 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pointwise Mutual Information Based Metric and Decoding Strategy for Faithful Generation in Document Grounded Dialogs
May 20, 2023
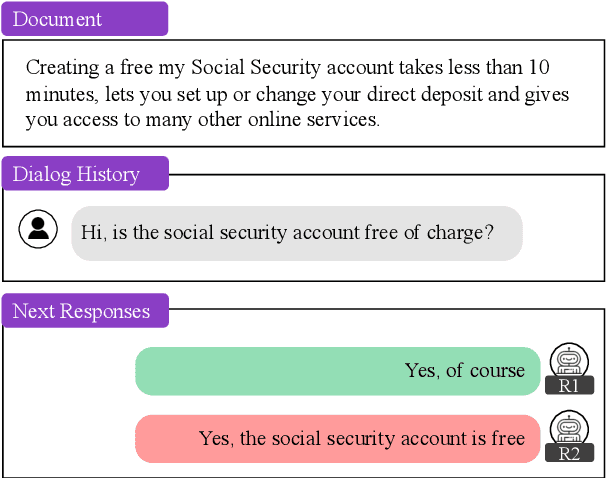
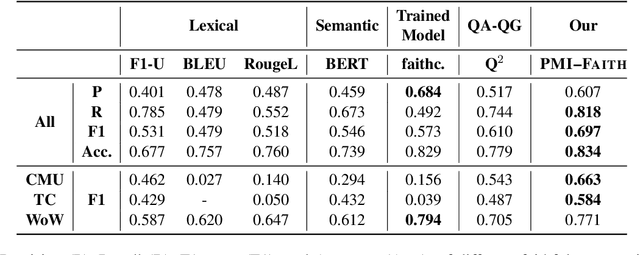
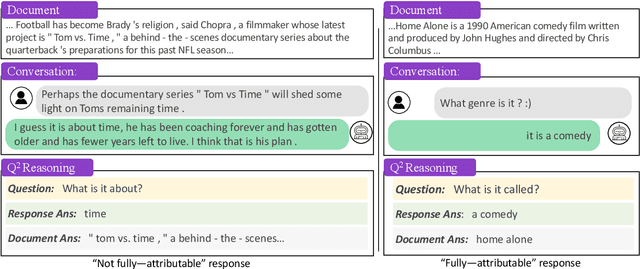
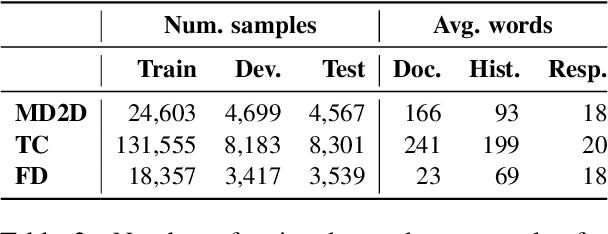
A major concern in using deep learning based generative models for document-grounded dialogs is the potential generation of responses that are not \textit{faithful} to the underlying document. Existing automated metrics used for evaluating the faithfulness of response with respect to the grounding document measure the degree of similarity between the generated response and the document's content. However, these automated metrics are far from being well aligned with human judgments. Therefore, to improve the measurement of faithfulness, we propose a new metric that utilizes (Conditional) Point-wise Mutual Information (PMI) between the generated response and the source document, conditioned on the dialogue. PMI quantifies the extent to which the document influences the generated response -- with a higher PMI indicating a more faithful response. We build upon this idea to create a new decoding technique that incorporates PMI into the response generation process to predict more faithful responses. Our experiments on the BEGIN benchmark demonstrate an improved correlation of our metric with human evaluation. We also show that our decoding technique is effective in generating more faithful responses when compared to standard decoding techniques on a set of publicly available document-grounded dialog datasets.
Stroke Extraction of Chinese Character Based on Deep Structure Deformable Image Registration
Jul 10, 2023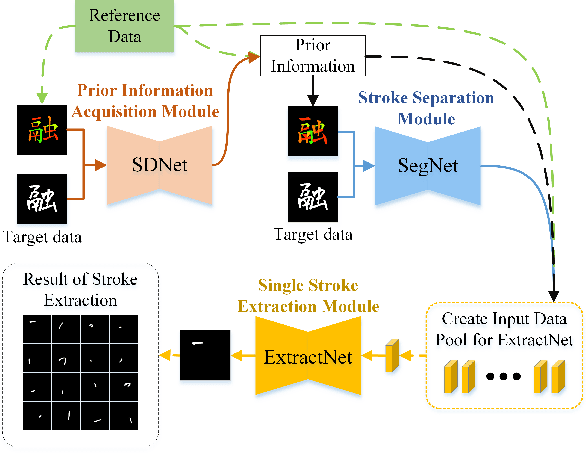
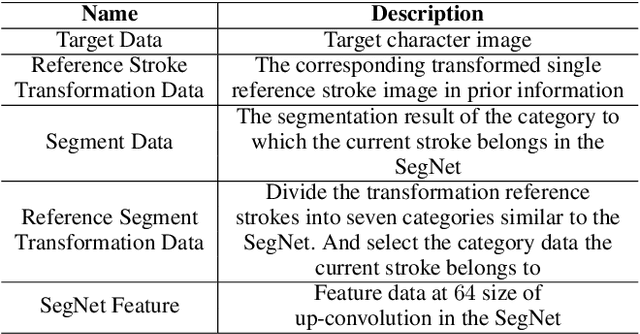
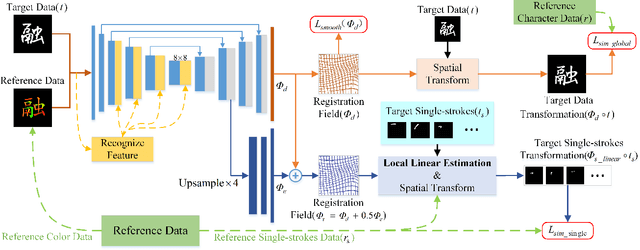
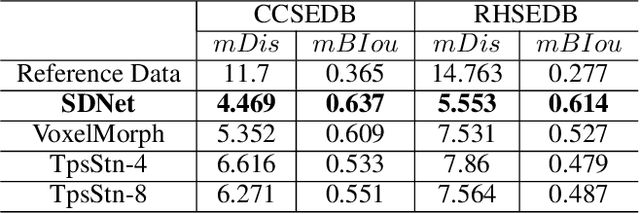
Stroke extraction of Chinese characters plays an important role in the field of character recognition and generation. The most existing character stroke extraction methods focus on image morphological features. These methods usually lead to errors of cross strokes extraction and stroke matching due to rarely using stroke semantics and prior information. In this paper, we propose a deep learning-based character stroke extraction method that takes semantic features and prior information of strokes into consideration. This method consists of three parts: image registration-based stroke registration that establishes the rough registration of the reference strokes and the target as prior information; image semantic segmentation-based stroke segmentation that preliminarily separates target strokes into seven categories; and high-precision extraction of single strokes. In the stroke registration, we propose a structure deformable image registration network to achieve structure-deformable transformation while maintaining the stable morphology of single strokes for character images with complex structures. In order to verify the effectiveness of the method, we construct two datasets respectively for calligraphy characters and regular handwriting characters. The experimental results show that our method strongly outperforms the baselines. Code is available at https://github.com/MengLi-l1/StrokeExtraction.
* 10 pages, 8 figures, published to AAAI-23 (oral)
Decentralized Adaptive Formation via Consensus-Oriented Multi-Agent Communication
Jul 23, 2023Adaptive multi-agent formation control, which requires the formation to flexibly adjust along with the quantity variations of agents in a decentralized manner, belongs to one of the most challenging issues in multi-agent systems, especially under communication-limited constraints. In this paper, we propose a novel Consensus-based Decentralized Adaptive Formation (Cons-DecAF) framework. Specifically, we develop a novel multi-agent reinforcement learning method, Consensus-oriented Multi-Agent Communication (ConsMAC), to enable agents to perceive global information and establish the consensus from local states by effectively aggregating neighbor messages. Afterwards, we leverage policy distillation to accomplish the adaptive formation adjustment. Meanwhile, instead of pre-assigning specific positions of agents, we employ a displacement-based formation by Hausdorff distance to significantly improve the formation efficiency. The experimental results through extensive simulations validate that the proposed method has achieved outstanding performance in terms of both speed and stability.
Mental Workload Estimation with Electroencephalogram Signals by Combining Multi-Space Deep Models
Jul 23, 2023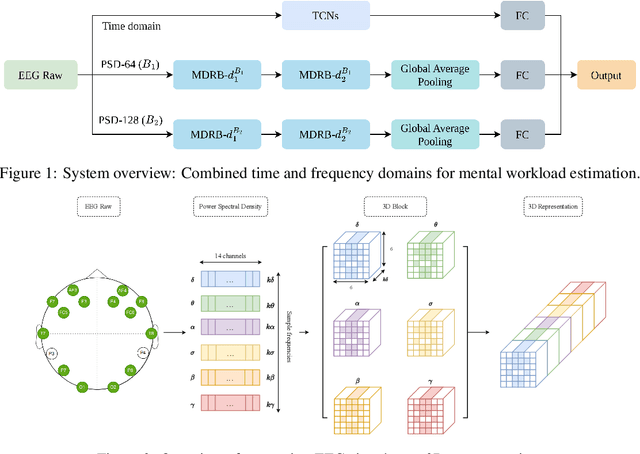
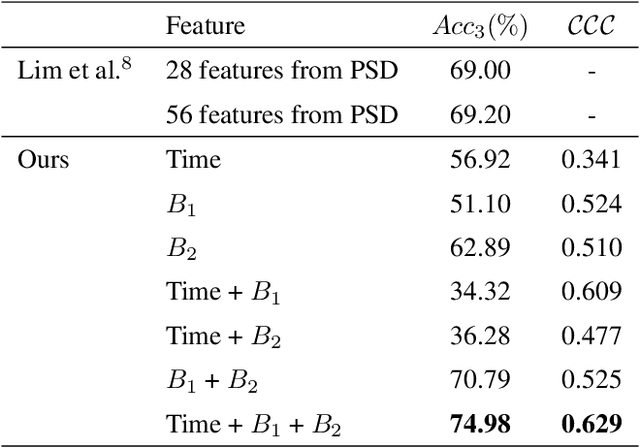
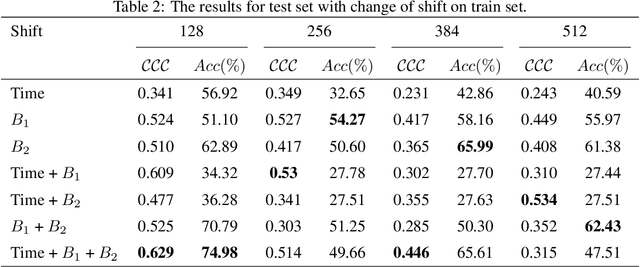
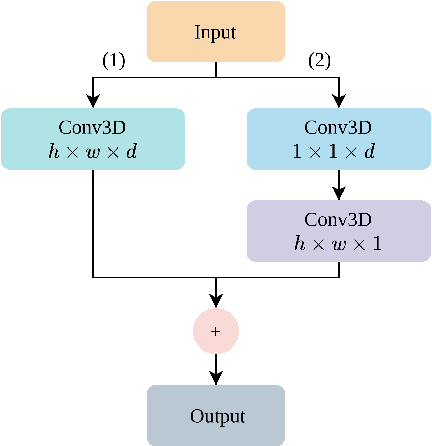
The human brain is in a continuous state of activity during both work and rest. Mental activity is a daily process, and when the brain is overworked, it can have negative effects on human health. In recent years, great attention has been paid to early detection of mental health problems because it can help prevent serious health problems and improve quality of life. Several signals are used to assess mental state, but the electroencephalogram (EEG) is widely used by researchers because of the large amount of information it provides about the brain. This paper aims to classify mental workload into three states and estimate continuum levels. Our method combines multiple dimensions of space to achieve the best results for mental estimation. In the time domain approach, we use Temporal Convolutional Networks, and in the frequency domain, we propose a new architecture called the Multi-Dimensional Residual Block, which combines residual blocks.
Rethinking pose estimation in crowds: overcoming the detection information-bottleneck and ambiguity
Jun 13, 2023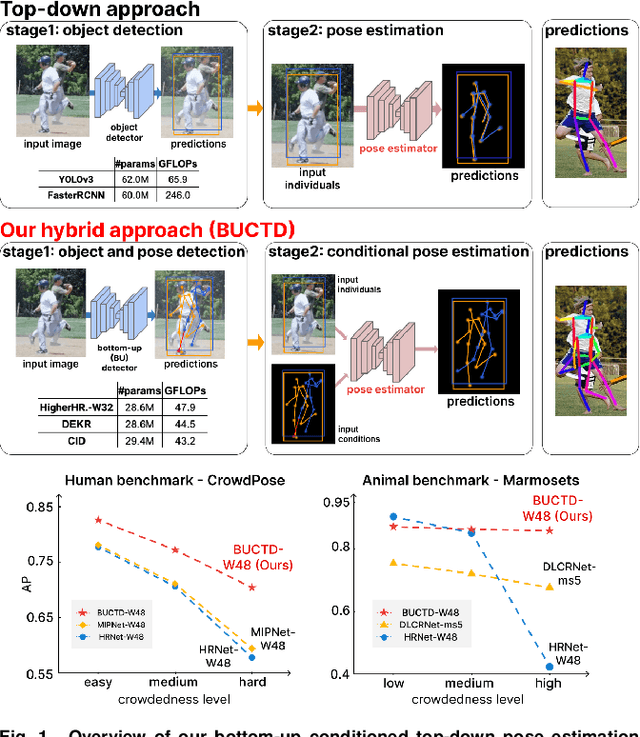
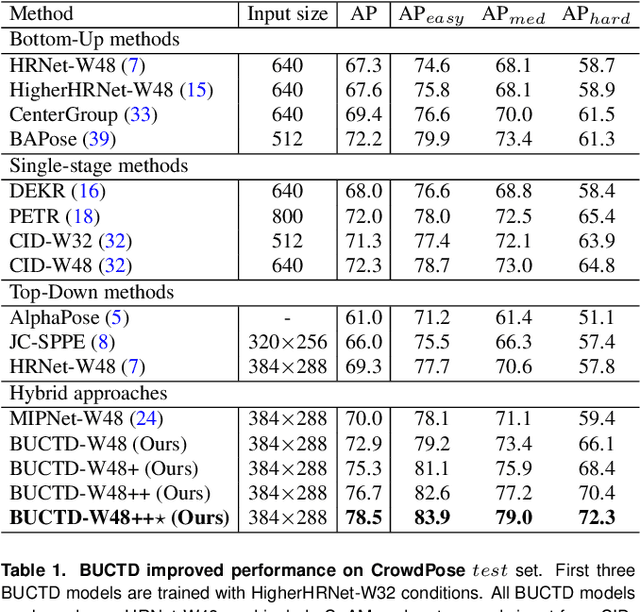
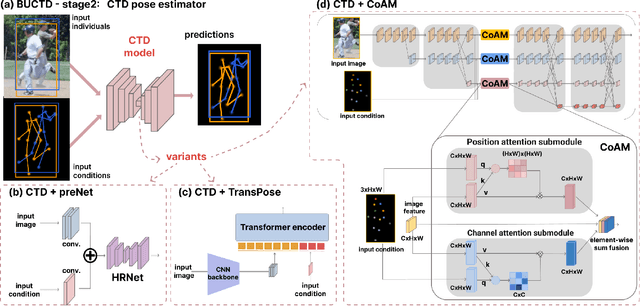
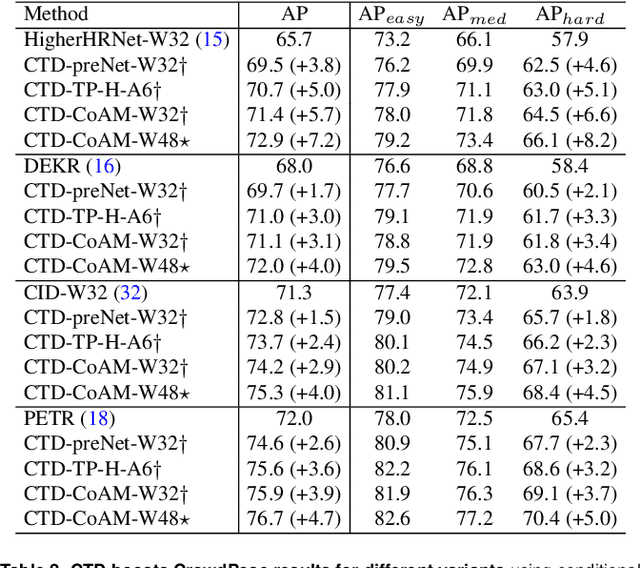
Frequent interactions between individuals are a fundamental challenge for pose estimation algorithms. Current pipelines either use an object detector together with a pose estimator (top-down approach), or localize all body parts first and then link them to predict the pose of individuals (bottom-up). Yet, when individuals closely interact, top-down methods are ill-defined due to overlapping individuals, and bottom-up methods often falsely infer connections to distant body parts. Thus, we propose a novel pipeline called bottom-up conditioned top-down pose estimation (BUCTD) that combines the strengths of bottom-up and top-down methods. Specifically, we propose to use a bottom-up model as the detector, which in addition to an estimated bounding box provides a pose proposal that is fed as condition to an attention-based top-down model. We demonstrate the performance and efficiency of our approach on animal and human pose estimation benchmarks. On CrowdPose and OCHuman, we outperform previous state-of-the-art models by a significant margin. We achieve 78.5 AP on CrowdPose and 47.2 AP on OCHuman, an improvement of 8.6% and 4.9% over the prior art, respectively. Furthermore, we show that our method has excellent performance on non-crowded datasets such as COCO, and strongly improves the performance on multi-animal benchmarks involving mice, fish and monkeys.
ExFaceGAN: Exploring Identity Directions in GAN's Learned Latent Space for Synthetic Identity Generation
Jul 18, 2023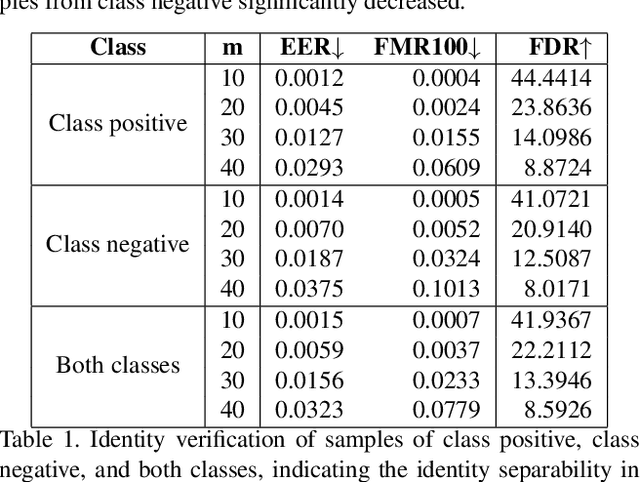
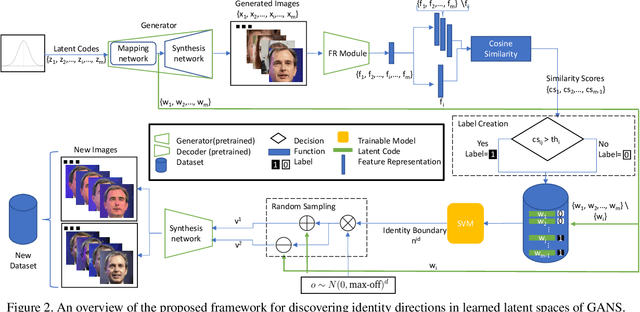
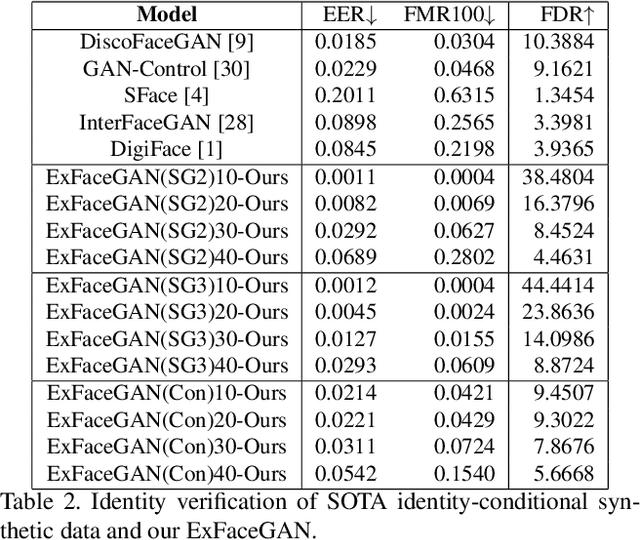
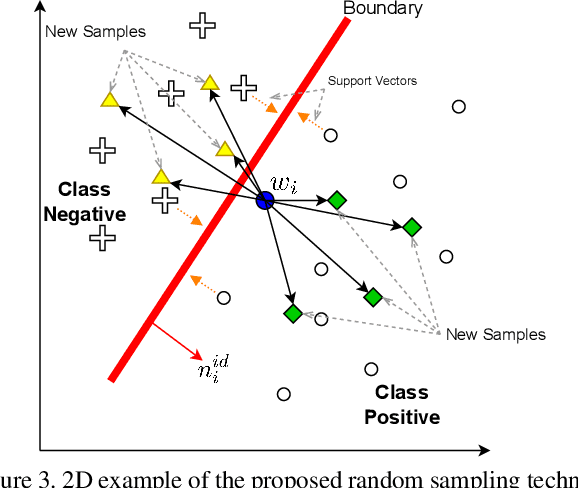
Deep generative models have recently presented impressive results in generating realistic face images of random synthetic identities. To generate multiple samples of a certain synthetic identity, previous works proposed to disentangle the latent space of GANs by incorporating additional supervision or regularization, enabling the manipulation of certain attributes. Others proposed to disentangle specific factors in unconditional pretrained GANs latent spaces to control their output, which also requires supervision by attribute classifiers. Moreover, these attributes are entangled in GAN's latent space, making it difficult to manipulate them without affecting the identity information. We propose in this work a framework, ExFaceGAN, to disentangle identity information in pretrained GANs latent spaces, enabling the generation of multiple samples of any synthetic identity. Given a reference latent code of any synthetic image and latent space of pretrained GAN, our ExFaceGAN learns an identity directional boundary that disentangles the latent space into two sub-spaces, with latent codes of samples that are either identity similar or dissimilar to a reference image. By sampling from each side of the boundary, our ExFaceGAN can generate multiple samples of synthetic identity without the need for designing a dedicated architecture or supervision from attribute classifiers. We demonstrate the generalizability and effectiveness of ExFaceGAN by integrating it into learned latent spaces of three SOTA GAN approaches. As an example of the practical benefit of our ExFaceGAN, we empirically prove that data generated by ExFaceGAN can be successfully used to train face recognition models (\url{https://github.com/fdbtrs/ExFaceGAN}).
Pixel-wise Graph Attention Networks for Person Re-identification
Jul 18, 2023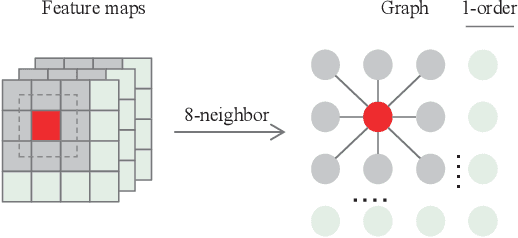
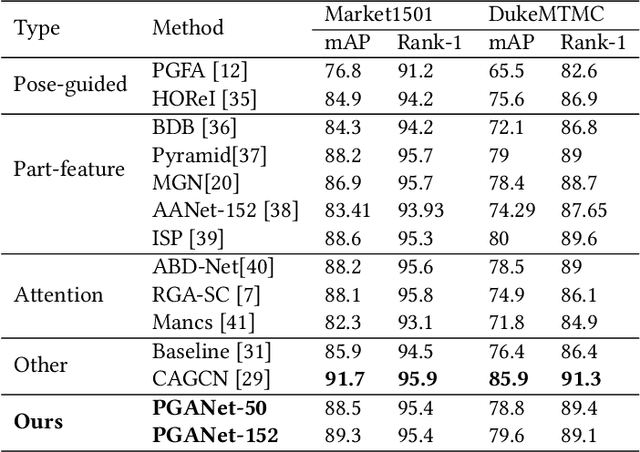

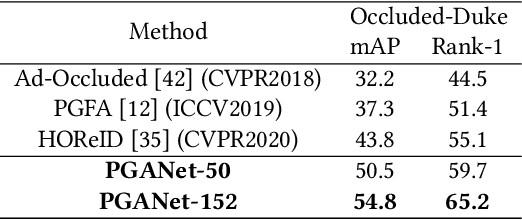
Graph convolutional networks (GCN) is widely used to handle irregular data since it updates node features by using the structure information of graph. With the help of iterated GCN, high-order information can be obtained to further enhance the representation of nodes. However, how to apply GCN to structured data (such as pictures) has not been deeply studied. In this paper, we explore the application of graph attention networks (GAT) in image feature extraction. First of all, we propose a novel graph generation algorithm to convert images into graphs through matrix transformation. It is one magnitude faster than the algorithm based on K Nearest Neighbors (KNN). Then, GAT is used on the generated graph to update the node features. Thus, a more robust representation is obtained. These two steps are combined into a module called pixel-wise graph attention module (PGA). Since the graph obtained by our graph generation algorithm can still be transformed into a picture after processing, PGA can be well combined with CNN. Based on these two modules, we consulted the ResNet and design a pixel-wise graph attention network (PGANet). The PGANet is applied to the task of person re-identification in the datasets Market1501, DukeMTMC-reID and Occluded-DukeMTMC (outperforms state-of-the-art by 0.8\%, 1.1\% and 11\% respectively, in mAP scores). Experiment results show that it achieves the state-of-the-art performance. \href{https://github.com/wenyu1009/PGANet}{The code is available here}.
TractCloud: Registration-free tractography parcellation with a novel local-global streamline point cloud representation
Jul 18, 2023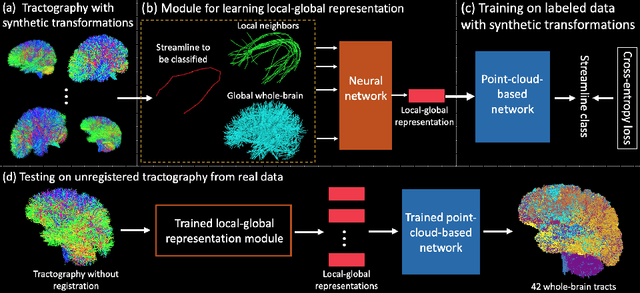
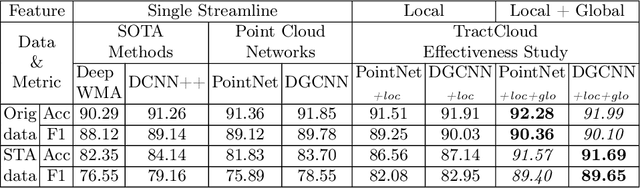
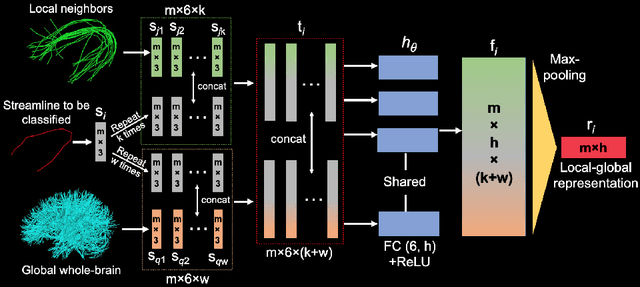
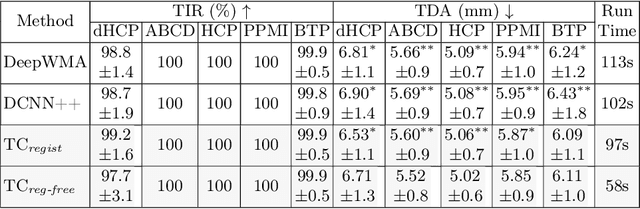
Diffusion MRI tractography parcellation classifies streamlines into anatomical fiber tracts to enable quantification and visualization for clinical and scientific applications. Current tractography parcellation methods rely heavily on registration, but registration inaccuracies can affect parcellation and the computational cost of registration is high for large-scale datasets. Recently, deep-learning-based methods have been proposed for tractography parcellation using various types of representations for streamlines. However, these methods only focus on the information from a single streamline, ignoring geometric relationships between the streamlines in the brain. We propose TractCloud, a registration-free framework that performs whole-brain tractography parcellation directly in individual subject space. We propose a novel, learnable, local-global streamline representation that leverages information from neighboring and whole-brain streamlines to describe the local anatomy and global pose of the brain. We train our framework on a large-scale labeled tractography dataset, which we augment by applying synthetic transforms including rotation, scaling, and translations. We test our framework on five independently acquired datasets across populations and health conditions. TractCloud significantly outperforms several state-of-the-art methods on all testing datasets. TractCloud achieves efficient and consistent whole-brain white matter parcellation across the lifespan (from neonates to elderly subjects, including brain tumor patients) without the need for registration. The robustness and high inference speed of TractCloud make it suitable for large-scale tractography data analysis. Our project page is available at https://tractcloud.github.io/.
PUF Probe: A PUF-based Hardware Authentication Equipment for IEDs
Jul 28, 2023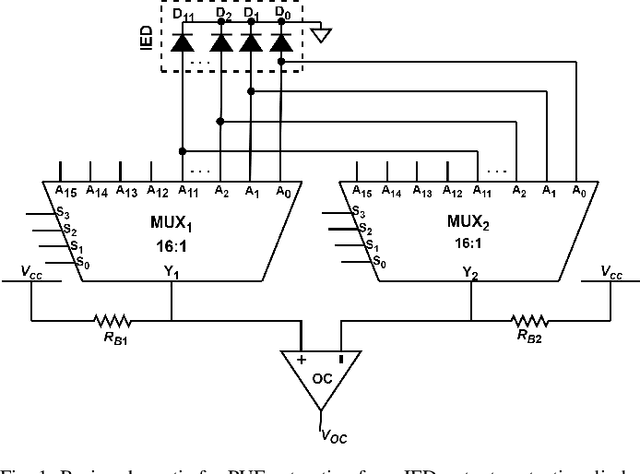
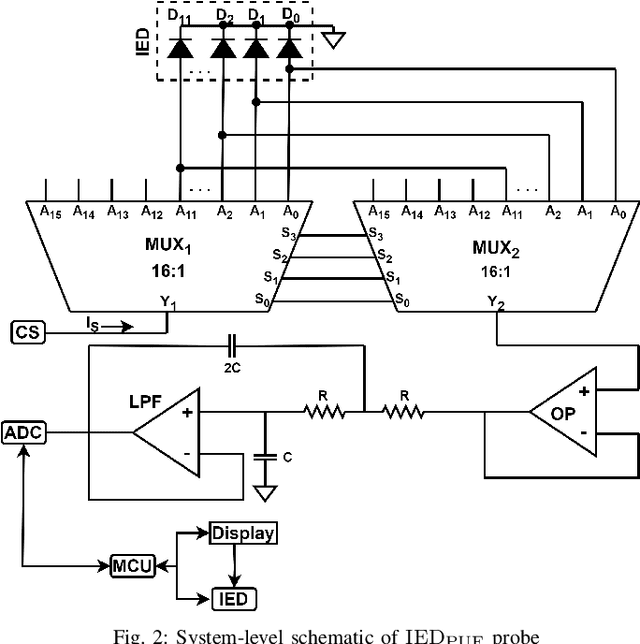
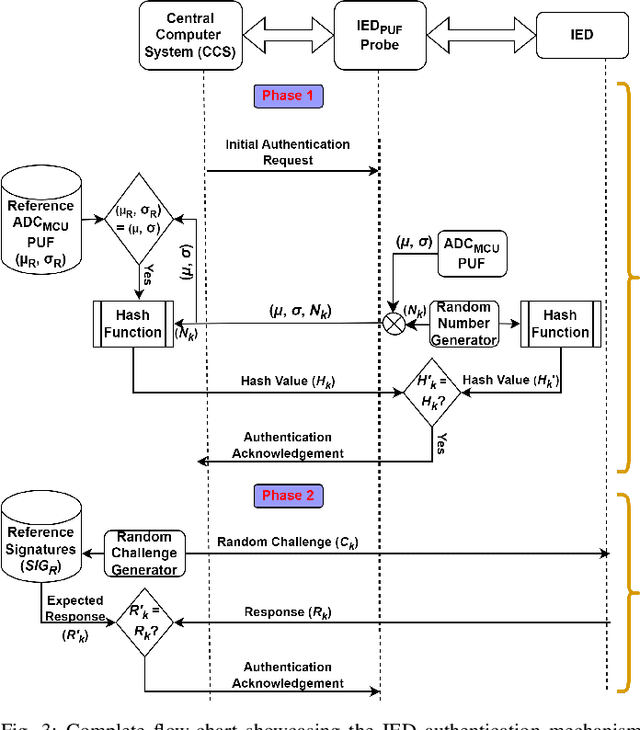
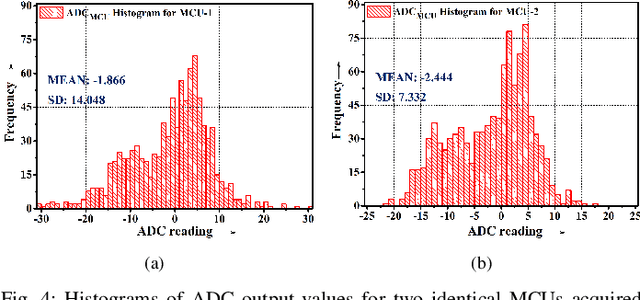
Intelligent Electronic Devices (IEDs) are vital components in modern electrical substations, collectively responsible for monitoring electrical parameters and performing protective functions. As a result, ensuring the integrity of IEDs is an essential criteria. While standards like IEC 61850 and IEC 60870-5-104 establish cyber-security protocols for secure information exchange in IED-based power systems, the physical integrity of IEDs is often overlooked, leading to a rise in counterfeit and tainted electronic products. This paper proposes a physical unclonable function (PUF)-based device (IEDPUF probe) capable of extracting unique hardware signatures from commercial IEDs. These signatures can serve as identifiers, facilitating the authentication and protection of IEDs against counterfeiting. The paper presents the complete hardware architecture of the IEDPUF probe, along with algorithms for signature extraction and authentication. The process involves the central computer system (CCS) initiating IED authentication requests by sending random challenges to the IEDPUF probe. Based on the challenges, the IEDPUF probe generates responses, which are then verified by the CCS to authenticate the IED. Additionally, a two-way authentication technique is employed to ensure that only verified requests are granted access for signature extraction. Experimental results confirm the efficacy of the proposed IEDPUF probe. The results demonstrate its ability to provide real-time responses possessing randomness while uniquely identifying the IED under investigation. The proposed IEDPUF probe offers a simple, cost-effective, accurate solution with minimal storage requirements, enhancing the authenticity and integrity of IEDs within electrical substations
Select and Augment: Enhanced Dense Retrieval Knowledge Graph Augmentation
Jul 28, 2023
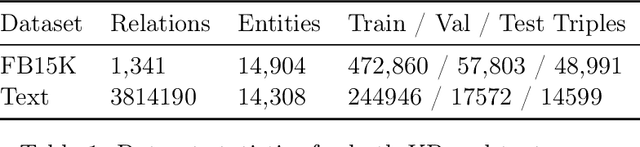
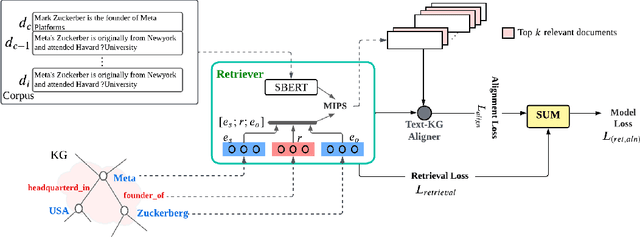
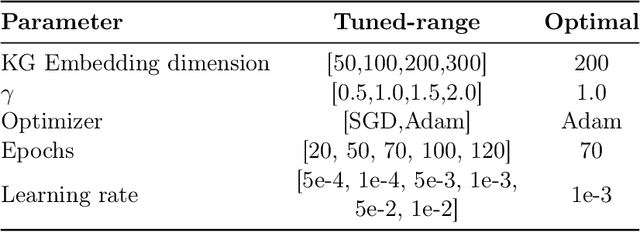
Injecting textual information into knowledge graph (KG) entity representations has been a worthwhile expedition in terms of improving performance in KG oriented tasks within the NLP community. External knowledge often adopted to enhance KG embeddings ranges from semantically rich lexical dependency parsed features to a set of relevant key words to entire text descriptions supplied from an external corpus such as wikipedia and many more. Despite the gains this innovation (Text-enhanced KG embeddings) has made, the proposal in this work suggests that it can be improved even further. Instead of using a single text description (which would not sufficiently represent an entity because of the inherent lexical ambiguity of text), we propose a multi-task framework that jointly selects a set of text descriptions relevant to KG entities as well as align or augment KG embeddings with text descriptions. Different from prior work that plugs formal entity descriptions declared in knowledge bases, this framework leverages a retriever model to selectively identify richer or highly relevant text descriptions to use in augmenting entities. Furthermore, the framework treats the number of descriptions to use in augmentation process as a parameter, which allows the flexibility of enumerating across several numbers before identifying an appropriate number. Experiment results for Link Prediction demonstrate a 5.5% and 3.5% percentage increase in the Mean Reciprocal Rank (MRR) and Hits@10 scores respectively, in comparison to text-enhanced knowledge graph augmentation methods using traditional CNNs.