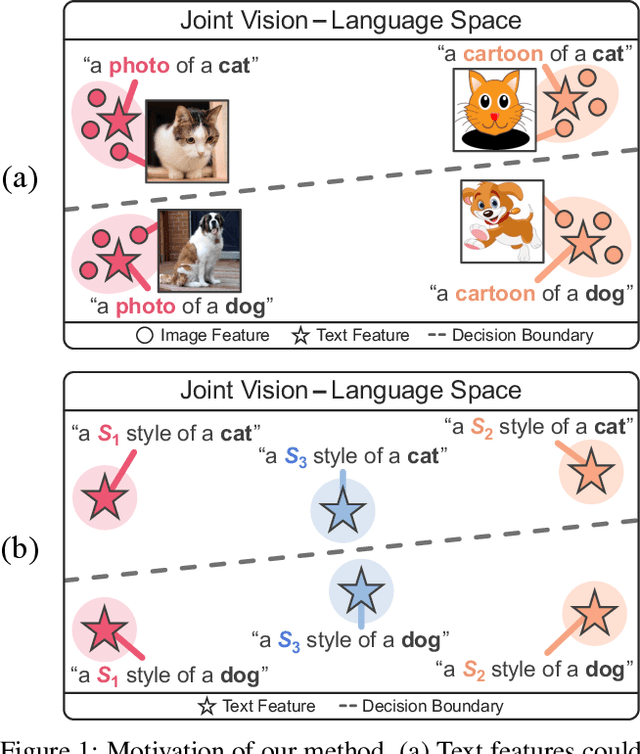
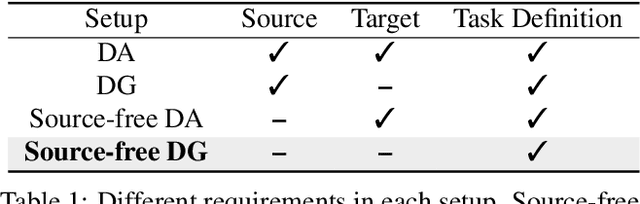
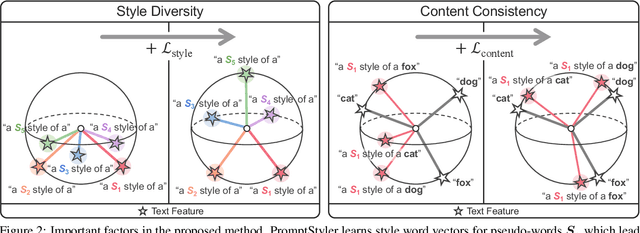
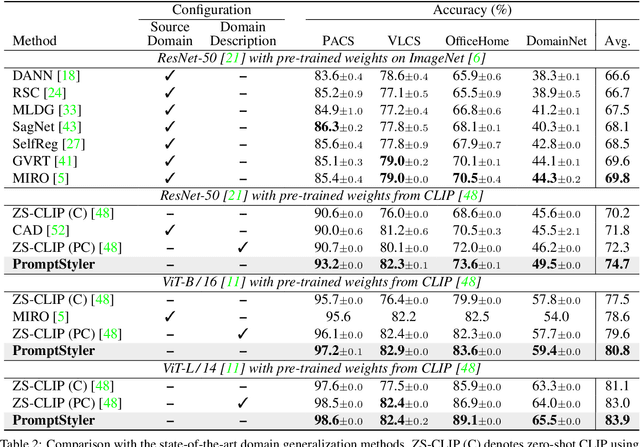
In a joint vision-language space, a text feature (e.g., from "a photo of a dog") could effectively represent its relevant image features (e.g., from dog photos). Inspired by this, we propose PromptStyler which simulates various distribution shifts in the joint space by synthesizing diverse styles via prompts without using any images to deal with source-free domain generalization. Our method learns to generate a variety of style features (from "a S* style of a") via learnable style word vectors for pseudo-words S*. To ensure that learned styles do not distort content information, we force style-content features (from "a S* style of a [class]") to be located nearby their corresponding content features (from "[class]") in the joint vision-language space. After learning style word vectors, we train a linear classifier using synthesized style-content features. PromptStyler achieves the state of the art on PACS, VLCS, OfficeHome and DomainNet, although it does not require any images and takes just ~30 minutes for training using a single GPU.
Adaptive Segmentation Network for Scene Text Detection
Jul 27, 2023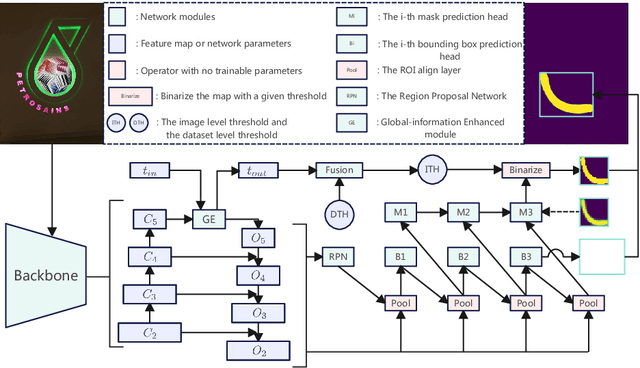
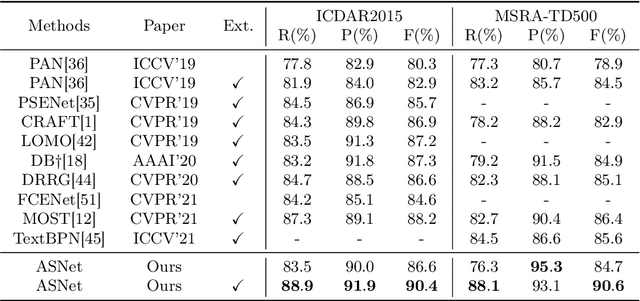
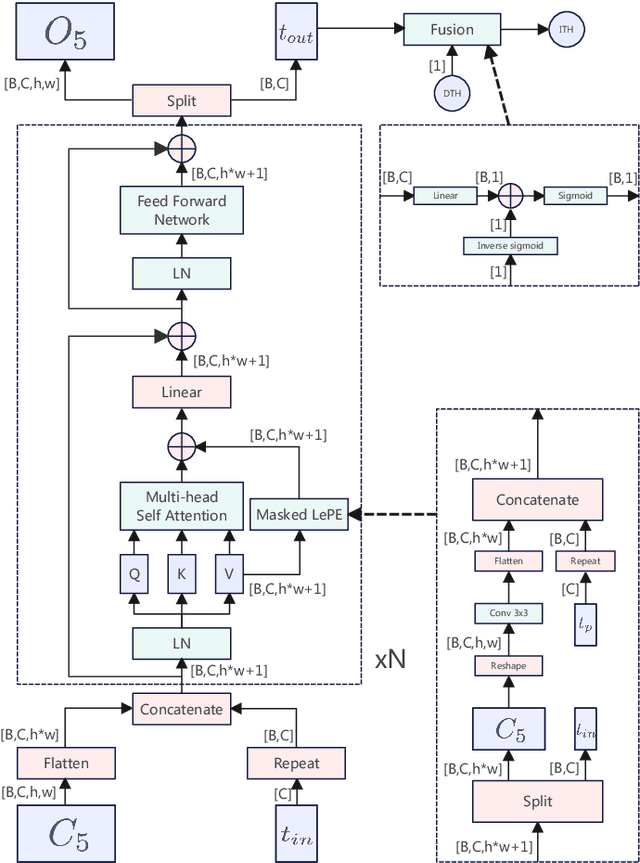
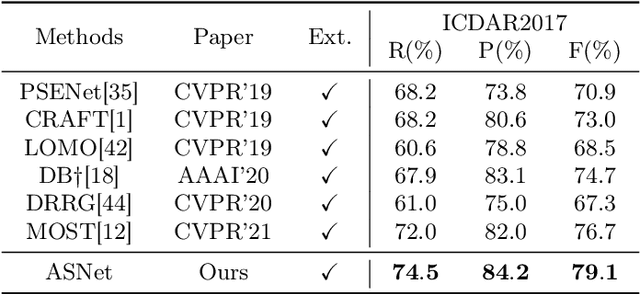
Inspired by deep convolution segmentation algorithms, scene text detectors break the performance ceiling of datasets steadily. However, these methods often encounter threshold selection bottlenecks and have poor performance on text instances with extreme aspect ratios. In this paper, we propose to automatically learn the discriminate segmentation threshold, which distinguishes text pixels from background pixels for segmentation-based scene text detectors and then further reduces the time-consuming manual parameter adjustment. Besides, we design a Global-information Enhanced Feature Pyramid Network (GE-FPN) for capturing text instances with macro size and extreme aspect ratios. Following the GE-FPN, we introduce a cascade optimization structure to further refine the text instances. Finally, together with the proposed threshold learning strategy and text detection structure, we design an Adaptive Segmentation Network (ASNet) for scene text detection. Extensive experiments are carried out to demonstrate that the proposed ASNet can achieve the state-of-the-art performance on four text detection benchmarks, i.e., ICDAR 2015, MSRA-TD500, ICDAR 2017 MLT and CTW1500. The ablation experiments also verify the effectiveness of our contributions.