 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Redemption from Range-view for Accurate 3D Object Detection
Jul 21, 2023
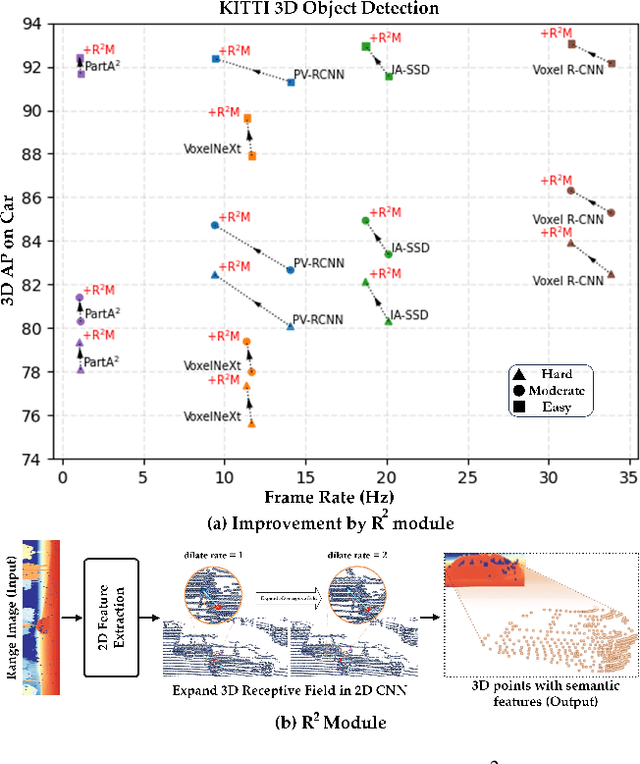
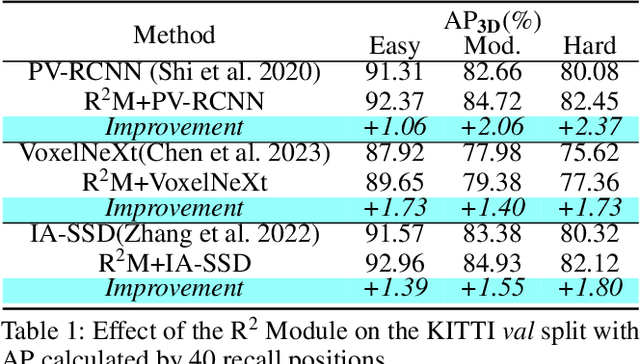
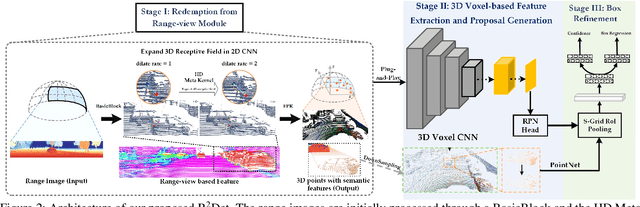
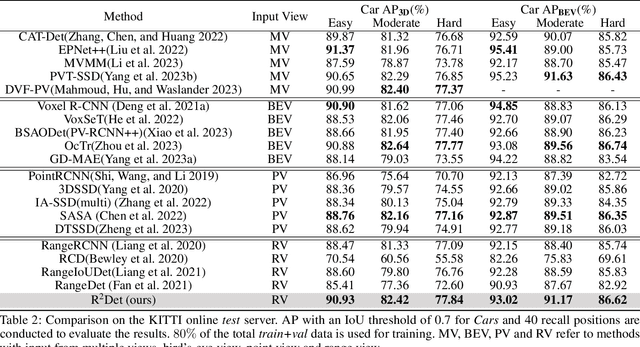
Most recent approaches for 3D object detection predominantly rely on point-view or bird's-eye view representations, with limited exploration of range-view-based methods. The range-view representation suffers from scale variation and surface texture deficiency, both of which pose significant limitations for developing corresponding methods. Notably, the surface texture loss problem has been largely ignored by all existing methods, despite its significant impact on the accuracy of range-view-based 3D object detection. In this study, we propose Redemption from Range-view R-CNN (R2 R-CNN), a novel and accurate approach that comprehensively explores the range-view representation. Our proposed method addresses scale variation through the HD Meta Kernel, which captures range-view geometry information in multiple scales. Additionally, we introduce Feature Points Redemption (FPR) to recover the lost 3D surface texture information from the range view, and Synchronous-Grid RoI Pooling (S-Grid RoI Pooling), a multi-scaled approach with multiple receptive fields for accurate box refinement. Our R2 R-CNN outperforms existing range-view-based methods, achieving state-of-the-art performance on both the KITTI benchmark and the Waymo Open Dataset. Our study highlights the critical importance of addressing the surface texture loss problem for accurate 3D object detection in range-view-based methods. Codes will be made publicly available.
Transformer-based end-to-end classification of variable-length volumetric data
Jul 21, 2023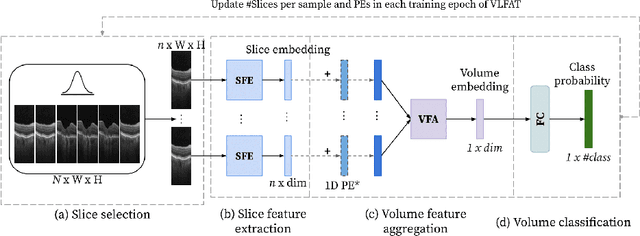
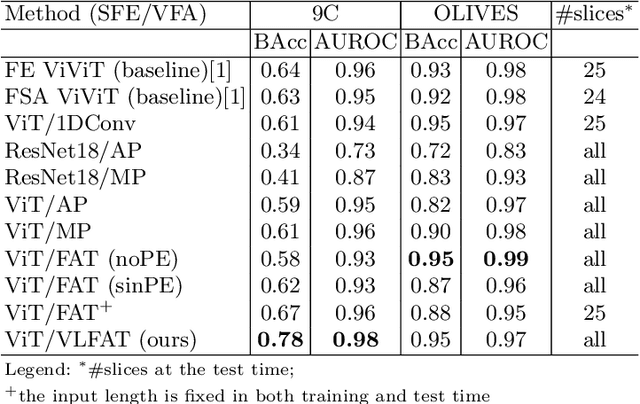
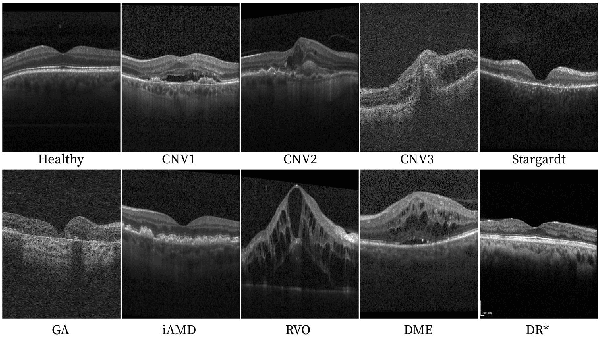
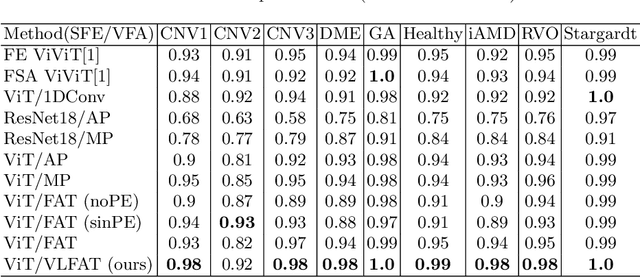
The automatic classification of 3D medical data is memory-intensive. Also, variations in the number of slices between samples is common. Na\"ive solutions such as subsampling can solve these problems, but at the cost of potentially eliminating relevant diagnosis information. Transformers have shown promising performance for sequential data analysis. However, their application for long sequences is data, computationally, and memory demanding. In this paper, we propose an end-to-end Transformer-based framework that allows to classify volumetric data of variable length in an efficient fashion. Particularly, by randomizing the input volume-wise resolution(#slices) during training, we enhance the capacity of the learnable positional embedding assigned to each volume slice. Consequently, the accumulated positional information in each positional embedding can be generalized to the neighbouring slices, even for high-resolution volumes at the test time. By doing so, the model will be more robust to variable volume length and amenable to different computational budgets. We evaluated the proposed approach in retinal OCT volume classification and achieved 21.96% average improvement in balanced accuracy on a 9-class diagnostic task, compared to state-of-the-art video transformers. Our findings show that varying the volume-wise resolution of the input during training results in more informative volume representation as compared to training with fixed number of slices per volume.
Towards Precise Weakly Supervised Object Detection via Interactive Contrastive Learning of Context Information
Apr 27, 2023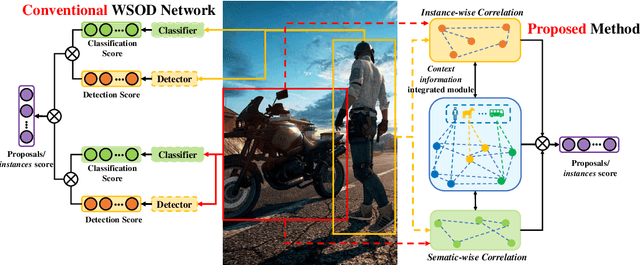
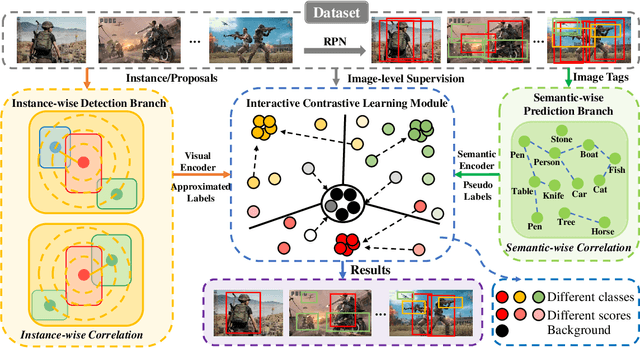
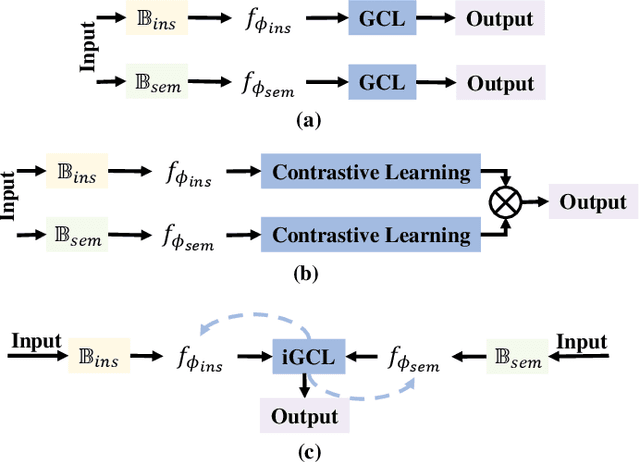

Weakly supervised object detection (WSOD) aims at learning precise object detectors with only image-level tags. In spite of intensive research on deep learning (DL) approaches over the past few years, there is still a significant performance gap between WSOD and fully supervised object detection. In fact, most existing WSOD methods only consider the visual appearance of each region proposal but ignore employing the useful context information in the image. To this end, this paper proposes an interactive end-to-end WSDO framework called JLWSOD with two innovations: i) two types of WSOD-specific context information (i.e., instance-wise correlation andsemantic-wise correlation) are proposed and introduced into WSOD framework; ii) an interactive graph contrastive learning (iGCL) mechanism is designed to jointly optimize the visual appearance and context information for better WSOD performance. Specifically, the iGCL mechanism takes full advantage of the complementary interpretations of the WSOD, namely instance-wise detection and semantic-wise prediction tasks, forming a more comprehensive solution. Extensive experiments on the widely used PASCAL VOC and MS COCO benchmarks verify the superiority of JLWSOD over alternative state-of-the-art approaches and baseline models (improvement of 3.6%~23.3% on mAP and 3.4%~19.7% on CorLoc, respectively).
Aggressive saliency-aware point cloud compression
Jul 20, 2023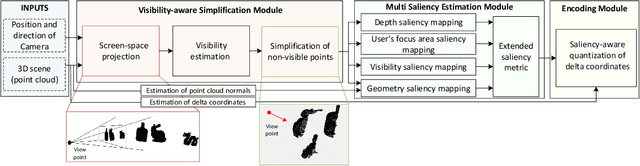
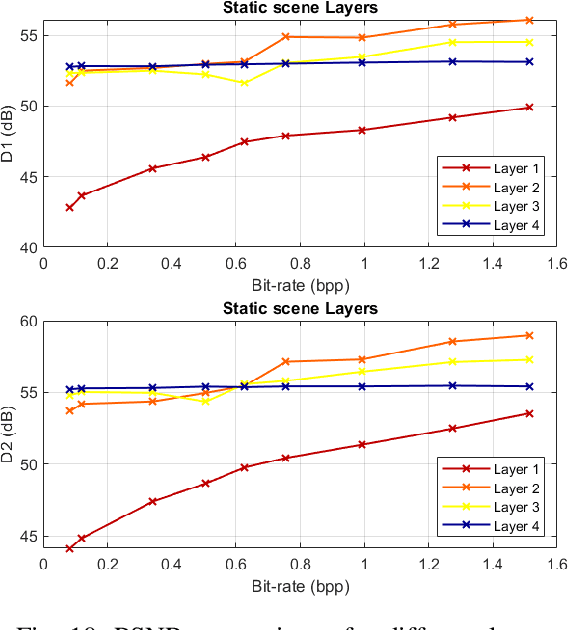
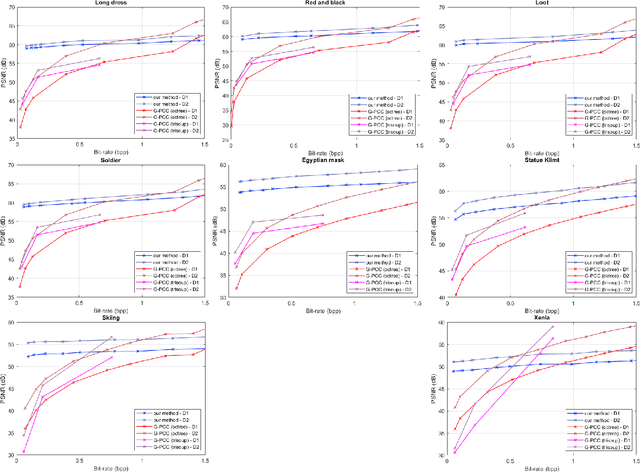

The increasing demand for accurate representations of 3D scenes, combined with immersive technologies has led point clouds to extensive popularity. However, quality point clouds require a large amount of data and therefore the need for compression methods is imperative. In this paper, we present a novel, geometry-based, end-to-end compression scheme, that combines information on the geometrical features of the point cloud and the user's position, achieving remarkable results for aggressive compression schemes demanding very small bit rates. After separating visible and non-visible points, four saliency maps are calculated, utilizing the point cloud's geometry and distance from the user, the visibility information, and the user's focus point. A combination of these maps results in a final saliency map, indicating the overall significance of each point and therefore quantizing different regions with a different number of bits during the encoding process. The decoder reconstructs the point cloud making use of delta coordinates and solving a sparse linear system. Evaluation studies and comparisons with the geometry-based point cloud compression (G-PCC) algorithm by the Moving Picture Experts Group (MPEG), carried out for a variety of point clouds, demonstrate that the proposed method achieves significantly better results for small bit rates.
Advancing Robot Autonomy for Long-Horizon Tasks
Jul 24, 2023

Autonomous robots have real-world applications in diverse fields, such as mobile manipulation and environmental exploration, and many such tasks benefit from a hands-off approach in terms of human user involvement over a long task horizon. However, the level of autonomy achievable by a deployment is limited in part by the problem definition or task specification required by the system. Task specifications often require technical, low-level information that is unintuitive to describe and may result in generic solutions, burdening the user technically both before and after task completion. In this thesis, we aim to advance task specification abstraction toward the goal of increasing robot autonomy in real-world scenarios. We do so by tackling problems that address several different angles of this goal. First, we develop a way for the automatic discovery of optimal transition points between subtasks in the context of constrained mobile manipulation, removing the need for the human to hand-specify these in the task specification. We further propose a way to automatically describe constraints on robot motion by using demonstrated data as opposed to manually-defined constraints. Then, within the context of environmental exploration, we propose a flexible task specification framework, requiring just a set of quantiles of interest from the user that allows the robot to directly suggest locations in the environment for the user to study. We next systematically study the effect of including a robot team in the task specification and show that multirobot teams have the ability to improve performance under certain specification conditions, including enabling inter-robot communication. Finally, we propose methods for a communication protocol that autonomously selects useful but limited information to share with the other robots.
YOLIC: An Efficient Method for Object Localization and Classification on Edge Devices
Jul 19, 2023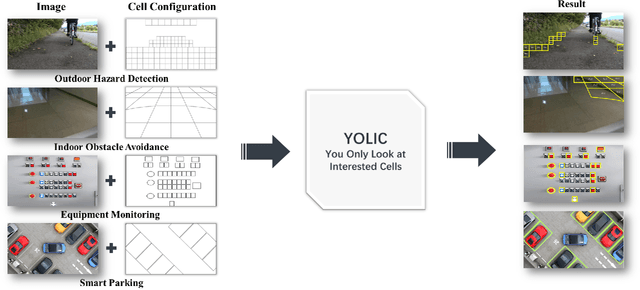
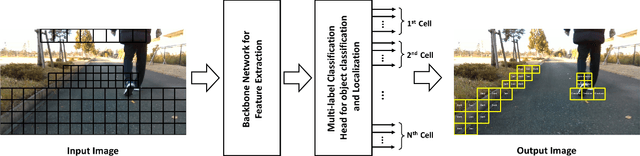


In the realm of Tiny AI, we introduce "You Only Look at Interested Cells" (YOLIC), an efficient method for object localization and classification on edge devices. Seamlessly blending the strengths of semantic segmentation and object detection, YOLIC offers superior computational efficiency and precision. By adopting Cells of Interest for classification instead of individual pixels, YOLIC encapsulates relevant information, reduces computational load, and enables rough object shape inference. Importantly, the need for bounding box regression is obviated, as YOLIC capitalizes on the predetermined cell configuration that provides information about potential object location, size, and shape. To tackle the issue of single-label classification limitations, a multi-label classification approach is applied to each cell, effectively recognizing overlapping or closely situated objects. This paper presents extensive experiments on multiple datasets, demonstrating that YOLIC achieves detection performance comparable to the state-of-the-art YOLO algorithms while surpassing in speed, exceeding 30fps on a Raspberry Pi 4B CPU. All resources related to this study, including datasets, cell designer, image annotation tool, and source code, have been made publicly available on our project website at https://kai3316.github.io/yolic.github.io
Uncertainty-Driven Multi-Scale Feature Fusion Network for Real-time Image Deraining
Jul 19, 2023
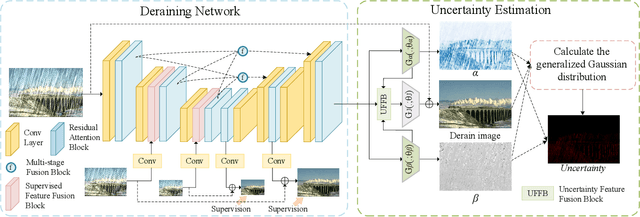
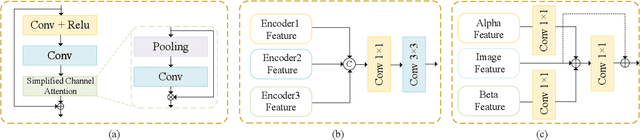
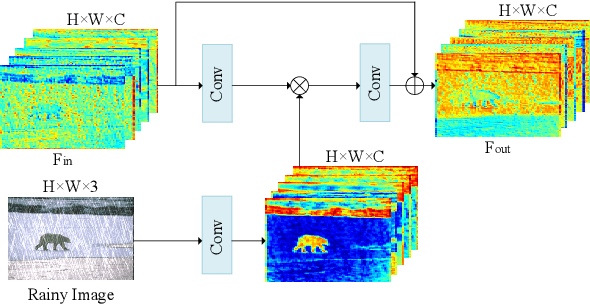
Visual-based measurement systems are frequently affected by rainy weather due to the degradation caused by rain streaks in captured images, and existing imaging devices struggle to address this issue in real-time. While most efforts leverage deep networks for image deraining and have made progress, their large parameter sizes hinder deployment on resource-constrained devices. Additionally, these data-driven models often produce deterministic results, without considering their inherent epistemic uncertainty, which can lead to undesired reconstruction errors. Well-calibrated uncertainty can help alleviate prediction errors and assist measurement devices in mitigating risks and improving usability. Therefore, we propose an Uncertainty-Driven Multi-Scale Feature Fusion Network (UMFFNet) that learns the probability mapping distribution between paired images to estimate uncertainty. Specifically, we introduce an uncertainty feature fusion block (UFFB) that utilizes uncertainty information to dynamically enhance acquired features and focus on blurry regions obscured by rain streaks, reducing prediction errors. In addition, to further boost the performance of UMFFNet, we fused feature information from multiple scales to guide the network for efficient collaborative rain removal. Extensive experiments demonstrate that UMFFNet achieves significant performance improvements with few parameters, surpassing state-of-the-art image deraining methods.
SAMConvex: Fast Discrete Optimization for CT Registration using Self-supervised Anatomical Embedding and Correlation Pyramid
Jul 19, 2023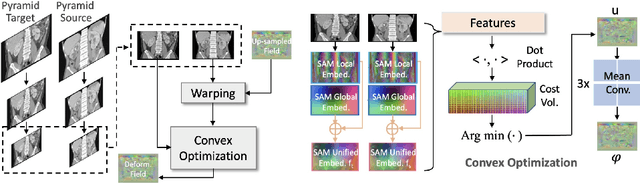
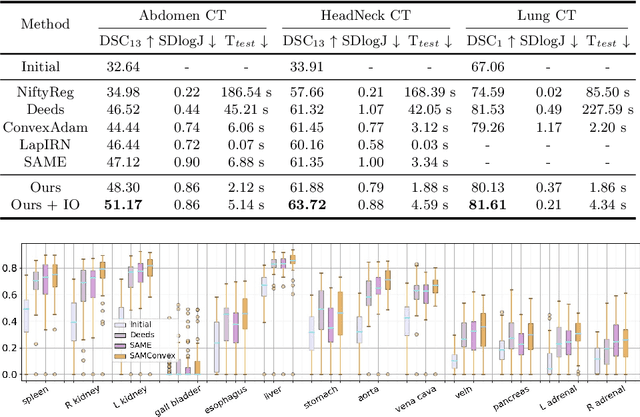
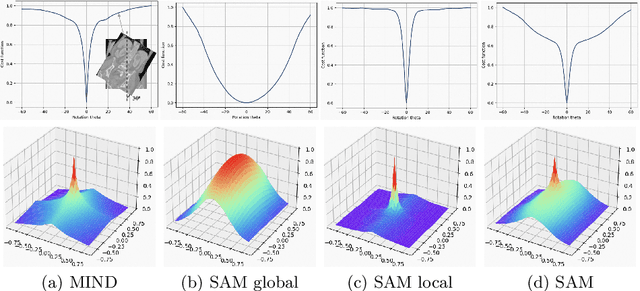

Estimating displacement vector field via a cost volume computed in the feature space has shown great success in image registration, but it suffers excessive computation burdens. Moreover, existing feature descriptors only extract local features incapable of representing the global semantic information, which is especially important for solving large transformations. To address the discussed issues, we propose SAMConvex, a fast coarse-to-fine discrete optimization method for CT registration that includes a decoupled convex optimization procedure to obtain deformation fields based on a self-supervised anatomical embedding (SAM) feature extractor that captures both local and global information. To be specific, SAMConvex extracts per-voxel features and builds 6D correlation volumes based on SAM features, and iteratively updates a flow field by performing lookups on the correlation volumes with a coarse-to-fine scheme. SAMConvex outperforms the state-of-the-art learning-based methods and optimization-based methods over two inter-patient registration datasets (Abdomen CT and HeadNeck CT) and one intra-patient registration dataset (Lung CT). Moreover, as an optimization-based method, SAMConvex only takes $\sim2$s ($\sim5s$ with instance optimization) for one paired images.
TUNeS: A Temporal U-Net with Self-Attention for Video-based Surgical Phase Recognition
Jul 19, 2023To enable context-aware computer assistance in the operating room of the future, cognitive systems need to understand automatically which surgical phase is being performed by the medical team. The primary source of information for surgical phase recognition is typically video, which presents two challenges: extracting meaningful features from the video stream and effectively modeling temporal information in the sequence of visual features. For temporal modeling, attention mechanisms have gained popularity due to their ability to capture long-range dependencies. In this paper, we explore design choices for attention in existing temporal models for surgical phase recognition and propose a novel approach that does not resort to local attention or regularization of attention weights: TUNeS is an efficient and simple temporal model that incorporates self-attention at the coarsest stage of a U-Net-like structure. In addition, we propose to train the feature extractor, a standard CNN, together with an LSTM on preferably long video segments, i.e., with long temporal context. In our experiments, all temporal models performed better on top of feature extractors that were trained with longer temporal context. On top of these contextualized features, TUNeS achieves state-of-the-art results on Cholec80.
Wider and Deeper LLM Networks are Fairer LLM Evaluators
Aug 03, 2023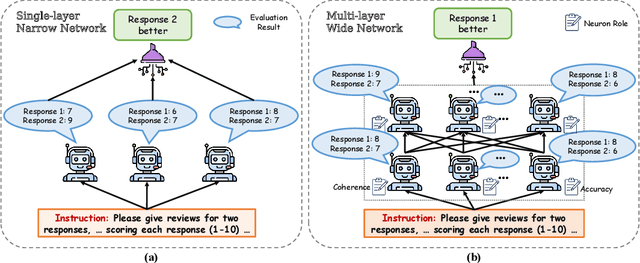
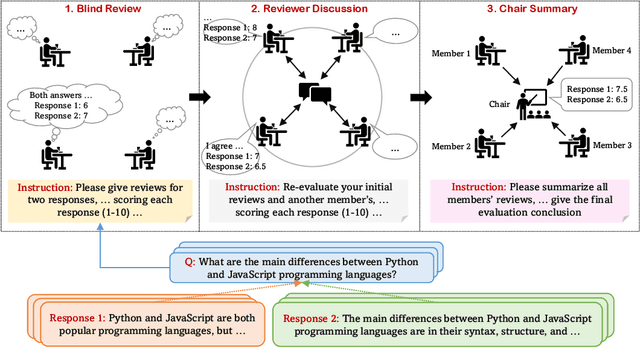
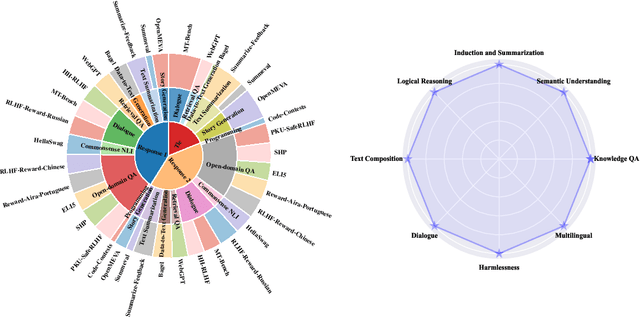

Measuring the quality of responses generated by LLMs is a challenging task, particularly when it comes to evaluating whether the response is aligned with human preference. A novel approach involves using the LLM itself to make evaluation and stabilizing the results through multiple independent evaluations, similar to a single-layer narrow LLM network. This network consists of a fixed number of neurons, with each neuron being the same LLM. In this paper, we draw upon the extensive research on deep neural networks to explore whether deeper and wider networks can lead to fairer evaluations. Specifically, inspired by the observation that different neurons in a neural network are responsible for detecting different concepts, we first adaptively generate as many neuron roles as possible for each evaluation sample. Each perspective corresponds to the role of a specific LLM neuron in the first layer. In subsequent layers, we follow the idea that higher layers in deep networks are responsible for more comprehensive features, each layer receives representations from all neurons in the previous layer, integrating the locally learned evaluation information to obtain a more comprehensive evaluation result. Interestingly, this network design resembles the process of academic paper reviewing. To validate the effectiveness of our method, we construct the largest and most diverse English evaluation benchmark LLMEval$^2$ for LLM evaluators, comprising 15 tasks, 8 abilities, and 2,553 samples. Experimental results demonstrate that a wider network (involving many reviewers) with 2 layers (one round of discussion) performs the best, improving kappa correlation coefficient from 0.28 to 0.34. We also leverage WideDeep to aid in the assessment of Chinese LLMs, which has accelerated the evaluation time by 4.6 times, resulting in a 60% cost saving. WideDeep achieves a remarkable 93% agreement level among humans.