 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Beyond Single-Feature Importance with ICECREAM
Jul 19, 2023



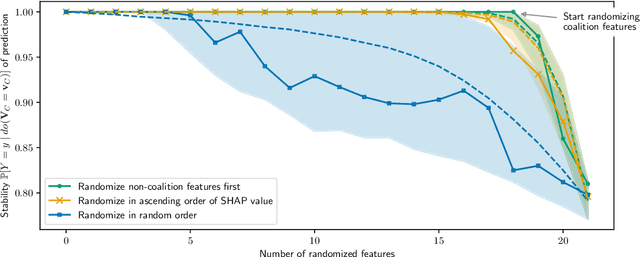
Which set of features was responsible for a certain output of a machine learning model? Which components caused the failure of a cloud computing application? These are just two examples of questions we are addressing in this work by Identifying Coalition-based Explanations for Common and Rare Events in Any Model (ICECREAM). Specifically, we propose an information-theoretic quantitative measure for the influence of a coalition of variables on the distribution of a target variable. This allows us to identify which set of factors is essential to obtain a certain outcome, as opposed to well-established explainability and causal contribution analysis methods which can assign contributions only to individual factors and rank them by their importance. In experiments with synthetic and real-world data, we show that ICECREAM outperforms state-of-the-art methods for explainability and root cause analysis, and achieves impressive accuracy in both tasks.
Learn to Compress (LtC): Efficient Learning-based Streaming Video Analytics
Jul 25, 2023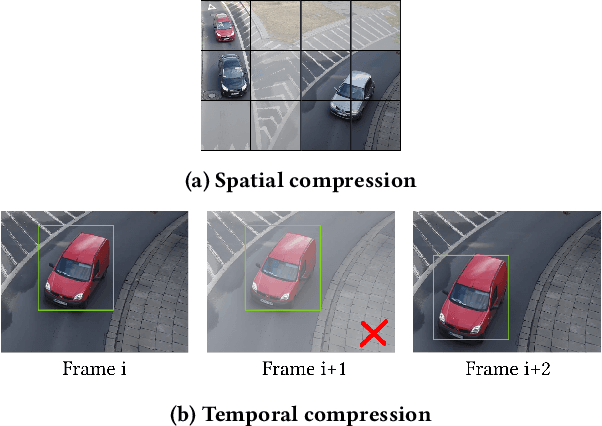
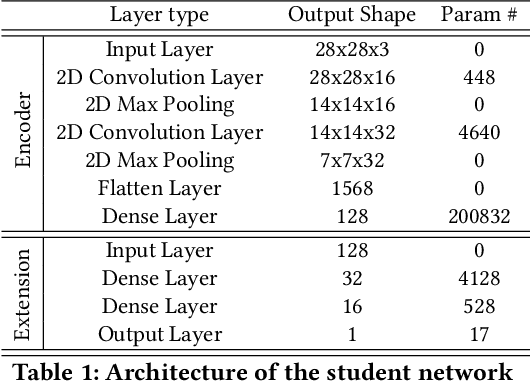
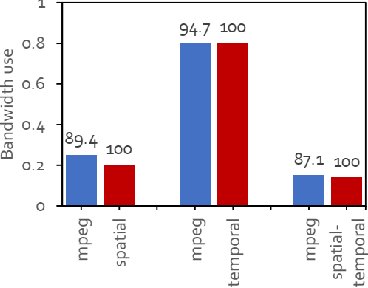

Video analytics are often performed as cloud services in edge settings, mainly to offload computation, and also in situations where the results are not directly consumed at the video sensors. Sending high-quality video data from the edge devices can be expensive both in terms of bandwidth and power use. In order to build a streaming video analytics pipeline that makes efficient use of these resources, it is therefore imperative to reduce the size of the video stream. Traditional video compression algorithms are unaware of the semantics of the video, and can be both inefficient and harmful for the analytics performance. In this paper, we introduce LtC, a collaborative framework between the video source and the analytics server, that efficiently learns to reduce the video streams within an analytics pipeline. Specifically, LtC uses the full-fledged analytics algorithm at the server as a teacher to train a lightweight student neural network, which is then deployed at the video source. The student network is trained to comprehend the semantic significance of various regions within the videos, which is used to differentially preserve the crucial regions in high quality while the remaining regions undergo aggressive compression. Furthermore, LtC also incorporates a novel temporal filtering algorithm based on feature-differencing to omit transmitting frames that do not contribute new information. Overall, LtC is able to use 28-35% less bandwidth and has up to 45% shorter response delay compared to recently published state of the art streaming frameworks while achieving similar analytics performance.
Transformer-based end-to-end classification of variable-length volumetric data
Jul 13, 2023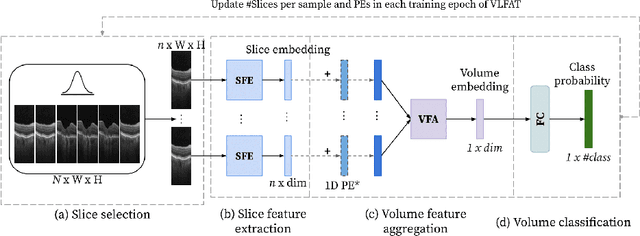
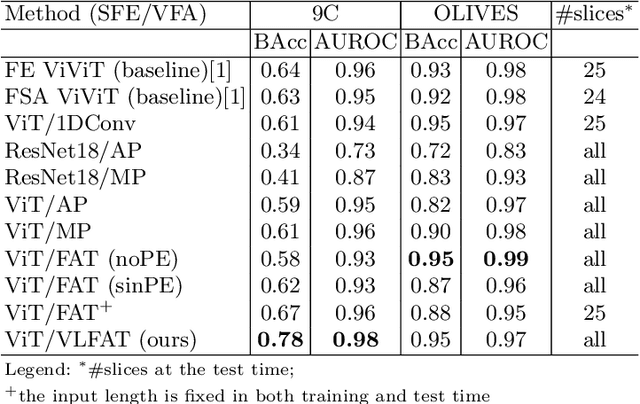
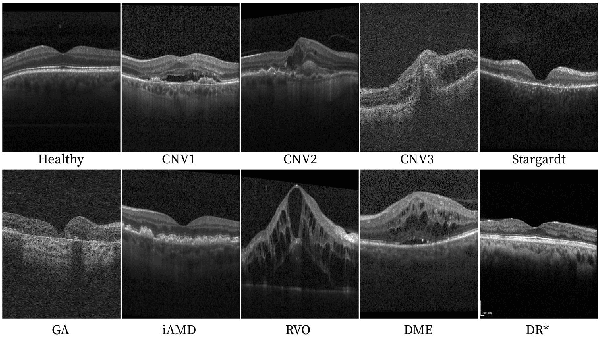
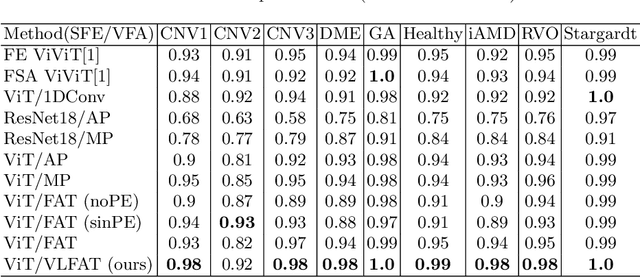
The automatic classification of 3D medical data is memory-intensive. Also, variations in the number of slices between samples is common. Naive solutions such as subsampling can solve these problems, but at the cost of potentially eliminating relevant diagnosis information. Transformers have shown promising performance for sequential data analysis. However, their application for long-sequences is data, computationally, and memory demanding. In this paper, we propose an end-to-end Transformer-based framework that allows to classify volumetric data of variable length in an efficient fashion. Particularly, by randomizing the input slice-wise resolution during training, we enhance the capacity of the learnable positional embedding assigned to each volume slice. Consequently, the accumulated positional information in each positional embedding can be generalized to the neighbouring slices, even for high resolution volumes at the test time. By doing so, the model will be more robust to variable volume length and amenable to different computational budgets. We evaluated the proposed approach in retinal OCT volume classification and achieved 21.96% average improvement in balanced accuracy on a 9-class diagnostic task, compared to state-of-the-art video transformers. Our findings show that varying the slice-wise resolution of the input during training results in more informative volume representation as compared to training with fixed number of slices per volume. Our code is available at: https://github.com/marziehoghbaie/VLFAT.
A Survey and Approach to Chart Classification
Jul 09, 2023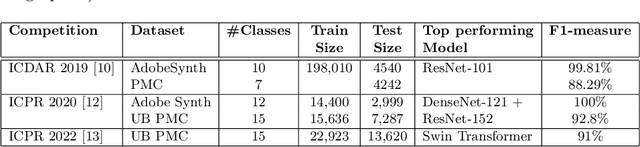
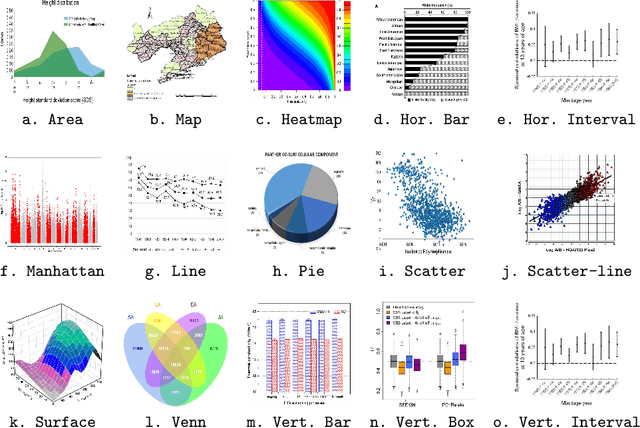
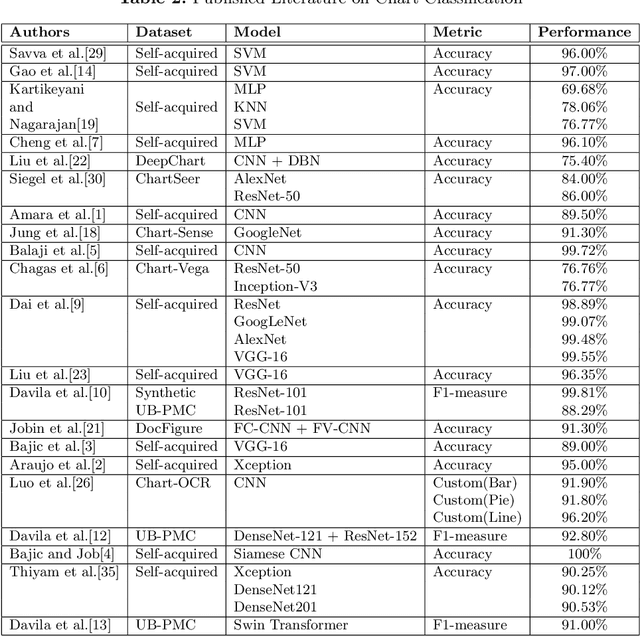
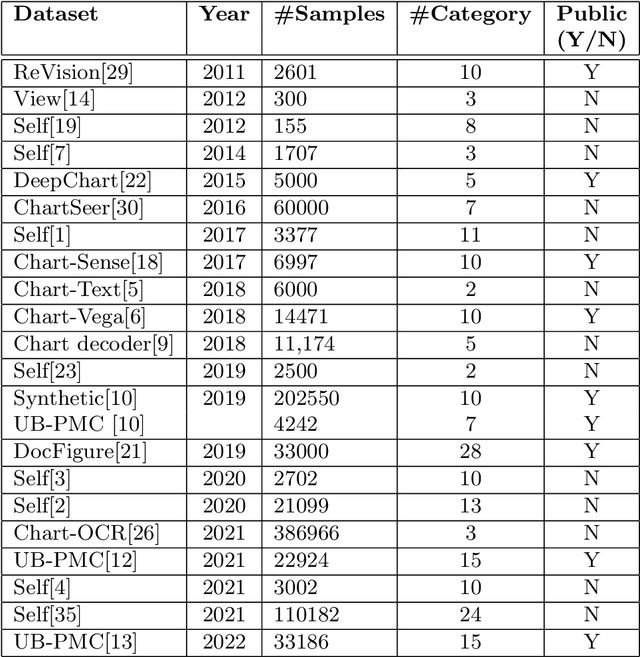
Charts represent an essential source of visual information in documents and facilitate a deep understanding and interpretation of information typically conveyed numerically. In the scientific literature, there are many charts, each with its stylistic differences. Recently the document understanding community has begun to address the problem of automatic chart understanding, which begins with chart classification. In this paper, we present a survey of the current state-of-the-art techniques for chart classification and discuss the available datasets and their supported chart types. We broadly classify these contributions as traditional approaches based on ML, CNN, and Transformers. Furthermore, we carry out an extensive comparative performance analysis of CNN-based and transformer-based approaches on the recently published CHARTINFO UB-UNITECH PMC dataset for the CHART-Infographics competition at ICPR 2022. The data set includes 15 different chart categories, including 22,923 training images and 13,260 test images. We have implemented a vision-based transformer model that produces state-of-the-art results in chart classification.
On Collaboration in Distributed Parameter Estimation with Resource Constraints
Jul 12, 2023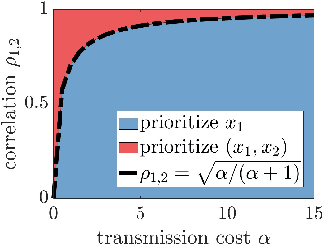
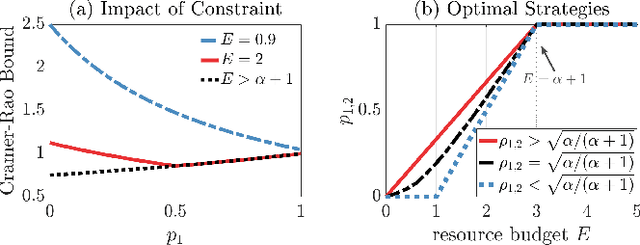
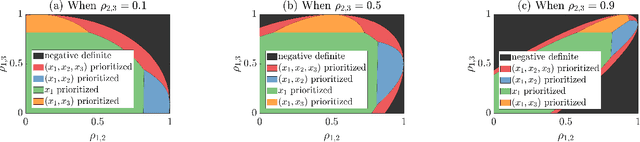
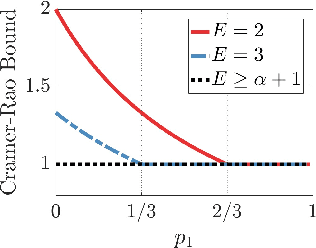
We study sensor/agent data collection and collaboration policies for parameter estimation, accounting for resource constraints and correlation between observations collected by distinct sensors/agents. Specifically, we consider a group of sensors/agents each samples from different variables of a multivariate Gaussian distribution and has different estimation objectives, and we formulate a sensor/agent's data collection and collaboration policy design problem as a Fisher information maximization (or Cramer-Rao bound minimization) problem. When the knowledge of correlation between variables is available, we analytically identify two particular scenarios: (1) where the knowledge of the correlation between samples cannot be leveraged for collaborative estimation purposes and (2) where the optimal data collection policy involves investing scarce resources to collaboratively sample and transfer information that is not of immediate interest and whose statistics are already known, with the sole goal of increasing the confidence on the estimate of the parameter of interest. When the knowledge of certain correlation is unavailable but collaboration may still be worthwhile, we propose novel ways to apply multi-armed bandit algorithms to learn the optimal data collection and collaboration policy in our distributed parameter estimation problem and demonstrate that the proposed algorithms, DOUBLE-F, DOUBLE-Z, UCB-F, UCB-Z, are effective through simulations.
Enhancing Cross-lingual Transfer via Phonemic Transcription Integration
Jul 10, 2023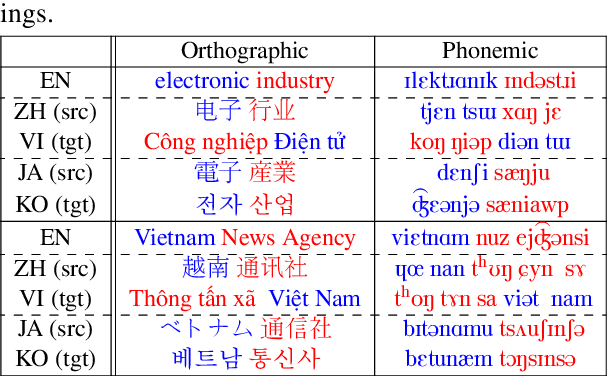
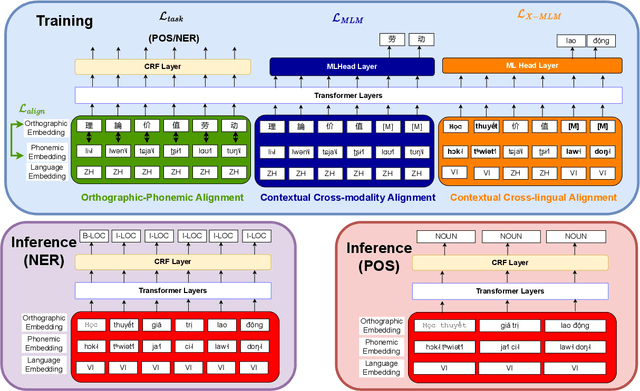
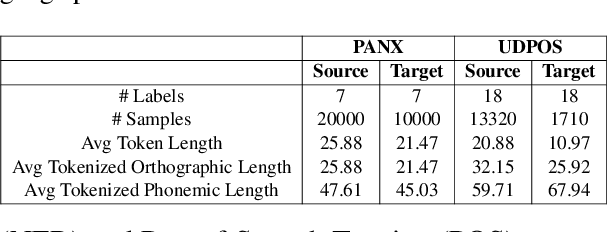
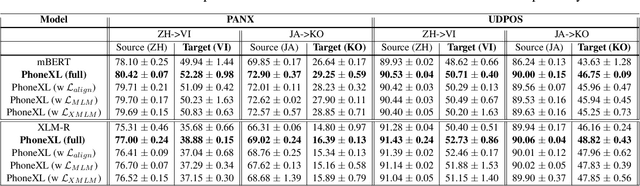
Previous cross-lingual transfer methods are restricted to orthographic representation learning via textual scripts. This limitation hampers cross-lingual transfer and is biased towards languages sharing similar well-known scripts. To alleviate the gap between languages from different writing scripts, we propose PhoneXL, a framework incorporating phonemic transcriptions as an additional linguistic modality beyond the traditional orthographic transcriptions for cross-lingual transfer. Particularly, we propose unsupervised alignment objectives to capture (1) local one-to-one alignment between the two different modalities, (2) alignment via multi-modality contexts to leverage information from additional modalities, and (3) alignment via multilingual contexts where additional bilingual dictionaries are incorporated. We also release the first phonemic-orthographic alignment dataset on two token-level tasks (Named Entity Recognition and Part-of-Speech Tagging) among the understudied but interconnected Chinese-Japanese-Korean-Vietnamese (CJKV) languages. Our pilot study reveals phonemic transcription provides essential information beyond the orthography to enhance cross-lingual transfer and bridge the gap among CJKV languages, leading to consistent improvements on cross-lingual token-level tasks over orthographic-based multilingual PLMs.
Diffusion idea exploration for art generation
Jul 11, 2023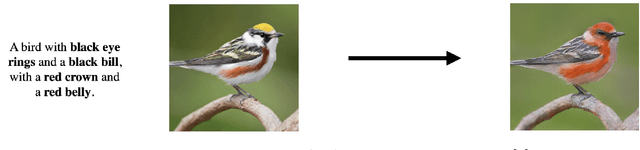


Cross-Modal learning tasks have picked up pace in recent times. With plethora of applications in diverse areas, generation of novel content using multiple modalities of data has remained a challenging problem. To address the same, various generative modelling techniques have been proposed for specific tasks. Novel and creative image generation is one important aspect for industrial application which could help as an arm for novel content generation. Techniques proposed previously used Generative Adversarial Network(GAN), autoregressive models and Variational Autoencoders (VAE) for accomplishing similar tasks. These approaches are limited in their capability to produce images guided by either text instructions or rough sketch images decreasing the overall performance of image generator. We used state of the art diffusion models to generate creative art by primarily leveraging text with additional support of rough sketches. Diffusion starts with a pattern of random dots and slowly converts that pattern into a design image using the guiding information fed into the model. Diffusion models have recently outperformed other generative models in image generation tasks using cross modal data as guiding information. The initial experiments for this task of novel image generation demonstrated promising qualitative results.
Robust Estimation of Surface Curvature Information from Point Cloud Data
Jun 01, 2023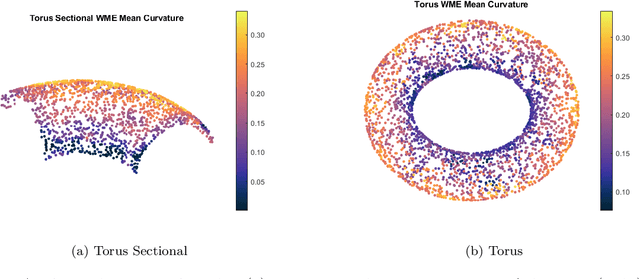
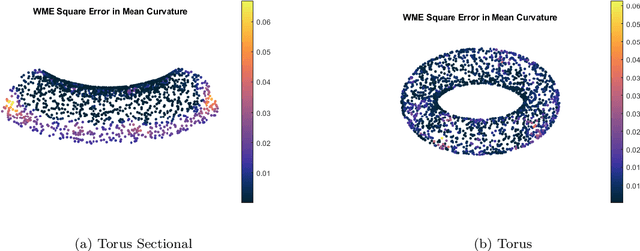
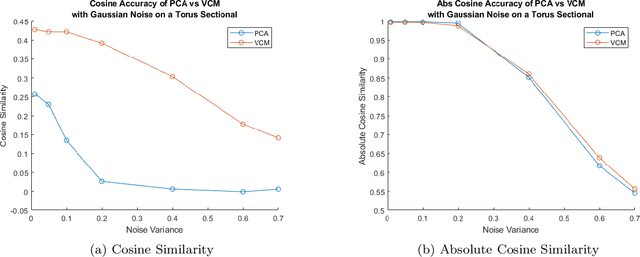
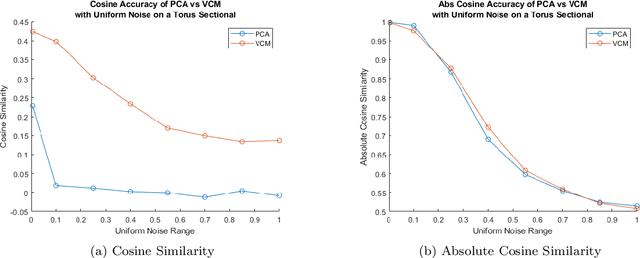
This paper surveys and evaluates some popular state of the art methods for algorithmic curvature and normal estimation. In addition to surveying existing methods we also propose a new method for robust curvature estimation and evaluate it against existing methods thus demonstrating its superiority to existing methods in the case of significant data noise. Throughout this paper we are concerned with computation in low dimensional spaces (N < 10) and primarily focus on the computation of the Weingarten map and quantities that may be derived from this; however, the algorithms discussed are theoretically applicable in any dimension. One thing that is common to all these methods is their basis in an estimated graph structure. For any of these methods to work the local geometry of the manifold must be exploited; however, in the case of point cloud data it is often difficult to discover a robust manifold structure underlying the data, even in simple cases, which can greatly influence the results of these algorithms. We hope that in pushing these algorithms to their limits we are able to discover, and perhaps resolve, many major pitfalls that may affect potential users and future researchers hoping to improve these methods
LiDAR Meta Depth Completion
Jul 24, 2023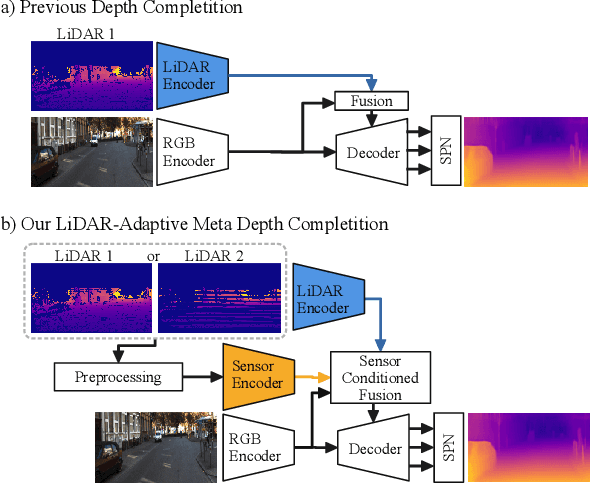

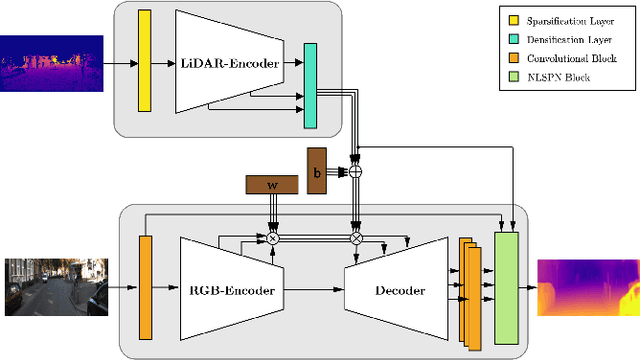
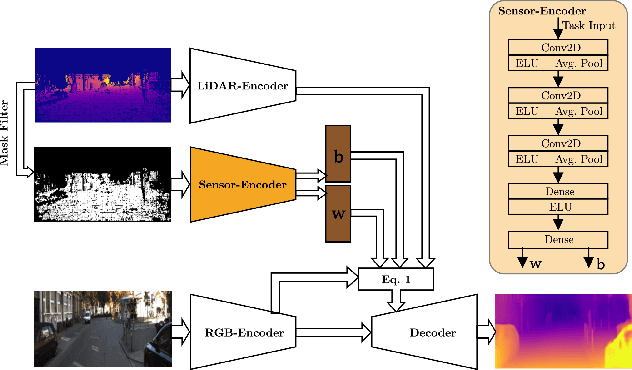
Depth estimation is one of the essential tasks to be addressed when creating mobile autonomous systems. While monocular depth estimation methods have improved in recent times, depth completion provides more accurate and reliable depth maps by additionally using sparse depth information from other sensors such as LiDAR. However, current methods are specifically trained for a single LiDAR sensor. As the scanning pattern differs between sensors, every new sensor would require re-training a specialized depth completion model, which is computationally inefficient and not flexible. Therefore, we propose to dynamically adapt the depth completion model to the used sensor type enabling LiDAR adaptive depth completion. Specifically, we propose a meta depth completion network that uses data patterns derived from the data to learn a task network to alter weights of the main depth completion network to solve a given depth completion task effectively. The method demonstrates a strong capability to work on multiple LiDAR scanning patterns and can also generalize to scanning patterns that are unseen during training. While using a single model, our method yields significantly better results than a non-adaptive baseline trained on different LiDAR patterns. It outperforms LiDAR-specific expert models for very sparse cases. These advantages allow flexible deployment of a single depth completion model on different sensors, which could also prove valuable to process the input of nascent LiDAR technology with adaptive instead of fixed scanning patterns.
Is attention all you need in medical image analysis? A review
Jul 24, 2023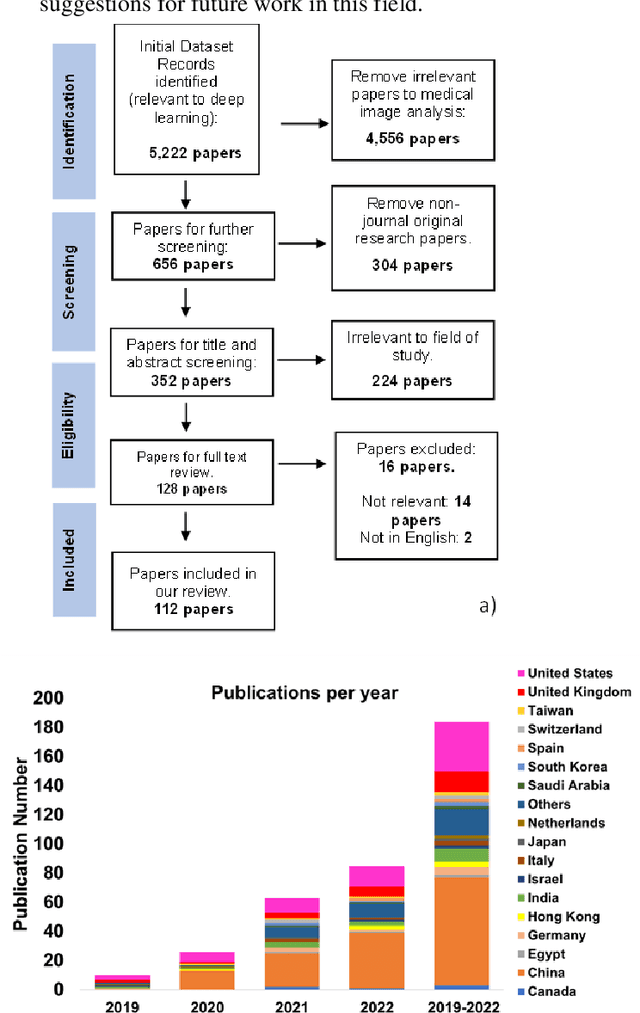
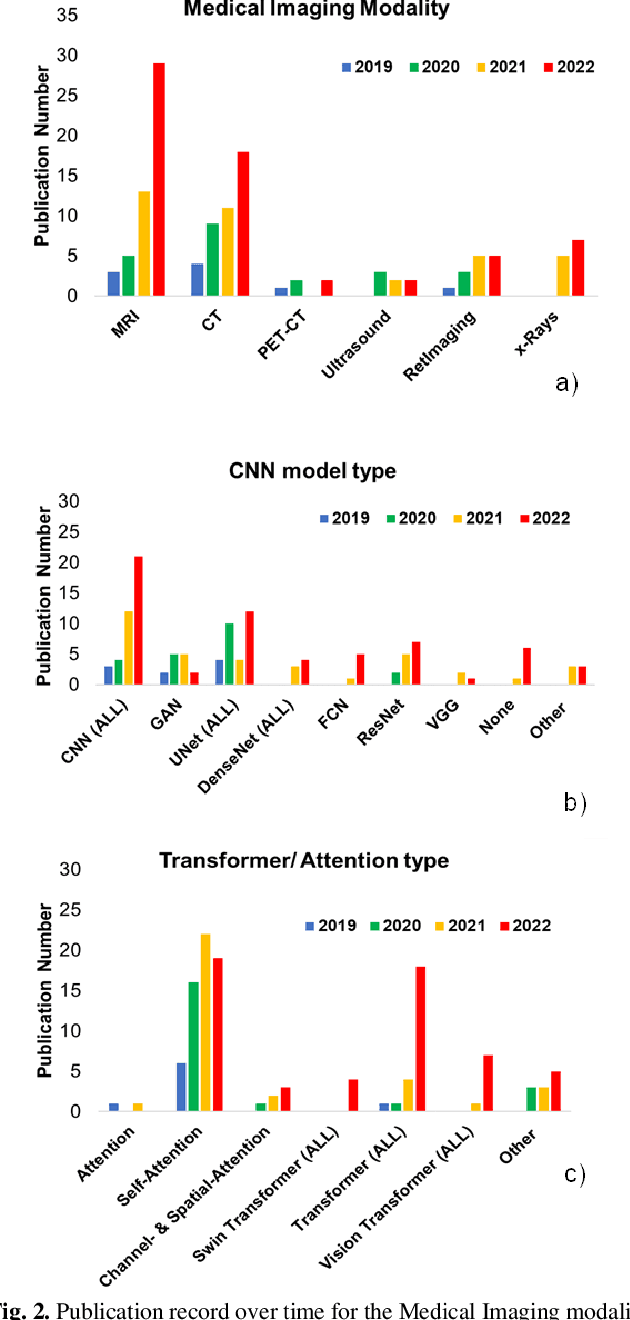
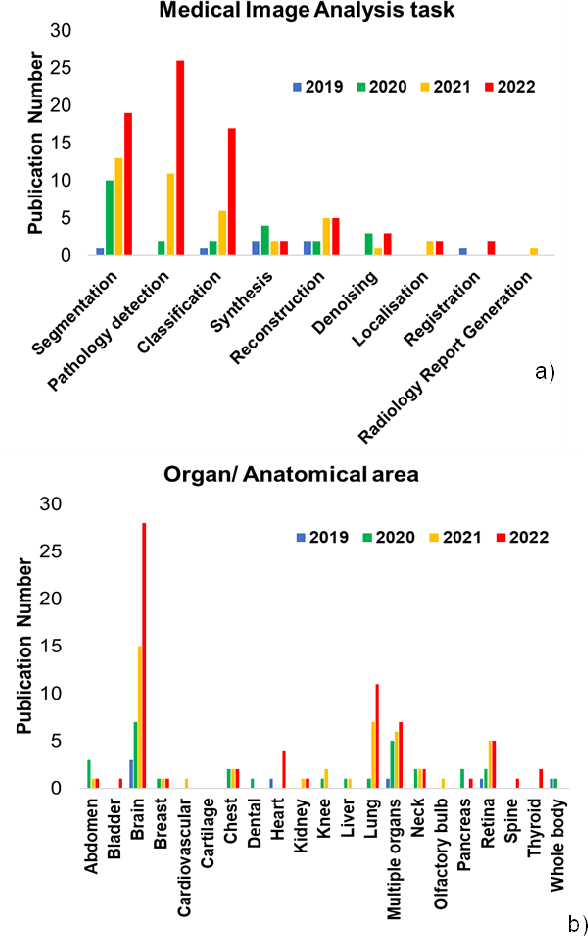
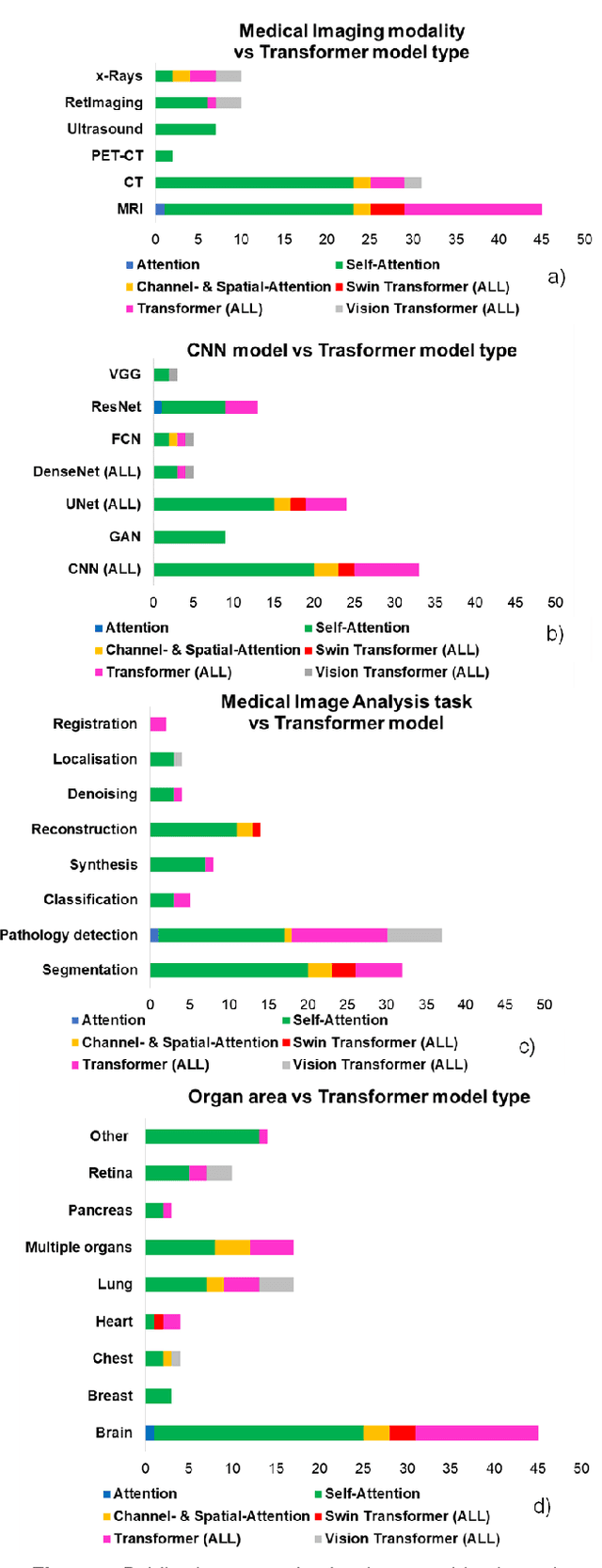
Medical imaging is a key component in clinical diagnosis, treatment planning and clinical trial design, accounting for almost 90% of all healthcare data. CNNs achieved performance gains in medical image analysis (MIA) over the last years. CNNs can efficiently model local pixel interactions and be trained on small-scale MI data. The main disadvantage of typical CNN models is that they ignore global pixel relationships within images, which limits their generalisation ability to understand out-of-distribution data with different 'global' information. The recent progress of Artificial Intelligence gave rise to Transformers, which can learn global relationships from data. However, full Transformer models need to be trained on large-scale data and involve tremendous computational complexity. Attention and Transformer compartments (Transf/Attention) which can well maintain properties for modelling global relationships, have been proposed as lighter alternatives of full Transformers. Recently, there is an increasing trend to co-pollinate complementary local-global properties from CNN and Transf/Attention architectures, which led to a new era of hybrid models. The past years have witnessed substantial growth in hybrid CNN-Transf/Attention models across diverse MIA problems. In this systematic review, we survey existing hybrid CNN-Transf/Attention models, review and unravel key architectural designs, analyse breakthroughs, and evaluate current and future opportunities as well as challenges. We also introduced a comprehensive analysis framework on generalisation opportunities of scientific and clinical impact, based on which new data-driven domain generalisation and adaptation methods can be stimulated.