 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Can Self-Supervised Representation Learning Methods Withstand Distribution Shifts and Corruptions?
Jul 31, 2023
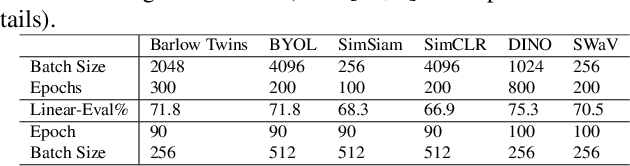
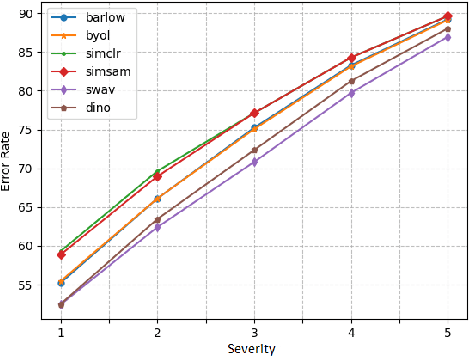
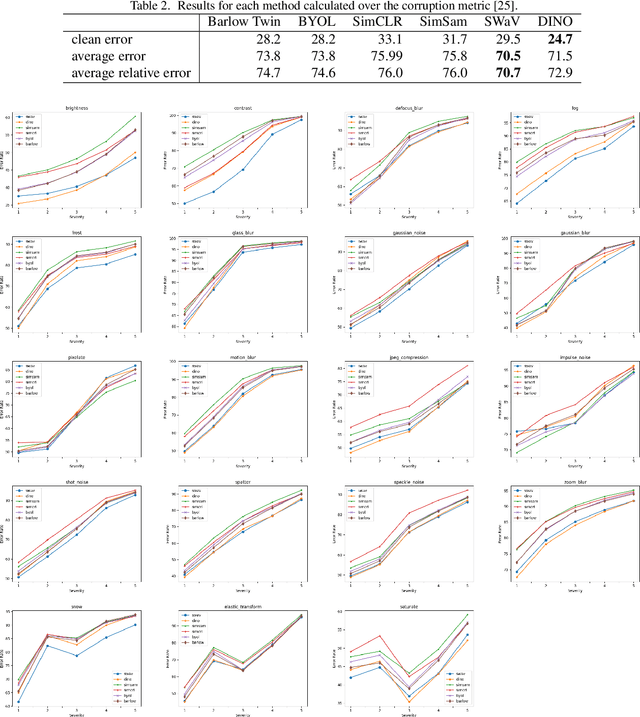

Self-supervised learning in computer vision aims to leverage the inherent structure and relationships within data to learn meaningful representations without explicit human annotation, enabling a holistic understanding of visual scenes. Robustness in vision machine learning ensures reliable and consistent performance, enhancing generalization, adaptability, and resistance to noise, variations, and adversarial attacks. Self-supervised paradigms, namely contrastive learning, knowledge distillation, mutual information maximization, and clustering, have been considered to have shown advances in invariant learning representations. This work investigates the robustness of learned representations of self-supervised learning approaches focusing on distribution shifts and image corruptions in computer vision. Detailed experiments have been conducted to study the robustness of self-supervised learning methods on distribution shifts and image corruptions. The empirical analysis demonstrates a clear relationship between the performance of learned representations within self-supervised paradigms and the severity of distribution shifts and corruptions. Notably, higher levels of shifts and corruptions are found to significantly diminish the robustness of the learned representations. These findings highlight the critical impact of distribution shifts and image corruptions on the performance and resilience of self-supervised learning methods, emphasizing the need for effective strategies to mitigate their adverse effects. The study strongly advocates for future research in the field of self-supervised representation learning to prioritize the key aspects of safety and robustness in order to ensure practical applicability. The source code and results are available on GitHub.
Substance or Style: What Does Your Image Embedding Know?
Jul 10, 2023
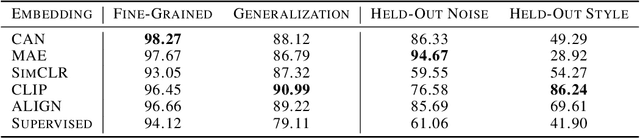


Probes are small networks that predict properties of underlying data from embeddings, and they provide a targeted, effective way to illuminate the information contained in embeddings. While analysis through the use of probes has become standard in NLP, there has been much less exploration in vision. Image foundation models have primarily been evaluated for semantic content. Better understanding the non-semantic information in popular embeddings (e.g., MAE, SimCLR, or CLIP) will shed new light both on the training algorithms and on the uses for these foundation models. We design a systematic transformation prediction task and measure the visual content of embeddings along many axes, including image style, quality, and a range of natural and artificial transformations. Surprisingly, six embeddings (including SimCLR) encode enough non-semantic information to identify dozens of transformations. We also consider a generalization task, where we group similar transformations and hold out several for testing. We find that image-text models (CLIP and ALIGN) are better at recognizing new examples of style transfer than masking-based models (CAN and MAE). Overall, our results suggest that the choice of pre-training algorithm impacts the types of information in the embedding, and certain models are better than others for non-semantic downstream tasks.
Computational Long Exposure Mobile Photography
Aug 02, 2023Long exposure photography produces stunning imagery, representing moving elements in a scene with motion-blur. It is generally employed in two modalities, producing either a foreground or a background blur effect. Foreground blur images are traditionally captured on a tripod-mounted camera and portray blurred moving foreground elements, such as silky water or light trails, over a perfectly sharp background landscape. Background blur images, also called panning photography, are captured while the camera is tracking a moving subject, to produce an image of a sharp subject over a background blurred by relative motion. Both techniques are notoriously challenging and require additional equipment and advanced skills. In this paper, we describe a computational burst photography system that operates in a hand-held smartphone camera app, and achieves these effects fully automatically, at the tap of the shutter button. Our approach first detects and segments the salient subject. We track the scene motion over multiple frames and align the images in order to preserve desired sharpness and to produce aesthetically pleasing motion streaks. We capture an under-exposed burst and select the subset of input frames that will produce blur trails of controlled length, regardless of scene or camera motion velocity. We predict inter-frame motion and synthesize motion-blur to fill the temporal gaps between the input frames. Finally, we composite the blurred image with the sharp regular exposure to protect the sharpness of faces or areas of the scene that are barely moving, and produce a final high resolution and high dynamic range (HDR) photograph. Our system democratizes a capability previously reserved to professionals, and makes this creative style accessible to most casual photographers. More information and supplementary material can be found on our project webpage: https://motion-mode.github.io/
* 15 pages, 17 figures
Investigating Graph Structure Information for Entity Alignment with Dangling Cases
Apr 10, 2023
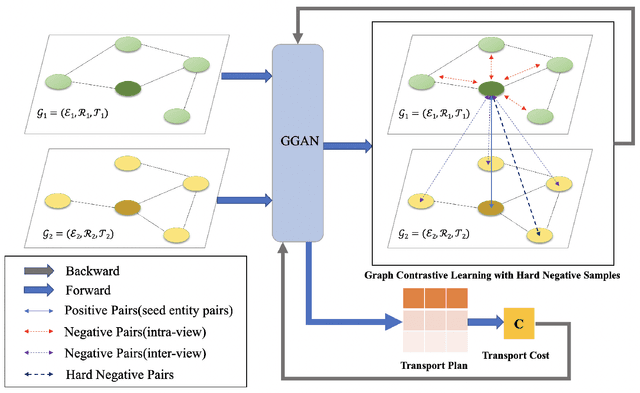
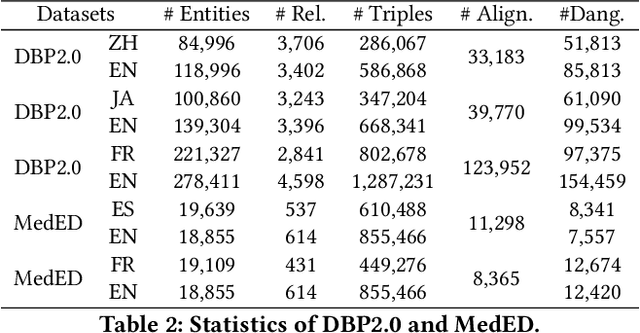
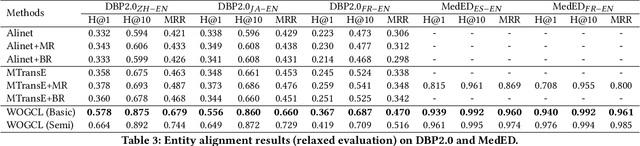
Entity alignment (EA) aims to discover the equivalent entities in different knowledge graphs (KGs), which play an important role in knowledge engineering. Recently, EA with dangling entities has been proposed as a more realistic setting, which assumes that not all entities have corresponding equivalent entities. In this paper, we focus on this setting. Some work has explored this problem by leveraging translation API, pre-trained word embeddings, and other off-the-shelf tools. However, these approaches over-rely on the side information (e.g., entity names), and fail to work when the side information is absent. On the contrary, they still insufficiently exploit the most fundamental graph structure information in KG. To improve the exploitation of the structural information, we propose a novel entity alignment framework called Weakly-Optimal Graph Contrastive Learning (WOGCL), which is refined on three dimensions : (i) Model. We propose a novel Gated Graph Attention Network to capture local and global graph structure similarity. (ii) Training. Two learning objectives: contrastive learning and optimal transport learning are designed to obtain distinguishable entity representations via the optimal transport plan. (iii) Inference. In the inference phase, a PageRank-based method is proposed to calculate higher-order structural similarity. Extensive experiments on two dangling benchmarks demonstrate that our WOGCL outperforms the current state-of-the-art methods with pure structural information in both traditional (relaxed) and dangling (consolidated) settings. The code will be public soon.
Question Answering with Deep Neural Networks for Semi-Structured Heterogeneous Genealogical Knowledge Graphs
Jul 30, 2023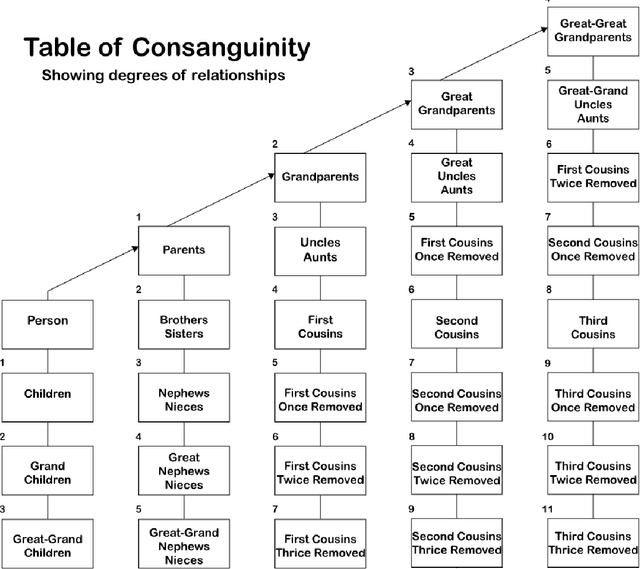
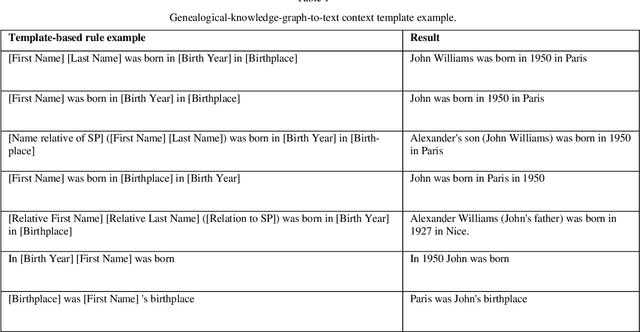

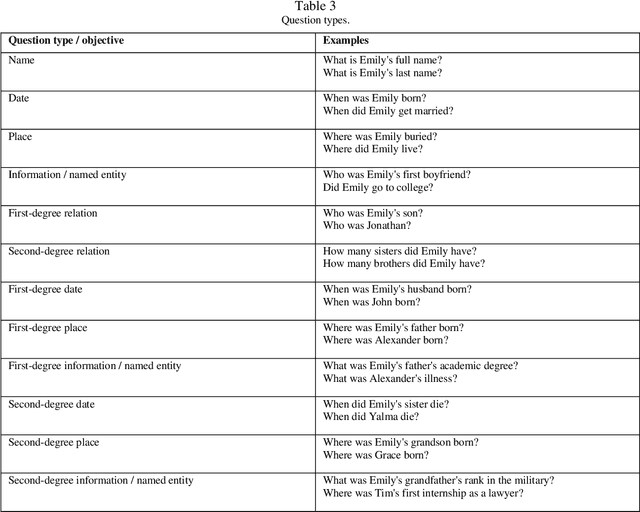
With the rising popularity of user-generated genealogical family trees, new genealogical information systems have been developed. State-of-the-art natural question answering algorithms use deep neural network (DNN) architecture based on self-attention networks. However, some of these models use sequence-based inputs and are not suitable to work with graph-based structure, while graph-based DNN models rely on high levels of comprehensiveness of knowledge graphs that is nonexistent in the genealogical domain. Moreover, these supervised DNN models require training datasets that are absent in the genealogical domain. This study proposes an end-to-end approach for question answering using genealogical family trees by: 1) representing genealogical data as knowledge graphs, 2) converting them to texts, 3) combining them with unstructured texts, and 4) training a trans-former-based question answering model. To evaluate the need for a dedicated approach, a comparison between the fine-tuned model (Uncle-BERT) trained on the auto-generated genealogical dataset and state-of-the-art question-answering models was per-formed. The findings indicate that there are significant differences between answering genealogical questions and open-domain questions. Moreover, the proposed methodology reduces complexity while increasing accuracy and may have practical implications for genealogical research and real-world projects, making genealogical data accessible to experts as well as the general public.
SR-R$^2$KAC: Improving Single Image Defocus Deblurring
Jul 30, 2023
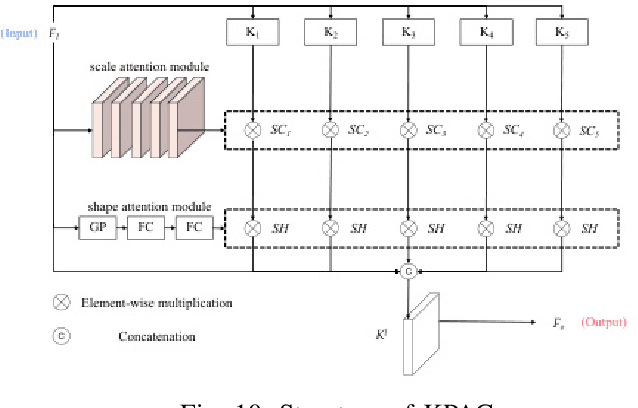


We propose an efficient deep learning method for single image defocus deblurring (SIDD) by further exploring inverse kernel properties. Although the current inverse kernel method, i.e., kernel-sharing parallel atrous convolution (KPAC), can address spatially varying defocus blurs, it has difficulty in handling large blurs of this kind. To tackle this issue, we propose a Residual and Recursive Kernel-sharing Atrous Convolution (R$^2$KAC). R$^2$KAC builds on a significant observation of inverse kernels, that is, successive use of inverse-kernel-based deconvolutions with fixed size helps remove unexpected large blurs but produces ringing artifacts. Specifically, on top of kernel-sharing atrous convolutions used to simulate multi-scale inverse kernels, R$^2$KAC applies atrous convolutions recursively to simulate a large inverse kernel. Specifically, on top of kernel-sharing atrous convolutions, R$^2$KAC stacks atrous convolutions recursively to simulate a large inverse kernel. To further alleviate the contingent effect of recursive stacking, i.e., ringing artifacts, we add identity shortcuts between atrous convolutions to simulate residual deconvolutions. Lastly, a scale recurrent module is embedded in the R$^2$KAC network, leading to SR-R$^2$KAC, so that multi-scale information from coarse to fine is exploited to progressively remove the spatially varying defocus blurs. Extensive experimental results show that our method achieves the state-of-the-art performance.
Proposing a conceptual framework: social media listening for public health behavior
Jul 30, 2023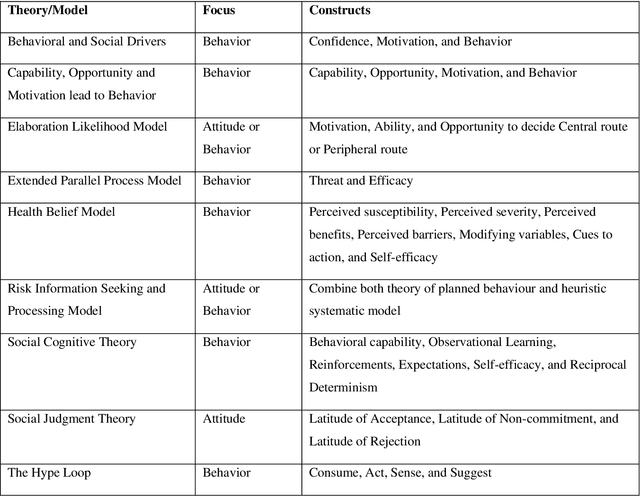
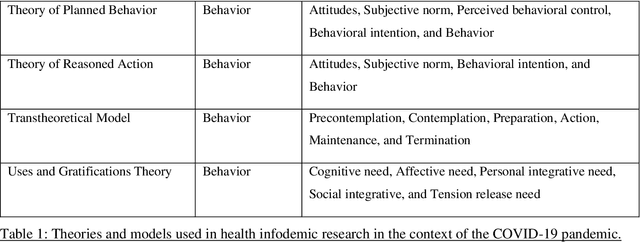
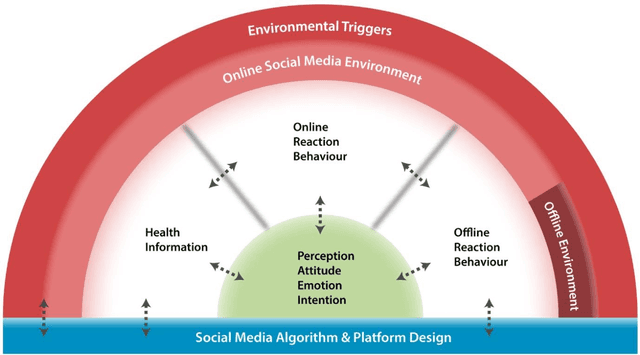

Existing communications and behavioral theories have been adopted to address health misinformation. Although various theories and models have been used to investigate the COVID-19 pandemic, there is no framework specially designed for social listening or misinformation studies using social media data and natural language processing techniques. This study aimed to propose a novel yet theory-based conceptual framework for misinformation research. We collected theories and models used in COVID-19 related studies published in peer-reviewed journals. The theories and models ranged from health behaviors, communications, to misinformation. They are analyzed and critiqued for their components, followed by proposing a conceptual framework with a demonstration. We reviewed Health Belief Model, Theory of Planned Behavior/Reasoned Action, Communication for Behavioral Impact, Transtheoretical Model, Uses and Gratifications Theory, Social Judgment Theory, Risk Information Seeking and Processing Model, Behavioral and Social Drivers, and Hype Loop. Accordingly, we proposed the Social Media Listening for Public Health Behavior Conceptual Framework by not only integrating important attributes of existing theories, but also adding new attributes. The proposed conceptual framework was demonstrated in the Freedom Convoy social media listening. The proposed conceptual framework can be used to better understand public discourse on social media, and it can be integrated with other data analyses to gather a more comprehensive picture. The framework will continue to be revised and adopted as health misinformation evolves.
Object-based Probabilistic Similarity Evidence of Sparse Latent Features from Fully Convolutional Networks
Jul 25, 2023Similarity analysis using neural networks has emerged as a powerful technique for understanding and categorizing complex patterns in various domains. By leveraging the latent representations learned by neural networks, data objects such as images can be compared effectively. This research explores the utilization of latent information generated by fully convolutional networks (FCNs) in similarity analysis, notably to estimate the visual resemblance of objects segmented in 2D pictures. To do this, the analytical scheme comprises two steps: (1) extracting and transforming feature patterns per 2D object from a trained FCN, and (2) identifying the most similar patterns through fuzzy inference. The step (2) can be further enhanced by incorporating a weighting scheme that considers the significance of latent variables in the analysis. The results provide valuable insights into the benefits and challenges of employing neural network-based similarity analysis for discerning data patterns effectively.
DeepMem: ML Models as storage channels and their (mis-)applications
Jul 17, 2023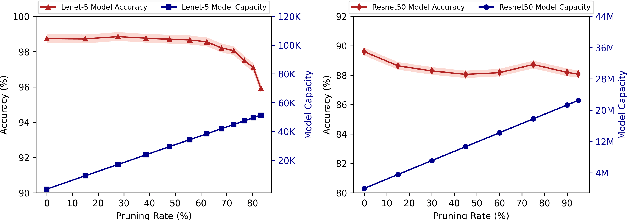
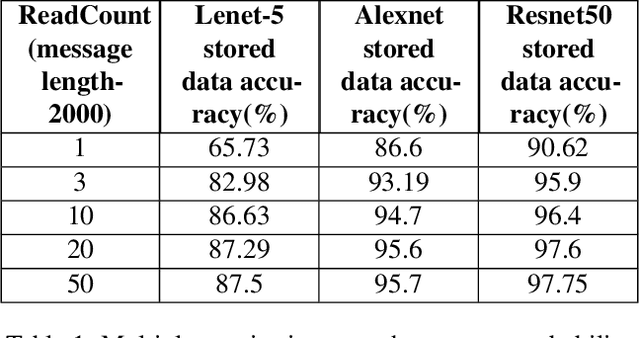
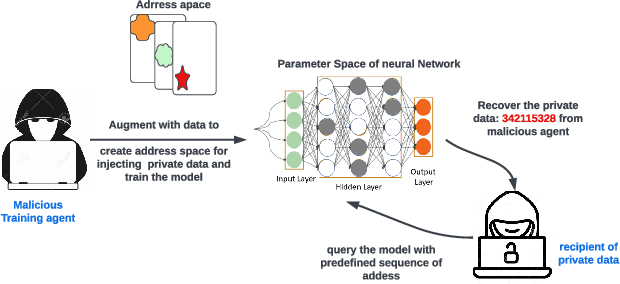
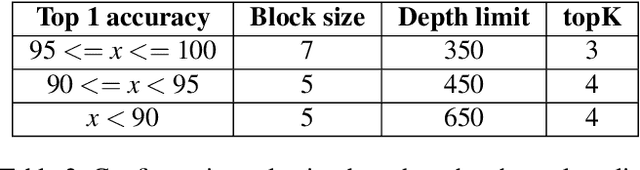
Machine learning (ML) models are overparameterized to support generality and avoid overfitting. Prior works have shown that these additional parameters can be used for both malicious (e.g., hiding a model covertly within a trained model) and beneficial purposes (e.g., watermarking a model). In this paper, we propose a novel information theoretic perspective of the problem; we consider the ML model as a storage channel with a capacity that increases with overparameterization. Specifically, we consider a sender that embeds arbitrary information in the model at training time, which can be extracted by a receiver with a black-box access to the deployed model. We derive an upper bound on the capacity of the channel based on the number of available parameters. We then explore black-box write and read primitives that allow the attacker to: (i) store data in an optimized way within the model by augmenting the training data at the transmitter side, and (ii) to read it by querying the model after it is deployed. We also analyze the detectability of the writing primitive and consider a new version of the problem which takes information storage covertness into account. Specifically, to obtain storage covertness, we introduce a new constraint such that the data augmentation used for the write primitives minimizes the distribution shift with the initial (baseline task) distribution. This constraint introduces a level of "interference" with the initial task, thereby limiting the channel's effective capacity. Therefore, we develop optimizations to improve the capacity in this case, including a novel ML-specific substitution based error correction protocol. We believe that the proposed modeling of the problem offers new tools to better understand and mitigate potential vulnerabilities of ML, especially in the context of increasingly large models.
Noise-aware Speech Enhancement using Diffusion Probabilistic Model
Jul 16, 2023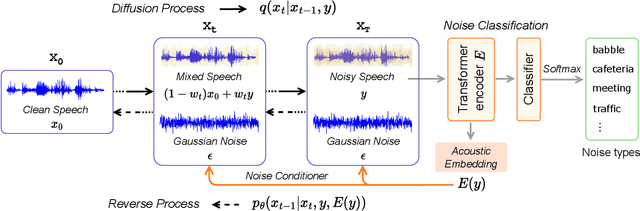
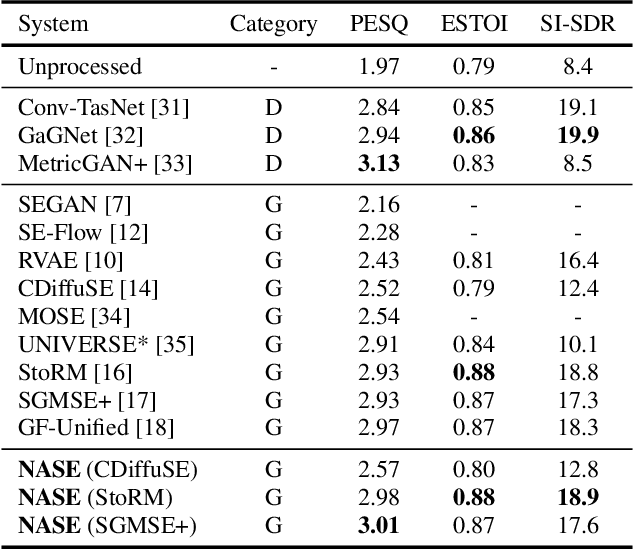
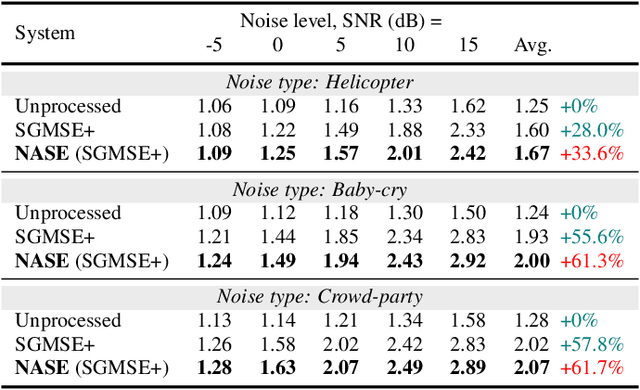
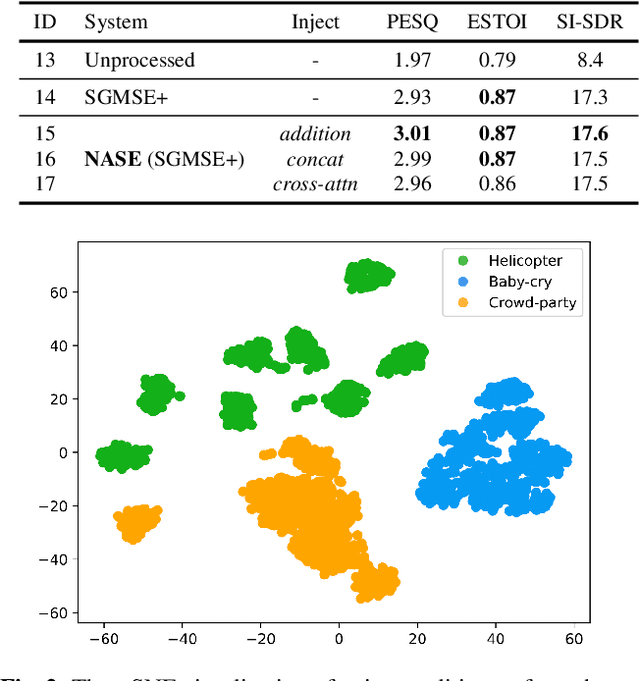
With recent advances of diffusion model, generative speech enhancement (SE) has attracted a surge of research interest due to its great potential for unseen testing noises. However, existing efforts mainly focus on inherent properties of clean speech for inference, underexploiting the varying noise information in real-world conditions. In this paper, we propose a noise-aware speech enhancement (NASE) approach that extracts noise-specific information to guide the reverse process in diffusion model. Specifically, we design a noise classification (NC) model to produce acoustic embedding as a noise conditioner for guiding the reverse denoising process. Meanwhile, a multi-task learning scheme is devised to jointly optimize SE and NC tasks, in order to enhance the noise specificity of extracted noise conditioner. Our proposed NASE is shown to be a plug-and-play module that can be generalized to any diffusion SE models. Experiment evidence on VoiceBank-DEMAND dataset shows that NASE achieves significant improvement over multiple mainstream diffusion SE models, especially on unseen testing noises.