 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PNT-Edge: Towards Robust Edge Detection with Noisy Labels by Learning Pixel-level Noise Transitions
Jul 26, 2023
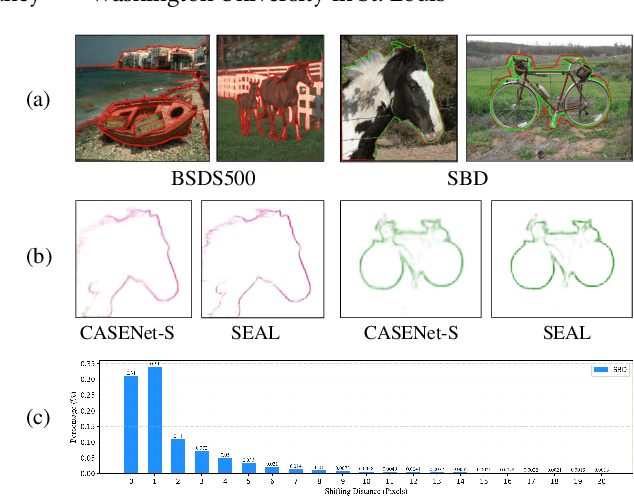
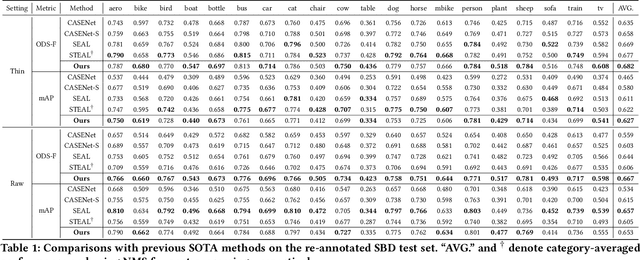
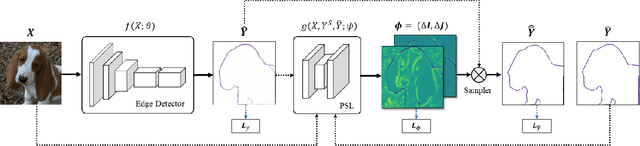
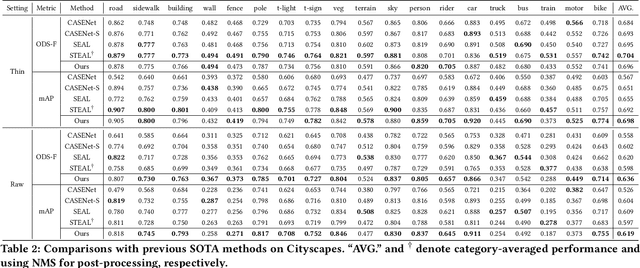
Relying on large-scale training data with pixel-level labels, previous edge detection methods have achieved high performance. However, it is hard to manually label edges accurately, especially for large datasets, and thus the datasets inevitably contain noisy labels. This label-noise issue has been studied extensively for classification, while still remaining under-explored for edge detection. To address the label-noise issue for edge detection, this paper proposes to learn Pixel-level NoiseTransitions to model the label-corruption process. To achieve it, we develop a novel Pixel-wise Shift Learning (PSL) module to estimate the transition from clean to noisy labels as a displacement field. Exploiting the estimated noise transitions, our model, named PNT-Edge, is able to fit the prediction to clean labels. In addition, a local edge density regularization term is devised to exploit local structure information for better transition learning. This term encourages learning large shifts for the edges with complex local structures. Experiments on SBD and Cityscapes demonstrate the effectiveness of our method in relieving the impact of label noise. Codes will be available at github.
Controllable Guide-Space for Generalizable Face Forgery Detection
Jul 26, 2023
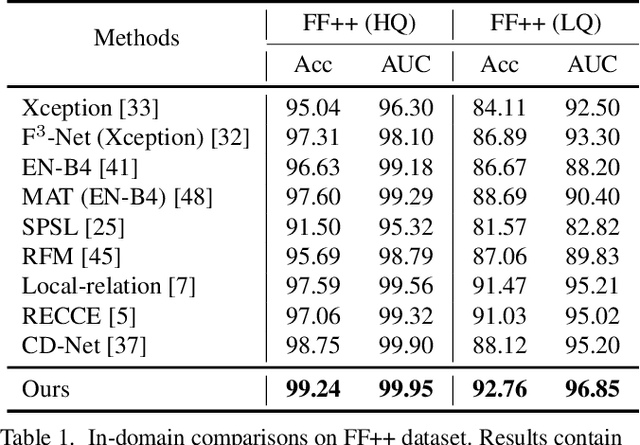
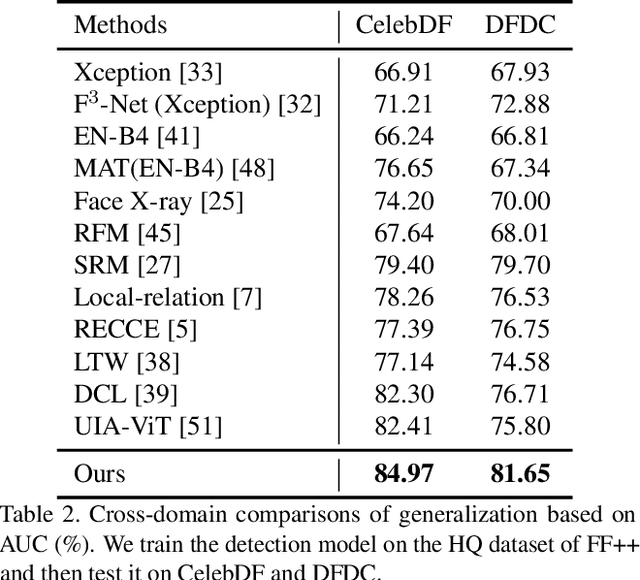
Recent studies on face forgery detection have shown satisfactory performance for methods involved in training datasets, but are not ideal enough for unknown domains. This motivates many works to improve the generalization, but forgery-irrelevant information, such as image background and identity, still exists in different domain features and causes unexpected clustering, limiting the generalization. In this paper, we propose a controllable guide-space (GS) method to enhance the discrimination of different forgery domains, so as to increase the forgery relevance of features and thereby improve the generalization. The well-designed guide-space can simultaneously achieve both the proper separation of forgery domains and the large distance between real-forgery domains in an explicit and controllable manner. Moreover, for better discrimination, we use a decoupling module to weaken the interference of forgery-irrelevant correlations between domains. Furthermore, we make adjustments to the decision boundary manifold according to the clustering degree of the same domain features within the neighborhood. Extensive experiments in multiple in-domain and cross-domain settings confirm that our method can achieve state-of-the-art generalization.
A semantics-driven methodology for high-quality image annotation
Jul 26, 2023Recent work in Machine Learning and Computer Vision has highlighted the presence of various types of systematic flaws inside ground truth object recognition benchmark datasets. Our basic tenet is that these flaws are rooted in the many-to-many mappings which exist between the visual information encoded in images and the intended semantics of the labels annotating them. The net consequence is that the current annotation process is largely under-specified, thus leaving too much freedom to the subjective judgment of annotators. In this paper, we propose vTelos, an integrated Natural Language Processing, Knowledge Representation, and Computer Vision methodology whose main goal is to make explicit the (otherwise implicit) intended annotation semantics, thus minimizing the number and role of subjective choices. A key element of vTelos is the exploitation of the WordNet lexico-semantic hierarchy as the main means for providing the meaning of natural language labels and, as a consequence, for driving the annotation of images based on the objects and the visual properties they depict. The methodology is validated on images populating a subset of the ImageNet hierarchy.
Rethinking Voice-Face Correlation: A Geometry View
Jul 26, 2023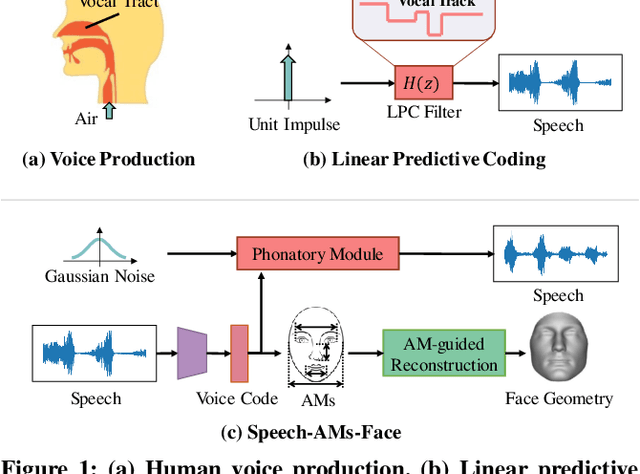

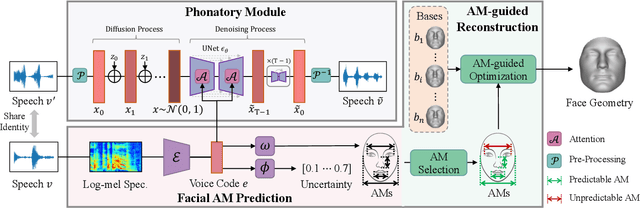

Previous works on voice-face matching and voice-guided face synthesis demonstrate strong correlations between voice and face, but mainly rely on coarse semantic cues such as gender, age, and emotion. In this paper, we aim to investigate the capability of reconstructing the 3D facial shape from voice from a geometry perspective without any semantic information. We propose a voice-anthropometric measurement (AM)-face paradigm, which identifies predictable facial AMs from the voice and uses them to guide 3D face reconstruction. By leveraging AMs as a proxy to link the voice and face geometry, we can eliminate the influence of unpredictable AMs and make the face geometry tractable. Our approach is evaluated on our proposed dataset with ground-truth 3D face scans and corresponding voice recordings, and we find significant correlations between voice and specific parts of the face geometry, such as the nasal cavity and cranium. Our work offers a new perspective on voice-face correlation and can serve as a good empirical study for anthropometry science.
Cross-Modal Content Inference and Feature Enrichment for Cold-Start Recommendation
Jul 06, 2023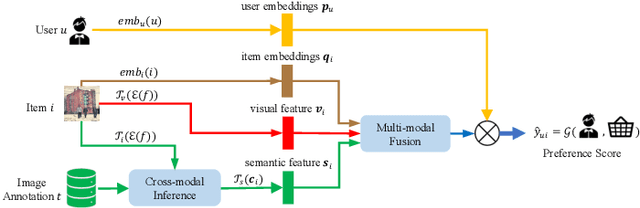
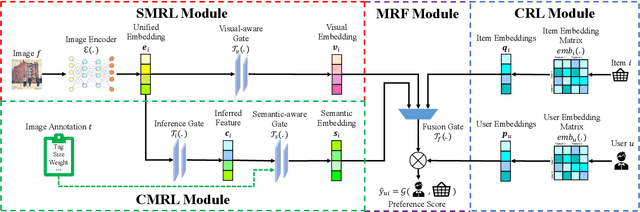
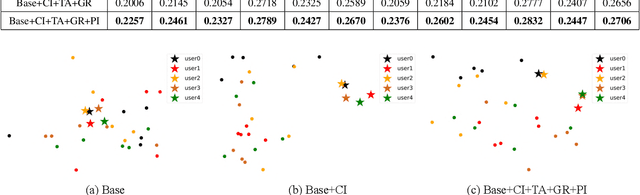
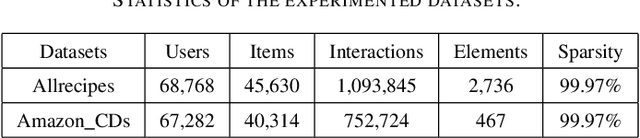
Multimedia recommendation aims to fuse the multi-modal information of items for feature enrichment to improve the recommendation performance. However, existing methods typically introduce multi-modal information based on collaborative information to improve the overall recommendation precision, while failing to explore its cold-start recommendation performance. Meanwhile, these above methods are only applicable when such multi-modal data is available. To address this problem, this paper proposes a recommendation framework, named Cross-modal Content Inference and Feature Enrichment Recommendation (CIERec), which exploits the multi-modal information to improve its cold-start recommendation performance. Specifically, CIERec first introduces image annotation as the privileged information to help guide the mapping of unified features from the visual space to the semantic space in the training phase. And then CIERec enriches the content representation with the fusion of collaborative, visual, and cross-modal inferred representations, so as to improve its cold-start recommendation performance. Experimental results on two real-world datasets show that the content representations learned by CIERec are able to achieve superior cold-start recommendation performance over existing visually-aware recommendation algorithms. More importantly, CIERec can consistently achieve significant improvements with different conventional visually-aware backbones, which verifies its universality and effectiveness.
3D Skeletonization of Complex Grapevines for Robotic Pruning
Jul 21, 2023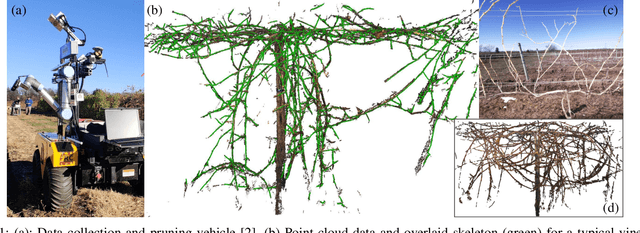
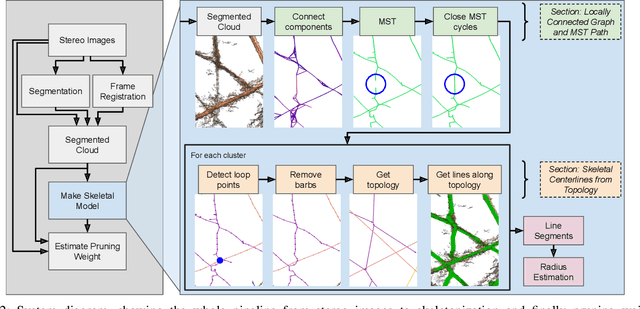
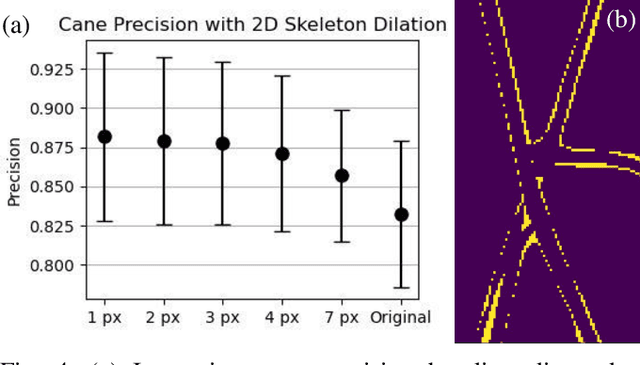
Robotic pruning of dormant grapevines is an area of active research in order to promote vine balance and grape quality, but so far robotic efforts have largely focused on planar, simplified vines not representative of commercial vineyards. This paper aims to advance the robotic perception capabilities necessary for pruning in denser and more complex vine structures by extending plant skeletonization techniques. The proposed pipeline generates skeletal grapevine models that have lower reprojection error and higher connectivity than baseline algorithms. We also show how 3D and skeletal information enables prediction accuracy of pruning weight for dense vines surpassing prior work, where pruning weight is an important vine metric influencing pruning site selection.
Teamwork Is Not Always Good: An Empirical Study of Classifier Drift in Class-incremental Information Extraction
May 26, 2023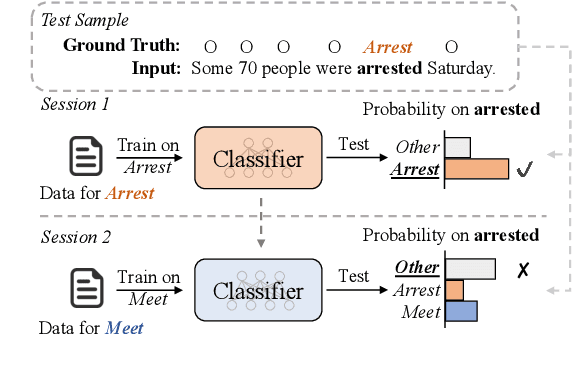
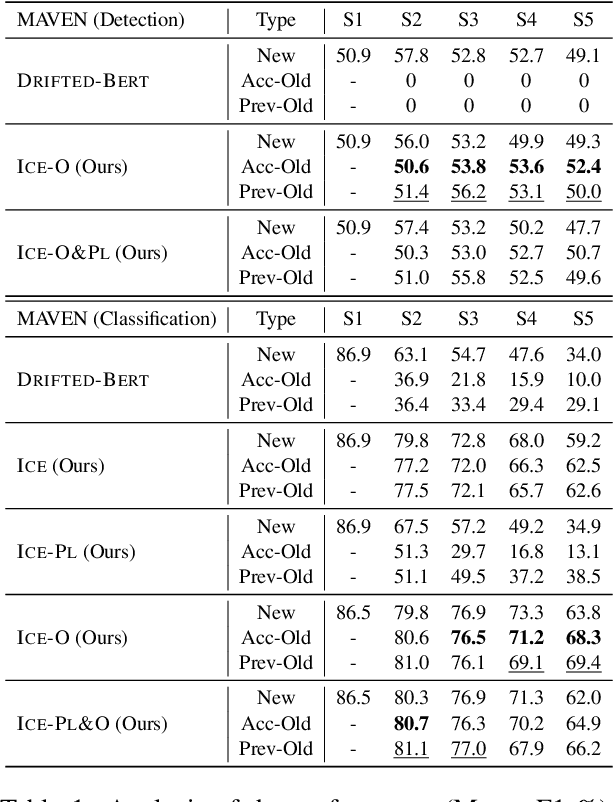
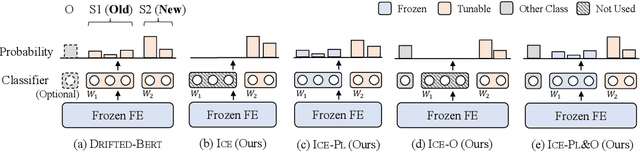
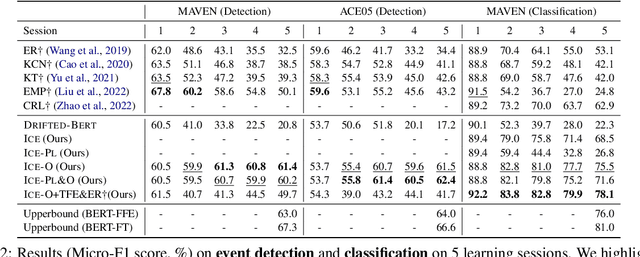
Class-incremental learning (CIL) aims to develop a learning system that can continually learn new classes from a data stream without forgetting previously learned classes. When learning classes incrementally, the classifier must be constantly updated to incorporate new classes, and the drift in decision boundary may lead to severe forgetting. This fundamental challenge, however, has not yet been studied extensively, especially in the setting where no samples from old classes are stored for rehearsal. In this paper, we take a closer look at how the drift in the classifier leads to forgetting, and accordingly, design four simple yet (super-) effective solutions to alleviate the classifier drift: an Individual Classifiers with Frozen Feature Extractor (ICE) framework where we individually train a classifier for each learning session, and its three variants ICE-PL, ICE-O, and ICE-PL&O which further take the logits of previously learned classes from old sessions or a constant logit of an Other class as a constraint to the learning of new classifiers. Extensive experiments and analysis on 6 class-incremental information extraction tasks demonstrate that our solutions, especially ICE-O, consistently show significant improvement over the previous state-of-the-art approaches with up to 44.7% absolute F-score gain, providing a strong baseline and insights for future research on class-incremental learning.
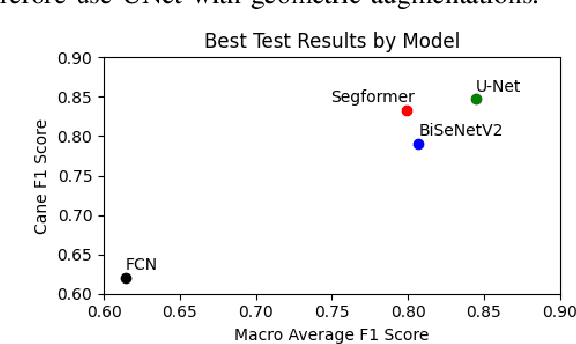
Recognizing student identification numbers from the matrix templates using a modified U-net architecture
Jul 12, 2023This paper presents an innovative approach to student identification during exams and knowledge tests, which overcomes the limitations of the traditional personal information entry method. The proposed method employs a matrix template on the designated section of the exam, where squares containing numbers are selectively blackened. The methodology involves the development of a neural network specifically designed for recognizing students' personal identification numbers. The neural network utilizes a specially adapted U-Net architecture, trained on an extensive dataset comprising images of blackened tables. The network demonstrates proficiency in recognizing the patterns and arrangement of blackened squares, accurately interpreting the information inscribed within them. Additionally, the model exhibits high accuracy in correctly identifying entered student personal numbers and effectively detecting erroneous entries within the table. This approach offers multiple advantages. Firstly, it significantly accelerates the exam marking process by automatically extracting identifying information from the blackened tables, eliminating the need for manual entry and minimizing the potential for errors. Secondly, the method automates the identification process, thereby reducing administrative effort and expediting data processing. The introduction of this innovative identification system represents a notable advancement in the field of exams and knowledge tests, replacing the conventional manual entry of personal data with a streamlined, efficient, and accurate identification process.
Sequential Multi-Dimensional Self-Supervised Learning for Clinical Time Series
Jul 20, 2023

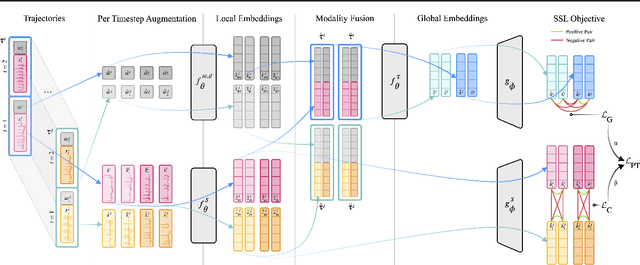
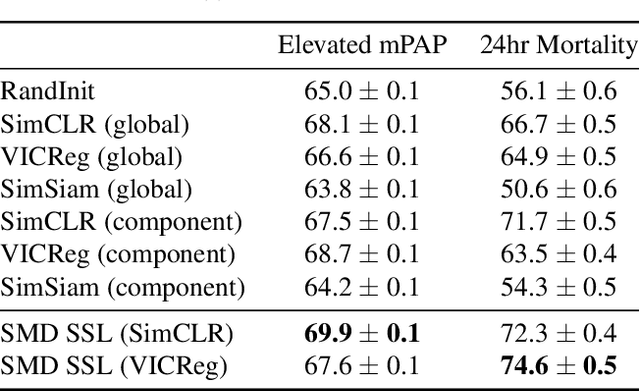
Self-supervised learning (SSL) for clinical time series data has received significant attention in recent literature, since these data are highly rich and provide important information about a patient's physiological state. However, most existing SSL methods for clinical time series are limited in that they are designed for unimodal time series, such as a sequence of structured features (e.g., lab values and vitals signs) or an individual high-dimensional physiological signal (e.g., an electrocardiogram). These existing methods cannot be readily extended to model time series that exhibit multimodality, with structured features and high-dimensional data being recorded at each timestep in the sequence. In this work, we address this gap and propose a new SSL method -- Sequential Multi-Dimensional SSL -- where a SSL loss is applied both at the level of the entire sequence and at the level of the individual high-dimensional data points in the sequence in order to better capture information at both scales. Our strategy is agnostic to the specific form of loss function used at each level -- it can be contrastive, as in SimCLR, or non-contrastive, as in VICReg. We evaluate our method on two real-world clinical datasets, where the time series contains sequences of (1) high-frequency electrocardiograms and (2) structured data from lab values and vitals signs. Our experimental results indicate that pre-training with our method and then fine-tuning on downstream tasks improves performance over baselines on both datasets, and in several settings, can lead to improvements across different self-supervised loss functions.
Leveraging arbitrary mobile sensor trajectories with shallow recurrent decoder networks for full-state reconstruction
Jul 20, 2023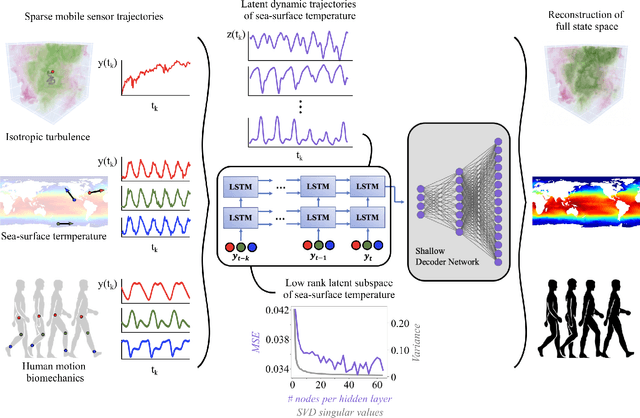
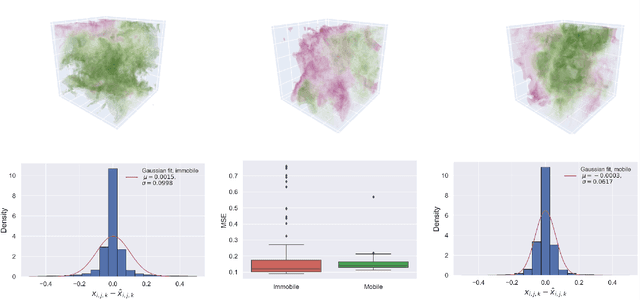
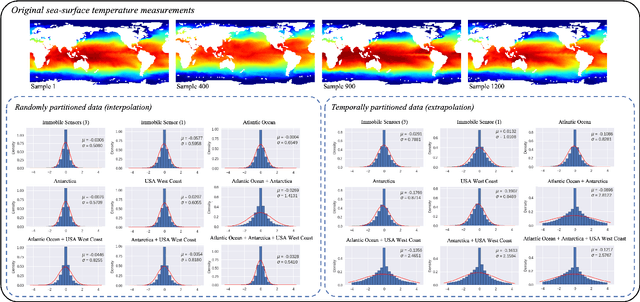
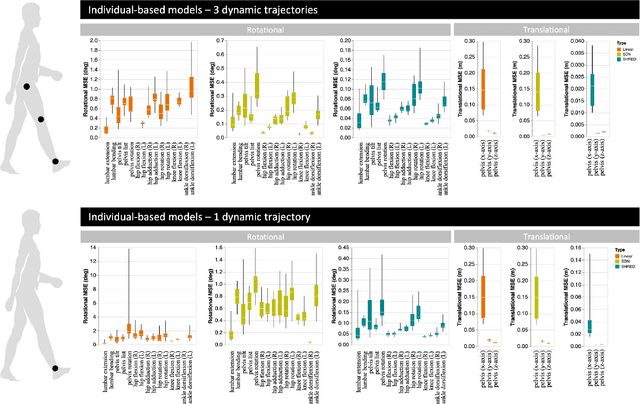
Sensing is one of the most fundamental tasks for the monitoring, forecasting and control of complex, spatio-temporal systems. In many applications, a limited number of sensors are mobile and move with the dynamics, with examples including wearable technology, ocean monitoring buoys, and weather balloons. In these dynamic systems (without regions of statistical-independence), the measurement time history encodes a significant amount of information that can be extracted for critical tasks. Most model-free sensing paradigms aim to map current sparse sensor measurements to the high-dimensional state space, ignoring the time-history all together. Using modern deep learning architectures, we show that a sequence-to-vector model, such as an LSTM (long, short-term memory) network, with a decoder network, dynamic trajectory information can be mapped to full state-space estimates. Indeed, we demonstrate that by leveraging mobile sensor trajectories with shallow recurrent decoder networks, we can train the network (i) to accurately reconstruct the full state space using arbitrary dynamical trajectories of the sensors, (ii) the architecture reduces the variance of the mean-square error of the reconstruction error in comparison with immobile sensors, and (iii) the architecture also allows for rapid generalization (parameterization of dynamics) for data outside the training set. Moreover, the path of the sensor can be chosen arbitrarily, provided training data for the spatial trajectory of the sensor is available. The exceptional performance of the network architecture is demonstrated on three applications: turbulent flows, global sea-surface temperature data, and human movement biomechanics.