 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PAIF: Perception-Aware Infrared-Visible Image Fusion for Attack-Tolerant Semantic Segmentation
Aug 08, 2023

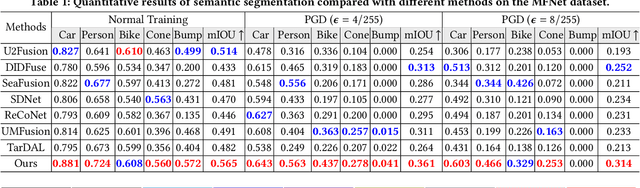
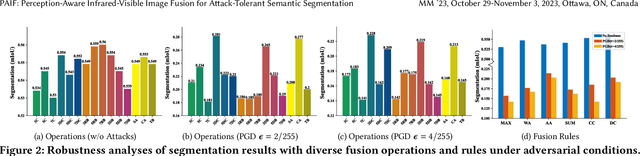
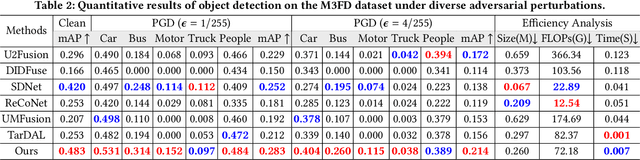
Infrared and visible image fusion is a powerful technique that combines complementary information from different modalities for downstream semantic perception tasks. Existing learning-based methods show remarkable performance, but are suffering from the inherent vulnerability of adversarial attacks, causing a significant decrease in accuracy. In this work, a perception-aware fusion framework is proposed to promote segmentation robustness in adversarial scenes. We first conduct systematic analyses about the components of image fusion, investigating the correlation with segmentation robustness under adversarial perturbations. Based on these analyses, we propose a harmonized architecture search with a decomposition-based structure to balance standard accuracy and robustness. We also propose an adaptive learning strategy to improve the parameter robustness of image fusion, which can learn effective feature extraction under diverse adversarial perturbations. Thus, the goals of image fusion (\textit{i.e.,} extracting complementary features from source modalities and defending attack) can be realized from the perspectives of architectural and learning strategies. Extensive experimental results demonstrate that our scheme substantially enhances the robustness, with gains of 15.3% mIOU of segmentation in the adversarial scene, compared with advanced competitors. The source codes are available at https://github.com/LiuZhu-CV/PAIF.
Calibrated Explanations: with Uncertainty Information and Counterfactuals
May 03, 2023
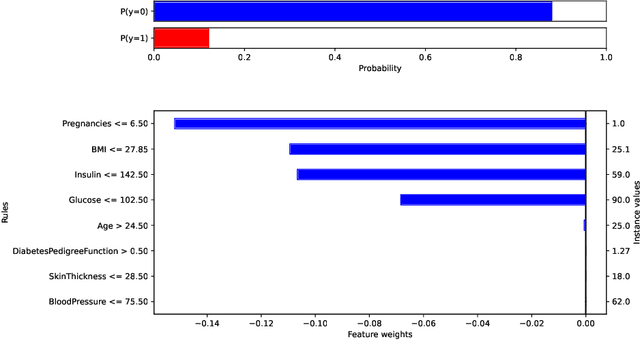
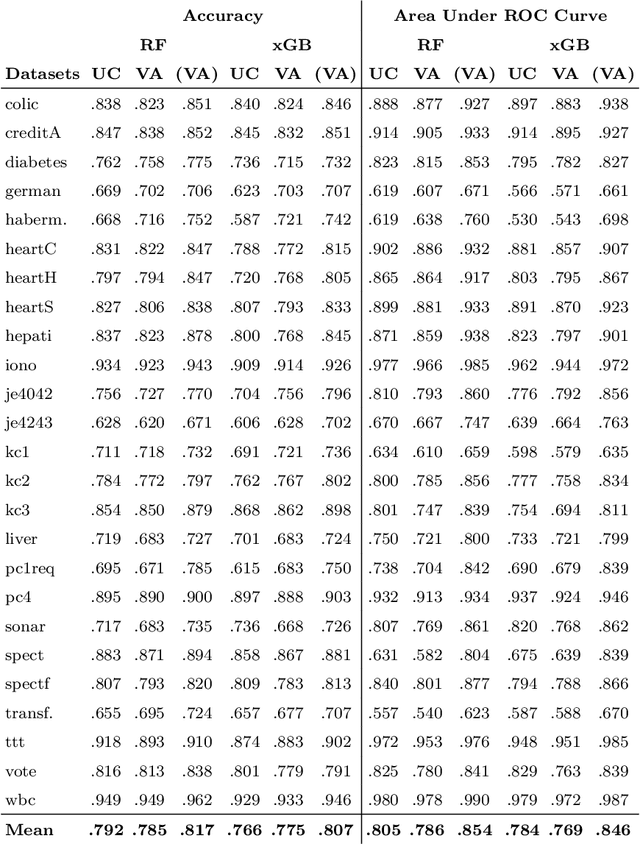
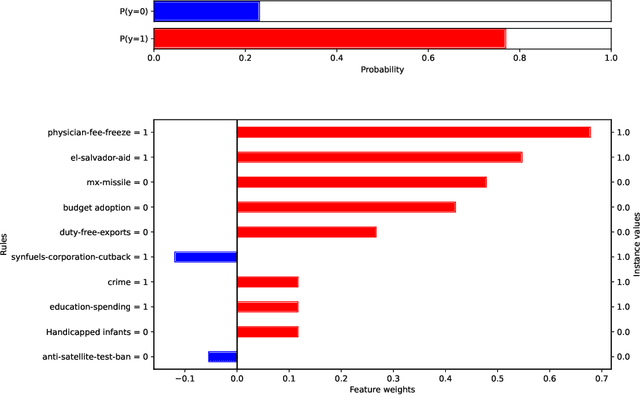
Artificial Intelligence (AI) has become an integral part of decision support systems (DSSs) in various domains, but the lack of transparency in the predictive models used in AI-based DSSs can lead to misuse or disuse. Explainable Artificial Intelligence (XAI) aims to create AI systems that can explain their rationale to human users. Local explanations in XAI can provide information about the causes of individual predictions in terms of feature importance, but they suffer from drawbacks such as instability. To address these issues, we propose a new feature importance explanation method, Calibrated Explanations (CE), which is based on Venn-Abers and calibrates the underlying model while generating feature importance explanations. CE provides fast, reliable, stable, and robust explanations, along with uncertainty quantification of the probability estimates and feature importance weights. Furthermore, the method is model agnostic with easily understood conditional rules and can also generate counterfactual explanations with uncertainty quantification.
Heterogeneous Forgetting Compensation for Class-Incremental Learning
Aug 07, 2023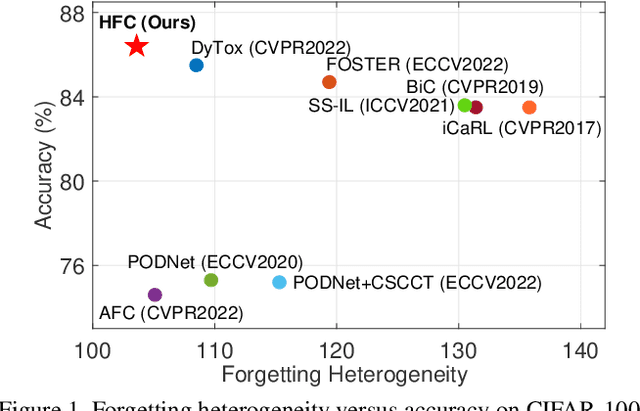
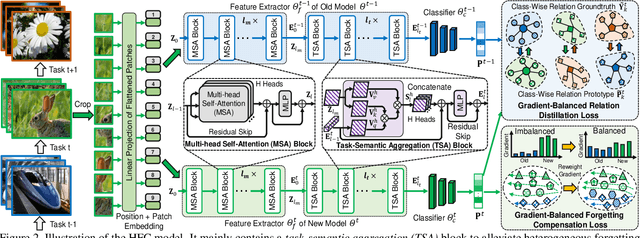
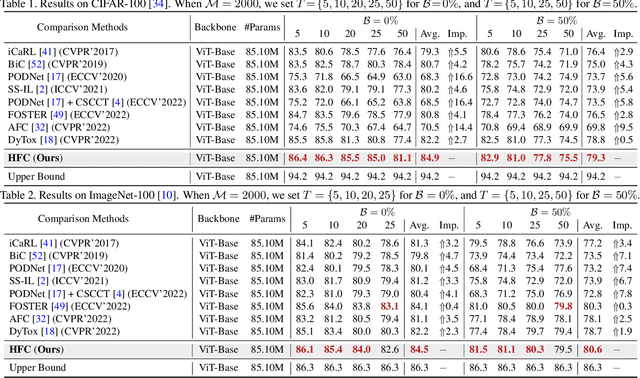
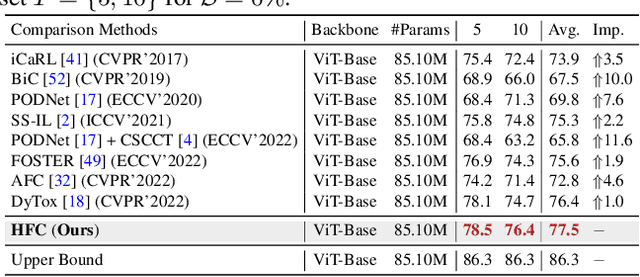
Class-incremental learning (CIL) has achieved remarkable successes in learning new classes consecutively while overcoming catastrophic forgetting on old categories. However, most existing CIL methods unreasonably assume that all old categories have the same forgetting pace, and neglect negative influence of forgetting heterogeneity among different old classes on forgetting compensation. To surmount the above challenges, we develop a novel Heterogeneous Forgetting Compensation (HFC) model, which can resolve heterogeneous forgetting of easy-to-forget and hard-to-forget old categories from both representation and gradient aspects. Specifically, we design a task-semantic aggregation block to alleviate heterogeneous forgetting from representation aspect. It aggregates local category information within each task to learn task-shared global representations. Moreover, we develop two novel plug-and-play losses: a gradient-balanced forgetting compensation loss and a gradient-balanced relation distillation loss to alleviate forgetting from gradient aspect. They consider gradient-balanced compensation to rectify forgetting heterogeneity of old categories and heterogeneous relation consistency. Experiments on several representative datasets illustrate effectiveness of our HFC model. The code is available at https://github.com/JiahuaDong/HFC.
Keyword Spotting Simplified: A Segmentation-Free Approach using Character Counting and CTC re-scoring
Aug 07, 2023
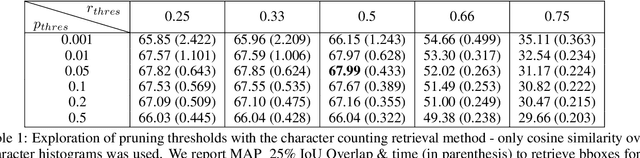
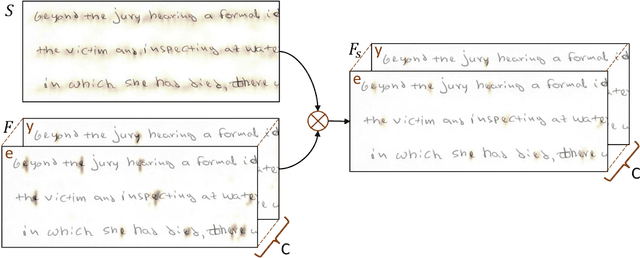
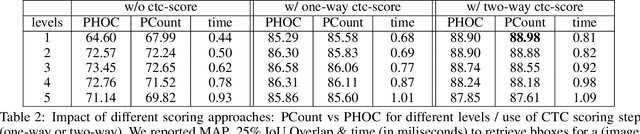
Recent advances in segmentation-free keyword spotting treat this problem w.r.t. an object detection paradigm and borrow from state-of-the-art detection systems to simultaneously propose a word bounding box proposal mechanism and compute a corresponding representation. Contrary to the norm of such methods that rely on complex and large DNN models, we propose a novel segmentation-free system that efficiently scans a document image to find rectangular areas that include the query information. The underlying model is simple and compact, predicting character occurrences over rectangular areas through an implicitly learned scale map, trained on word-level annotated images. The proposed document scanning is then performed using this character counting in a cost-effective manner via integral images and binary search. Finally, the retrieval similarity by character counting is refined by a pyramidal representation and a CTC-based re-scoring algorithm, fully utilizing the trained CNN model. Experimental validation on two widely-used datasets shows that our method achieves state-of-the-art results outperforming the more complex alternatives, despite the simplicity of the underlying model.
Dual Aggregation Transformer for Image Super-Resolution
Aug 07, 2023
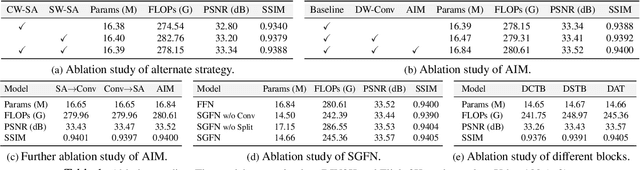
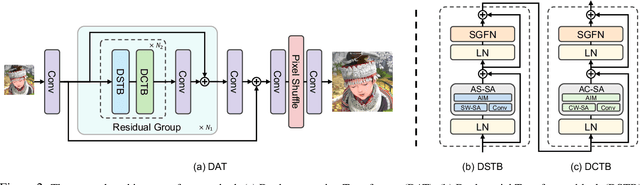
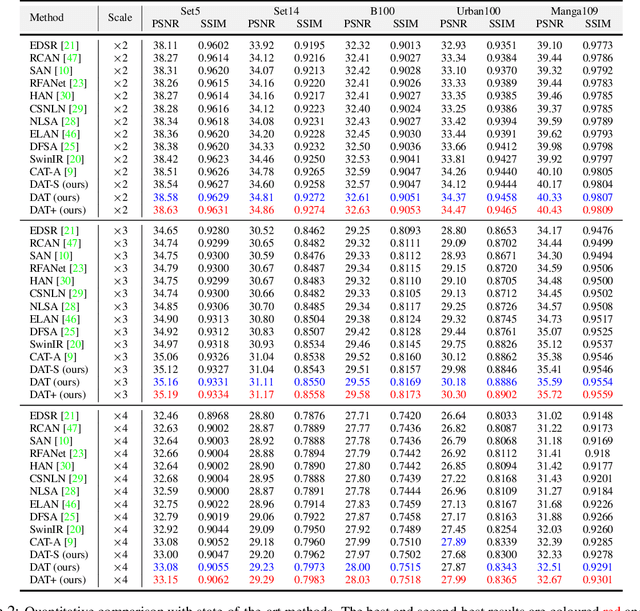
Transformer has recently gained considerable popularity in low-level vision tasks, including image super-resolution (SR). These networks utilize self-attention along different dimensions, spatial or channel, and achieve impressive performance. This inspires us to combine the two dimensions in Transformer for a more powerful representation capability. Based on the above idea, we propose a novel Transformer model, Dual Aggregation Transformer (DAT), for image SR. Our DAT aggregates features across spatial and channel dimensions, in the inter-block and intra-block dual manner. Specifically, we alternately apply spatial and channel self-attention in consecutive Transformer blocks. The alternate strategy enables DAT to capture the global context and realize inter-block feature aggregation. Furthermore, we propose the adaptive interaction module (AIM) and the spatial-gate feed-forward network (SGFN) to achieve intra-block feature aggregation. AIM complements two self-attention mechanisms from corresponding dimensions. Meanwhile, SGFN introduces additional non-linear spatial information in the feed-forward network. Extensive experiments show that our DAT surpasses current methods. Code and models are obtainable at https://github.com/zhengchen1999/DAT.
PMU measurements based short-term voltage stability assessment of power systems via deep transfer learning
Aug 07, 2023Deep learning has emerged as an effective solution for addressing the challenges of short-term voltage stability assessment (STVSA) in power systems. However, existing deep learning-based STVSA approaches face limitations in adapting to topological changes, sample labeling, and handling small datasets. To overcome these challenges, this paper proposes a novel phasor measurement unit (PMU) measurements-based STVSA method by using deep transfer learning. The method leverages the real-time dynamic information captured by PMUs to create an initial dataset. It employs temporal ensembling for sample labeling and utilizes least squares generative adversarial networks (LSGAN) for data augmentation, enabling effective deep learning on small-scale datasets. Additionally, the method enhances adaptability to topological changes by exploring connections between different faults. Experimental results on the IEEE 39-bus test system demonstrate that the proposed method improves model evaluation accuracy by approximately 20% through transfer learning, exhibiting strong adaptability to topological changes. Leveraging the self-attention mechanism of the Transformer model, this approach offers significant advantages over shallow learning methods and other deep learning-based approaches.
Joint Device Identification, Channel Estimation, and Signal Detection for LEO Satellite-Enabled Random Access
Aug 07, 2023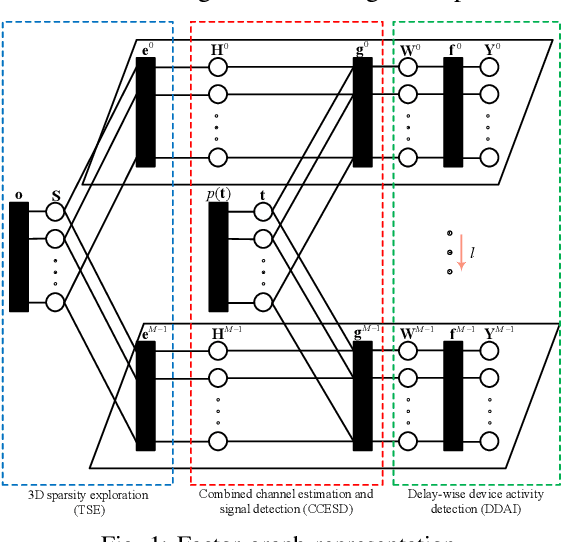
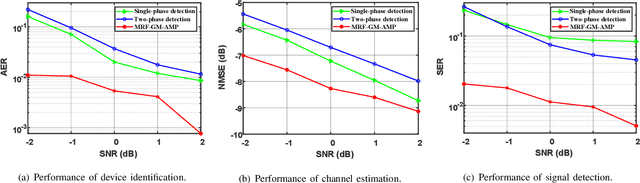
This paper investigates joint device identification, channel estimation, and signal detection for LEO satellite-enabled grant-free random access, where a multiple-input multipleoutput (MIMO) system with orthogonal time-frequency space modulation (OTFS) is utilized to combat the dynamics of the terrestrial-satellite link (TSL). We divide the receiver structure into three modules: first, a linear module for identifying active devices, which leverages the generalized approximate message passing (GAMP) algorithm to eliminate inter-user interference in the delay-Doppler domain; second, a non-linear module adopting the message passing algorithm to jointly estimate channel and detect transmit signals; the third aided by Markov random field (MRF) aims to explore the three dimensional block sparsity of channel in the delay-Doppler-angle domain. The soft information is exchanged iteratively between these three modules by careful scheduling. Furthermore, the expectation-maximization algorithm is embedded to learn the hyperparameters in prior distributions. Simulation results demonstrate that the proposed scheme outperforms the conventional methods significantly in terms of activity error rate, channel estimation accuracy, and symbol error rate.
Exploring Automated Distractor and Feedback Generation for Math Multiple-choice Questions via In-context Learning
Aug 07, 2023

Multiple-choice questions (MCQs) are ubiquitous in almost all levels of education since they are easy to administer, grade, and are a reliable format in both assessments and practices. An important aspect of MCQs is the distractors, i.e., incorrect options that are designed to target specific misconceptions or insufficient knowledge among students. To date, the task of crafting high-quality distractors has largely remained a labor-intensive process for teachers and learning content designers, which has limited scalability. In this work, we explore the task of automated distractor and corresponding feedback message generation in math MCQs using large language models. We establish a formulation of these two tasks and propose a simple, in-context learning-based solution. Moreover, we explore using two non-standard metrics to evaluate the quality of the generated distractors and feedback messages. We conduct extensive experiments on these tasks using a real-world MCQ dataset that contains student response information. Our findings suggest that there is a lot of room for improvement in automated distractor and feedback generation. We also outline several directions for future work
Generative AI trial for nonviolent communication mediation
Aug 07, 2023Aiming for a mixbiotic society that combines freedom and solidarity among people with diverse values, I focused on nonviolent communication (NVC) that enables compassionate giving in various situations of social division and conflict, and tried a generative AI for it. Specifically, ChatGPT was used in place of the traditional certified trainer to test the possibility of mediating (modifying) input sentences in four processes: observation, feelings, needs, and requests. The results indicate that there is potential for the application of generative AI, although not yet at a practical level. Suggested improvement guidelines included adding model responses, relearning revised responses, specifying appropriate terminology for each process, and re-asking for required information. The use of generative AI will be useful initially to assist certified trainers, to prepare for and review events and workshops, and in the future to support consensus building and cooperative behavior in digital democracy, platform cooperatives, and cyber-human social co-operating systems. It is hoped that the widespread use of NVC mediation using generative AI will lead to the early realization of a mixbiotic society.
Phase Matching for Out-of-Distribution Generalization
Aug 07, 2023
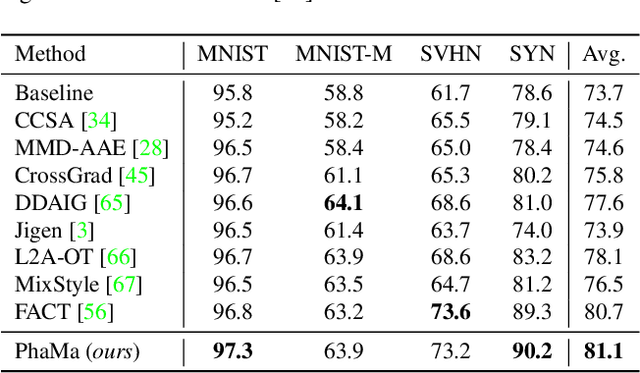
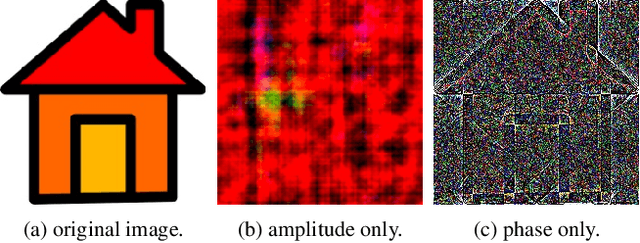
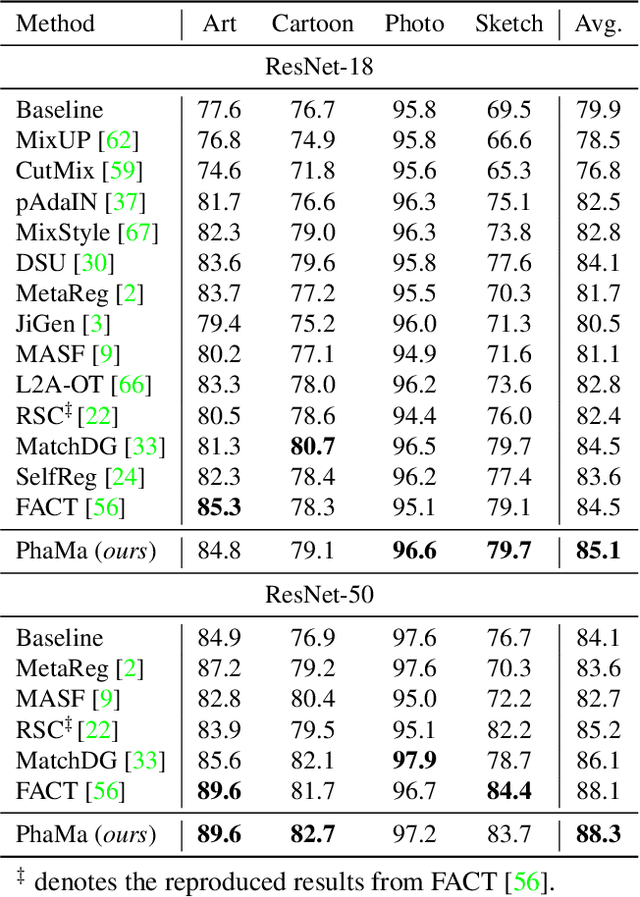
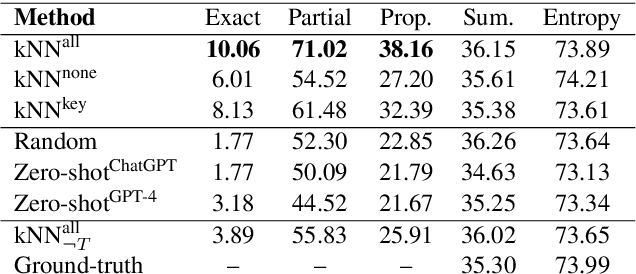
The Fourier transform, serving as an explicit decomposition method for visual signals, has been employed to explain the out-of-distribution generalization behaviors of Convolutional Neural Networks (CNNs). Previous studies have indicated that the amplitude spectrum is susceptible to the disturbance caused by distribution shifts. On the other hand, the phase spectrum preserves highly-structured spatial information, which is crucial for robust visual representation learning. However, the spatial relationships of phase spectrum remain unexplored in previous researches. In this paper, we aim to clarify the relationships between Domain Generalization (DG) and the frequency components, and explore the spatial relationships of the phase spectrum. Specifically, we first introduce a Fourier-based structural causal model which interprets the phase spectrum as semi-causal factors and the amplitude spectrum as non-causal factors. Then, we propose Phase Matching (PhaMa) to address DG problems. Our method introduces perturbations on the amplitude spectrum and establishes spatial relationships to match the phase components. Through experiments on multiple benchmarks, we demonstrate that our proposed method achieves state-of-the-art performance in domain generalization and out-of-distribution robustness tasks.