 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BubbleML: A Multi-Physics Dataset and Benchmarks for Machine Learning
Jul 27, 2023
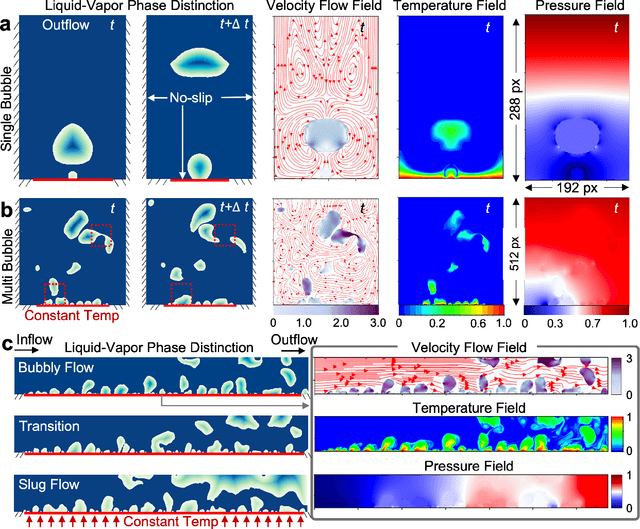
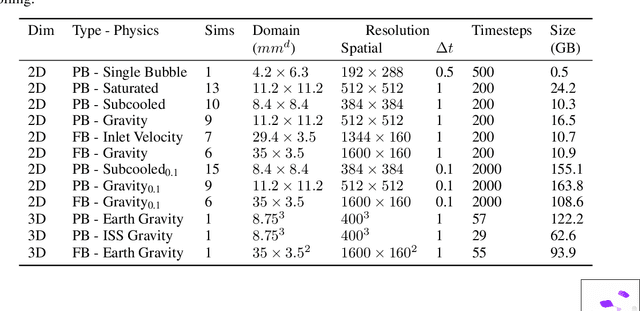
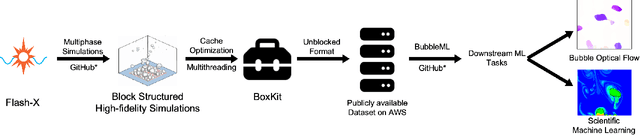
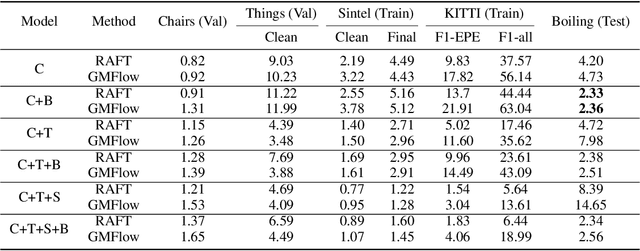
In the field of phase change phenomena, the lack of accessible and diverse datasets suitable for machine learning (ML) training poses a significant challenge. Existing experimental datasets are often restricted, with limited availability and sparse ground truth data, impeding our understanding of this complex multi-physics phenomena. To bridge this gap, we present the BubbleML Dataset(https://github.com/HPCForge/BubbleML) which leverages physics-driven simulations to provide accurate ground truth information for various boiling scenarios, encompassing nucleate pool boiling, flow boiling, and sub-cooled boiling. This extensive dataset covers a wide range of parameters, including varying gravity conditions, flow rates, sub-cooling levels, and wall superheat, comprising 51 simulations. BubbleML is validated against experimental observations and trends, establishing it as an invaluable resource for ML research. Furthermore, we showcase its potential to facilitate exploration of diverse downstream tasks by introducing two benchmarks: (a) optical flow analysis to capture bubble dynamics, and (b) operator networks for learning temperature dynamics. The BubbleML dataset and its benchmarks serve as a catalyst for advancements in ML-driven research on multi-physics phase change phenomena, enabling the development and comparison of state-of-the-art techniques and models.
RRAML: Reinforced Retrieval Augmented Machine Learning
Jul 27, 2023The emergence of large language models (LLMs) has revolutionized machine learning and related fields, showcasing remarkable abilities in comprehending, generating, and manipulating human language. However, their conventional usage through API-based text prompt submissions imposes certain limitations in terms of context constraints and external source availability. To address these challenges, we propose a novel framework called Reinforced Retrieval Augmented Machine Learning (RRAML). RRAML integrates the reasoning capabilities of LLMs with supporting information retrieved by a purpose-built retriever from a vast user-provided database. By leveraging recent advancements in reinforcement learning, our method effectively addresses several critical challenges. Firstly, it circumvents the need for accessing LLM gradients. Secondly, our method alleviates the burden of retraining LLMs for specific tasks, as it is often impractical or impossible due to restricted access to the model and the computational intensity involved. Additionally we seamlessly link the retriever's task with the reasoner, mitigating hallucinations and reducing irrelevant, and potentially damaging retrieved documents. We believe that the research agenda outlined in this paper has the potential to profoundly impact the field of AI, democratizing access to and utilization of LLMs for a wide range of entities.
Physics Informed Neural Network for Head-Related Transfer Function Upsampling
Jul 27, 2023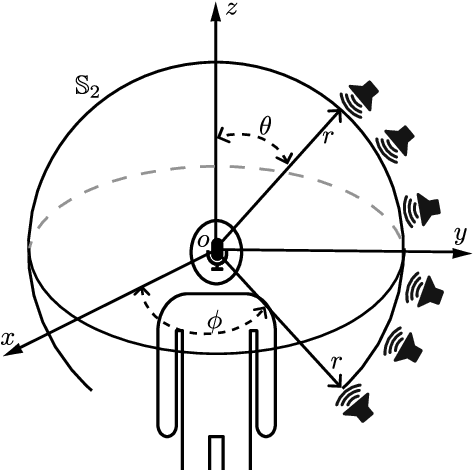

Head-related transfer functions (HRTFs) capture the spatial and spectral features that a person uses to localize sound sources in space and thus are vital for creating an authentic virtual acoustic experience. However, practical HRTF measurement systems can only provide an incomplete measurement of a person's HRTFs, and this necessitates HRTF upsampling. This paper proposes a physics-informed neural network (PINN) method for HRTF upsampling. Unlike other upsampling methods which are based on the measured HRTFs only, the PINN method exploits the Helmholtz equation as additional information for constraining the upsampling process. This helps the PINN method to generate physically amiable upsamplings which generalize beyond the measured HRTFs. Furthermore, the width and the depth of the PINN are set according to the dimensionality of HRTFs under spherical harmonic (SH) decomposition and the Helmholtz equation. This makes the PINN have an appropriate level of expressiveness and thus does not suffer from under-fitting and over-fitting problems. Numerical experiments confirm the superior performance of the PINN method for HRTF upsampling in both interpolation and extrapolation scenarios over several datasets in comparison with the SH methods.
A Sparse Quantized Hopfield Network for Online-Continual Memory
Jul 27, 2023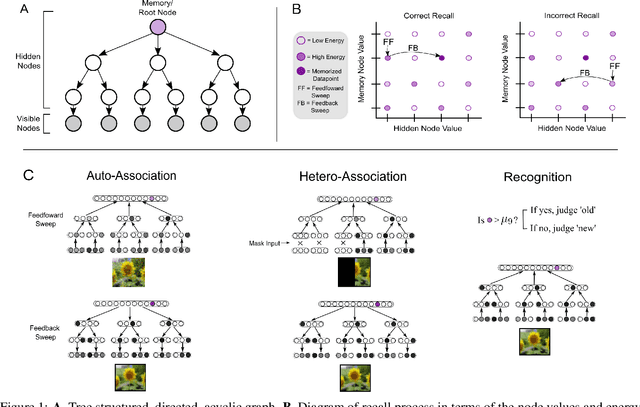

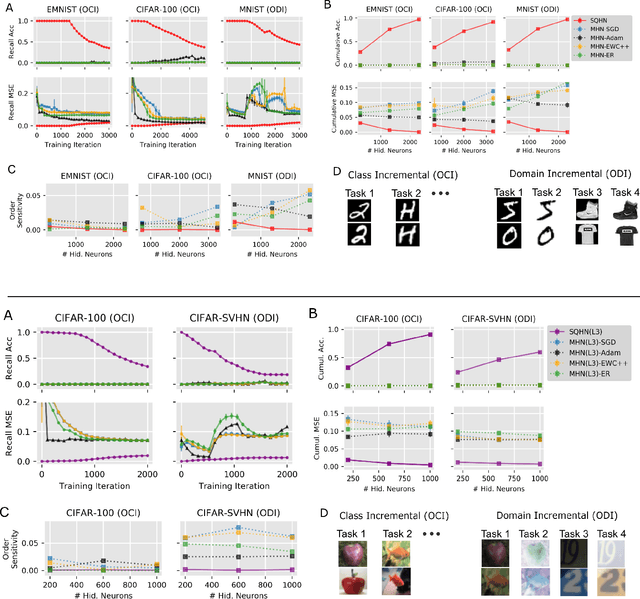
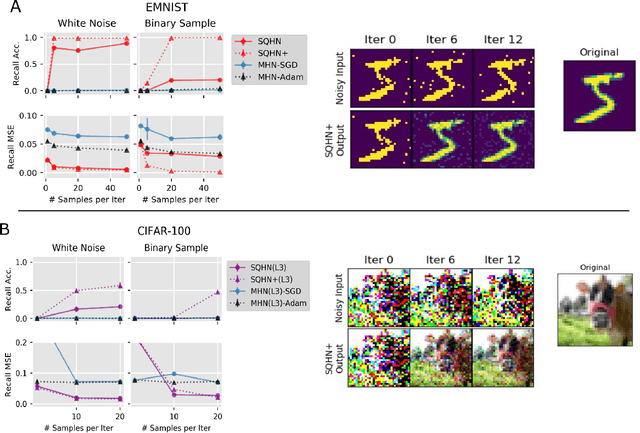
An important difference between brains and deep neural networks is the way they learn. Nervous systems learn online where a stream of noisy data points are presented in a non-independent, identically distributed (non-i.i.d.) way. Further, synaptic plasticity in the brain depends only on information local to synapses. Deep networks, on the other hand, typically use non-local learning algorithms and are trained in an offline, non-noisy, i.i.d. setting. Understanding how neural networks learn under the same constraints as the brain is an open problem for neuroscience and neuromorphic computing. A standard approach to this problem has yet to be established. In this paper, we propose that discrete graphical models that learn via an online maximum a posteriori learning algorithm could provide such an approach. We implement this kind of model in a novel neural network called the Sparse Quantized Hopfield Network (SQHN). We show that SQHNs outperform state-of-the-art neural networks on associative memory tasks, outperform these models in online, non-i.i.d. settings, learn efficiently with noisy inputs, and are better than baselines on a novel episodic memory task.
Towards understanding neural collapse in supervised contrastive learning with the information bottleneck method
May 19, 2023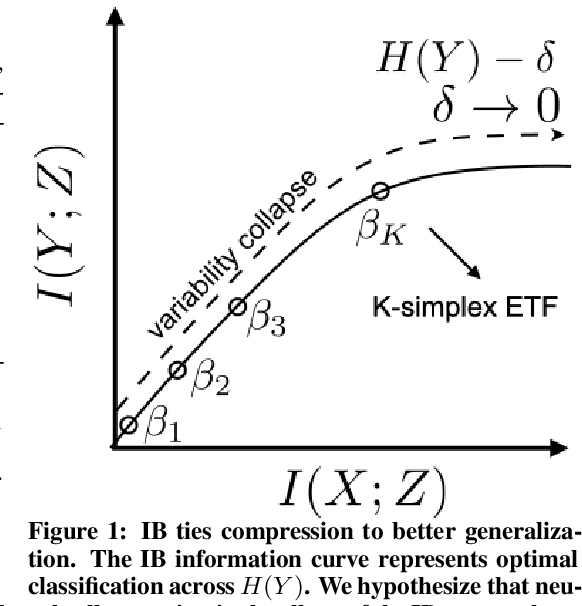

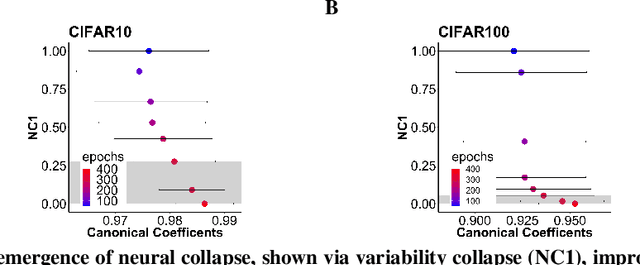

Neural collapse describes the geometry of activation in the final layer of a deep neural network when it is trained beyond performance plateaus. Open questions include whether neural collapse leads to better generalization and, if so, why and how training beyond the plateau helps. We model neural collapse as an information bottleneck (IB) problem in order to investigate whether such a compact representation exists and discover its connection to generalization. We demonstrate that neural collapse leads to good generalization specifically when it approaches an optimal IB solution of the classification problem. Recent research has shown that two deep neural networks independently trained with the same contrastive loss objective are linearly identifiable, meaning that the resulting representations are equivalent up to a matrix transformation. We leverage linear identifiability to approximate an analytical solution of the IB problem. This approximation demonstrates that when class means exhibit $K$-simplex Equiangular Tight Frame (ETF) behavior (e.g., $K$=10 for CIFAR10 and $K$=100 for CIFAR100), they coincide with the critical phase transitions of the corresponding IB problem. The performance plateau occurs once the optimal solution for the IB problem includes all of these phase transitions. We also show that the resulting $K$-simplex ETF can be packed into a $K$-dimensional Gaussian distribution using supervised contrastive learning with a ResNet50 backbone. This geometry suggests that the $K$-simplex ETF learned by supervised contrastive learning approximates the optimal features for source coding. Hence, there is a direct correspondence between optimal IB solutions and generalization in contrastive learning.
ECL: Class-Enhancement Contrastive Learning for Long-tailed Skin Lesion Classification
Jul 09, 2023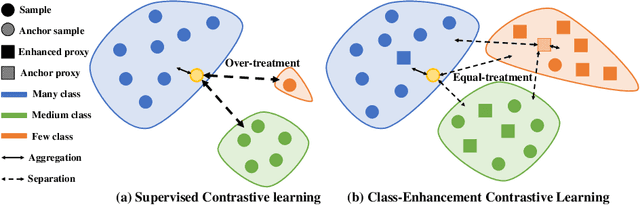
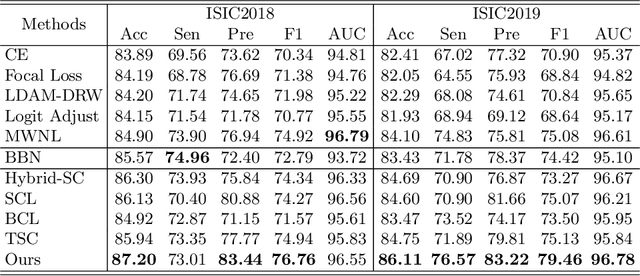
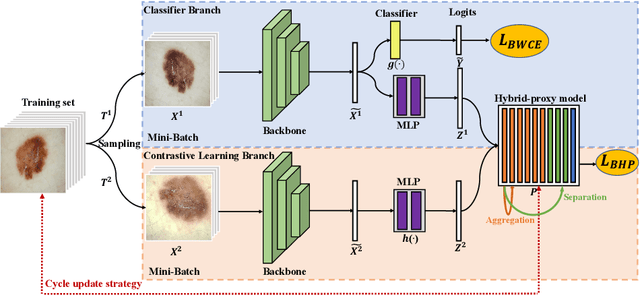
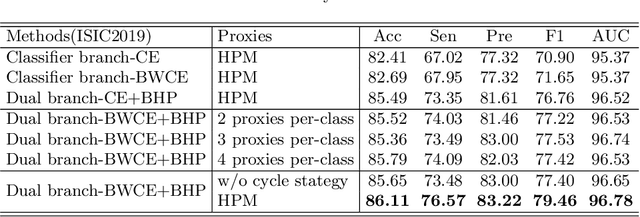
Skin image datasets often suffer from imbalanced data distribution, exacerbating the difficulty of computer-aided skin disease diagnosis. Some recent works exploit supervised contrastive learning (SCL) for this long-tailed challenge. Despite achieving significant performance, these SCL-based methods focus more on head classes, yet ignoring the utilization of information in tail classes. In this paper, we propose class-Enhancement Contrastive Learning (ECL), which enriches the information of minority classes and treats different classes equally. For information enhancement, we design a hybrid-proxy model to generate class-dependent proxies and propose a cycle update strategy for parameters optimization. A balanced-hybrid-proxy loss is designed to exploit relations between samples and proxies with different classes treated equally. Taking both "imbalanced data" and "imbalanced diagnosis difficulty" into account, we further present a balanced-weighted cross-entropy loss following curriculum learning schedule. Experimental results on the classification of imbalanced skin lesion data have demonstrated the superiority and effectiveness of our method.
Physical Layer Secret Key Agreement Using One-Bit Quantization and Low-Density Parity-Check Codes
Jul 08, 2023
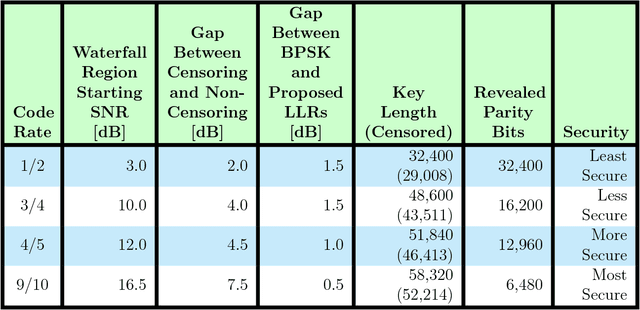
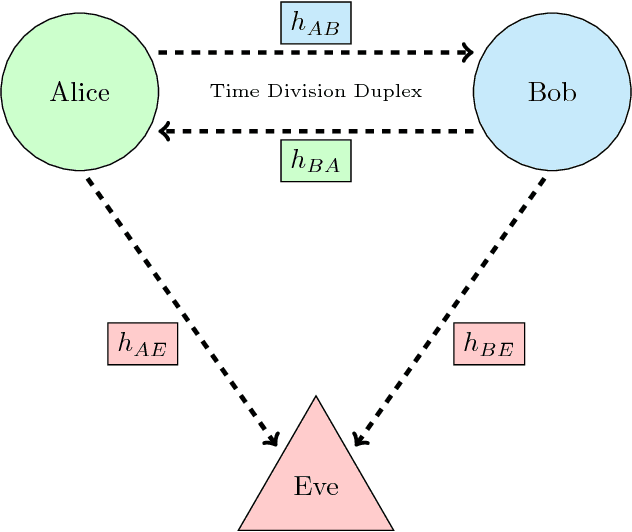
Physical layer approaches for generating secret encryption keys for wireless systems using channel information have attracted increased interest from researchers in recent years. This paper presents a new approach for calculating log-likelihood ratios (LLRs) for secret key generation that is based on one-bit quantization of channel measurements and the difference between channel estimates at legitimate reciprocal nodes. The studied secret key agreement approach, which implements advantage distillation along with information reconciliation using Slepian-Wolf low-density parity-check (LDPC) codes, is discussed and illustrated with numerical results obtained from simulations. These results show the probability of bit disagreement for keys generated using the proposed LLR calculations compared with alternative LLR calculation methods for key generation based on channel state information. The proposed LLR calculations are shown to be an improvement to the studied approach of physical layer secret key agreement.
Sequential Multi-Dimensional Self-Supervised Learning for Clinical Time Series
Jul 20, 2023

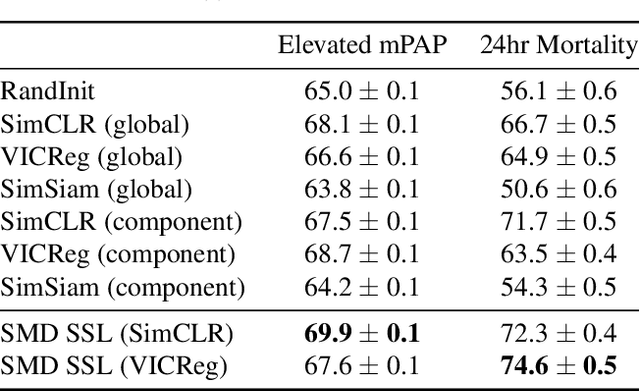
Self-supervised learning (SSL) for clinical time series data has received significant attention in recent literature, since these data are highly rich and provide important information about a patient's physiological state. However, most existing SSL methods for clinical time series are limited in that they are designed for unimodal time series, such as a sequence of structured features (e.g., lab values and vitals signs) or an individual high-dimensional physiological signal (e.g., an electrocardiogram). These existing methods cannot be readily extended to model time series that exhibit multimodality, with structured features and high-dimensional data being recorded at each timestep in the sequence. In this work, we address this gap and propose a new SSL method -- Sequential Multi-Dimensional SSL -- where a SSL loss is applied both at the level of the entire sequence and at the level of the individual high-dimensional data points in the sequence in order to better capture information at both scales. Our strategy is agnostic to the specific form of loss function used at each level -- it can be contrastive, as in SimCLR, or non-contrastive, as in VICReg. We evaluate our method on two real-world clinical datasets, where the time series contains sequences of (1) high-frequency electrocardiograms and (2) structured data from lab values and vitals signs. Our experimental results indicate that pre-training with our method and then fine-tuning on downstream tasks improves performance over baselines on both datasets, and in several settings, can lead to improvements across different self-supervised loss functions.
Leveraging arbitrary mobile sensor trajectories with shallow recurrent decoder networks for full-state reconstruction
Jul 20, 2023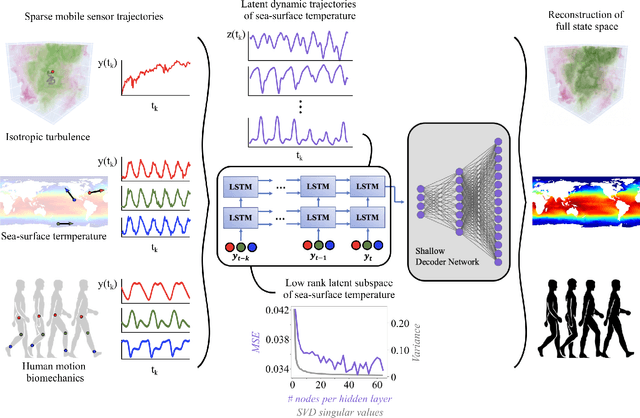
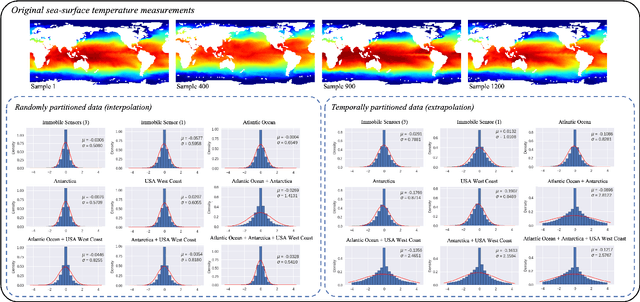
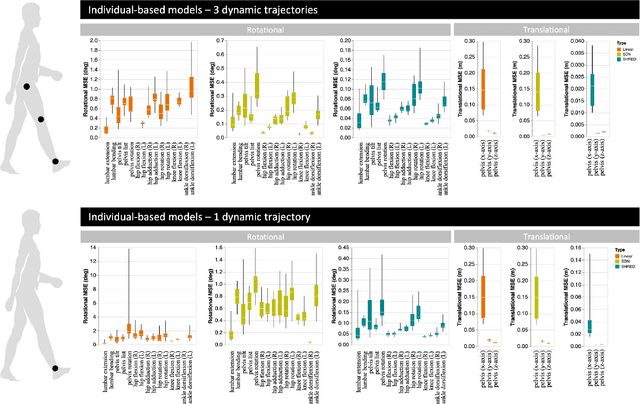
Sensing is one of the most fundamental tasks for the monitoring, forecasting and control of complex, spatio-temporal systems. In many applications, a limited number of sensors are mobile and move with the dynamics, with examples including wearable technology, ocean monitoring buoys, and weather balloons. In these dynamic systems (without regions of statistical-independence), the measurement time history encodes a significant amount of information that can be extracted for critical tasks. Most model-free sensing paradigms aim to map current sparse sensor measurements to the high-dimensional state space, ignoring the time-history all together. Using modern deep learning architectures, we show that a sequence-to-vector model, such as an LSTM (long, short-term memory) network, with a decoder network, dynamic trajectory information can be mapped to full state-space estimates. Indeed, we demonstrate that by leveraging mobile sensor trajectories with shallow recurrent decoder networks, we can train the network (i) to accurately reconstruct the full state space using arbitrary dynamical trajectories of the sensors, (ii) the architecture reduces the variance of the mean-square error of the reconstruction error in comparison with immobile sensors, and (iii) the architecture also allows for rapid generalization (parameterization of dynamics) for data outside the training set. Moreover, the path of the sensor can be chosen arbitrarily, provided training data for the spatial trajectory of the sensor is available. The exceptional performance of the network architecture is demonstrated on three applications: turbulent flows, global sea-surface temperature data, and human movement biomechanics.
DocParser: End-to-end OCR-free Information Extraction from Visually Rich Documents
Apr 24, 2023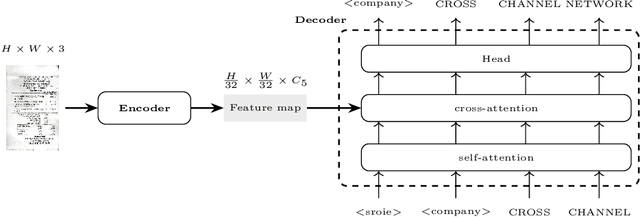
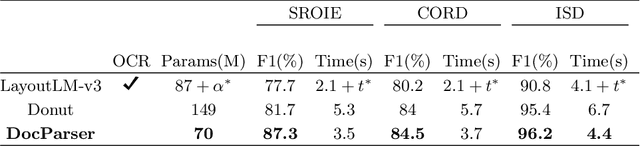
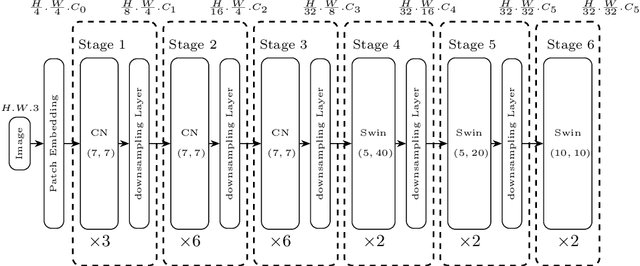

Information Extraction from visually rich documents is a challenging task that has gained a lot of attention in recent years due to its importance in several document-control based applications and its widespread commercial value. The majority of the research work conducted on this topic to date follow a two-step pipeline. First, they read the text using an off-the-shelf Optical Character Recognition (OCR) engine, then, they extract the fields of interest from the obtained text. The main drawback of these approaches is their dependence on an external OCR system, which can negatively impact both performance and computational speed. Recent OCR-free methods were proposed to address the previous issues. Inspired by their promising results, we propose in this paper an OCR-free end-to-end information extraction model named DocParser. It differs from prior end-to-end approaches by its ability to better extract discriminative character features. DocParser achieves state-of-the-art results on various datasets, while still being faster than previous works.