 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Unified and General Framework for Continual Learning
Mar 20, 2024
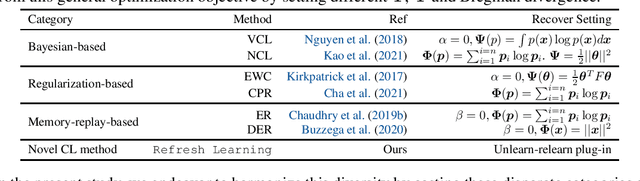
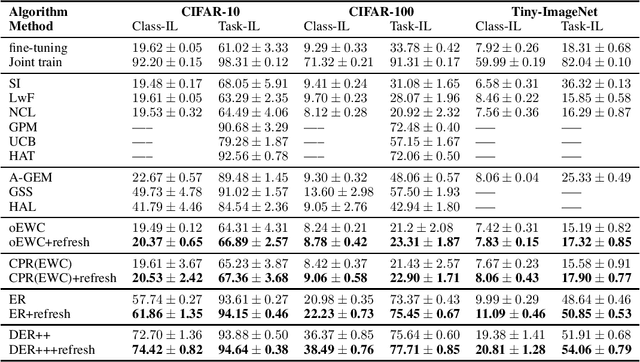
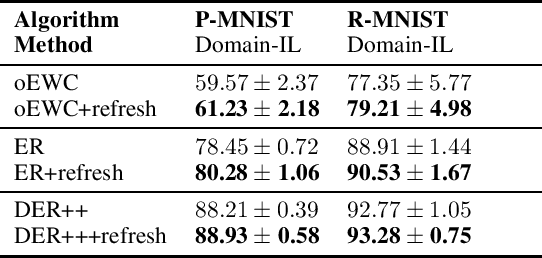

Continual Learning (CL) focuses on learning from dynamic and changing data distributions while retaining previously acquired knowledge. Various methods have been developed to address the challenge of catastrophic forgetting, including regularization-based, Bayesian-based, and memory-replay-based techniques. However, these methods lack a unified framework and common terminology for describing their approaches. This research aims to bridge this gap by introducing a comprehensive and overarching framework that encompasses and reconciles these existing methodologies. Notably, this new framework is capable of encompassing established CL approaches as special instances within a unified and general optimization objective. An intriguing finding is that despite their diverse origins, these methods share common mathematical structures. This observation highlights the compatibility of these seemingly distinct techniques, revealing their interconnectedness through a shared underlying optimization objective. Moreover, the proposed general framework introduces an innovative concept called refresh learning, specifically designed to enhance the CL performance. This novel approach draws inspiration from neuroscience, where the human brain often sheds outdated information to improve the retention of crucial knowledge and facilitate the acquisition of new information. In essence, refresh learning operates by initially unlearning current data and subsequently relearning it. It serves as a versatile plug-in that seamlessly integrates with existing CL methods, offering an adaptable and effective enhancement to the learning process. Extensive experiments on CL benchmarks and theoretical analysis demonstrate the effectiveness of the proposed refresh learning. Code is available at \url{https://github.com/joey-wang123/CL-refresh-learning}.
PseudoTouch: Efficiently Imaging the Surface Feel of Objects for Robotic Manipulation
Mar 22, 2024Humans seemingly incorporate potential touch signals in their perception. Our goal is to equip robots with a similar capability, which we term \ourmodel. \ourmodel aims to predict the expected touch signal based on a visual patch representing the touched area. We frame this problem as the task of learning a low-dimensional visual-tactile embedding, wherein we encode a depth patch from which we decode the tactile signal. To accomplish this task, we employ ReSkin, an inexpensive and replaceable magnetic-based tactile sensor. Using ReSkin, we collect and train PseudoTouch on a dataset comprising aligned tactile and visual data pairs obtained through random touching of eight basic geometric shapes. We demonstrate the efficacy of PseudoTouch through its application to two downstream tasks: object recognition and grasp stability prediction. In the object recognition task, we evaluate the learned embedding's performance on a set of five basic geometric shapes and five household objects. Using PseudoTouch, we achieve an object recognition accuracy 84% after just ten touches, surpassing a proprioception baseline. For the grasp stability task, we use ACRONYM labels to train and evaluate a grasp success predictor using PseudoTouch's predictions derived from virtual depth information. Our approach yields an impressive 32% absolute improvement in accuracy compared to the baseline relying on partial point cloud data. We make the data, code, and trained models publicly available at http://pseudotouch.cs.uni-freiburg.de.
Adaptive Coded Federated Learning: Privacy Preservation and Straggler Mitigation
Mar 22, 2024In this article, we address the problem of federated learning in the presence of stragglers. For this problem, a coded federated learning framework has been proposed, where the central server aggregates gradients received from the non-stragglers and gradient computed from a privacy-preservation global coded dataset to mitigate the negative impact of the stragglers. However, when aggregating these gradients, fixed weights are consistently applied across iterations, neglecting the generation process of the global coded dataset and the dynamic nature of the trained model over iterations. This oversight may result in diminished learning performance. To overcome this drawback, we propose a new method named adaptive coded federated learning (ACFL). In ACFL, before the training, each device uploads a coded local dataset with additive noise to the central server to generate a global coded dataset under privacy preservation requirements. During each iteration of the training, the central server aggregates the gradients received from the non-stragglers and the gradient computed from the global coded dataset, where an adaptive policy for varying the aggregation weights is designed. Under this policy, we optimize the performance in terms of privacy and learning, where the learning performance is analyzed through convergence analysis and the privacy performance is characterized via mutual information differential privacy. Finally, we perform simulations to demonstrate the superiority of ACFL compared with the non-adaptive methods.
The Value of Reward Lookahead in Reinforcement Learning
Mar 18, 2024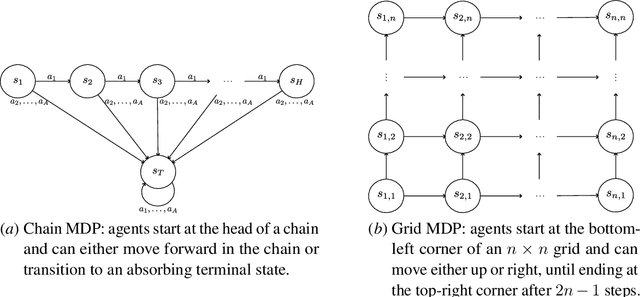
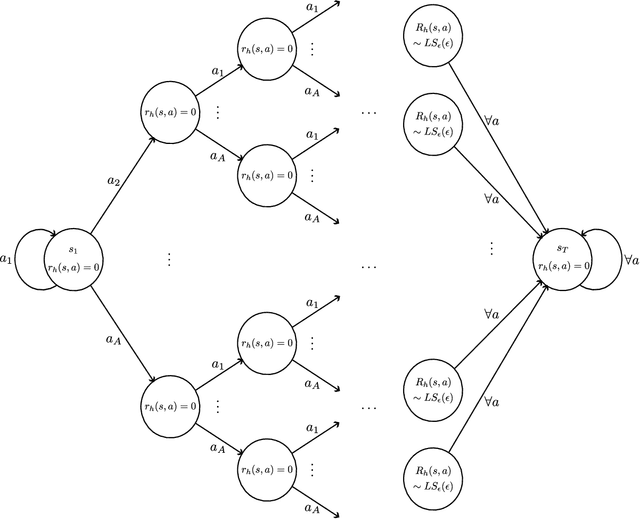
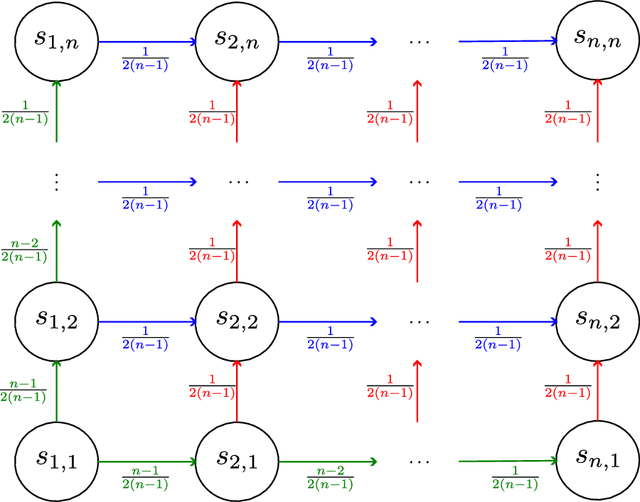
In reinforcement learning (RL), agents sequentially interact with changing environments while aiming to maximize the obtained rewards. Usually, rewards are observed only after acting, and so the goal is to maximize the expected cumulative reward. Yet, in many practical settings, reward information is observed in advance -- prices are observed before performing transactions; nearby traffic information is partially known; and goals are oftentimes given to agents prior to the interaction. In this work, we aim to quantifiably analyze the value of such future reward information through the lens of competitive analysis. In particular, we measure the ratio between the value of standard RL agents and that of agents with partial future-reward lookahead. We characterize the worst-case reward distribution and derive exact ratios for the worst-case reward expectations. Surprisingly, the resulting ratios relate to known quantities in offline RL and reward-free exploration. We further provide tight bounds for the ratio given the worst-case dynamics. Our results cover the full spectrum between observing the immediate rewards before acting to observing all the rewards before the interaction starts.
FE-DeTr: Keypoint Detection and Tracking in Low-quality Image Frames with Events
Mar 18, 2024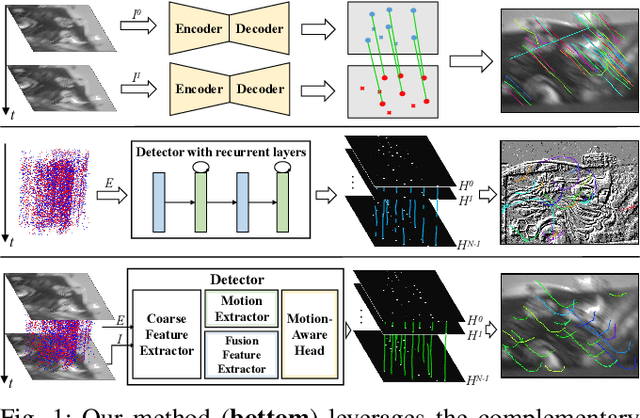
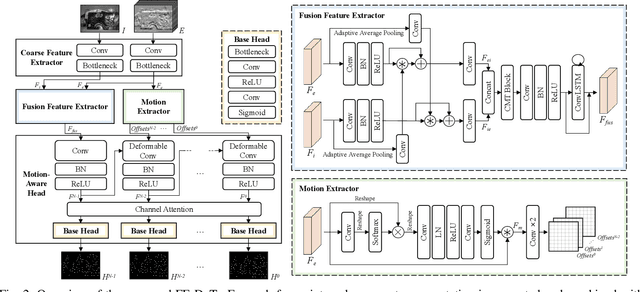
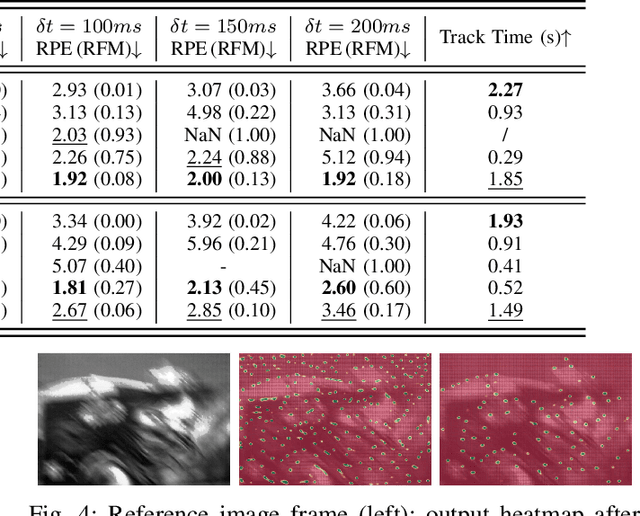
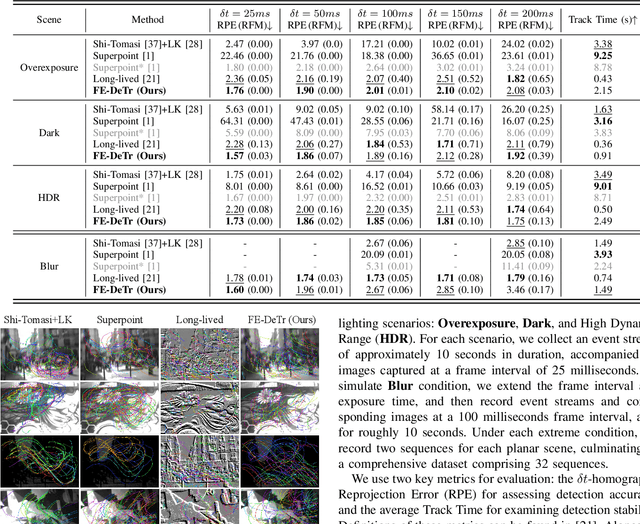
Keypoint detection and tracking in traditional image frames are often compromised by image quality issues such as motion blur and extreme lighting conditions. Event cameras offer potential solutions to these challenges by virtue of their high temporal resolution and high dynamic range. However, they have limited performance in practical applications due to their inherent noise in event data. This paper advocates fusing the complementary information from image frames and event streams to achieve more robust keypoint detection and tracking. Specifically, we propose a novel keypoint detection network that fuses the textural and structural information from image frames with the high-temporal-resolution motion information from event streams, namely FE-DeTr. The network leverages a temporal response consistency for supervision, ensuring stable and efficient keypoint detection. Moreover, we use a spatio-temporal nearest-neighbor search strategy for robust keypoint tracking. Extensive experiments are conducted on a new dataset featuring both image frames and event data captured under extreme conditions. The experimental results confirm the superior performance of our method over both existing frame-based and event-based methods.
Scene-LLM: Extending Language Model for 3D Visual Understanding and Reasoning
Mar 18, 2024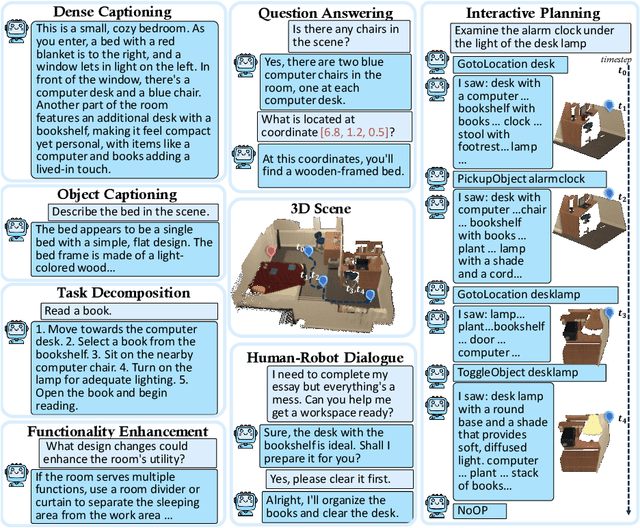
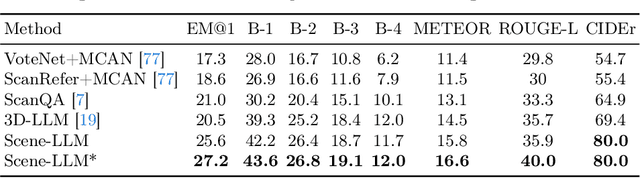
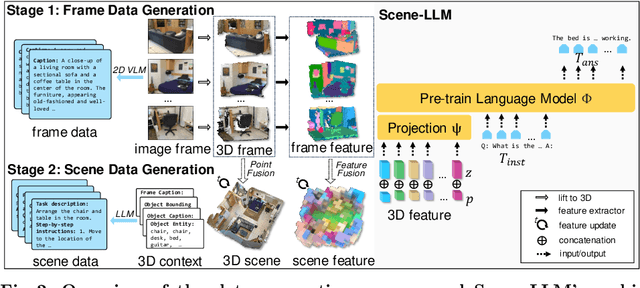
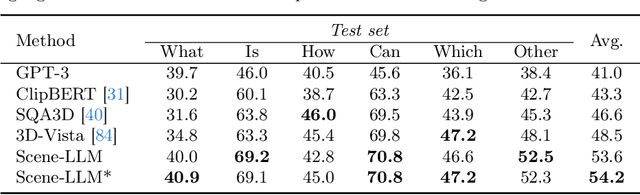
This paper introduces Scene-LLM, a 3D-visual-language model that enhances embodied agents' abilities in interactive 3D indoor environments by integrating the reasoning strengths of Large Language Models (LLMs). Scene-LLM adopts a hybrid 3D visual feature representation, that incorporates dense spatial information and supports scene state updates. The model employs a projection layer to efficiently project these features in the pre-trained textual embedding space, enabling effective interpretation of 3D visual information. Unique to our approach is the integration of both scene-level and ego-centric 3D information. This combination is pivotal for interactive planning, where scene-level data supports global planning and ego-centric data is important for localization. Notably, we use ego-centric 3D frame features for feature alignment, an efficient technique that enhances the model's ability to align features of small objects within the scene. Our experiments with Scene-LLM demonstrate its strong capabilities in dense captioning, question answering, and interactive planning. We believe Scene-LLM advances the field of 3D visual understanding and reasoning, offering new possibilities for sophisticated agent interactions in indoor settings.
YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
Feb 29, 2024Today's deep learning methods focus on how to design the most appropriate objective functions so that the prediction results of the model can be closest to the ground truth. Meanwhile, an appropriate architecture that can facilitate acquisition of enough information for prediction has to be designed. Existing methods ignore a fact that when input data undergoes layer-by-layer feature extraction and spatial transformation, large amount of information will be lost. This paper will delve into the important issues of data loss when data is transmitted through deep networks, namely information bottleneck and reversible functions. We proposed the concept of programmable gradient information (PGI) to cope with the various changes required by deep networks to achieve multiple objectives. PGI can provide complete input information for the target task to calculate objective function, so that reliable gradient information can be obtained to update network weights. In addition, a new lightweight network architecture -- Generalized Efficient Layer Aggregation Network (GELAN), based on gradient path planning is designed. GELAN's architecture confirms that PGI has gained superior results on lightweight models. We verified the proposed GELAN and PGI on MS COCO dataset based object detection. The results show that GELAN only uses conventional convolution operators to achieve better parameter utilization than the state-of-the-art methods developed based on depth-wise convolution. PGI can be used for variety of models from lightweight to large. It can be used to obtain complete information, so that train-from-scratch models can achieve better results than state-of-the-art models pre-trained using large datasets, the comparison results are shown in Figure 1. The source codes are at: https://github.com/WongKinYiu/yolov9.
Raw Instinct: Trust Your Classifiers and Skip the Conversion
Mar 21, 2024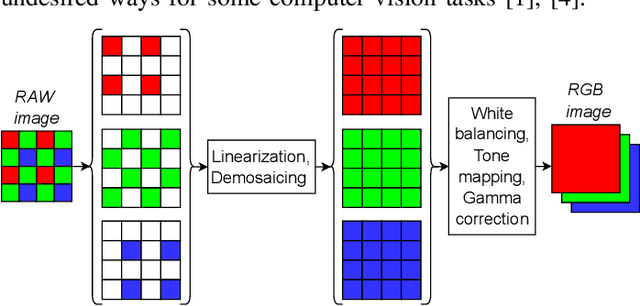
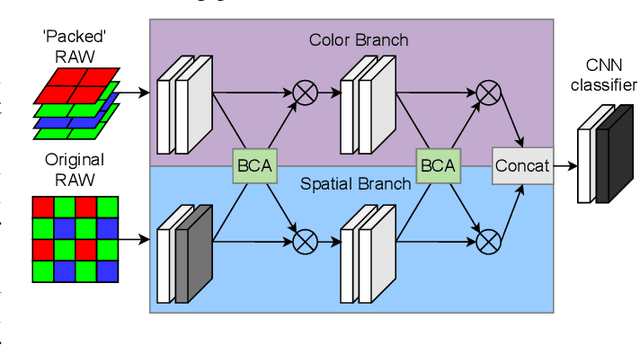

Using RAW-images in computer vision problems is surprisingly underexplored considering that converting from RAW to RGB does not introduce any new capture information. In this paper, we show that a sufficiently advanced classifier can yield equivalent results on RAW input compared to RGB and present a new public dataset consisting of RAW images and the corresponding converted RGB images. Classifying images directly from RAW is attractive, as it allows for skipping the conversion to RGB, lowering computation time significantly. Two CNN classifiers are used to classify the images in both formats, confirming that classification performance can indeed be preserved. We furthermore show that the total computation time from RAW image data to classification results for RAW images can be up to 8.46 times faster than RGB. These results contribute to the evidence found in related works, that using RAW images as direct input to computer vision algorithms looks very promising.
* https://www.kaggle.com/datasets/mathiasviborg/raw-instinct
Varroa destructor detection on honey bees using hyperspectral imagery
Mar 21, 2024


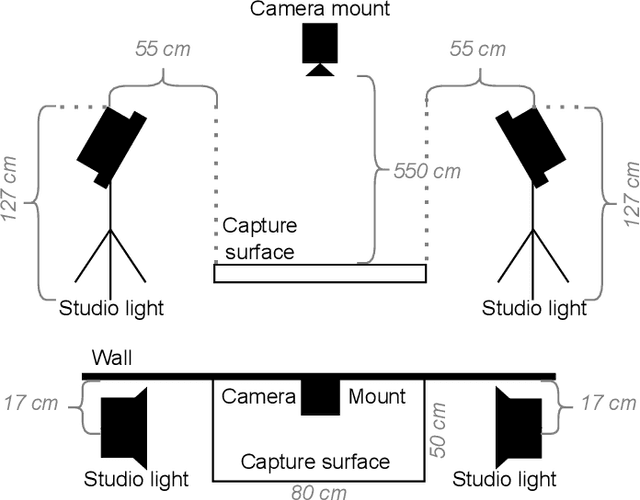
Hyperspectral (HS) imagery in agriculture is becoming increasingly common. These images have the advantage of higher spectral resolution. Advanced spectral processing techniques are required to unlock the information potential in these HS images. The present paper introduces a method rooted in multivariate statistics designed to detect parasitic Varroa destructor mites on the body of western honey bee Apis mellifera, enabling easier and continuous monitoring of the bee hives. The methodology explores unsupervised (K-means++) and recently developed supervised (Kernel Flows - Partial Least-Squares, KF-PLS) methods for parasitic identification. Additionally, in light of the emergence of custom-band multispectral cameras, the present research outlines a strategy for identifying the specific wavelengths necessary for effective bee-mite separation, suitable for implementation in a custom-band camera. Illustrated with a real-case dataset, our findings demonstrate that as few as four spectral bands are sufficient for accurate parasite identification.
Chained Information-Theoretic bounds and Tight Regret Rate for Linear Bandit Problems
Mar 05, 2024This paper studies the Bayesian regret of a variant of the Thompson-Sampling algorithm for bandit problems. It builds upon the information-theoretic framework of [Russo and Van Roy, 2015] and, more specifically, on the rate-distortion analysis from [Dong and Van Roy, 2020], where they proved a bound with regret rate of $O(d\sqrt{T \log(T)})$ for the $d$-dimensional linear bandit setting. We focus on bandit problems with a metric action space and, using a chaining argument, we establish new bounds that depend on the metric entropy of the action space for a variant of Thompson-Sampling. Under suitable continuity assumption of the rewards, our bound offers a tight rate of $O(d\sqrt{T})$ for $d$-dimensional linear bandit problems.