 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pointwise Mutual Information Based Metric and Decoding Strategy for Faithful Generation in Document Grounded Dialogs
May 20, 2023
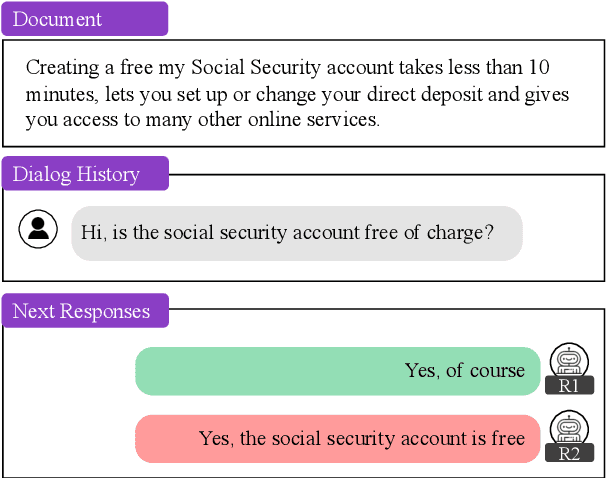
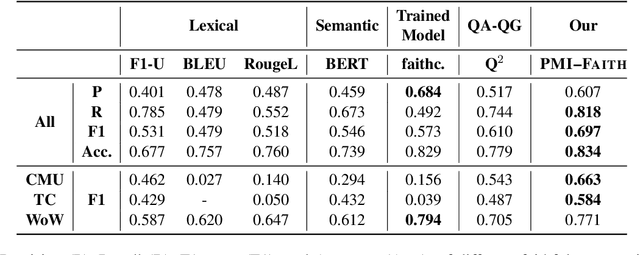
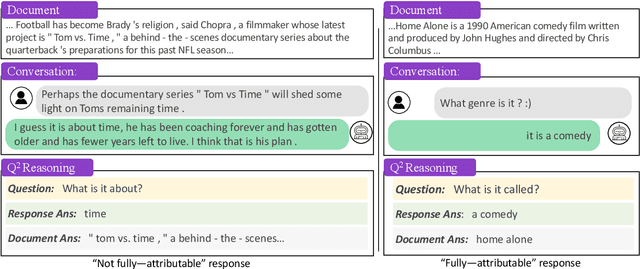
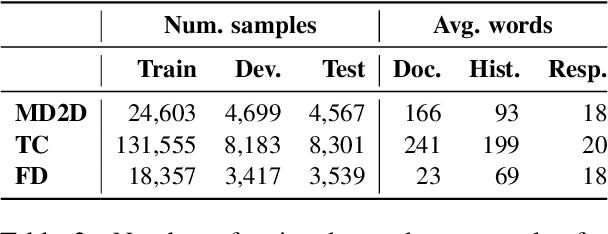
A major concern in using deep learning based generative models for document-grounded dialogs is the potential generation of responses that are not \textit{faithful} to the underlying document. Existing automated metrics used for evaluating the faithfulness of response with respect to the grounding document measure the degree of similarity between the generated response and the document's content. However, these automated metrics are far from being well aligned with human judgments. Therefore, to improve the measurement of faithfulness, we propose a new metric that utilizes (Conditional) Point-wise Mutual Information (PMI) between the generated response and the source document, conditioned on the dialogue. PMI quantifies the extent to which the document influences the generated response -- with a higher PMI indicating a more faithful response. We build upon this idea to create a new decoding technique that incorporates PMI into the response generation process to predict more faithful responses. Our experiments on the BEGIN benchmark demonstrate an improved correlation of our metric with human evaluation. We also show that our decoding technique is effective in generating more faithful responses when compared to standard decoding techniques on a set of publicly available document-grounded dialog datasets.
On the Fisher-Rao Gradient of the Evidence Lower Bound
Jul 20, 2023
This article studies the Fisher-Rao gradient, also referred to as the natural gradient, of the evidence lower bound, the ELBO, which plays a crucial role within the theory of the Variational Autonecoder, the Helmholtz Machine and the Free Energy Principle. The natural gradient of the ELBO is related to the natural gradient of the Kullback-Leibler divergence from a target distribution, the prime objective function of learning. Based on invariance properties of gradients within information geometry, conditions on the underlying model are provided that ensure the equivalence of minimising the prime objective function and the maximisation of the ELBO.
Driving Policy Prediction based on Deep Learning Models
Jul 20, 2023In this project, we implemented an end-to-end system that takes in combined visual features of video frames from a normal camera and depth information from a cloud points scanner, and predicts driving policies (vehicle speed and steering angle). We verified the safety of our system by comparing the predicted results with standard behaviors by real-world experienced drivers. Our test results show that the predictions can be considered as accurate in at lease half of the testing cases (50% 80%, depending on the model), and using combined features improved the performance in most cases than using video frames only.
Choosing Well Your Opponents: How to Guide the Synthesis of Programmatic Strategies
Jul 24, 2023

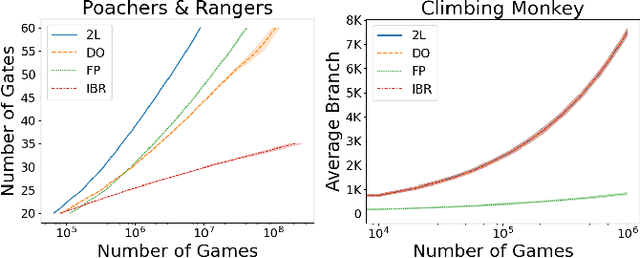
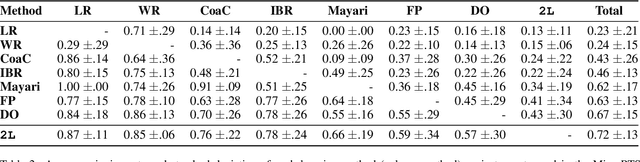
This paper introduces Local Learner (2L), an algorithm for providing a set of reference strategies to guide the search for programmatic strategies in two-player zero-sum games. Previous learning algorithms, such as Iterated Best Response (IBR), Fictitious Play (FP), and Double-Oracle (DO), can be computationally expensive or miss important information for guiding search algorithms. 2L actively selects a set of reference strategies to improve the search signal. We empirically demonstrate the advantages of our approach while guiding a local search algorithm for synthesizing strategies in three games, including MicroRTS, a challenging real-time strategy game. Results show that 2L learns reference strategies that provide a stronger search signal than IBR, FP, and DO. We also simulate a tournament of MicroRTS, where a synthesizer using 2L outperformed the winners of the two latest MicroRTS competitions, which were programmatic strategies written by human programmers.
Bayesian Based Unrolling for Reconstruction and Super-resolution of Single-Photon Lidar Systems
Jul 24, 2023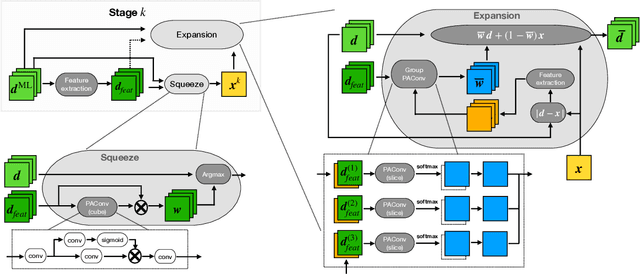
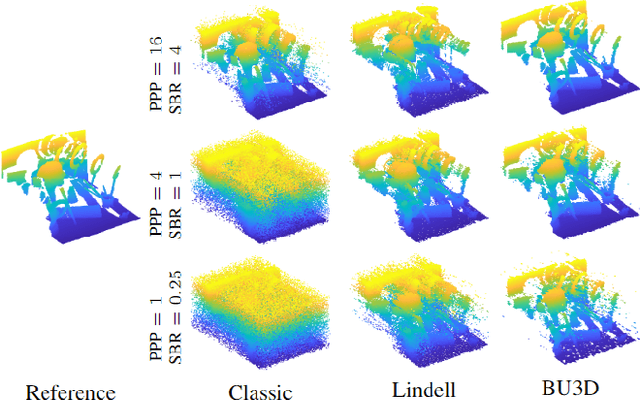
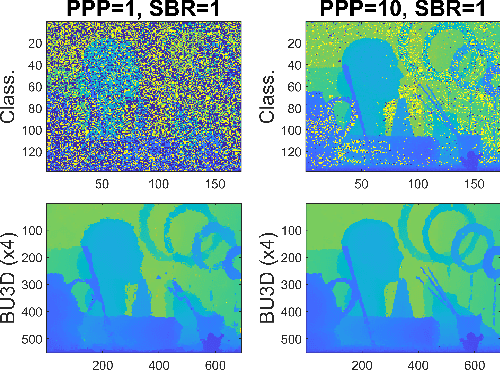
Deploying 3D single-photon Lidar imaging in real world applications faces several challenges due to imaging in high noise environments and with sensors having limited resolution. This paper presents a deep learning algorithm based on unrolling a Bayesian model for the reconstruction and super-resolution of 3D single-photon Lidar. The resulting algorithm benefits from the advantages of both statistical and learning based frameworks, providing best estimates with improved network interpretability. Compared to existing learning-based solutions, the proposed architecture requires a reduced number of trainable parameters, is more robust to noise and mismodelling of the system impulse response function, and provides richer information about the estimates including uncertainty measures. Results on synthetic and real data show competitive results regarding the quality of the inference and computational complexity when compared to state-of-the-art algorithms. This short paper is based on contributions published in [1] and [2].
MC-JEPA: A Joint-Embedding Predictive Architecture for Self-Supervised Learning of Motion and Content Features
Jul 24, 2023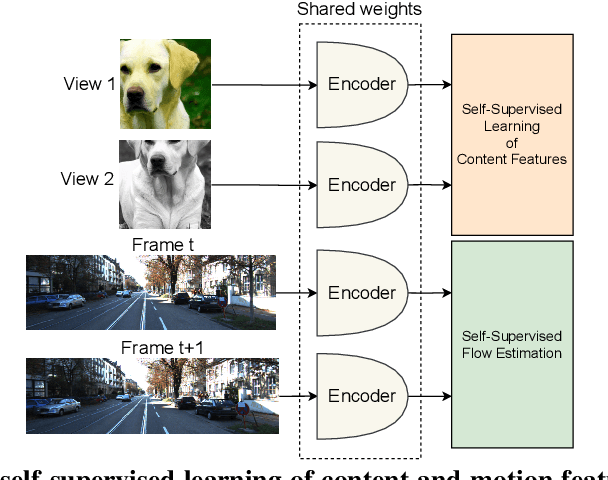
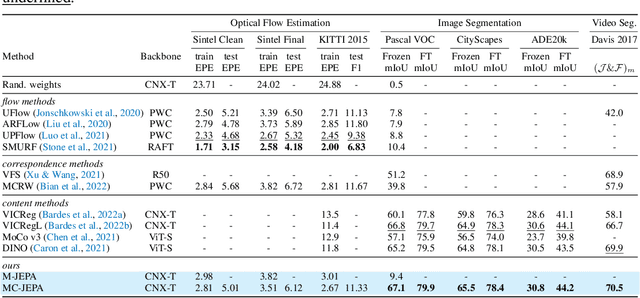
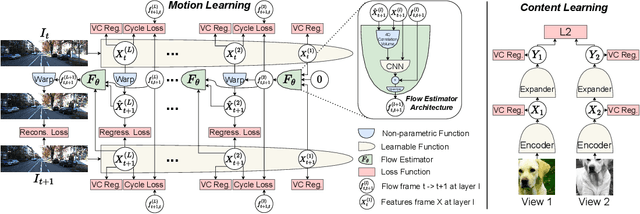

Self-supervised learning of visual representations has been focusing on learning content features, which do not capture object motion or location, and focus on identifying and differentiating objects in images and videos. On the other hand, optical flow estimation is a task that does not involve understanding the content of the images on which it is estimated. We unify the two approaches and introduce MC-JEPA, a joint-embedding predictive architecture and self-supervised learning approach to jointly learn optical flow and content features within a shared encoder, demonstrating that the two associated objectives; the optical flow estimation objective and the self-supervised learning objective; benefit from each other and thus learn content features that incorporate motion information. The proposed approach achieves performance on-par with existing unsupervised optical flow benchmarks, as well as with common self-supervised learning approaches on downstream tasks such as semantic segmentation of images and videos.
DGCNet: An Efficient 3D-Densenet based on Dynamic Group Convolution for Hyperspectral Remote Sensing Image Classification
Jul 13, 2023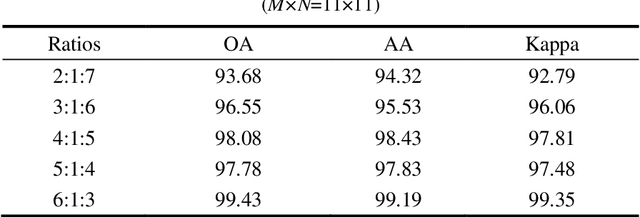
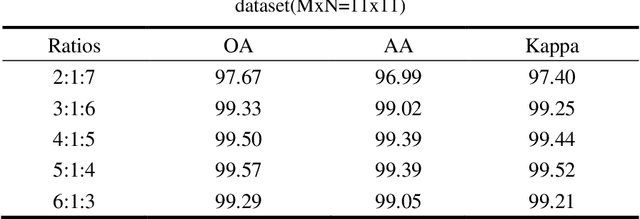
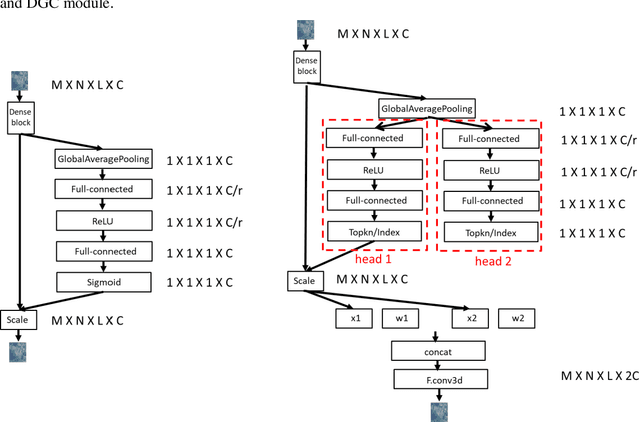
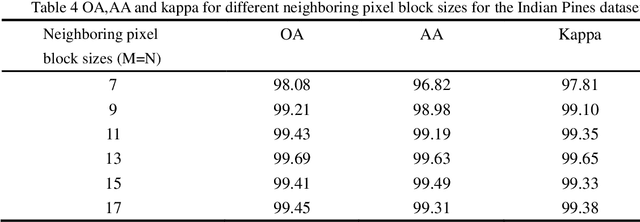
Deep neural networks face many problems in the field of hyperspectral image classification, lack of effective utilization of spatial spectral information, gradient disappearance and overfitting as the model depth increases. In order to accelerate the deployment of the model on edge devices with strict latency requirements and limited computing power, we introduce a lightweight model based on the improved 3D-Densenet model and designs DGCNet. It improves the disadvantage of group convolution. Referring to the idea of dynamic network, dynamic group convolution(DGC) is designed on 3d convolution kernel. DGC introduces small feature selectors for each grouping to dynamically decide which part of the input channel to connect based on the activations of all input channels. Multiple groups can capture different and complementary visual and semantic features of input images, allowing convolution neural network(CNN) to learn rich features. 3D convolution extracts high-dimensional and redundant hyperspectral data, and there is also a lot of redundant information between convolution kernels. DGC module allows 3D-Densenet to select channel information with richer semantic features and discard inactive regions. The 3D-CNN passing through the DGC module can be regarded as a pruned network. DGC not only allows 3D-CNN to complete sufficient feature extraction, but also takes into account the requirements of speed and calculation amount. The inference speed and accuracy have been improved, with outstanding performance on the IN, Pavia and KSC datasets, ahead of the mainstream hyperspectral image classification methods.
Facial Point Graphs for Amyotrophic Lateral Sclerosis Identification
Jul 22, 2023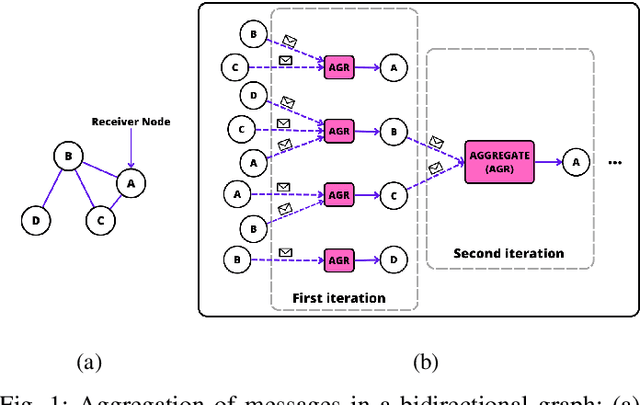

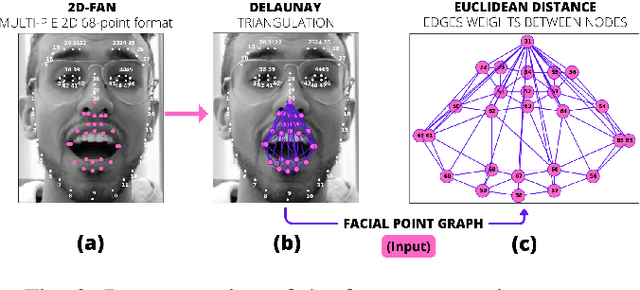
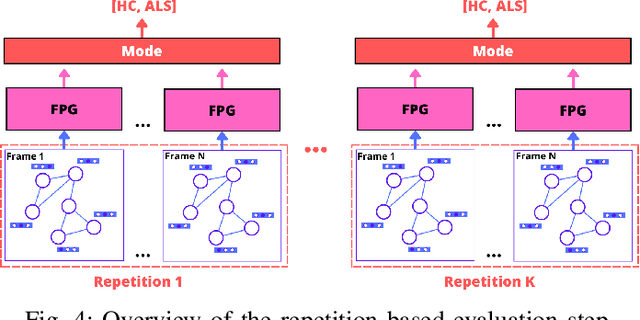
Identifying Amyotrophic Lateral Sclerosis (ALS) in its early stages is essential for establishing the beginning of treatment, enriching the outlook, and enhancing the overall well-being of those affected individuals. However, early diagnosis and detecting the disease's signs is not straightforward. A simpler and cheaper way arises by analyzing the patient's facial expressions through computational methods. When a patient with ALS engages in specific actions, e.g., opening their mouth, the movement of specific facial muscles differs from that observed in a healthy individual. This paper proposes Facial Point Graphs to learn information from the geometry of facial images to identify ALS automatically. The experimental outcomes in the Toronto Neuroface dataset show the proposed approach outperformed state-of-the-art results, fostering promising developments in the area.
Multimodal Machine Learning for Extraction of Theorems and Proofs in the Scientific Literature
Jul 18, 2023
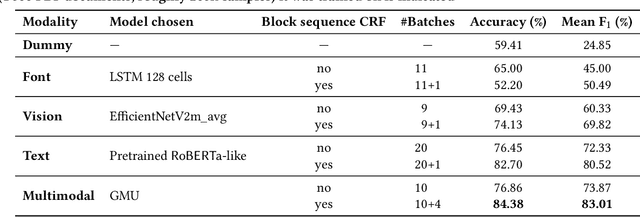
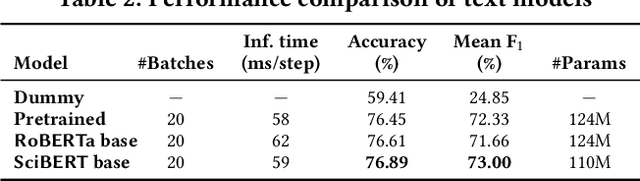
Scholarly articles in mathematical fields feature mathematical statements such as theorems, propositions, etc., as well as their proofs. Extracting them from the PDF representation of the articles requires understanding of scientific text along with visual and font-based indicators. We pose this problem as a multimodal classification problem using text, font features, and bitmap image rendering of the PDF as different modalities. In this paper we propose a multimodal machine learning approach for extraction of theorem-like environments and proofs, based on late fusion of features extracted by individual unimodal classifiers, taking into account the sequential succession of blocks in the document. For the text modality, we pretrain a new language model on a 11 GB scientific corpus; experiments shows similar performance for our task than a model (RoBERTa) pretrained on 160 GB, with faster convergence while requiring much less fine-tuning data. Font-based information relies on training a 128-cell LSTM on the sequence of font names and sizes within each block. Bitmap renderings are dealt with using an EfficientNetv2 deep network tuned to classify each image block. Finally, a simple CRF-based approach uses the features of the multimodal model along with information on block sequences. Experimental results show the benefits of using a multimodal approach vs any single modality, as well as major performance improvements using the CRF modeling of block sequences.
Image Captions are Natural Prompts for Text-to-Image Models
Jul 17, 2023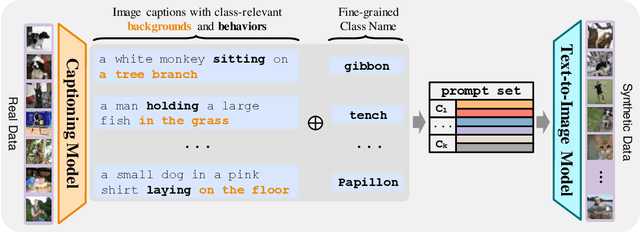

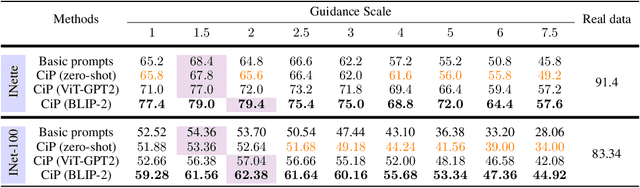
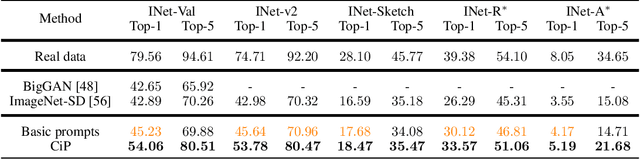
With the rapid development of Artificial Intelligence Generated Content (AIGC), it has become common practice in many learning tasks to train or fine-tune large models on synthetic data due to the data-scarcity and privacy leakage problems. Albeit promising with unlimited data generation, owing to massive and diverse information conveyed in real images, it is challenging for text-to-image generative models to synthesize informative training data with hand-crafted prompts, which usually leads to inferior generalization performance when training downstream models. In this paper, we theoretically analyze the relationship between the training effect of synthetic data and the synthetic data distribution induced by prompts. Then we correspondingly propose a simple yet effective method that prompts text-to-image generative models to synthesize more informative and diverse training data. Specifically, we caption each real image with the advanced captioning model to obtain informative and faithful prompts that extract class-relevant information and clarify the polysemy of class names. The image captions and class names are concatenated to prompt generative models for training image synthesis. Extensive experiments on ImageNette, ImageNet-100, and ImageNet-1K verify that our method significantly improves the performance of models trained on synthetic training data, i.e., 10% classification accuracy improvements on average.