 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
E-CLIP: Towards Label-efficient Event-based Open-world Understanding by CLIP
Aug 06, 2023
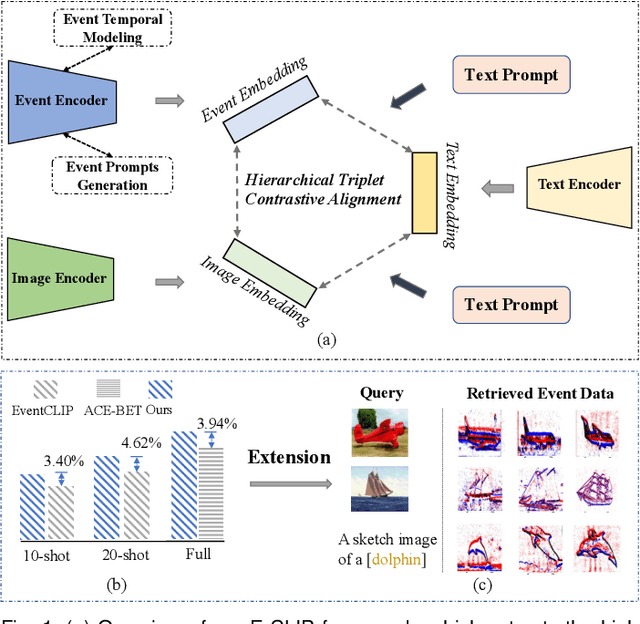
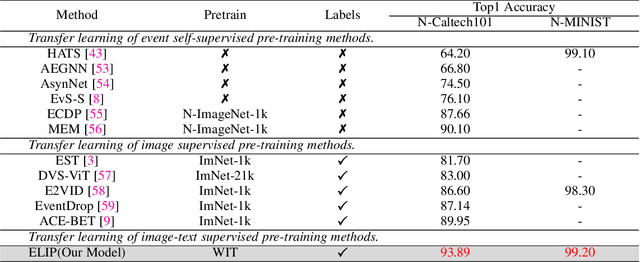
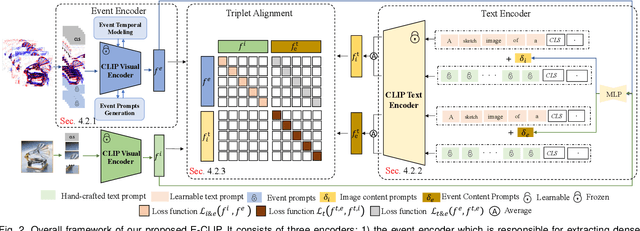
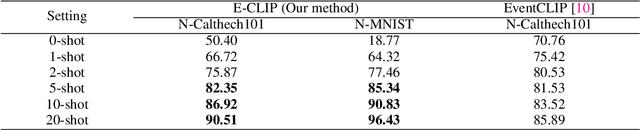
Contrasting Language-image pertaining (CLIP) has recently shown promising open-world and few-shot performance on 2D image-based recognition tasks. However, the transferred capability of CLIP to the novel event camera data still remains under-explored. In particular, due to the modality gap with the image-text data and the lack of large-scale datasets, achieving this goal is non-trivial and thus requires significant research innovation. In this paper, we propose E-CLIP, a novel and effective framework that unleashes the potential of CLIP for event-based recognition to compensate for the lack of large-scale event-based datasets. Our work addresses two crucial challenges: 1) how to generalize CLIP's visual encoder to event data while fully leveraging events' unique properties, e.g., sparsity and high temporal resolution; 2) how to effectively align the multi-modal embeddings, i.e., image, text, and events. To this end, we first introduce a novel event encoder that subtly models the temporal information from events and meanwhile generates event prompts to promote the modality bridging. We then design a text encoder that generates content prompts and utilizes hybrid text prompts to enhance the E-CLIP's generalization ability across diverse datasets. With the proposed event encoder, text encoder, and original image encoder, a novel Hierarchical Triple Contrastive Alignment (HTCA) module is introduced to jointly optimize the correlation and enable efficient knowledge transfer among the three modalities. We conduct extensive experiments on two recognition benchmarks, and the results demonstrate that our E-CLIP outperforms existing methods by a large margin of +3.94% and +4.62% on the N-Caltech dataset, respectively, in both fine-tuning and few-shot settings. Moreover, our E-CLIP can be flexibly extended to the event retrieval task using both text or image queries, showing plausible performance.
Cal-SFDA: Source-Free Domain-adaptive Semantic Segmentation with Differentiable Expected Calibration Error
Aug 06, 2023
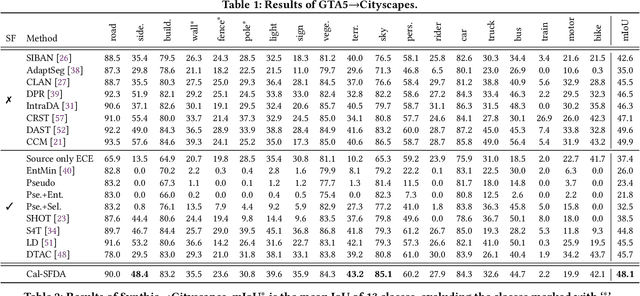
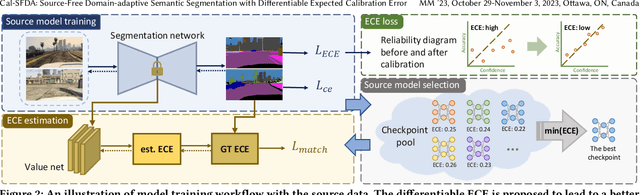
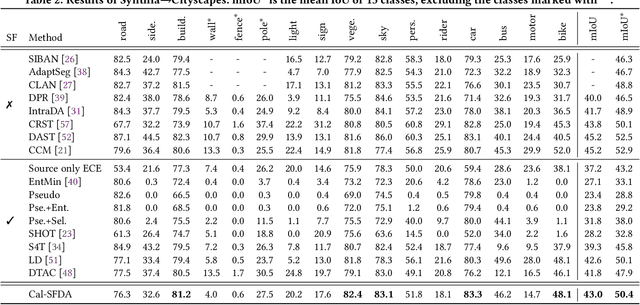
The prevalence of domain adaptive semantic segmentation has prompted concerns regarding source domain data leakage, where private information from the source domain could inadvertently be exposed in the target domain. To circumvent the requirement for source data, source-free domain adaptation has emerged as a viable solution that leverages self-training methods to pseudo-label high-confidence regions and adapt the model to the target data. However, the confidence scores obtained are often highly biased due to over-confidence and class-imbalance issues, which render both model selection and optimization problematic. In this paper, we propose a novel calibration-guided source-free domain adaptive semantic segmentation (Cal-SFDA) framework. The core idea is to estimate the expected calibration error (ECE) from the segmentation predictions, serving as a strong indicator of the model's generalization capability to the unlabeled target domain. The estimated ECE scores, in turn, assist the model training and fair selection in both source training and target adaptation stages. During model pre-training on the source domain, we ensure the differentiability of the ECE objective by leveraging the LogSumExp trick and using ECE scores to select the best source checkpoints for adaptation. To enable ECE estimation on the target domain without requiring labels, we train a value net for ECE estimation and apply statistic warm-up on its BatchNorm layers for stability. The estimated ECE scores assist in determining the reliability of prediction and enable class-balanced pseudo-labeling by positively guiding the adaptation progress and inhibiting potential error accumulation. Extensive experiments on two widely-used synthetic-to-real transfer tasks show that the proposed approach surpasses previous state-of-the-art by up to 5.25% of mIoU with fair model selection criteria.
Intrinsic Appearance Decomposition Using Point Cloud Representation
Jul 20, 2023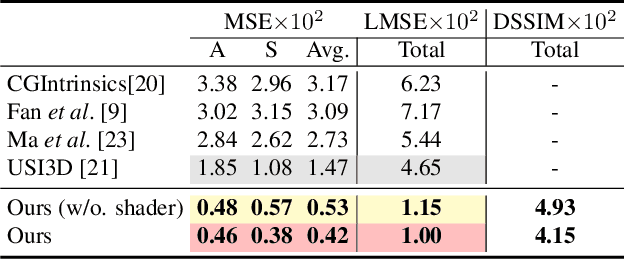
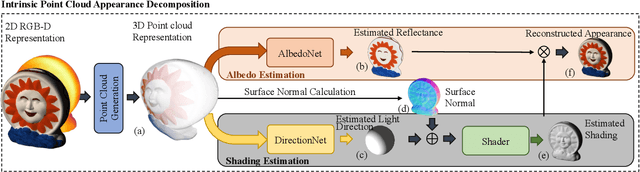
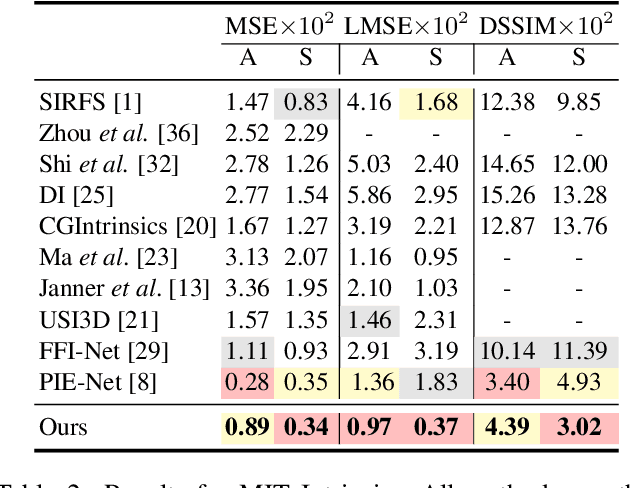

Intrinsic decomposition is to infer the albedo and shading from the image. Since it is a heavily ill-posed problem, previous methods rely on prior assumptions from 2D images, however, the exploration of the data representation itself is limited. The point cloud is known as a rich format of scene representation, which naturally aligns the geometric information and the color information of an image. Our proposed method, Point Intrinsic Net, in short, PoInt-Net, jointly predicts the albedo, light source direction, and shading, using point cloud representation. Experiments reveal the benefits of PoInt-Net, in terms of accuracy, it outperforms 2D representation approaches on multiple metrics across datasets; in terms of efficiency, it trains on small-scale point clouds and performs stably on any-scale point clouds; in terms of robustness, it only trains on single object level dataset, and demonstrates reasonable generalization ability for unseen objects and scenes.
Toward Transparent Sequence Models with Model-Based Tree Markov Model
Jul 28, 2023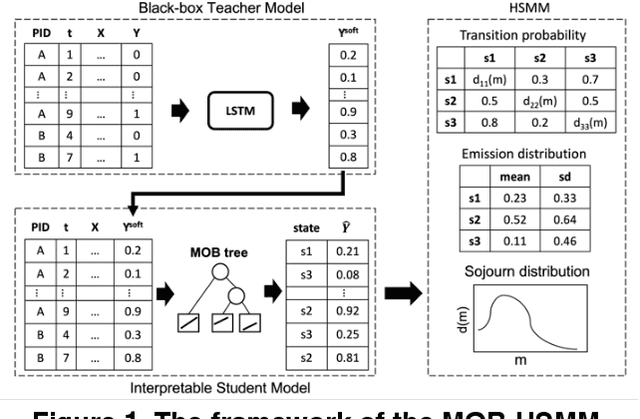

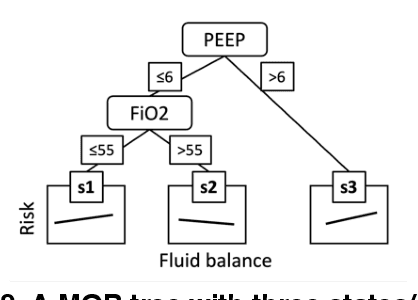

In this study, we address the interpretability issue in complex, black-box Machine Learning models applied to sequence data. We introduce the Model-Based tree Hidden Semi-Markov Model (MOB-HSMM), an inherently interpretable model aimed at detecting high mortality risk events and discovering hidden patterns associated with the mortality risk in Intensive Care Units (ICU). This model leverages knowledge distilled from Deep Neural Networks (DNN) to enhance predictive performance while offering clear explanations. Our experimental results indicate the improved performance of Model-Based trees (MOB trees) via employing LSTM for learning sequential patterns, which are then transferred to MOB trees. Integrating MOB trees with the Hidden Semi-Markov Model (HSMM) in the MOB-HSMM enables uncovering potential and explainable sequences using available information.
Where Did the President Visit Last Week? Detecting Celebrity Trips from News Articles
Jul 17, 2023

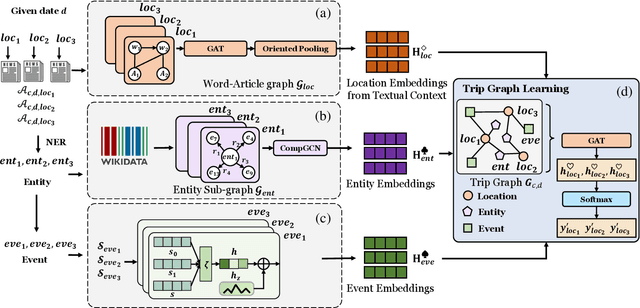

Celebrities' whereabouts are of pervasive importance. For instance, where politicians go, how often they visit, and who they meet, come with profound geopolitical and economic implications. Although news articles contain travel information of celebrities, it is not possible to perform large-scale and network-wise analysis due to the lack of automatic itinerary detection tools. To design such tools, we have to overcome difficulties from the heterogeneity among news articles: 1)One single article can be noisy, with irrelevant people and locations, especially when the articles are long. 2)Though it may be helpful if we consider multiple articles together to determine a particular trip, the key semantics are still scattered across different articles intertwined with various noises, making it hard to aggregate them effectively. 3)Over 20% of the articles refer to the celebrities' trips indirectly, instead of using the exact celebrity names or location names, leading to large portions of trips escaping regular detecting algorithms. We model text content across articles related to each candidate location as a graph to better associate essential information and cancel out the noises. Besides, we design a special pooling layer based on attention mechanism and node similarity, reducing irrelevant information from longer articles. To make up the missing information resulted from indirect mentions, we construct knowledge sub-graphs for named entities (person, organization, facility, etc.). Specifically, we dynamically update embeddings of event entities like the G7 summit from news descriptions since the properties (date and location) of the event change each time, which is not captured by the pre-trained event representations. The proposed CeleTrip jointly trains these modules, which outperforms all baseline models and achieves 82.53% in the F1 metric.
A Survey of What to Share in Federated Learning: Perspectives on Model Utility, Privacy Leakage, and Communication Efficiency
Jul 20, 2023Federated learning (FL) has emerged as a highly effective paradigm for privacy-preserving collaborative training among different parties. Unlike traditional centralized learning, which requires collecting data from each party, FL allows clients to share privacy-preserving information without exposing private datasets. This approach not only guarantees enhanced privacy protection but also facilitates more efficient and secure collaboration among multiple participants. Therefore, FL has gained considerable attention from researchers, promoting numerous surveys to summarize the related works. However, the majority of these surveys concentrate on methods sharing model parameters during the training process, while overlooking the potential of sharing other forms of local information. In this paper, we present a systematic survey from a new perspective, i.e., what to share in FL, with an emphasis on the model utility, privacy leakage, and communication efficiency. This survey differs from previous ones due to four distinct contributions. First, we present a new taxonomy of FL methods in terms of the sharing methods, which includes three categories of shared information: model sharing, synthetic data sharing, and knowledge sharing. Second, we analyze the vulnerability of different sharing methods to privacy attacks and review the defense mechanisms that provide certain privacy guarantees. Third, we conduct extensive experiments to compare the performance and communication overhead of various sharing methods in FL. Besides, we assess the potential privacy leakage through model inversion and membership inference attacks, while comparing the effectiveness of various defense approaches. Finally, we discuss potential deficiencies in current methods and outline future directions for improvement.
Deep Spiking-UNet for Image Processing
Jul 20, 2023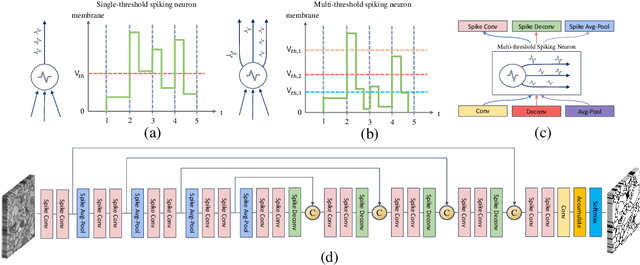
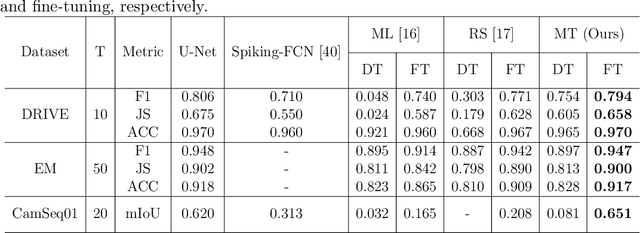
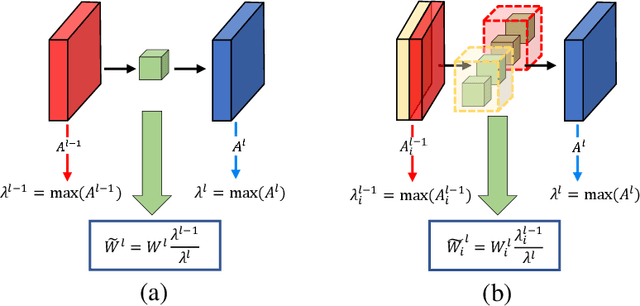
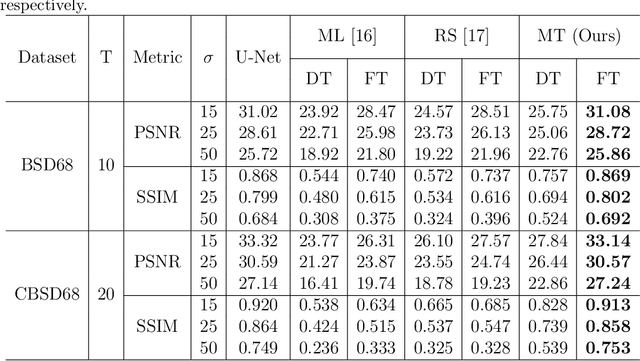
U-Net, known for its simple yet efficient architecture, is widely utilized for image processing tasks and is particularly suitable for deployment on neuromorphic chips. This paper introduces the novel concept of Spiking-UNet for image processing, which combines the power of Spiking Neural Networks (SNNs) with the U-Net architecture. To achieve an efficient Spiking-UNet, we face two primary challenges: ensuring high-fidelity information propagation through the network via spikes and formulating an effective training strategy. To address the issue of information loss, we introduce multi-threshold spiking neurons, which improve the efficiency of information transmission within the Spiking-UNet. For the training strategy, we adopt a conversion and fine-tuning pipeline that leverage pre-trained U-Net models. During the conversion process, significant variability in data distribution across different parts is observed when utilizing skip connections. Therefore, we propose a connection-wise normalization method to prevent inaccurate firing rates. Furthermore, we adopt a flow-based training method to fine-tune the converted models, reducing time steps while preserving performance. Experimental results show that, on image segmentation and denoising, our Spiking-UNet achieves comparable performance to its non-spiking counterpart, surpassing existing SNN methods. Compared with the converted Spiking-UNet without fine-tuning, our Spiking-UNet reduces inference time by approximately 90\%. This research broadens the application scope of SNNs in image processing and is expected to inspire further exploration in the field of neuromorphic engineering. The code for our Spiking-UNet implementation is available at https://github.com/SNNresearch/Spiking-UNet.
VisAlign: Dataset for Measuring the Degree of Alignment between AI and Humans in Visual Perception
Aug 03, 2023
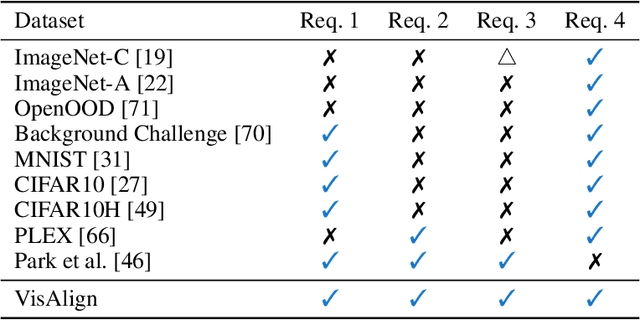
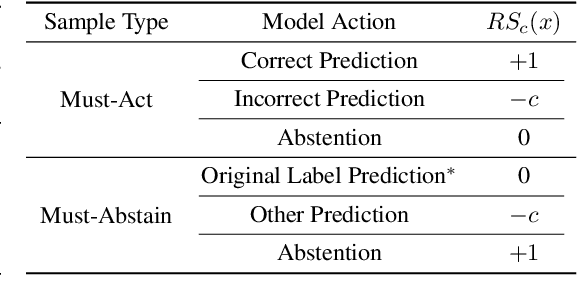

AI alignment refers to models acting towards human-intended goals, preferences, or ethical principles. Given that most large-scale deep learning models act as black boxes and cannot be manually controlled, analyzing the similarity between models and humans can be a proxy measure for ensuring AI safety. In this paper, we focus on the models' visual perception alignment with humans, further referred to as AI-human visual alignment. Specifically, we propose a new dataset for measuring AI-human visual alignment in terms of image classification, a fundamental task in machine perception. In order to evaluate AI-human visual alignment, a dataset should encompass samples with various scenarios that may arise in the real world and have gold human perception labels. Our dataset consists of three groups of samples, namely Must-Act (i.e., Must-Classify), Must-Abstain, and Uncertain, based on the quantity and clarity of visual information in an image and further divided into eight categories. All samples have a gold human perception label; even Uncertain (severely blurry) sample labels were obtained via crowd-sourcing. The validity of our dataset is verified by sampling theory, statistical theories related to survey design, and experts in the related fields. Using our dataset, we analyze the visual alignment and reliability of five popular visual perception models and seven abstention methods. Our code and data is available at \url{https://github.com/jiyounglee-0523/VisAlign}.
Infor-Coef: Information Bottleneck-based Dynamic Token Downsampling for Compact and Efficient language model
May 21, 2023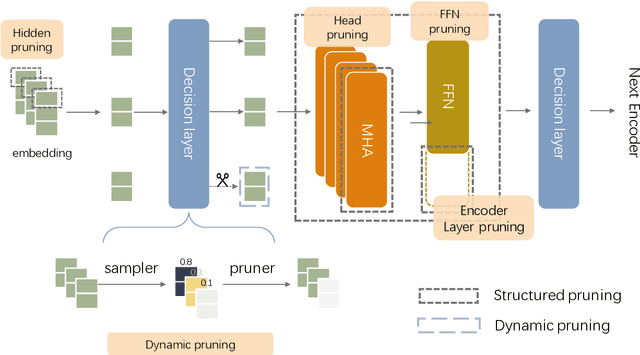
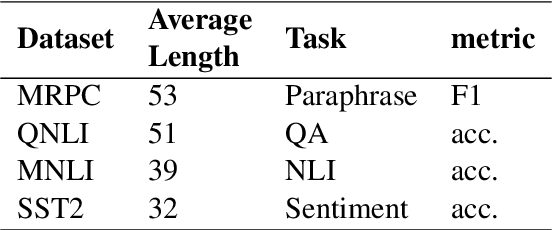
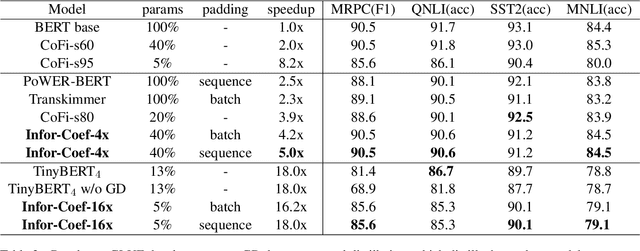
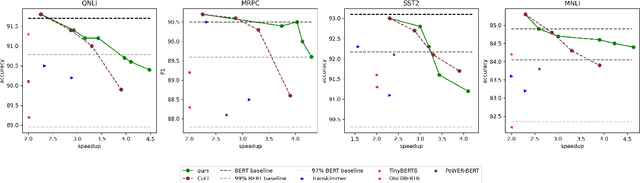
The prevalence of Transformer-based pre-trained language models (PLMs) has led to their wide adoption for various natural language processing tasks. However, their excessive overhead leads to large latency and computational costs. The statically compression methods allocate fixed computation to different samples, resulting in redundant computation. The dynamic token pruning method selectively shortens the sequences but are unable to change the model size and hardly achieve the speedups as static pruning. In this paper, we propose a model accelaration approaches for large language models that incorporates dynamic token downsampling and static pruning, optimized by the information bottleneck loss. Our model, Infor-Coef, achieves an 18x FLOPs speedup with an accuracy degradation of less than 8\% compared to BERT. This work provides a promising approach to compress and accelerate transformer-based models for NLP tasks.
AIGC Empowering Telecom Sector White Paper_chinese
Jul 24, 2023In the global craze of GPT, people have deeply realized that AI, as a transformative technology and key force in economic and social development, will bring great leaps and breakthroughs to the global industry and profoundly influence the future world competition pattern. As the builder and operator of information and communication infrastructure, the telecom sector provides infrastructure support for the development of AI, and even takes the lead in the implementation of AI applications. How to enable the application of AIGC (GPT) and implement AIGC in the telecom sector are questions that telecom practitioners must ponder and answer. Through the study of GPT, a typical representative of AIGC, the authors have analyzed how GPT empowers the telecom sector in the form of scenarios, discussed the gap between the current GPT general model and telecom services, proposed for the first time a Telco Augmented Cognition capability system, provided answers to how to construct a telecom service GPT in the telecom sector, and carried out various practices. Our counterparts in the industry are expected to focus on collaborative innovation around telecom and AI, build an open and shared innovation ecosystem, promote the deep integration of AI and telecom sector, and accelerate the construction of next-generation information infrastructure, in an effort to facilitate the digital transformation of the economy and society.