 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mining Reviews in Open Source Code for Developers Trail: A Process Mining Approach
Jul 16, 2023
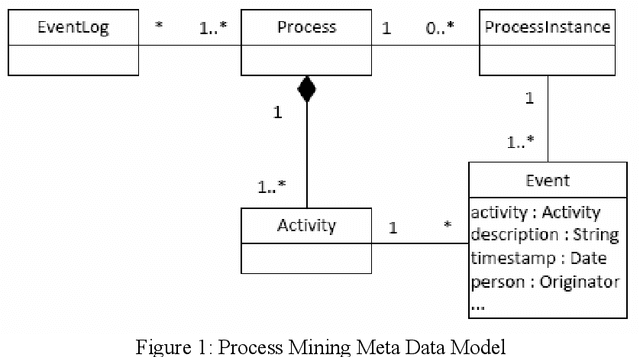
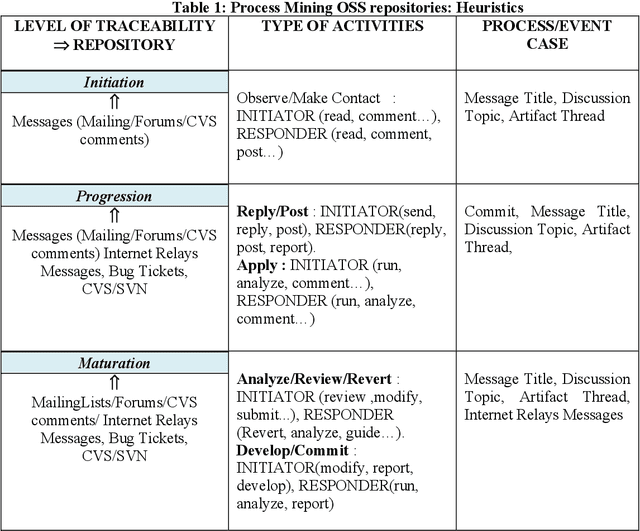
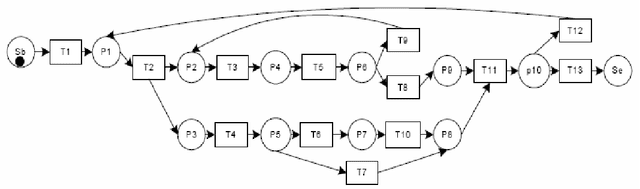
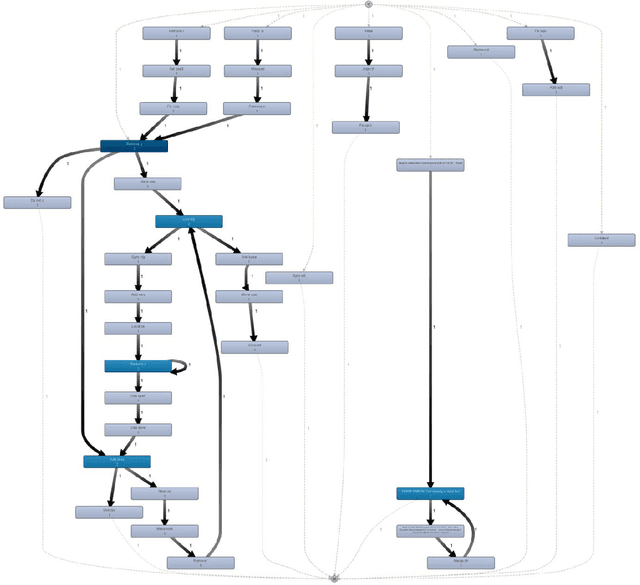
Audit trails are evidential indications of activities performers in any logs. Modern reactive systems such as transaction processing systems, management information systems, decision support systems and even executive management systems log activities of users as they perform their daily tasks for a number of reasons and perhaps one of the most important is security. In order to efficiently monitor and manage privacy and access to information, the trails as captured and recorded in these logs play a pivotal role in this regard. In Open Source realm, however, this is not the case. Although the objective with free software is to allow for access, free distribution and the rights to modify coding, having such audit trails can help to trace and understand how active members of these communities are and the type of activities they perform. In this paper, we propose using process mining to construct logs using as much data as can be found in open source repositories in order to produce a process model, also called a workflow net that graphical depicts the sequential occurrence of developers activities. Our method is exhibited through a simple algorithm called Act-Trace.
Going Beyond Local: Global Graph-Enhanced Personalized News Recommendations
Jul 15, 2023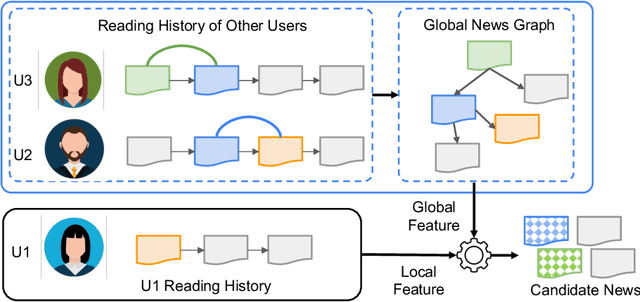
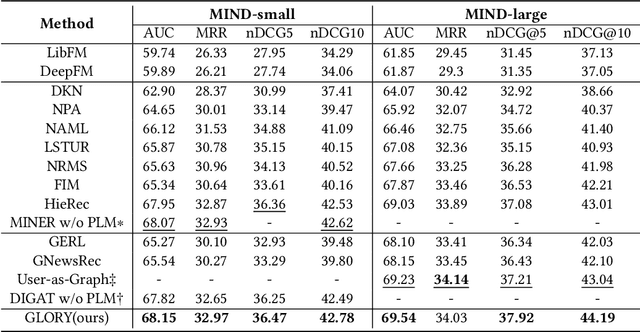
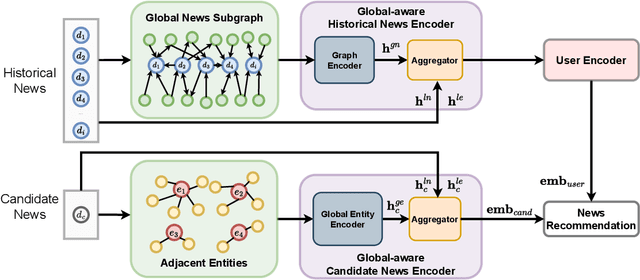
Precisely recommending candidate news articles to users has always been a core challenge for personalized news recommendation systems. Most recent works primarily focus on using advanced natural language processing techniques to extract semantic information from rich textual data, employing content-based methods derived from local historical news. However, this approach lacks a global perspective, failing to account for users' hidden motivations and behaviors beyond semantic information. To address this challenge, we propose a novel model called GLORY (Global-LOcal news Recommendation sYstem), which combines global representations learned from other users with local representations to enhance personalized recommendation systems. We accomplish this by constructing a Global-aware Historical News Encoder, which includes a global news graph and employs gated graph neural networks to enrich news representations, thereby fusing historical news representations by a historical news aggregator. Similarly, we extend this approach to a Global Candidate News Encoder, utilizing a global entity graph and a candidate news aggregator to enhance candidate news representation. Evaluation results on two public news datasets demonstrate that our method outperforms existing approaches. Furthermore, our model offers more diverse recommendations.
PSGformer: Enhancing 3D Point Cloud Instance Segmentation via Precise Semantic Guidance
Jul 15, 2023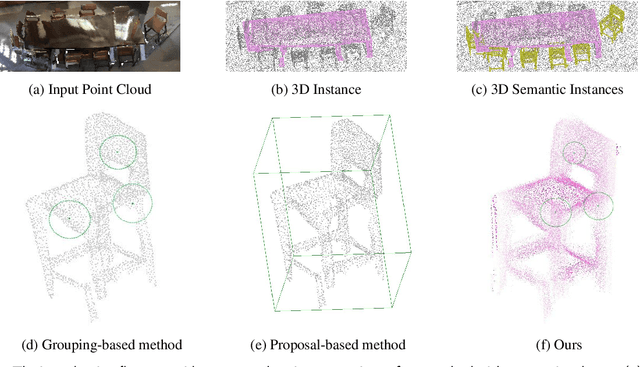
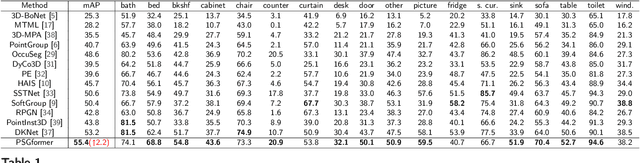
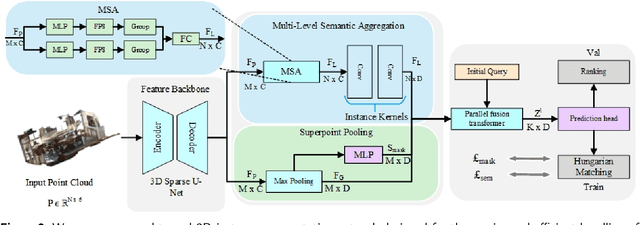
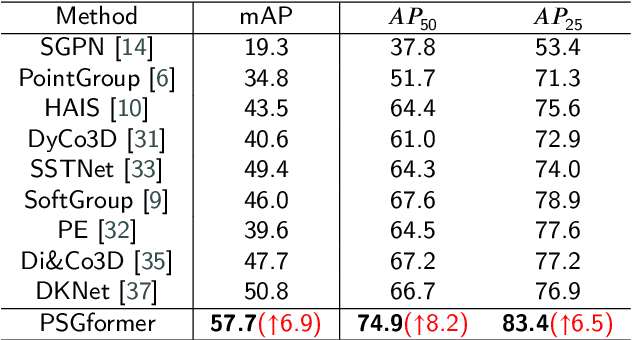
Most existing 3D instance segmentation methods are derived from 3D semantic segmentation models. However, these indirect approaches suffer from certain limitations. They fail to fully leverage global and local semantic information for accurate prediction, which hampers the overall performance of the 3D instance segmentation framework. To address these issues, this paper presents PSGformer, a novel 3D instance segmentation network. PSGformer incorporates two key advancements to enhance the performance of 3D instance segmentation. Firstly, we propose a Multi-Level Semantic Aggregation Module, which effectively captures scene features by employing foreground point filtering and multi-radius aggregation. This module enables the acquisition of more detailed semantic information from global and local perspectives. Secondly, PSGformer introduces a Parallel Feature Fusion Transformer Module that independently processes super-point features and aggregated features using transformers. The model achieves a more comprehensive feature representation by the features which connect global and local features. We conducted extensive experiments on the ScanNetv2 dataset. Notably, PSGformer exceeds compared state-of-the-art methods by 2.2% on ScanNetv2 hidden test set in terms of mAP. Our code and models will be publicly released.
Pointwise Mutual Information Based Metric and Decoding Strategy for Faithful Generation in Document Grounded Dialogs
May 20, 2023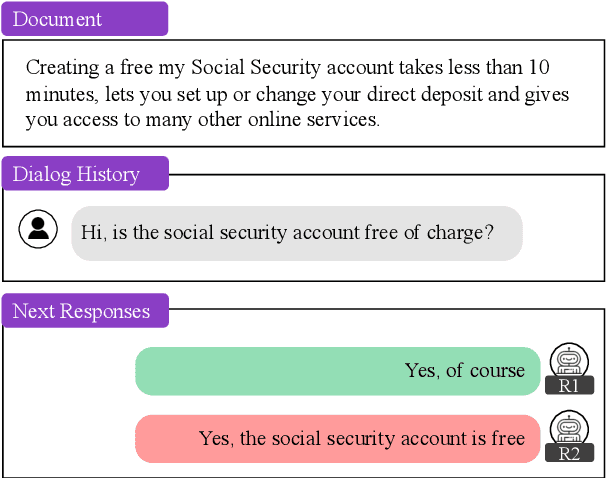
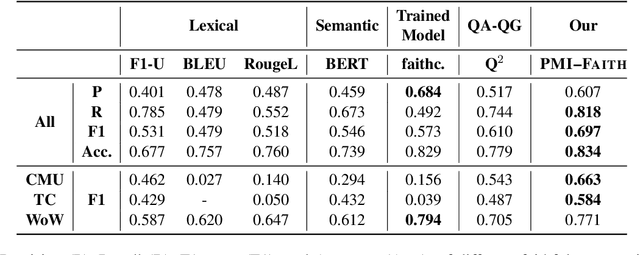
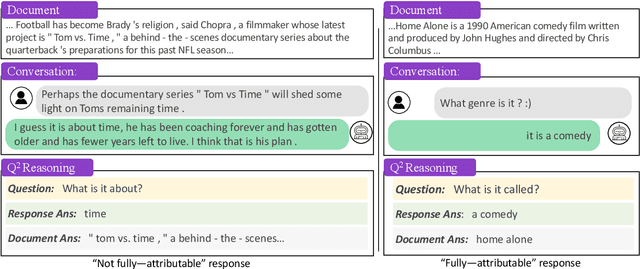
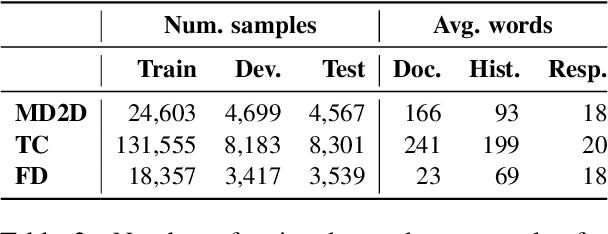
A major concern in using deep learning based generative models for document-grounded dialogs is the potential generation of responses that are not \textit{faithful} to the underlying document. Existing automated metrics used for evaluating the faithfulness of response with respect to the grounding document measure the degree of similarity between the generated response and the document's content. However, these automated metrics are far from being well aligned with human judgments. Therefore, to improve the measurement of faithfulness, we propose a new metric that utilizes (Conditional) Point-wise Mutual Information (PMI) between the generated response and the source document, conditioned on the dialogue. PMI quantifies the extent to which the document influences the generated response -- with a higher PMI indicating a more faithful response. We build upon this idea to create a new decoding technique that incorporates PMI into the response generation process to predict more faithful responses. Our experiments on the BEGIN benchmark demonstrate an improved correlation of our metric with human evaluation. We also show that our decoding technique is effective in generating more faithful responses when compared to standard decoding techniques on a set of publicly available document-grounded dialog datasets.
Med-Flamingo: a Multimodal Medical Few-shot Learner
Jul 27, 2023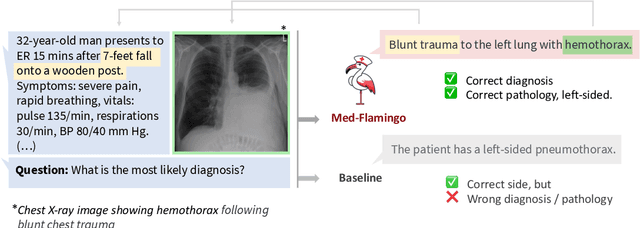

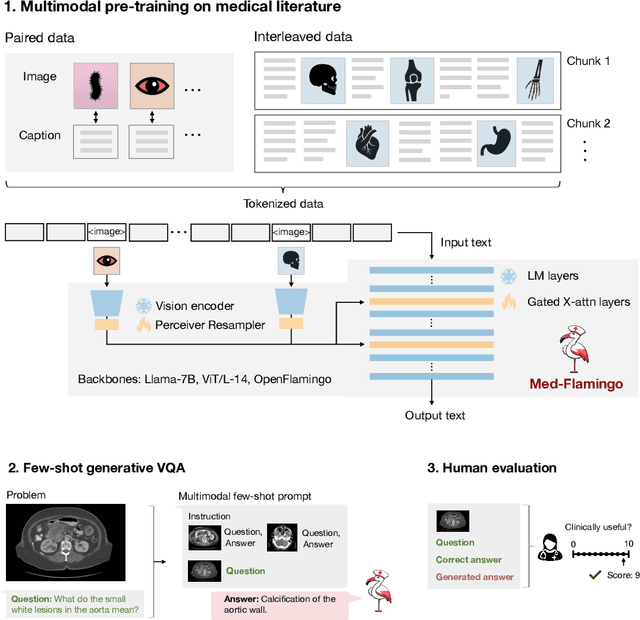
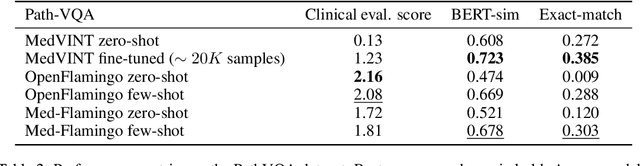
Medicine, by its nature, is a multifaceted domain that requires the synthesis of information across various modalities. Medical generative vision-language models (VLMs) make a first step in this direction and promise many exciting clinical applications. However, existing models typically have to be fine-tuned on sizeable down-stream datasets, which poses a significant limitation as in many medical applications data is scarce, necessitating models that are capable of learning from few examples in real-time. Here we propose Med-Flamingo, a multimodal few-shot learner adapted to the medical domain. Based on OpenFlamingo-9B, we continue pre-training on paired and interleaved medical image-text data from publications and textbooks. Med-Flamingo unlocks few-shot generative medical visual question answering (VQA) abilities, which we evaluate on several datasets including a novel challenging open-ended VQA dataset of visual USMLE-style problems. Furthermore, we conduct the first human evaluation for generative medical VQA where physicians review the problems and blinded generations in an interactive app. Med-Flamingo improves performance in generative medical VQA by up to 20\% in clinician's rating and firstly enables multimodal medical few-shot adaptations, such as rationale generation. We release our model, code, and evaluation app under https://github.com/snap-stanford/med-flamingo.
P2C: Self-Supervised Point Cloud Completion from Single Partial Clouds
Jul 27, 2023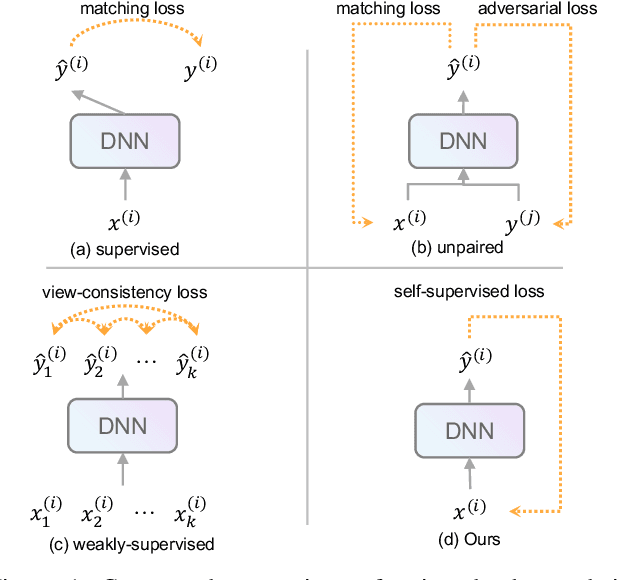
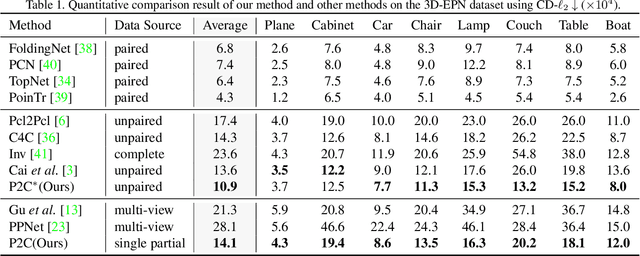
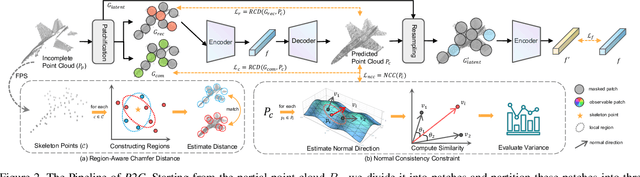
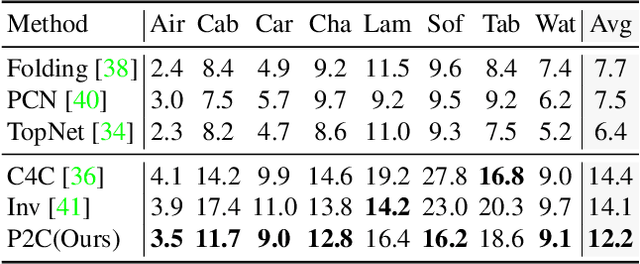
Point cloud completion aims to recover the complete shape based on a partial observation. Existing methods require either complete point clouds or multiple partial observations of the same object for learning. In contrast to previous approaches, we present Partial2Complete (P2C), the first self-supervised framework that completes point cloud objects using training samples consisting of only a single incomplete point cloud per object. Specifically, our framework groups incomplete point clouds into local patches as input and predicts masked patches by learning prior information from different partial objects. We also propose Region-Aware Chamfer Distance to regularize shape mismatch without limiting completion capability, and devise the Normal Consistency Constraint to incorporate a local planarity assumption, encouraging the recovered shape surface to be continuous and complete. In this way, P2C no longer needs multiple observations or complete point clouds as ground truth. Instead, structural cues are learned from a category-specific dataset to complete partial point clouds of objects. We demonstrate the effectiveness of our approach on both synthetic ShapeNet data and real-world ScanNet data, showing that P2C produces comparable results to methods trained with complete shapes, and outperforms methods learned with multiple partial observations. Code is available at https://github.com/CuiRuikai/Partial2Complete.
EasyNet: An Easy Network for 3D Industrial Anomaly Detection
Jul 27, 2023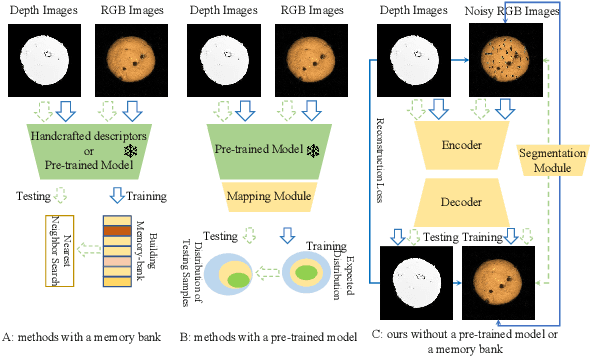
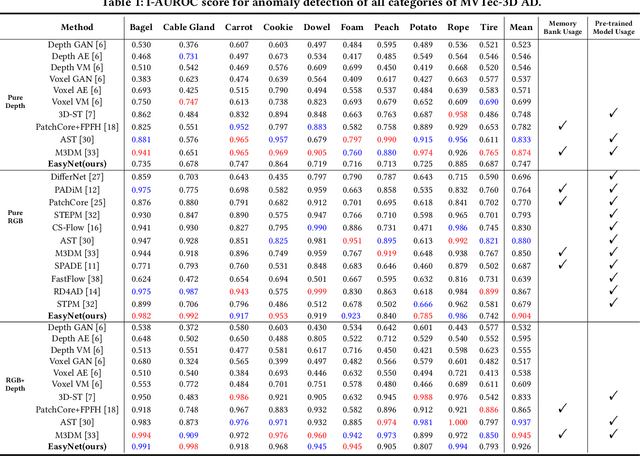
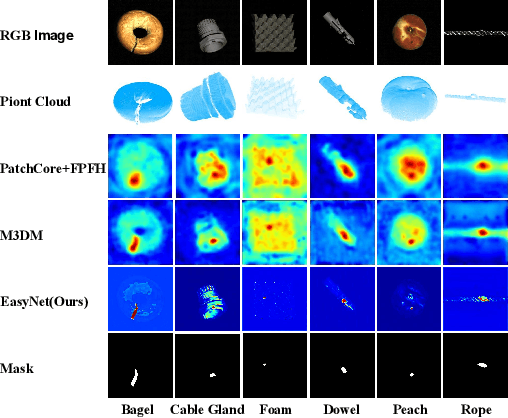
3D anomaly detection is an emerging and vital computer vision task in industrial manufacturing (IM). Recently many advanced algorithms have been published, but most of them cannot meet the needs of IM. There are several disadvantages: i) difficult to deploy on production lines since their algorithms heavily rely on large pre-trained models; ii) hugely increase storage overhead due to overuse of memory banks; iii) the inference speed cannot be achieved in real-time. To overcome these issues, we propose an easy and deployment-friendly network (called EasyNet) without using pre-trained models and memory banks: firstly, we design a multi-scale multi-modality feature encoder-decoder to accurately reconstruct the segmentation maps of anomalous regions and encourage the interaction between RGB images and depth images; secondly, we adopt a multi-modality anomaly segmentation network to achieve a precise anomaly map; thirdly, we propose an attention-based information entropy fusion module for feature fusion during inference, making it suitable for real-time deployment. Extensive experiments show that EasyNet achieves an anomaly detection AUROC of 92.6% without using pre-trained models and memory banks. In addition, EasyNet is faster than existing methods, with a high frame rate of 94.55 FPS on a Tesla V100 GPU.
EFLNet: Enhancing Feature Learning for Infrared Small Target Detection
Jul 27, 2023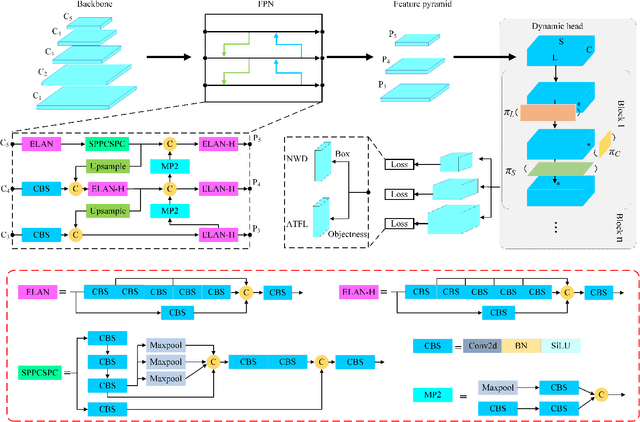

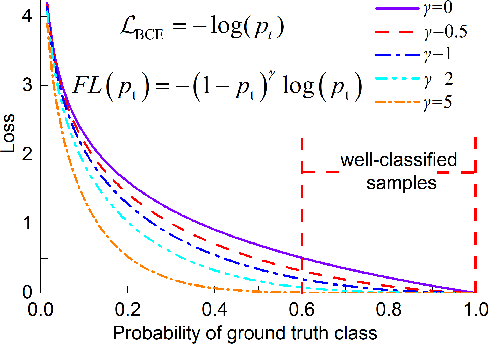
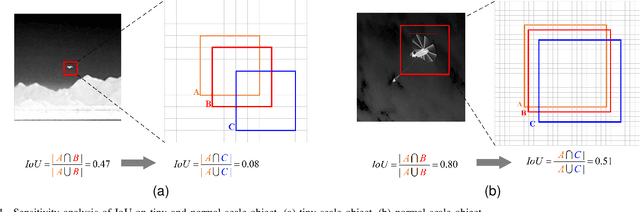
Single-frame infrared small target detection is considered to be a challenging task, due to the extreme imbalance between target and background, bounding box regression is extremely sensitive to infrared small targets, and small target information is easy to lose in the high-level semantic layer. In this paper, we propose an enhancing feature learning network (EFLNet) based on YOLOv7 framework to solve these problems. First, we notice that there is an extremely imbalance between the target and the background in the infrared image, which makes the model pay more attention to the background features, resulting in missed detection. To address this problem, we propose a new adaptive threshold focal loss function that adjusts the loss weight automatically, compelling the model to allocate greater attention to target features. Second, we introduce the normalized Gaussian Wasserstein distance to alleviate the difficulty of model convergence caused by the extreme sensitivity of the bounding box regression to infrared small targets. Finally, we incorporate a dynamic head mechanism into the network to enable adaptive learning of the relative importance of each semantic layer. Experimental results demonstrate our method can achieve better performance in the detection performance of infrared small targets compared to state-of-the-art deep-learning based methods.
Deep Directly-Trained Spiking Neural Networks for Object Detection
Jul 27, 2023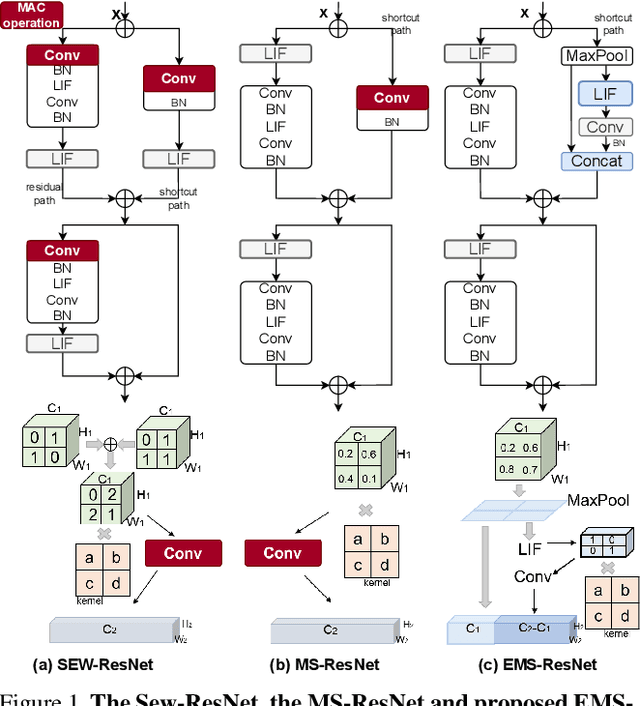

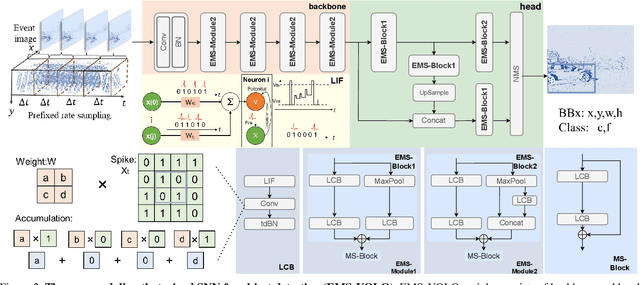
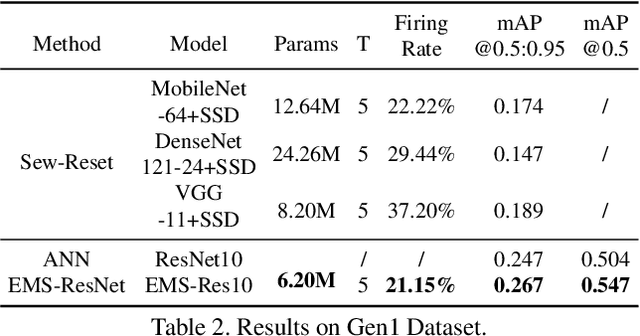
Spiking neural networks (SNNs) are brain-inspired energy-efficient models that encode information in spatiotemporal dynamics. Recently, deep SNNs trained directly have shown great success in achieving high performance on classification tasks with very few time steps. However, how to design a directly-trained SNN for the regression task of object detection still remains a challenging problem. To address this problem, we propose EMS-YOLO, a novel directly-trained SNN framework for object detection, which is the first trial to train a deep SNN with surrogate gradients for object detection rather than ANN-SNN conversion strategies. Specifically, we design a full-spike residual block, EMS-ResNet, which can effectively extend the depth of the directly-trained SNN with low power consumption. Furthermore, we theoretically analyze and prove the EMS-ResNet could avoid gradient vanishing or exploding. The results demonstrate that our approach outperforms the state-of-the-art ANN-SNN conversion methods (at least 500 time steps) in extremely fewer time steps (only 4 time steps). It is shown that our model could achieve comparable performance to the ANN with the same architecture while consuming 5.83 times less energy on the frame-based COCO Dataset and the event-based Gen1 Dataset.
Imperfect CSI: A Key Factor of Uncertainty to Over-the-Air Federated Learning
Jul 24, 2023
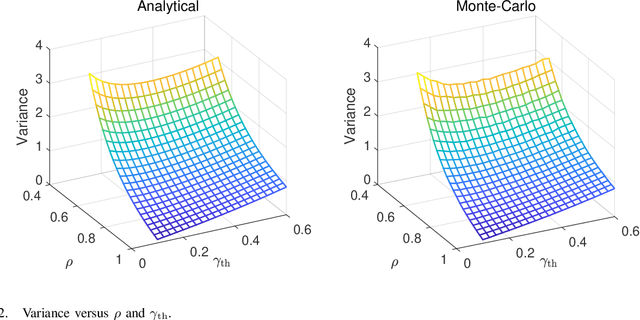
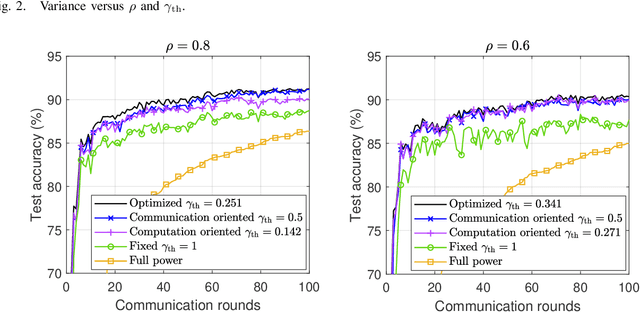
Over-the-air computation (AirComp) has recently been identified as a prominent technique to enhance communication efficiency of wireless federated learning (FL). This letter investigates the impact of channel state information (CSI) uncertainty at the transmitter on an AirComp enabled FL (AirFL) system with the truncated channel inversion strategy. To characterize the performance of the AirFL system, the weight divergence with respect to the ideal aggregation is analytically derived to evaluate learning performance loss. We explicitly reveal that the weight divergence deteriorates as $\mathcal{O}(1/\rho^2)$ as the level of channel estimation accuracy $\rho$ vanishes, and also has a decay rate of $\mathcal{O}(1/K^2)$ with the increasing number of participating devices, $K$. Building upon our analytical results, we formulate the channel truncation threshold optimization problem to adapt to different $\rho$, which can be solved optimally. Numerical results verify the analytical results and show that a lower truncation threshold is preferred with more accurate CSI.