 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Entropy Neural Estimation for Graph Contrastive Learning
Jul 26, 2023
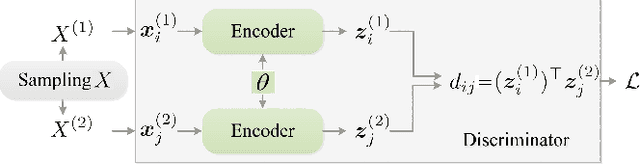
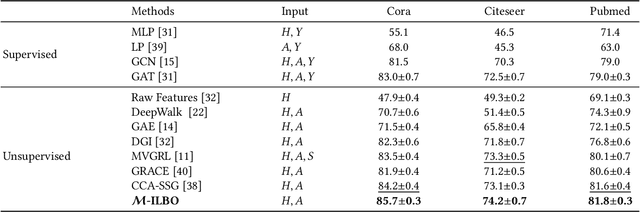
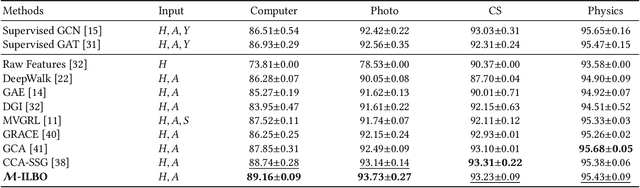
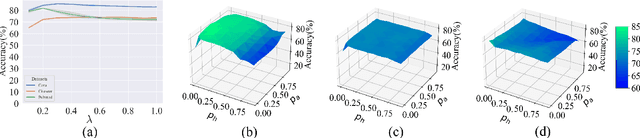
Contrastive learning on graphs aims at extracting distinguishable high-level representations of nodes. In this paper, we theoretically illustrate that the entropy of a dataset can be approximated by maximizing the lower bound of the mutual information across different views of a graph, \ie, entropy is estimated by a neural network. Based on this finding, we propose a simple yet effective subset sampling strategy to contrast pairwise representations between views of a dataset. In particular, we randomly sample nodes and edges from a given graph to build the input subset for a view. Two views are fed into a parameter-shared Siamese network to extract the high-dimensional embeddings and estimate the information entropy of the entire graph. For the learning process, we propose to optimize the network using two objectives, simultaneously. Concretely, the input of the contrastive loss function consists of positive and negative pairs. Our selection strategy of pairs is different from previous works and we present a novel strategy to enhance the representation ability of the graph encoder by selecting nodes based on cross-view similarities. We enrich the diversity of the positive and negative pairs by selecting highly similar samples and totally different data with the guidance of cross-view similarity scores, respectively. We also introduce a cross-view consistency constraint on the representations generated from the different views. This objective guarantees the learned representations are consistent across views from the perspective of the entire graph. We conduct extensive experiments on seven graph benchmarks, and the proposed approach achieves competitive performance compared to the current state-of-the-art methods. The source code will be publicly released once this paper is accepted.
* ACM MM 2023 accepted
JacobiNeRF: NeRF Shaping with Mutual Information Gradients
Apr 01, 2023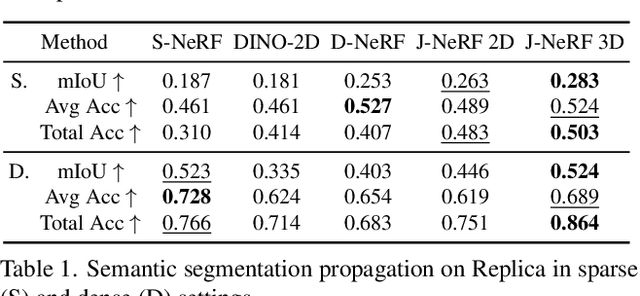
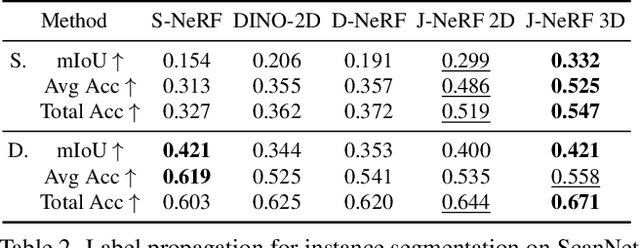

We propose a method that trains a neural radiance field (NeRF) to encode not only the appearance of the scene but also semantic correlations between scene points, regions, or entities -- aiming to capture their mutual co-variation patterns. In contrast to the traditional first-order photometric reconstruction objective, our method explicitly regularizes the learning dynamics to align the Jacobians of highly-correlated entities, which proves to maximize the mutual information between them under random scene perturbations. By paying attention to this second-order information, we can shape a NeRF to express semantically meaningful synergies when the network weights are changed by a delta along the gradient of a single entity, region, or even a point. To demonstrate the merit of this mutual information modeling, we leverage the coordinated behavior of scene entities that emerges from our shaping to perform label propagation for semantic and instance segmentation. Our experiments show that a JacobiNeRF is more efficient in propagating annotations among 2D pixels and 3D points compared to NeRFs without mutual information shaping, especially in extremely sparse label regimes -- thus reducing annotation burden. The same machinery can further be used for entity selection or scene modifications.
Deep Learning with Passive Optical Nonlinear Mapping
Jul 18, 2023Deep learning has fundamentally transformed artificial intelligence, but the ever-increasing complexity in deep learning models calls for specialized hardware accelerators. Optical accelerators can potentially offer enhanced performance, scalability, and energy efficiency. However, achieving nonlinear mapping, a critical component of neural networks, remains challenging optically. Here, we introduce a design that leverages multiple scattering in a reverberating cavity to passively induce optical nonlinear random mapping, without the need for additional laser power. A key advantage emerging from our work is that we show we can perform optical data compression, facilitated by multiple scattering in the cavity, to efficiently compress and retain vital information while also decreasing data dimensionality. This allows rapid optical information processing and generation of low dimensional mixtures of highly nonlinear features. These are particularly useful for applications demanding high-speed analysis and responses such as in edge computing devices. Utilizing rapid optical information processing capabilities, our optical platforms could potentially offer more efficient and real-time processing solutions for a broad range of applications. We demonstrate the efficacy of our design in improving computational performance across tasks, including classification, image reconstruction, key-point detection, and object detection, all achieved through optical data compression combined with a digital decoder. Notably, we observed high performance, at an extreme compression ratio, for real-time pedestrian detection. Our findings pave the way for novel algorithms and architectural designs for optical computing.
Harnessing the Web and Knowledge Graphs for Automated Impact Investing Scoring
Aug 04, 2023The Sustainable Development Goals (SDGs) were introduced by the United Nations in order to encourage policies and activities that help guarantee human prosperity and sustainability. SDG frameworks produced in the finance industry are designed to provide scores that indicate how well a company aligns with each of the 17 SDGs. This scoring enables a consistent assessment of investments that have the potential of building an inclusive and sustainable economy. As a result of the high quality and reliability required by such frameworks, the process of creating and maintaining them is time-consuming and requires extensive domain expertise. In this work, we describe a data-driven system that seeks to automate the process of creating an SDG framework. First, we propose a novel method for collecting and filtering a dataset of texts from different web sources and a knowledge graph relevant to a set of companies. We then implement and deploy classifiers trained with this data for predicting scores of alignment with SDGs for a given company. Our results indicate that our best performing model can accurately predict SDG scores with a micro average F1 score of 0.89, demonstrating the effectiveness of the proposed solution. We further describe how the integration of the models for its use by humans can be facilitated by providing explanations in the form of data relevant to a predicted score. We find that our proposed solution enables access to a large amount of information that analysts would normally not be able to process, resulting in an accurate prediction of SDG scores at a fraction of the cost.
Reinforcement Learning Under Probabilistic Spatio-Temporal Constraints with Time Windows
Jul 29, 2023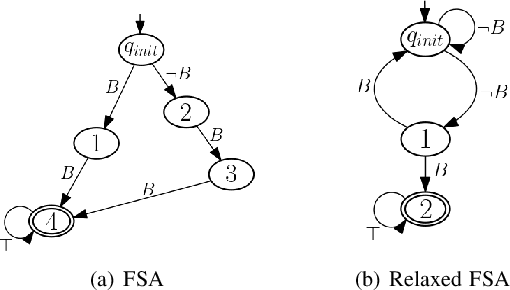
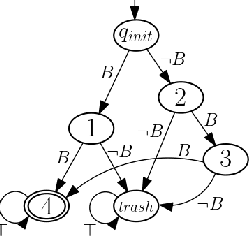
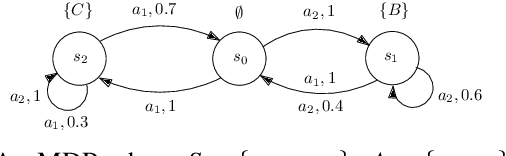
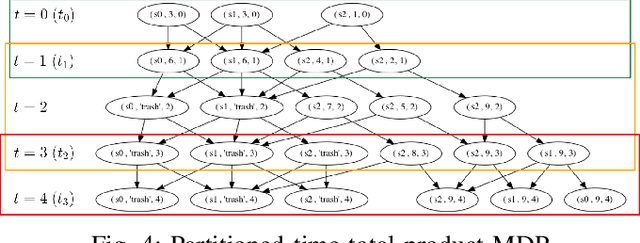
We propose an automata-theoretic approach for reinforcement learning (RL) under complex spatio-temporal constraints with time windows. The problem is formulated using a Markov decision process under a bounded temporal logic constraint. Different from existing RL methods that can eventually learn optimal policies satisfying such constraints, our proposed approach enforces a desired probability of constraint satisfaction throughout learning. This is achieved by translating the bounded temporal logic constraint into a total automaton and avoiding "unsafe" actions based on the available prior information regarding the transition probabilities, i.e., a pair of upper and lower bounds for each transition probability. We provide theoretical guarantees on the resulting probability of constraint satisfaction. We also provide numerical results in a scenario where a robot explores the environment to discover high-reward regions while fulfilling some periodic pick-up and delivery tasks that are encoded as temporal logic constraints.
Debiased Pairwise Learning from Positive-Unlabeled Implicit Feedback
Jul 29, 2023

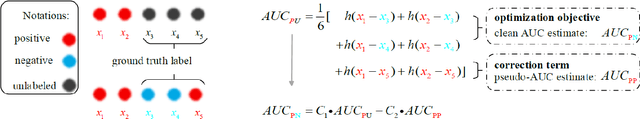

Learning contrastive representations from pairwise comparisons has achieved remarkable success in various fields, such as natural language processing, computer vision, and information retrieval. Collaborative filtering algorithms based on pairwise learning also rooted in this paradigm. A significant concern is the absence of labels for negative instances in implicit feedback data, which often results in the random selected negative instances contains false negatives and inevitably, biased embeddings. To address this issue, we introduce a novel correction method for sampling bias that yields a modified loss for pairwise learning called debiased pairwise loss (DPL). The key idea underlying DPL is to correct the biased probability estimates that result from false negatives, thereby correcting the gradients to approximate those of fully supervised data. The implementation of DPL only requires a small modification of the codes. Experimental studies on five public datasets validate the effectiveness of proposed learning method.
Private Information Retrieval and Its Applications: An Introduction, Open Problems, Future Directions
Apr 27, 2023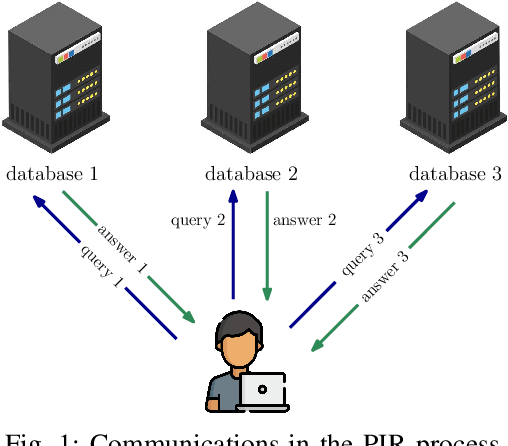
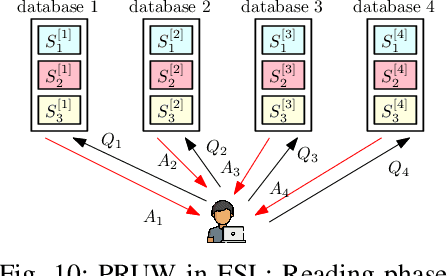
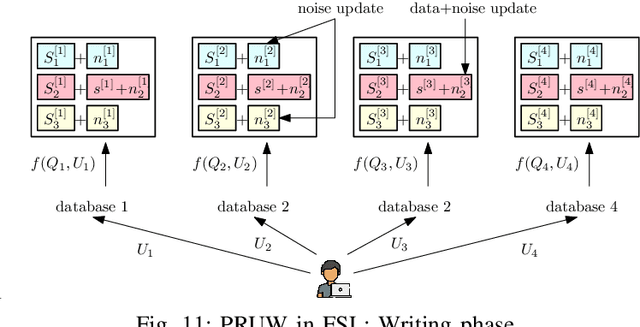
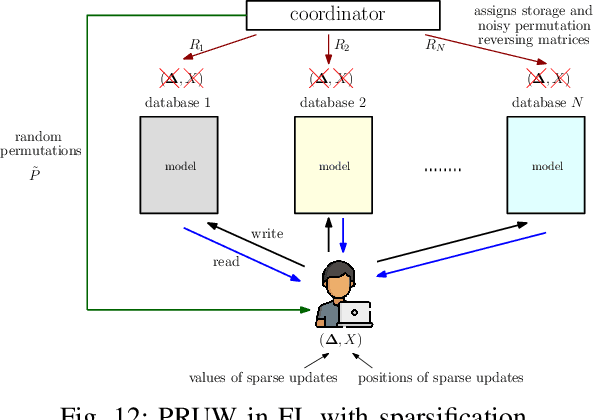
Private information retrieval (PIR) is a privacy setting that allows a user to download a required message from a set of messages stored in a system of databases without revealing the index of the required message to the databases. PIR was introduced under computational privacy guarantees, and is recently re-formulated to provide information-theoretic guarantees, resulting in \emph{information theoretic privacy}. Subsequently, many important variants of the basic PIR problem have been studied focusing on fundamental performance limits as well as achievable schemes. More recently, a variety of conceptual extensions of PIR have been introduced, such as, private set intersection (PSI), private set union (PSU), and private read-update-write (PRUW). Some of these extensions are mainly intended to solve the privacy issues that arise in distributed learning applications due to the extensive dependency of machine learning on users' private data. In this article, we first provide an introduction to basic PIR with examples, followed by a brief description of its immediate variants. We then provide a detailed discussion on the conceptual extensions of PIR, along with potential research directions.
ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation
Aug 03, 2023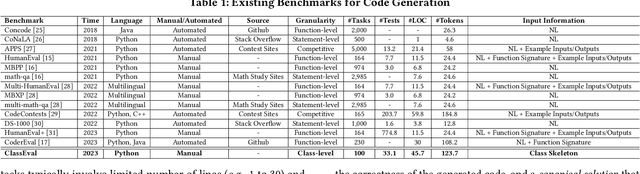


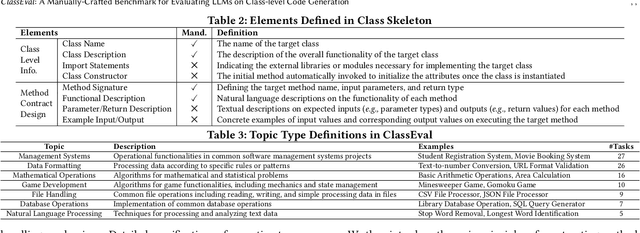
In this work, we make the first attempt to evaluate LLMs in a more challenging code generation scenario, i.e. class-level code generation. We first manually construct the first class-level code generation benchmark ClassEval of 100 class-level Python code generation tasks with approximately 500 person-hours. Based on it, we then perform the first study of 11 state-of-the-art LLMs on class-level code generation. Based on our results, we have the following main findings. First, we find that all existing LLMs show much worse performance on class-level code generation compared to on standalone method-level code generation benchmarks like HumanEval; and the method-level coding ability cannot equivalently reflect the class-level coding ability among LLMs. Second, we find that GPT-4 and GPT-3.5 still exhibit dominate superior than other LLMs on class-level code generation, and the second-tier models includes Instruct-Starcoder, Instruct-Codegen, and Wizardcoder with very similar performance. Third, we find that generating the entire class all at once (i.e. holistic generation strategy) is the best generation strategy only for GPT-4 and GPT-3.5, while method-by-method generation (i.e. incremental and compositional) is better strategies for the other models with limited ability of understanding long instructions and utilizing the middle information. Lastly, we find the limited model ability of generating method-dependent code and discuss the frequent error types in generated classes. Our benchmark is available at https://github.com/FudanSELab/ClassEval.
ADRNet: A Generalized Collaborative Filtering Framework Combining Clinical and Non-Clinical Data for Adverse Drug Reaction Prediction
Aug 03, 2023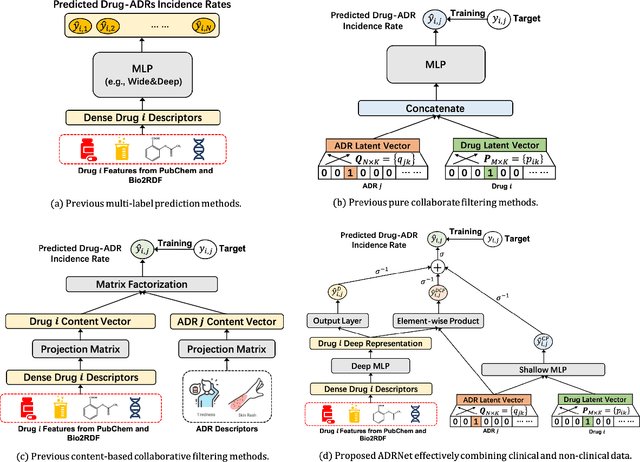
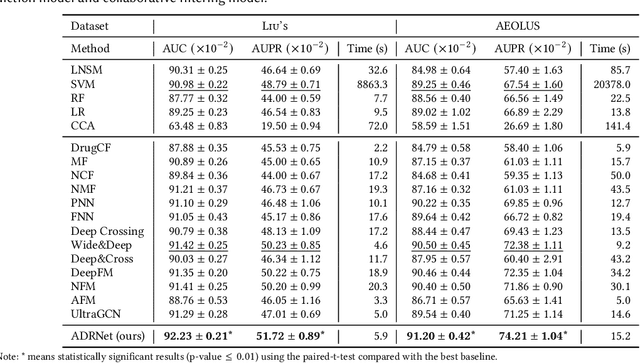
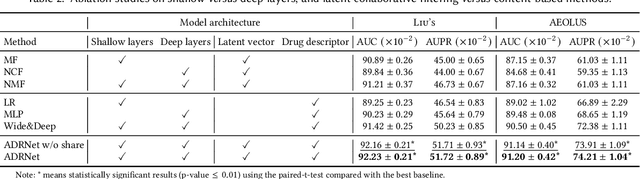

Adverse drug reaction (ADR) prediction plays a crucial role in both health care and drug discovery for reducing patient mortality and enhancing drug safety. Recently, many studies have been devoted to effectively predict the drug-ADRs incidence rates. However, these methods either did not effectively utilize non-clinical data, i.e., physical, chemical, and biological information about the drug, or did little to establish a link between content-based and pure collaborative filtering during the training phase. In this paper, we first formulate the prediction of multi-label ADRs as a drug-ADR collaborative filtering problem, and to the best of our knowledge, this is the first work to provide extensive benchmark results of previous collaborative filtering methods on two large publicly available clinical datasets. Then, by exploiting the easy accessible drug characteristics from non-clinical data, we propose ADRNet, a generalized collaborative filtering framework combining clinical and non-clinical data for drug-ADR prediction. Specifically, ADRNet has a shallow collaborative filtering module and a deep drug representation module, which can exploit the high-dimensional drug descriptors to further guide the learning of low-dimensional ADR latent embeddings, which incorporates both the benefits of collaborative filtering and representation learning. Extensive experiments are conducted on two publicly available real-world drug-ADR clinical datasets and two non-clinical datasets to demonstrate the accuracy and efficiency of the proposed ADRNet. The code is available at https://github.com/haoxuanli-pku/ADRnet.
Neural Approaches to Entity-Centric Information Extraction
Apr 15, 2023

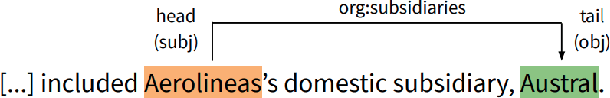
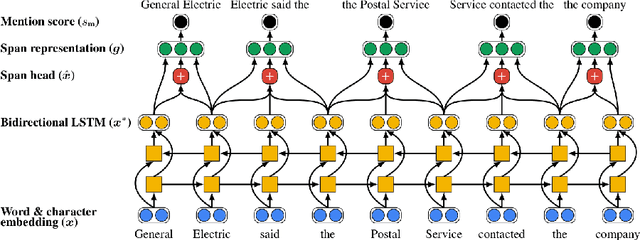
Artificial Intelligence (AI) has huge impact on our daily lives with applications such as voice assistants, facial recognition, chatbots, autonomously driving cars, etc. Natural Language Processing (NLP) is a cross-discipline of AI and Linguistics, dedicated to study the understanding of the text. This is a very challenging area due to unstructured nature of the language, with many ambiguous and corner cases. In this thesis we address a very specific area of NLP that involves the understanding of entities (e.g., names of people, organizations, locations) in text. First, we introduce a radically different, entity-centric view of the information in text. We argue that instead of using individual mentions in text to understand their meaning, we should build applications that would work in terms of entity concepts. Next, we present a more detailed model on how the entity-centric approach can be used for the entity linking task. In our work, we show that this task can be improved by considering performing entity linking at the coreference cluster level rather than each of the mentions individually. In our next work, we further study how information from Knowledge Base entities can be integrated into text. Finally, we analyze the evolution of the entities from the evolving temporal perspective.