 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
OV-Uni3DETR: Towards Unified Open-Vocabulary 3D Object Detection via Cycle-Modality Propagation
Mar 28, 2024
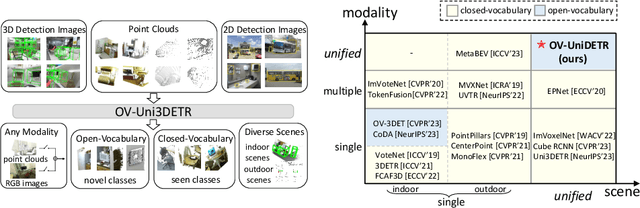
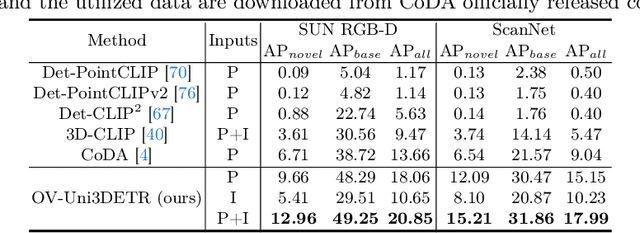
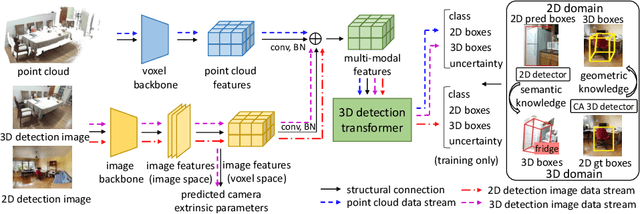
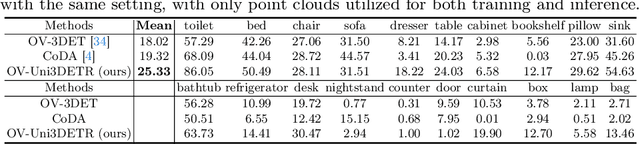
In the current state of 3D object detection research, the severe scarcity of annotated 3D data, substantial disparities across different data modalities, and the absence of a unified architecture, have impeded the progress towards the goal of universality. In this paper, we propose \textbf{OV-Uni3DETR}, a unified open-vocabulary 3D detector via cycle-modality propagation. Compared with existing 3D detectors, OV-Uni3DETR offers distinct advantages: 1) Open-vocabulary 3D detection: During training, it leverages various accessible data, especially extensive 2D detection images, to boost training diversity. During inference, it can detect both seen and unseen classes. 2) Modality unifying: It seamlessly accommodates input data from any given modality, effectively addressing scenarios involving disparate modalities or missing sensor information, thereby supporting test-time modality switching. 3) Scene unifying: It provides a unified multi-modal model architecture for diverse scenes collected by distinct sensors. Specifically, we propose the cycle-modality propagation, aimed at propagating knowledge bridging 2D and 3D modalities, to support the aforementioned functionalities. 2D semantic knowledge from large-vocabulary learning guides novel class discovery in the 3D domain, and 3D geometric knowledge provides localization supervision for 2D detection images. OV-Uni3DETR achieves the state-of-the-art performance on various scenarios, surpassing existing methods by more than 6\% on average. Its performance using only RGB images is on par with or even surpasses that of previous point cloud based methods. Code and pre-trained models will be released later.
Information Extraction: An application to the domain of hyper-local financial data on developing countries
Mar 14, 2024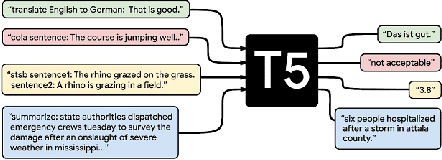

Despite the need for financial data on company activities in developing countries for development research and economic analysis, such data does not exist. In this project, we develop and evaluate two Natural Language Processing (NLP) based techniques to address this issue. First, we curate a custom dataset specific to the domain of financial text data on developing countries and explore multiple approaches for information extraction. We then explore a text-to-text approach with the transformer-based T5 model with the goal of undertaking simultaneous NER and relation extraction. We find that this model is able to learn the custom text structure output data corresponding to the entities and their relations, resulting in an accuracy of 92.44\%, a precision of 68.25\% and a recall of 54.20\% from our best T5 model on the combined task. Secondly, we explore an approach with sequential NER and relation extration. For the NER, we run pre-trained and fine-tuned models using SpaCy, and we develop a custom relation extraction model using SpaCy's Dependency Parser output and some heuristics to determine entity relationships \cite{spacy}. We obtain an accuracy of 84.72\%, a precision of 6.06\% and a recall of 5.57\% on this sequential task.
TDIP: Tunable Deep Image Processing, a Real Time Melt Pool Monitoring Solution
Mar 26, 2024In the era of Industry 4.0, Additive Manufacturing (AM), particularly metal AM, has emerged as a significant contributor due to its innovative and cost-effective approach to fabricate highly intricate geometries. Despite its potential, this industry still lacks real-time capable process monitoring algorithms. Recent advancements in this field suggest that Melt Pool (MP) signatures during the fabrication process contain crucial information about process dynamics and quality. To obtain this information, various sensory approaches, such as high-speed cameras-based vision modules are employed for online fabrication monitoring. However, many conventional in-depth analyses still cannot process all the recorded data simultaneously. Although conventional Image Processing (ImP) solutions provide a targeted tunable approach, they pose a trade-off between convergence certainty and convergence speed. As a result, conventional methods are not suitable for a dynamically changing application like MP monitoring. Therefore, this article proposes the implementation of a Tunable Deep Image Processing (TDIP) method to address the data-rich monitoring needs in real-time. The proposed model is first trained to replicate an ImP algorithm with tunable features and methodology. The TDIP model is then further improved to account for MP geometries and fabrication quality based on the vision input and process parameters. The TDIP model achieved over 94% estimation accuracy with more than 96% R2 score for quality, geometry, and MP signature estimation and isolation. The TDIP model can process 500 images per second, while conventional methods taking a few minutes per image. This significant processing time reduction enables the integration of vision-based monitoring in real-time for processes and quality estimation.
Transcribing Bengali Text with Regional Dialects to IPA using District Guided Tokens
Mar 26, 2024Accurate transcription of Bengali text to the International Phonetic Alphabet (IPA) is a challenging task due to the complex phonology of the language and context-dependent sound changes. This challenge is even more for regional Bengali dialects due to unavailability of standardized spelling conventions for these dialects, presence of local and foreign words popular in those regions and phonological diversity across different regions. This paper presents an approach to this sequence-to-sequence problem by introducing the District Guided Tokens (DGT) technique on a new dataset spanning six districts of Bangladesh. The key idea is to provide the model with explicit information about the regional dialect or "district" of the input text before generating the IPA transcription. This is achieved by prepending a district token to the input sequence, effectively guiding the model to understand the unique phonetic patterns associated with each district. The DGT technique is applied to fine-tune several transformer-based models, on this new dataset. Experimental results demonstrate the effectiveness of DGT, with the ByT5 model achieving superior performance over word-based models like mT5, BanglaT5, and umT5. This is attributed to ByT5's ability to handle a high percentage of out-of-vocabulary words in the test set. The proposed approach highlights the importance of incorporating regional dialect information into ubiquitous natural language processing systems for languages with diverse phonological variations. The following work was a result of the "Bhashamul" challenge, which is dedicated to solving the problem of Bengali text with regional dialects to IPA transcription https://www.kaggle.com/competitions/regipa/. The training and inference notebooks are available through the competition link.
GTC: GNN-Transformer Co-contrastive Learning for Self-supervised Heterogeneous Graph Representation
Mar 22, 2024Graph Neural Networks (GNNs) have emerged as the most powerful weapon for various graph tasks due to the message-passing mechanism's great local information aggregation ability. However, over-smoothing has always hindered GNNs from going deeper and capturing multi-hop neighbors. Unlike GNNs, Transformers can model global information and multi-hop interactions via multi-head self-attention and a proper Transformer structure can show more immunity to the over-smoothing problem. So, can we propose a novel framework to combine GNN and Transformer, integrating both GNN's local information aggregation and Transformer's global information modeling ability to eliminate the over-smoothing problem? To realize this, this paper proposes a collaborative learning scheme for GNN-Transformer and constructs GTC architecture. GTC leverages the GNN and Transformer branch to encode node information from different views respectively, and establishes contrastive learning tasks based on the encoded cross-view information to realize self-supervised heterogeneous graph representation. For the Transformer branch, we propose Metapath-aware Hop2Token and CG-Hetphormer, which can cooperate with GNN to attentively encode neighborhood information from different levels. As far as we know, this is the first attempt in the field of graph representation learning to utilize both GNN and Transformer to collaboratively capture different view information and conduct cross-view contrastive learning. The experiments on real datasets show that GTC exhibits superior performance compared with state-of-the-art methods. Codes can be available at https://github.com/PHD-lanyu/GTC.
Synthetic Privileged Information Enhances Medical Image Representation Learning
Mar 08, 2024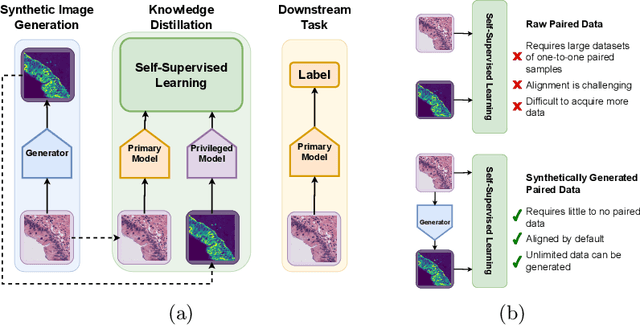
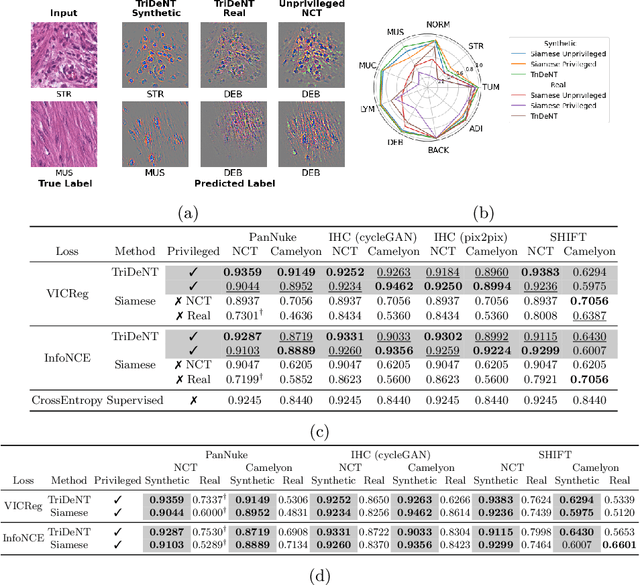
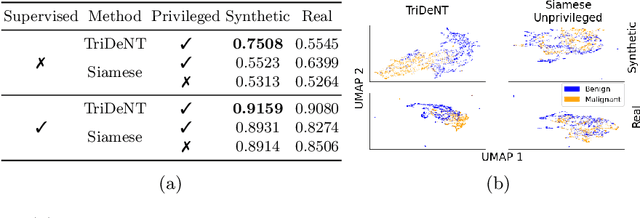
Multimodal self-supervised representation learning has consistently proven to be a highly effective method in medical image analysis, offering strong task performance and producing biologically informed insights. However, these methods heavily rely on large, paired datasets, which is prohibitive for their use in scenarios where paired data does not exist, or there is only a small amount available. In contrast, image generation methods can work well on very small datasets, and can find mappings between unpaired datasets, meaning an effectively unlimited amount of paired synthetic data can be generated. In this work, we demonstrate that representation learning can be significantly improved by synthetically generating paired information, both compared to training on either single-modality (up to 4.4x error reduction) or authentic multi-modal paired datasets (up to 5.6x error reduction).
Gaze-guided Hand-Object Interaction Synthesis: Benchmark and Method
Mar 28, 2024Gaze plays a crucial role in revealing human attention and intention, shedding light on the cognitive processes behind human actions. The integration of gaze guidance with the dynamics of hand-object interactions boosts the accuracy of human motion prediction. However, the lack of datasets that capture the intricate relationship and consistency among gaze, hand, and object movements remains a substantial hurdle. In this paper, we introduce the first Gaze-guided Hand-Object Interaction dataset, GazeHOI, and present a novel task for synthesizing gaze-guided hand-object interactions. Our dataset, GazeHOI, features simultaneous 3D modeling of gaze, hand, and object interactions, comprising 479 sequences with an average duration of 19.1 seconds, 812 sub-sequences, and 33 objects of various sizes. We propose a hierarchical framework centered on a gaze-guided hand-object interaction diffusion model, named GHO-Diffusion. In the pre-diffusion phase, we separate gaze conditions into spatial-temporal features and goal pose conditions at different levels of information granularity. During the diffusion phase, two gaze-conditioned diffusion models are stacked to simplify the complex synthesis of hand-object motions. Here, the object motion diffusion model generates sequences of object motions based on gaze conditions, while the hand motion diffusion model produces hand motions based on the generated object motion. To improve fine-grained goal pose alignment, we introduce a Spherical Gaussian constraint to guide the denoising step. In the subsequent post-diffusion phase, we optimize the generated hand motions using contact consistency. Our extensive experiments highlight the uniqueness of our dataset and the effectiveness of our approach.
A Review of Multi-Modal Large Language and Vision Models
Mar 28, 2024Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
Improving Sequence-to-Sequence Models for Abstractive Text Summarization Using Meta Heuristic Approaches
Mar 24, 2024As human society transitions into the information age, reduction in our attention span is a contingency, and people who spend time reading lengthy news articles are decreasing rapidly and the need for succinct information is higher than ever before. Therefore, it is essential to provide a quick overview of important news by concisely summarizing the top news article and the most intuitive headline. When humans try to make summaries, they extract the essential information from the source and add useful phrases and grammatical annotations from the original extract. Humans have a unique ability to create abstractions. However, automatic summarization is a complicated problem to solve. The use of sequence-to-sequence (seq2seq) models for neural abstractive text summarization has been ascending as far as prevalence. Numerous innovative strategies have been proposed to develop the current seq2seq models further, permitting them to handle different issues like saliency, familiarity, and human lucidness and create excellent synopses. In this article, we aimed toward enhancing the present architectures and models for abstractive text summarization. The modifications have been aimed at fine-tuning hyper-parameters, attempting specific encoder-decoder combinations. We examined many experiments on an extensively used CNN/DailyMail dataset to check the effectiveness of various models.
Task-Customized Mixture of Adapters for General Image Fusion
Mar 24, 2024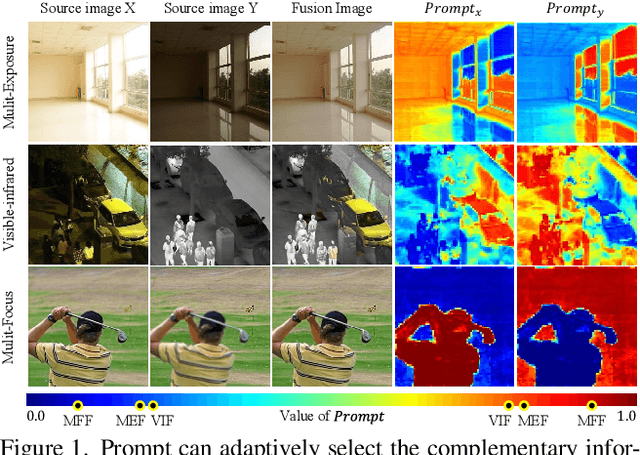
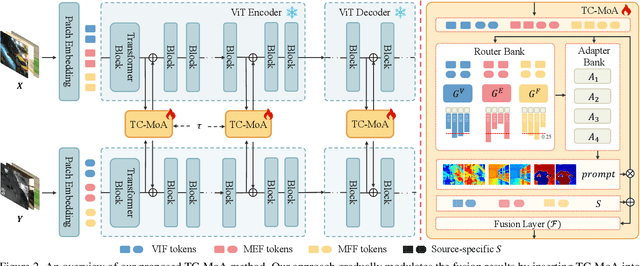
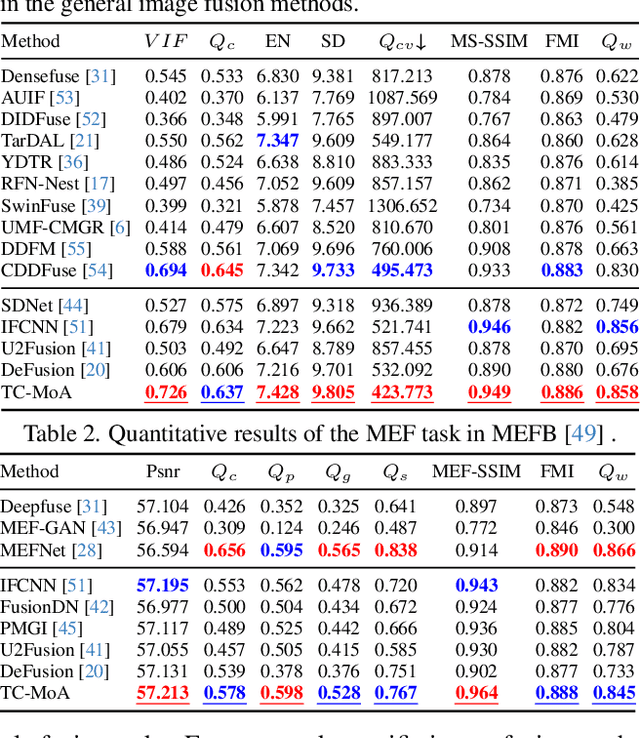

General image fusion aims at integrating important information from multi-source images. However, due to the significant cross-task gap, the respective fusion mechanism varies considerably in practice, resulting in limited performance across subtasks. To handle this problem, we propose a novel task-customized mixture of adapters (TC-MoA) for general image fusion, adaptively prompting various fusion tasks in a unified model. We borrow the insight from the mixture of experts (MoE), taking the experts as efficient tuning adapters to prompt a pre-trained foundation model. These adapters are shared across different tasks and constrained by mutual information regularization, ensuring compatibility with different tasks while complementarity for multi-source images. The task-specific routing networks customize these adapters to extract task-specific information from different sources with dynamic dominant intensity, performing adaptive visual feature prompt fusion. Notably, our TC-MoA controls the dominant intensity bias for different fusion tasks, successfully unifying multiple fusion tasks in a single model. Extensive experiments show that TC-MoA outperforms the competing approaches in learning commonalities while retaining compatibility for general image fusion (multi-modal, multi-exposure, and multi-focus), and also demonstrating striking controllability on more generalization experiments. The code is available at https://github.com/YangSun22/TC-MoA .