 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Phase Match for Out-of-Distribution Generalization
Jul 24, 2023

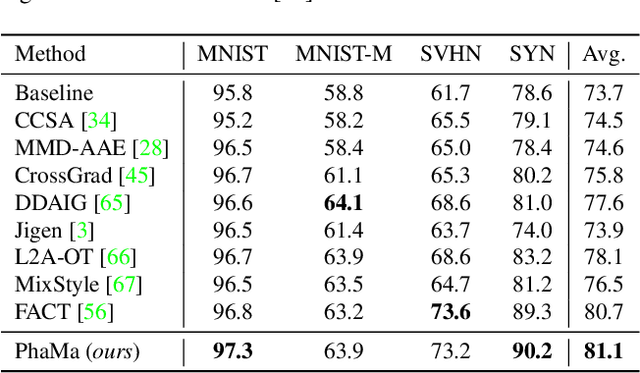
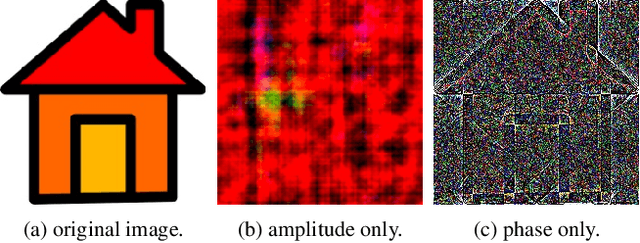
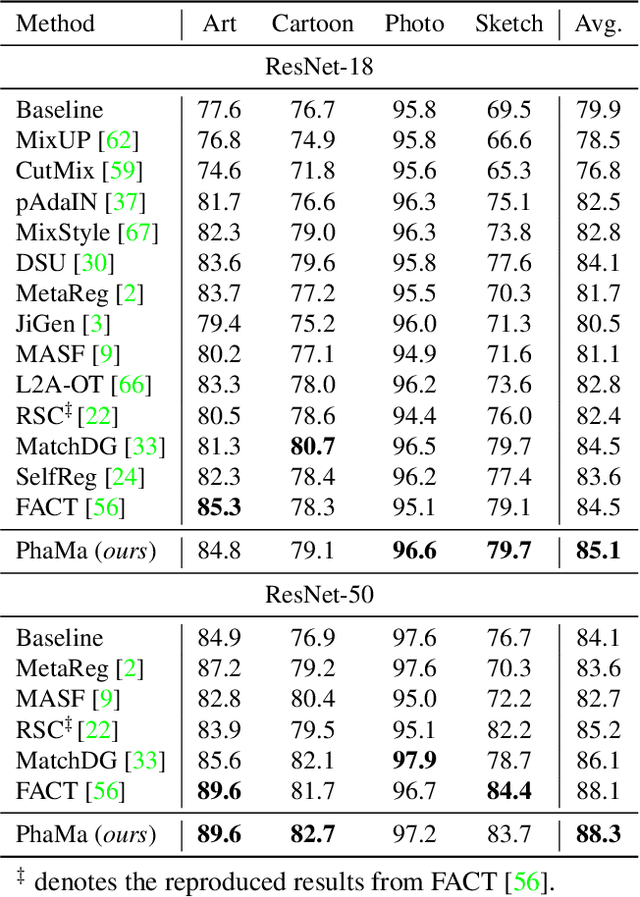
The Fourier transform, serving as an explicit decomposition method for visual signals, has been employed to explain the out-of-distribution generalization behaviors of Convolutional Neural Networks (CNNs). Previous research and empirical studies have indicated that the amplitude spectrum plays a decisive role in CNN recognition, but it is susceptible to disturbance caused by distribution shifts. On the other hand, the phase spectrum preserves highly-structured spatial information, which is crucial for visual representation learning. In this paper, we aim to clarify the relationships between Domain Generalization (DG) and the frequency components by introducing a Fourier-based structural causal model. Specifically, we interpret the phase spectrum as semi-causal factors and the amplitude spectrum as non-causal factors. Building upon these observations, we propose Phase Match (PhaMa) to address DG problems. Our method introduces perturbations on the amplitude spectrum and establishes spatial relationships to match the phase components. Through experiments on multiple benchmarks, we demonstrate that our proposed method achieves state-of-the-art performance in domain generalization and out-of-distribution robustness tasks.
PRIOR: Prototype Representation Joint Learning from Medical Images and Reports
Jul 24, 2023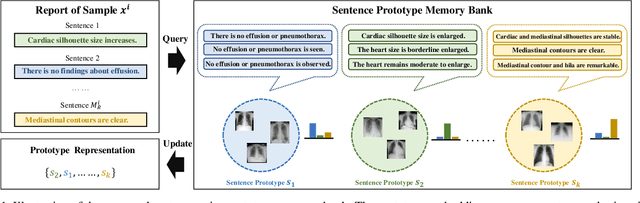
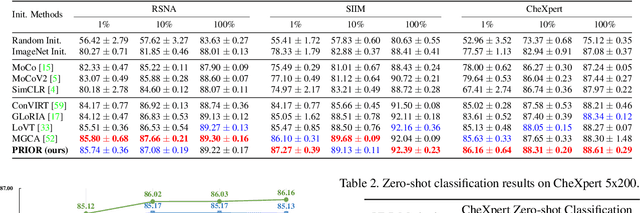
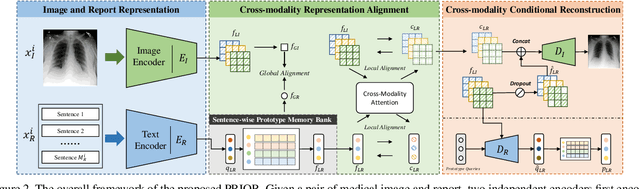
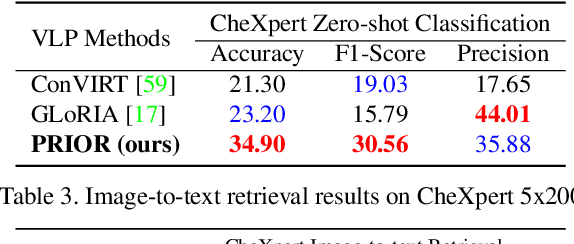
Contrastive learning based vision-language joint pre-training has emerged as a successful representation learning strategy. In this paper, we present a prototype representation learning framework incorporating both global and local alignment between medical images and reports. In contrast to standard global multi-modality alignment methods, we employ a local alignment module for fine-grained representation. Furthermore, a cross-modality conditional reconstruction module is designed to interchange information across modalities in the training phase by reconstructing masked images and reports. For reconstructing long reports, a sentence-wise prototype memory bank is constructed, enabling the network to focus on low-level localized visual and high-level clinical linguistic features. Additionally, a non-auto-regressive generation paradigm is proposed for reconstructing non-sequential reports. Experimental results on five downstream tasks, including supervised classification, zero-shot classification, image-to-text retrieval, semantic segmentation, and object detection, show the proposed method outperforms other state-of-the-art methods across multiple datasets and under different dataset size settings. The code is available at https://github.com/QtacierP/PRIOR.
TF-ICON: Diffusion-Based Training-Free Cross-Domain Image Composition
Jul 24, 2023Text-driven diffusion models have exhibited impressive generative capabilities, enabling various image editing tasks. In this paper, we propose TF-ICON, a novel Training-Free Image COmpositioN framework that harnesses the power of text-driven diffusion models for cross-domain image-guided composition. This task aims to seamlessly integrate user-provided objects into a specific visual context. Current diffusion-based methods often involve costly instance-based optimization or finetuning of pretrained models on customized datasets, which can potentially undermine their rich prior. In contrast, TF-ICON can leverage off-the-shelf diffusion models to perform cross-domain image-guided composition without requiring additional training, finetuning, or optimization. Moreover, we introduce the exceptional prompt, which contains no information, to facilitate text-driven diffusion models in accurately inverting real images into latent representations, forming the basis for compositing. Our experiments show that equipping Stable Diffusion with the exceptional prompt outperforms state-of-the-art inversion methods on various datasets (CelebA-HQ, COCO, and ImageNet), and that TF-ICON surpasses prior baselines in versatile visual domains. Code is available at https://github.com/Shilin-LU/TF-ICON
Performance of Large Language Models in a Computer Science Degree Program
Jul 24, 2023Large language models such as ChatGPT-3.5 and GPT-4.0 are ubiquitous and dominate the current discourse. Their transformative capabilities have led to a paradigm shift in how we interact with and utilize (text-based) information. Each day, new possibilities to leverage the capabilities of these models emerge. This paper presents findings on the performance of different large language models in a university of applied sciences' undergraduate computer science degree program. Our primary objective is to assess the effectiveness of these models within the curriculum by employing them as educational aids. By prompting the models with lecture material, exercise tasks, and past exams, we aim to evaluate their proficiency across different computer science domains. We showcase the strong performance of current large language models while highlighting limitations and constraints within the context of such a degree program. We found that ChatGPT-3.5 averaged 79.9% of the total score in 10 tested modules, BingAI achieved 68.4%, and LLaMa, in the 65 billion parameter variant, 20%. Despite these convincing results, even GPT-4.0 would not pass the degree program - due to limitations in mathematical calculations.
Nonparametric Linear Feature Learning in Regression Through Regularisation
Jul 24, 2023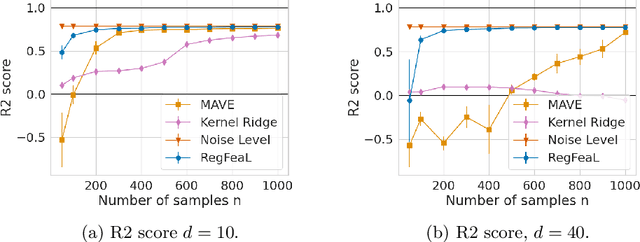
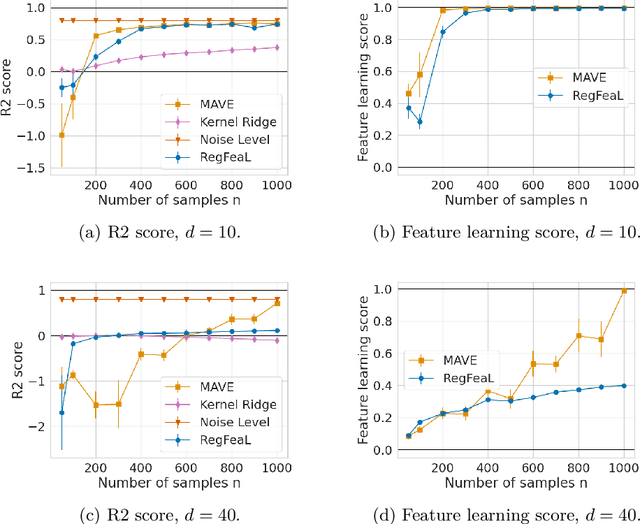
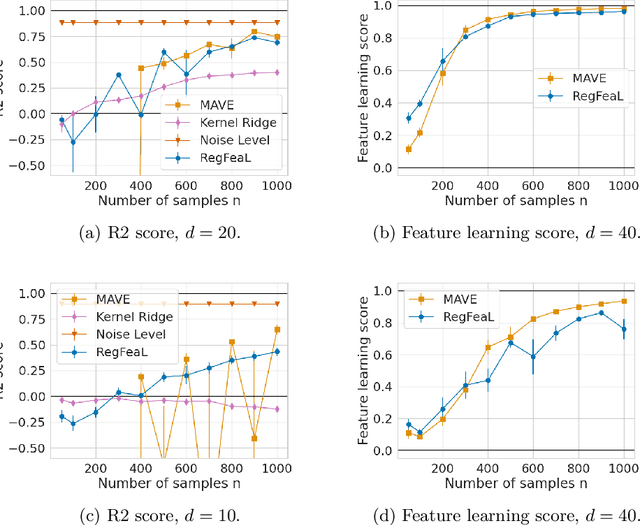
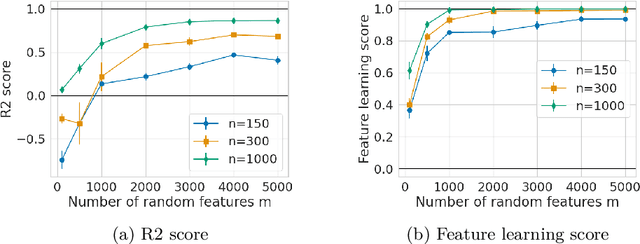
Representation learning plays a crucial role in automated feature selection, particularly in the context of high-dimensional data, where non-parametric methods often struggle. In this study, we focus on supervised learning scenarios where the pertinent information resides within a lower-dimensional linear subspace of the data, namely the multi-index model. If this subspace were known, it would greatly enhance prediction, computation, and interpretation. To address this challenge, we propose a novel method for linear feature learning with non-parametric prediction, which simultaneously estimates the prediction function and the linear subspace. Our approach employs empirical risk minimisation, augmented with a penalty on function derivatives, ensuring versatility. Leveraging the orthogonality and rotation invariance properties of Hermite polynomials, we introduce our estimator, named RegFeaL. By utilising alternative minimisation, we iteratively rotate the data to improve alignment with leading directions and accurately estimate the relevant dimension in practical settings. We establish that our method yields a consistent estimator of the prediction function with explicit rates. Additionally, we provide empirical results demonstrating the performance of RegFeaL in various experiments.
Privacy-Preserving Graph Machine Learning from Data to Computation: A Survey
Jul 10, 2023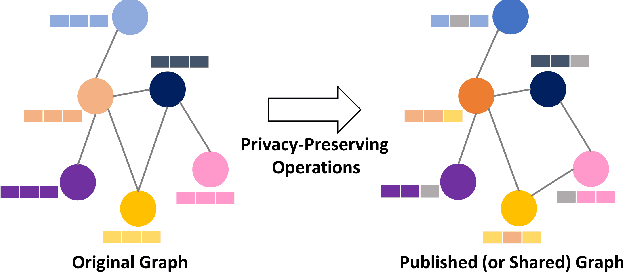
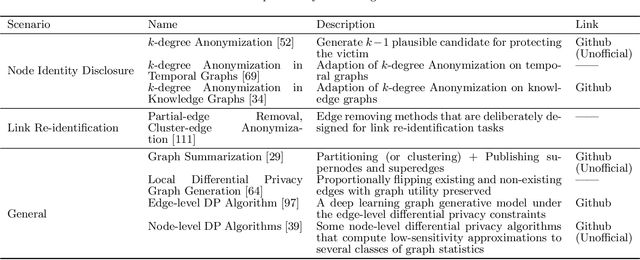
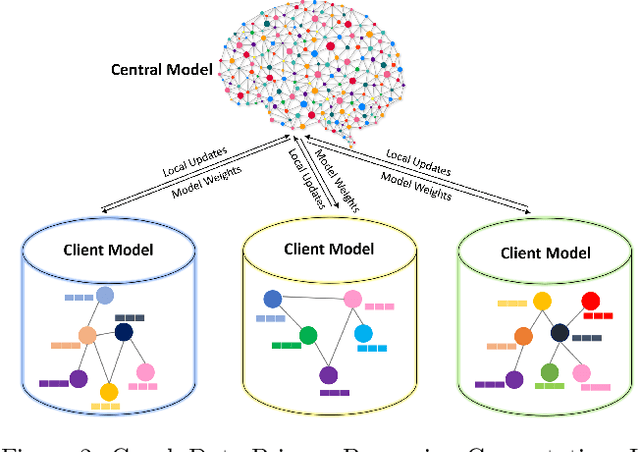
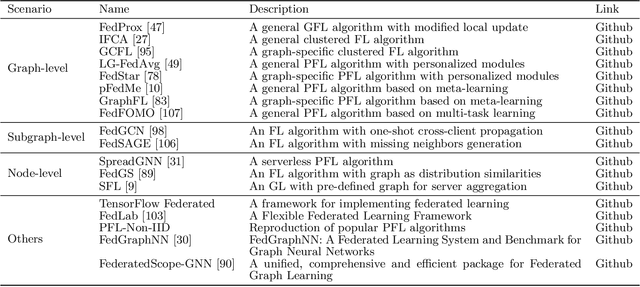
In graph machine learning, data collection, sharing, and analysis often involve multiple parties, each of which may require varying levels of data security and privacy. To this end, preserving privacy is of great importance in protecting sensitive information. In the era of big data, the relationships among data entities have become unprecedentedly complex, and more applications utilize advanced data structures (i.e., graphs) that can support network structures and relevant attribute information. To date, many graph-based AI models have been proposed (e.g., graph neural networks) for various domain tasks, like computer vision and natural language processing. In this paper, we focus on reviewing privacy-preserving techniques of graph machine learning. We systematically review related works from the data to the computational aspects. We first review methods for generating privacy-preserving graph data. Then we describe methods for transmitting privacy-preserved information (e.g., graph model parameters) to realize the optimization-based computation when data sharing among multiple parties is risky or impossible. In addition to discussing relevant theoretical methodology and software tools, we also discuss current challenges and highlight several possible future research opportunities for privacy-preserving graph machine learning. Finally, we envision a unified and comprehensive secure graph machine learning system.
Generalization Guarantees via Algorithm-dependent Rademacher Complexity
Jul 04, 2023Algorithm- and data-dependent generalization bounds are required to explain the generalization behavior of modern machine learning algorithms. In this context, there exists information theoretic generalization bounds that involve (various forms of) mutual information, as well as bounds based on hypothesis set stability. We propose a conceptually related, but technically distinct complexity measure to control generalization error, which is the empirical Rademacher complexity of an algorithm- and data-dependent hypothesis class. Combining standard properties of Rademacher complexity with the convenient structure of this class, we are able to (i) obtain novel bounds based on the finite fractal dimension, which (a) extend previous fractal dimension-type bounds from continuous to finite hypothesis classes, and (b) avoid a mutual information term that was required in prior work; (ii) we greatly simplify the proof of a recent dimension-independent generalization bound for stochastic gradient descent; and (iii) we easily recover results for VC classes and compression schemes, similar to approaches based on conditional mutual information.
Dipping PLMs Sauce: Bridging Structure and Text for Effective Knowledge Graph Completion via Conditional Soft Prompting
Jul 04, 2023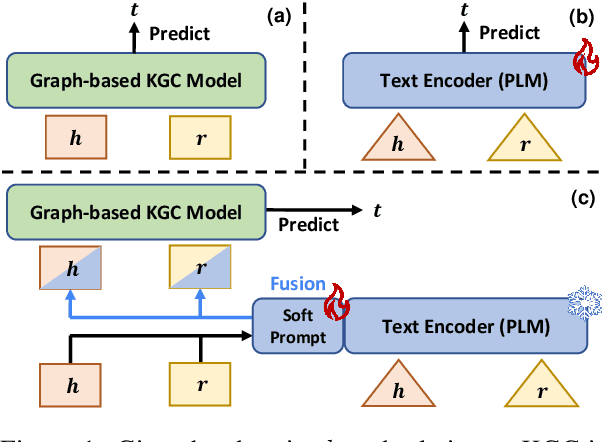
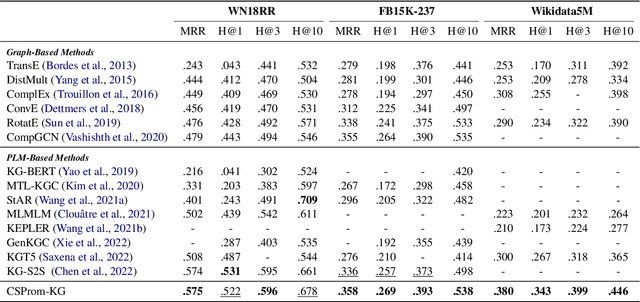
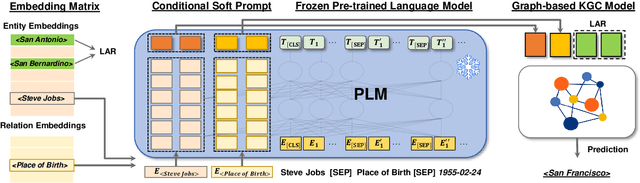
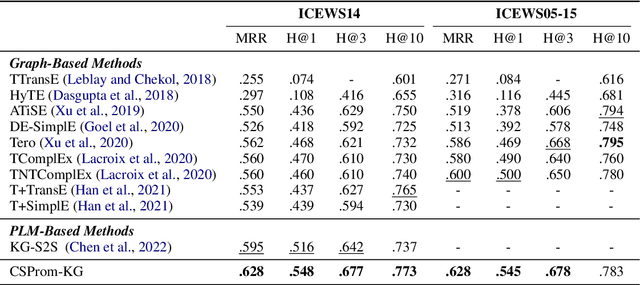
Knowledge Graph Completion (KGC) often requires both KG structural and textual information to be effective. Pre-trained Language Models (PLMs) have been used to learn the textual information, usually under the fine-tune paradigm for the KGC task. However, the fine-tuned PLMs often overwhelmingly focus on the textual information and overlook structural knowledge. To tackle this issue, this paper proposes CSProm-KG (Conditional Soft Prompts for KGC) which maintains a balance between structural information and textual knowledge. CSProm-KG only tunes the parameters of Conditional Soft Prompts that are generated by the entities and relations representations. We verify the effectiveness of CSProm-KG on three popular static KGC benchmarks WN18RR, FB15K-237 and Wikidata5M, and two temporal KGC benchmarks ICEWS14 and ICEWS05-15. CSProm-KG outperforms competitive baseline models and sets new state-of-the-art on these benchmarks. We conduct further analysis to show (i) the effectiveness of our proposed components, (ii) the efficiency of CSProm-KG, and (iii) the flexibility of CSProm-KG.
LIC-GAN: Language Information Conditioned Graph Generative GAN Model
Jun 02, 2023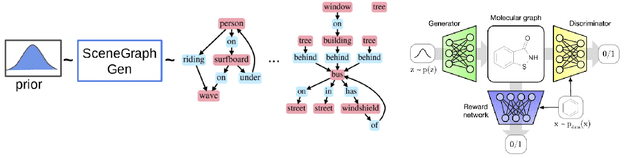
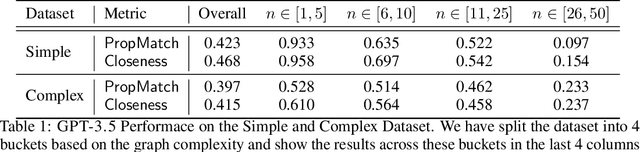
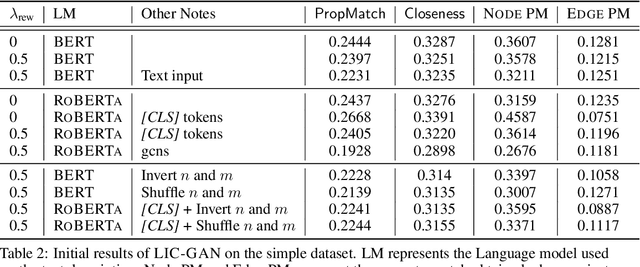
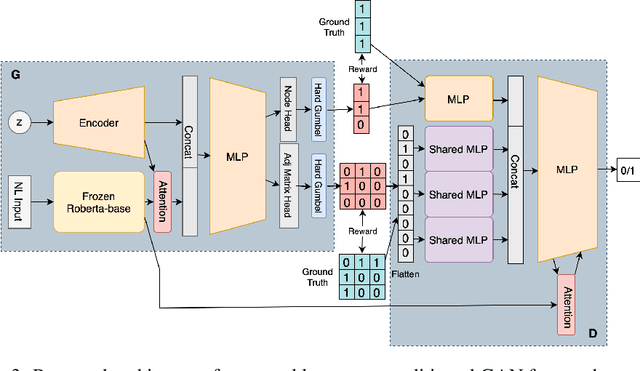
Deep generative models for Natural Language data offer a new angle on the problem of graph synthesis: by optimizing differentiable models that directly generate graphs, it is possible to side-step expensive search procedures in the discrete and vast space of possible graphs. We introduce LIC-GAN, an implicit, likelihood-free generative model for small graphs that circumvents the need for expensive graph matching procedures. Our method takes as input a natural language query and using a combination of language modelling and Generative Adversarial Networks (GANs) and returns a graph that closely matches the description of the query. We combine our approach with a reward network to further enhance the graph generation with desired properties. Our experiments, show that LIC-GAN does well on metrics such as PropMatch and Closeness getting scores of 0.36 and 0.48. We also show that LIC-GAN performs as good as ChatGPT, with ChatGPT getting scores of 0.40 and 0.42. We also conduct a few experiments to demonstrate the robustness of our method, while also highlighting a few interesting caveats of the model.
An Optimization Framework For Anomaly Detection Scores Refinement With Side Information
Apr 21, 2023
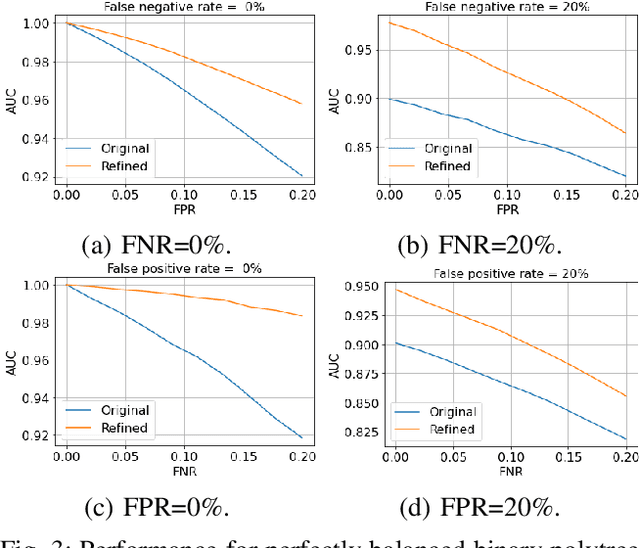
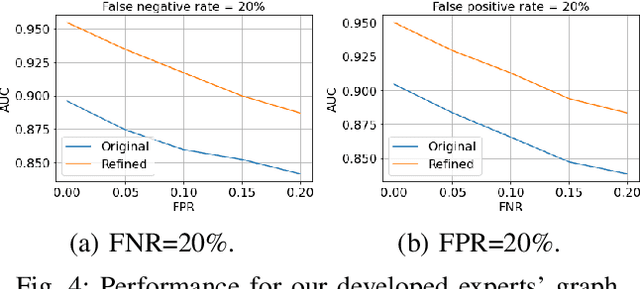
This paper considers an anomaly detection problem in which a detection algorithm assigns anomaly scores to multi-dimensional data points, such as cellular networks' Key Performance Indicators (KPIs). We propose an optimization framework to refine these anomaly scores by leveraging side information in the form of a causality graph between the various features of the data points. The refinement block builds on causality theory and a proposed notion of confidence scores. After motivating our framework, smoothness properties are proved for the ensuing mathematical expressions. Next, equipped with these results, a gradient descent algorithm is proposed, and a proof of its convergence to a stationary point is provided. Our results hold (i) for any causal anomaly detection algorithm and (ii) for any side information in the form of a directed acyclic graph. Numerical results are provided to illustrate the advantage of our proposed framework in dealing with False Positives (FPs) and False Negatives (FNs). Additionally, the effect of the graph's structure on the expected performance advantage and the various trade-offs that take place are analyzed.