 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Toward Transparent Sequence Models with Model-Based Tree Markov Model
Jul 28, 2023
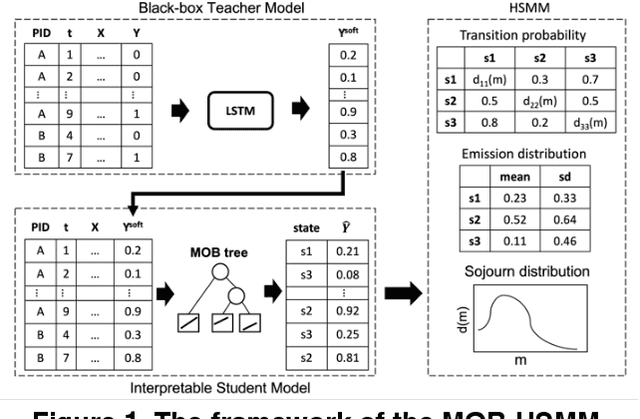

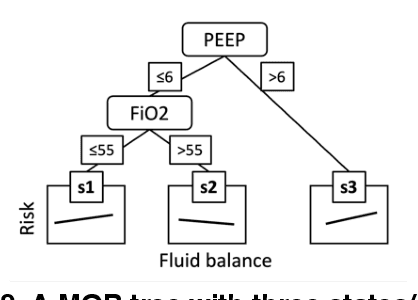

In this study, we address the interpretability issue in complex, black-box Machine Learning models applied to sequence data. We introduce the Model-Based tree Hidden Semi-Markov Model (MOB-HSMM), an inherently interpretable model aimed at detecting high mortality risk events and discovering hidden patterns associated with the mortality risk in Intensive Care Units (ICU). This model leverages knowledge distilled from Deep Neural Networks (DNN) to enhance predictive performance while offering clear explanations. Our experimental results indicate the improved performance of Model-Based trees (MOB trees) via employing LSTM for learning sequential patterns, which are then transferred to MOB trees. Integrating MOB trees with the Hidden Semi-Markov Model (HSMM) in the MOB-HSMM enables uncovering potential and explainable sequences using available information.
Both Spatial and Frequency Cues Contribute to High-Fidelity Image Inpainting
Jul 15, 2023
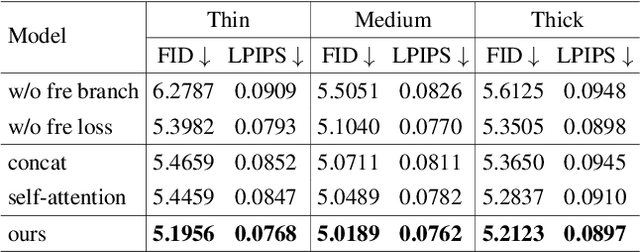
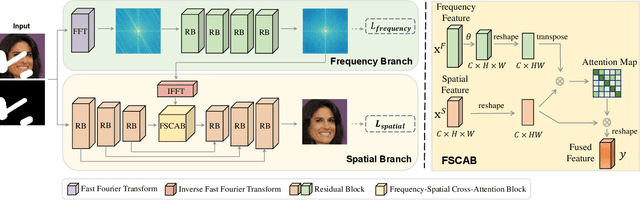
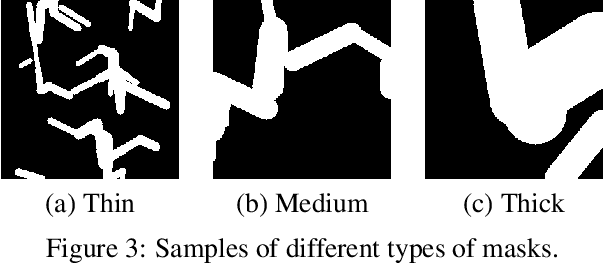
Deep generative approaches have obtained great success in image inpainting recently. However, most generative inpainting networks suffer from either over-smooth results or aliasing artifacts. The former lacks high-frequency details, while the latter lacks semantic structure. To address this issue, we propose an effective Frequency-Spatial Complementary Network (FSCN) by exploiting rich semantic information in both spatial and frequency domains. Specifically, we introduce an extra Frequency Branch and Frequency Loss on the spatial-based network to impose direct supervision on the frequency information, and propose a Frequency-Spatial Cross-Attention Block (FSCAB) to fuse multi-domain features and combine the corresponding characteristics. With our FSCAB, the inpainting network is capable of capturing frequency information and preserving visual consistency simultaneously. Extensive quantitative and qualitative experiments demonstrate that our inpainting network can effectively achieve superior results, outperforming previous state-of-the-art approaches with significantly fewer parameters and less computation cost. The code will be released soon.
From Military to Healthcare: Adopting and Expanding Ethical Principles for Generative Artificial Intelligence
Aug 04, 2023
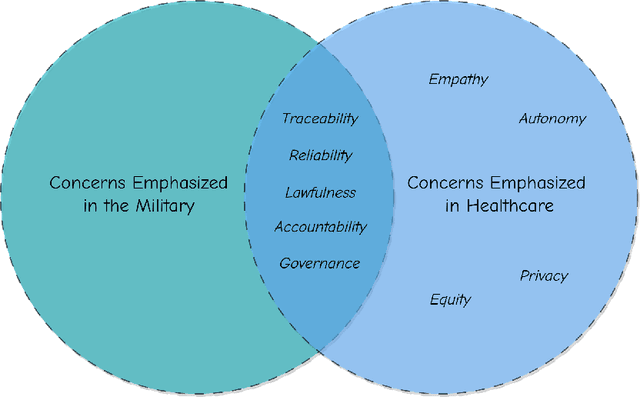
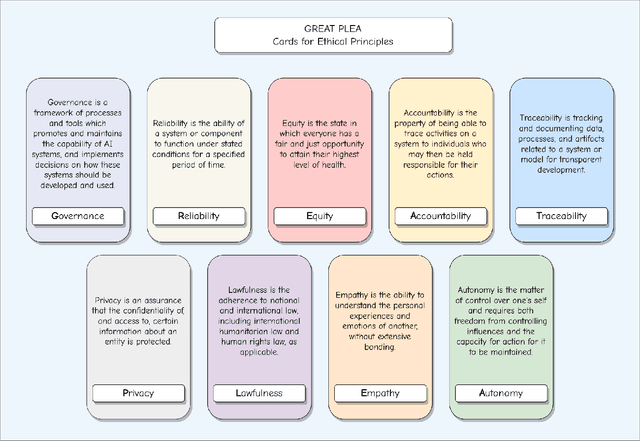
In 2020, the U.S. Department of Defense officially disclosed a set of ethical principles to guide the use of Artificial Intelligence (AI) technologies on future battlefields. Despite stark differences, there are core similarities between the military and medical service. Warriors on battlefields often face life-altering circumstances that require quick decision-making. Medical providers experience similar challenges in a rapidly changing healthcare environment, such as in the emergency department or during surgery treating a life-threatening condition. Generative AI, an emerging technology designed to efficiently generate valuable information, holds great promise. As computing power becomes more accessible and the abundance of health data, such as electronic health records, electrocardiograms, and medical images, increases, it is inevitable that healthcare will be revolutionized by this technology. Recently, generative AI has captivated the research community, leading to debates about its application in healthcare, mainly due to concerns about transparency and related issues. Meanwhile, concerns about the potential exacerbation of health disparities due to modeling biases have raised notable ethical concerns regarding the use of this technology in healthcare. However, the ethical principles for generative AI in healthcare have been understudied, and decision-makers often fail to consider the significance of generative AI. In this paper, we propose GREAT PLEA ethical principles, encompassing governance, reliability, equity, accountability, traceability, privacy, lawfulness, empathy, and autonomy, for generative AI in healthcare. We aim to proactively address the ethical dilemmas and challenges posed by the integration of generative AI in healthcare.
World-Model-Based Control for Industrial box-packing of Multiple Objects using NewtonianVAE
Aug 04, 2023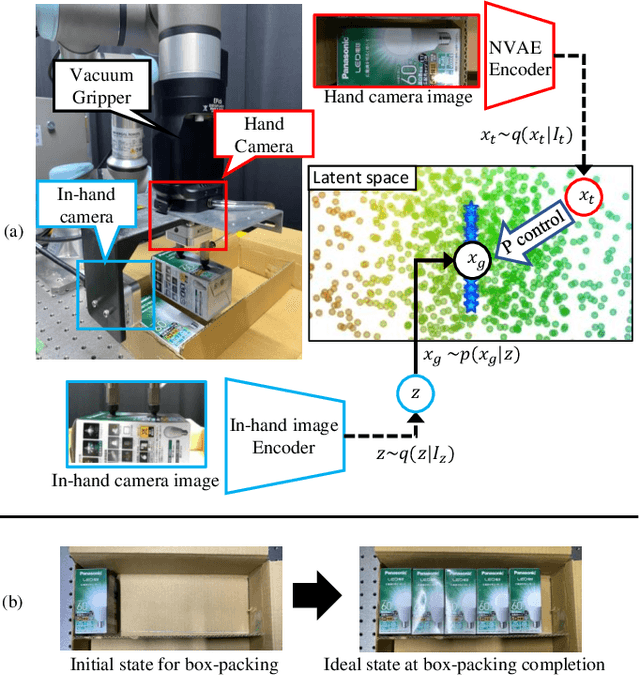
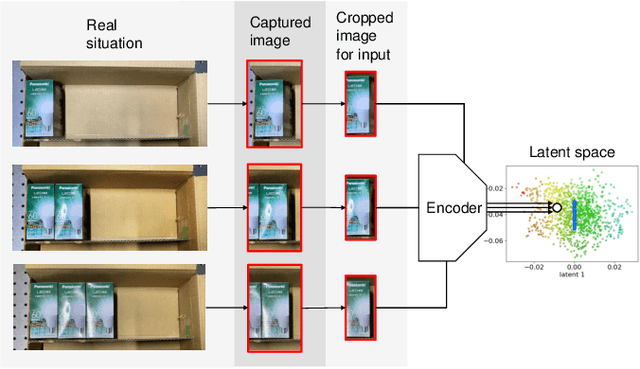
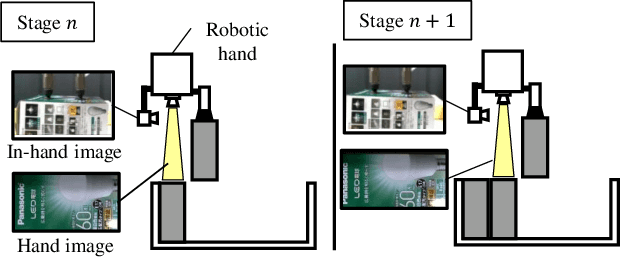

The process of industrial box-packing, which involves the accurate placement of multiple objects, requires high-accuracy positioning and sequential actions. When a robot is tasked with placing an object at a specific location with high accuracy, it is important not only to have information about the location of the object to be placed, but also the posture of the object grasped by the robotic hand. Often, industrial box-packing requires the sequential placement of identically shaped objects into a single box. The robot's action should be determined by the same learned model. In factories, new kinds of products often appear and there is a need for a model that can easily adapt to them. Therefore, it should be easy to collect data to train the model. In this study, we designed a robotic system to automate real-world industrial tasks, employing a vision-based learning control model. We propose in-hand-view-sensitive Newtonian variational autoencoder (ihVS-NVAE), which employs an RGB camera to obtain in-hand postures of objects. We demonstrate that our model, trained for a single object-placement task, can handle sequential tasks without additional training. To evaluate efficacy of the proposed model, we employed a real robot to perform sequential industrial box-packing of multiple objects. Results showed that the proposed model achieved a 100% success rate in industrial box-packing tasks, thereby outperforming the state-of-the-art and conventional approaches, underscoring its superior effectiveness and potential in industrial tasks.
On Interpolating Experts and Multi-Armed Bandits
Aug 04, 2023Learning with expert advice and multi-armed bandit are two classic online decision problems which differ on how the information is observed in each round of the game. We study a family of problems interpolating the two. For a vector $\mathbf{m}=(m_1,\dots,m_K)\in \mathbb{N}^K$, an instance of $\mathbf{m}$-MAB indicates that the arms are partitioned into $K$ groups and the $i$-th group contains $m_i$ arms. Once an arm is pulled, the losses of all arms in the same group are observed. We prove tight minimax regret bounds for $\mathbf{m}$-MAB and design an optimal PAC algorithm for its pure exploration version, $\mathbf{m}$-BAI, where the goal is to identify the arm with minimum loss with as few rounds as possible. We show that the minimax regret of $\mathbf{m}$-MAB is $\Theta\left(\sqrt{T\sum_{k=1}^K\log (m_k+1)}\right)$ and the minimum number of pulls for an $(\epsilon,0.05)$-PAC algorithm of $\mathbf{m}$-BAI is $\Theta\left(\frac{1}{\epsilon^2}\cdot \sum_{k=1}^K\log (m_k+1)\right)$. Both our upper bounds and lower bounds for $\mathbf{m}$-MAB can be extended to a more general setting, namely the bandit with graph feedback, in terms of the clique cover and related graph parameters. As consequences, we obtained tight minimax regret bounds for several families of feedback graphs.
EDI: ESKF-based Disjoint Initialization for Visual-Inertial SLAM Systems
Aug 04, 2023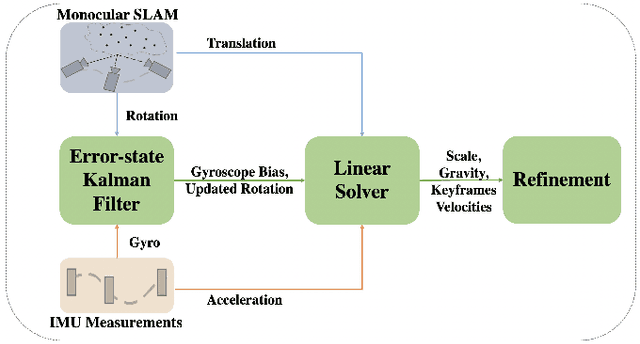
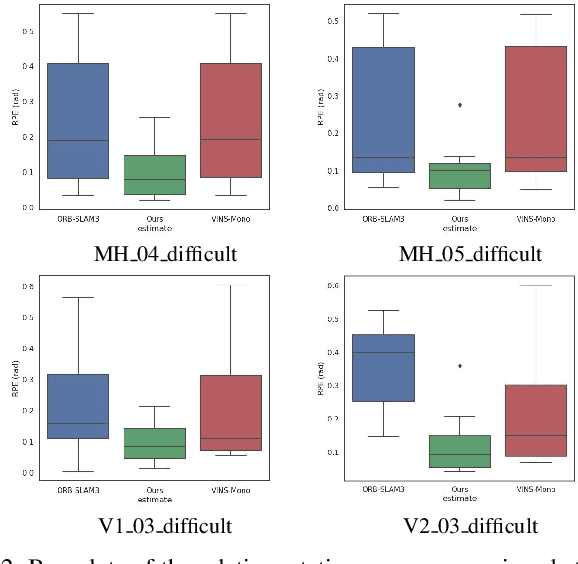

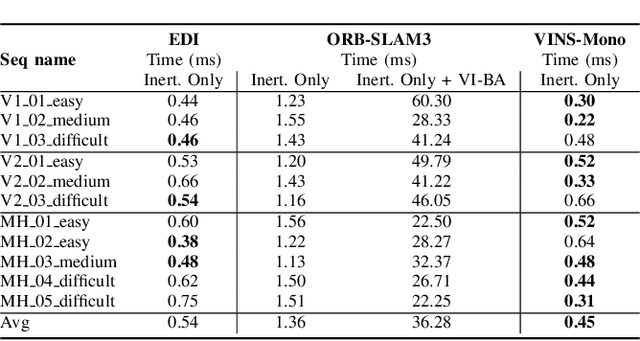
Visual-inertial initialization can be classified into joint and disjoint approaches. Joint approaches tackle both the visual and the inertial parameters together by aligning observations from feature-bearing points based on IMU integration then use a closed-form solution with visual and acceleration observations to find initial velocity and gravity. In contrast, disjoint approaches independently solve the Structure from Motion (SFM) problem and determine inertial parameters from up-to-scale camera poses obtained from pure monocular SLAM. However, previous disjoint methods have limitations, like assuming negligible acceleration bias impact or accurate rotation estimation by pure monocular SLAM. To address these issues, we propose EDI, a novel approach for fast, accurate, and robust visual-inertial initialization. Our method incorporates an Error-state Kalman Filter (ESKF) to estimate gyroscope bias and correct rotation estimates from monocular SLAM, overcoming dependence on pure monocular SLAM for rotation estimation. To estimate the scale factor without prior information, we offer a closed-form solution for initial velocity, scale, gravity, and acceleration bias estimation. To address gravity and acceleration bias coupling, we introduce weights in the linear least-squares equations, ensuring acceleration bias observability and handling outliers. Extensive evaluation on the EuRoC dataset shows that our method achieves an average scale error of 5.8% in less than 3 seconds, outperforming other state-of-the-art disjoint visual-inertial initialization approaches, even in challenging environments and with artificial noise corruption.
Adapting to Change: Robust Counterfactual Explanations in Dynamic Data Landscapes
Aug 04, 2023We introduce a novel semi-supervised Graph Counterfactual Explainer (GCE) methodology, Dynamic GRAph Counterfactual Explainer (DyGRACE). It leverages initial knowledge about the data distribution to search for valid counterfactuals while avoiding using information from potentially outdated decision functions in subsequent time steps. Employing two graph autoencoders (GAEs), DyGRACE learns the representation of each class in a binary classification scenario. The GAEs minimise the reconstruction error between the original graph and its learned representation during training. The method involves (i) optimising a parametric density function (implemented as a logistic regression function) to identify counterfactuals by maximising the factual autoencoder's reconstruction error, (ii) minimising the counterfactual autoencoder's error, and (iii) maximising the similarity between the factual and counterfactual graphs. This semi-supervised approach is independent of an underlying black-box oracle. A logistic regression model is trained on a set of graph pairs to learn weights that aid in finding counterfactuals. At inference, for each unseen graph, the logistic regressor identifies the best counterfactual candidate using these learned weights, while the GAEs can be iteratively updated to represent the continual adaptation of the learned graph representation over iterations. DyGRACE is quite effective and can act as a drift detector, identifying distributional drift based on differences in reconstruction errors between iterations. It avoids reliance on the oracle's predictions in successive iterations, thereby increasing the efficiency of counterfactual discovery. DyGRACE, with its capacity for contrastive learning and drift detection, will offer new avenues for semi-supervised learning and explanation generation.
Time for aCTIon: Automated Analysis of Cyber Threat Intelligence in the Wild
Jul 14, 2023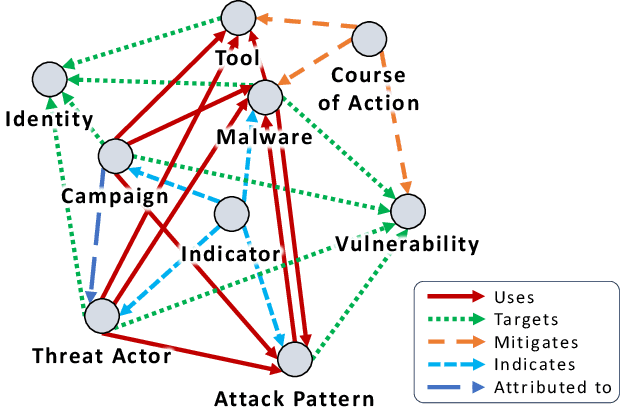
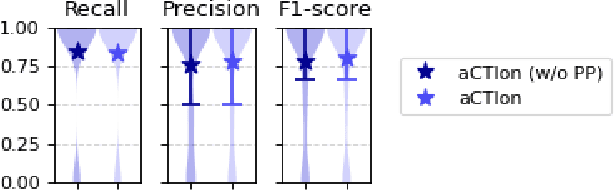
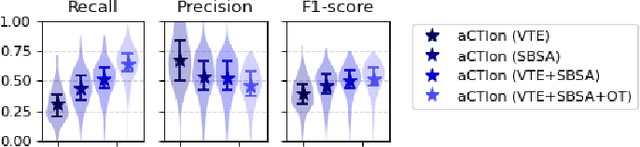
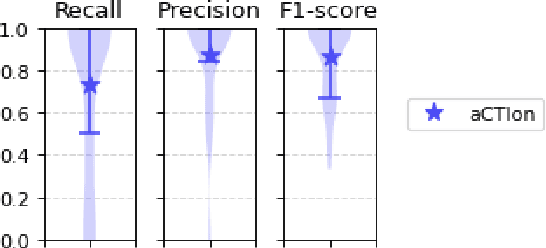
Cyber Threat Intelligence (CTI) plays a crucial role in assessing risks and enhancing security for organizations. However, the process of extracting relevant information from unstructured text sources can be expensive and time-consuming. Our empirical experience shows that existing tools for automated structured CTI extraction have performance limitations. Furthermore, the community lacks a common benchmark to quantitatively assess their performance. We fill these gaps providing a new large open benchmark dataset and aCTIon, a structured CTI information extraction tool. The dataset includes 204 real-world publicly available reports and their corresponding structured CTI information in STIX format. Our team curated the dataset involving three independent groups of CTI analysts working over the course of several months. To the best of our knowledge, this dataset is two orders of magnitude larger than previously released open source datasets. We then design aCTIon, leveraging recently introduced large language models (GPT3.5) in the context of two custom information extraction pipelines. We compare our method with 10 solutions presented in previous work, for which we develop our own implementations when open-source implementations were lacking. Our results show that aCTIon outperforms previous work for structured CTI extraction with an improvement of the F1-score from 10%points to 50%points across all tasks.
E-CLIP: Towards Label-efficient Event-based Open-world Understanding by CLIP
Aug 06, 2023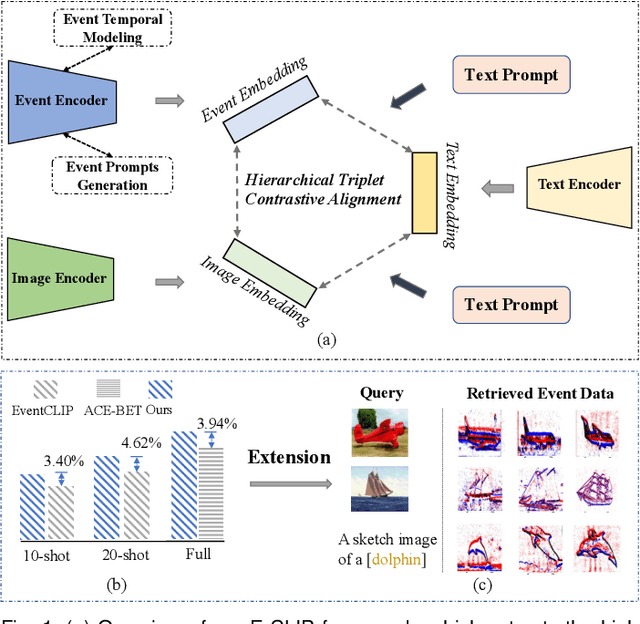
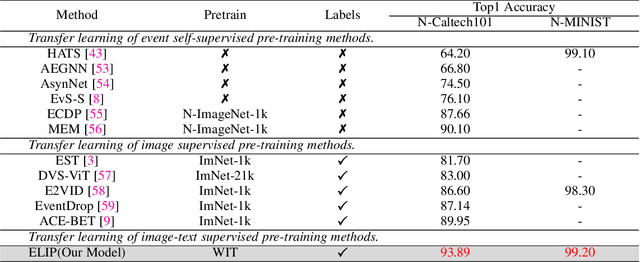
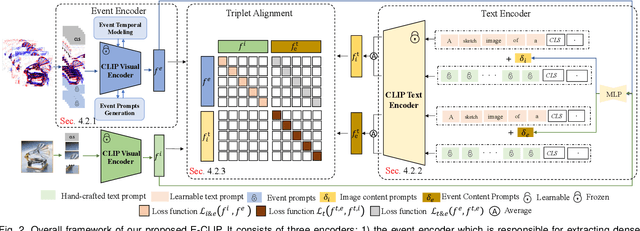
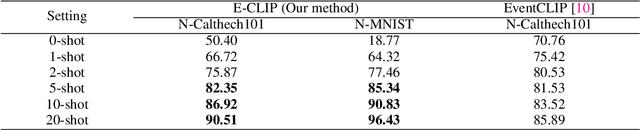
Contrasting Language-image pertaining (CLIP) has recently shown promising open-world and few-shot performance on 2D image-based recognition tasks. However, the transferred capability of CLIP to the novel event camera data still remains under-explored. In particular, due to the modality gap with the image-text data and the lack of large-scale datasets, achieving this goal is non-trivial and thus requires significant research innovation. In this paper, we propose E-CLIP, a novel and effective framework that unleashes the potential of CLIP for event-based recognition to compensate for the lack of large-scale event-based datasets. Our work addresses two crucial challenges: 1) how to generalize CLIP's visual encoder to event data while fully leveraging events' unique properties, e.g., sparsity and high temporal resolution; 2) how to effectively align the multi-modal embeddings, i.e., image, text, and events. To this end, we first introduce a novel event encoder that subtly models the temporal information from events and meanwhile generates event prompts to promote the modality bridging. We then design a text encoder that generates content prompts and utilizes hybrid text prompts to enhance the E-CLIP's generalization ability across diverse datasets. With the proposed event encoder, text encoder, and original image encoder, a novel Hierarchical Triple Contrastive Alignment (HTCA) module is introduced to jointly optimize the correlation and enable efficient knowledge transfer among the three modalities. We conduct extensive experiments on two recognition benchmarks, and the results demonstrate that our E-CLIP outperforms existing methods by a large margin of +3.94% and +4.62% on the N-Caltech dataset, respectively, in both fine-tuning and few-shot settings. Moreover, our E-CLIP can be flexibly extended to the event retrieval task using both text or image queries, showing plausible performance.
Cal-SFDA: Source-Free Domain-adaptive Semantic Segmentation with Differentiable Expected Calibration Error
Aug 06, 2023
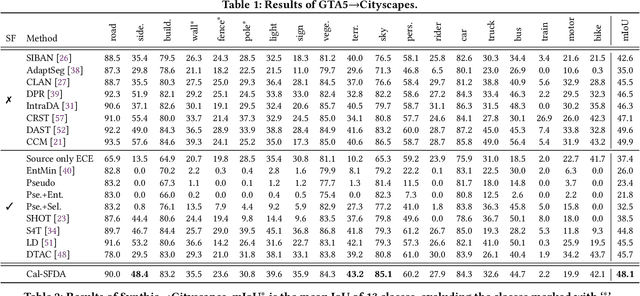
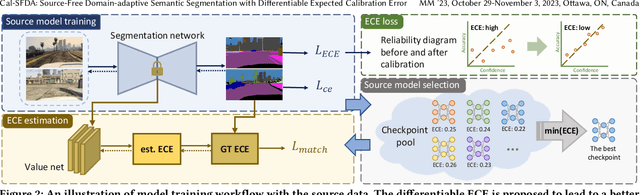
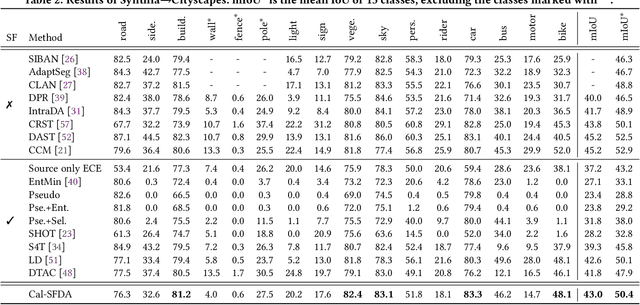
The prevalence of domain adaptive semantic segmentation has prompted concerns regarding source domain data leakage, where private information from the source domain could inadvertently be exposed in the target domain. To circumvent the requirement for source data, source-free domain adaptation has emerged as a viable solution that leverages self-training methods to pseudo-label high-confidence regions and adapt the model to the target data. However, the confidence scores obtained are often highly biased due to over-confidence and class-imbalance issues, which render both model selection and optimization problematic. In this paper, we propose a novel calibration-guided source-free domain adaptive semantic segmentation (Cal-SFDA) framework. The core idea is to estimate the expected calibration error (ECE) from the segmentation predictions, serving as a strong indicator of the model's generalization capability to the unlabeled target domain. The estimated ECE scores, in turn, assist the model training and fair selection in both source training and target adaptation stages. During model pre-training on the source domain, we ensure the differentiability of the ECE objective by leveraging the LogSumExp trick and using ECE scores to select the best source checkpoints for adaptation. To enable ECE estimation on the target domain without requiring labels, we train a value net for ECE estimation and apply statistic warm-up on its BatchNorm layers for stability. The estimated ECE scores assist in determining the reliability of prediction and enable class-balanced pseudo-labeling by positively guiding the adaptation progress and inhibiting potential error accumulation. Extensive experiments on two widely-used synthetic-to-real transfer tasks show that the proposed approach surpasses previous state-of-the-art by up to 5.25% of mIoU with fair model selection criteria.