 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Attention for Robot Touch: Tactile Saliency Prediction for Robust Sim-to-Real Tactile Control
Aug 02, 2023

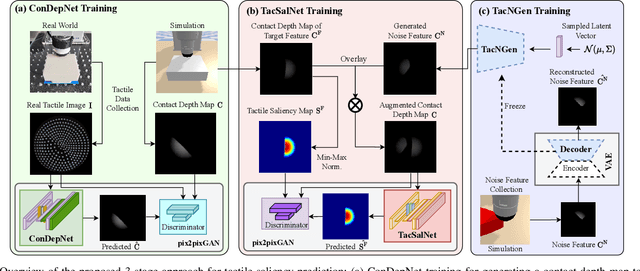
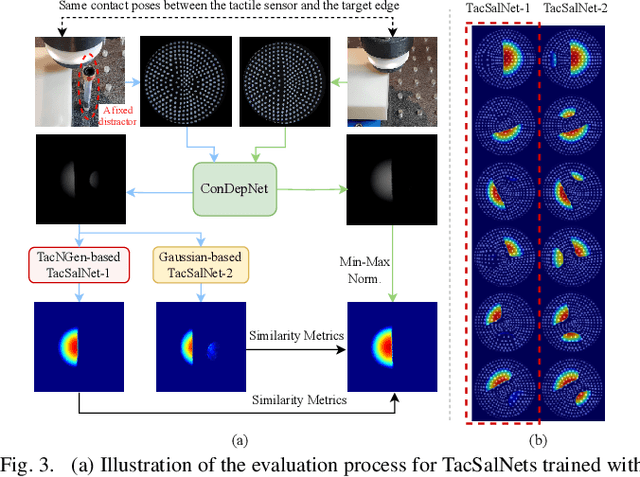
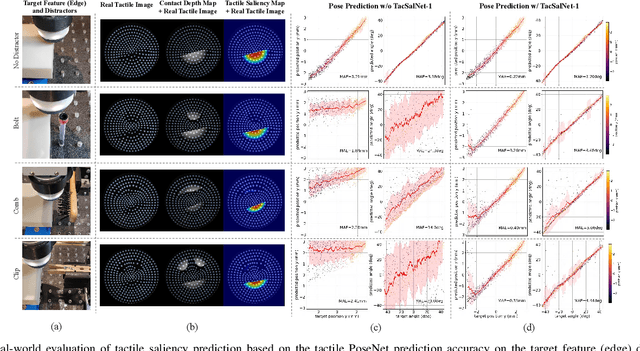
High-resolution tactile sensing can provide accurate information about local contact in contact-rich robotic tasks. However, the deployment of such tasks in unstructured environments remains under-investigated. To improve the robustness of tactile robot control in unstructured environments, we propose and study a new concept: \textit{tactile saliency} for robot touch, inspired by the human touch attention mechanism from neuroscience and the visual saliency prediction problem from computer vision. In analogy to visual saliency, this concept involves identifying key information in tactile images captured by a tactile sensor. While visual saliency datasets are commonly annotated by humans, manually labelling tactile images is challenging due to their counterintuitive patterns. To address this challenge, we propose a novel approach comprised of three interrelated networks: 1) a Contact Depth Network (ConDepNet), which generates a contact depth map to localize deformation in a real tactile image that contains target and noise features; 2) a Tactile Saliency Network (TacSalNet), which predicts a tactile saliency map to describe the target areas for an input contact depth map; 3) and a Tactile Noise Generator (TacNGen), which generates noise features to train the TacSalNet. Experimental results in contact pose estimation and edge-following in the presence of distractors showcase the accurate prediction of target features from real tactile images. Overall, our tactile saliency prediction approach gives robust sim-to-real tactile control in environments with unknown distractors. Project page: https://sites.google.com/view/tactile-saliency/.
ImageBrush: Learning Visual In-Context Instructions for Exemplar-Based Image Manipulation
Aug 02, 2023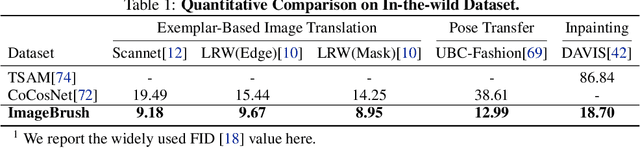
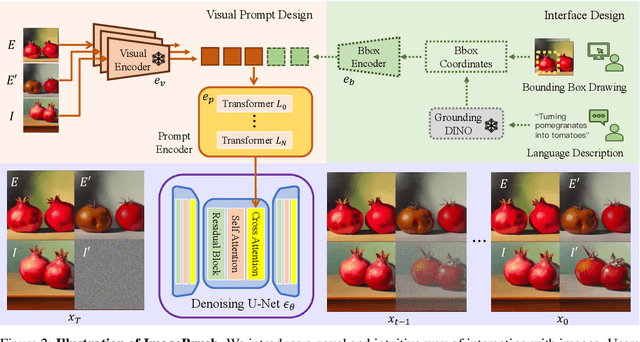

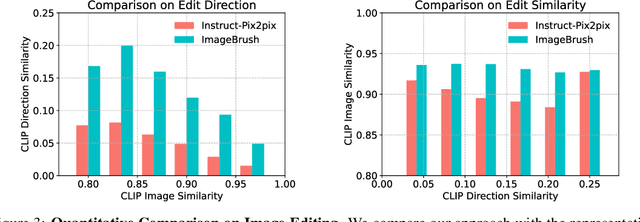
While language-guided image manipulation has made remarkable progress, the challenge of how to instruct the manipulation process faithfully reflecting human intentions persists. An accurate and comprehensive description of a manipulation task using natural language is laborious and sometimes even impossible, primarily due to the inherent uncertainty and ambiguity present in linguistic expressions. Is it feasible to accomplish image manipulation without resorting to external cross-modal language information? If this possibility exists, the inherent modality gap would be effortlessly eliminated. In this paper, we propose a novel manipulation methodology, dubbed ImageBrush, that learns visual instructions for more accurate image editing. Our key idea is to employ a pair of transformation images as visual instructions, which not only precisely captures human intention but also facilitates accessibility in real-world scenarios. Capturing visual instructions is particularly challenging because it involves extracting the underlying intentions solely from visual demonstrations and then applying this operation to a new image. To address this challenge, we formulate visual instruction learning as a diffusion-based inpainting problem, where the contextual information is fully exploited through an iterative process of generation. A visual prompting encoder is carefully devised to enhance the model's capacity in uncovering human intent behind the visual instructions. Extensive experiments show that our method generates engaging manipulation results conforming to the transformations entailed in demonstrations. Moreover, our model exhibits robust generalization capabilities on various downstream tasks such as pose transfer, image translation and video inpainting.
Probabilistic Detection of GNSS Spoofing using Opportunistic Information
May 09, 2023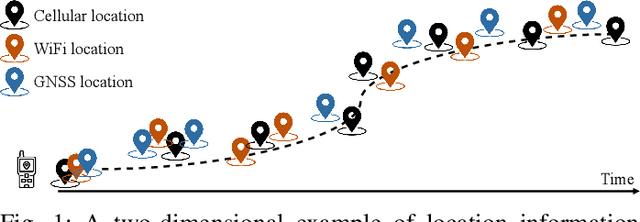
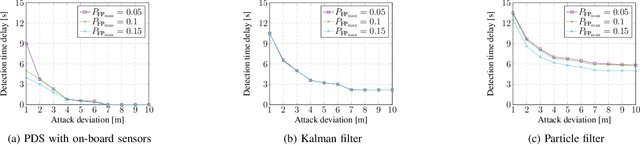
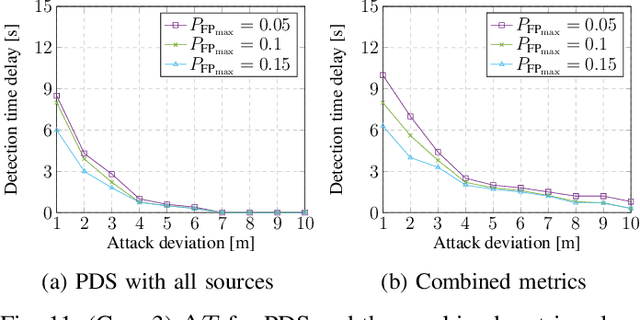
Global Navigation Satellite Systems (GNSS) are integrated into many devices. However, civilian GNSS signals are usually not cryptographically protected. This makes attacks that forge signals relatively easy. Considering modern devices often have network connections and onboard sensors, the proposed here Probabilistic Detection of GNSS Spoofing (PDS) scheme is based on such opportunistic information. PDS has at its core two parts. First, a regression problem with motion model constraints, which equalizes the noise of all locations considering the motion model of the device. Second, a Gaussian process, that analyzes statistical properties of location data to construct uncertainty. Then, a likelihood function, that fuses the two parts, as a basis for a Neyman-Pearson lemma (NPL)-based detection strategy. Our experimental evaluation shows a performance gain over the state-of-the-art, in terms of attack detection effectiveness.
ClusterSeq: Enhancing Sequential Recommender Systems with Clustering based Meta-Learning
Jul 25, 2023In practical scenarios, the effectiveness of sequential recommendation systems is hindered by the user cold-start problem, which arises due to limited interactions for accurately determining user preferences. Previous studies have attempted to address this issue by combining meta-learning with user and item-side information. However, these approaches face inherent challenges in modeling user preference dynamics, particularly for "minor users" who exhibit distinct preferences compared to more common or "major users." To overcome these limitations, we present a novel approach called ClusterSeq, a Meta-Learning Clustering-Based Sequential Recommender System. ClusterSeq leverages dynamic information in the user sequence to enhance item prediction accuracy, even in the absence of side information. This model preserves the preferences of minor users without being overshadowed by major users, and it capitalizes on the collective knowledge of users within the same cluster. Extensive experiments conducted on various benchmark datasets validate the effectiveness of ClusterSeq. Empirical results consistently demonstrate that ClusterSeq outperforms several state-of-the-art meta-learning recommenders. Notably, compared to existing meta-learning methods, our proposed approach achieves a substantial improvement of 16-39% in Mean Reciprocal Rank (MRR).
Prior Based Online Lane Graph Extraction from Single Onboard Camera Image
Jul 25, 2023
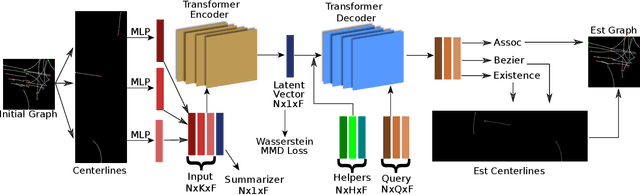
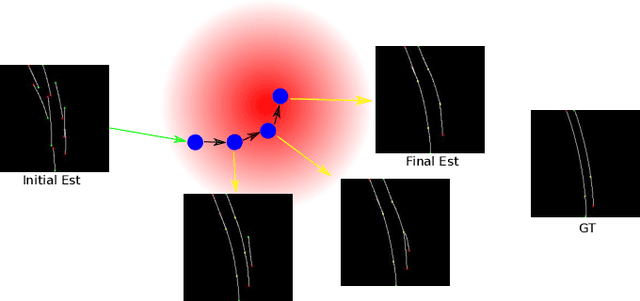
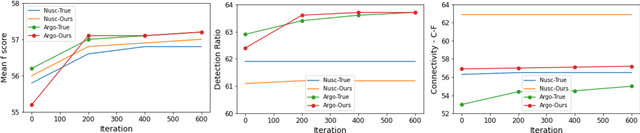
The local road network information is essential for autonomous navigation. This information is commonly obtained from offline HD-Maps in terms of lane graphs. However, the local road network at a given moment can be drastically different than the one given in the offline maps; due to construction works, accidents etc. Moreover, the autonomous vehicle might be at a location not covered in the offline HD-Map. Thus, online estimation of the lane graph is crucial for widespread and reliable autonomous navigation. In this work, we tackle online Bird's-Eye-View lane graph extraction from a single onboard camera image. We propose to use prior information to increase quality of the estimations. The prior is extracted from the dataset through a transformer based Wasserstein Autoencoder. The autoencoder is then used to enhance the initial lane graph estimates. This is done through optimization of the latent space vector. The optimization encourages the lane graph estimation to be logical by discouraging it to diverge from the prior distribution. We test the method on two benchmark datasets, NuScenes and Argoverse. The results show that the proposed method significantly improves the performance compared to state-of-the-art methods.
Detection and Segmentation of Cosmic Objects Based on Adaptive Thresholding and Back Propagation Neural Network
Aug 02, 2023
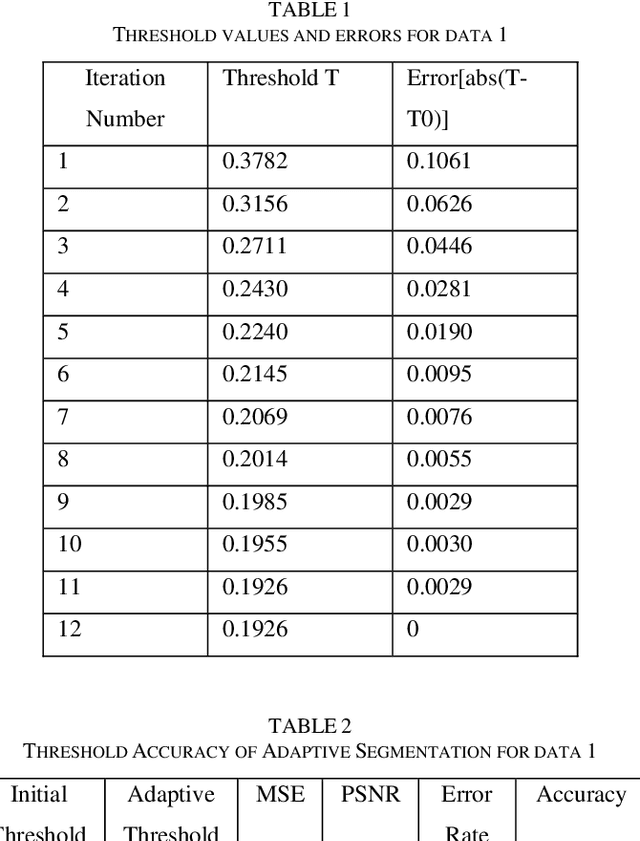
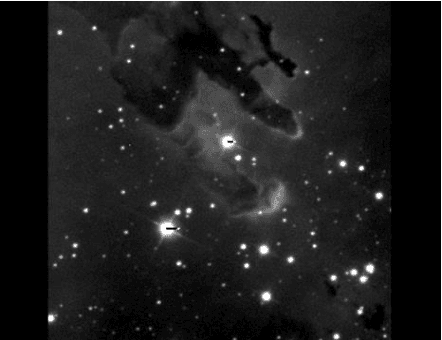

Astronomical images provide information about the great variety of cosmic objects in the Universe. Due to the large volumes of data, the presence of innumerable bright point sources as well as noise within the frame and the spatial gap between objects and satellite cameras, it is a challenging task to classify and detect the celestial objects. We propose an Adaptive Thresholding Method (ATM) based segmentation and Back Propagation Neural Network (BPNN) based cosmic object detection including a well-structured series of pre-processing steps designed to enhance segmentation and detection.
Manifold DivideMix: A Semi-Supervised Contrastive Learning Framework for Severe Label Noise
Aug 13, 2023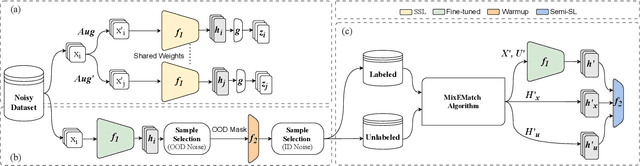

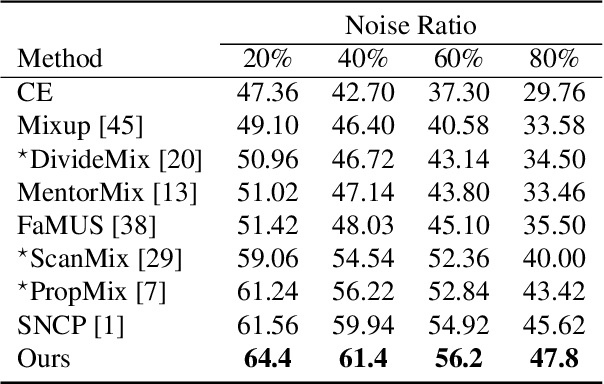
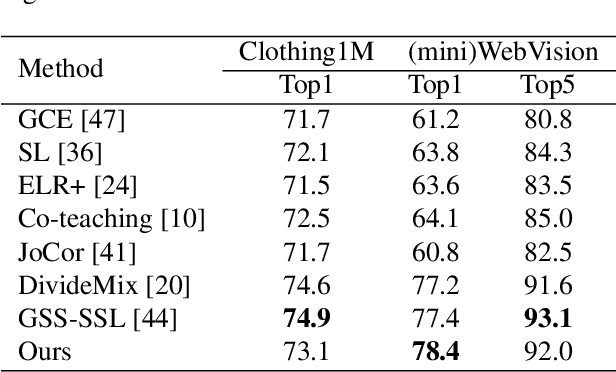
Deep neural networks have proven to be highly effective when large amounts of data with clean labels are available. However, their performance degrades when training data contains noisy labels, leading to poor generalization on the test set. Real-world datasets contain noisy label samples that either have similar visual semantics to other classes (in-distribution) or have no semantic relevance to any class (out-of-distribution) in the dataset. Most state-of-the-art methods leverage ID labeled noisy samples as unlabeled data for semi-supervised learning, but OOD labeled noisy samples cannot be used in this way because they do not belong to any class within the dataset. Hence, in this paper, we propose incorporating the information from all the training data by leveraging the benefits of self-supervised training. Our method aims to extract a meaningful and generalizable embedding space for each sample regardless of its label. Then, we employ a simple yet effective K-nearest neighbor method to remove portions of out-of-distribution samples. By discarding these samples, we propose an iterative "Manifold DivideMix" algorithm to find clean and noisy samples, and train our model in a semi-supervised way. In addition, we propose "MixEMatch", a new algorithm for the semi-supervised step that involves mixup augmentation at the input and final hidden representations of the model. This will extract better representations by interpolating both in the input and manifold spaces. Extensive experiments on multiple synthetic-noise image benchmarks and real-world web-crawled datasets demonstrate the effectiveness of our proposed framework. Code is available at https://github.com/Fahim-F/ManifoldDivideMix.
Neural Networks for Programming Quantum Annealers
Aug 13, 2023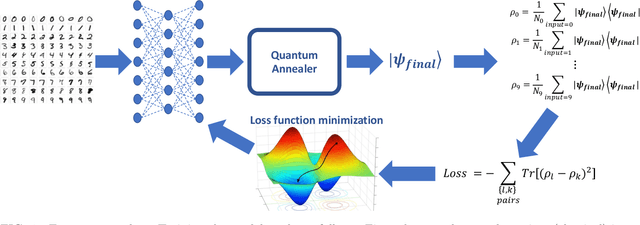
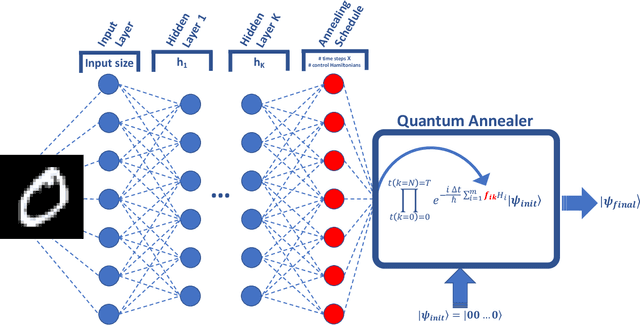
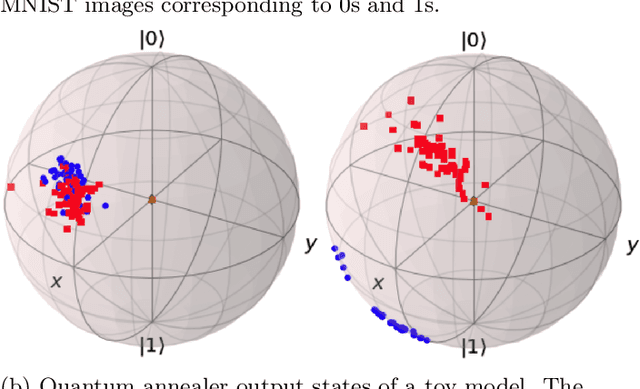
Quantum machine learning has the potential to enable advances in artificial intelligence, such as solving problems intractable on classical computers. Some fundamental ideas behind quantum machine learning are similar to kernel methods in classical machine learning. Both process information by mapping it into high-dimensional vector spaces without explicitly calculating their numerical values. We explore a setup for performing classification on labeled classical datasets, consisting of a classical neural network connected to a quantum annealer. The neural network programs the quantum annealer's controls and thereby maps the annealer's initial states into new states in the Hilbert space. The neural network's parameters are optimized to maximize the distance of states corresponding to inputs from different classes and minimize the distance between quantum states corresponding to the same class. Recent literature showed that at least some of the "learning" is due to the quantum annealer, connecting a small linear network to a quantum annealer and using it to learn small and linearly inseparable datasets. In this study, we consider a similar but not quite the same case, where a classical fully-fledged neural network is connected with a small quantum annealer. In such a setting, the fully-fledged classical neural-network already has built-in nonlinearity and learning power, and can already handle the classification problem alone, we want to see whether an additional quantum layer could boost its performance. We simulate this system to learn several common datasets, including those for image and sound recognition. We conclude that adding a small quantum annealer does not provide a significant benefit over just using a regular (nonlinear) classical neural network.
A Generalized Physical-knowledge-guided Dynamic Model for Underwater Image Enhancement
Aug 10, 2023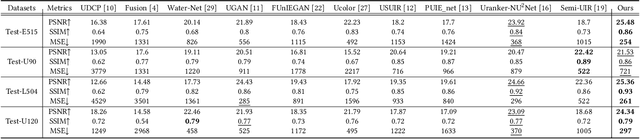
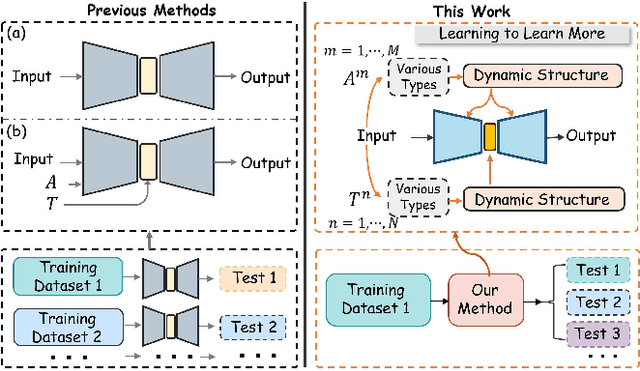
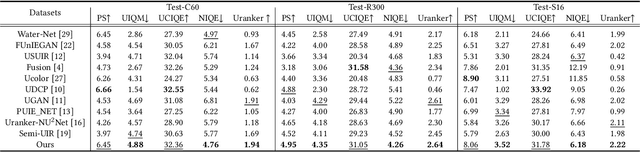
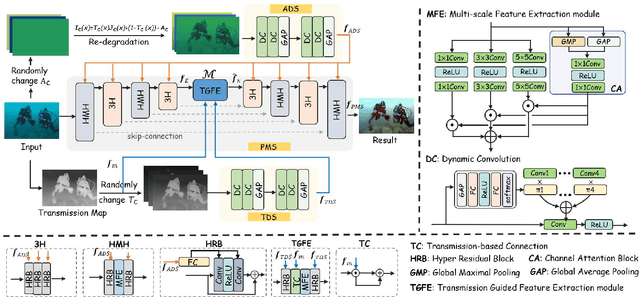
Underwater images often suffer from color distortion and low contrast resulting in various image types, due to the scattering and absorption of light by water. While it is difficult to obtain high-quality paired training samples with a generalized model. To tackle these challenges, we design a Generalized Underwater image enhancement method via a Physical-knowledge-guided Dynamic Model (short for GUPDM), consisting of three parts: Atmosphere-based Dynamic Structure (ADS), Transmission-guided Dynamic Structure (TDS), and Prior-based Multi-scale Structure (PMS). In particular, to cover complex underwater scenes, this study changes the global atmosphere light and the transmission to simulate various underwater image types (e.g., the underwater image color ranging from yellow to blue) through the formation model. We then design ADS and TDS that use dynamic convolutions to adaptively extract prior information from underwater images and generate parameters for PMS. These two modules enable the network to select appropriate parameters for various water types adaptively. Besides, the multi-scale feature extraction module in PMS uses convolution blocks with different kernel sizes and obtains weights for each feature map via channel attention block and fuses them to boost the receptive field of the network. The source code will be available at \href{https://github.com/shiningZZ/GUPDM}{https://github.com/shiningZZ/GUPDM}.
Robust Lifelong Indoor LiDAR Localization using the Area Graph
Aug 10, 2023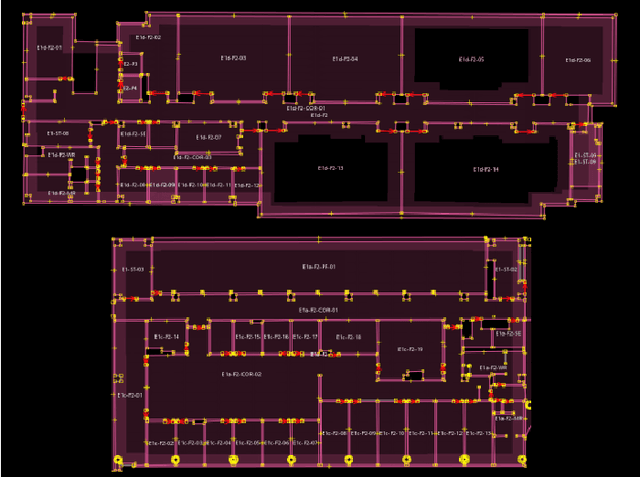
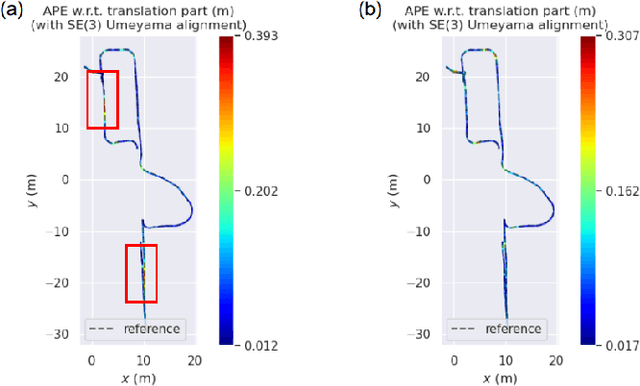
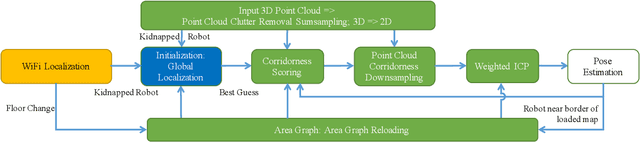

Lifelong indoor localization in a given map is the basis for navigation of autonomous mobile robots. In this letter, we address the problem of robust localization in cluttered indoor environments like office spaces and corridors using 3D LiDAR point clouds in a given Area Graph, which is a hierarchical, topometric semantic map representation that uses polygons to demark areas such as rooms, corridors or buildings. This representation is very compact, can represent different floors of buildings through its hierarchy and provides semantic information that helps with localization, like poses of doors and glass. In contrast to this, commonly used map representations, such as occupancy grid maps or point clouds, lack these features and require frequent updates in response to environmental changes (e.g. moved furniture), unlike our approach, which matches against lifelong architectural features such as walls and doors. For that we apply filtering to remove clutter from the 3D input point cloud and then employ further scoring and weight functions for localization. Given a broad initial guess from WiFi localization, our experiments show that our global localization and the weighted point to line ICP pose tracking perform very well, even when compared to localization and SLAM algorithms that use the current, feature-rich cluttered map for localization.