 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generalized Information Bottleneck for Gaussian Variables
Mar 31, 2023
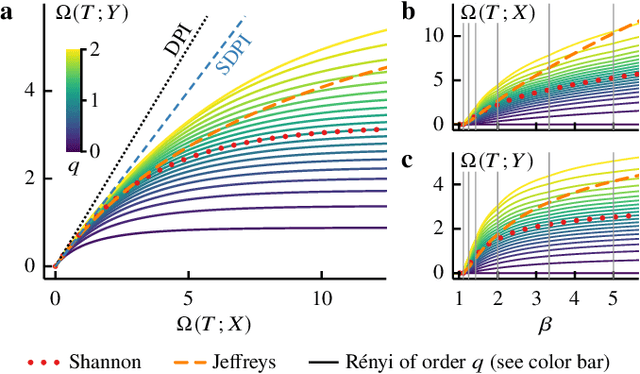
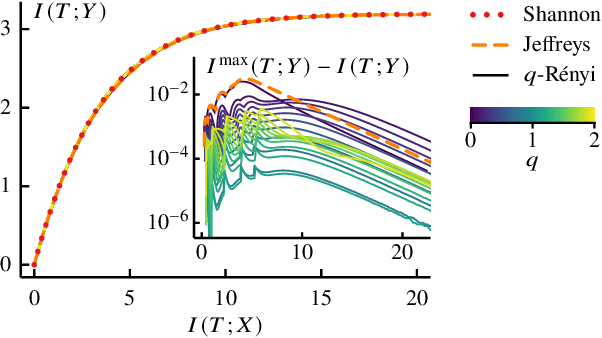
The information bottleneck (IB) method offers an attractive framework for understanding representation learning, however its applications are often limited by its computational intractability. Analytical characterization of the IB method is not only of practical interest, but it can also lead to new insights into learning phenomena. Here we consider a generalized IB problem, in which the mutual information in the original IB method is replaced by correlation measures based on Renyi and Jeffreys divergences. We derive an exact analytical IB solution for the case of Gaussian correlated variables. Our analysis reveals a series of structural transitions, similar to those previously observed in the original IB case. We find further that although solving the original, Renyi and Jeffreys IB problems yields different representations in general, the structural transitions occur at the same critical tradeoff parameters, and the Renyi and Jeffreys IB solutions perform well under the original IB objective. Our results suggest that formulating the IB method with alternative correlation measures could offer a strategy for obtaining an approximate solution to the original IB problem.
Decoding Taste Information in Human Brain: A Temporal and Spatial Reconstruction Data Augmentation Method Coupled with Taste EEG
Jul 01, 2023For humans, taste is essential for perceiving food's nutrient content or harmful components. The current sensory evaluation of taste mainly relies on artificial sensory evaluation and electronic tongue, but the former has strong subjectivity and poor repeatability, and the latter is not flexible enough. This work proposed a strategy for acquiring and recognizing taste electroencephalogram (EEG), aiming to decode people's objective perception of taste through taste EEG. Firstly, according to the proposed experimental paradigm, the taste EEG of subjects under different taste stimulation was collected. Secondly, to avoid insufficient training of the model due to the small number of taste EEG samples, a Temporal and Spatial Reconstruction Data Augmentation (TSRDA) method was proposed, which effectively augmented the taste EEG by reconstructing the taste EEG's important features in temporal and spatial dimensions. Thirdly, a multi-view channel attention module was introduced into a designed convolutional neural network to extract the important features of the augmented taste EEG. The proposed method has accuracy of 99.56%, F1-score of 99.48%, and kappa of 99.38%, proving the method's ability to distinguish the taste EEG evoked by different taste stimuli successfully. In summary, combining TSRDA with taste EEG technology provides an objective and effective method for sensory evaluation of food taste.
Spatial-Frequency U-Net for Denoising Diffusion Probabilistic Models
Jul 27, 2023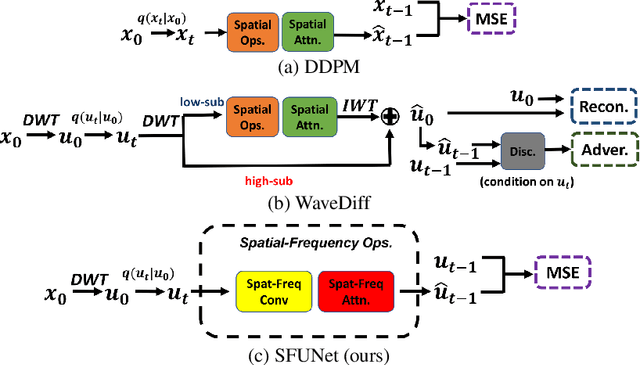
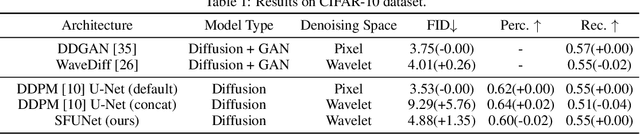
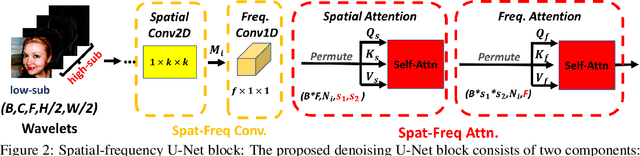
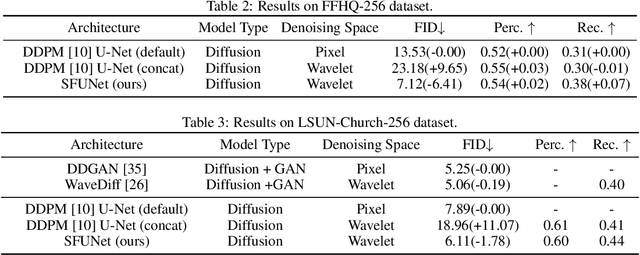
In this paper, we study the denoising diffusion probabilistic model (DDPM) in wavelet space, instead of pixel space, for visual synthesis. Considering the wavelet transform represents the image in spatial and frequency domains, we carefully design a novel architecture SFUNet to effectively capture the correlation for both domains. Specifically, in the standard denoising U-Net for pixel data, we supplement the 2D convolutions and spatial-only attention layers with our spatial frequency-aware convolution and attention modules to jointly model the complementary information from spatial and frequency domains in wavelet data. Our new architecture can be used as a drop-in replacement to the pixel-based network and is compatible with the vanilla DDPM training process. By explicitly modeling the wavelet signals, we find our model is able to generate images with higher quality on CIFAR-10, FFHQ, LSUN-Bedroom, and LSUN-Church datasets, than the pixel-based counterpart.
High Dynamic Range Imaging via Visual Attention Modules
Jul 27, 2023Thanks to High Dynamic Range (HDR) imaging methods, the scope of photography has seen profound changes recently. To be more specific, such methods try to reconstruct the lost luminosity of the real world caused by the limitation of regular cameras from the Low Dynamic Range (LDR) images. Additionally, although the State-Of-The-Art methods in this topic perform well, they mainly concentrate on combining different exposures and have less attention to extracting the informative parts of the images. Thus, this paper aims to introduce a new model capable of incorporating information from the most visible areas of each image extracted by a visual attention module (VAM), which is a result of a segmentation strategy. In particular, the model, based on a deep learning architecture, utilizes the extracted areas to produce the final HDR image. The results demonstrate that our method outperformed most of the State-Of-The-Art algorithms.
UCDFormer: Unsupervised Change Detection Using a Transformer-driven Image Translation
Aug 02, 2023
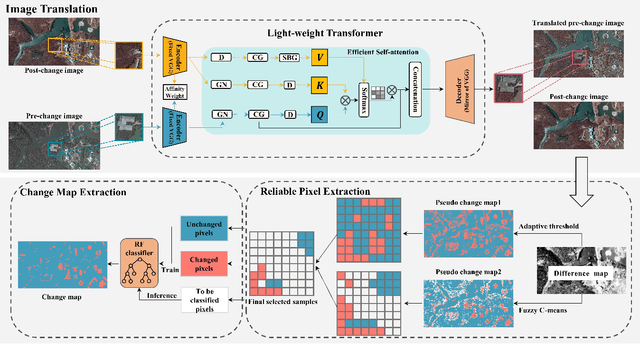


Change detection (CD) by comparing two bi-temporal images is a crucial task in remote sensing. With the advantages of requiring no cumbersome labeled change information, unsupervised CD has attracted extensive attention in the community. However, existing unsupervised CD approaches rarely consider the seasonal and style differences incurred by the illumination and atmospheric conditions in multi-temporal images. To this end, we propose a change detection with domain shift setting for remote sensing images. Furthermore, we present a novel unsupervised CD method using a light-weight transformer, called UCDFormer. Specifically, a transformer-driven image translation composed of a light-weight transformer and a domain-specific affinity weight is first proposed to mitigate domain shift between two images with real-time efficiency. After image translation, we can generate the difference map between the translated before-event image and the original after-event image. Then, a novel reliable pixel extraction module is proposed to select significantly changed/unchanged pixel positions by fusing the pseudo change maps of fuzzy c-means clustering and adaptive threshold. Finally, a binary change map is obtained based on these selected pixel pairs and a binary classifier. Experimental results on different unsupervised CD tasks with seasonal and style changes demonstrate the effectiveness of the proposed UCDFormer. For example, compared with several other related methods, UCDFormer improves performance on the Kappa coefficient by more than 12\%. In addition, UCDFormer achieves excellent performance for earthquake-induced landslide detection when considering large-scale applications. The code is available at \url{https://github.com/zhu-xlab/UCDFormer}
WCCNet: Wavelet-integrated CNN with Crossmodal Rearranging Fusion for Fast Multispectral Pedestrian Detection
Aug 02, 2023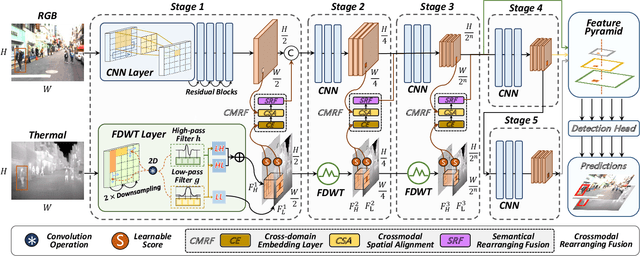
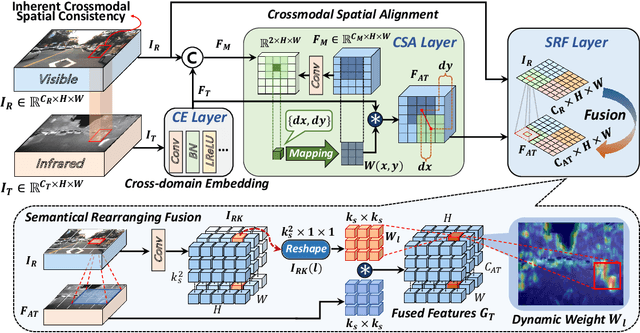
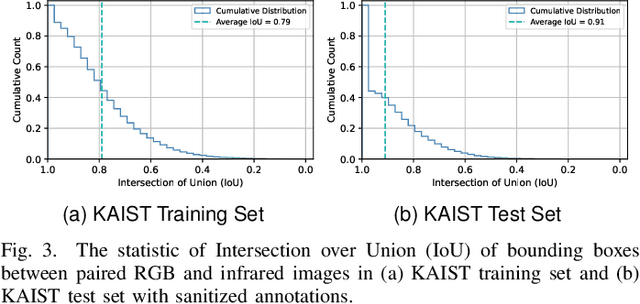
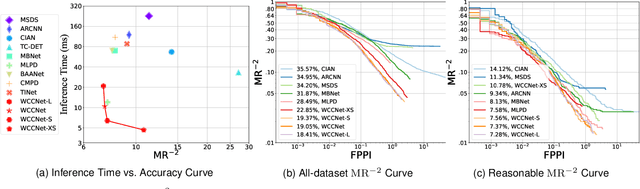
Multispectral pedestrian detection achieves better visibility in challenging conditions and thus has a broad application in various tasks, for which both the accuracy and computational cost are of paramount importance. Most existing approaches treat RGB and infrared modalities equally, typically adopting two symmetrical CNN backbones for multimodal feature extraction, which ignores the substantial differences between modalities and brings great difficulty for the reduction of the computational cost as well as effective crossmodal fusion. In this work, we propose a novel and efficient framework named WCCNet that is able to differentially extract rich features of different spectra with lower computational complexity and semantically rearranges these features for effective crossmodal fusion. Specifically, the discrete wavelet transform (DWT) allowing fast inference and training speed is embedded to construct a dual-stream backbone for efficient feature extraction. The DWT layers of WCCNet extract frequency components for infrared modality, while the CNN layers extract spatial-domain features for RGB modality. This methodology not only significantly reduces the computational complexity, but also improves the extraction of infrared features to facilitate the subsequent crossmodal fusion. Based on the well extracted features, we elaborately design the crossmodal rearranging fusion module (CMRF), which can mitigate spatial misalignment and merge semantically complementary features of spatially-related local regions to amplify the crossmodal complementary information. We conduct comprehensive evaluations on KAIST and FLIR benchmarks, in which WCCNet outperforms state-of-the-art methods with considerable computational efficiency and competitive accuracy. We also perform the ablation study and analyze thoroughly the impact of different components on the performance of WCCNet.
Factor Graph Neural Networks
Aug 02, 2023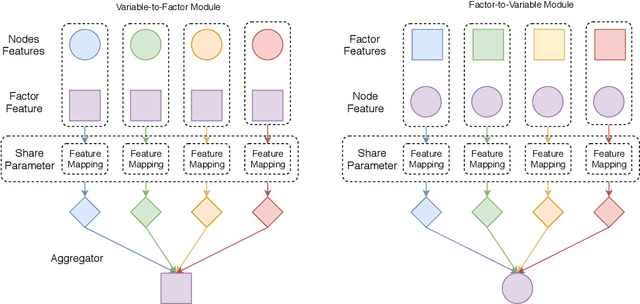

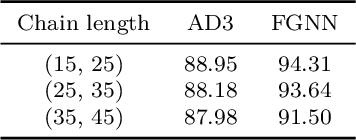
In recent years, we have witnessed a surge of Graph Neural Networks (GNNs), most of which can learn powerful representations in an end-to-end fashion with great success in many real-world applications. They have resemblance to Probabilistic Graphical Models (PGMs), but break free from some limitations of PGMs. By aiming to provide expressive methods for representation learning instead of computing marginals or most likely configurations, GNNs provide flexibility in the choice of information flowing rules while maintaining good performance. Despite their success and inspirations, they lack efficient ways to represent and learn higher-order relations among variables/nodes. More expressive higher-order GNNs which operate on k-tuples of nodes need increased computational resources in order to process higher-order tensors. We propose Factor Graph Neural Networks (FGNNs) to effectively capture higher-order relations for inference and learning. To do so, we first derive an efficient approximate Sum-Product loopy belief propagation inference algorithm for discrete higher-order PGMs. We then neuralize the novel message passing scheme into a Factor Graph Neural Network (FGNN) module by allowing richer representations of the message update rules; this facilitates both efficient inference and powerful end-to-end learning. We further show that with a suitable choice of message aggregation operators, our FGNN is also able to represent Max-Product belief propagation, providing a single family of architecture that can represent both Max and Sum-Product loopy belief propagation. Our extensive experimental evaluation on synthetic as well as real datasets demonstrates the potential of the proposed model.
ForensicsForest Family: A Series of Multi-scale Hierarchical Cascade Forests for Detecting GAN-generated Faces
Aug 02, 2023
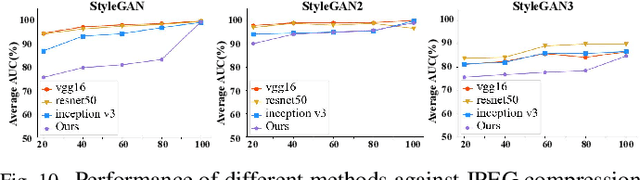
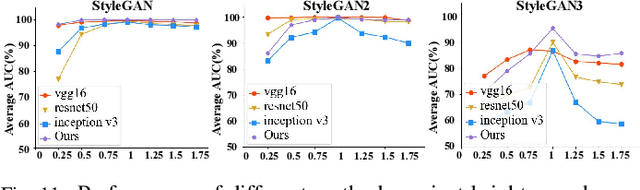
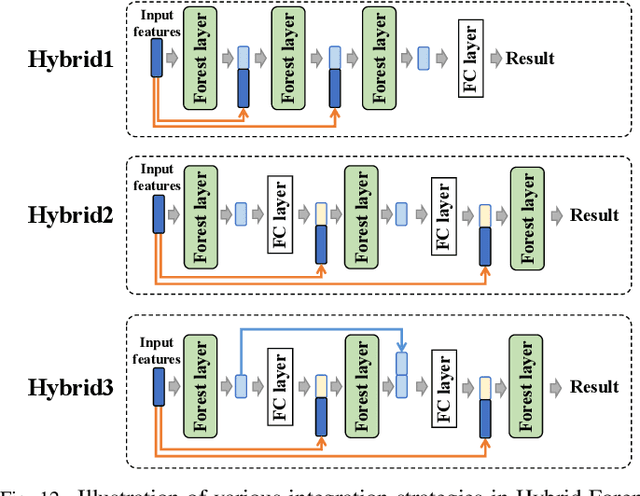
The prominent progress in generative models has significantly improved the reality of generated faces, bringing serious concerns to society. Since recent GAN-generated faces are in high realism, the forgery traces have become more imperceptible, increasing the forensics challenge. To combat GAN-generated faces, many countermeasures based on Convolutional Neural Networks (CNNs) have been spawned due to their strong learning ability. In this paper, we rethink this problem and explore a new approach based on forest models instead of CNNs. Specifically, we describe a simple and effective forest-based method set called {\em ForensicsForest Family} to detect GAN-generate faces. The proposed ForensicsForest family is composed of three variants, which are {\em ForensicsForest}, {\em Hybrid ForensicsForest} and {\em Divide-and-Conquer ForensicsForest} respectively. ForenscisForest is a newly proposed Multi-scale Hierarchical Cascade Forest, which takes semantic, frequency and biology features as input, hierarchically cascades different levels of features for authenticity prediction, and then employs a multi-scale ensemble scheme that can comprehensively consider different levels of information to improve the performance further. Based on ForensicsForest, we develop Hybrid ForensicsForest, an extended version that integrates the CNN layers into models, to further refine the effectiveness of augmented features. Moreover, to reduce the memory cost in training, we propose Divide-and-Conquer ForensicsForest, which can construct a forest model using only a portion of training samplings. In the training stage, we train several candidate forest models using the subsets of training samples. Then a ForensicsForest is assembled by picking the suitable components from these candidate forest models...
Learned Gridification for Efficient Point Cloud Processing
Jul 22, 2023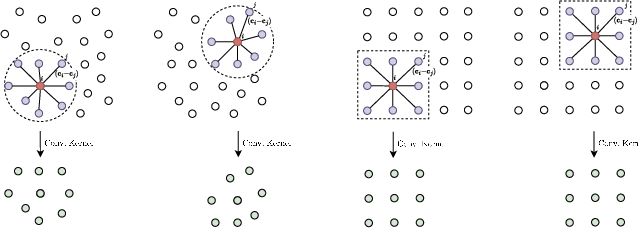

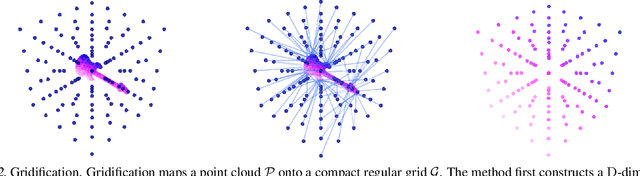
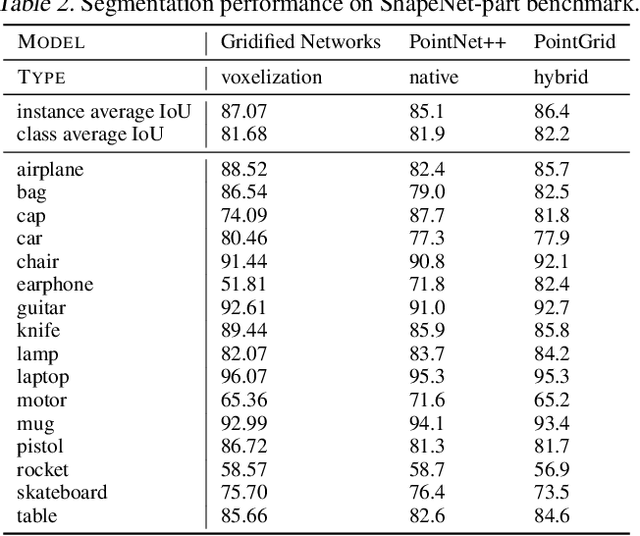
Neural operations that rely on neighborhood information are much more expensive when deployed on point clouds than on grid data due to the irregular distances between points in a point cloud. In a grid, on the other hand, we can compute the kernel only once and reuse it for all query positions. As a result, operations that rely on neighborhood information scale much worse for point clouds than for grid data, specially for large inputs and large neighborhoods. In this work, we address the scalability issue of point cloud methods by tackling its root cause: the irregularity of the data. We propose learnable gridification as the first step in a point cloud processing pipeline to transform the point cloud into a compact, regular grid. Thanks to gridification, subsequent layers can use operations defined on regular grids, e.g., Conv3D, which scale much better than native point cloud methods. We then extend gridification to point cloud to point cloud tasks, e.g., segmentation, by adding a learnable de-gridification step at the end of the point cloud processing pipeline to map the compact, regular grid back to its original point cloud form. Through theoretical and empirical analysis, we show that gridified networks scale better in terms of memory and time than networks directly applied on raw point cloud data, while being able to achieve competitive results. Our code is publicly available at https://github.com/computri/gridifier.
Towards Precise Weakly Supervised Object Detection via Interactive Contrastive Learning of Context Information
Apr 27, 2023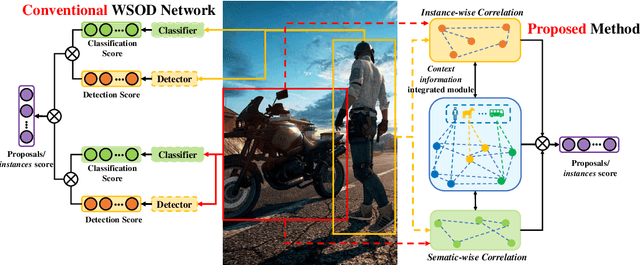
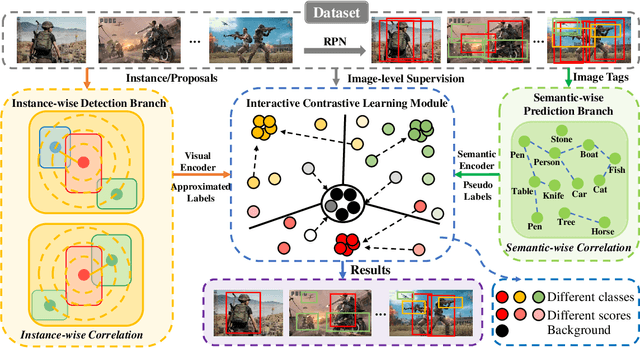
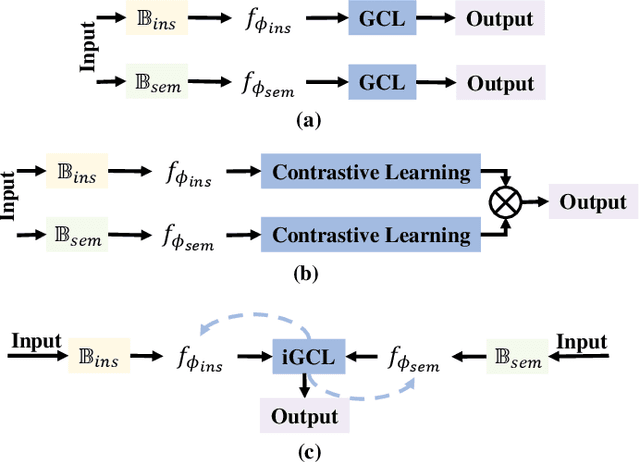

Weakly supervised object detection (WSOD) aims at learning precise object detectors with only image-level tags. In spite of intensive research on deep learning (DL) approaches over the past few years, there is still a significant performance gap between WSOD and fully supervised object detection. In fact, most existing WSOD methods only consider the visual appearance of each region proposal but ignore employing the useful context information in the image. To this end, this paper proposes an interactive end-to-end WSDO framework called JLWSOD with two innovations: i) two types of WSOD-specific context information (i.e., instance-wise correlation andsemantic-wise correlation) are proposed and introduced into WSOD framework; ii) an interactive graph contrastive learning (iGCL) mechanism is designed to jointly optimize the visual appearance and context information for better WSOD performance. Specifically, the iGCL mechanism takes full advantage of the complementary interpretations of the WSOD, namely instance-wise detection and semantic-wise prediction tasks, forming a more comprehensive solution. Extensive experiments on the widely used PASCAL VOC and MS COCO benchmarks verify the superiority of JLWSOD over alternative state-of-the-art approaches and baseline models (improvement of 3.6%~23.3% on mAP and 3.4%~19.7% on CorLoc, respectively).