 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Duet: efficient and scalable hybriD neUral rElation undersTanding
Jul 28, 2023
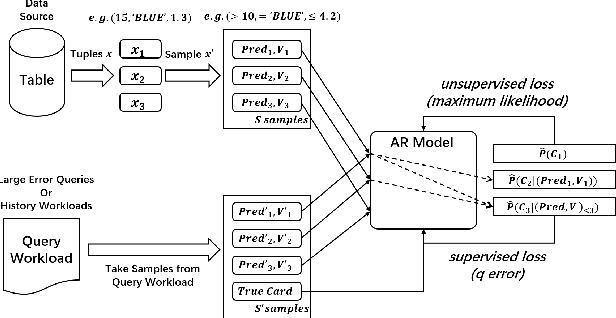
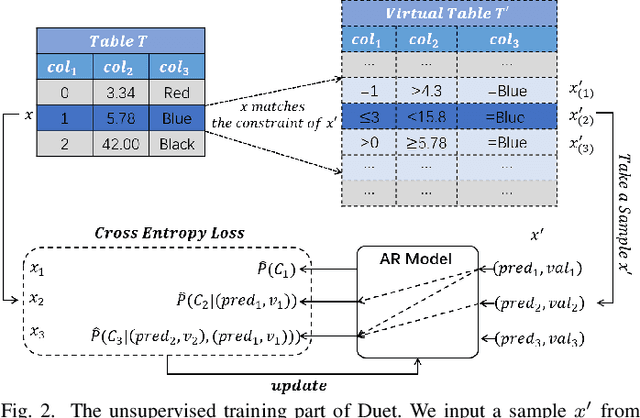
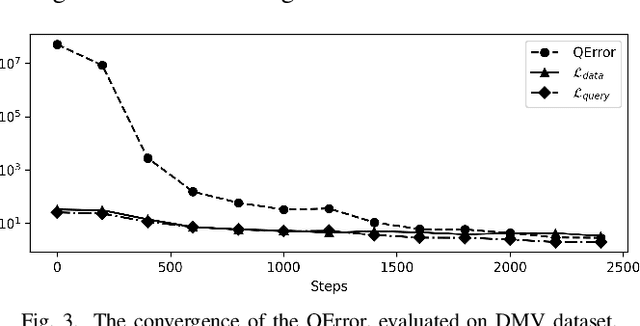
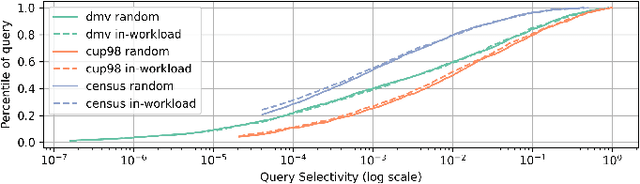
Learned cardinality estimation methods have achieved high precision compared to traditional methods. Among learned methods, query-driven approaches face the data and workload drift problem for a long time. Although both query-driven and hybrid methods are proposed to avoid this problem, even the state-of-the-art of them suffer from high training and estimation costs, limited scalability, instability, and long-tailed distribution problem on high cardinality and high-dimensional tables, which seriously affects the practical application of learned cardinality estimators. In this paper, we prove that most of these problems are directly caused by the widely used progressive sampling. We solve this problem by introducing predicates information into the autoregressive model and propose Duet, a stable, efficient, and scalable hybrid method to estimate cardinality directly without sampling or any non-differentiable process, which can not only reduces the inference complexity from O(n) to O(1) compared to Naru and UAE but also achieve higher accuracy on high cardinality and high-dimensional tables. Experimental results show that Duet can achieve all the design goals above and be much more practical and even has a lower inference cost on CPU than that of most learned methods on GPU.
Noise-aware Speech Enhancement using Diffusion Probabilistic Model
Jul 16, 2023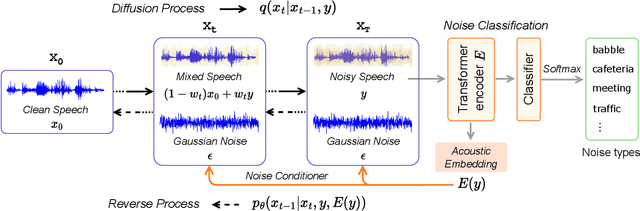
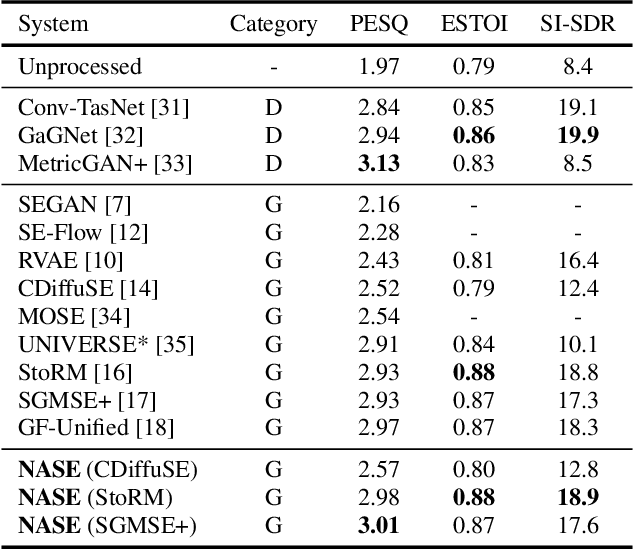
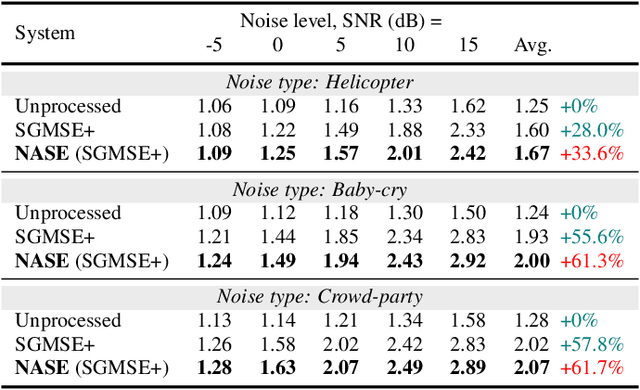
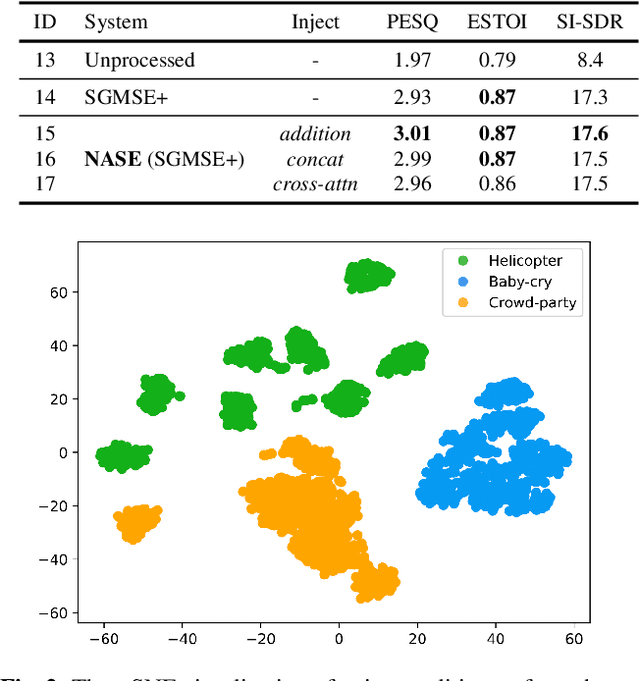
With recent advances of diffusion model, generative speech enhancement (SE) has attracted a surge of research interest due to its great potential for unseen testing noises. However, existing efforts mainly focus on inherent properties of clean speech for inference, underexploiting the varying noise information in real-world conditions. In this paper, we propose a noise-aware speech enhancement (NASE) approach that extracts noise-specific information to guide the reverse process in diffusion model. Specifically, we design a noise classification (NC) model to produce acoustic embedding as a noise conditioner for guiding the reverse denoising process. Meanwhile, a multi-task learning scheme is devised to jointly optimize SE and NC tasks, in order to enhance the noise specificity of extracted noise conditioner. Our proposed NASE is shown to be a plug-and-play module that can be generalized to any diffusion SE models. Experiment evidence on VoiceBank-DEMAND dataset shows that NASE achieves significant improvement over multiple mainstream diffusion SE models, especially on unseen testing noises.
Knowledge Boosting: Rethinking Medical Contrastive Vision-Language Pre-Training
Jul 17, 2023
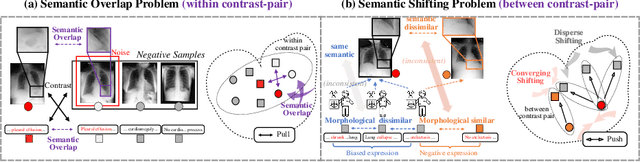
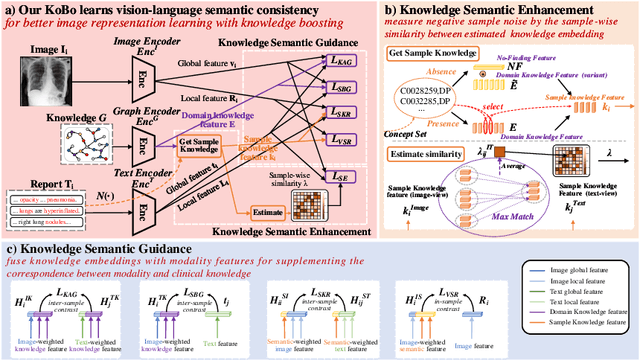
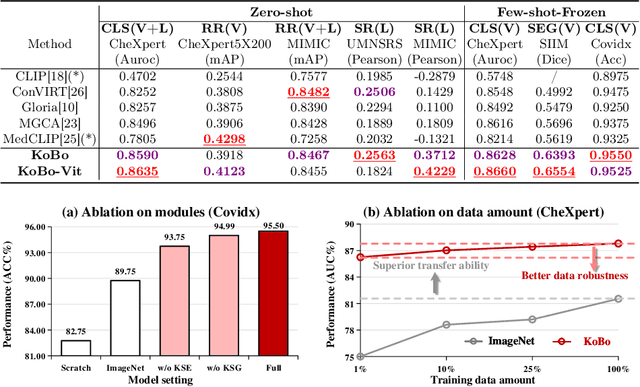
The foundation models based on pre-training technology have significantly advanced artificial intelligence from theoretical to practical applications. These models have facilitated the feasibility of computer-aided diagnosis for widespread use. Medical contrastive vision-language pre-training, which does not require human annotations, is an effective approach for guiding representation learning using description information in diagnostic reports. However, the effectiveness of pre-training is limited by the large-scale semantic overlap and shifting problems in medical field. To address these issues, we propose the Knowledge-Boosting Contrastive Vision-Language Pre-training framework (KoBo), which integrates clinical knowledge into the learning of vision-language semantic consistency. The framework uses an unbiased, open-set sample-wise knowledge representation to measure negative sample noise and supplement the correspondence between vision-language mutual information and clinical knowledge. Extensive experiments validate the effect of our framework on eight tasks including classification, segmentation, retrieval, and semantic relatedness, achieving comparable or better performance with the zero-shot or few-shot settings. Our code is open on https://github.com/ChenXiaoFei-CS/KoBo.
A Nested U-Structure for Instrument Segmentation in Robotic Surgery
Jul 17, 2023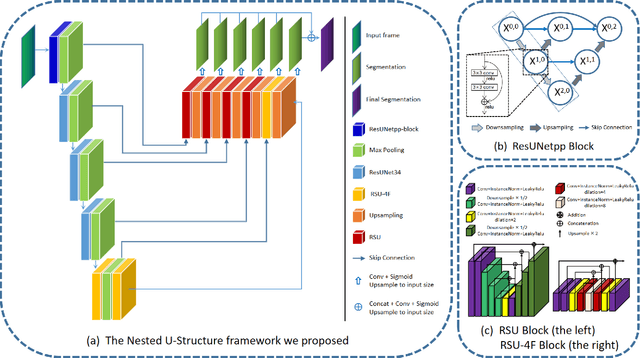
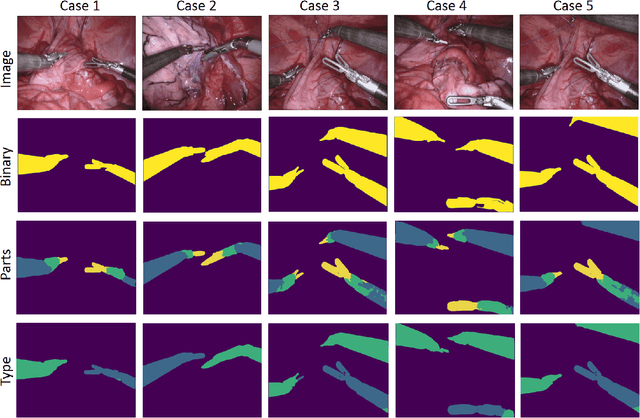

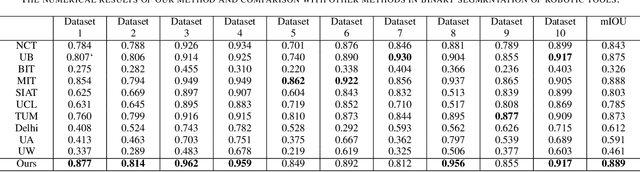
Robot-assisted surgery has made great progress with the development of medical imaging and robotics technology. Medical scene understanding can greatly improve surgical performance while the semantic segmentation of the robotic instrument is a key enabling technology for robot-assisted surgery. However, how to locate an instrument's position and estimate their pose in complex surgical environments is still a challenging fundamental problem. In this paper, pixel-wise instrument segmentation is investigated. The contributions of the paper are twofold: 1) We proposed a two-level nested U-structure model, which is an encoder-decoder architecture with skip-connections and each layer of the network structure adopts a U-structure instead of a simple superposition of convolutional layers. The model can capture more context information from multiple scales and better fuse the local and global information to achieve high-quality segmentation. 2) Experiments have been conducted to qualitatively and quantitatively show the performance of our approach on three segmentation tasks: the binary segmentation, the parts segmentation, and the type segmentation, respectively.
Benchmarking fixed-length Fingerprint Representations across different Embedding Sizes and Sensor Types
Jul 17, 2023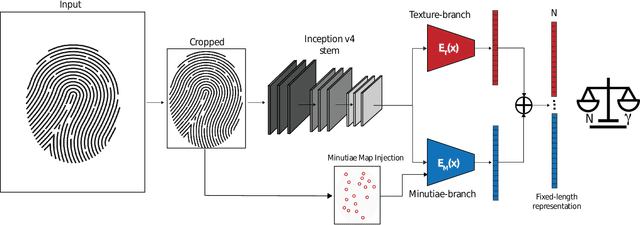
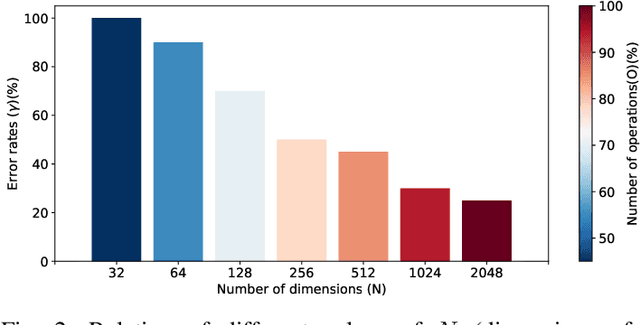

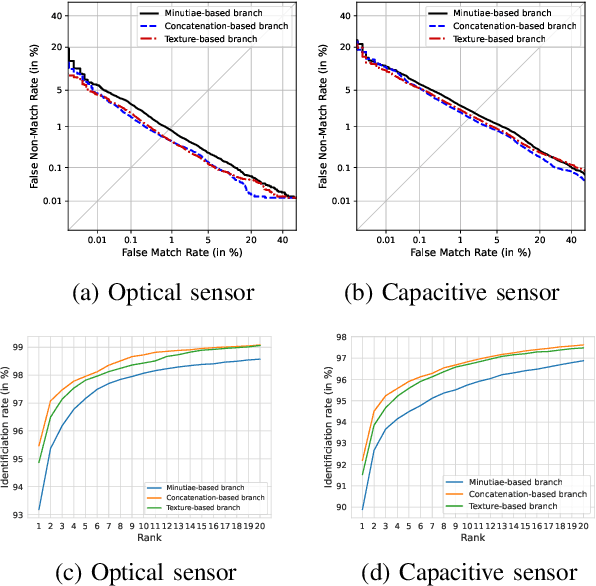
Traditional minutiae-based fingerprint representations consist of a variable-length set of minutiae. This necessitates a more complex comparison causing the drawback of high computational cost in one-to-many comparison. Recently, deep neural networks have been proposed to extract fixed-length embeddings from fingerprints. In this paper, we explore to what extent fingerprint texture information contained in such embeddings can be reduced in terms of dimension while preserving high biometric performance. This is of particular interest since it would allow to reduce the number of operations incurred at comparisons. We also study the impact in terms of recognition performance of the fingerprint textural information for two sensor types, i.e. optical and capacitive. Furthermore, the impact of rotation and translation of fingerprint images on the extraction of fingerprint embeddings is analysed. Experimental results conducted on a publicly available database reveal an optimal embedding size of 512 feature elements for the texture-based embedding part of fixed-length fingerprint representations. In addition, differences in performance between sensor types can be perceived.
A Multiobjective Reinforcement Learning Framework for Microgrid Energy Management
Jul 17, 2023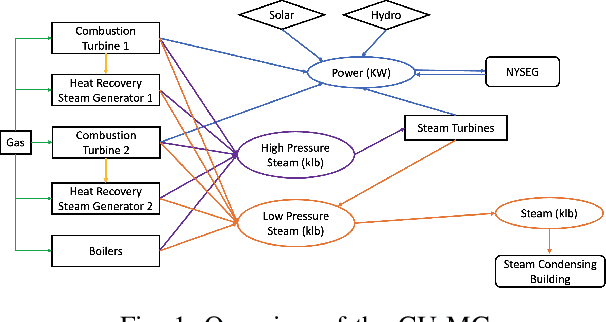
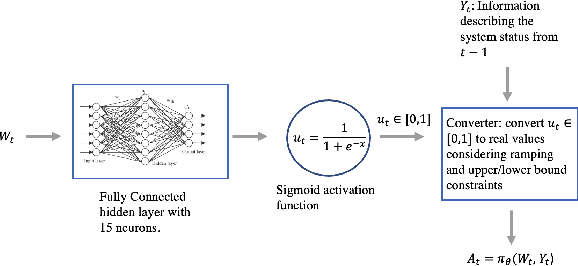
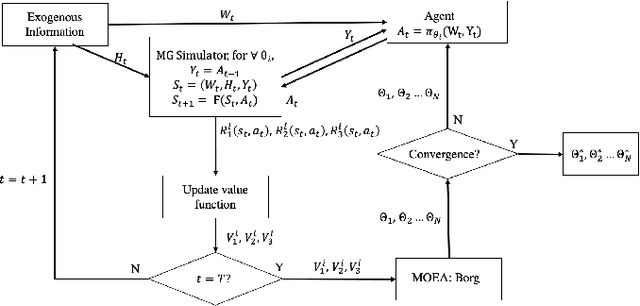
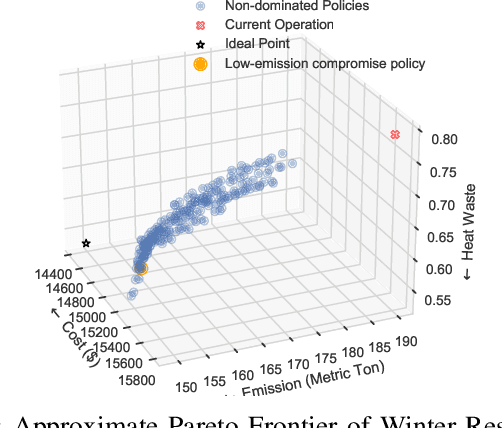
The emergence of microgrids (MGs) has provided a promising solution for decarbonizing and decentralizing the power grid, mitigating the challenges posed by climate change. However, MG operations often involve considering multiple objectives that represent the interests of different stakeholders, leading to potentially complex conflicts. To tackle this issue, we propose a novel multi-objective reinforcement learning framework that explores the high-dimensional objective space and uncovers the tradeoffs between conflicting objectives. This framework leverages exogenous information and capitalizes on the data-driven nature of reinforcement learning, enabling the training of a parametric policy without the need for long-term forecasts or knowledge of the underlying uncertainty distribution. The trained policies exhibit diverse, adaptive, and coordinative behaviors with the added benefit of providing interpretable insights on the dynamics of their information use. We employ this framework on the Cornell University MG (CU-MG), which is a combined heat and power MG, to evaluate its effectiveness. The results demonstrate performance improvements in all objectives considered compared to the status quo operations and offer more flexibility in navigating complex operational tradeoffs.
Towards Deeply Unified Depth-aware Panoptic Segmentation with Bi-directional Guidance Learning
Jul 27, 2023
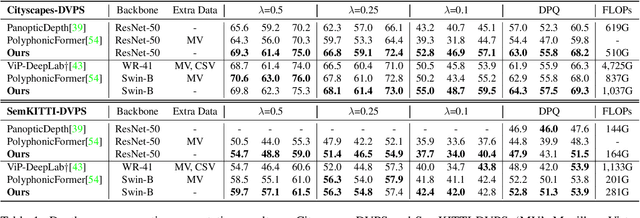
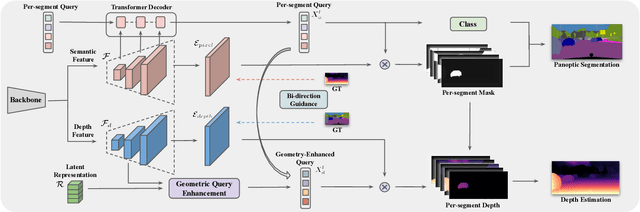
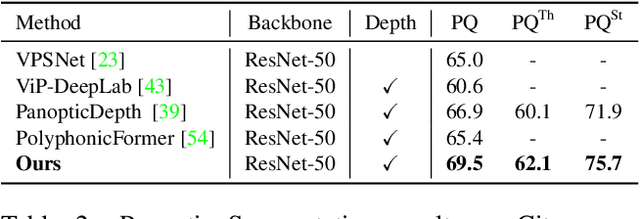
Depth-aware panoptic segmentation is an emerging topic in computer vision which combines semantic and geometric understanding for more robust scene interpretation. Recent works pursue unified frameworks to tackle this challenge but mostly still treat it as two individual learning tasks, which limits their potential for exploring cross-domain information. We propose a deeply unified framework for depth-aware panoptic segmentation, which performs joint segmentation and depth estimation both in a per-segment manner with identical object queries. To narrow the gap between the two tasks, we further design a geometric query enhancement method, which is able to integrate scene geometry into object queries using latent representations. In addition, we propose a bi-directional guidance learning approach to facilitate cross-task feature learning by taking advantage of their mutual relations. Our method sets the new state of the art for depth-aware panoptic segmentation on both Cityscapes-DVPS and SemKITTI-DVPS datasets. Moreover, our guidance learning approach is shown to deliver performance improvement even under incomplete supervision labels.
Incrementally-Computable Neural Networks: Efficient Inference for Dynamic Inputs
Jul 27, 2023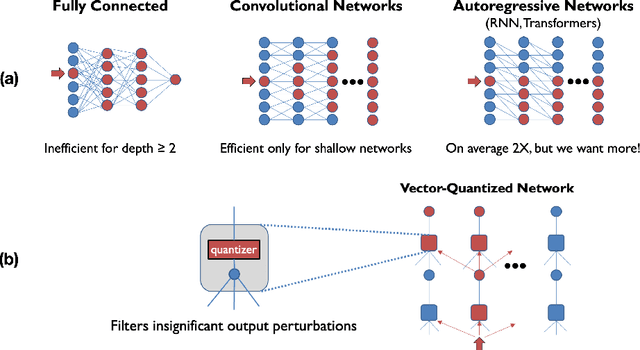
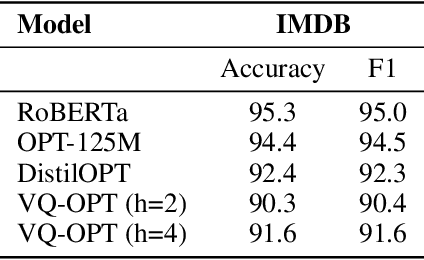
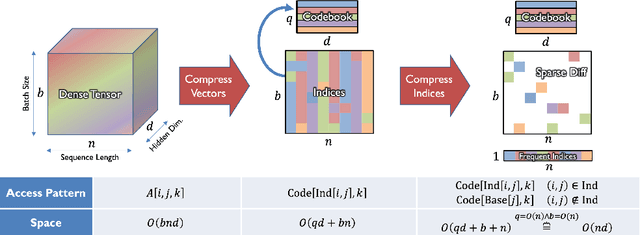
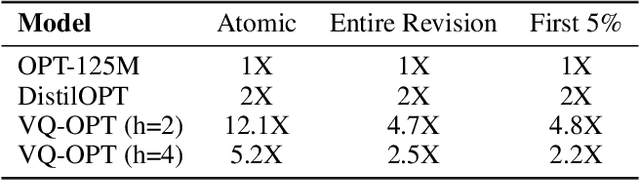
Deep learning often faces the challenge of efficiently processing dynamic inputs, such as sensor data or user inputs. For example, an AI writing assistant is required to update its suggestions in real time as a document is edited. Re-running the model each time is expensive, even with compression techniques like knowledge distillation, pruning, or quantization. Instead, we take an incremental computing approach, looking to reuse calculations as the inputs change. However, the dense connectivity of conventional architectures poses a major obstacle to incremental computation, as even minor input changes cascade through the network and restrict information reuse. To address this, we use vector quantization to discretize intermediate values in the network, which filters out noisy and unnecessary modifications to hidden neurons, facilitating the reuse of their values. We apply this approach to the transformers architecture, creating an efficient incremental inference algorithm with complexity proportional to the fraction of the modified inputs. Our experiments with adapting the OPT-125M pre-trained language model demonstrate comparable accuracy on document classification while requiring 12.1X (median) fewer operations for processing sequences of atomic edits.
PromptStyler: Prompt-driven Style Generation for Source-free Domain Generalization
Jul 27, 2023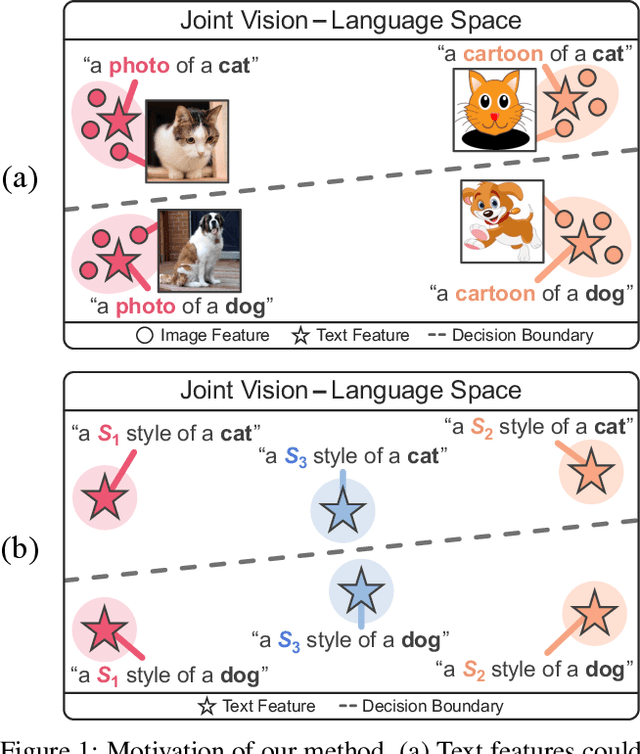
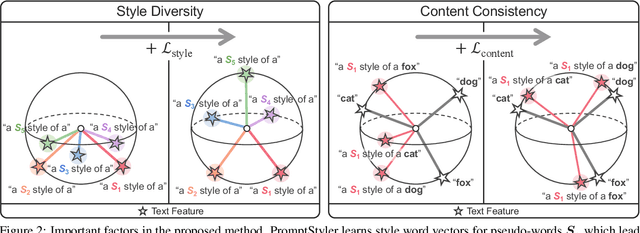
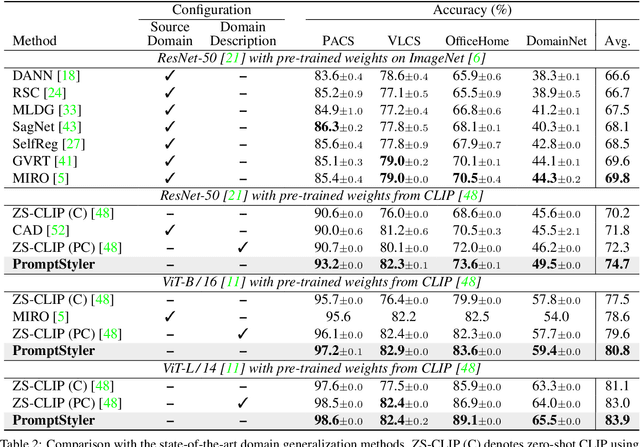
In a joint vision-language space, a text feature (e.g., from "a photo of a dog") could effectively represent its relevant image features (e.g., from dog photos). Inspired by this, we propose PromptStyler which simulates various distribution shifts in the joint space by synthesizing diverse styles via prompts without using any images to deal with source-free domain generalization. Our method learns to generate a variety of style features (from "a S* style of a") via learnable style word vectors for pseudo-words S*. To ensure that learned styles do not distort content information, we force style-content features (from "a S* style of a [class]") to be located nearby their corresponding content features (from "[class]") in the joint vision-language space. After learning style word vectors, we train a linear classifier using synthesized style-content features. PromptStyler achieves the state of the art on PACS, VLCS, OfficeHome and DomainNet, although it does not require any images and takes just ~30 minutes for training using a single GPU.
Empower Your Model with Longer and Better Context Comprehension
Jul 27, 2023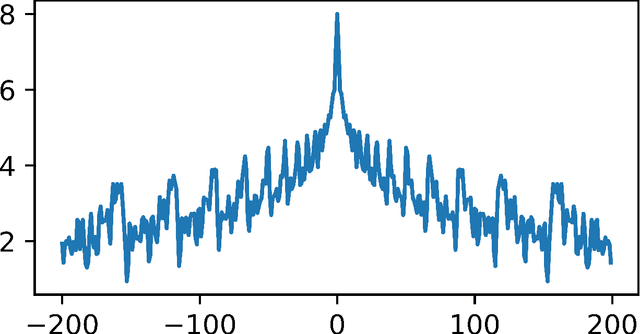

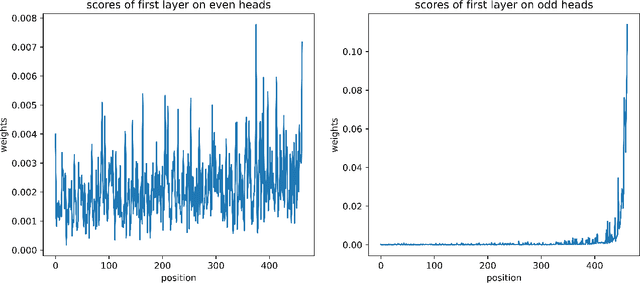
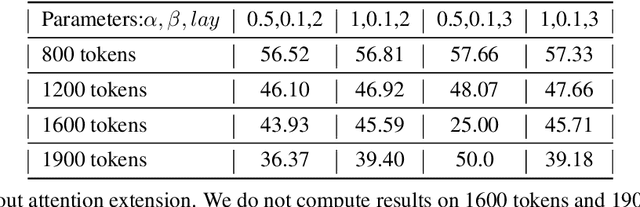
Recently, with the emergence of numerous Large Language Models (LLMs), the implementation of AI has entered a new era. Irrespective of these models' own capacity and structure, there is a growing demand for LLMs to possess enhanced comprehension of longer and more complex contexts with relatively smaller sizes. Models often encounter an upper limit when processing sequences of sentences that extend beyond their comprehension capacity and result in off-topic or even chaotic responses. While several recent works attempt to address this issue in various ways, they rarely focus on "why models are unable to compensate or strengthen their capabilities on their own". In this paper, we thoroughly investigate the nature of information transfer within LLMs and propose a novel technique called Attention Transition. This technique empowers models to achieve longer and better context comprehension with minimal additional training or impact on generation fluency. Our experiments are conducted on the challenging XSum dataset using LLaMa-7b model with context token length ranging from 800 to 1900. Results demonstrate that we achieve substantial improvements compared with the original generation results evaluated by GPT4.