 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Fly Neural Style Smoothing for Risk-Averse Domain Generalization
Jul 17, 2023
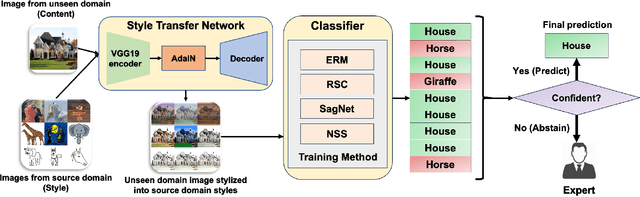
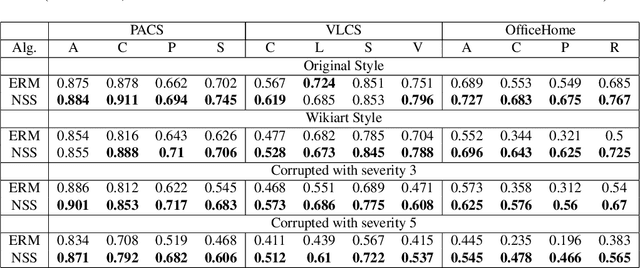
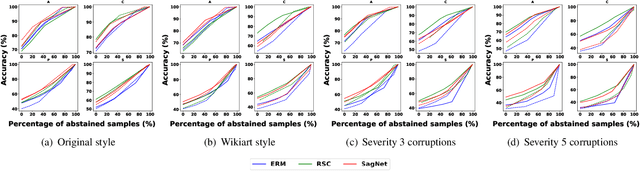
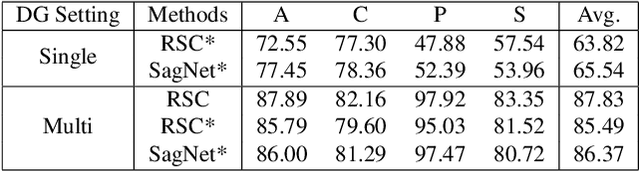
Achieving high accuracy on data from domains unseen during training is a fundamental challenge in domain generalization (DG). While state-of-the-art DG classifiers have demonstrated impressive performance across various tasks, they have shown a bias towards domain-dependent information, such as image styles, rather than domain-invariant information, such as image content. This bias renders them unreliable for deployment in risk-sensitive scenarios such as autonomous driving where a misclassification could lead to catastrophic consequences. To enable risk-averse predictions from a DG classifier, we propose a novel inference procedure, Test-Time Neural Style Smoothing (TT-NSS), that uses a "style-smoothed" version of the DG classifier for prediction at test time. Specifically, the style-smoothed classifier classifies a test image as the most probable class predicted by the DG classifier on random re-stylizations of the test image. TT-NSS uses a neural style transfer module to stylize a test image on the fly, requires only black-box access to the DG classifier, and crucially, abstains when predictions of the DG classifier on the stylized test images lack consensus. Additionally, we propose a neural style smoothing (NSS) based training procedure that can be seamlessly integrated with existing DG methods. This procedure enhances prediction consistency, improving the performance of TT-NSS on non-abstained samples. Our empirical results demonstrate the effectiveness of TT-NSS and NSS at producing and improving risk-averse predictions on unseen domains from DG classifiers trained with SOTA training methods on various benchmark datasets and their variations.
Muti-scale Graph Neural Network with Signed-attention for Social Bot Detection: A Frequency Perspective
Jul 05, 2023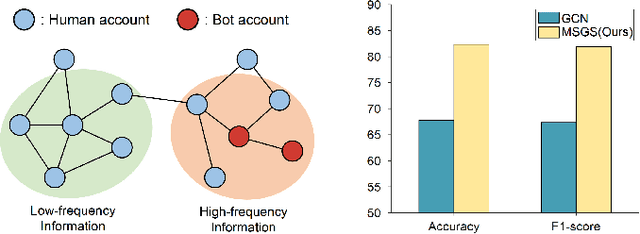
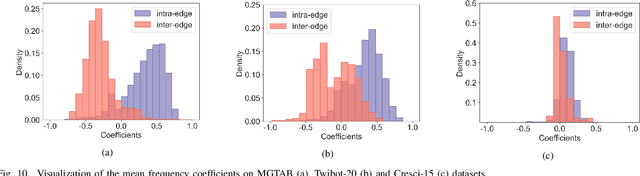
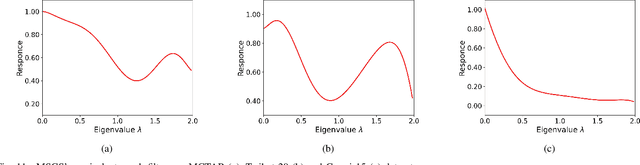

The presence of a large number of bots on social media has adverse effects. The graph neural network (GNN) can effectively leverage the social relationships between users and achieve excellent results in detecting bots. Recently, more and more GNN-based methods have been proposed for bot detection. However, the existing GNN-based bot detection methods only focus on low-frequency information and seldom consider high-frequency information, which limits the representation ability of the model. To address this issue, this paper proposes a Multi-scale with Signed-attention Graph Filter for social bot detection called MSGS. MSGS could effectively utilize both high and low-frequency information in the social graph. Specifically, MSGS utilizes a multi-scale structure to produce representation vectors at different scales. These representations are then combined using a signed-attention mechanism. Finally, multi-scale representations via MLP after polymerization to produce the final result. We analyze the frequency response and demonstrate that MSGS is a more flexible and expressive adaptive graph filter. MSGS can effectively utilize high-frequency information to alleviate the over-smoothing problem of deep GNNs. Experimental results on real-world datasets demonstrate that our method achieves better performance compared with several state-of-the-art social bot detection methods.
Parametric Depth Based Feature Representation Learning for Object Detection and Segmentation in Bird's Eye View
Jul 11, 2023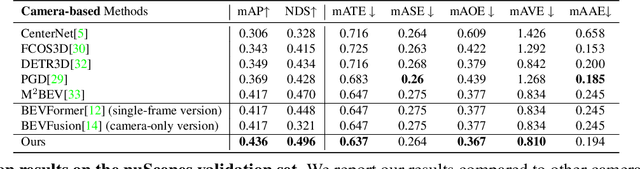


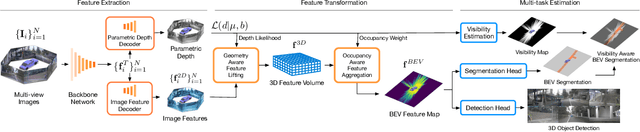
Recent vision-only perception models for autonomous driving achieved promising results by encoding multi-view image features into Bird's-Eye-View (BEV) space. A critical step and the main bottleneck of these methods is transforming image features into the BEV coordinate frame. This paper focuses on leveraging geometry information, such as depth, to model such feature transformation. Existing works rely on non-parametric depth distribution modeling leading to significant memory consumption, or ignore the geometry information to address this problem. In contrast, we propose to use parametric depth distribution modeling for feature transformation. We first lift the 2D image features to the 3D space defined for the ego vehicle via a predicted parametric depth distribution for each pixel in each view. Then, we aggregate the 3D feature volume based on the 3D space occupancy derived from depth to the BEV frame. Finally, we use the transformed features for downstream tasks such as object detection and semantic segmentation. Existing semantic segmentation methods do also suffer from an hallucination problem as they do not take visibility information into account. This hallucination can be particularly problematic for subsequent modules such as control and planning. To mitigate the issue, our method provides depth uncertainty and reliable visibility-aware estimations. We further leverage our parametric depth modeling to present a novel visibility-aware evaluation metric that, when taken into account, can mitigate the hallucination problem. Extensive experiments on object detection and semantic segmentation on the nuScenes datasets demonstrate that our method outperforms existing methods on both tasks.
Physical Layer Secret Key Agreement Using One-Bit Quantization and Low-Density Parity-Check Codes
Jul 05, 2023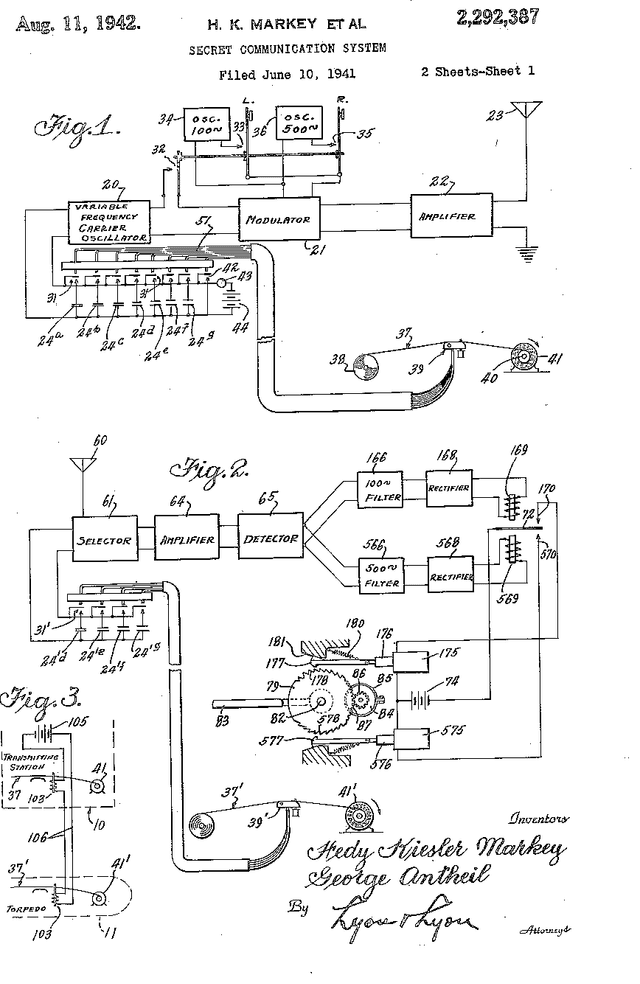
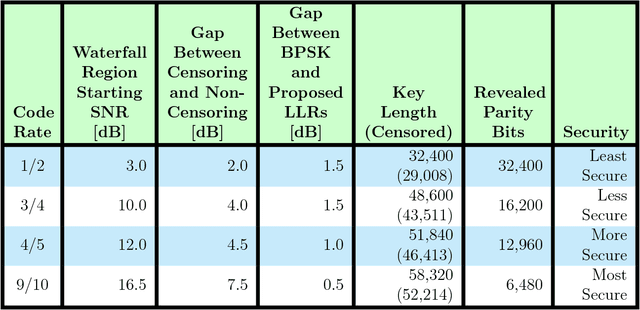
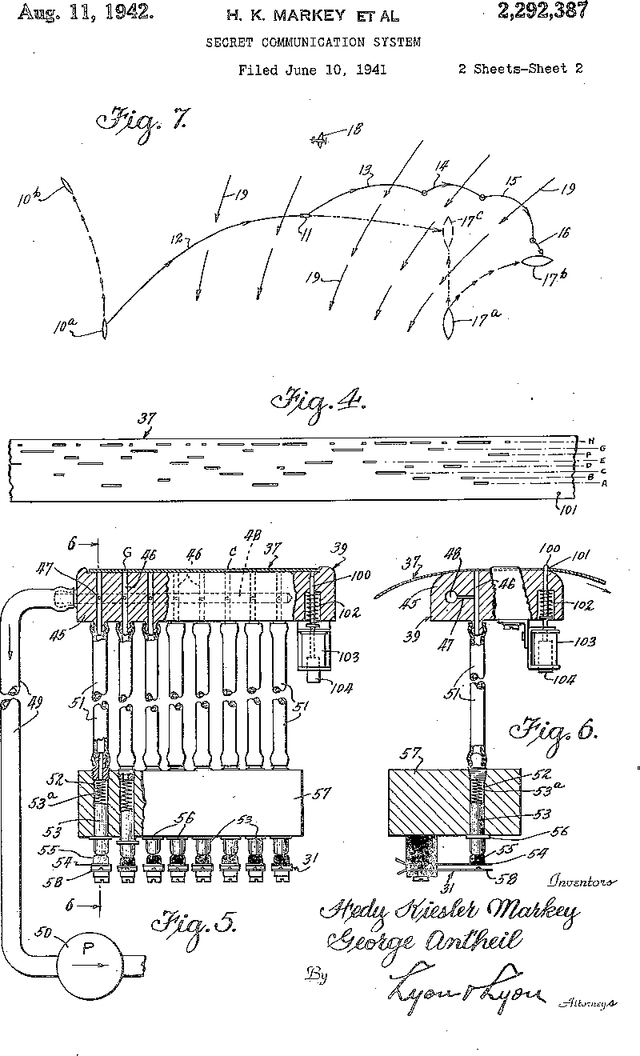
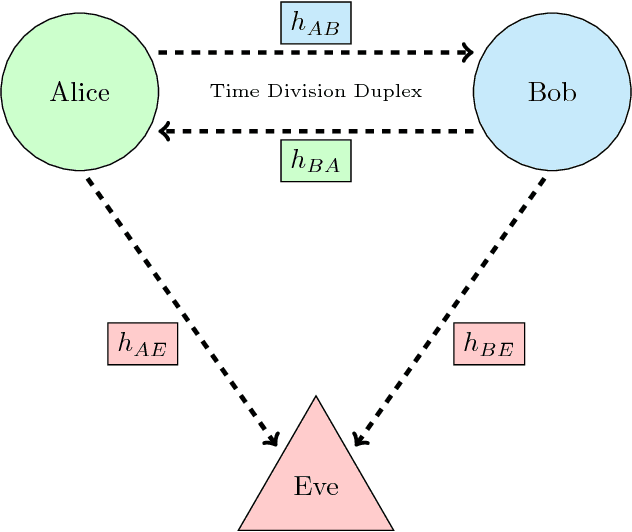
Physical layer approaches for generating secret encryption keys for wireless systems using channel information have attracted increased interest from researchers in recent years. This paper presents a new approach for calculating log-likelihood ratios (LLRs) for secret key generation that is based on one-bit quantization of channel measurements and the difference between channel estimates at legitimate reciprocal nodes. The studied secret key agreement approach, which implements advantage distillation along with information reconciliation using Slepian-Wolf low-density parity-check (LDPC) codes, is discussed and illustrated with numerical results obtained from simulations. These results show the probability of bit disagreement for keys generated using the proposed LLR calculations compared with alternative LLR calculation methods for key generation based on channel state information. The proposed LLR calculations are shown to be an improvement to the studied approach of physical layer secret key agreement.
A Meta-Learning Based Precoder Optimization Framework for Rate-Splitting Multiple Access
Jul 17, 2023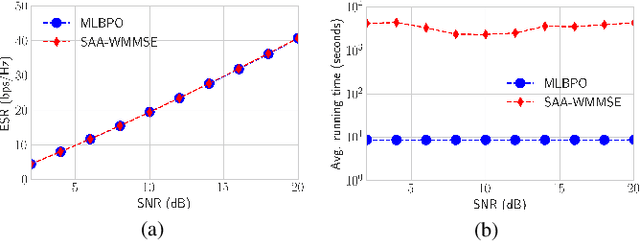
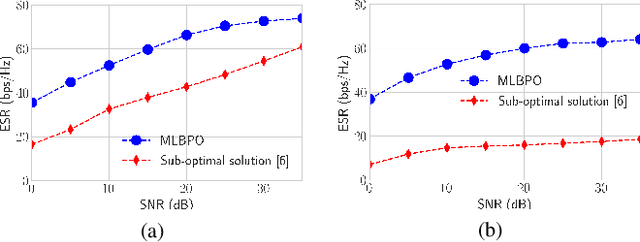
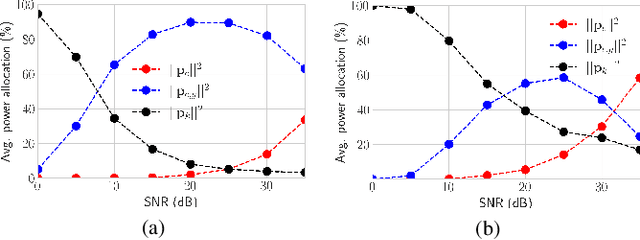
In this letter, we propose the use of a meta-learning based precoder optimization framework to directly optimize the Rate-Splitting Multiple Access (RSMA) precoders with partial Channel State Information at the Transmitter (CSIT). By exploiting the overfitting of the compact neural network to maximize the explicit Average Sum-Rate (ASR) expression, we effectively bypass the need for any other training data while minimizing the total running time. Numerical results reveal that the meta-learning based solution achieves similar ASR performance to conventional precoder optimization in medium-scale scenarios, and significantly outperforms sub-optimal low complexity precoder algorithms in the large-scale regime.
A Secure Aggregation for Federated Learning on Long-Tailed Data
Jul 17, 2023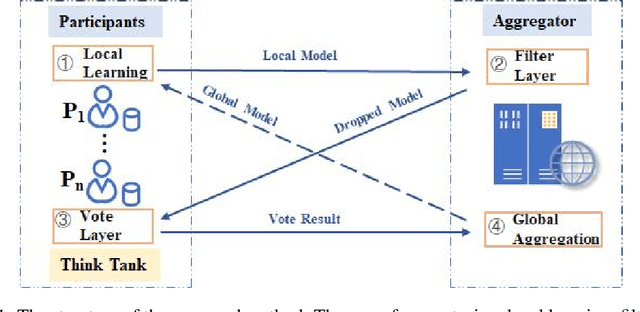
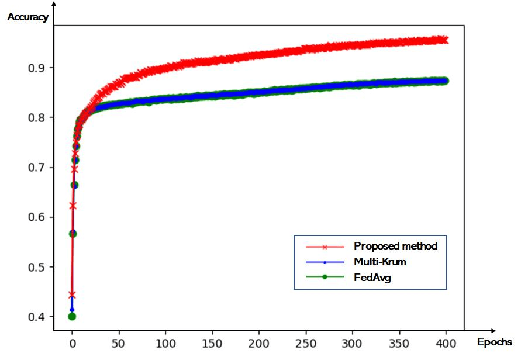
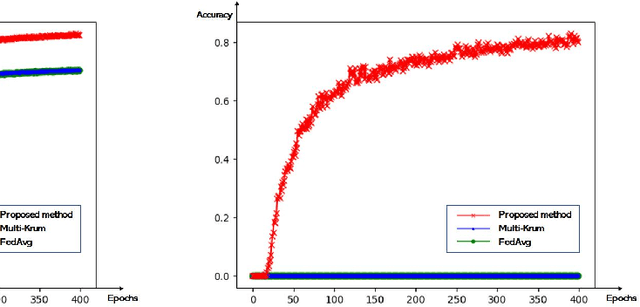
As a distributed learning, Federated Learning (FL) faces two challenges: the unbalanced distribution of training data among participants, and the model attack by Byzantine nodes. In this paper, we consider the long-tailed distribution with the presence of Byzantine nodes in the FL scenario. A novel two-layer aggregation method is proposed for the rejection of malicious models and the advisable selection of valuable models containing tail class data information. We introduce the concept of think tank to leverage the wisdom of all participants. Preliminary experiments validate that the think tank can make effective model selections for global aggregation.
Asymmetric $X$-Secure $T$-Private Information Retrieval: More Databases is Not Always Better
May 09, 2023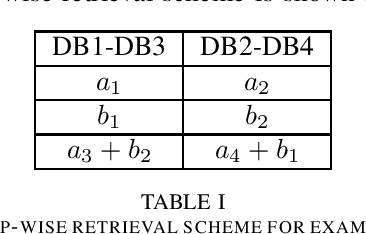
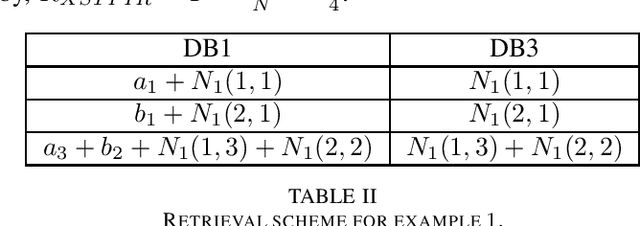
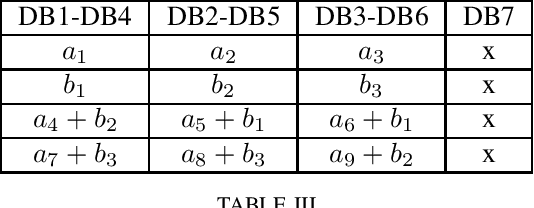

We consider a special case of $X$-secure $T$-private information retrieval (XSTPIR), where the security requirement is \emph{asymmetric} due to possible missing communication links between the $N$ databases considered in the system. We define the problem with a communication matrix that indicates all possible communications among the databases, and propose a database grouping mechanism that collects subsets of databases in an optimal manner, followed by a group-based PIR scheme to perform asymmetric XSTPIR with the goal of maximizing the communication rate (minimizing the download cost). We provide an upper bound on the general achievable rate of asymmetric XSTPIR, and show that the proposed scheme achieves this upper bound in some cases. The proposed approach outperforms classical XSTPIR under certain conditions, and the results of this work show that unlike in the symmetric case, some databases with certain properties can be dropped to achieve higher rates, concluding that more databases is not always better.
Machine learning at the mesoscale: a computation-dissipation bottleneck
Jul 05, 2023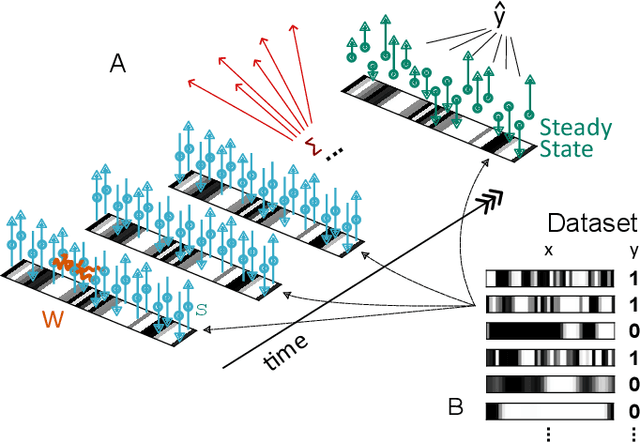
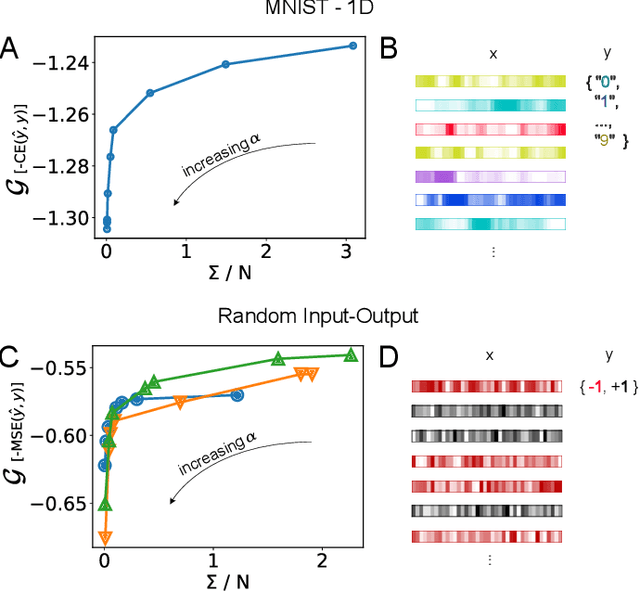
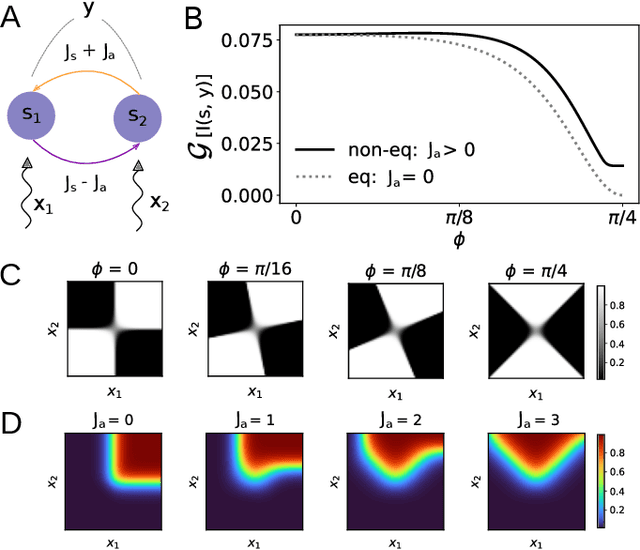
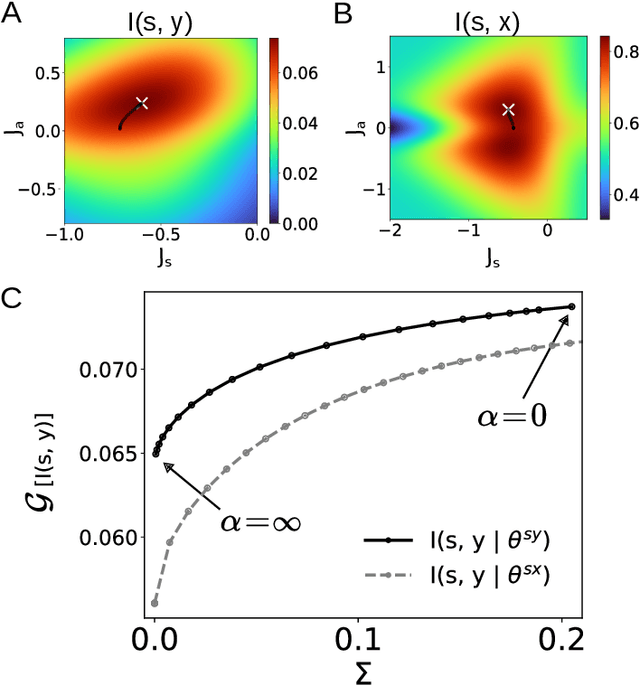
The cost of information processing in physical systems calls for a trade-off between performance and energetic expenditure. Here we formulate and study a computation-dissipation bottleneck in mesoscopic systems used as input-output devices. Using both real datasets and synthetic tasks, we show how non-equilibrium leads to enhanced performance. Our framework sheds light on a crucial compromise between information compression, input-output computation and dynamic irreversibility induced by non-reciprocal interactions.
A Strategic Framework for Optimal Decisions in Football 1-vs-1 Shot-Taking Situations: An Integrated Approach of Machine Learning, Theory-Based Modeling, and Game Theory
Jul 27, 2023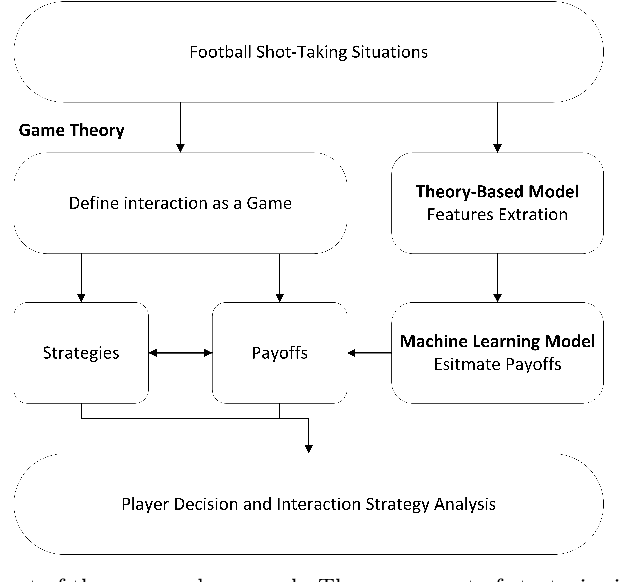

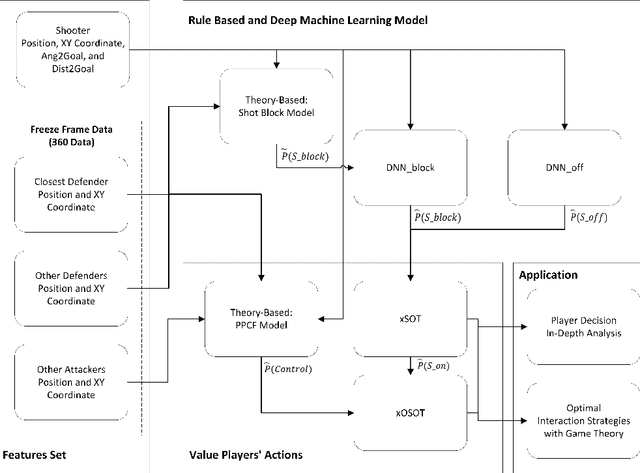
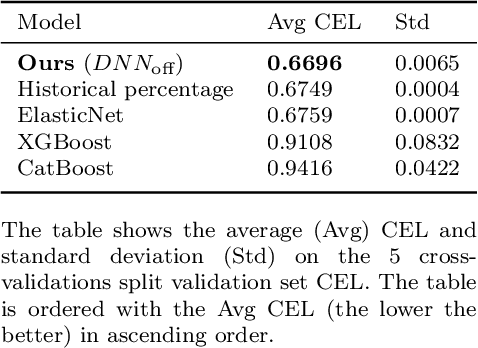
Complex interactions between two opposing agents frequently occur in domains of machine learning, game theory, and other application domains. Quantitatively analyzing the strategies involved can provide an objective basis for decision-making. One such critical scenario is shot-taking in football, where decisions, such as whether the attacker should shoot or pass the ball and whether the defender should attempt to block the shot, play a crucial role in the outcome of the game. However, there are currently no effective data-driven and/or theory-based approaches to analyzing such situations. To address this issue, we proposed a novel framework to analyze such scenarios based on game theory, where we estimate the expected payoff with machine learning (ML) models, and additional features for ML models were extracted with a theory-based shot block model. Conventionally, successes or failures (1 or 0) are used as payoffs, while a success shot (goal) is extremely rare in football. Therefore, we proposed the Expected Probability of Shot On Target (xSOT) metric to evaluate players' actions even if the shot results in no goal; this allows for effective differentiation and comparison between different shots and even enables counterfactual shot situation analysis. In our experiments, we have validated the framework by comparing it with baseline and ablated models. Furthermore, we have observed a high correlation between the xSOT and existing metrics. This alignment of information suggests that xSOT provides valuable insights. Lastly, as an illustration, we studied optimal strategies in the World Cup 2022 and analyzed a shot situation in EURO 2020.
On (Normalised) Discounted Cumulative Gain as an Offline Evaluation Metric for Top-$n$ Recommendation
Jul 27, 2023
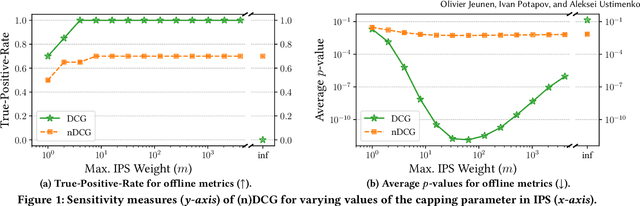
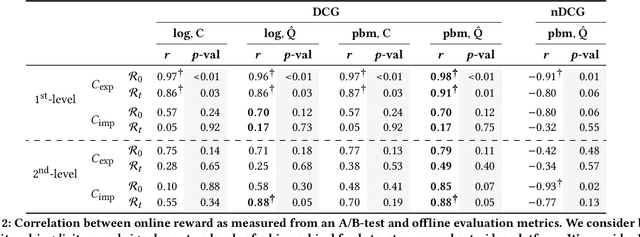
Approaches to recommendation are typically evaluated in one of two ways: (1) via a (simulated) online experiment, often seen as the gold standard, or (2) via some offline evaluation procedure, where the goal is to approximate the outcome of an online experiment. Several offline evaluation metrics have been adopted in the literature, inspired by ranking metrics prevalent in the field of Information Retrieval. (Normalised) Discounted Cumulative Gain (nDCG) is one such metric that has seen widespread adoption in empirical studies, and higher (n)DCG values have been used to present new methods as the state-of-the-art in top-$n$ recommendation for many years. Our work takes a critical look at this approach, and investigates when we can expect such metrics to approximate the gold standard outcome of an online experiment. We formally present the assumptions that are necessary to consider DCG an unbiased estimator of online reward and provide a derivation for this metric from first principles, highlighting where we deviate from its traditional uses in IR. Importantly, we show that normalising the metric renders it inconsistent, in that even when DCG is unbiased, ranking competing methods by their normalised DCG can invert their relative order. Through a correlation analysis between off- and on-line experiments conducted on a large-scale recommendation platform, we show that our unbiased DCG estimates strongly correlate with online reward, even when some of the metric's inherent assumptions are violated. This statement no longer holds for its normalised variant, suggesting that nDCG's practical utility may be limited.