 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Report from Dagstuhl Seminar 23031: Frontiers of Information Access Experimentation for Research and Education
Apr 18, 2023



This report documents the program and the outcomes of Dagstuhl Seminar 23031 ``Frontiers of Information Access Experimentation for Research and Education'', which brought together 37 participants from 12 countries. The seminar addressed technology-enhanced information access (information retrieval, recommender systems, natural language processing) and specifically focused on developing more responsible experimental practices leading to more valid results, both for research as well as for scientific education. The seminar brought together experts from various sub-fields of information access, namely IR, RS, NLP, information science, and human-computer interaction to create a joint understanding of the problems and challenges presented by next generation information access systems, from both the research and the experimentation point of views, to discuss existing solutions and impediments, and to propose next steps to be pursued in the area in order to improve not also our research methods and findings but also the education of the new generation of researchers and developers. The seminar featured a series of long and short talks delivered by participants, who helped in setting a common ground and in letting emerge topics of interest to be explored as the main output of the seminar. This led to the definition of five groups which investigated challenges, opportunities, and next steps in the following areas: reality check, i.e. conducting real-world studies, human-machine-collaborative relevance judgment frameworks, overcoming methodological challenges in information retrieval and recommender systems through awareness and education, results-blind reviewing, and guidance for authors.
DQ-Det: Learning Dynamic Query Combinations for Transformer-based Object Detection and Segmentation
Jul 23, 2023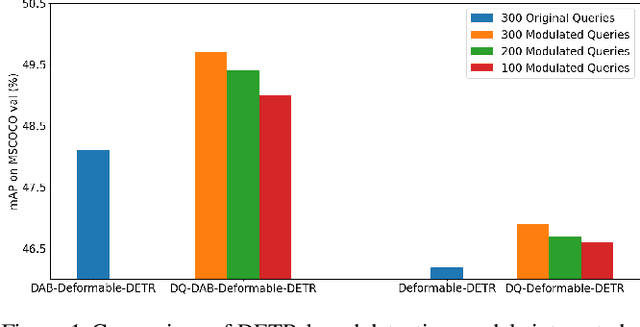

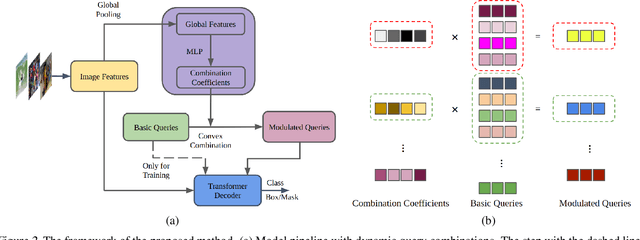
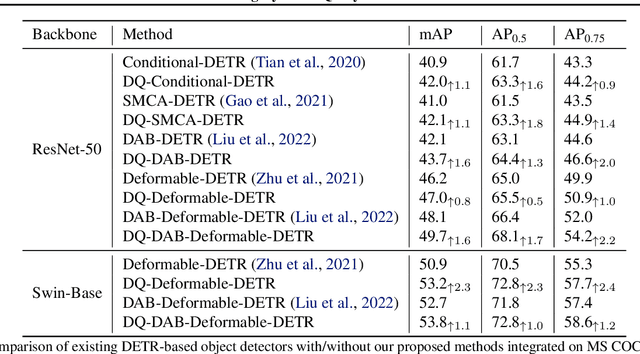
Transformer-based detection and segmentation methods use a list of learned detection queries to retrieve information from the transformer network and learn to predict the location and category of one specific object from each query. We empirically find that random convex combinations of the learned queries are still good for the corresponding models. We then propose to learn a convex combination with dynamic coefficients based on the high-level semantics of the image. The generated dynamic queries, named modulated queries, better capture the prior of object locations and categories in the different images. Equipped with our modulated queries, a wide range of DETR-based models achieve consistent and superior performance across multiple tasks including object detection, instance segmentation, panoptic segmentation, and video instance segmentation.
Robust Multi-Agent Reinforcement Learning with State Uncertainty
Jul 30, 2023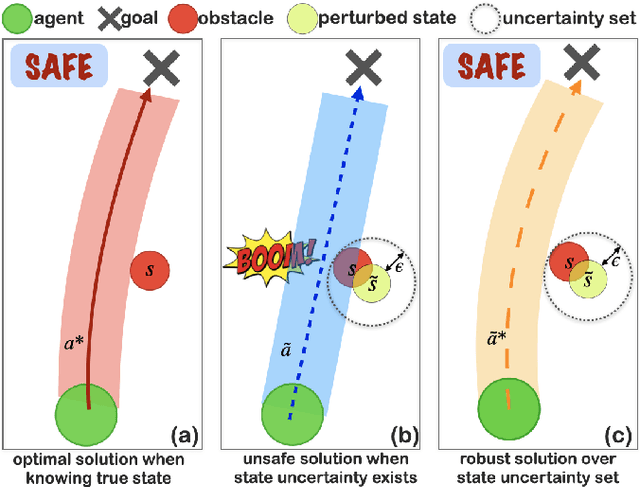

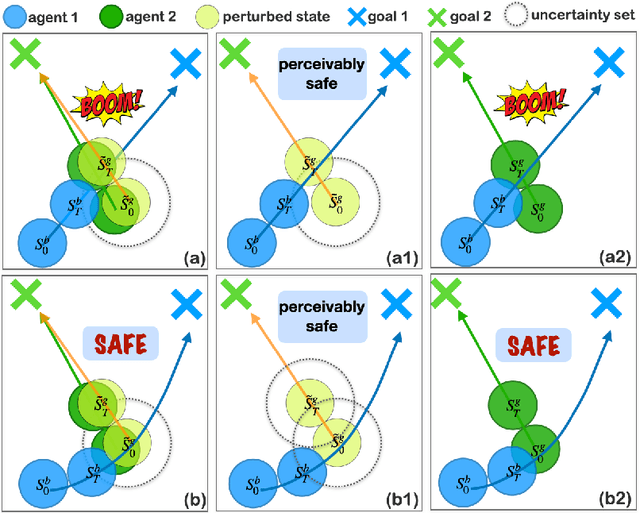
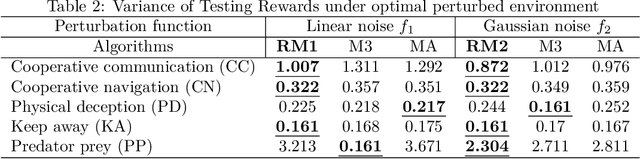
In real-world multi-agent reinforcement learning (MARL) applications, agents may not have perfect state information (e.g., due to inaccurate measurement or malicious attacks), which challenges the robustness of agents' policies. Though robustness is getting important in MARL deployment, little prior work has studied state uncertainties in MARL, neither in problem formulation nor algorithm design. Motivated by this robustness issue and the lack of corresponding studies, we study the problem of MARL with state uncertainty in this work. We provide the first attempt to the theoretical and empirical analysis of this challenging problem. We first model the problem as a Markov Game with state perturbation adversaries (MG-SPA) by introducing a set of state perturbation adversaries into a Markov Game. We then introduce robust equilibrium (RE) as the solution concept of an MG-SPA. We conduct a fundamental analysis regarding MG-SPA such as giving conditions under which such a robust equilibrium exists. Then we propose a robust multi-agent Q-learning (RMAQ) algorithm to find such an equilibrium, with convergence guarantees. To handle high-dimensional state-action space, we design a robust multi-agent actor-critic (RMAAC) algorithm based on an analytical expression of the policy gradient derived in the paper. Our experiments show that the proposed RMAQ algorithm converges to the optimal value function; our RMAAC algorithm outperforms several MARL and robust MARL methods in multiple multi-agent environments when state uncertainty is present. The source code is public on \url{https://github.com/sihongho/robust_marl_with_state_uncertainty}.
HiFi: High-Information Attention Heads Hold for Parameter-Efficient Model Adaptation
May 08, 2023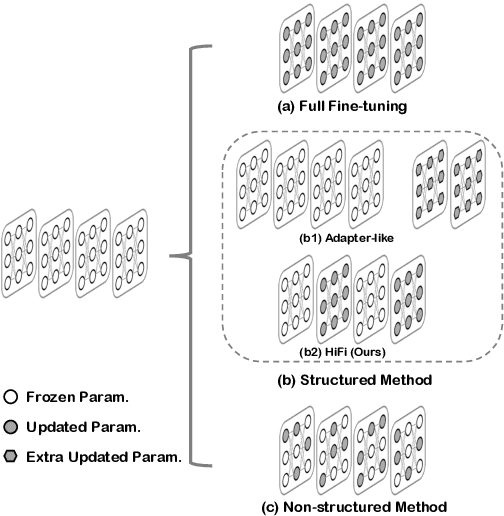
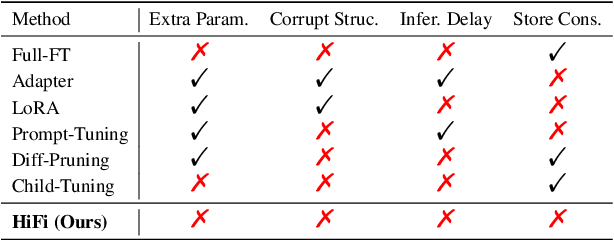
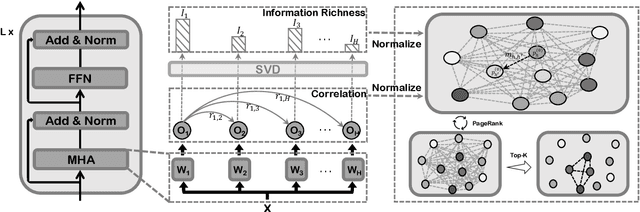
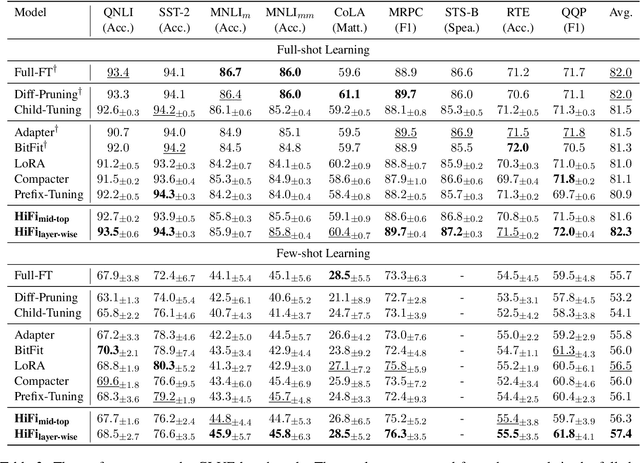
To fully leverage the advantages of large-scale pre-trained language models (PLMs) on downstream tasks, it has become a ubiquitous adaptation paradigm to fine-tune the entire parameters of PLMs. However, this paradigm poses issues of inefficient updating and resource over-consuming for fine-tuning in data-scarce and resource-limited scenarios, because of the large scale of parameters in PLMs. To alleviate these concerns, in this paper, we propose a parameter-efficient fine-tuning method HiFi, that is, only the highly informative and strongly correlated attention heads for the specific task are fine-tuned. To search for those significant attention heads, we develop a novel framework to analyze the effectiveness of heads. Specifically, we first model the relationship between heads into a graph from two perspectives of information richness and correlation, and then apply PageRank algorithm to determine the relative importance of each head. Extensive experiments on the GLUE benchmark demonstrate the effectiveness of our method, and show that HiFi obtains state-of-the-art performance over the prior baselines.
Retrieving Comparative Arguments using Ensemble Methods and Neural Information Retrieval
May 01, 2023
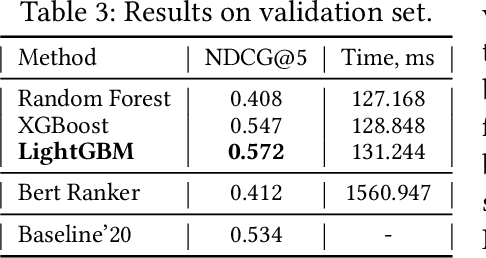


In this paper, we present a submission to the Touche lab's Task 2 on Argument Retrieval for Comparative Questions. Our team Katana supplies several approaches based on decision tree ensembles algorithms to rank comparative documents in accordance with their relevance and argumentative support. We use PyTerrier library to apply ensembles models to a ranking problem, considering statistical text features and features based on comparative structures. We also employ large contextualized language modelling techniques, such as BERT, to solve the proposed ranking task. To merge this technique with ranking modelling, we leverage neural ranking library OpenNIR. Our systems substantially outperforming the proposed baseline and scored first in relevance and second in quality according to the official metrics of the competition (for measure NDCG@5 score). Presented models could help to improve the performance of processing comparative queries in information retrieval and dialogue systems.
DIALGEN: Collaborative Human-LM Generated Dialogues for Improved Understanding of Human-Human Conversations
Jul 13, 2023
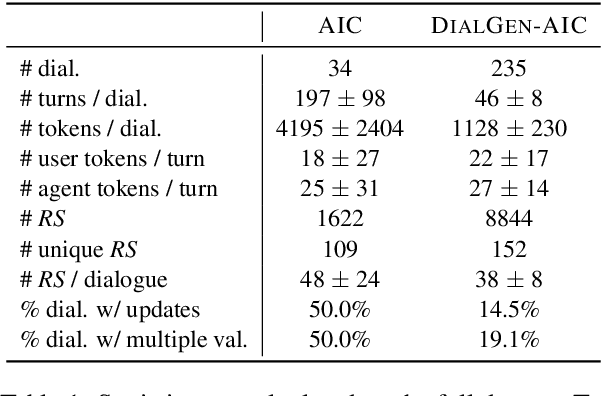
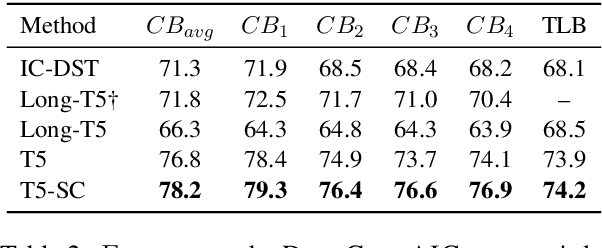
Applications that could benefit from automatic understanding of human-human conversations often come with challenges associated with private information in real-world data such as call center or clinical conversations. Working with protected data also increases costs of annotation, which limits technology development. To address these challenges, we propose DIALGEN, a human-in-the-loop semi-automated dialogue generation framework. DIALGEN uses a language model (ChatGPT) that can follow schema and style specifications to produce fluent conversational text, generating a complex conversation through iteratively generating subdialogues and using human feedback to correct inconsistencies or redirect the flow. In experiments on structured summarization of agent-client information gathering calls, framed as dialogue state tracking, we show that DIALGEN data enables significant improvement in model performance.
Towards Ontologically Grounded and Language-Agnostic Knowledge Graphs
Jul 20, 2023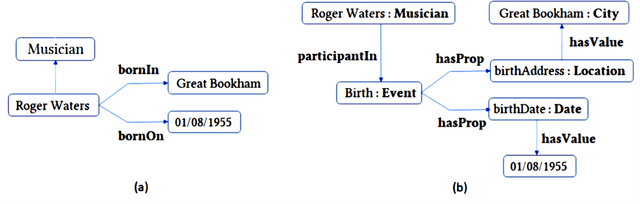


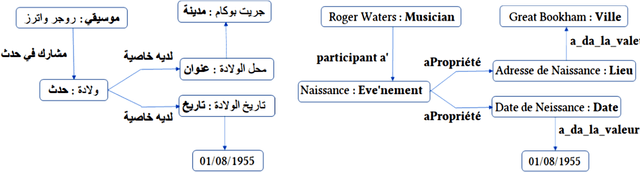
Knowledge graphs (KGs) have become the standard technology for the representation of factual information in applications such as recommendation engines, search, and question-answering systems. However, the continual updating of KGs, as well as the integration of KGs from different domains and KGs in different languages, remains to be a major challenge. What we suggest here is that by a reification of abstract objects and by acknowledging the ontological distinction between concepts and types, we arrive at an ontologically grounded and language-agnostic representation that can alleviate the difficulties in KG integration.
Self-Supervised Contrastive BERT Fine-tuning for Fusion-based Reviewed-Item Retrieval
Aug 01, 2023As natural language interfaces enable users to express increasingly complex natural language queries, there is a parallel explosion of user review content that can allow users to better find items such as restaurants, books, or movies that match these expressive queries. While Neural Information Retrieval (IR) methods have provided state-of-the-art results for matching queries to documents, they have not been extended to the task of Reviewed-Item Retrieval (RIR), where query-review scores must be aggregated (or fused) into item-level scores for ranking. In the absence of labeled RIR datasets, we extend Neural IR methodology to RIR by leveraging self-supervised methods for contrastive learning of BERT embeddings for both queries and reviews. Specifically, contrastive learning requires a choice of positive and negative samples, where the unique two-level structure of our item-review data combined with meta-data affords us a rich structure for the selection of these samples. For contrastive learning in a Late Fusion scenario, we investigate the use of positive review samples from the same item and/or with the same rating, selection of hard positive samples by choosing the least similar reviews from the same anchor item, and selection of hard negative samples by choosing the most similar reviews from different items. We also explore anchor sub-sampling and augmenting with meta-data. For a more end-to-end Early Fusion approach, we introduce contrastive item embedding learning to fuse reviews into single item embeddings. Experimental results show that Late Fusion contrastive learning for Neural RIR outperforms all other contrastive IR configurations, Neural IR, and sparse retrieval baselines, thus demonstrating the power of exploiting the two-level structure in Neural RIR approaches as well as the importance of preserving the nuance of individual review content via Late Fusion methods.
DriveAdapter: Breaking the Coupling Barrier of Perception and Planning in End-to-End Autonomous Driving
Aug 01, 2023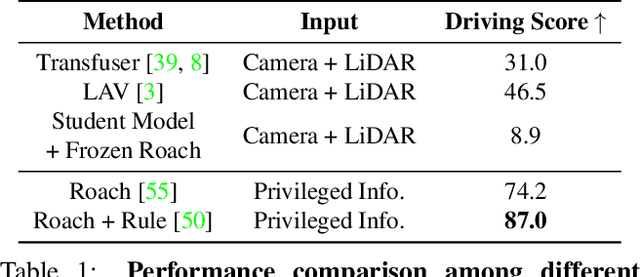
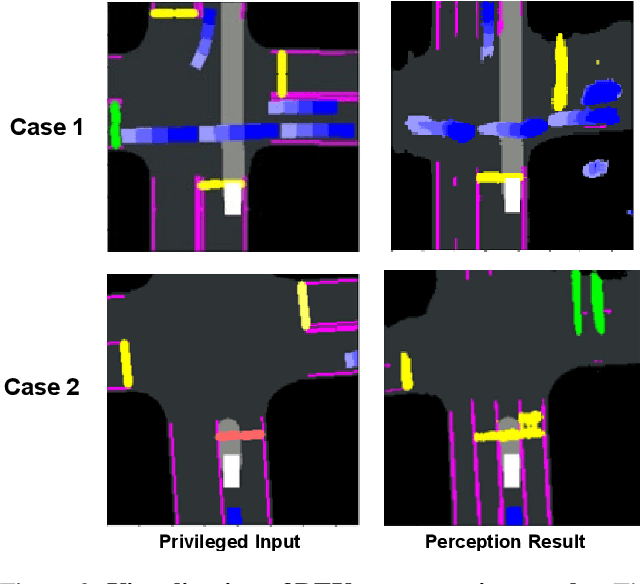
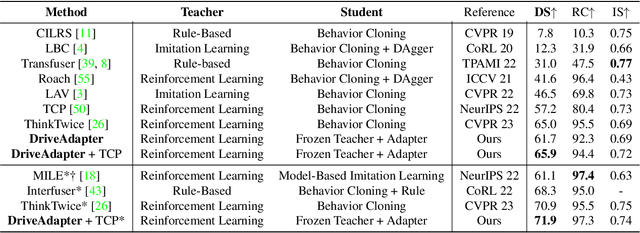
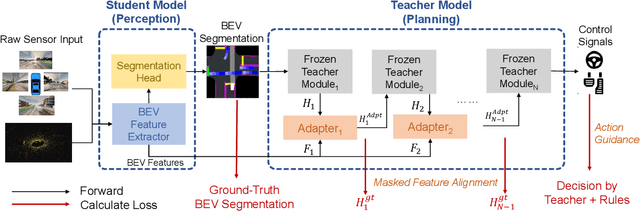
End-to-end autonomous driving aims to build a fully differentiable system that takes raw sensor data as inputs and directly outputs the planned trajectory or control signals of the ego vehicle. State-of-the-art methods usually follow the `Teacher-Student' paradigm. The Teacher model uses privileged information (ground-truth states of surrounding agents and map elements) to learn the driving strategy. The student model only has access to raw sensor data and conducts behavior cloning on the data collected by the teacher model. By eliminating the noise of the perception part during planning learning, state-of-the-art works could achieve better performance with significantly less data compared to those coupled ones. However, under the current Teacher-Student paradigm, the student model still needs to learn a planning head from scratch, which could be challenging due to the redundant and noisy nature of raw sensor inputs and the casual confusion issue of behavior cloning. In this work, we aim to explore the possibility of directly adopting the strong teacher model to conduct planning while letting the student model focus more on the perception part. We find that even equipped with a SOTA perception model, directly letting the student model learn the required inputs of the teacher model leads to poor driving performance, which comes from the large distribution gap between predicted privileged inputs and the ground-truth. To this end, we propose DriveAdapter, which employs adapters with the feature alignment objective function between the student (perception) and teacher (planning) modules. Additionally, since the pure learning-based teacher model itself is imperfect and occasionally breaks safety rules, we propose a method of action-guided feature learning with a mask for those imperfect teacher features to further inject the priors of hand-crafted rules into the learning process.
Discourse-Aware Text Simplification: From Complex Sentences to Linked Propositions
Aug 01, 2023
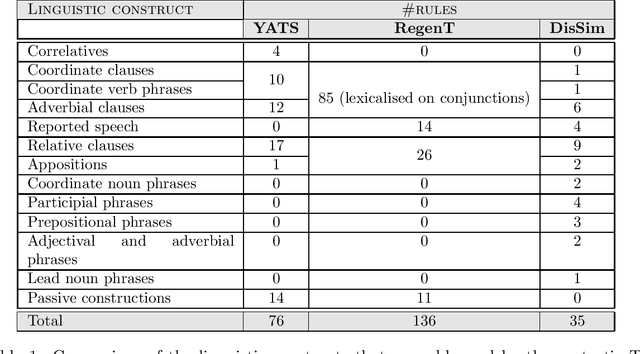
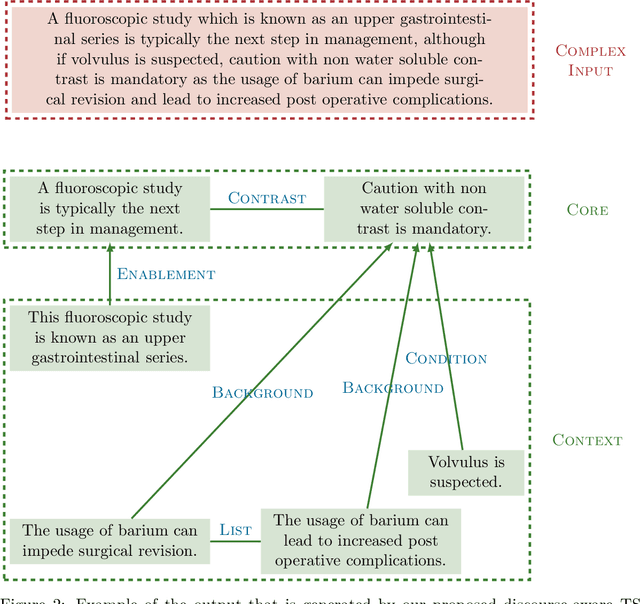

Sentences that present a complex syntax act as a major stumbling block for downstream Natural Language Processing applications whose predictive quality deteriorates with sentence length and complexity. The task of Text Simplification (TS) may remedy this situation. It aims to modify sentences in order to make them easier to process, using a set of rewriting operations, such as reordering, deletion, or splitting. State-of-the-art syntactic TS approaches suffer from two major drawbacks: first, they follow a very conservative approach in that they tend to retain the input rather than transforming it, and second, they ignore the cohesive nature of texts, where context spread across clauses or sentences is needed to infer the true meaning of a statement. To address these problems, we present a discourse-aware TS approach that splits and rephrases complex English sentences within the semantic context in which they occur. Based on a linguistically grounded transformation stage that uses clausal and phrasal disembedding mechanisms, complex sentences are transformed into shorter utterances with a simple canonical structure that can be easily analyzed by downstream applications. With sentence splitting, we thus address a TS task that has hardly been explored so far. Moreover, we introduce the notion of minimality in this context, as we aim to decompose source sentences into a set of self-contained minimal semantic units. To avoid breaking down the input into a disjointed sequence of statements that is difficult to interpret because important contextual information is missing, we incorporate the semantic context between the split propositions in the form of hierarchical structures and semantic relationships. In that way, we generate a semantic hierarchy of minimal propositions that leads to a novel representation of complex assertions that puts a semantic layer on top of the simplified sentences.