 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Latent Positional Information is in the Self-Attention Variance of Transformer Language Models Without Positional Embeddings
May 23, 2023

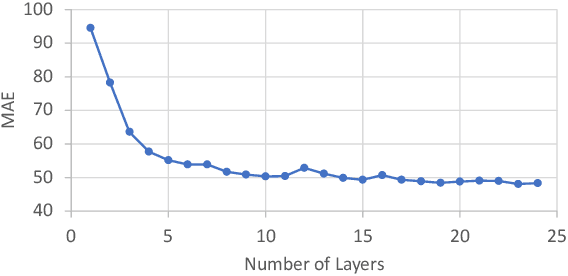
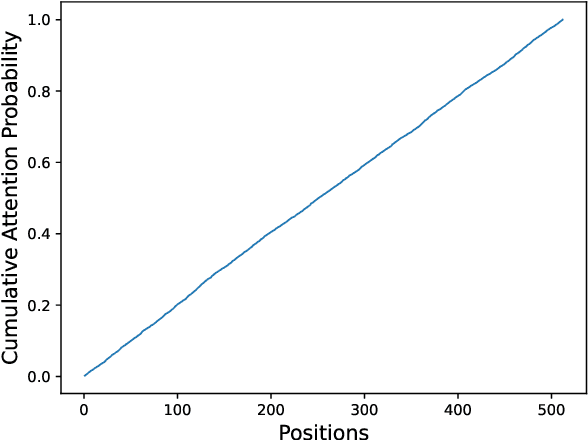
The use of positional embeddings in transformer language models is widely accepted. However, recent research has called into question the necessity of such embeddings. We further extend this inquiry by demonstrating that a randomly initialized and frozen transformer language model, devoid of positional embeddings, inherently encodes strong positional information through the shrinkage of self-attention variance. To quantify this variance, we derive the underlying distribution of each step within a transformer layer. Through empirical validation using a fully pretrained model, we show that the variance shrinkage effect still persists after extensive gradient updates. Our findings serve to justify the decision to discard positional embeddings and thus facilitate more efficient pretraining of transformer language models.
ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation
Aug 03, 2023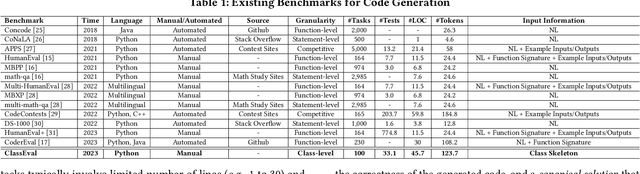


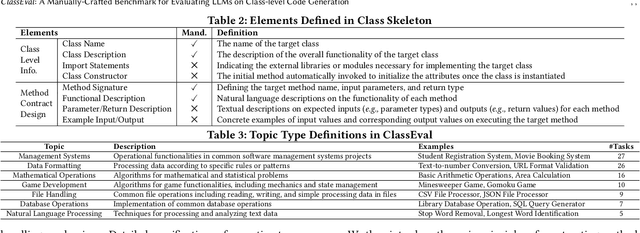
In this work, we make the first attempt to evaluate LLMs in a more challenging code generation scenario, i.e. class-level code generation. We first manually construct the first class-level code generation benchmark ClassEval of 100 class-level Python code generation tasks with approximately 500 person-hours. Based on it, we then perform the first study of 11 state-of-the-art LLMs on class-level code generation. Based on our results, we have the following main findings. First, we find that all existing LLMs show much worse performance on class-level code generation compared to on standalone method-level code generation benchmarks like HumanEval; and the method-level coding ability cannot equivalently reflect the class-level coding ability among LLMs. Second, we find that GPT-4 and GPT-3.5 still exhibit dominate superior than other LLMs on class-level code generation, and the second-tier models includes Instruct-Starcoder, Instruct-Codegen, and Wizardcoder with very similar performance. Third, we find that generating the entire class all at once (i.e. holistic generation strategy) is the best generation strategy only for GPT-4 and GPT-3.5, while method-by-method generation (i.e. incremental and compositional) is better strategies for the other models with limited ability of understanding long instructions and utilizing the middle information. Lastly, we find the limited model ability of generating method-dependent code and discuss the frequent error types in generated classes. Our benchmark is available at https://github.com/FudanSELab/ClassEval.
ADRNet: A Generalized Collaborative Filtering Framework Combining Clinical and Non-Clinical Data for Adverse Drug Reaction Prediction
Aug 03, 2023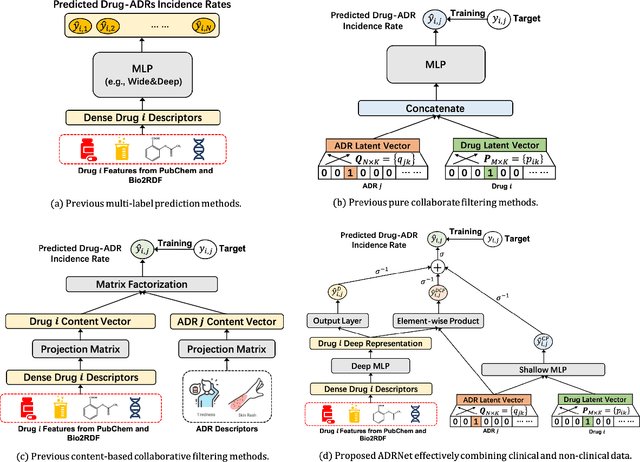
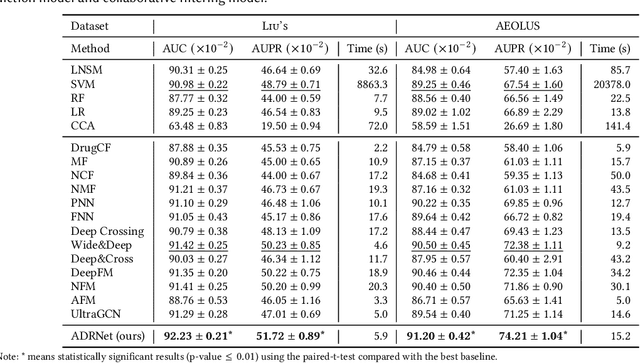
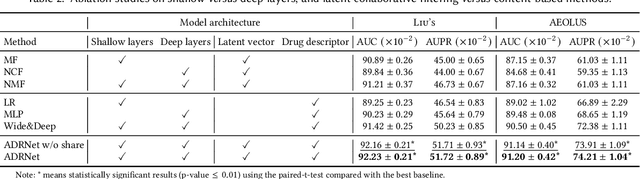

Adverse drug reaction (ADR) prediction plays a crucial role in both health care and drug discovery for reducing patient mortality and enhancing drug safety. Recently, many studies have been devoted to effectively predict the drug-ADRs incidence rates. However, these methods either did not effectively utilize non-clinical data, i.e., physical, chemical, and biological information about the drug, or did little to establish a link between content-based and pure collaborative filtering during the training phase. In this paper, we first formulate the prediction of multi-label ADRs as a drug-ADR collaborative filtering problem, and to the best of our knowledge, this is the first work to provide extensive benchmark results of previous collaborative filtering methods on two large publicly available clinical datasets. Then, by exploiting the easy accessible drug characteristics from non-clinical data, we propose ADRNet, a generalized collaborative filtering framework combining clinical and non-clinical data for drug-ADR prediction. Specifically, ADRNet has a shallow collaborative filtering module and a deep drug representation module, which can exploit the high-dimensional drug descriptors to further guide the learning of low-dimensional ADR latent embeddings, which incorporates both the benefits of collaborative filtering and representation learning. Extensive experiments are conducted on two publicly available real-world drug-ADR clinical datasets and two non-clinical datasets to demonstrate the accuracy and efficiency of the proposed ADRNet. The code is available at https://github.com/haoxuanli-pku/ADRnet.
Meta-multigraph Search: Rethinking Meta-structure on Heterogeneous Information Networks
Apr 23, 2023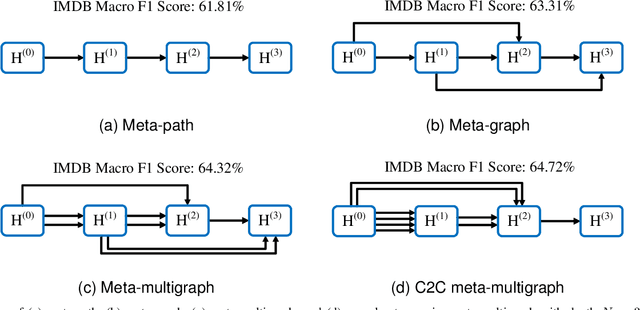
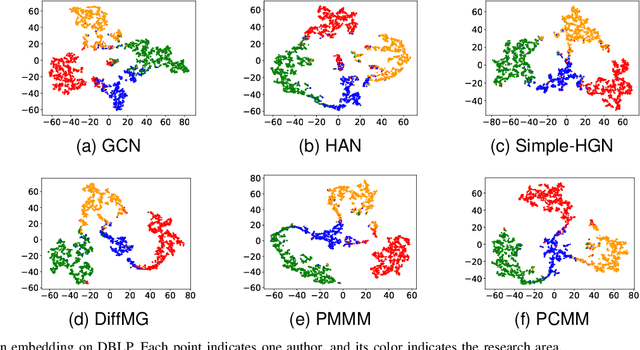
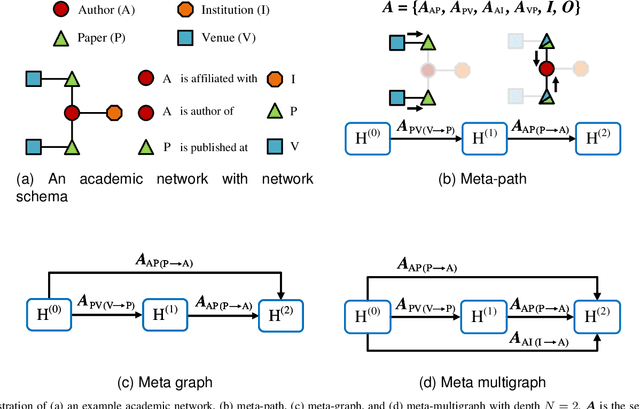
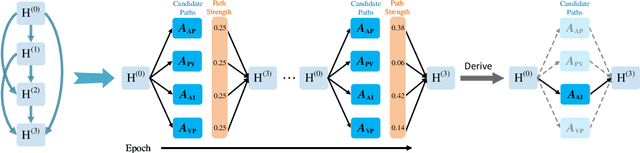
Meta-structures are widely used to define which subset of neighbors to aggregate information in heterogeneous information networks (HINs). In this work, we investigate existing meta-structures, including meta-path and meta-graph, and observe that they are initially designed manually with fixed patterns and hence are insufficient to encode various rich semantic information on diverse HINs. Through reflection on their limitation, we define a new concept called meta-multigraph as a more expressive and flexible generalization of meta-graph, and propose a stable differentiable search method to automatically optimize the meta-multigraph for specific HINs and tasks. As the flexibility of meta-multigraphs may propagate redundant messages, we further introduce a complex-to-concise (C2C) meta-multigraph that propagates messages from complex to concise along the depth of meta-multigraph. Moreover, we observe that the differentiable search typically suffers from unstable search and a significant gap between the meta-structures in search and evaluation. To this end, we propose a progressive search algorithm by implicitly narrowing the search space to improve search stability and reduce inconsistency. Extensive experiments are conducted on six medium-scale benchmark datasets and one large-scale benchmark dataset over two representative tasks, i.e., node classification and recommendation. Empirical results demonstrate that our search methods can automatically find expressive meta-multigraphs and C2C meta-multigraphs, enabling our model to outperform state-of-the-art heterogeneous graph neural networks.
Space-Air-Ground Integrated Network (SAGIN): A Survey
Jul 27, 2023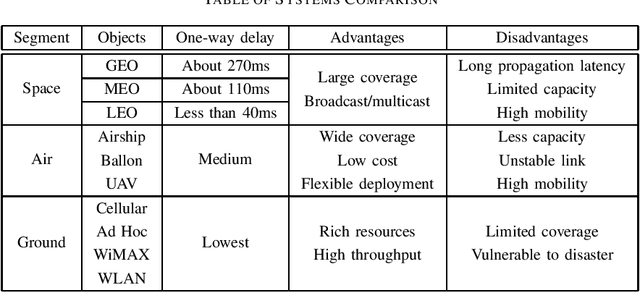
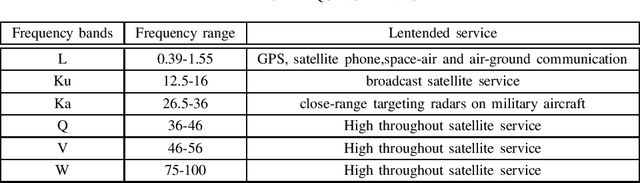
Since existing mobile communication networks may not be able to meet the low latency and high-efficiency requirements of emerging technologies and applications, novel network architectures need to be investigated to support these new requirements. As a new network architecture that integrates satellite systems, air networks and ground communication, Space-Air-Ground Integrated Network (SAGIN) has attracted extensive attention in recent years. This paper summarizes the recent research work on SAGIN from several aspects, with the basic information of SAGIN first introduced, followed by the physical characteristics. Then the drive and prospects of the current SAGIN architecture in supporting new requirements are deeply analyzed. On this basis, the requirements and challenges are analyzed. Finally, it summarizes the existing solutions and prospects the future research directions.
Learning Dynamic Query Combinations for Transformer-based Object Detection and Segmentation
Jul 27, 2023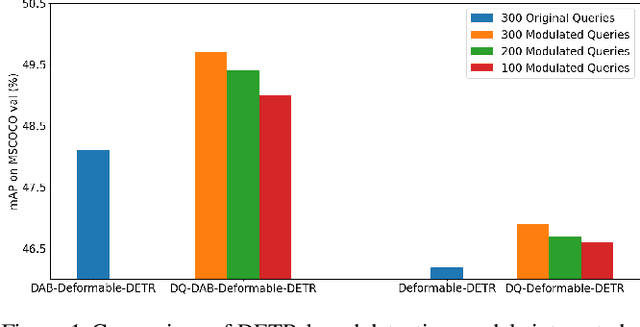

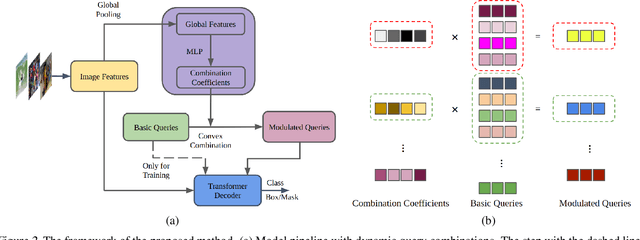
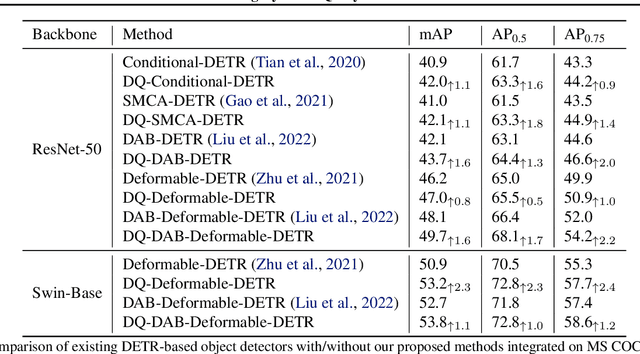
Transformer-based detection and segmentation methods use a list of learned detection queries to retrieve information from the transformer network and learn to predict the location and category of one specific object from each query. We empirically find that random convex combinations of the learned queries are still good for the corresponding models. We then propose to learn a convex combination with dynamic coefficients based on the high-level semantics of the image. The generated dynamic queries, named modulated queries, better capture the prior of object locations and categories in the different images. Equipped with our modulated queries, a wide range of DETR-based models achieve consistent and superior performance across multiple tasks including object detection, instance segmentation, panoptic segmentation, and video instance segmentation.
Compound Attention and Neighbor Matching Network for Multi-contrast MRI Super-resolution
Jul 24, 2023
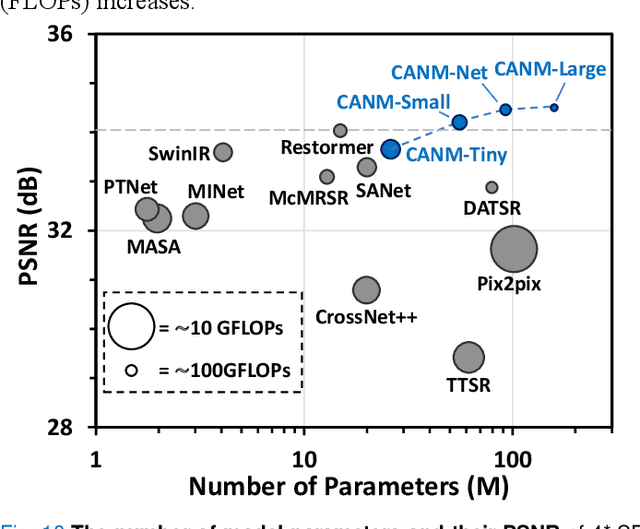
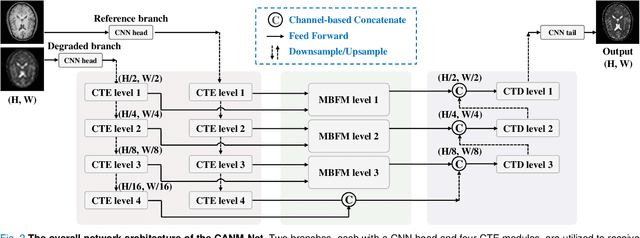
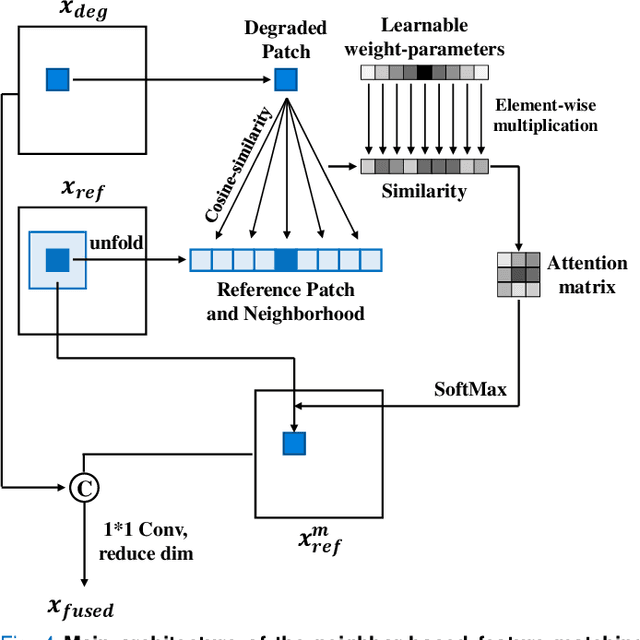
Multi-contrast magnetic resonance imaging (MRI) reflects information about human tissue from different perspectives and has many clinical applications. By utilizing the complementary information among different modalities, multi-contrast super-resolution (SR) of MRI can achieve better results than single-image super-resolution. However, existing methods of multi-contrast MRI SR have the following shortcomings that may limit their performance: First, existing methods either simply concatenate the reference and degraded features or exploit global feature-matching between them, which are unsuitable for multi-contrast MRI SR. Second, although many recent methods employ transformers to capture long-range dependencies in the spatial dimension, they neglect that self-attention in the channel dimension is also important for low-level vision tasks. To address these shortcomings, we proposed a novel network architecture with compound-attention and neighbor matching (CANM-Net) for multi-contrast MRI SR: The compound self-attention mechanism effectively captures the dependencies in both spatial and channel dimension; the neighborhood-based feature-matching modules are exploited to match degraded features and adjacent reference features and then fuse them to obtain the high-quality images. We conduct experiments of SR tasks on the IXI, fastMRI, and real-world scanning datasets. The CANM-Net outperforms state-of-the-art approaches in both retrospective and prospective experiments. Moreover, the robustness study in our work shows that the CANM-Net still achieves good performance when the reference and degraded images are imperfectly registered, proving good potential in clinical applications.
To Compress or Not to Compress -- Self-Supervised Learning and Information Theory: A Review
Apr 19, 2023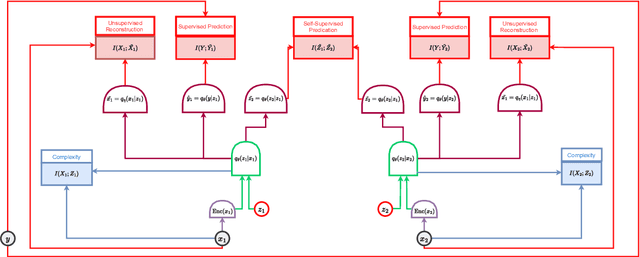
Deep neural networks have demonstrated remarkable performance in supervised learning tasks but require large amounts of labeled data. Self-supervised learning offers an alternative paradigm, enabling the model to learn from data without explicit labels. Information theory has been instrumental in understanding and optimizing deep neural networks. Specifically, the information bottleneck principle has been applied to optimize the trade-off between compression and relevant information preservation in supervised settings. However, the optimal information objective in self-supervised learning remains unclear. In this paper, we review various approaches to self-supervised learning from an information-theoretic standpoint and present a unified framework that formalizes the \textit{self-supervised information-theoretic learning problem}. We integrate existing research into a coherent framework, examine recent self-supervised methods, and identify research opportunities and challenges. Moreover, we discuss empirical measurement of information-theoretic quantities and their estimators. This paper offers a comprehensive review of the intersection between information theory, self-supervised learning, and deep neural networks.
Multimodal brain age estimation using interpretable adaptive population-graph learning
Jul 19, 2023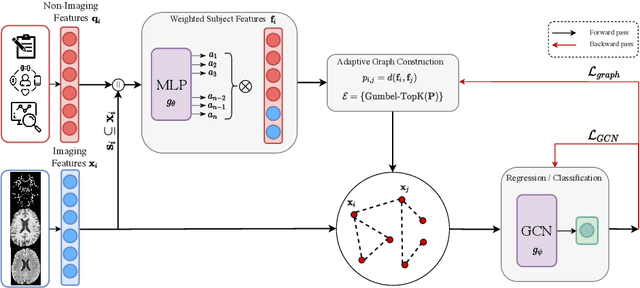
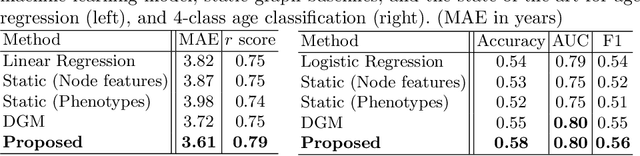
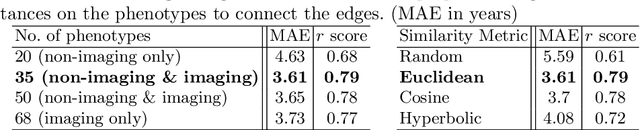
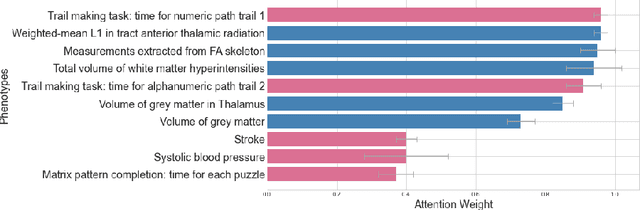
Brain age estimation is clinically important as it can provide valuable information in the context of neurodegenerative diseases such as Alzheimer's. Population graphs, which include multimodal imaging information of the subjects along with the relationships among the population, have been used in literature along with Graph Convolutional Networks (GCNs) and have proved beneficial for a variety of medical imaging tasks. A population graph is usually static and constructed manually using non-imaging information. However, graph construction is not a trivial task and might significantly affect the performance of the GCN, which is inherently very sensitive to the graph structure. In this work, we propose a framework that learns a population graph structure optimized for the downstream task. An attention mechanism assigns weights to a set of imaging and non-imaging features (phenotypes), which are then used for edge extraction. The resulting graph is used to train the GCN. The entire pipeline can be trained end-to-end. Additionally, by visualizing the attention weights that were the most important for the graph construction, we increase the interpretability of the graph. We use the UK Biobank, which provides a large variety of neuroimaging and non-imaging phenotypes, to evaluate our method on brain age regression and classification. The proposed method outperforms competing static graph approaches and other state-of-the-art adaptive methods. We further show that the assigned attention scores indicate that there are both imaging and non-imaging phenotypes that are informative for brain age estimation and are in agreement with the relevant literature.
Decomposing and Coupling Saliency Map for Lesion Segmentation in Ultrasound Images
Aug 02, 2023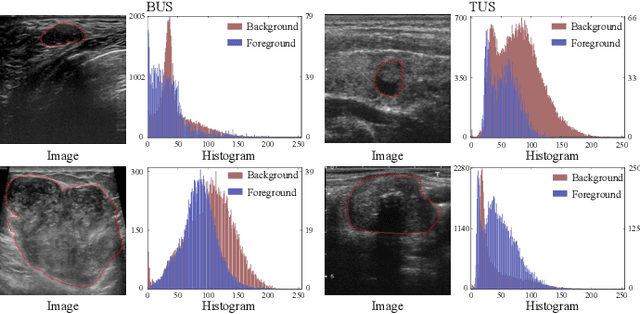

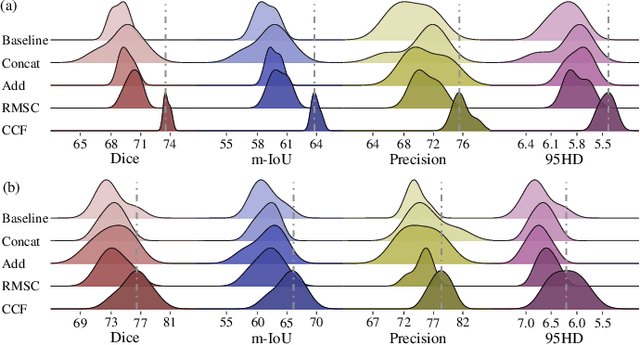
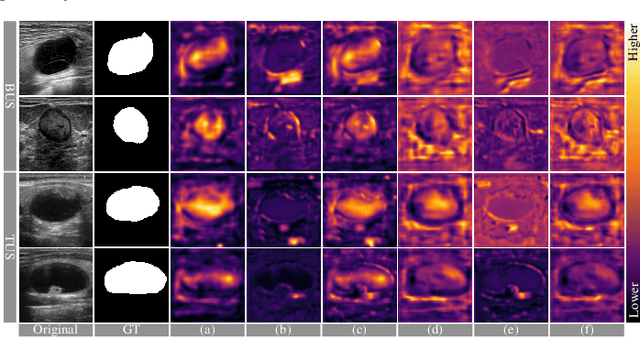
Complex scenario of ultrasound image, in which adjacent tissues (i.e., background) share similar intensity with and even contain richer texture patterns than lesion region (i.e., foreground), brings a unique challenge for accurate lesion segmentation. This work presents a decomposition-coupling network, called DC-Net, to deal with this challenge in a (foreground-background) saliency map disentanglement-fusion manner. The DC-Net consists of decomposition and coupling subnets, and the former preliminarily disentangles original image into foreground and background saliency maps, followed by the latter for accurate segmentation under the assistance of saliency prior fusion. The coupling subnet involves three aspects of fusion strategies, including: 1) regional feature aggregation (via differentiable context pooling operator in the encoder) to adaptively preserve local contextual details with the larger receptive field during dimension reduction; 2) relation-aware representation fusion (via cross-correlation fusion module in the decoder) to efficiently fuse low-level visual characteristics and high-level semantic features during resolution restoration; 3) dependency-aware prior incorporation (via coupler) to reinforce foreground-salient representation with the complementary information derived from background representation. Furthermore, a harmonic loss function is introduced to encourage the network to focus more attention on low-confidence and hard samples. The proposed method is evaluated on two ultrasound lesion segmentation tasks, which demonstrates the remarkable performance improvement over existing state-of-the-art methods.