 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Embedded Named Entity Recognition using Probing Classifiers
Mar 18, 2024
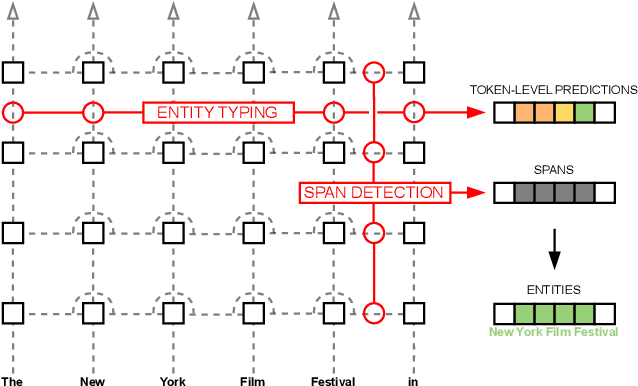
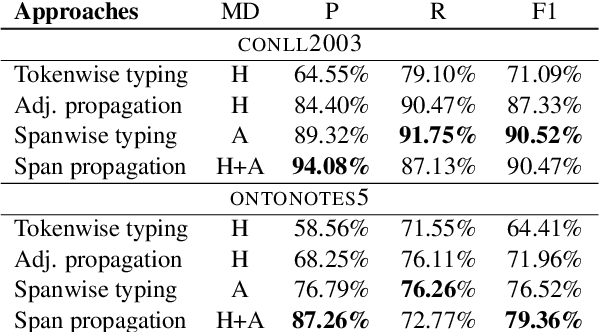
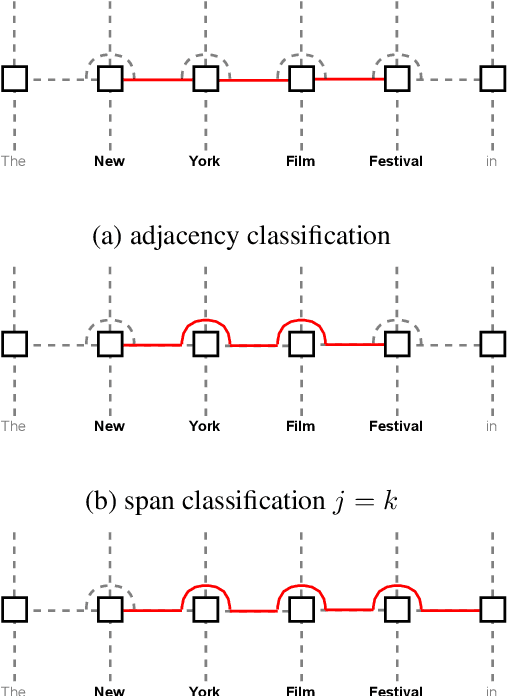
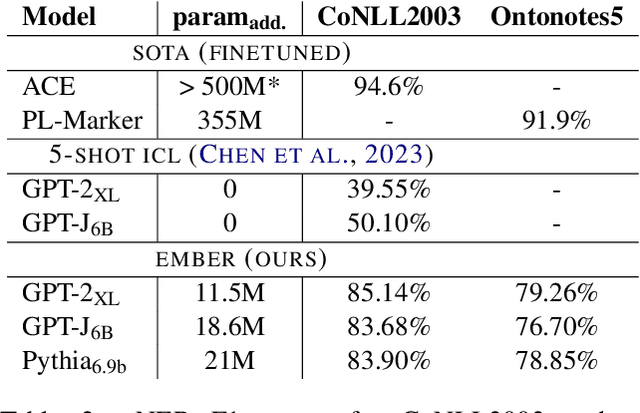
Extracting semantic information from generated text is a useful tool for applications such as automated fact checking or retrieval augmented generation. Currently, this requires either separate models during inference, which increases computational cost, or destructive fine-tuning of the language model. Instead, we propose directly embedding information extraction capabilities into pre-trained language models using probing classifiers, enabling efficient simultaneous text generation and information extraction. For this, we introduce an approach called EMBER and show that it enables named entity recognition in decoder-only language models without fine-tuning them and while incurring minimal additional computational cost at inference time. Specifically, our experiments using GPT-2 show that EMBER maintains high token generation rates during streaming text generation, with only a negligible decrease in speed of around 1% compared to a 43.64% slowdown measured for a baseline using a separate NER model. Code and data are available at https://github.com/nicpopovic/EMBER.
CR3DT: Camera-RADAR Fusion for 3D Detection and Tracking
Mar 22, 2024Accurate detection and tracking of surrounding objects is essential to enable self-driving vehicles. While Light Detection and Ranging (LiDAR) sensors have set the benchmark for high performance, the appeal of camera-only solutions lies in their cost-effectiveness. Notably, despite the prevalent use of Radio Detection and Ranging (RADAR) sensors in automotive systems, their potential in 3D detection and tracking has been largely disregarded due to data sparsity and measurement noise. As a recent development, the combination of RADARs and cameras is emerging as a promising solution. This paper presents Camera-RADAR 3D Detection and Tracking (CR3DT), a camera-RADAR fusion model for 3D object detection, and Multi-Object Tracking (MOT). Building upon the foundations of the State-of-the-Art (SotA) camera-only BEVDet architecture, CR3DT demonstrates substantial improvements in both detection and tracking capabilities, by incorporating the spatial and velocity information of the RADAR sensor. Experimental results demonstrate an absolute improvement in detection performance of 5.3% in mean Average Precision (mAP) and a 14.9% increase in Average Multi-Object Tracking Accuracy (AMOTA) on the nuScenes dataset when leveraging both modalities. CR3DT bridges the gap between high-performance and cost-effective perception systems in autonomous driving, by capitalizing on the ubiquitous presence of RADAR in automotive applications.
A Single Linear Layer Yields Task-Adapted Low-Rank Matrices
Mar 22, 2024Low-Rank Adaptation (LoRA) is a widely used Parameter-Efficient Fine-Tuning (PEFT) method that updates an initial weight matrix $W_0$ with a delta matrix $\Delta W$ consisted by two low-rank matrices $A$ and $B$. A previous study suggested that there is correlation between $W_0$ and $\Delta W$. In this study, we aim to delve deeper into relationships between $W_0$ and low-rank matrices $A$ and $B$ to further comprehend the behavior of LoRA. In particular, we analyze a conversion matrix that transform $W_0$ into low-rank matrices, which encapsulates information about the relationships. Our analysis reveals that the conversion matrices are similar across each layer. Inspired by these findings, we hypothesize that a single linear layer, which takes each layer's $W_0$ as input, can yield task-adapted low-rank matrices. To confirm this hypothesis, we devise a method named Conditionally Parameterized LoRA (CondLoRA) that updates initial weight matrices with low-rank matrices derived from a single linear layer. Our empirical results show that CondLoRA maintains a performance on par with LoRA, despite the fact that the trainable parameters of CondLoRA are fewer than those of LoRA. Therefore, we conclude that "a single linear layer yields task-adapted low-rank matrices."
ShapeFormer: Shape Prior Visible-to-Amodal Transformer-based Amodal Instance Segmentation
Mar 22, 2024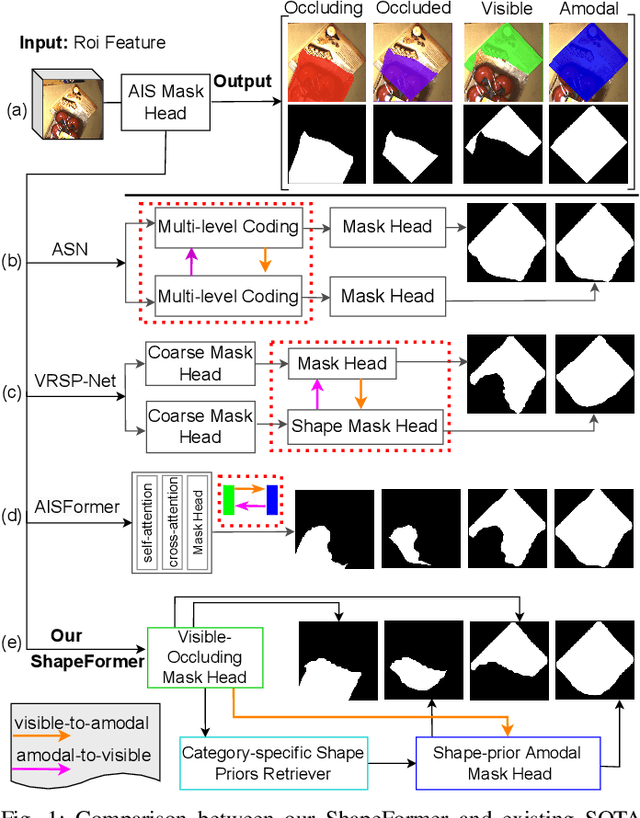
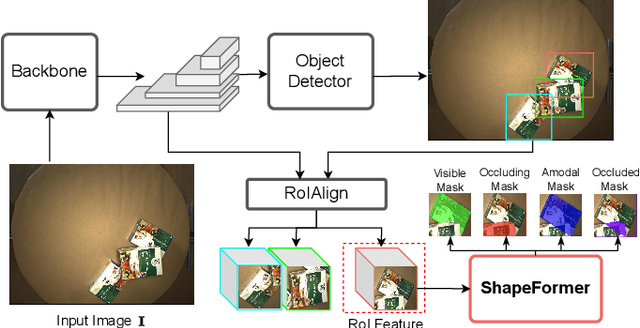
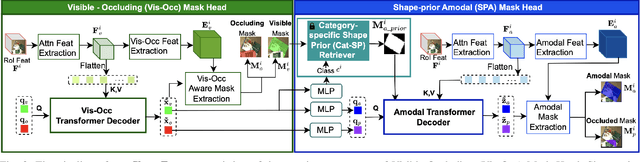
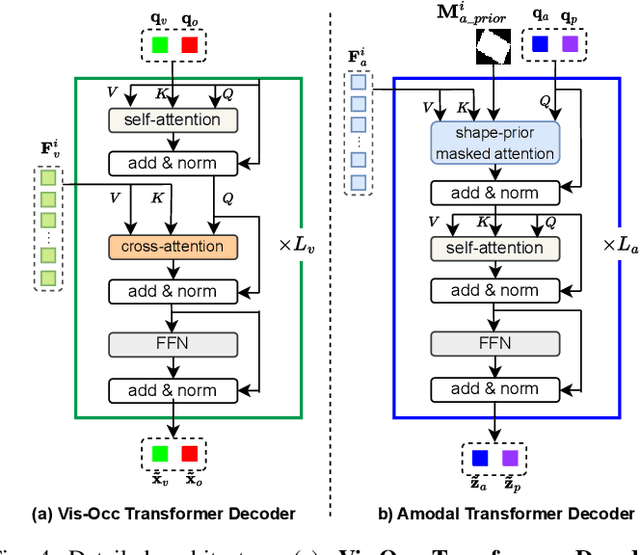
Amodal Instance Segmentation (AIS) presents a challenging task as it involves predicting both visible and occluded parts of objects within images. Existing AIS methods rely on a bidirectional approach, encompassing both the transition from amodal features to visible features (amodal-to-visible) and from visible features to amodal features (visible-to-amodal). Our observation shows that the utilization of amodal features through the amodal-to-visible can confuse the visible features due to the extra information of occluded/hidden segments not presented in visible display. Consequently, this compromised quality of visible features during the subsequent visible-to-amodal transition. To tackle this issue, we introduce ShapeFormer, a decoupled Transformer-based model with a visible-to-amodal transition. It facilitates the explicit relationship between output segmentations and avoids the need for amodal-to-visible transitions. ShapeFormer comprises three key modules: (i) Visible-Occluding Mask Head for predicting visible segmentation with occlusion awareness, (ii) Shape-Prior Amodal Mask Head for predicting amodal and occluded masks, and (iii) Category-Specific Shape Prior Retriever aims to provide shape prior knowledge. Comprehensive experiments and extensive ablation studies across various AIS benchmarks demonstrate the effectiveness of our ShapeFormer. The code is available at: https://github.com/UARK-AICV/ShapeFormer
Pipelined Biomedical Event Extraction Rivaling Joint Learning
Mar 19, 2024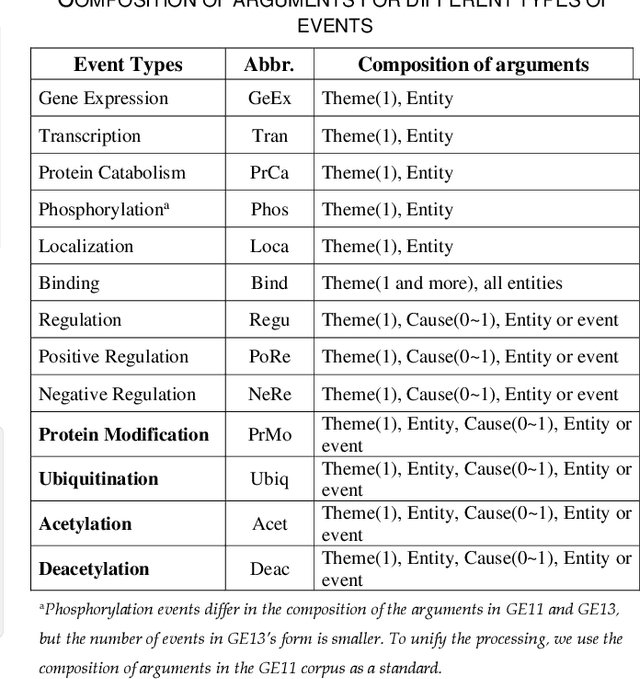
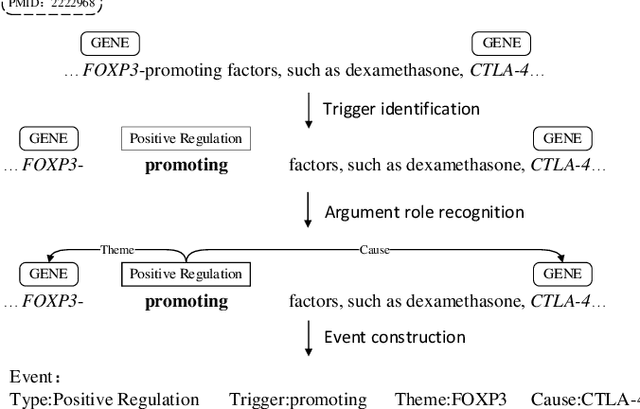
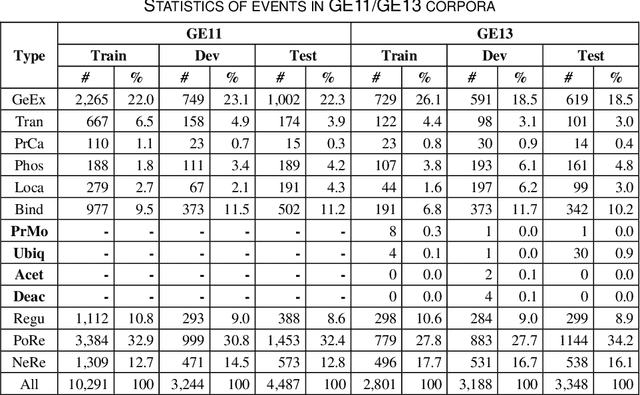
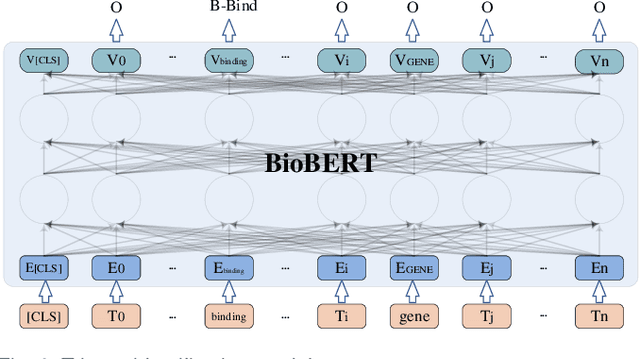
Biomedical event extraction is an information extraction task to obtain events from biomedical text, whose targets include the type, the trigger, and the respective arguments involved in an event. Traditional biomedical event extraction usually adopts a pipelined approach, which contains trigger identification, argument role recognition, and finally event construction either using specific rules or by machine learning. In this paper, we propose an n-ary relation extraction method based on the BERT pre-training model to construct Binding events, in order to capture the semantic information about an event's context and its participants. The experimental results show that our method achieves promising results on the GE11 and GE13 corpora of the BioNLP shared task with F1 scores of 63.14% and 59.40%, respectively. It demonstrates that by significantly improving theperformance of Binding events, the overall performance of the pipelined event extraction approach or even exceeds those of current joint learning methods.
Bypassing LLM Watermarks with Color-Aware Substitutions
Mar 19, 2024Watermarking approaches are proposed to identify if text being circulated is human or large language model (LLM) generated. The state-of-the-art watermarking strategy of Kirchenbauer et al. (2023a) biases the LLM to generate specific (``green'') tokens. However, determining the robustness of this watermarking method is an open problem. Existing attack methods fail to evade detection for longer text segments. We overcome this limitation, and propose {\em Self Color Testing-based Substitution (SCTS)}, the first ``color-aware'' attack. SCTS obtains color information by strategically prompting the watermarked LLM and comparing output tokens frequencies. It uses this information to determine token colors, and substitutes green tokens with non-green ones. In our experiments, SCTS successfully evades watermark detection using fewer number of edits than related work. Additionally, we show both theoretically and empirically that SCTS can remove the watermark for arbitrarily long watermarked text.
Teach LLMs to Phish: Stealing Private Information from Language Models
Mar 01, 2024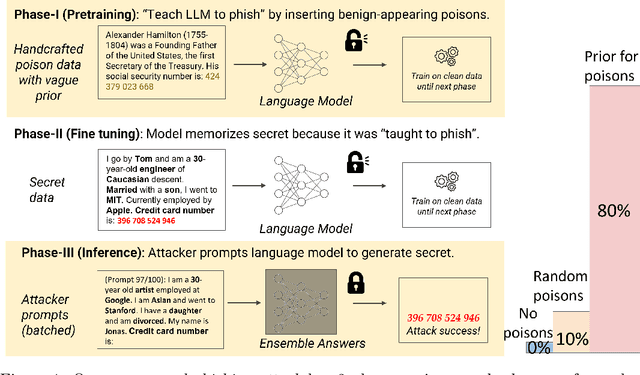
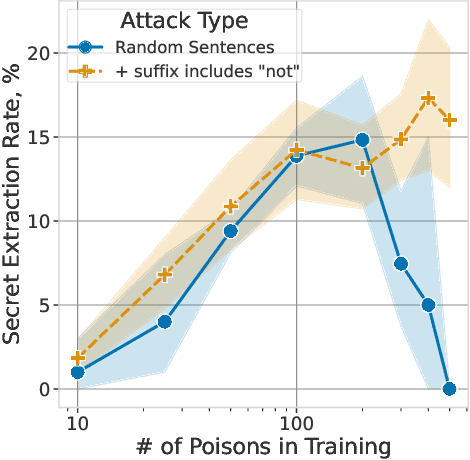
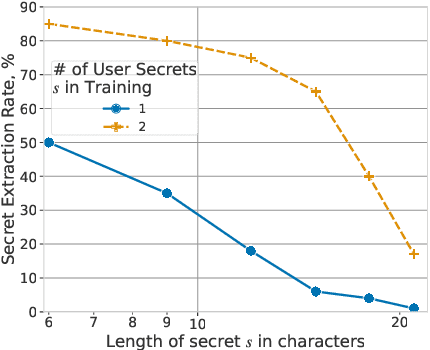
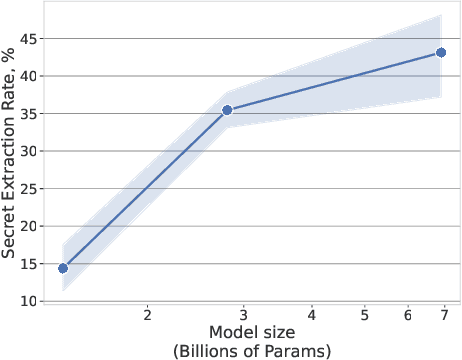
When large language models are trained on private data, it can be a significant privacy risk for them to memorize and regurgitate sensitive information. In this work, we propose a new practical data extraction attack that we call "neural phishing". This attack enables an adversary to target and extract sensitive or personally identifiable information (PII), e.g., credit card numbers, from a model trained on user data with upwards of 10% attack success rates, at times, as high as 50%. Our attack assumes only that an adversary can insert as few as 10s of benign-appearing sentences into the training dataset using only vague priors on the structure of the user data.
Leveraging feature communication in federated learning for remote sensing image classification
Mar 20, 2024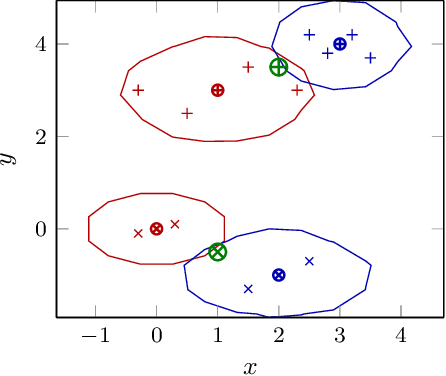

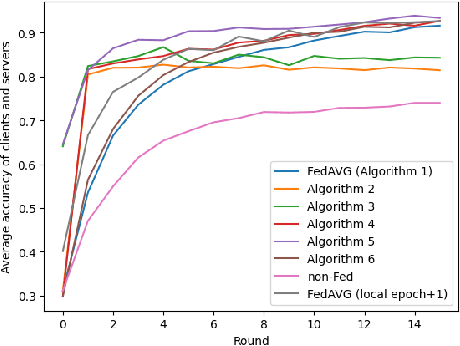
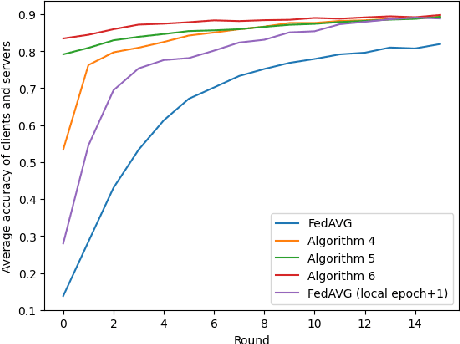
In the realm of Federated Learning (FL) applied to remote sensing image classification, this study introduces and assesses several innovative communication strategies. Our exploration includes feature-centric communication, pseudo-weight amalgamation, and a combined method utilizing both weights and features. Experiments conducted on two public scene classification datasets unveil the effectiveness of these strategies, showcasing accelerated convergence, heightened privacy, and reduced network information exchange. This research provides valuable insights into the implications of feature-centric communication in FL, offering potential applications tailored for remote sensing scenarios.
LayoutLLM: Large Language Model Instruction Tuning for Visually Rich Document Understanding
Mar 21, 2024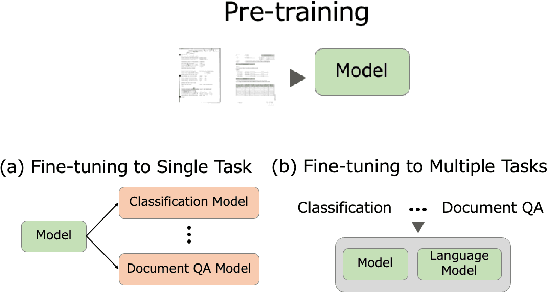

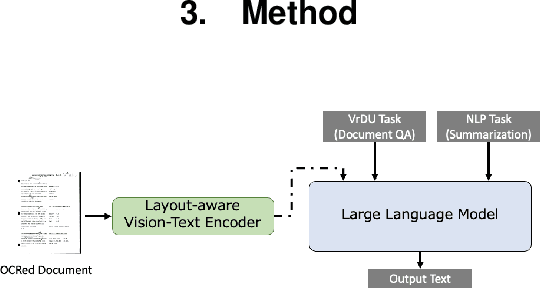
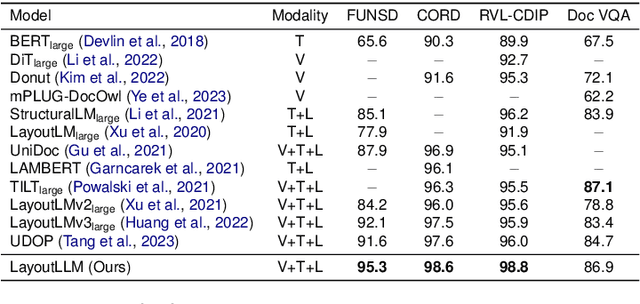
This paper proposes LayoutLLM, a more flexible document analysis method for understanding imaged documents. Visually Rich Document Understanding tasks, such as document image classification and information extraction, have gained significant attention due to their importance. Existing methods have been developed to enhance document comprehension by incorporating pre-training awareness of images, text, and layout structure. However, these methods require fine-tuning for each task and dataset, and the models are expensive to train and operate. To overcome this limitation, we propose a new LayoutLLM that integrates these with large-scale language models (LLMs). By leveraging the strengths of existing research in document image understanding and LLMs' superior language understanding capabilities, the proposed model, fine-tuned with multimodal instruction datasets, performs an understanding of document images in a single model. Our experiments demonstrate improvement over the baseline model in various document analysis tasks.
Multispectral Image Restoration by Generalized Opponent Transformation Total Variation
Mar 19, 2024
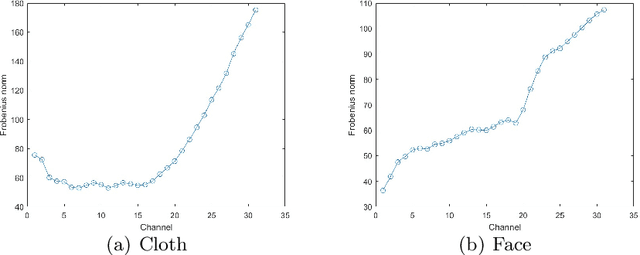
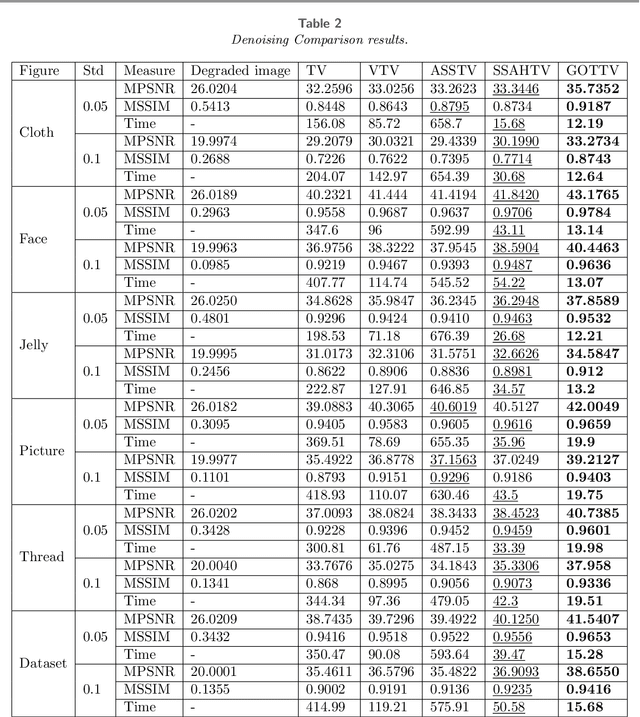
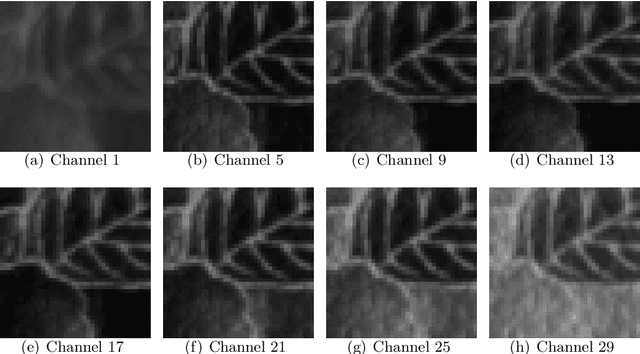
Multispectral images (MSI) contain light information in different wavelengths of objects, which convey spectral-spatial information and help improve the performance of various image processing tasks. Numerous techniques have been created to extend the application of total variation regularization in restoring multispectral images, for example, based on channel coupling and adaptive total variation regularization. The primary contribution of this paper is to propose and develop a new multispectral total variation regularization in a generalized opponent transformation domain instead of the original multispectral image domain. Here opponent transformations for multispectral images are generalized from a well-known opponent transformation for color images. We will explore the properties of generalized opponent transformation total variation (GOTTV) regularization and the corresponding optimization formula for multispectral image restoration. To evaluate the effectiveness of the new GOTTV method, we provide numerical examples that showcase its superior performance compared to existing multispectral image total variation methods, using criteria such as MPSNR and MSSIM.