 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AspectCSE: Sentence Embeddings for Aspect-based Semantic Textual Similarity using Contrastive Learning and Structured Knowledge
Jul 22, 2023
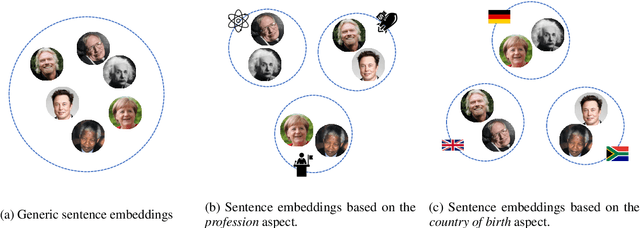
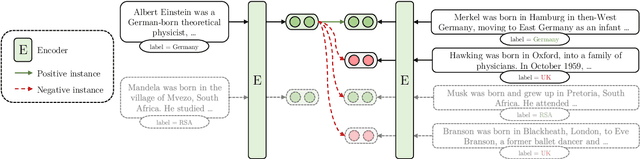
Generic sentence embeddings provide a coarse-grained approximation of semantic textual similarity but ignore specific aspects that make texts similar. Conversely, aspect-based sentence embeddings provide similarities between texts based on certain predefined aspects. Thus, similarity predictions of texts are more targeted to specific requirements and more easily explainable. In this paper, we present AspectCSE, an approach for aspect-based contrastive learning of sentence embeddings. Results indicate that AspectCSE achieves an average improvement of 3.97% on information retrieval tasks across multiple aspects compared to the previous best results. We also propose using Wikidata knowledge graph properties to train models of multi-aspect sentence embeddings in which multiple specific aspects are simultaneously considered during similarity predictions. We demonstrate that multi-aspect embeddings outperform single-aspect embeddings on aspect-specific information retrieval tasks. Finally, we examine the aspect-based sentence embedding space and demonstrate that embeddings of semantically similar aspect labels are often close, even without explicit similarity training between different aspect labels.
Deep Reinforcement Learning Based Intelligent Reflecting Surface Optimization for TDD MultiUser MIMO Systems
Jul 28, 2023
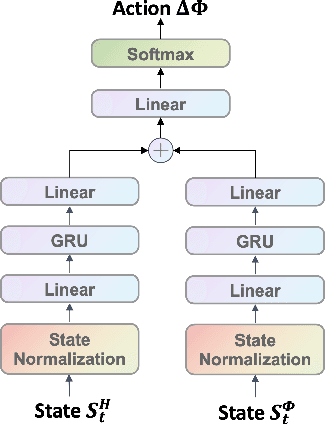
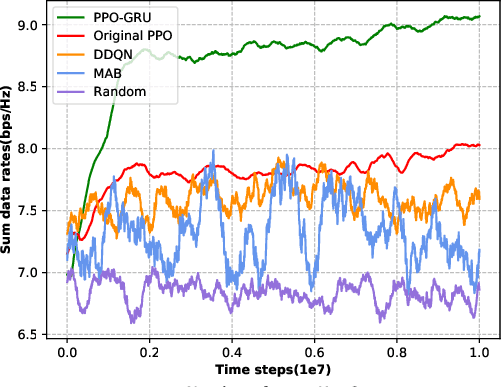
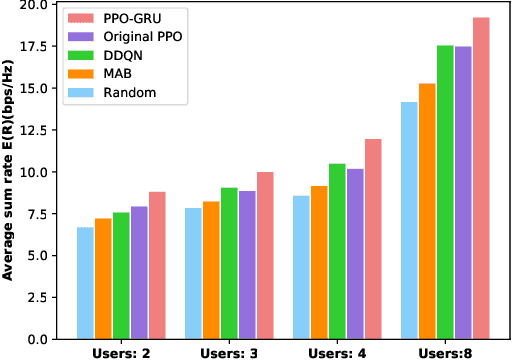
In this letter, we investigate the discrete phase shift design of the intelligent reflecting surface (IRS) in a time division duplexing (TDD) multi-user multiple input multiple output (MIMO) system.We modify the design of deep reinforcement learning (DRL) scheme so that we can maximizing the average downlink data transmission rate free from the sub-channel channel state information (CSI). Based on the characteristics of the model, we modify the proximal policy optimization (PPO) algorithm and integrate gated recurrent unit (GRU) to tackle the non-convex optimization problem. Simulation results show that the performance of the proposed PPO-GRU surpasses the benchmarks in terms of performance, convergence speed, and training stability.
A Preliminary Evaluation of ChatGPT in Requirements Information Retrieval
Apr 25, 2023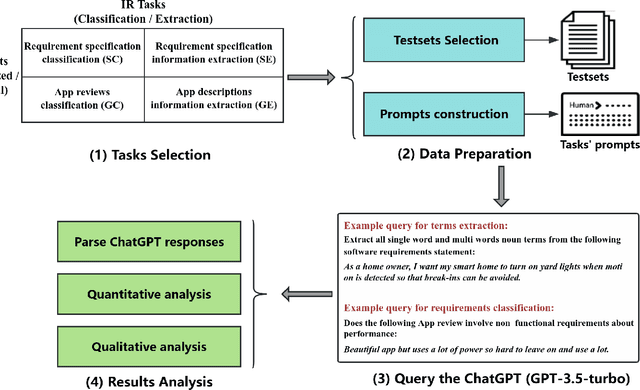
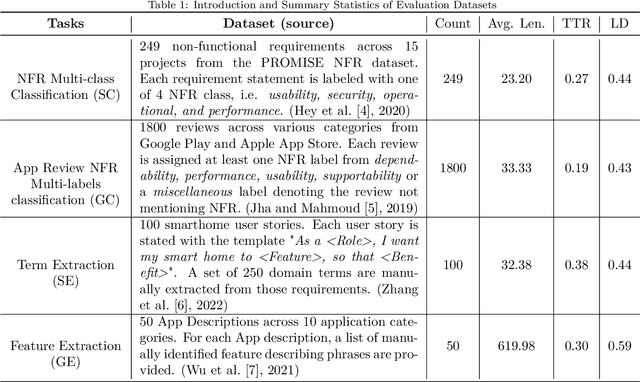
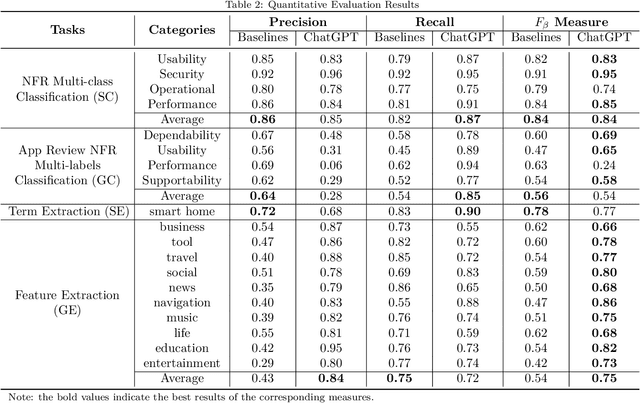
Context: Recently, many illustrative examples have shown ChatGPT's impressive ability to perform programming tasks and answer general domain questions. Objective: We empirically evaluate how ChatGPT performs on requirements analysis tasks to derive insights into how generative large language model, represented by ChatGPT, influence the research and practice of natural language processing for requirements engineering. Method: We design an evaluation pipeline including two common requirements information retrieval tasks, four public datasets involving two typical requirements artifacts, querying ChatGPT with fixed task prompts, and quantitative and qualitative results analysis. Results: Quantitative results show that ChatGPT achieves comparable or better $F\beta$ values in all datasets under a zero-shot setting. Qualitative analysis further illustrates ChatGPT's powerful natural language processing ability and limited requirements engineering domain knowledge. Conclusion: The evaluation results demonstrate ChatGPT' impressive ability to retrieve requirements information from different types artifacts involving multiple languages under a zero-shot setting. It is worthy for the research and industry communities to study generative large language model based requirements retrieval models and to develop corresponding tools.
Implicit Identity Representation Conditioned Memory Compensation Network for Talking Head video Generation
Jul 20, 2023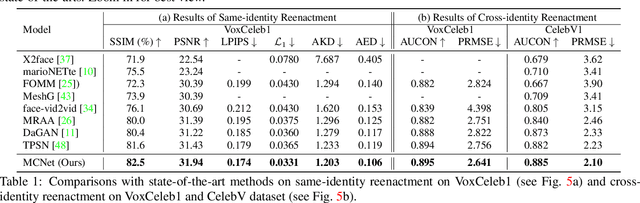
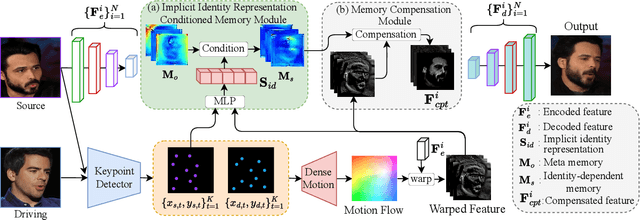
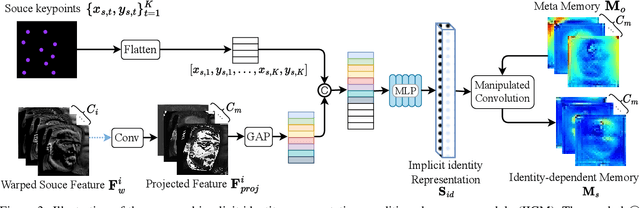
Talking head video generation aims to animate a human face in a still image with dynamic poses and expressions using motion information derived from a target-driving video, while maintaining the person's identity in the source image. However, dramatic and complex motions in the driving video cause ambiguous generation, because the still source image cannot provide sufficient appearance information for occluded regions or delicate expression variations, which produces severe artifacts and significantly degrades the generation quality. To tackle this problem, we propose to learn a global facial representation space, and design a novel implicit identity representation conditioned memory compensation network, coined as MCNet, for high-fidelity talking head generation.~Specifically, we devise a network module to learn a unified spatial facial meta-memory bank from all training samples, which can provide rich facial structure and appearance priors to compensate warped source facial features for the generation. Furthermore, we propose an effective query mechanism based on implicit identity representations learned from the discrete keypoints of the source image. It can greatly facilitate the retrieval of more correlated information from the memory bank for the compensation. Extensive experiments demonstrate that MCNet can learn representative and complementary facial memory, and can clearly outperform previous state-of-the-art talking head generation methods on VoxCeleb1 and CelebV datasets. Please check our \href{https://github.com/harlanhong/ICCV2023-MCNET}{Project}.
Layer-wise Representation Fusion for Compositional Generalization
Jul 20, 2023Despite successes across a broad range of applications, sequence-to-sequence models' construct of solutions are argued to be less compositional than human-like generalization. There is mounting evidence that one of the reasons hindering compositional generalization is representations of the encoder and decoder uppermost layer are entangled. In other words, the syntactic and semantic representations of sequences are twisted inappropriately. However, most previous studies mainly concentrate on enhancing token-level semantic information to alleviate the representations entanglement problem, rather than composing and using the syntactic and semantic representations of sequences appropriately as humans do. In addition, we explain why the entanglement problem exists from the perspective of recent studies about training deeper Transformer, mainly owing to the ``shallow'' residual connections and its simple, one-step operations, which fails to fuse previous layers' information effectively. Starting from this finding and inspired by humans' strategies, we propose \textsc{FuSion} (\textbf{Fu}sing \textbf{S}yntactic and Semant\textbf{i}c Representati\textbf{on}s), an extension to sequence-to-sequence models to learn to fuse previous layers' information back into the encoding and decoding process appropriately through introducing a \emph{fuse-attention module} at each encoder and decoder layer. \textsc{FuSion} achieves competitive and even \textbf{state-of-the-art} results on two realistic benchmarks, which empirically demonstrates the effectiveness of our proposal.
Towards Precise Weakly Supervised Object Detection via Interactive Contrastive Learning of Context Information
May 05, 2023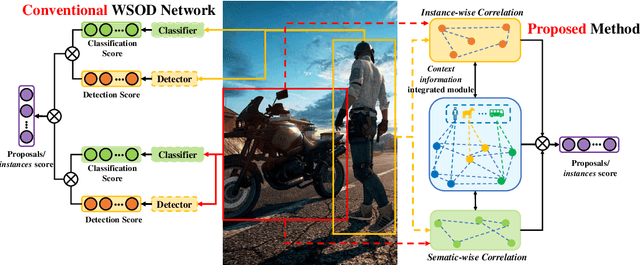
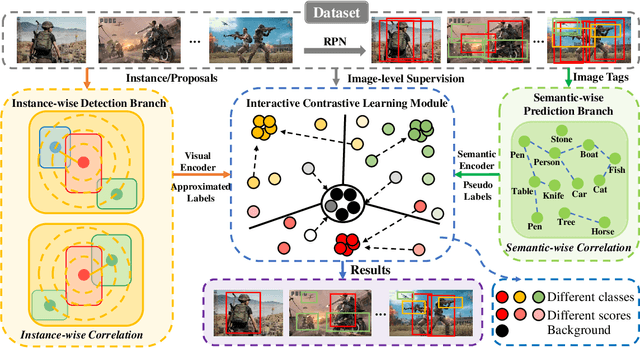
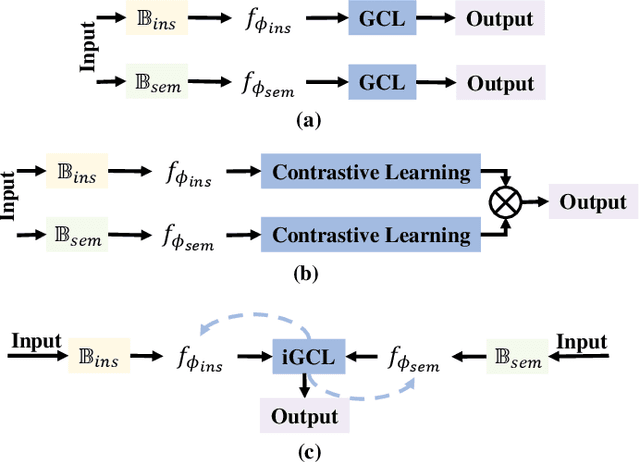

Weakly supervised object detection (WSOD) aims at learning precise object detectors with only image-level tags. In spite of intensive research on deep learning (DL) approaches over the past few years, there is still a significant performance gap between WSOD and fully supervised object detection. In fact, most existing WSOD methods only consider the visual appearance of each region proposal but ignore employing the useful context information in the image. To this end, this paper proposes an interactive end-to-end WSDO framework called JLWSOD with two innovations: i) two types of WSOD-specific context information (i.e., instance-wise correlation andsemantic-wise correlation) are proposed and introduced into WSOD framework; ii) an interactive graph contrastive learning (iGCL) mechanism is designed to jointly optimize the visual appearance and context information for better WSOD performance. Specifically, the iGCL mechanism takes full advantage of the complementary interpretations of the WSOD, namely instance-wise detection and semantic-wise prediction tasks, forming a more comprehensive solution. Extensive experiments on the widely used PASCAL VOC and MS COCO benchmarks verify the superiority of JLWSOD over alternative state-of-the-art approaches and baseline models (improvement of 3.6%~23.3% on mAP and 3.4%~19.7% on CorLoc, respectively).
Statistical Mechanics of Learning via Reverberation in Bidirectional Associative Memories
Jul 17, 2023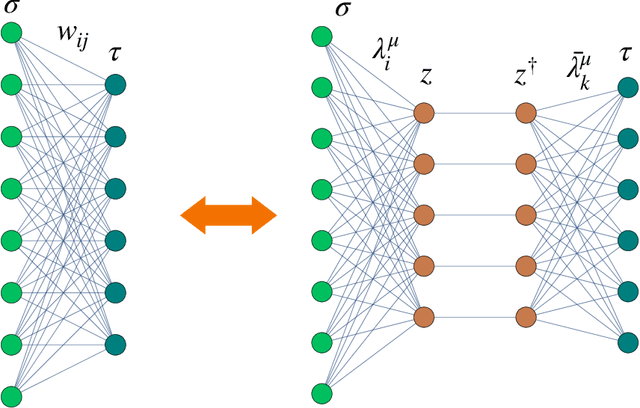
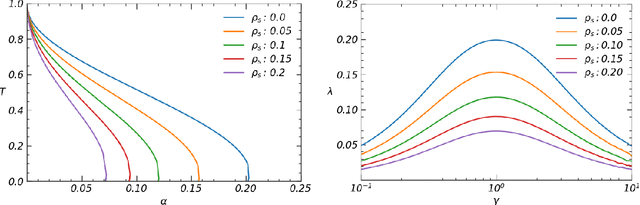
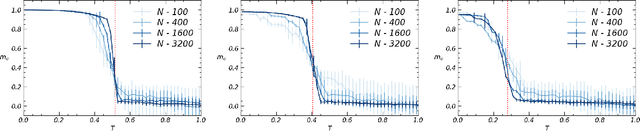
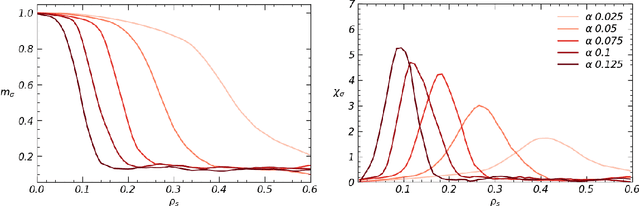
We study bi-directional associative neural networks that, exposed to noisy examples of an extensive number of random archetypes, learn the latter (with or without the presence of a teacher) when the supplied information is enough: in this setting, learning is heteroassociative -- involving couples of patterns -- and it is achieved by reverberating the information depicted from the examples through the layers of the network. By adapting Guerra's interpolation technique, we provide a full statistical mechanical picture of supervised and unsupervised learning processes (at the replica symmetric level of description) obtaining analytically phase diagrams, thresholds for learning, a picture of the ground-state in plain agreement with Monte Carlo simulations and signal-to-noise outcomes. In the large dataset limit, the Kosko storage prescription as well as its statistical mechanical picture provided by Kurchan, Peliti, and Saber in the eighties is fully recovered. Computational advantages in dealing with information reverberation, rather than storage, are discussed for natural test cases. In particular, we show how this network admits an integral representation in terms of two coupled restricted Boltzmann machines, whose hidden layers are entirely built of by grand-mother neurons, to prove that by coupling solely these grand-mother neurons we can correlate the patterns they are related to: it is thus possible to recover Pavlov's Classical Conditioning by adding just one synapse among the correct grand-mother neurons (hence saving an extensive number of these links for further information storage w.r.t. the classical autoassociative setting).
Anticipating Responsibility in Multiagent Planning
Jul 31, 2023Responsibility anticipation is the process of determining if the actions of an individual agent may cause it to be responsible for a particular outcome. This can be used in a multi-agent planning setting to allow agents to anticipate responsibility in the plans they consider. The planning setting in this paper includes partial information regarding the initial state and considers formulas in linear temporal logic as positive or negative outcomes to be attained or avoided. We firstly define attribution for notions of active, passive and contributive responsibility, and consider their agentive variants. We then use these to define the notion of responsibility anticipation. We prove that our notions of anticipated responsibility can be used to coordinate agents in a planning setting and give complexity results for our model, discussing equivalence with classical planning. We also present an outline for solving some of our attribution and anticipation problems using PDDL solvers.
Towards General Visual-Linguistic Face Forgery Detection
Jul 31, 2023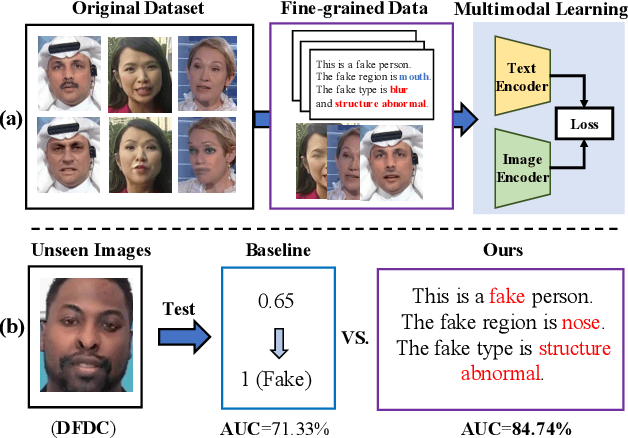
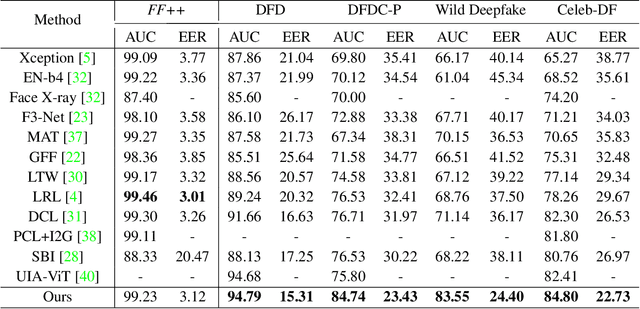
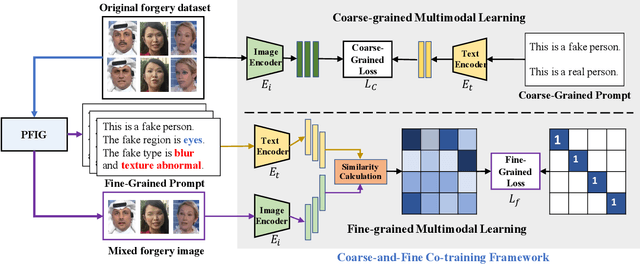
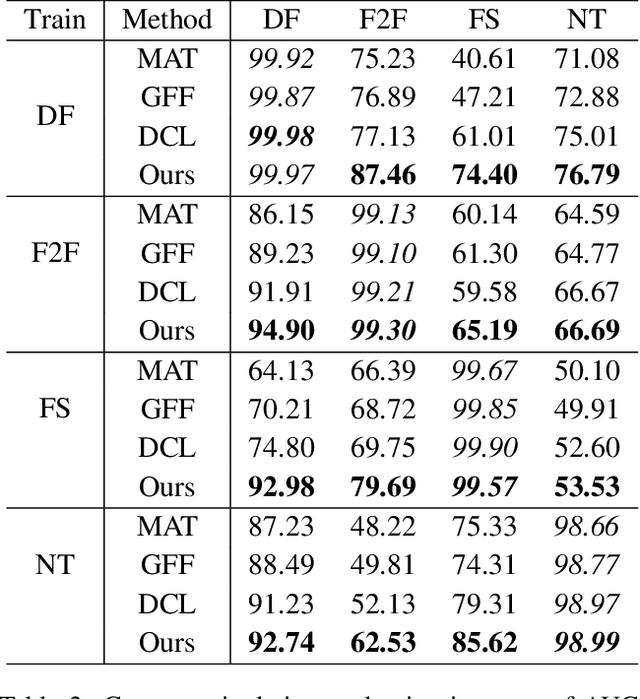
Deepfakes are realistic face manipulations that can pose serious threats to security, privacy, and trust. Existing methods mostly treat this task as binary classification, which uses digital labels or mask signals to train the detection model. We argue that such supervisions lack semantic information and interpretability. To address this issues, in this paper, we propose a novel paradigm named Visual-Linguistic Face Forgery Detection(VLFFD), which uses fine-grained sentence-level prompts as the annotation. Since text annotations are not available in current deepfakes datasets, VLFFD first generates the mixed forgery image with corresponding fine-grained prompts via Prompt Forgery Image Generator (PFIG). Then, the fine-grained mixed data and coarse-grained original data and is jointly trained with the Coarse-and-Fine Co-training framework (C2F), enabling the model to gain more generalization and interpretability. The experiments show the proposed method improves the existing detection models on several challenging benchmarks.
TFE-GNN: A Temporal Fusion Encoder Using Graph Neural Networks for Fine-grained Encrypted Traffic Classification
Jul 31, 2023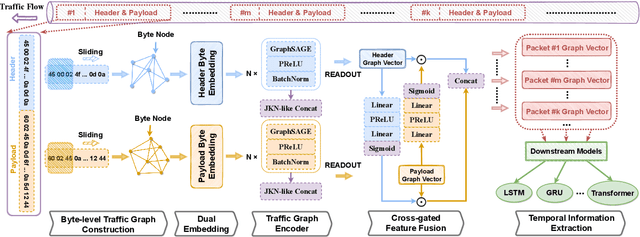
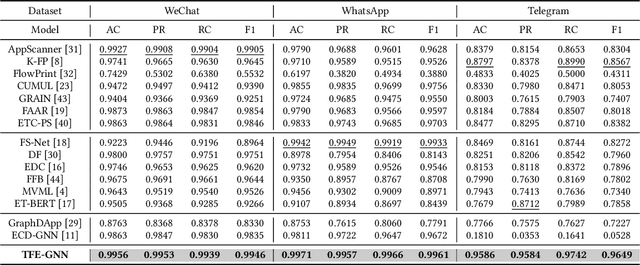
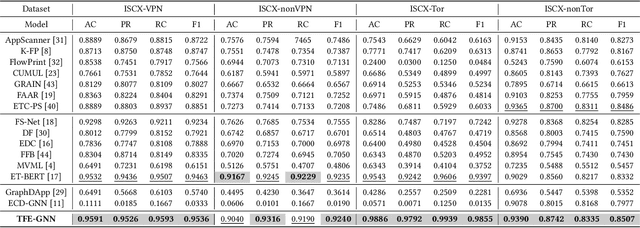
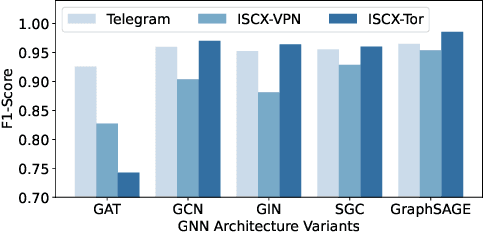
Encrypted traffic classification is receiving widespread attention from researchers and industrial companies. However, the existing methods only extract flow-level features, failing to handle short flows because of unreliable statistical properties, or treat the header and payload equally, failing to mine the potential correlation between bytes. Therefore, in this paper, we propose a byte-level traffic graph construction approach based on point-wise mutual information (PMI), and a model named Temporal Fusion Encoder using Graph Neural Networks (TFE-GNN) for feature extraction. In particular, we design a dual embedding layer, a GNN-based traffic graph encoder as well as a cross-gated feature fusion mechanism, which can first embed the header and payload bytes separately and then fuses them together to obtain a stronger feature representation. The experimental results on two real datasets demonstrate that TFE-GNN outperforms multiple state-of-the-art methods in fine-grained encrypted traffic classification tasks.