 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Syntax-Aware Complex-Valued Neural Machine Translation
Jul 17, 2023

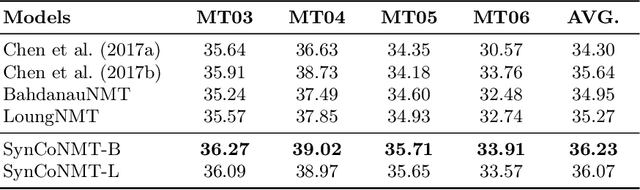
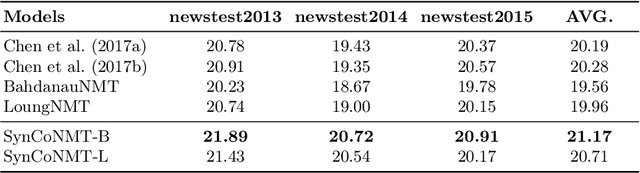
Syntax has been proven to be remarkably effective in neural machine translation (NMT). Previous models obtained syntax information from syntactic parsing tools and integrated it into NMT models to improve translation performance. In this work, we propose a method to incorporate syntax information into a complex-valued Encoder-Decoder architecture. The proposed model jointly learns word-level and syntax-level attention scores from the source side to the target side using an attention mechanism. Importantly, it is not dependent on specific network architectures and can be directly integrated into any existing sequence-to-sequence (Seq2Seq) framework. The experimental results demonstrate that the proposed method can bring significant improvements in BLEU scores on two datasets. In particular, the proposed method achieves a greater improvement in BLEU scores in translation tasks involving language pairs with significant syntactic differences.
Training-Free Instance Segmentation from Semantic Image Segmentation Masks
Aug 02, 2023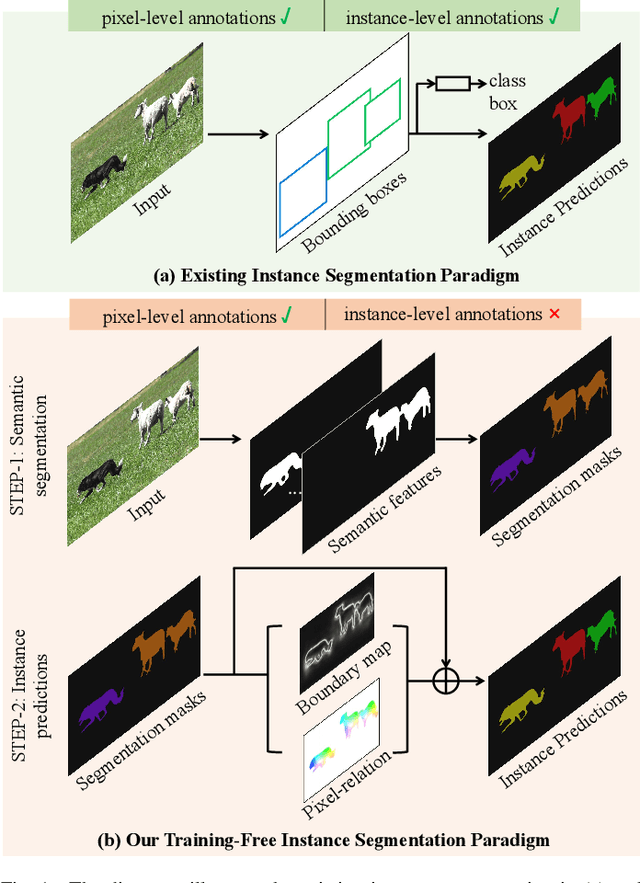
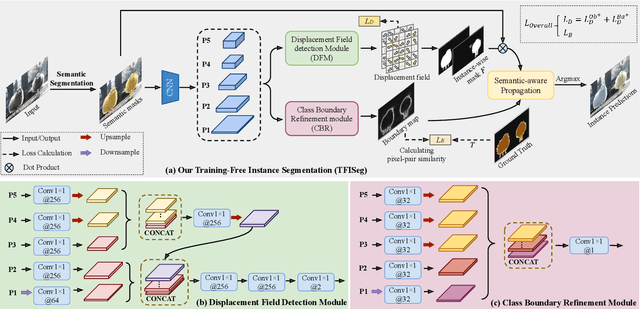


In recent years, the development of instance segmentation has garnered significant attention in a wide range of applications. However, the training of a fully-supervised instance segmentation model requires costly both instance-level and pixel-level annotations. In contrast, weakly-supervised instance segmentation methods (i.e., with image-level class labels or point labels) struggle to satisfy the accuracy and recall requirements of practical scenarios. In this paper, we propose a novel paradigm for instance segmentation called training-free instance segmentation (TFISeg), which achieves instance segmentation results from image masks predicted using off-the-shelf semantic segmentation models. TFISeg does not require training a semantic or/and instance segmentation model and avoids the need for instance-level image annotations. Therefore, it is highly efficient. Specifically, we first obtain a semantic segmentation mask of the input image via a trained semantic segmentation model. Then, we calculate a displacement field vector for each pixel based on the segmentation mask, which can indicate representations belonging to the same class but different instances, i.e., obtaining the instance-level object information. Finally, instance segmentation results are obtained after being refined by a learnable category-agnostic object boundary branch. Extensive experimental results on two challenging datasets and representative semantic segmentation baselines (including CNNs and Transformers) demonstrate that TFISeg can achieve competitive results compared to the state-of-the-art fully-supervised instance segmentation methods without the need for additional human resources or increased computational costs. The code is available at: TFISeg
Beyond Generic: Enhancing Image Captioning with Real-World Knowledge using Vision-Language Pre-Training Model
Aug 02, 2023


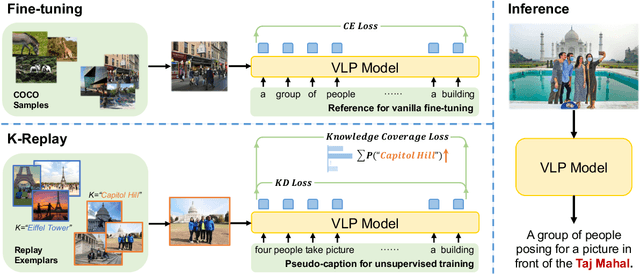
Current captioning approaches tend to generate correct but "generic" descriptions that lack real-world knowledge, e.g., named entities and contextual information. Considering that Vision-Language Pre-Training (VLP) models master massive such knowledge from large-scale web-harvested data, it is promising to utilize the generalizability of VLP models to incorporate knowledge into image descriptions. However, using VLP models faces challenges: zero-shot inference suffers from knowledge hallucination that leads to low-quality descriptions, but the generic bias in downstream task fine-tuning hinders the VLP model from expressing knowledge. To address these concerns, we propose a simple yet effective method called Knowledge-guided Replay (K-Replay), which enables the retention of pre-training knowledge during fine-tuning. Our approach consists of two parts: (1) a knowledge prediction task on automatically collected replay exemplars to continuously awaken the VLP model's memory about knowledge, thus preventing the model from collapsing into the generic pattern; (2) a knowledge distillation constraint to improve the faithfulness of generated descriptions hence alleviating the knowledge hallucination. To evaluate knowledge-enhanced descriptions, we construct a novel captioning benchmark KnowCap, containing knowledge of landmarks, famous brands, special foods and movie characters. Experimental results show that our approach effectively incorporates knowledge into descriptions, outperforming strong VLP baseline by 20.9 points (78.7->99.6) in CIDEr score and 20.5 percentage points (34.0%->54.5%) in knowledge recognition accuracy. Our code and data is available at https://github.com/njucckevin/KnowCap.
Mercury: An Automated Remote Side-channel Attack to Nvidia Deep Learning Accelerator
Aug 02, 2023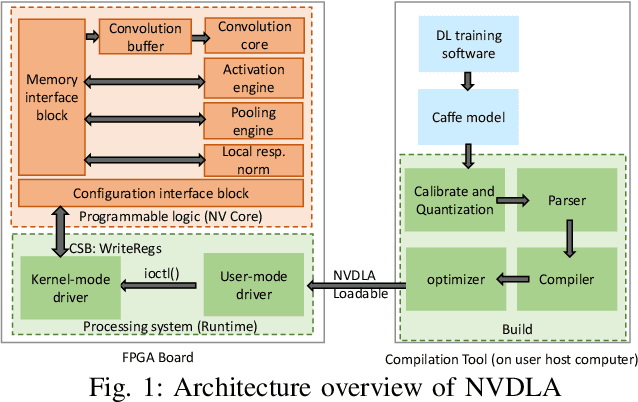
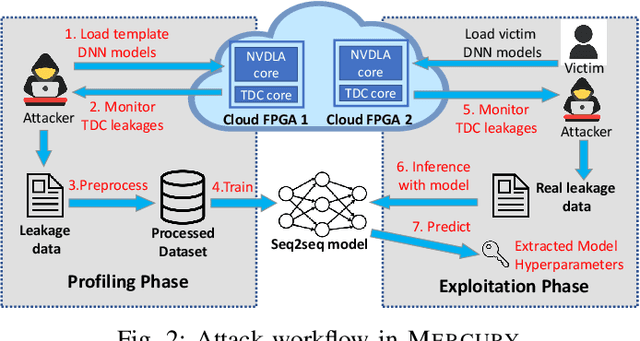
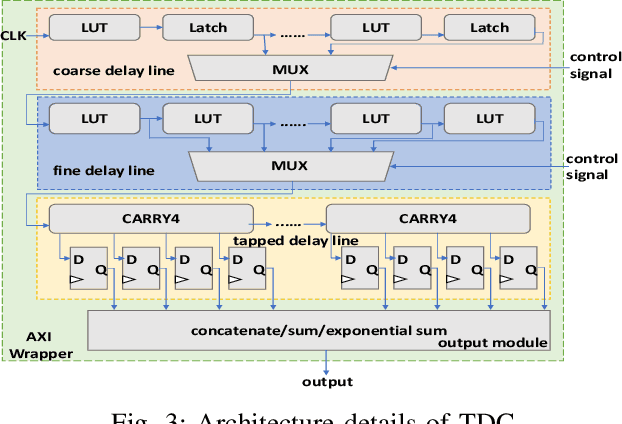
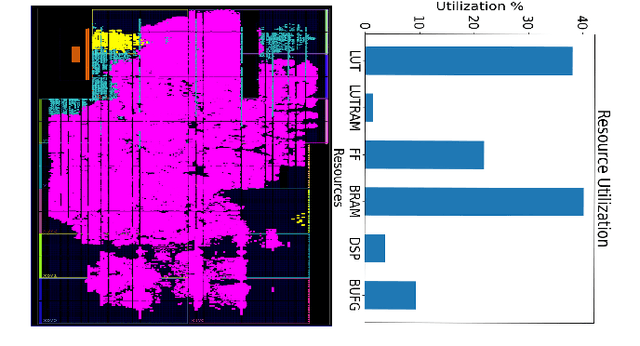
DNN accelerators have been widely deployed in many scenarios to speed up the inference process and reduce the energy consumption. One big concern about the usage of the accelerators is the confidentiality of the deployed models: model inference execution on the accelerators could leak side-channel information, which enables an adversary to preciously recover the model details. Such model extraction attacks can not only compromise the intellectual property of DNN models, but also facilitate some adversarial attacks. Although previous works have demonstrated a number of side-channel techniques to extract models from DNN accelerators, they are not practical for two reasons. (1) They only target simplified accelerator implementations, which have limited practicality in the real world. (2) They require heavy human analysis and domain knowledge. To overcome these limitations, this paper presents Mercury, the first automated remote side-channel attack against the off-the-shelf Nvidia DNN accelerator. The key insight of Mercury is to model the side-channel extraction process as a sequence-to-sequence problem. The adversary can leverage a time-to-digital converter (TDC) to remotely collect the power trace of the target model's inference. Then he uses a learning model to automatically recover the architecture details of the victim model from the power trace without any prior knowledge. The adversary can further use the attention mechanism to localize the leakage points that contribute most to the attack. Evaluation results indicate that Mercury can keep the error rate of model extraction below 1%.
Degeneration-Tuning: Using Scrambled Grid shield Unwanted Concepts from Stable Diffusion
Aug 02, 2023
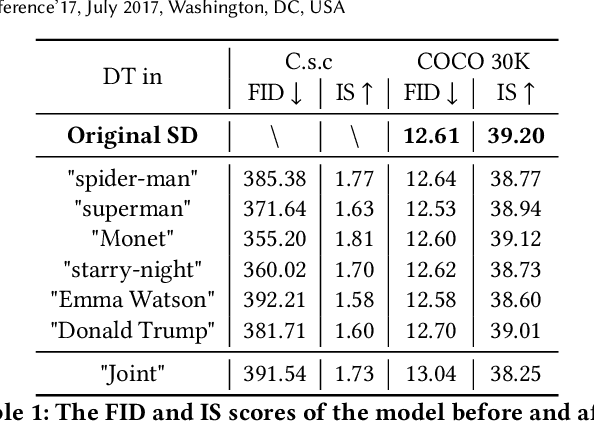

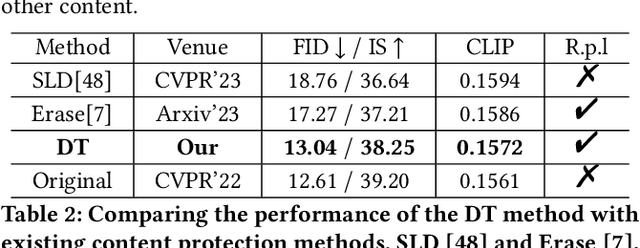
Owing to the unrestricted nature of the content in the training data, large text-to-image diffusion models, such as Stable Diffusion (SD), are capable of generating images with potentially copyrighted or dangerous content based on corresponding textual concepts information. This includes specific intellectual property (IP), human faces, and various artistic styles. However, Negative Prompt, a widely used method for content removal, frequently fails to conceal this content due to inherent limitations in its inference logic. In this work, we propose a novel strategy named \textbf{Degeneration-Tuning (DT)} to shield contents of unwanted concepts from SD weights. By utilizing Scrambled Grid to reconstruct the correlation between undesired concepts and their corresponding image domain, we guide SD to generate meaningless content when such textual concepts are provided as input. As this adaptation occurs at the level of the model's weights, the SD, after DT, can be grafted onto other conditional diffusion frameworks like ControlNet to shield unwanted concepts. In addition to qualitatively showcasing the effectiveness of our DT method in protecting various types of concepts, a quantitative comparison of the SD before and after DT indicates that the DT method does not significantly impact the generative quality of other contents. The FID and IS scores of the model on COCO-30K exhibit only minor changes after DT, shifting from 12.61 and 39.20 to 13.04 and 38.25, respectively, which clearly outperforms the previous methods.
SegNetr: Rethinking the local-global interactions and skip connections in U-shaped networks
Jul 21, 2023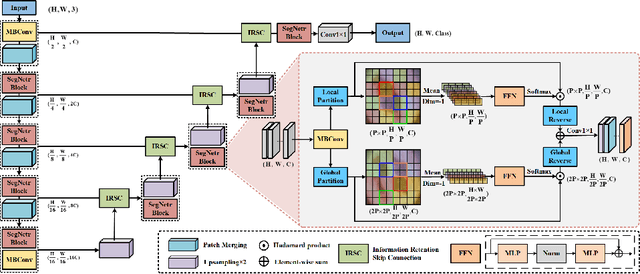
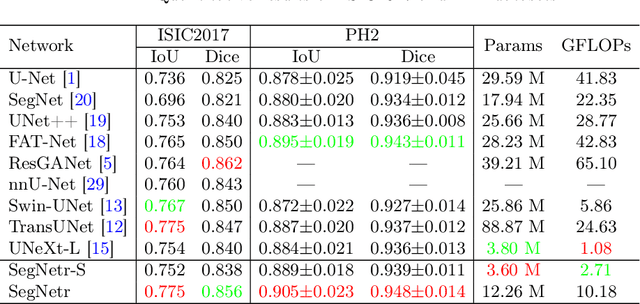
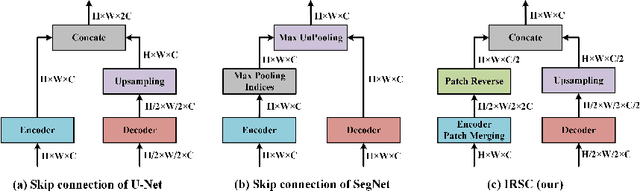
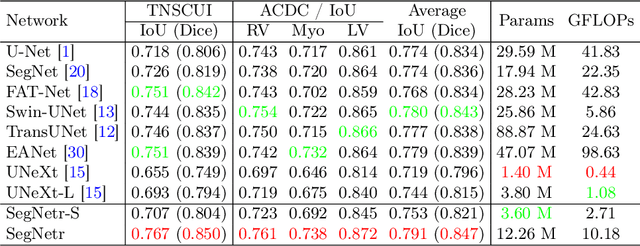
Recently, U-shaped networks have dominated the field of medical image segmentation due to their simple and easily tuned structure. However, existing U-shaped segmentation networks: 1) mostly focus on designing complex self-attention modules to compensate for the lack of long-term dependence based on convolution operation, which increases the overall number of parameters and computational complexity of the network; 2) simply fuse the features of encoder and decoder, ignoring the connection between their spatial locations. In this paper, we rethink the above problem and build a lightweight medical image segmentation network, called SegNetr. Specifically, we introduce a novel SegNetr block that can perform local-global interactions dynamically at any stage and with only linear complexity. At the same time, we design a general information retention skip connection (IRSC) to preserve the spatial location information of encoder features and achieve accurate fusion with the decoder features. We validate the effectiveness of SegNetr on four mainstream medical image segmentation datasets, with 59\% and 76\% fewer parameters and GFLOPs than vanilla U-Net, while achieving segmentation performance comparable to state-of-the-art methods. Notably, the components proposed in this paper can be applied to other U-shaped networks to improve their segmentation performance.
Multi-interactive Feature Learning and a Full-time Multi-modality Benchmark for Image Fusion and Segmentation
Aug 04, 2023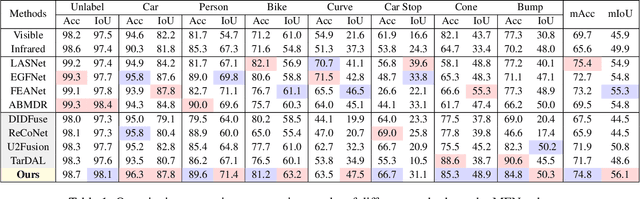
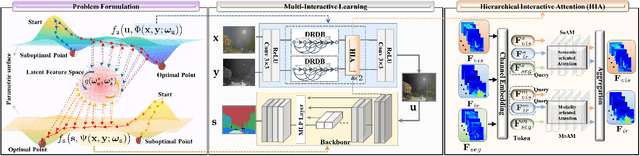
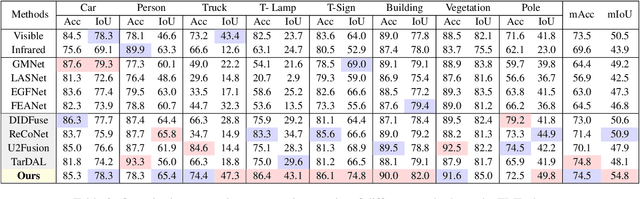
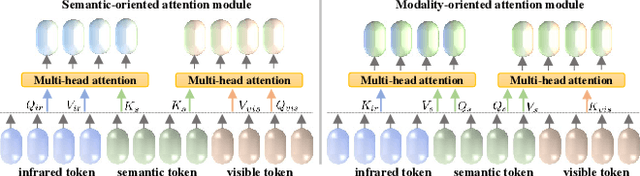
Multi-modality image fusion and segmentation play a vital role in autonomous driving and robotic operation. Early efforts focus on boosting the performance for only one task, \emph{e.g.,} fusion or segmentation, making it hard to reach~`Best of Both Worlds'. To overcome this issue, in this paper, we propose a \textbf{M}ulti-\textbf{i}nteractive \textbf{F}eature learning architecture for image fusion and \textbf{Seg}mentation, namely SegMiF, and exploit dual-task correlation to promote the performance of both tasks. The SegMiF is of a cascade structure, containing a fusion sub-network and a commonly used segmentation sub-network. By slickly bridging intermediate features between two components, the knowledge learned from the segmentation task can effectively assist the fusion task. Also, the benefited fusion network supports the segmentation one to perform more pretentiously. Besides, a hierarchical interactive attention block is established to ensure fine-grained mapping of all the vital information between two tasks, so that the modality/semantic features can be fully mutual-interactive. In addition, a dynamic weight factor is introduced to automatically adjust the corresponding weights of each task, which can balance the interactive feature correspondence and break through the limitation of laborious tuning. Furthermore, we construct a smart multi-wave binocular imaging system and collect a full-time multi-modality benchmark with 15 annotated pixel-level categories for image fusion and segmentation. Extensive experiments on several public datasets and our benchmark demonstrate that the proposed method outputs visually appealing fused images and perform averagely $7.66\%$ higher segmentation mIoU in the real-world scene than the state-of-the-art approaches. The source code and benchmark are available at \url{https://github.com/JinyuanLiu-CV/SegMiF}.
Learning to Select the Relevant History Turns in Conversational Question Answering
Aug 04, 2023
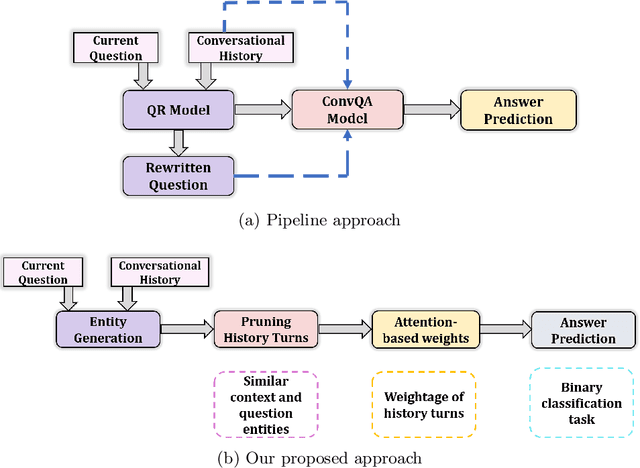
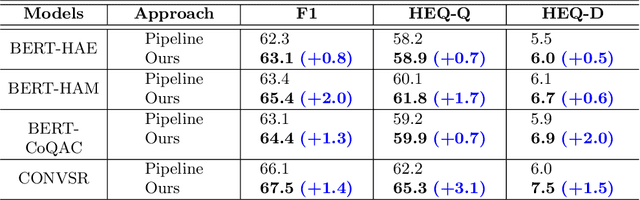
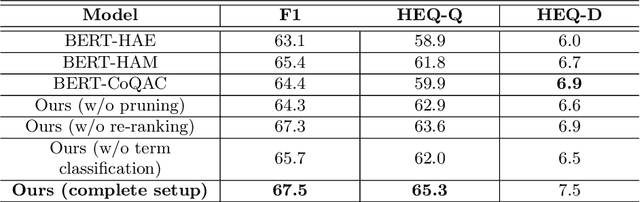
The increasing demand for the web-based digital assistants has given a rapid rise in the interest of the Information Retrieval (IR) community towards the field of conversational question answering (ConvQA). However, one of the critical aspects of ConvQA is the effective selection of conversational history turns to answer the question at hand. The dependency between relevant history selection and correct answer prediction is an intriguing but under-explored area. The selected relevant context can better guide the system so as to where exactly in the passage to look for an answer. Irrelevant context, on the other hand, brings noise to the system, thereby resulting in a decline in the model's performance. In this paper, we propose a framework, DHS-ConvQA (Dynamic History Selection in Conversational Question Answering), that first generates the context and question entities for all the history turns, which are then pruned on the basis of similarity they share in common with the question at hand. We also propose an attention-based mechanism to re-rank the pruned terms based on their calculated weights of how useful they are in answering the question. In the end, we further aid the model by highlighting the terms in the re-ranked conversational history using a binary classification task and keeping the useful terms (predicted as 1) and ignoring the irrelevant terms (predicted as 0). We demonstrate the efficacy of our proposed framework with extensive experimental results on CANARD and QuAC -- the two popularly utilized datasets in ConvQA. We demonstrate that selecting relevant turns works better than rewriting the original question. We also investigate how adding the irrelevant history turns negatively impacts the model's performance and discuss the research challenges that demand more attention from the IR community.
Towards an architectural framework for intelligent virtual agents using probabilistic programming
Jul 20, 2023We present a new framework called KorraAI for conceiving and building embodied conversational agents (ECAs). Our framework models ECAs' behavior considering contextual information, for example, about environment and interaction time, and uncertain information provided by the human interaction partner. Moreover, agents built with KorraAI can show proactive behavior, as they can initiate interactions with human partners. For these purposes, KorraAI exploits probabilistic programming. Probabilistic models in KorraAI are used to model its behavior and interactions with the user. They enable adaptation to the user's preferences and a certain degree of indeterminism in the ECAs to achieve more natural behavior. Human-like internal states, such as moods, preferences, and emotions (e.g., surprise), can be modeled in KorraAI with distributions and Bayesian networks. These models can evolve over time, even without interaction with the user. ECA models are implemented as plugins and share a common interface. This enables ECA designers to focus more on the character they are modeling and less on the technical details, as well as to store and exchange ECA models. Several applications of KorraAI ECAs are possible, such as virtual sales agents, customer service agents, virtual companions, entertainers, or tutors.
MASR: Metadata Aware Speech Representation
Jul 20, 2023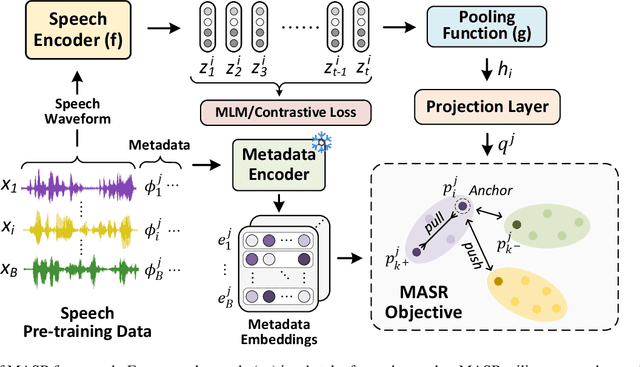
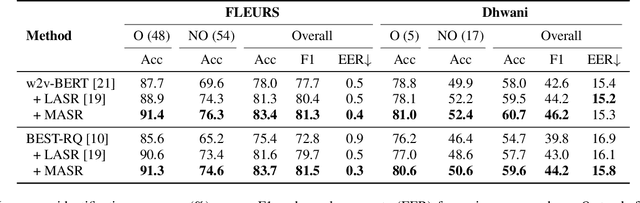
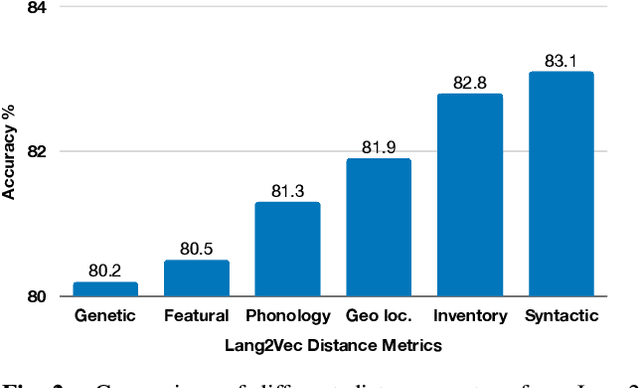

In the recent years, speech representation learning is constructed primarily as a self-supervised learning (SSL) task, using the raw audio signal alone, while ignoring the side-information that is often available for a given speech recording. In this paper, we propose MASR, a Metadata Aware Speech Representation learning framework, which addresses the aforementioned limitations. MASR enables the inclusion of multiple external knowledge sources to enhance the utilization of meta-data information. The external knowledge sources are incorporated in the form of sample-level pair-wise similarity matrices that are useful in a hard-mining loss. A key advantage of the MASR framework is that it can be combined with any choice of SSL method. Using MASR representations, we perform evaluations on several downstream tasks such as language identification, speech recognition and other non-semantic tasks such as speaker and emotion recognition. In these experiments, we illustrate significant performance improvements for the MASR over other established benchmarks. We perform a detailed analysis on the language identification task to provide insights on how the proposed loss function enables the representations to separate closely related languages.