 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Explaining Relation Classification Models with Semantic Extents
Aug 04, 2023
In recent years, the development of large pretrained language models, such as BERT and GPT, significantly improved information extraction systems on various tasks, including relation classification. State-of-the-art systems are highly accurate on scientific benchmarks. A lack of explainability is currently a complicating factor in many real-world applications. Comprehensible systems are necessary to prevent biased, counterintuitive, or harmful decisions. We introduce semantic extents, a concept to analyze decision patterns for the relation classification task. Semantic extents are the most influential parts of texts concerning classification decisions. Our definition allows similar procedures to determine semantic extents for humans and models. We provide an annotation tool and a software framework to determine semantic extents for humans and models conveniently and reproducibly. Comparing both reveals that models tend to learn shortcut patterns from data. These patterns are hard to detect with current interpretability methods, such as input reductions. Our approach can help detect and eliminate spurious decision patterns during model development. Semantic extents can increase the reliability and security of natural language processing systems. Semantic extents are an essential step in enabling applications in critical areas like healthcare or finance. Moreover, our work opens new research directions for developing methods to explain deep learning models.
AIDE: A Vision-Driven Multi-View, Multi-Modal, Multi-Tasking Dataset for Assistive Driving Perception
Aug 01, 2023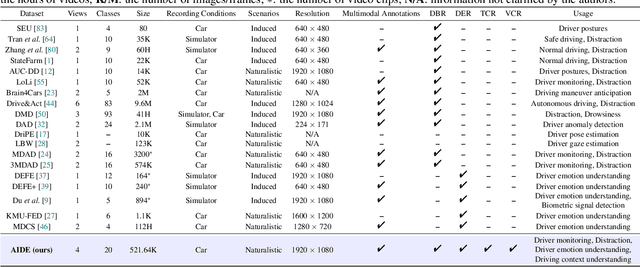
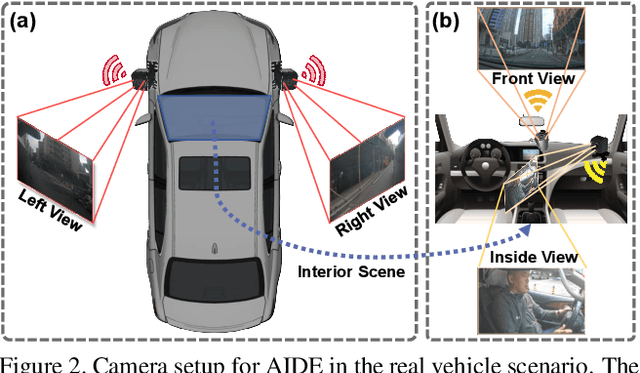
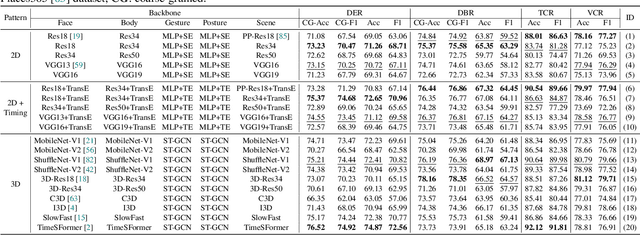
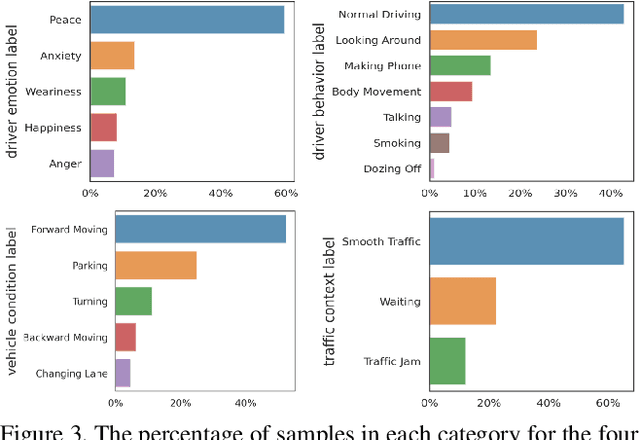
Driver distraction has become a significant cause of severe traffic accidents over the past decade. Despite the growing development of vision-driven driver monitoring systems, the lack of comprehensive perception datasets restricts road safety and traffic security. In this paper, we present an AssIstive Driving pErception dataset (AIDE) that considers context information both inside and outside the vehicle in naturalistic scenarios. AIDE facilitates holistic driver monitoring through three distinctive characteristics, including multi-view settings of driver and scene, multi-modal annotations of face, body, posture, and gesture, and four pragmatic task designs for driving understanding. To thoroughly explore AIDE, we provide experimental benchmarks on three kinds of baseline frameworks via extensive methods. Moreover, two fusion strategies are introduced to give new insights into learning effective multi-stream/modal representations. We also systematically investigate the importance and rationality of the key components in AIDE and benchmarks. The project link is https://github.com/ydk122024/AIDE.
ELFNet: Evidential Local-global Fusion for Stereo Matching
Aug 01, 2023

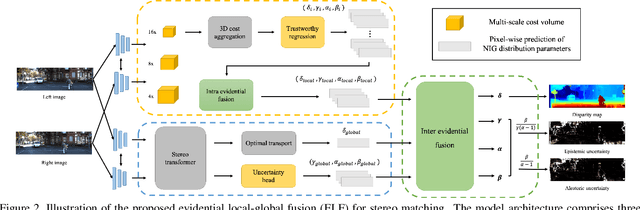
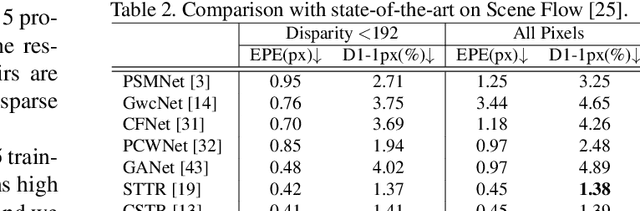
Although existing stereo matching models have achieved continuous improvement, they often face issues related to trustworthiness due to the absence of uncertainty estimation. Additionally, effectively leveraging multi-scale and multi-view knowledge of stereo pairs remains unexplored. In this paper, we introduce the \textbf{E}vidential \textbf{L}ocal-global \textbf{F}usion (ELF) framework for stereo matching, which endows both uncertainty estimation and confidence-aware fusion with trustworthy heads. Instead of predicting the disparity map alone, our model estimates an evidential-based disparity considering both aleatoric and epistemic uncertainties. With the normal inverse-Gamma distribution as a bridge, the proposed framework realizes intra evidential fusion of multi-level predictions and inter evidential fusion between cost-volume-based and transformer-based stereo matching. Extensive experimental results show that the proposed framework exploits multi-view information effectively and achieves state-of-the-art overall performance both on accuracy and cross-domain generalization. The codes are available at https://github.com/jimmy19991222/ELFNet.
Relational Contrastive Learning for Scene Text Recognition
Aug 01, 2023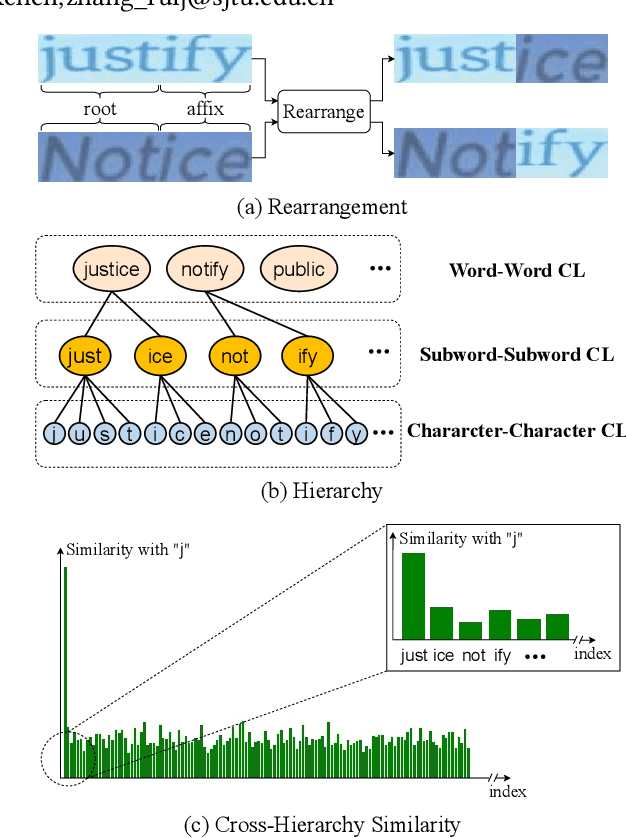
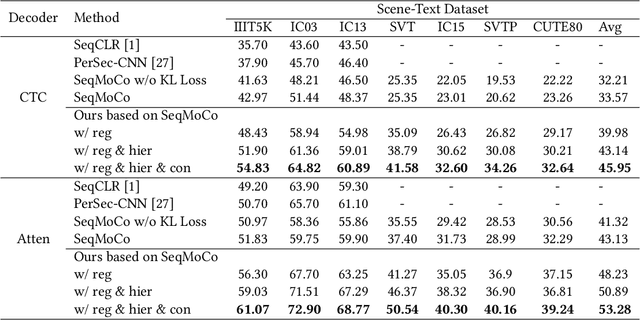
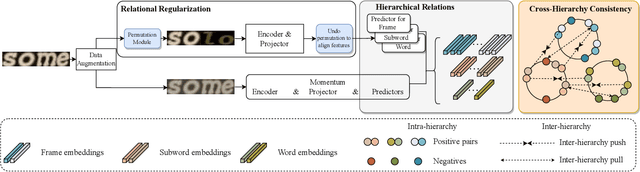

Context-aware methods achieved great success in supervised scene text recognition via incorporating semantic priors from words. We argue that such prior contextual information can be interpreted as the relations of textual primitives due to the heterogeneous text and background, which can provide effective self-supervised labels for representation learning. However, textual relations are restricted to the finite size of dataset due to lexical dependencies, which causes the problem of over-fitting and compromises representation robustness. To this end, we propose to enrich the textual relations via rearrangement, hierarchy and interaction, and design a unified framework called RCLSTR: Relational Contrastive Learning for Scene Text Recognition. Based on causality, we theoretically explain that three modules suppress the bias caused by the contextual prior and thus guarantee representation robustness. Experiments on representation quality show that our method outperforms state-of-the-art self-supervised STR methods. Code is available at https://github.com/ThunderVVV/RCLSTR.
The Bias Amplification Paradox in Text-to-Image Generation
Aug 01, 2023Bias amplification is a phenomenon in which models increase imbalances present in the training data. In this paper, we study bias amplification in the text-to-image domain using Stable Diffusion by comparing gender ratios in training vs. generated images. We find that the model appears to amplify gender-occupation biases found in the training data (LAION). However, we discover that amplification can largely be attributed to discrepancies between training captions and model prompts. For example, an inherent difference is that captions from the training data often contain explicit gender information while the prompts we use do not, which leads to a distribution shift and consequently impacts bias measures. Once we account for various distributional differences between texts used for training and generation, we observe that amplification decreases considerably. Our findings illustrate the challenges of comparing biases in models and the data they are trained on, and highlight confounding factors that contribute to bias amplification.
CoSMo: A constructor specification language for Abstract Wikipedia's content selection process
Aug 01, 2023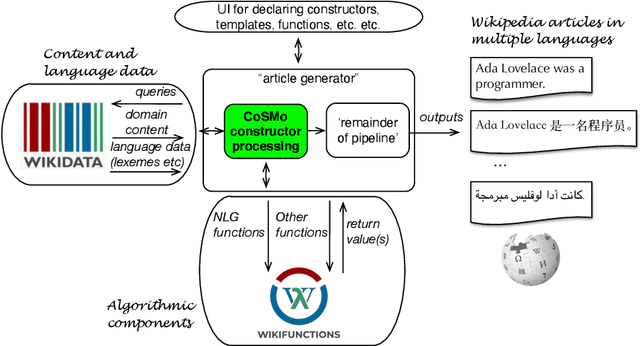
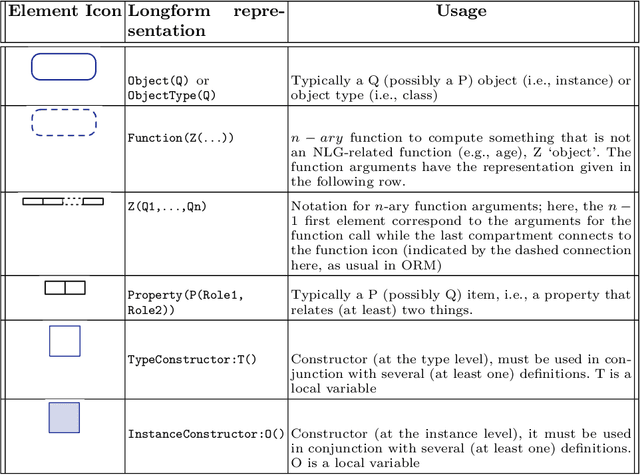
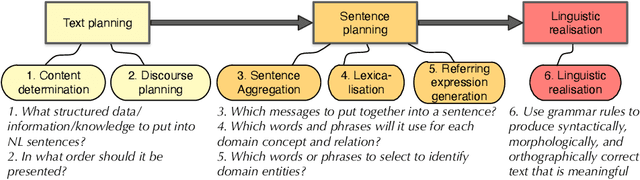
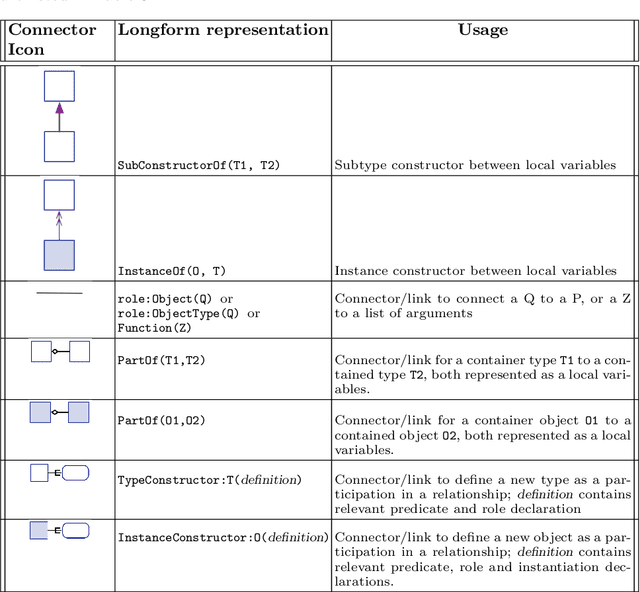
Representing snippets of information abstractly is a task that needs to be performed for various purposes, such as database view specification and the first stage in the natural language generation pipeline for generative AI from structured input, i.e., the content selection stage to determine what needs to be verbalised. For the Abstract Wikipedia project, requirements analysis revealed that such an abstract representation requires multilingual modelling, content selection covering declarative content and functions, and both classes and instances. There is no modelling language that meets either of the three features, let alone a combination. Following a rigorous language design process inclusive of broad stakeholder consultation, we created CoSMo, a novel {\sc Co}ntent {\sc S}election {\sc Mo}deling language that meets these and other requirements so that it may be useful both in Abstract Wikipedia as well as other contexts. We describe the design process, rationale and choices, the specification, and preliminary evaluation of the language.
Iterative Graph Filtering Network for 3D Human Pose Estimation
Aug 07, 2023
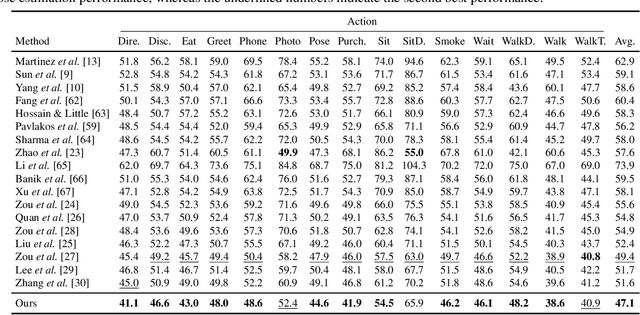

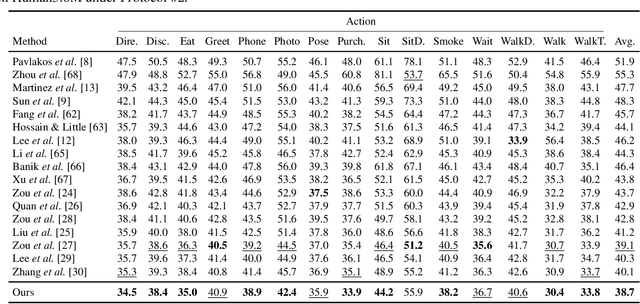
Graph convolutional networks (GCNs) have proven to be an effective approach for 3D human pose estimation. By naturally modeling the skeleton structure of the human body as a graph, GCNs are able to capture the spatial relationships between joints and learn an efficient representation of the underlying pose. However, most GCN-based methods use a shared weight matrix, making it challenging to accurately capture the different and complex relationships between joints. In this paper, we introduce an iterative graph filtering framework for 3D human pose estimation, which aims to predict the 3D joint positions given a set of 2D joint locations in images. Our approach builds upon the idea of iteratively solving graph filtering with Laplacian regularization via the Gauss-Seidel iterative method. Motivated by this iterative solution, we design a Gauss-Seidel network (GS-Net) architecture, which makes use of weight and adjacency modulation, skip connection, and a pure convolutional block with layer normalization. Adjacency modulation facilitates the learning of edges that go beyond the inherent connections of body joints, resulting in an adjusted graph structure that reflects the human skeleton, while skip connections help maintain crucial information from the input layer's initial features as the network depth increases. We evaluate our proposed model on two standard benchmark datasets, and compare it with a comprehensive set of strong baseline methods for 3D human pose estimation. Our experimental results demonstrate that our approach outperforms the baseline methods on both datasets, achieving state-of-the-art performance. Furthermore, we conduct ablation studies to analyze the contributions of different components of our model architecture and show that the skip connection and adjacency modulation help improve the model performance.
Establishing Trust in ChatGPT BioMedical Generated Text: An Ontology-Based Knowledge Graph to Validate Disease-Symptom Links
Aug 07, 2023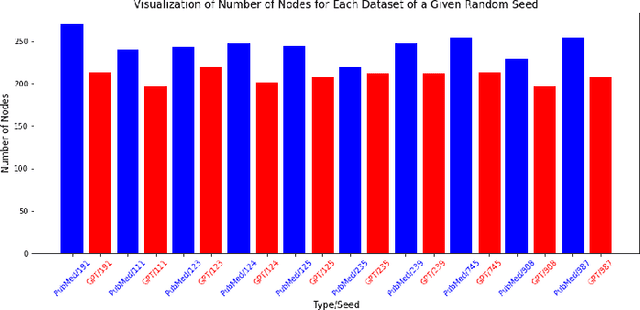
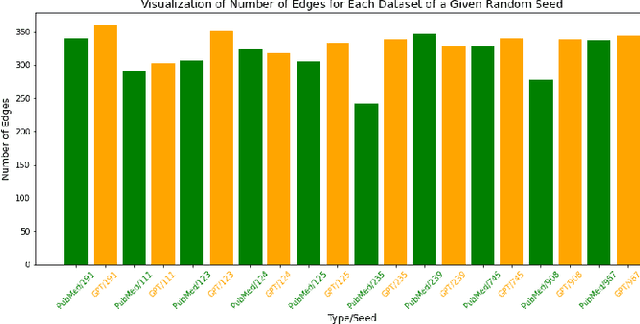
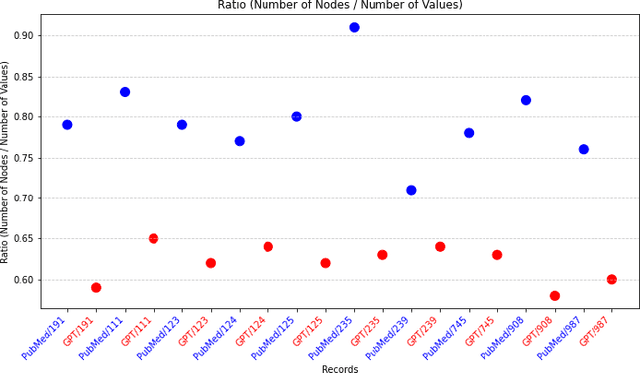
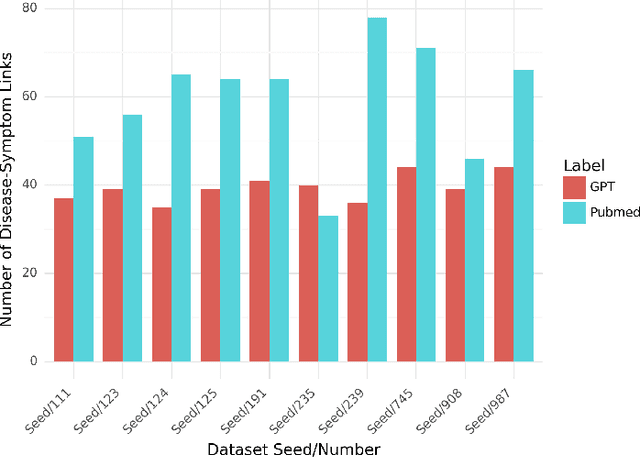
Methods: Through an innovative approach, we construct ontology-based knowledge graphs from authentic medical literature and AI-generated content. Our goal is to distinguish factual information from unverified data. We compiled two datasets: one from biomedical literature using a "human disease and symptoms" query, and another generated by ChatGPT, simulating articles. With these datasets (PubMed and ChatGPT), we curated 10 sets of 250 abstracts each, selected randomly with a specific seed. Our method focuses on utilizing disease ontology (DOID) and symptom ontology (SYMP) to build knowledge graphs, robust mathematical models that facilitate unbiased comparisons. By employing our fact-checking algorithms and network centrality metrics, we conducted GPT disease-symptoms link analysis to quantify the accuracy of factual knowledge amid noise, hypotheses, and significant findings. Results: The findings obtained from the comparison of diverse ChatGPT knowledge graphs with their PubMed counterparts revealed some interesting observations. While PubMed knowledge graphs exhibit a wealth of disease-symptom terms, it is surprising to observe that some ChatGPT graphs surpass them in the number of connections. Furthermore, some GPT graphs are demonstrating supremacy of the centrality scores, especially for the overlapping nodes. This striking contrast indicates the untapped potential of knowledge that can be derived from AI-generated content, awaiting verification. Out of all the graphs, the factual link ratio between any two graphs reached its peak at 60%. Conclusions: An intriguing insight from our findings was the striking number of links among terms in the knowledge graph generated from ChatGPT datasets, surpassing some of those in its PubMed counterpart. This early discovery has prompted further investigation using universal network metrics to unveil the new knowledge the links may hold.
Implicit Identity Representation Conditioned Memory Compensation Network for Talking Head video Generation
Jul 20, 2023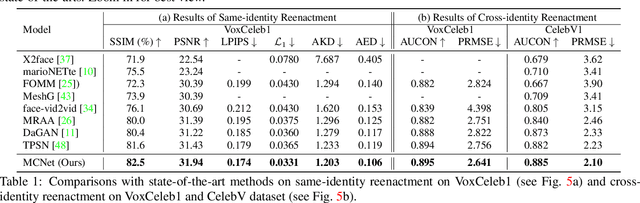
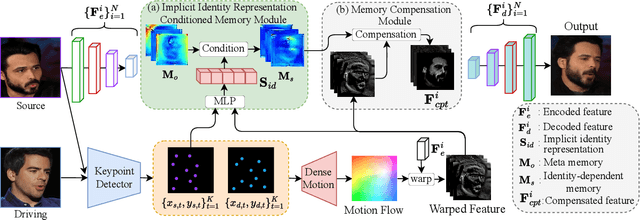
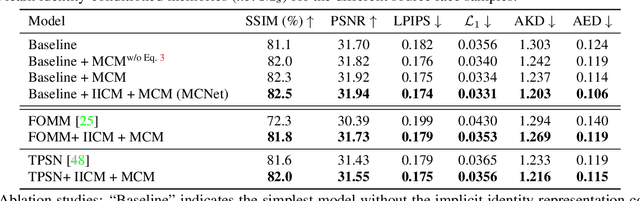
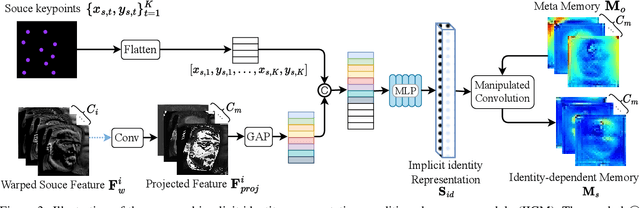
Talking head video generation aims to animate a human face in a still image with dynamic poses and expressions using motion information derived from a target-driving video, while maintaining the person's identity in the source image. However, dramatic and complex motions in the driving video cause ambiguous generation, because the still source image cannot provide sufficient appearance information for occluded regions or delicate expression variations, which produces severe artifacts and significantly degrades the generation quality. To tackle this problem, we propose to learn a global facial representation space, and design a novel implicit identity representation conditioned memory compensation network, coined as MCNet, for high-fidelity talking head generation.~Specifically, we devise a network module to learn a unified spatial facial meta-memory bank from all training samples, which can provide rich facial structure and appearance priors to compensate warped source facial features for the generation. Furthermore, we propose an effective query mechanism based on implicit identity representations learned from the discrete keypoints of the source image. It can greatly facilitate the retrieval of more correlated information from the memory bank for the compensation. Extensive experiments demonstrate that MCNet can learn representative and complementary facial memory, and can clearly outperform previous state-of-the-art talking head generation methods on VoxCeleb1 and CelebV datasets. Please check our \href{https://github.com/harlanhong/ICCV2023-MCNET}{Project}.
Layer-wise Representation Fusion for Compositional Generalization
Jul 20, 2023Despite successes across a broad range of applications, sequence-to-sequence models' construct of solutions are argued to be less compositional than human-like generalization. There is mounting evidence that one of the reasons hindering compositional generalization is representations of the encoder and decoder uppermost layer are entangled. In other words, the syntactic and semantic representations of sequences are twisted inappropriately. However, most previous studies mainly concentrate on enhancing token-level semantic information to alleviate the representations entanglement problem, rather than composing and using the syntactic and semantic representations of sequences appropriately as humans do. In addition, we explain why the entanglement problem exists from the perspective of recent studies about training deeper Transformer, mainly owing to the ``shallow'' residual connections and its simple, one-step operations, which fails to fuse previous layers' information effectively. Starting from this finding and inspired by humans' strategies, we propose \textsc{FuSion} (\textbf{Fu}sing \textbf{S}yntactic and Semant\textbf{i}c Representati\textbf{on}s), an extension to sequence-to-sequence models to learn to fuse previous layers' information back into the encoding and decoding process appropriately through introducing a \emph{fuse-attention module} at each encoder and decoder layer. \textsc{FuSion} achieves competitive and even \textbf{state-of-the-art} results on two realistic benchmarks, which empirically demonstrates the effectiveness of our proposal.