 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Supervised Visual Acoustic Matching
Jul 27, 2023

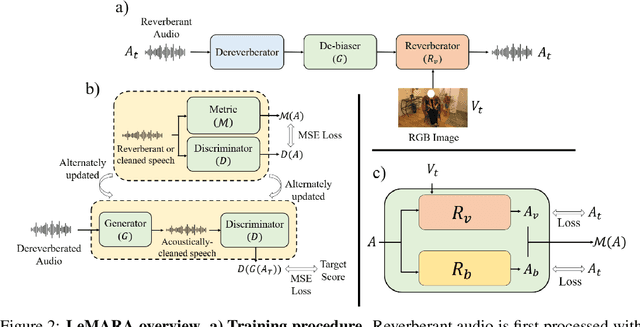


Acoustic matching aims to re-synthesize an audio clip to sound as if it were recorded in a target acoustic environment. Existing methods assume access to paired training data, where the audio is observed in both source and target environments, but this limits the diversity of training data or requires the use of simulated data or heuristics to create paired samples. We propose a self-supervised approach to visual acoustic matching where training samples include only the target scene image and audio -- without acoustically mismatched source audio for reference. Our approach jointly learns to disentangle room acoustics and re-synthesize audio into the target environment, via a conditional GAN framework and a novel metric that quantifies the level of residual acoustic information in the de-biased audio. Training with either in-the-wild web data or simulated data, we demonstrate it outperforms the state-of-the-art on multiple challenging datasets and a wide variety of real-world audio and environments.
Multi-Robot Multi-Room Exploration with Geometric Cue Extraction and Spherical Decomposition
Jul 27, 2023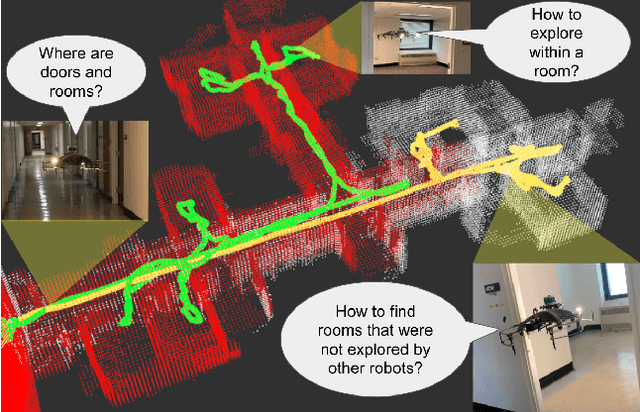
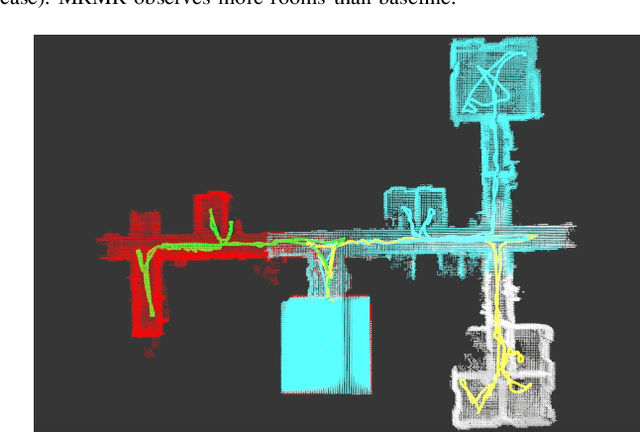
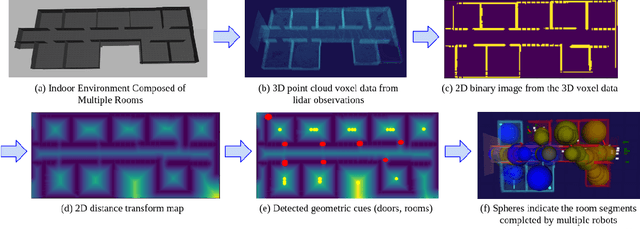
This work proposes an autonomous multi-robot exploration pipeline that coordinates the behaviors of robots in an indoor environment composed of multiple rooms. Contrary to simple frontier-based exploration approaches, we aim to enable robots to methodically explore and observe an unknown set of rooms in a structured building, keeping track of which rooms are already explored and sharing this information among robots to coordinate their behaviors in a distributed manner. To this end, we propose (1) a geometric cue extraction method that processes 3D map point cloud data and detects the locations of potential cues such as doors and rooms, (2) a spherical decomposition for open spaces used for target assignment. Using these two components, our pipeline effectively assigns tasks among robots, and enables a methodical exploration of rooms. We evaluate the performance of our pipeline using a team of up to 3 aerial robots, and show that our method outperforms the baseline by 36.6% in simulation and 26.4% in real-world experiments.
Evaluating Generative Models for Graph-to-Text Generation
Jul 27, 2023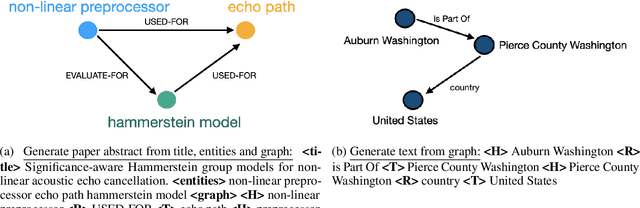



Large language models (LLMs) have been widely employed for graph-to-text generation tasks. However, the process of finetuning LLMs requires significant training resources and annotation work. In this paper, we explore the capability of generative models to generate descriptive text from graph data in a zero-shot setting. Specifically, we evaluate GPT-3 and ChatGPT on two graph-to-text datasets and compare their performance with that of finetuned LLM models such as T5 and BART. Our results demonstrate that generative models are capable of generating fluent and coherent text, achieving BLEU scores of 10.57 and 11.08 for the AGENDA and WebNLG datasets, respectively. However, our error analysis reveals that generative models still struggle with understanding the semantic relations between entities, and they also tend to generate text with hallucinations or irrelevant information. As a part of error analysis, we utilize BERT to detect machine-generated text and achieve high macro-F1 scores. We have made the text generated by generative models publicly available.
CodeLens: An Interactive Tool for Visualizing Code Representations
Jul 27, 2023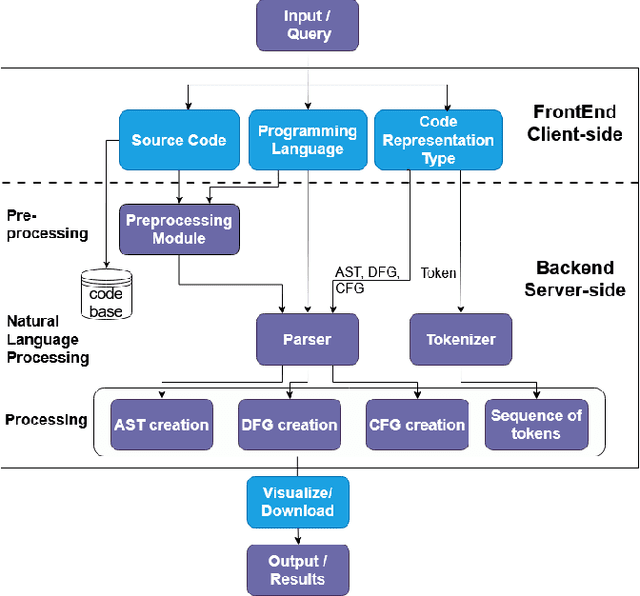
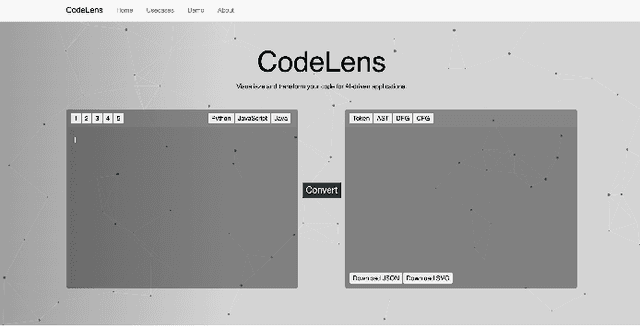
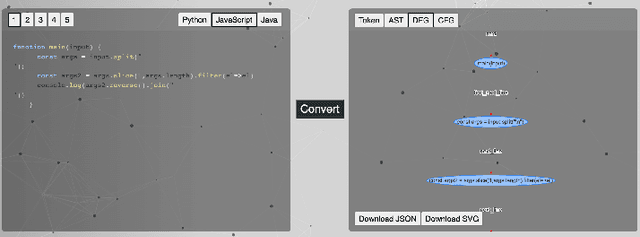
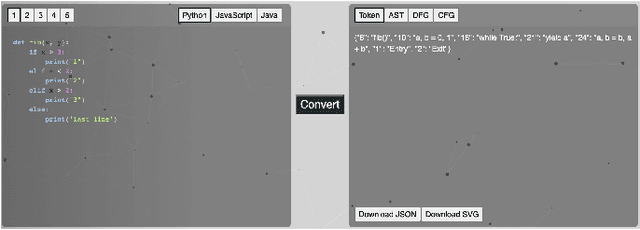
Representing source code in a generic input format is crucial to automate software engineering tasks, e.g., applying machine learning algorithms to extract information. Visualizing code representations can further enable human experts to gain an intuitive insight into the code. Unfortunately, as of today, there is no universal tool that can simultaneously visualise different types of code representations. In this paper, we introduce a tool, CodeLens, which provides a visual interaction environment that supports various representation methods and helps developers understand and explore them. CodeLens is designed to support multiple programming languages, such as Java, Python, and JavaScript, and four types of code representations, including sequence of tokens, abstract syntax tree (AST), data flow graph (DFG), and control flow graph (CFG). By using CodeLens, developers can quickly visualize the specific code representation and also obtain the represented inputs for models of code. The Web-based interface of CodeLens is available at http://www.codelens.org. The demonstration video can be found at http://www.codelens.org/demo.
A Time-Frequency Generative Adversarial based method for Audio Packet Loss Concealment
Jul 28, 2023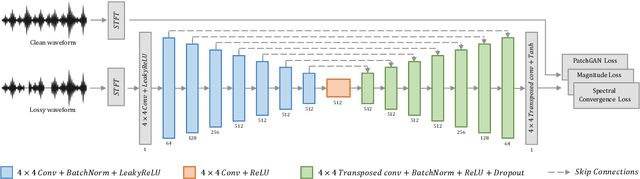
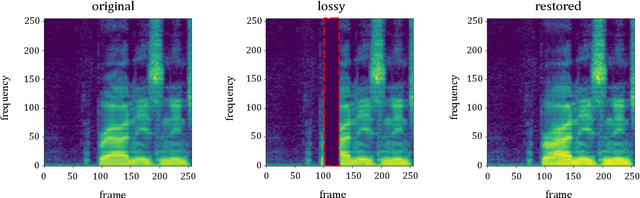
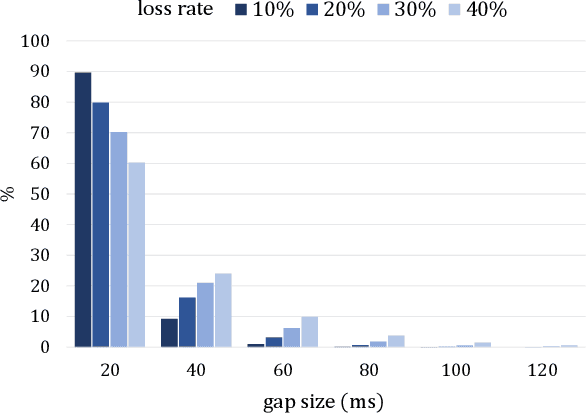
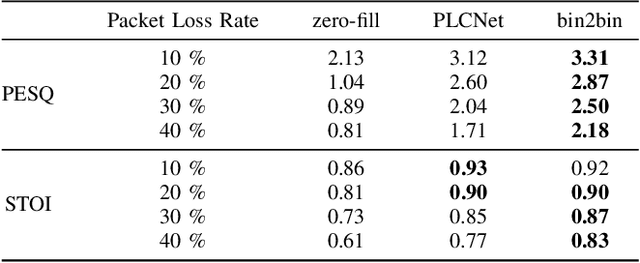
Packet loss is a major cause of voice quality degradation in VoIP transmissions with serious impact on intelligibility and user experience. This paper describes a system based on a generative adversarial approach, which aims to repair the lost fragments during the transmission of audio streams. Inspired by the powerful image-to-image translation capability of Generative Adversarial Networks (GANs), we propose bin2bin, an improved pix2pix framework to achieve the translation task from magnitude spectrograms of audio frames with lost packets, to noncorrupted speech spectrograms. In order to better maintain the structural information after spectrogram translation, this paper introduces the combination of two STFT-based loss functions, mixed with the traditional GAN objective. Furthermore, we employ a modified PatchGAN structure as discriminator and we lower the concealment time by a proper initialization of the phase reconstruction algorithm. Experimental results show that the proposed method has obvious advantages when compared with the current state-of-the-art methods, as it can better handle both high packet loss rates and large gaps.
CHATREPORT: Democratizing Sustainability Disclosure Analysis through LLM-based Tools
Jul 28, 2023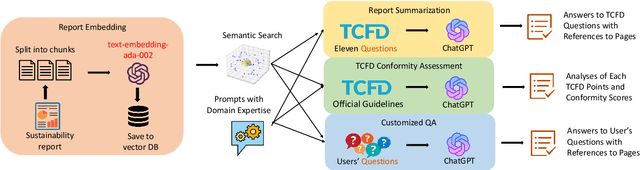

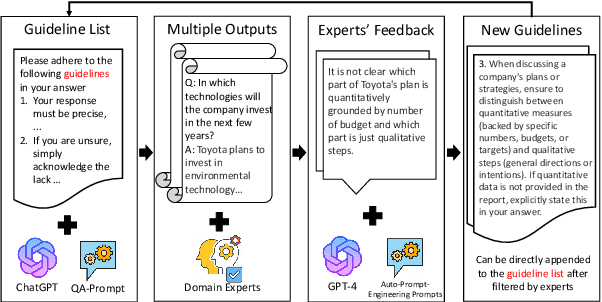

In the face of climate change, are companies really taking substantial steps toward more sustainable operations? A comprehensive answer lies in the dense, information-rich landscape of corporate sustainability reports. However, the sheer volume and complexity of these reports make human analysis very costly. Therefore, only a few entities worldwide have the resources to analyze these reports at scale, which leads to a lack of transparency in sustainability reporting. Empowering stakeholders with LLM-based automatic analysis tools can be a promising way to democratize sustainability report analysis. However, developing such tools is challenging due to (1) the hallucination of LLMs and (2) the inefficiency of bringing domain experts into the AI development loop. In this paper, we ChatReport, a novel LLM-based system to automate the analysis of corporate sustainability reports, addressing existing challenges by (1) making the answers traceable to reduce the harm of hallucination and (2) actively involving domain experts in the development loop. We make our methodology, annotated datasets, and generated analyses of 1015 reports publicly available.
Sat2Cap: Mapping Fine-Grained Textual Descriptions from Satellite Images
Jul 29, 2023


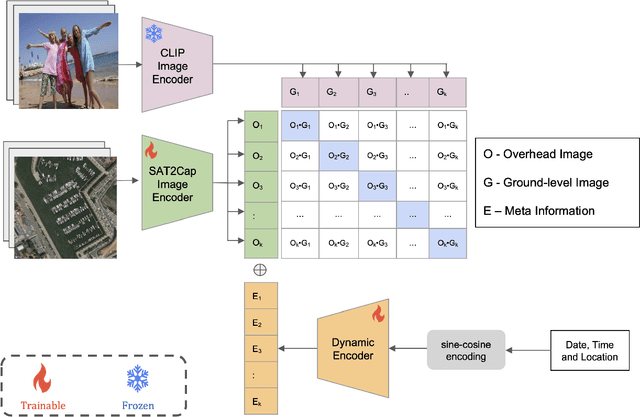
We propose a novel weakly supervised approach for creating maps using free-form textual descriptions (or captions). We refer to this new line of work of creating textual maps as zero-shot mapping. Prior works have approached mapping tasks by developing models that predict over a fixed set of attributes using overhead imagery. However, these models are very restrictive as they can only solve highly specific tasks for which they were trained. Mapping text, on the other hand, allows us to solve a large variety of mapping problems with minimal restrictions. To achieve this, we train a contrastive learning framework called Sat2Cap on a new large-scale dataset of paired overhead and ground-level images. For a given location, our model predicts the expected CLIP embedding of the ground-level scenery. Sat2Cap is also conditioned on temporal information, enabling it to learn dynamic concepts that vary over time. Our experimental results demonstrate that our models successfully capture fine-grained concepts and effectively adapt to temporal variations. Our approach does not require any text-labeled data making the training easily scalable. The code, dataset, and models will be made publicly available.
METTS: Multilingual Emotional Text-to-Speech by Cross-speaker and Cross-lingual Emotion Transfer
Jul 29, 2023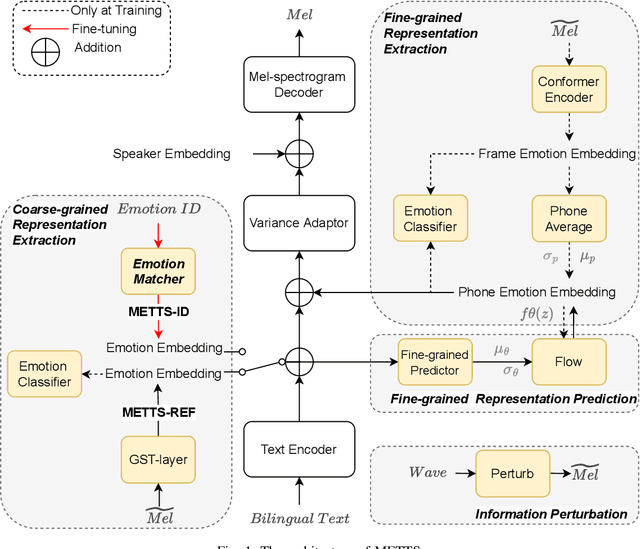
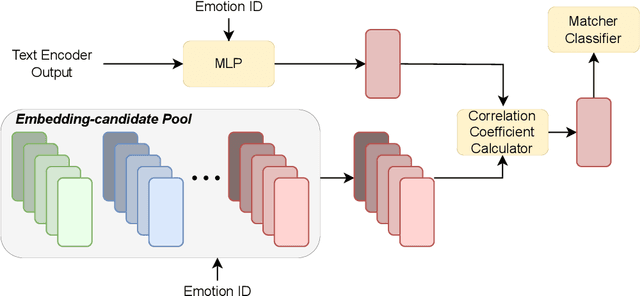
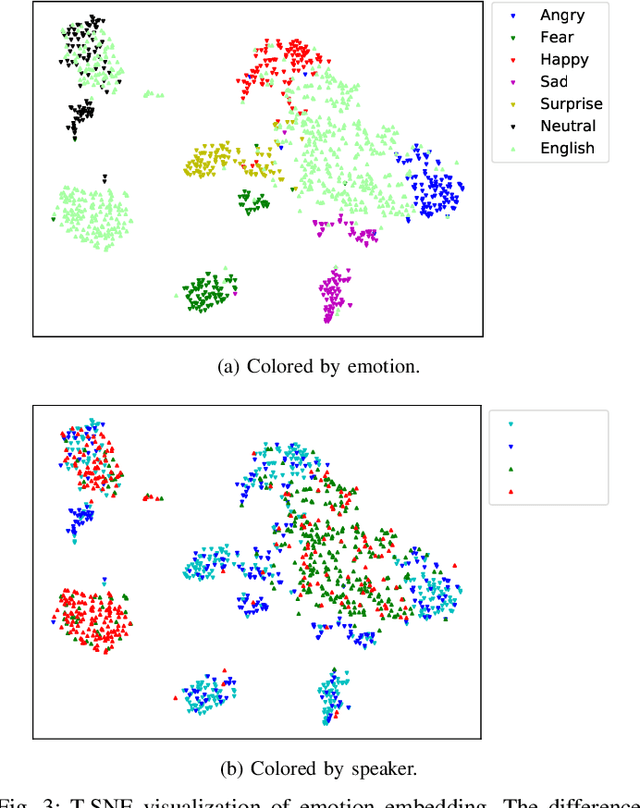

Previous multilingual text-to-speech (TTS) approaches have considered leveraging monolingual speaker data to enable cross-lingual speech synthesis. However, such data-efficient approaches have ignored synthesizing emotional aspects of speech due to the challenges of cross-speaker cross-lingual emotion transfer - the heavy entanglement of speaker timbre, emotion, and language factors in the speech signal will make a system produce cross-lingual synthetic speech with an undesired foreign accent and weak emotion expressiveness. This paper proposes the Multilingual Emotional TTS (METTS) model to mitigate these problems, realizing both cross-speaker and cross-lingual emotion transfer. Specifically, METTS takes DelightfulTTS as the backbone model and proposes the following designs. First, to alleviate the foreign accent problem, METTS introduces multi-scale emotion modeling to disentangle speech prosody into coarse-grained and fine-grained scales, producing language-agnostic and language-specific emotion representations, respectively. Second, as a pre-processing step, formant shift-based information perturbation is applied to the reference signal for better disentanglement of speaker timbre in the speech. Third, a vector quantization-based emotion matcher is designed for reference selection, leading to decent naturalness and emotion diversity in cross-lingual synthetic speech. Experiments demonstrate the good design of METTS.
Report from Dagstuhl Seminar 23031: Frontiers of Information Access Experimentation for Research and Education
Apr 18, 2023


This report documents the program and the outcomes of Dagstuhl Seminar 23031 ``Frontiers of Information Access Experimentation for Research and Education'', which brought together 37 participants from 12 countries. The seminar addressed technology-enhanced information access (information retrieval, recommender systems, natural language processing) and specifically focused on developing more responsible experimental practices leading to more valid results, both for research as well as for scientific education. The seminar brought together experts from various sub-fields of information access, namely IR, RS, NLP, information science, and human-computer interaction to create a joint understanding of the problems and challenges presented by next generation information access systems, from both the research and the experimentation point of views, to discuss existing solutions and impediments, and to propose next steps to be pursued in the area in order to improve not also our research methods and findings but also the education of the new generation of researchers and developers. The seminar featured a series of long and short talks delivered by participants, who helped in setting a common ground and in letting emerge topics of interest to be explored as the main output of the seminar. This led to the definition of five groups which investigated challenges, opportunities, and next steps in the following areas: reality check, i.e. conducting real-world studies, human-machine-collaborative relevance judgment frameworks, overcoming methodological challenges in information retrieval and recommender systems through awareness and education, results-blind reviewing, and guidance for authors.
On the Universality of Linear Recurrences Followed by Nonlinear Projections
Jul 21, 2023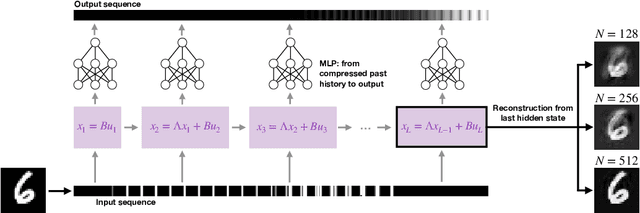

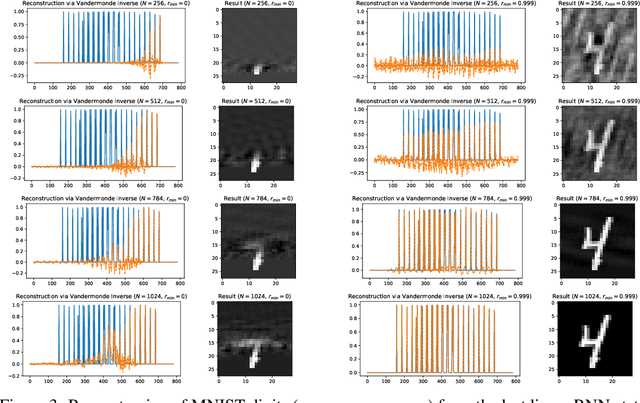
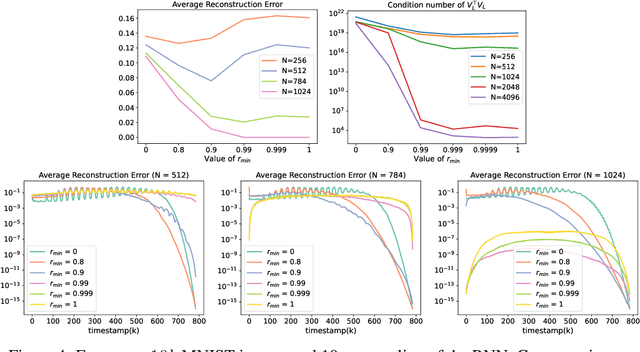
In this note (work in progress towards a full-length paper) we show that a family of sequence models based on recurrent linear layers~(including S4, S5, and the LRU) interleaved with position-wise multi-layer perceptrons~(MLPs) can approximate arbitrarily well any sufficiently regular non-linear sequence-to-sequence map. The main idea behind our result is to see recurrent layers as compression algorithms that can faithfully store information about the input sequence into an inner state, before it is processed by the highly expressive MLP.