 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive Segmentation Network for Scene Text Detection
Jul 27, 2023
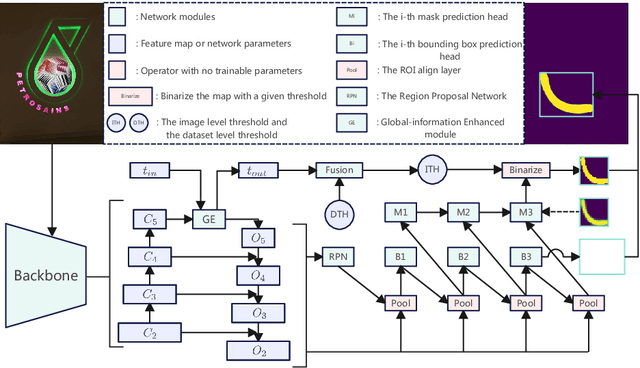
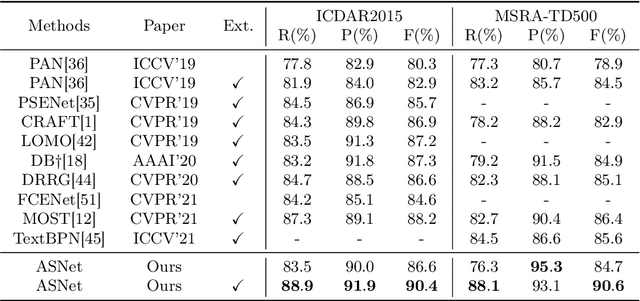
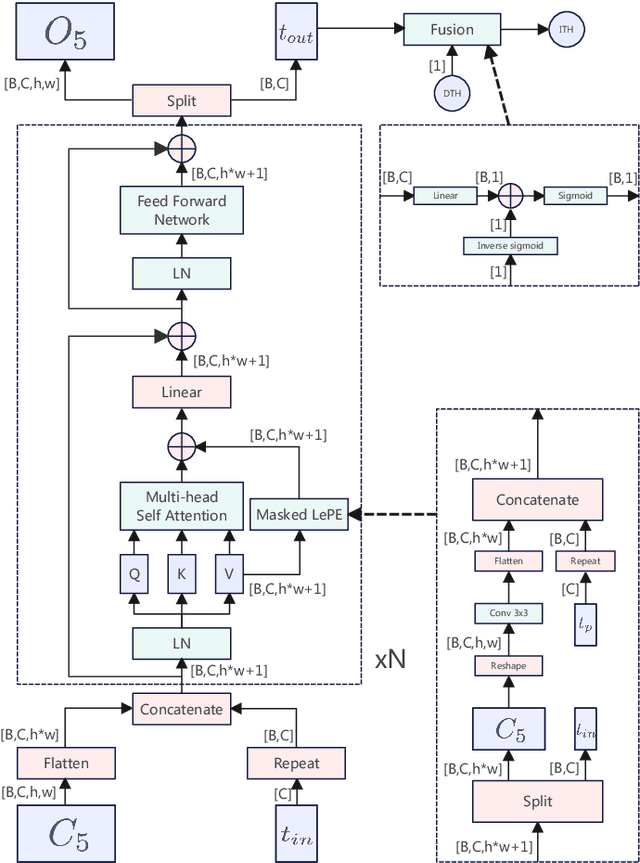
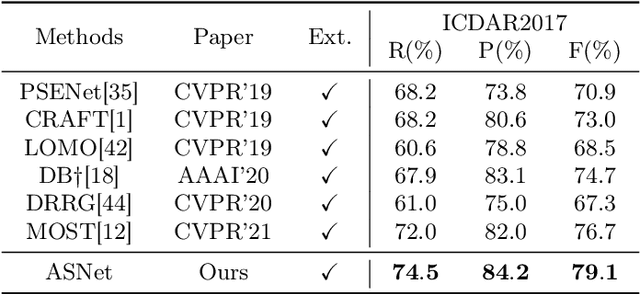
Inspired by deep convolution segmentation algorithms, scene text detectors break the performance ceiling of datasets steadily. However, these methods often encounter threshold selection bottlenecks and have poor performance on text instances with extreme aspect ratios. In this paper, we propose to automatically learn the discriminate segmentation threshold, which distinguishes text pixels from background pixels for segmentation-based scene text detectors and then further reduces the time-consuming manual parameter adjustment. Besides, we design a Global-information Enhanced Feature Pyramid Network (GE-FPN) for capturing text instances with macro size and extreme aspect ratios. Following the GE-FPN, we introduce a cascade optimization structure to further refine the text instances. Finally, together with the proposed threshold learning strategy and text detection structure, we design an Adaptive Segmentation Network (ASNet) for scene text detection. Extensive experiments are carried out to demonstrate that the proposed ASNet can achieve the state-of-the-art performance on four text detection benchmarks, i.e., ICDAR 2015, MSRA-TD500, ICDAR 2017 MLT and CTW1500. The ablation experiments also verify the effectiveness of our contributions.
Performance of RIS-Assisted Full-Duplex Space Shift Keying With Imperfect Self-Interference Cancellation
Jul 27, 2023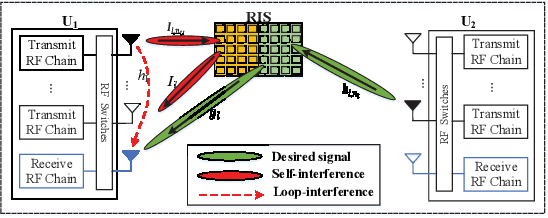
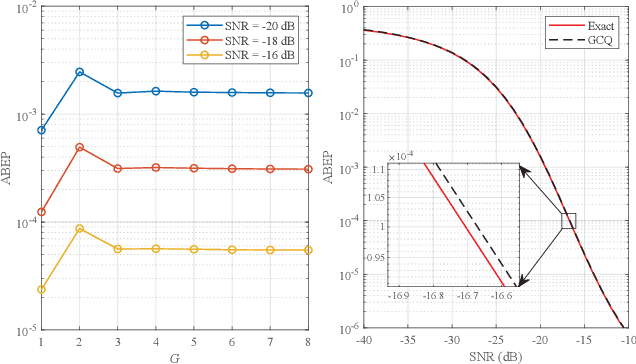
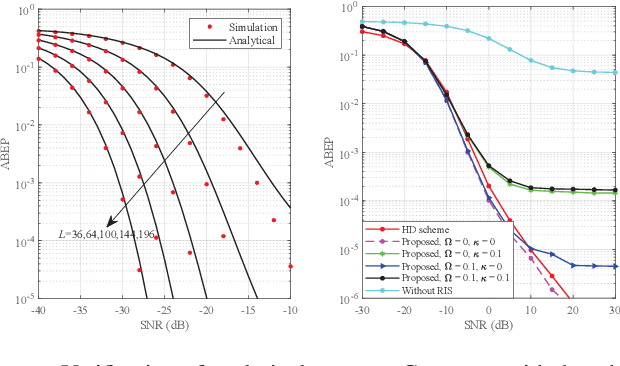
In this paper, we consider a full-duplex (FD) space shift keying (SSK) communication system, where information exchange between two users is assisted only by a reconfigurable intelligent surface (RIS). In particular, the impact of loop interference (LI) between the transmit and receive antennas as well as residual self-interference (SI) from the RIS is considered. Based on the maximum likelihood detector, we derive the conditional pairwise error probability and the numerical integration expression for the unconditional pairwise error probability (UPEP). Since it is difficult to find a closed-form solution, we perform accurate estimation by the Gauss-Chebyshev quadrature (GCQ) method. To gain more useful insights, we derive an expression for UPEP in the high signal-to-noise ratio region and further give the average bit error probability (ABEP) expression. Monte Carlo simulations were performed to validate the derived results. It is found that SI and LI have severe impacts on system performance. Fortunately, these two disturbances can be well counteracted by increasing the number of RIS units.
Visual Information Matters for ASR Error Correction
Mar 16, 2023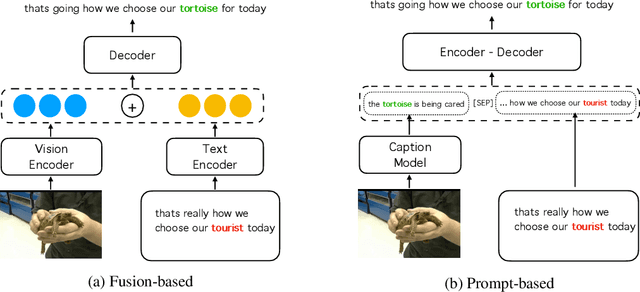
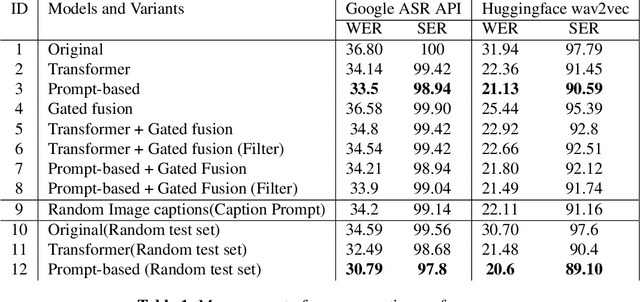


Aiming to improve the Automatic Speech Recognition (ASR) outputs with a post-processing step, ASR error correction (EC) techniques have been widely developed due to their efficiency in using parallel text data. Previous works mainly focus on using text or/ and speech data, which hinders the performance gain when not only text and speech information, but other modalities, such as visual information are critical for EC. The challenges are mainly two folds: one is that previous work fails to emphasize visual information, thus rare exploration has been studied. The other is that the community lacks a high-quality benchmark where visual information matters for the EC models. Therefore, this paper provides 1) simple yet effective methods, namely gated fusion and image captions as prompts to incorporate visual information to help EC; 2) large-scale benchmark datasets, namely Visual-ASR-EC, where each item in the training data consists of visual, speech, and text information, and the test data are carefully selected by human annotators to ensure that even humans could make mistakes when visual information is missing. Experimental results show that using captions as prompts could effectively use the visual information and surpass state-of-the-art methods by upto 1.2% in Word Error Rate(WER), which also indicates that visual information is critical in our proposed Visual-ASR-EC dataset
ConTrack: Contextual Transformer for Device Tracking in X-ray
Jul 14, 2023Device tracking is an important prerequisite for guidance during endovascular procedures. Especially during cardiac interventions, detection and tracking of guiding the catheter tip in 2D fluoroscopic images is important for applications such as mapping vessels from angiography (high dose with contrast) to fluoroscopy (low dose without contrast). Tracking the catheter tip poses different challenges: the tip can be occluded by contrast during angiography or interventional devices; and it is always in continuous movement due to the cardiac and respiratory motions. To overcome these challenges, we propose ConTrack, a transformer-based network that uses both spatial and temporal contextual information for accurate device detection and tracking in both X-ray fluoroscopy and angiography. The spatial information comes from the template frames and the segmentation module: the template frames define the surroundings of the device, whereas the segmentation module detects the entire device to bring more context for the tip prediction. Using multiple templates makes the model more robust to the change in appearance of the device when it is occluded by the contrast agent. The flow information computed on the segmented catheter mask between the current and the previous frame helps in further refining the prediction by compensating for the respiratory and cardiac motions. The experiments show that our method achieves 45% or higher accuracy in detection and tracking when compared to state-of-the-art tracking models.
A Human-in-the-Loop Approach for Information Extraction from Privacy Policies under Data Scarcity
May 24, 2023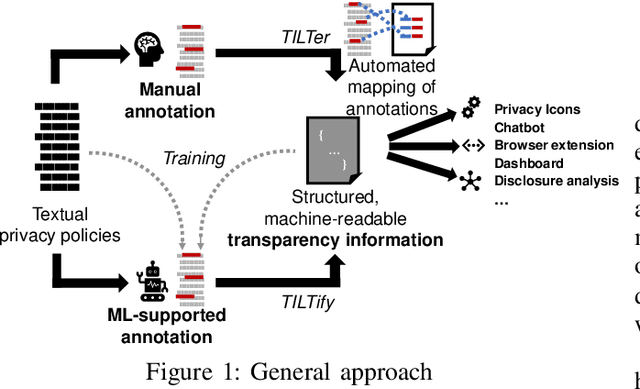
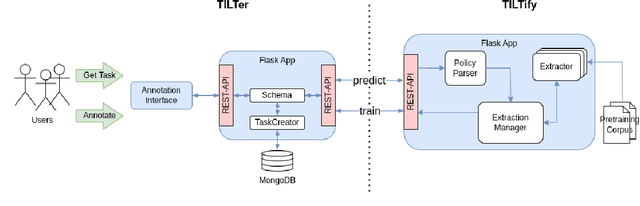
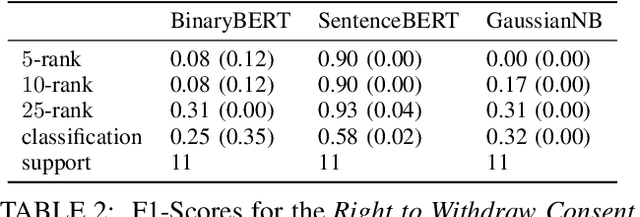
Machine-readable representations of privacy policies are door openers for a broad variety of novel privacy-enhancing and, in particular, transparency-enhancing technologies (TETs). In order to generate such representations, transparency information needs to be extracted from written privacy policies. However, respective manual annotation and extraction processes are laborious and require expert knowledge. Approaches for fully automated annotation, in turn, have so far not succeeded due to overly high error rates in the specific domain of privacy policies. In the end, a lack of properly annotated privacy policies and respective machine-readable representations persists and enduringly hinders the development and establishment of novel technical approaches fostering policy perception and data subject informedness. In this work, we present a prototype system for a `Human-in-the-Loop' approach to privacy policy annotation that integrates ML-generated suggestions and ultimately human annotation decisions. We propose an ML-based suggestion system specifically tailored to the constraint of data scarcity prevalent in the domain of privacy policy annotation. On this basis, we provide meaningful predictions to users thereby streamlining the annotation process. Additionally, we also evaluate our approach through a prototypical implementation to show that our ML-based extraction approach provides superior performance over other recently used extraction models for legal documents.
Rethinking Data Distillation: Do Not Overlook Calibration
Jul 24, 2023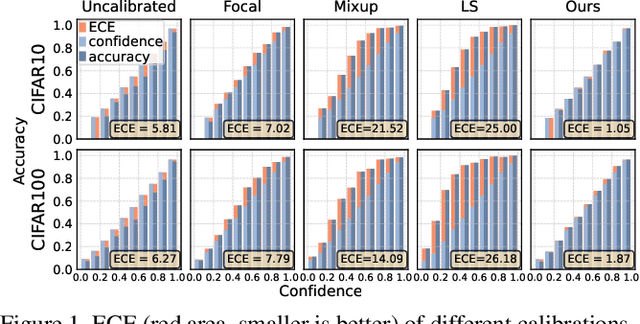
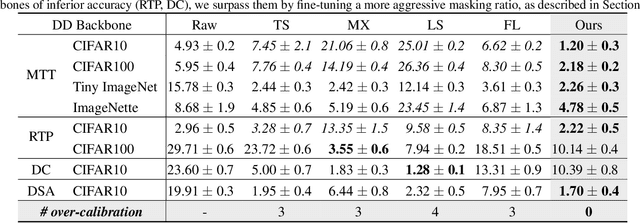
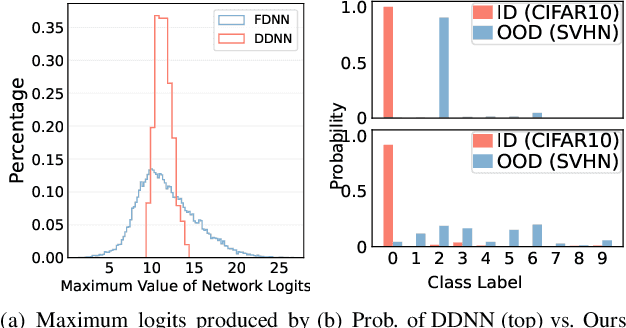
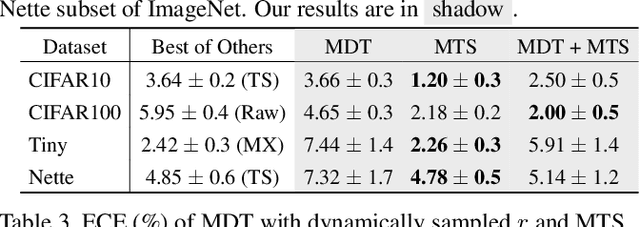
Neural networks trained on distilled data often produce over-confident output and require correction by calibration methods. Existing calibration methods such as temperature scaling and mixup work well for networks trained on original large-scale data. However, we find that these methods fail to calibrate networks trained on data distilled from large source datasets. In this paper, we show that distilled data lead to networks that are not calibratable due to (i) a more concentrated distribution of the maximum logits and (ii) the loss of information that is semantically meaningful but unrelated to classification tasks. To address this problem, we propose Masked Temperature Scaling (MTS) and Masked Distillation Training (MDT) which mitigate the limitations of distilled data and achieve better calibration results while maintaining the efficiency of dataset distillation.
Towards Trustworthy and Aligned Machine Learning: A Data-centric Survey with Causality Perspectives
Jul 31, 2023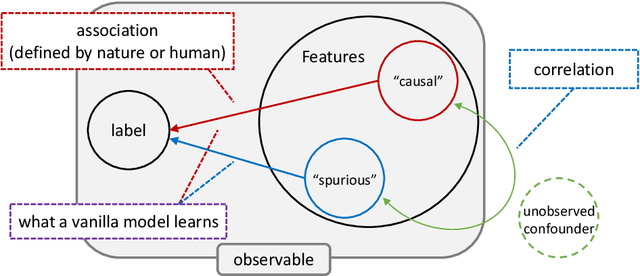
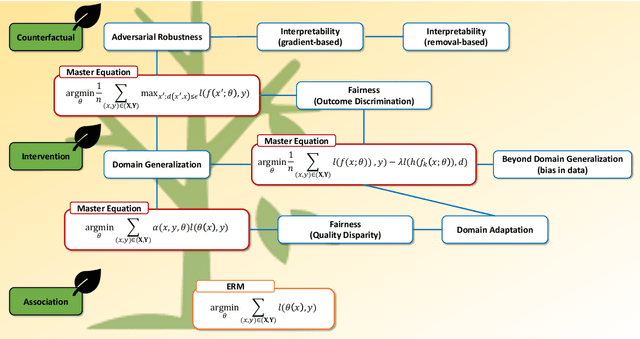
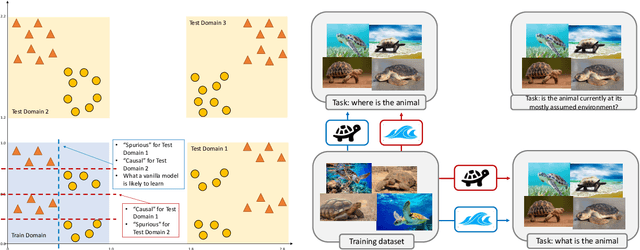
The trustworthiness of machine learning has emerged as a critical topic in the field, encompassing various applications and research areas such as robustness, security, interpretability, and fairness. The last decade saw the development of numerous methods addressing these challenges. In this survey, we systematically review these advancements from a data-centric perspective, highlighting the shortcomings of traditional empirical risk minimization (ERM) training in handling challenges posed by the data. Interestingly, we observe a convergence of these methods, despite being developed independently across trustworthy machine learning subfields. Pearl's hierarchy of causality offers a unifying framework for these techniques. Accordingly, this survey presents the background of trustworthy machine learning development using a unified set of concepts, connects this language to Pearl's causal hierarchy, and finally discusses methods explicitly inspired by causality literature. We provide a unified language with mathematical vocabulary to link these methods across robustness, adversarial robustness, interpretability, and fairness, fostering a more cohesive understanding of the field. Further, we explore the trustworthiness of large pretrained models. After summarizing dominant techniques like fine-tuning, parameter-efficient fine-tuning, prompting, and reinforcement learning with human feedback, we draw connections between them and the standard ERM. This connection allows us to build upon the principled understanding of trustworthy methods, extending it to these new techniques in large pretrained models, paving the way for future methods. Existing methods under this perspective are also reviewed. Lastly, we offer a brief summary of the applications of these methods and discuss potential future aspects related to our survey. For more information, please visit http://trustai.one.
Towards Precise Weakly Supervised Object Detection via Interactive Contrastive Learning of Context Information
Apr 27, 2023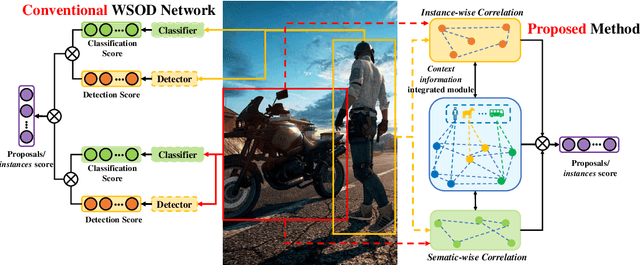
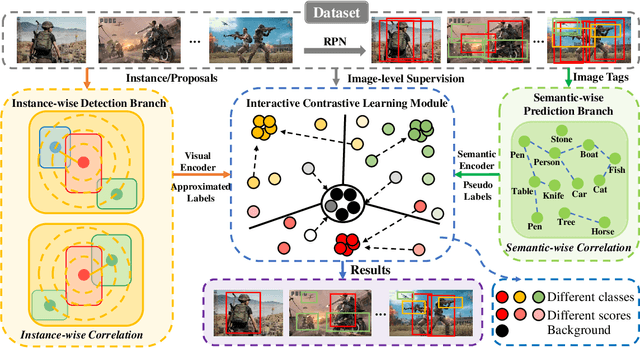
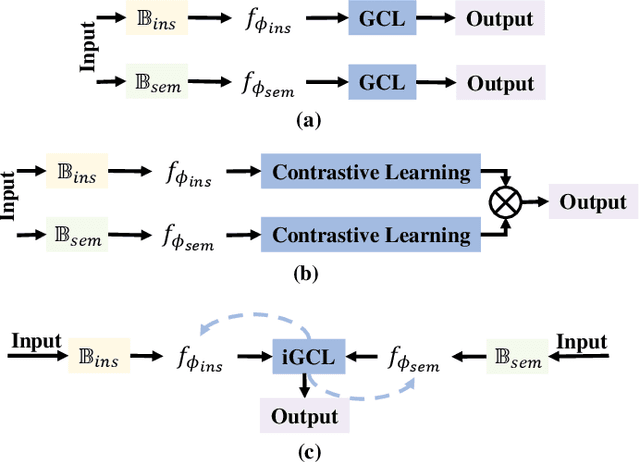

Weakly supervised object detection (WSOD) aims at learning precise object detectors with only image-level tags. In spite of intensive research on deep learning (DL) approaches over the past few years, there is still a significant performance gap between WSOD and fully supervised object detection. In fact, most existing WSOD methods only consider the visual appearance of each region proposal but ignore employing the useful context information in the image. To this end, this paper proposes an interactive end-to-end WSDO framework called JLWSOD with two innovations: i) two types of WSOD-specific context information (i.e., instance-wise correlation andsemantic-wise correlation) are proposed and introduced into WSOD framework; ii) an interactive graph contrastive learning (iGCL) mechanism is designed to jointly optimize the visual appearance and context information for better WSOD performance. Specifically, the iGCL mechanism takes full advantage of the complementary interpretations of the WSOD, namely instance-wise detection and semantic-wise prediction tasks, forming a more comprehensive solution. Extensive experiments on the widely used PASCAL VOC and MS COCO benchmarks verify the superiority of JLWSOD over alternative state-of-the-art approaches and baseline models (improvement of 3.6%~23.3% on mAP and 3.4%~19.7% on CorLoc, respectively).
CohortGPT: An Enhanced GPT for Participant Recruitment in Clinical Study
Jul 21, 2023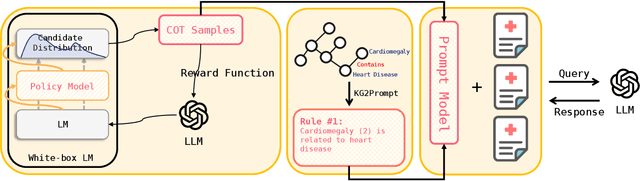

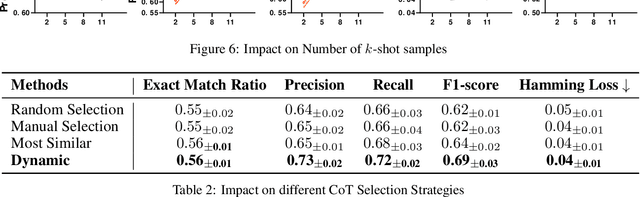
Participant recruitment based on unstructured medical texts such as clinical notes and radiology reports has been a challenging yet important task for the cohort establishment in clinical research. Recently, Large Language Models (LLMs) such as ChatGPT have achieved tremendous success in various downstream tasks thanks to their promising performance in language understanding, inference, and generation. It is then natural to test their feasibility in solving the cohort recruitment task, which involves the classification of a given paragraph of medical text into disease label(s). However, when applied to knowledge-intensive problem settings such as medical text classification, where the LLMs are expected to understand the decision made by human experts and accurately identify the implied disease labels, the LLMs show a mediocre performance. A possible explanation is that, by only using the medical text, the LLMs neglect to use the rich context of additional information that languages afford. To this end, we propose to use a knowledge graph as auxiliary information to guide the LLMs in making predictions. Moreover, to further boost the LLMs adapt to the problem setting, we apply a chain-of-thought (CoT) sample selection strategy enhanced by reinforcement learning, which selects a set of CoT samples given each individual medical report. Experimental results and various ablation studies show that our few-shot learning method achieves satisfactory performance compared with fine-tuning strategies and gains superb advantages when the available data is limited. The code and sample dataset of the proposed CohortGPT model is available at: https://anonymous.4open.science/r/CohortGPT-4872/
MORE: Measurement and Correlation Based Variational Quantum Circuit for Multi-classification
Jul 21, 2023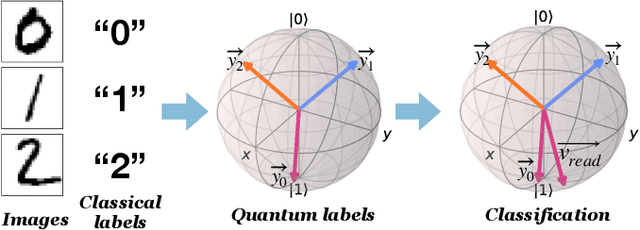
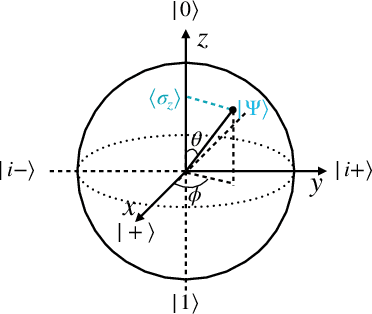
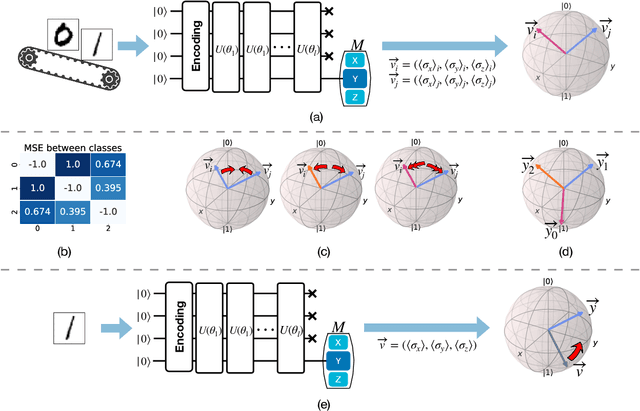
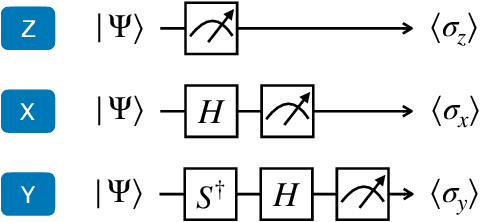
Quantum computing has shown considerable promise for compute-intensive tasks in recent years. For instance, classification tasks based on quantum neural networks (QNN) have garnered significant interest from researchers and have been evaluated in various scenarios. However, the majority of quantum classifiers are currently limited to binary classification tasks due to either constrained quantum computing resources or the need for intensive classical post-processing. In this paper, we propose an efficient quantum multi-classifier called MORE, which stands for measurement and correlation based variational quantum multi-classifier. MORE adopts the same variational ansatz as binary classifiers while performing multi-classification by fully utilizing the quantum information of a single readout qubit. To extract the complete information from the readout qubit, we select three observables that form the basis of a two-dimensional Hilbert space. We then use the quantum state tomography technique to reconstruct the readout state from the measurement results. Afterward, we explore the correlation between classes to determine the quantum labels for classes using the variational quantum clustering approach. Next, quantum label-based supervised learning is performed to identify the mapping between the input data and their corresponding quantum labels. Finally, the predicted label is determined by its closest quantum label when using the classifier. We implement this approach using the Qiskit Python library and evaluate it through extensive experiments on both noise-free and noisy quantum systems. Our evaluation results demonstrate that MORE, despite using a simple ansatz and limited quantum resources, achieves advanced performance.