 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Regionalization within a Differentiable High-Resolution Hydrological Model using Accurate Spatial Cost Gradients
Aug 02, 2023
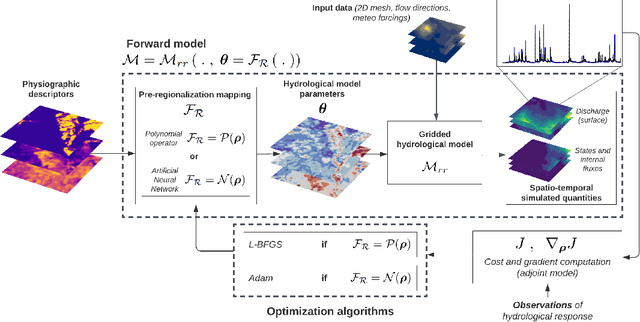

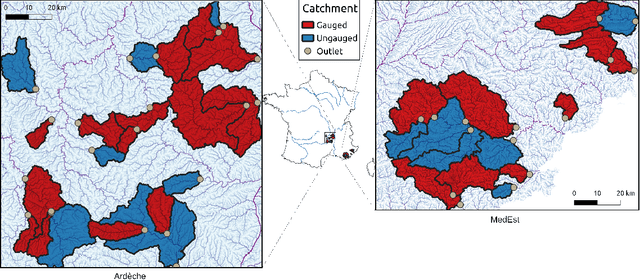
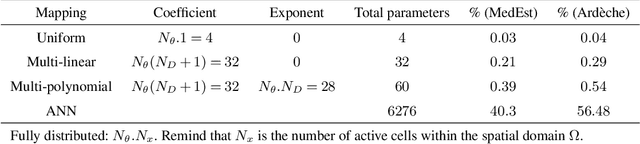
Estimating spatially distributed hydrological parameters in ungauged catchments poses a challenging regionalization problem and requires imposing spatial constraints given the sparsity of discharge data. A possible approach is to search for a transfer function that quantitatively relates physical descriptors to conceptual model parameters. This paper introduces a Hybrid Data Assimilation and Parameter Regionalization (HDA-PR) approach incorporating learnable regionalization mappings, based on either multivariate regressions or neural networks, into a differentiable hydrological model. It enables the exploitation of heterogeneous datasets across extensive spatio-temporal computational domains within a high-dimensional regionalization context, using accurate adjoint-based gradients. The inverse problem is tackled with a multi-gauge calibration cost function accounting for information from multiple observation sites. HDA-PR was tested on high-resolution, hourly and kilometric regional modeling of two flash-flood-prone areas located in the South of France. In both study areas, the median Nash-Sutcliffe efficiency (NSE) scores ranged from 0.52 to 0.78 at pseudo-ungauged sites over calibration and validation periods. These results highlight a strong regionalization performance of HDA-PR, improving NSE by up to 0.57 compared to the baseline model calibrated with lumped parameters, and achieving a performance comparable to the reference solution obtained with local uniform calibration (median NSE from 0.59 to 0.79). Multiple evaluation metrics based on flood-oriented hydrological signatures are also employed to assess the accuracy and robustness of the approach. The regionalization method is amenable to state-parameter correction from multi-source data over a range of time scales needed for operational data assimilation, and it is adaptable to other differentiable geophysical models.
Node Injection Link Stealing Attack
Jul 25, 2023In this paper, we present a stealthy and effective attack that exposes privacy vulnerabilities in Graph Neural Networks (GNNs) by inferring private links within graph-structured data. Focusing on the inductive setting where new nodes join the graph and an API is used to query predictions, we investigate the potential leakage of private edge information. We also propose methods to preserve privacy while maintaining model utility. Our attack demonstrates superior performance in inferring the links compared to the state of the art. Furthermore, we examine the application of differential privacy (DP) mechanisms to mitigate the impact of our proposed attack, we analyze the trade-off between privacy preservation and model utility. Our work highlights the privacy vulnerabilities inherent in GNNs, underscoring the importance of developing robust privacy-preserving mechanisms for their application.
MAEA: Multimodal Attribution for Embodied AI
Jul 25, 2023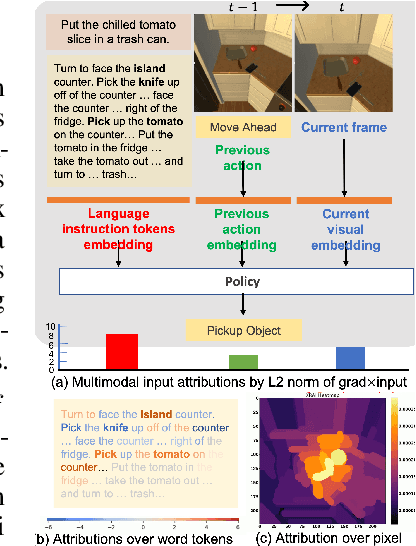

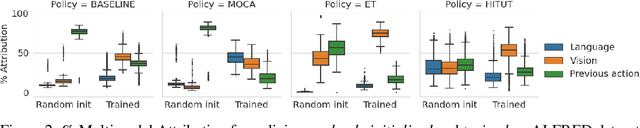
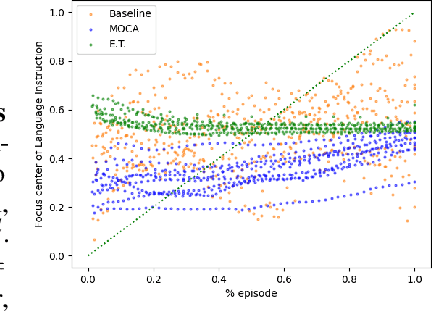
Understanding multimodal perception for embodied AI is an open question because such inputs may contain highly complementary as well as redundant information for the task. A relevant direction for multimodal policies is understanding the global trends of each modality at the fusion layer. To this end, we disentangle the attributions for visual, language, and previous action inputs across different policies trained on the ALFRED dataset. Attribution analysis can be utilized to rank and group the failure scenarios, investigate modeling and dataset biases, and critically analyze multimodal EAI policies for robustness and user trust before deployment. We present MAEA, a framework to compute global attributions per modality of any differentiable policy. In addition, we show how attributions enable lower-level behavior analysis in EAI policies for language and visual attributions.
A short review of the main concerns in A.I. development and application within the public sector supported by NLP and TM
Jul 25, 2023Artificial Intelligence is not a new subject, and business, industry and public sectors have used it in different ways and contexts and considering multiple concerns. This work reviewed research papers published in ACM Digital Library and IEEE Xplore conference proceedings in the last two years supported by fundamental concepts of Natural Language Processing (NLP) and Text Mining (TM). The objective was to capture insights regarding data privacy, ethics, interpretability, explainability, trustworthiness, and fairness in the public sector. The methodology has saved analysis time and could retrieve papers containing relevant information. The results showed that fairness was the most frequent concern. The least prominent topic was data privacy (although embedded in most articles), while the most prominent was trustworthiness. Finally, gathering helpful insights about those concerns regarding A.I. applications in the public sector was also possible.
Substance or Style: What Does Your Image Embedding Know?
Jul 10, 2023
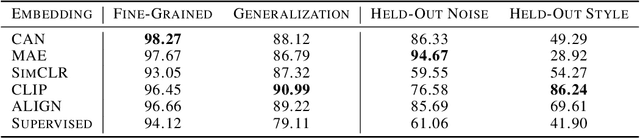


Probes are small networks that predict properties of underlying data from embeddings, and they provide a targeted, effective way to illuminate the information contained in embeddings. While analysis through the use of probes has become standard in NLP, there has been much less exploration in vision. Image foundation models have primarily been evaluated for semantic content. Better understanding the non-semantic information in popular embeddings (e.g., MAE, SimCLR, or CLIP) will shed new light both on the training algorithms and on the uses for these foundation models. We design a systematic transformation prediction task and measure the visual content of embeddings along many axes, including image style, quality, and a range of natural and artificial transformations. Surprisingly, six embeddings (including SimCLR) encode enough non-semantic information to identify dozens of transformations. We also consider a generalization task, where we group similar transformations and hold out several for testing. We find that image-text models (CLIP and ALIGN) are better at recognizing new examples of style transfer than masking-based models (CAN and MAE). Overall, our results suggest that the choice of pre-training algorithm impacts the types of information in the embedding, and certain models are better than others for non-semantic downstream tasks.
Cross-Ray Neural Radiance Fields for Novel-view Synthesis from Unconstrained Image Collections
Jul 16, 2023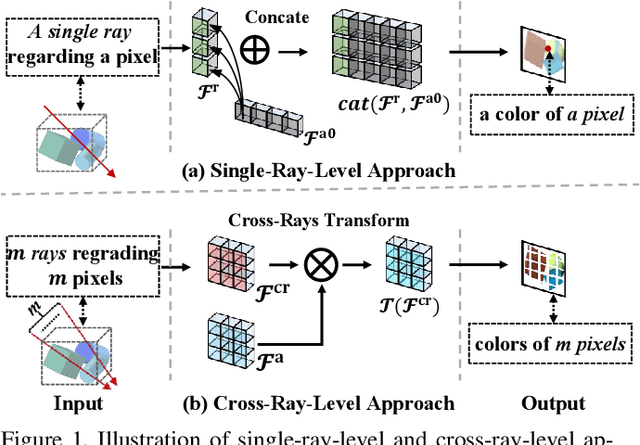
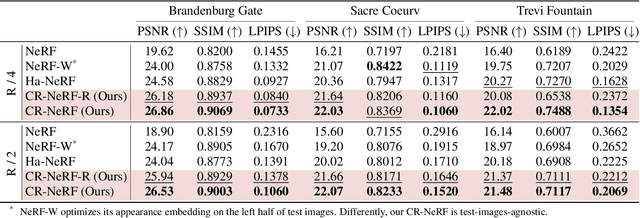
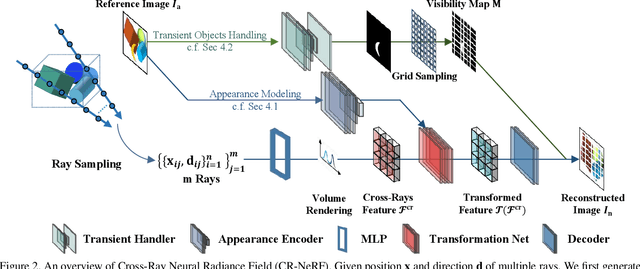

Neural Radiance Fields (NeRF) is a revolutionary approach for rendering scenes by sampling a single ray per pixel and it has demonstrated impressive capabilities in novel-view synthesis from static scene images. However, in practice, we usually need to recover NeRF from unconstrained image collections, which poses two challenges: 1) the images often have dynamic changes in appearance because of different capturing time and camera settings; 2) the images may contain transient objects such as humans and cars, leading to occlusion and ghosting artifacts. Conventional approaches seek to address these challenges by locally utilizing a single ray to synthesize a color of a pixel. In contrast, humans typically perceive appearance and objects by globally utilizing information across multiple pixels. To mimic the perception process of humans, in this paper, we propose Cross-Ray NeRF (CR-NeRF) that leverages interactive information across multiple rays to synthesize occlusion-free novel views with the same appearances as the images. Specifically, to model varying appearances, we first propose to represent multiple rays with a novel cross-ray feature and then recover the appearance by fusing global statistics, i.e., feature covariance of the rays and the image appearance. Moreover, to avoid occlusion introduced by transient objects, we propose a transient objects handler and introduce a grid sampling strategy for masking out the transient objects. We theoretically find that leveraging correlation across multiple rays promotes capturing more global information. Moreover, extensive experimental results on large real-world datasets verify the effectiveness of CR-NeRF.
CodeIE: Large Code Generation Models are Better Few-Shot Information Extractors
May 11, 2023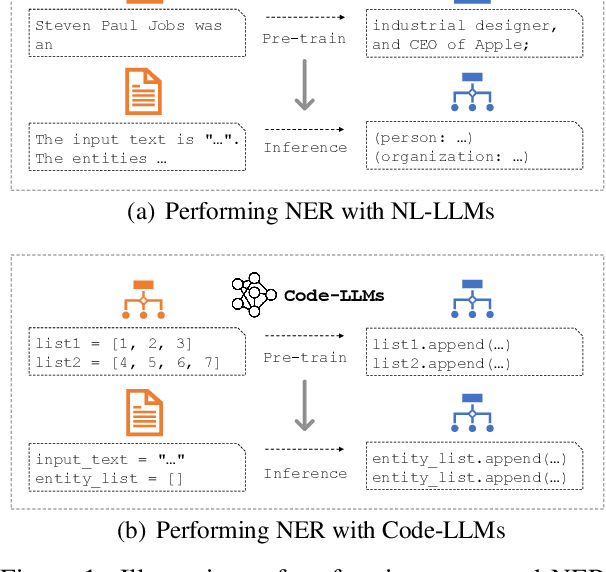
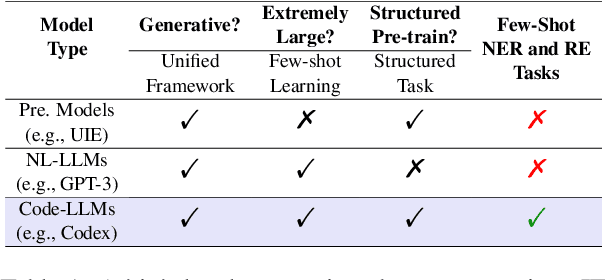
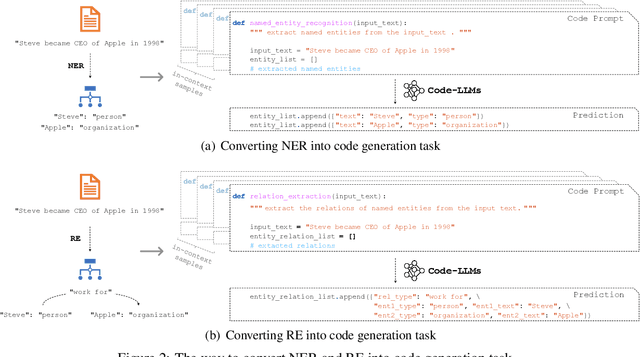
Large language models (LLMs) pre-trained on massive corpora have demonstrated impressive few-shot learning ability on many NLP tasks. A common practice is to recast the task into a text-to-text format such that generative LLMs of natural language (NL-LLMs) like GPT-3 can be prompted to solve it. However, it is nontrivial to perform information extraction (IE) tasks with NL-LLMs since the output of the IE task is usually structured and therefore is hard to be converted into plain text. In this paper, we propose to recast the structured output in the form of code instead of natural language and utilize generative LLMs of code (Code-LLMs) such as Codex to perform IE tasks, in particular, named entity recognition and relation extraction. In contrast to NL-LLMs, we show that Code-LLMs can be well-aligned with these IE tasks by designing code-style prompts and formulating these IE tasks as code generation tasks. Experiment results on seven benchmarks show that our method consistently outperforms fine-tuning moderate-size pre-trained models specially designed for IE tasks (e.g., UIE) and prompting NL-LLMs under few-shot settings. We further conduct a series of in-depth analyses to demonstrate the merits of leveraging Code-LLMs for IE tasks.
SCPAT-GAN: Structural Constrained and Pathology Aware Convolutional Transformer-GAN for Virtual Histology Staining of Human Coronary OCT images
Jul 22, 2023There is a significant need for the generation of virtual histological information from coronary optical coherence tomography (OCT) images to better guide the treatment of coronary artery disease. However, existing methods either require a large pixel-wisely paired training dataset or have limited capability to map pathological regions. To address these issues, we proposed a structural constrained, pathology aware, transformer generative adversarial network, namely SCPAT-GAN, to generate virtual stained H&E histology from OCT images. The proposed SCPAT-GAN advances existing methods via a novel design to impose pathological guidance on structural layers using transformer-based network.
Retrieving Comparative Arguments using Ensemble Methods and Neural Information Retrieval
May 01, 2023
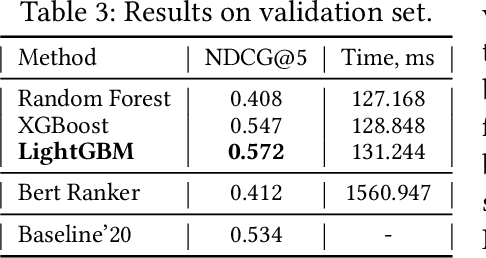


In this paper, we present a submission to the Touche lab's Task 2 on Argument Retrieval for Comparative Questions. Our team Katana supplies several approaches based on decision tree ensembles algorithms to rank comparative documents in accordance with their relevance and argumentative support. We use PyTerrier library to apply ensembles models to a ranking problem, considering statistical text features and features based on comparative structures. We also employ large contextualized language modelling techniques, such as BERT, to solve the proposed ranking task. To merge this technique with ranking modelling, we leverage neural ranking library OpenNIR. Our systems substantially outperforming the proposed baseline and scored first in relevance and second in quality according to the official metrics of the competition (for measure NDCG@5 score). Presented models could help to improve the performance of processing comparative queries in information retrieval and dialogue systems.
Performance Issue Identification in Cloud Systems with Relational-Temporal Anomaly Detection
Aug 01, 2023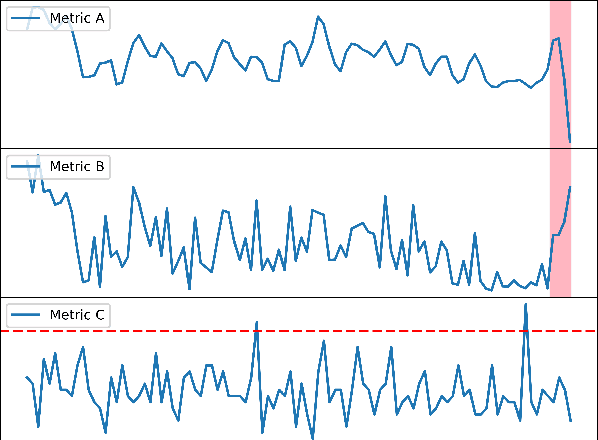
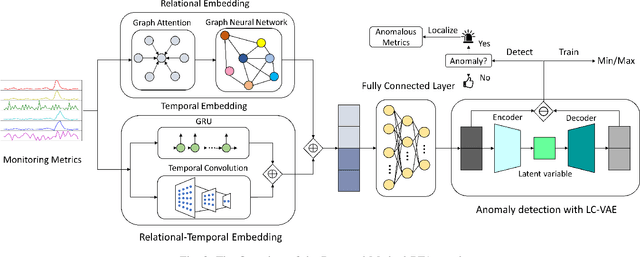
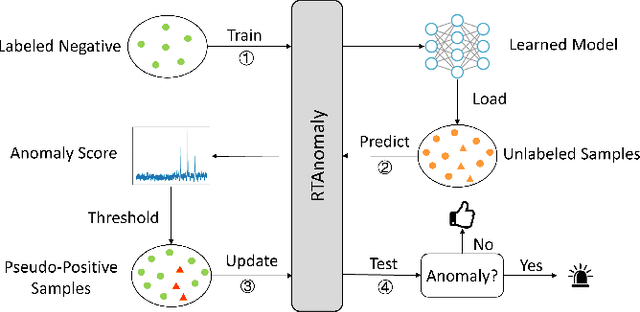
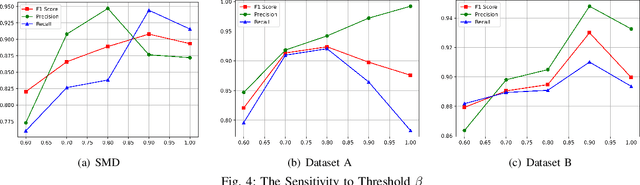
Performance issues permeate large-scale cloud service systems, which can lead to huge revenue losses. To ensure reliable performance, it's essential to accurately identify and localize these issues using service monitoring metrics. Given the complexity and scale of modern cloud systems, this task can be challenging and may require extensive expertise and resources beyond the capacity of individual humans. Some existing methods tackle this problem by analyzing each metric independently to detect anomalies. However, this could incur overwhelming alert storms that are difficult for engineers to diagnose manually. To pursue better performance, not only the temporal patterns of metrics but also the correlation between metrics (i.e., relational patterns) should be considered, which can be formulated as a multivariate metrics anomaly detection problem. However, most of the studies fall short of extracting these two types of features explicitly. Moreover, there exist some unlabeled anomalies mixed in the training data, which may hinder the detection performance. To address these limitations, we propose the Relational- Temporal Anomaly Detection Model (RTAnomaly) that combines the relational and temporal information of metrics. RTAnomaly employs a graph attention layer to learn the dependencies among metrics, which will further help pinpoint the anomalous metrics that may cause the anomaly effectively. In addition, we exploit the concept of positive unlabeled learning to address the issue of potential anomalies in the training data. To evaluate our method, we conduct experiments on a public dataset and two industrial datasets. RTAnomaly outperforms all the baseline models by achieving an average F1 score of 0.929 and Hit@3 of 0.920, demonstrating its superiority.