 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Gradient strikes back: How filtering out high frequencies improves explanations
Jul 18, 2023
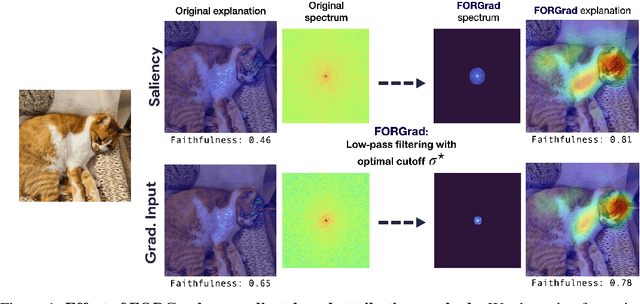
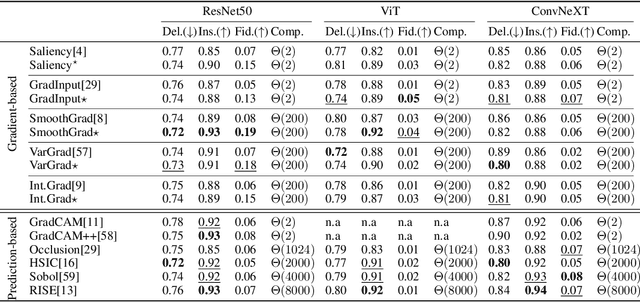
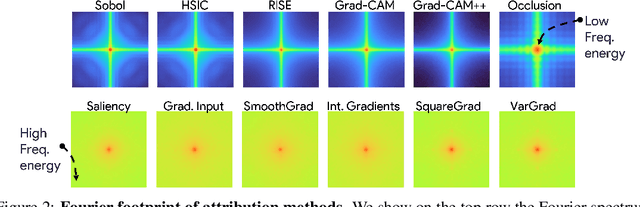

Recent years have witnessed an explosion in the development of novel prediction-based attribution methods, which have slowly been supplanting older gradient-based methods to explain the decisions of deep neural networks. However, it is still not clear why prediction-based methods outperform gradient-based ones. Here, we start with an empirical observation: these two approaches yield attribution maps with very different power spectra, with gradient-based methods revealing more high-frequency content than prediction-based methods. This observation raises multiple questions: What is the source of this high-frequency information, and does it truly reflect decisions made by the system? Lastly, why would the absence of high-frequency information in prediction-based methods yield better explainability scores along multiple metrics? We analyze the gradient of three representative visual classification models and observe that it contains noisy information emanating from high-frequencies. Furthermore, our analysis reveals that the operations used in Convolutional Neural Networks (CNNs) for downsampling appear to be a significant source of this high-frequency content -- suggesting aliasing as a possible underlying basis. We then apply an optimal low-pass filter for attribution maps and demonstrate that it improves gradient-based attribution methods. We show that (i) removing high-frequency noise yields significant improvements in the explainability scores obtained with gradient-based methods across multiple models -- leading to (ii) a novel ranking of state-of-the-art methods with gradient-based methods at the top. We believe that our results will spur renewed interest in simpler and computationally more efficient gradient-based methods for explainability.
Adversarial Self-Attack Defense and Spatial-Temporal Relation Mining for Visible-Infrared Video Person Re-Identification
Jul 08, 2023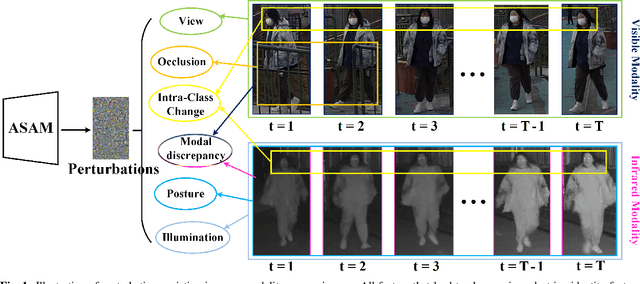
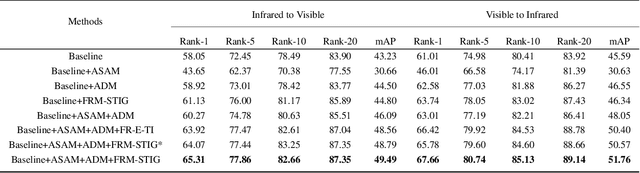
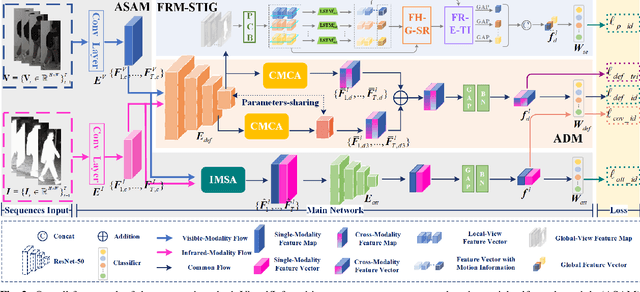
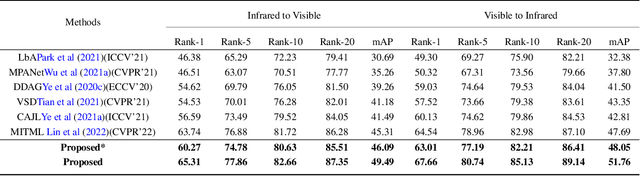
In visible-infrared video person re-identification (re-ID), extracting features not affected by complex scenes (such as modality, camera views, pedestrian pose, background, etc.) changes, and mining and utilizing motion information are the keys to solving cross-modal pedestrian identity matching. To this end, the paper proposes a new visible-infrared video person re-ID method from a novel perspective, i.e., adversarial self-attack defense and spatial-temporal relation mining. In this work, the changes of views, posture, background and modal discrepancy are considered as the main factors that cause the perturbations of person identity features. Such interference information contained in the training samples is used as an adversarial perturbation. It performs adversarial attacks on the re-ID model during the training to make the model more robust to these unfavorable factors. The attack from the adversarial perturbation is introduced by activating the interference information contained in the input samples without generating adversarial samples, and it can be thus called adversarial self-attack. This design allows adversarial attack and defense to be integrated into one framework. This paper further proposes a spatial-temporal information-guided feature representation network to use the information in video sequences. The network cannot only extract the information contained in the video-frame sequences but also use the relation of the local information in space to guide the network to extract more robust features. The proposed method exhibits compelling performance on large-scale cross-modality video datasets. The source code of the proposed method will be released at https://github.com/lhf12278/xxx.
A Study of Unsupervised Evaluation Metrics for Practical and Automatic Domain Adaptation
Aug 01, 2023
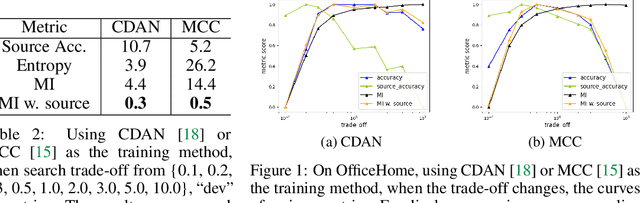
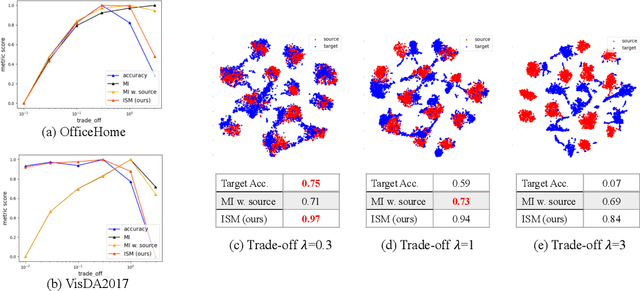
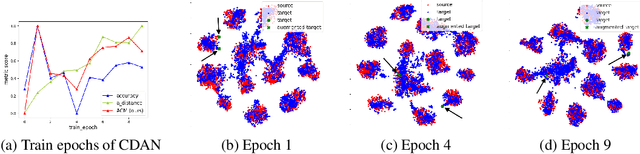
Unsupervised domain adaptation (UDA) methods facilitate the transfer of models to target domains without labels. However, these methods necessitate a labeled target validation set for hyper-parameter tuning and model selection. In this paper, we aim to find an evaluation metric capable of assessing the quality of a transferred model without access to target validation labels. We begin with the metric based on mutual information of the model prediction. Through empirical analysis, we identify three prevalent issues with this metric: 1) It does not account for the source structure. 2) It can be easily attacked. 3) It fails to detect negative transfer caused by the over-alignment of source and target features. To address the first two issues, we incorporate source accuracy into the metric and employ a new MLP classifier that is held out during training, significantly improving the result. To tackle the final issue, we integrate this enhanced metric with data augmentation, resulting in a novel unsupervised UDA metric called the Augmentation Consistency Metric (ACM). Additionally, we empirically demonstrate the shortcomings of previous experiment settings and conduct large-scale experiments to validate the effectiveness of our proposed metric. Furthermore, we employ our metric to automatically search for the optimal hyper-parameter set, achieving superior performance compared to manually tuned sets across four common benchmarks. Codes will be available soon.
Local Conditional Neural Fields for Versatile and Generalizable Large-Scale Reconstructions in Computational Imaging
Jul 22, 2023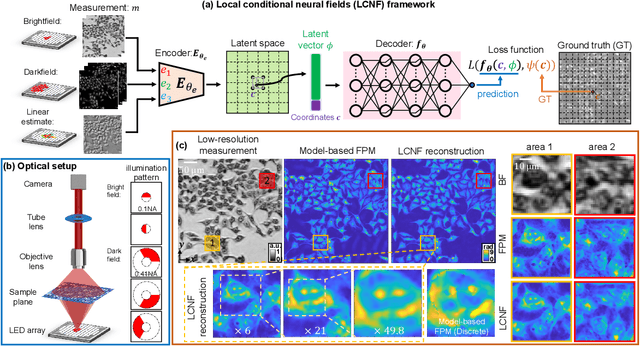
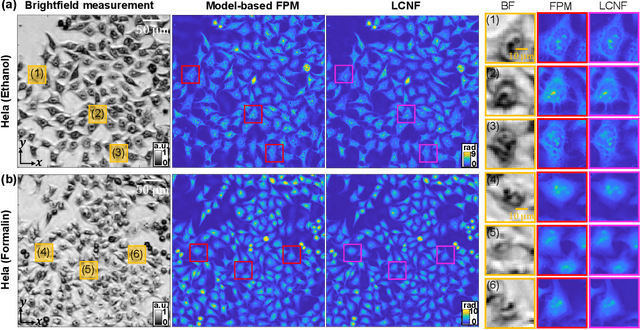
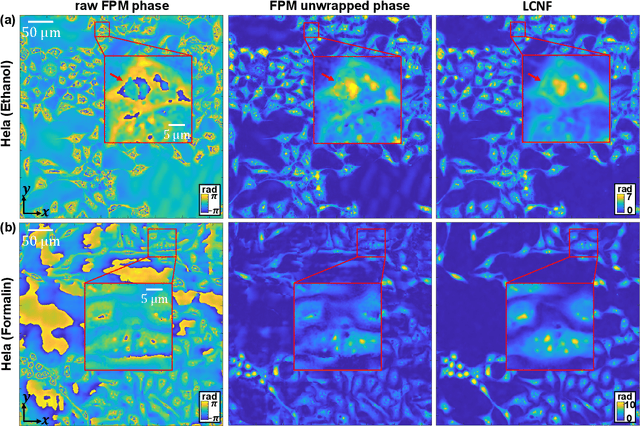
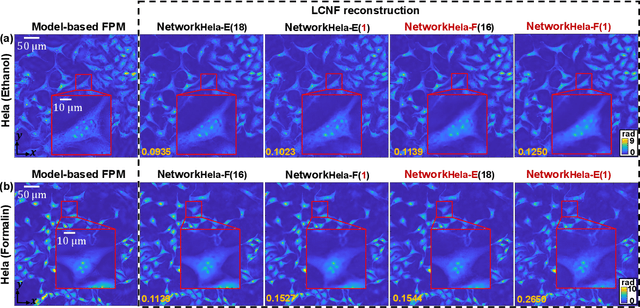
Deep learning has transformed computational imaging, but traditional pixel-based representations limit their ability to capture continuous, multiscale details of objects. Here we introduce a novel Local Conditional Neural Fields (LCNF) framework, leveraging a continuous implicit neural representation to address this limitation. LCNF enables flexible object representation and facilitates the reconstruction of multiscale information. We demonstrate the capabilities of LCNF in solving the highly ill-posed inverse problem in Fourier ptychographic microscopy (FPM) with multiplexed measurements, achieving robust, scalable, and generalizable large-scale phase retrieval. Unlike traditional neural fields frameworks, LCNF incorporates a local conditional representation that promotes model generalization, learning multiscale information, and efficient processing of large-scale imaging data. By combining an encoder and a decoder conditioned on a learned latent vector, LCNF achieves versatile continuous-domain super-resolution image reconstruction. We demonstrate accurate reconstruction of wide field-of-view, high-resolution phase images using only a few multiplexed measurements. LCNF robustly captures the continuous object priors and eliminates various phase artifacts, even when it is trained on imperfect datasets. The framework exhibits strong generalization, reconstructing diverse objects even with limited training data. Furthermore, LCNF can be trained on a physics simulator using natural images and successfully applied to experimental measurements on biological samples. Our results highlight the potential of LCNF for solving large-scale inverse problems in computational imaging, with broad applicability in various deep-learning-based techniques.
GADER: GAit DEtection and Recognition in the Wild
Jul 27, 2023
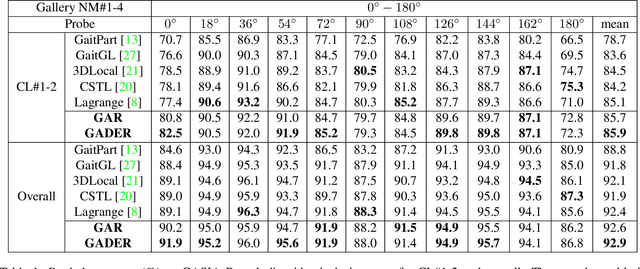
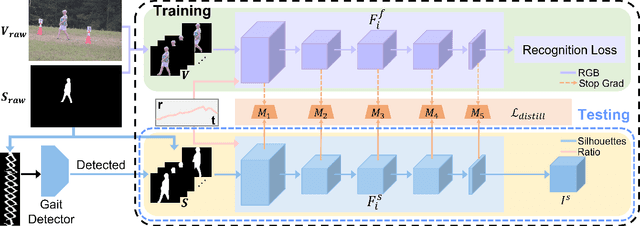
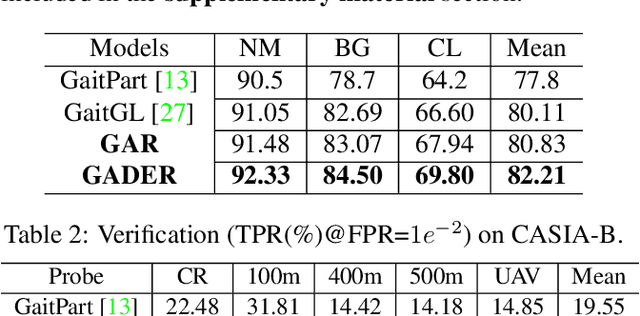
Gait recognition holds the promise of robustly identifying subjects based on their walking patterns instead of color information. While previous approaches have performed well for curated indoor scenes, they have significantly impeded applicability in unconstrained situations, e.g. outdoor, long distance scenes. We propose an end-to-end GAit DEtection and Recognition (GADER) algorithm for human authentication in challenging outdoor scenarios. Specifically, GADER leverages a Double Helical Signature to detect the fragment of human movement and incorporates a novel gait recognition method, which learns representations by distilling from an auxiliary RGB recognition model. At inference time, GADER only uses the silhouette modality but benefits from a more robust representation. Extensive experiments on indoor and outdoor datasets demonstrate that the proposed method outperforms the State-of-The-Arts for gait recognition and verification, with a significant 20.6% improvement on unconstrained, long distance scenes.
Non Intrusive Intelligibility Predictor for Hearing Impaired Individuals using Self Supervised Speech Representations
Jul 27, 2023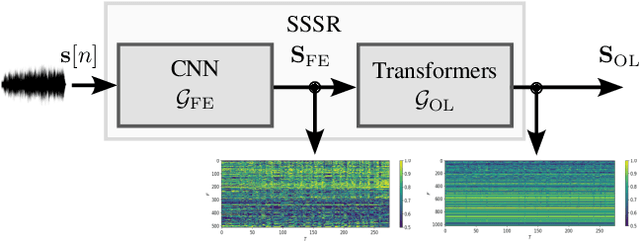
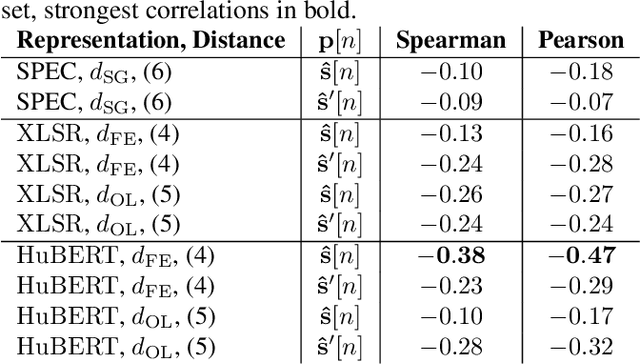
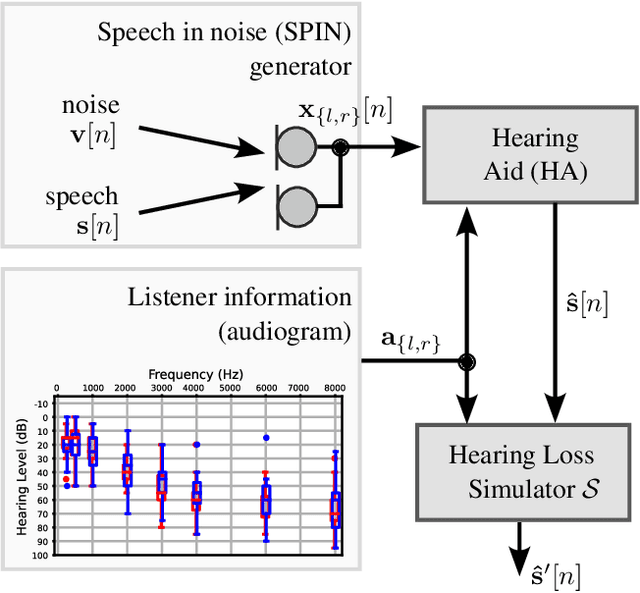
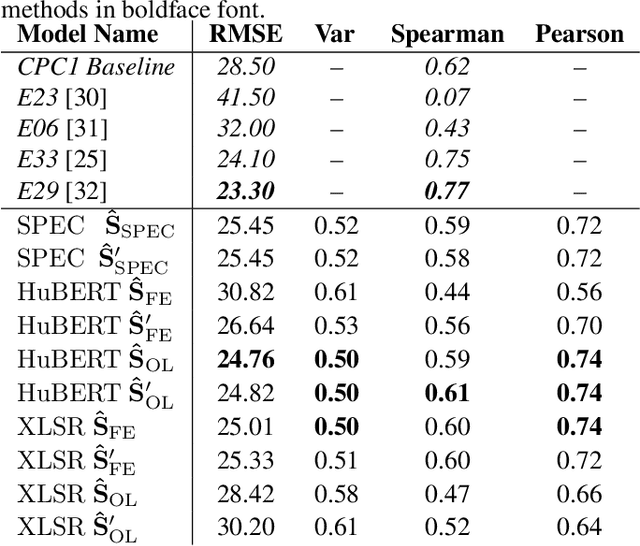
Self-supervised speech representations (SSSRs) have been successfully applied to a number of speech-processing tasks, e.g. as feature extractor for speech quality (SQ) prediction, which is, in turn, relevant for assessment and training speech enhancement systems for users with normal or impaired hearing. However, exact knowledge of why and how quality-related information is encoded well in such representations remains poorly understood. In this work, techniques for non-intrusive prediction of SQ ratings are extended to the prediction of intelligibility for hearing-impaired users. It is found that self-supervised representations are useful as input features to non-intrusive prediction models, achieving competitive performance to more complex systems. A detailed analysis of the performance depending on Clarity Prediction Challenge 1 listeners and enhancement systems indicates that more data might be needed to allow generalisation to unknown systems and (hearing-impaired) individuals
Measuring Item Global Residual Value for Fair Recommendation
Jul 17, 2023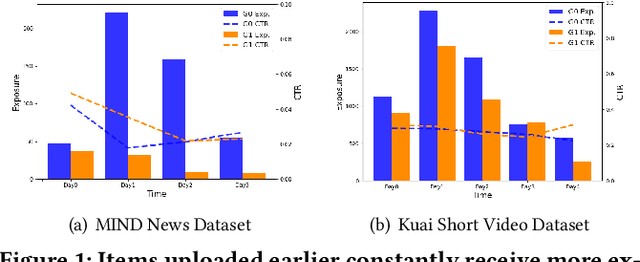

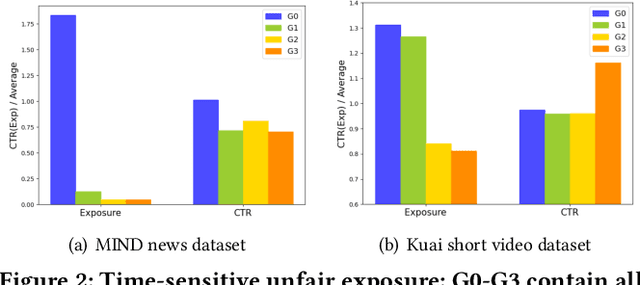

In the era of information explosion, numerous items emerge every day, especially in feed scenarios. Due to the limited system display slots and user browsing attention, various recommendation systems are designed not only to satisfy users' personalized information needs but also to allocate items' exposure. However, recent recommendation studies mainly focus on modeling user preferences to present satisfying results and maximize user interactions, while paying little attention to developing item-side fair exposure mechanisms for rational information delivery. This may lead to serious resource allocation problems on the item side, such as the Snowball Effect. Furthermore, unfair exposure mechanisms may hurt recommendation performance. In this paper, we call for a shift of attention from modeling user preferences to developing fair exposure mechanisms for items. We first conduct empirical analyses of feed scenarios to explore exposure problems between items with distinct uploaded times. This points out that unfair exposure caused by the time factor may be the major cause of the Snowball Effect. Then, we propose to explicitly model item-level customized timeliness distribution, Global Residual Value (GRV), for fair resource allocation. This GRV module is introduced into recommendations with the designed Timeliness-aware Fair Recommendation Framework (TaFR). Extensive experiments on two datasets demonstrate that TaFR achieves consistent improvements with various backbone recommendation models. By modeling item-side customized Global Residual Value, we achieve a fairer distribution of resources and, at the same time, improve recommendation performance.
AI for the Generation and Testing of Ideas Towards an AI Supported Knowledge Development Environment
Jul 17, 2023New systems employ Machine Learning to sift through large knowledge sources, creating flexible Large Language Models. These models discern context and predict sequential information in various communication forms. Generative AI, leveraging Transformers, generates textual or visual outputs mimicking human responses. It proposes one or multiple contextually feasible solutions for a user to contemplate. However, generative AI does not currently support traceability of ideas, a useful feature provided by search engines indicating origin of information. The narrative style of generative AI has gained positive reception. People learn from stories. Yet, early ChatGPT efforts had difficulty with truth, reference, calculations, and aspects like accurate maps. Current capabilities of referencing locations and linking to apps seem to be better catered by the link-centric search methods we've used for two decades. Deploying truly believable solutions extends beyond simulating contextual relevance as done by generative AI. Combining the creativity of generative AI with the provenance of internet sources in hybrid scenarios could enhance internet usage. Generative AI, viewed as drafts, stimulates thinking, offering alternative ideas for final versions or actions. Scenarios for information requests are considered. We discuss how generative AI can boost idea generation by eliminating human bias. We also describe how search can verify facts, logic, and context. The user evaluates these generated ideas for selection and usage. This paper introduces a system for knowledge workers, Generate And Search Test, enabling individuals to efficiently create solutions previously requiring top collaborations of experts.
SegNetr: Rethinking the local-global interactions and skip connections in U-shaped networks
Jul 21, 2023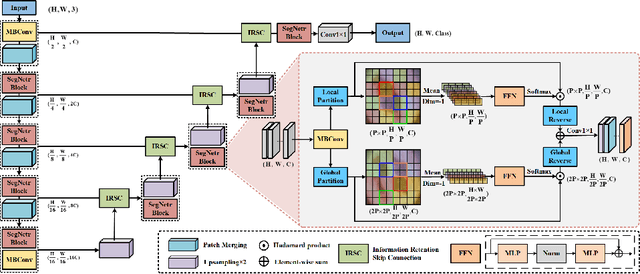
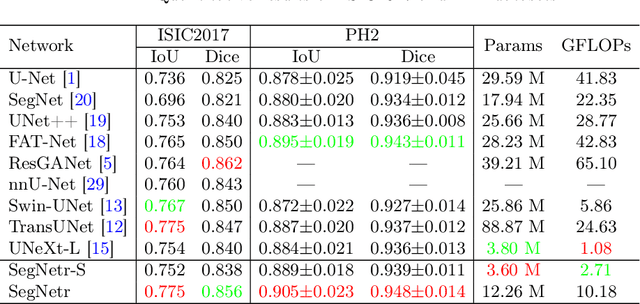
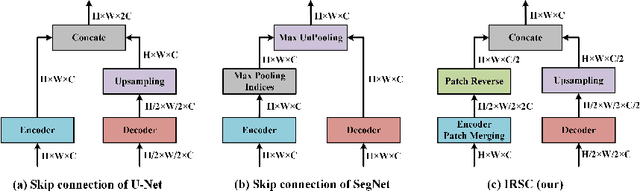
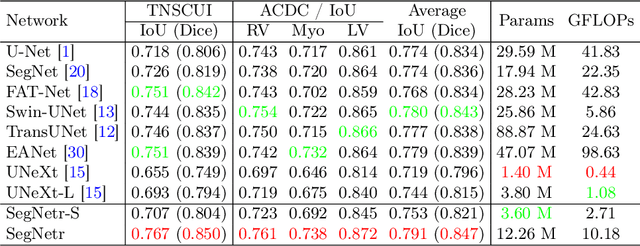
Recently, U-shaped networks have dominated the field of medical image segmentation due to their simple and easily tuned structure. However, existing U-shaped segmentation networks: 1) mostly focus on designing complex self-attention modules to compensate for the lack of long-term dependence based on convolution operation, which increases the overall number of parameters and computational complexity of the network; 2) simply fuse the features of encoder and decoder, ignoring the connection between their spatial locations. In this paper, we rethink the above problem and build a lightweight medical image segmentation network, called SegNetr. Specifically, we introduce a novel SegNetr block that can perform local-global interactions dynamically at any stage and with only linear complexity. At the same time, we design a general information retention skip connection (IRSC) to preserve the spatial location information of encoder features and achieve accurate fusion with the decoder features. We validate the effectiveness of SegNetr on four mainstream medical image segmentation datasets, with 59\% and 76\% fewer parameters and GFLOPs than vanilla U-Net, while achieving segmentation performance comparable to state-of-the-art methods. Notably, the components proposed in this paper can be applied to other U-shaped networks to improve their segmentation performance.
LaplaceConfidence: a Graph-based Approach for Learning with Noisy Labels
Jul 31, 2023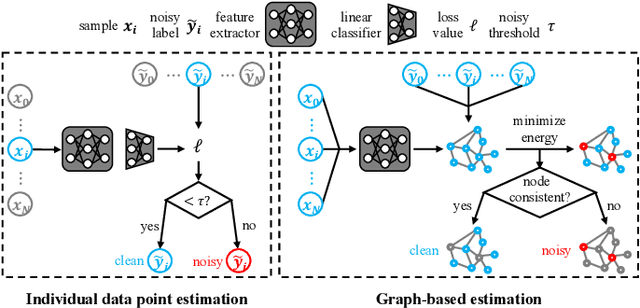
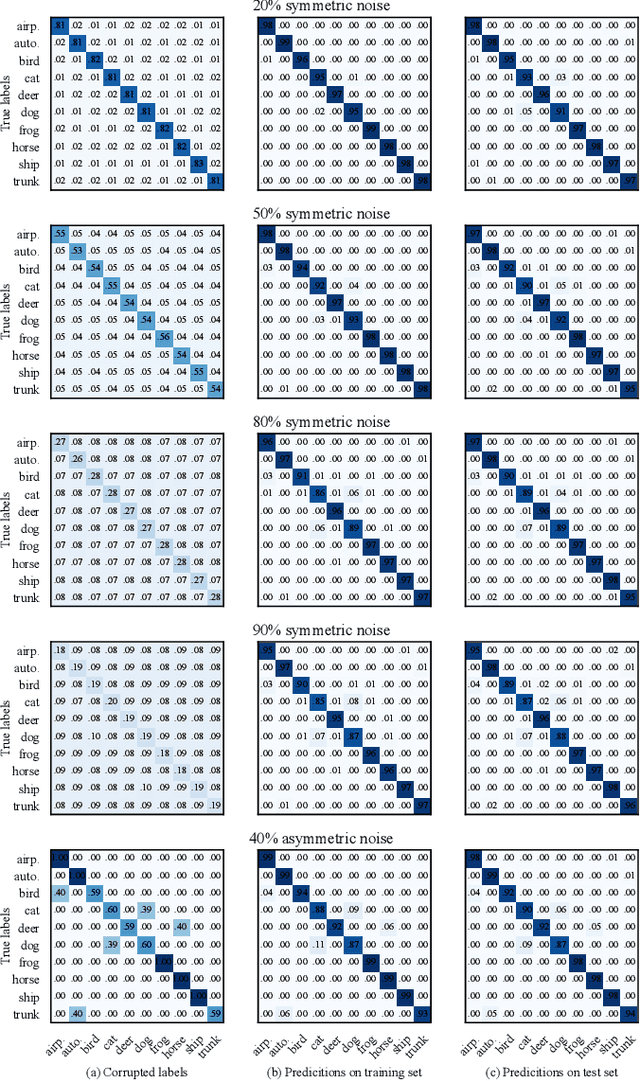

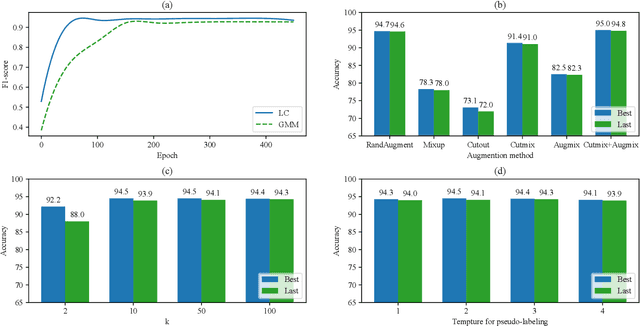
In real-world applications, perfect labels are rarely available, making it challenging to develop robust machine learning algorithms that can handle noisy labels. Recent methods have focused on filtering noise based on the discrepancy between model predictions and given noisy labels, assuming that samples with small classification losses are clean. This work takes a different approach by leveraging the consistency between the learned model and the entire noisy dataset using the rich representational and topological information in the data. We introduce LaplaceConfidence, a method that to obtain label confidence (i.e., clean probabilities) utilizing the Laplacian energy. Specifically, it first constructs graphs based on the feature representations of all noisy samples and minimizes the Laplacian energy to produce a low-energy graph. Clean labels should fit well into the low-energy graph while noisy ones should not, allowing our method to determine data's clean probabilities. Furthermore, LaplaceConfidence is embedded into a holistic method for robust training, where co-training technique generates unbiased label confidence and label refurbishment technique better utilizes it. We also explore the dimensionality reduction technique to accommodate our method on large-scale noisy datasets. Our experiments demonstrate that LaplaceConfidence outperforms state-of-the-art methods on benchmark datasets under both synthetic and real-world noise.