 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning-based Spatial and Angular Information Separation for Light Field Compression
Apr 13, 2023
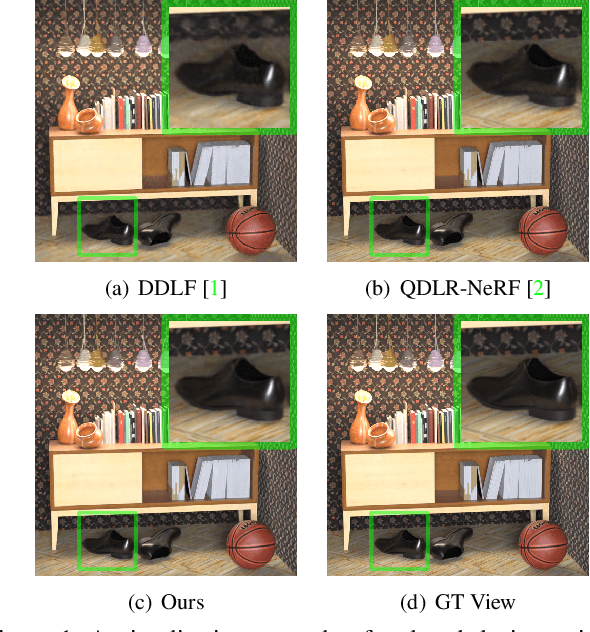
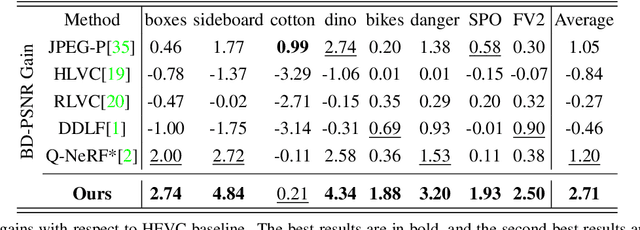
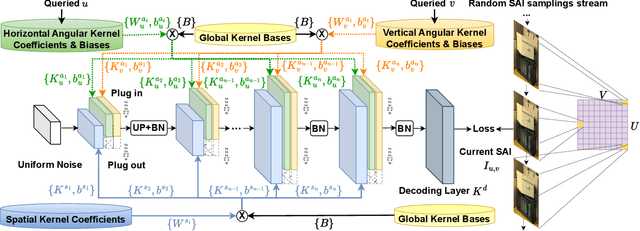
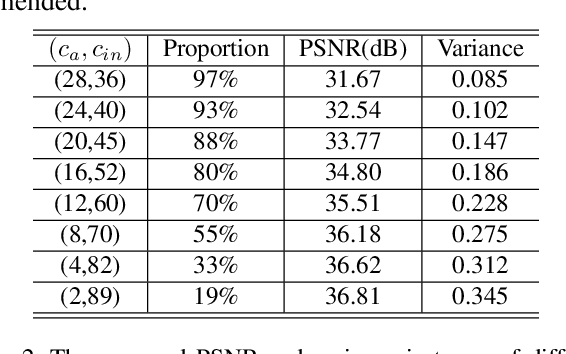
Light fields are a type of image data that capture both spatial and angular scene information by recording light rays emitted by a scene from different orientations. In this context, spatial information is defined as features that remain static regardless of perspectives, while angular information refers to features that vary between viewpoints. We propose a novel neural network that, by design, can separate angular and spatial information of a light field. The network represents spatial information using spatial kernels shared among all Sub-Aperture Images (SAIs), and angular information using sets of angular kernels for each SAI. To further improve the representation capability of the network without increasing parameter number, we also introduce angular kernel allocation and kernel tensor decomposition mechanisms. Extensive experiments demonstrate the benefits of information separation: when applied to the compression task, our network outperforms other state-of-the-art methods by a large margin. And angular information can be easily transferred to other scenes for rendering dense views, showing the successful separation and the potential use case for the view synthesis task. We plan to release the code upon acceptance of the paper to encourage further research on this topic.
Towards Precise Weakly Supervised Object Detection via Interactive Contrastive Learning of Context Information
May 05, 2023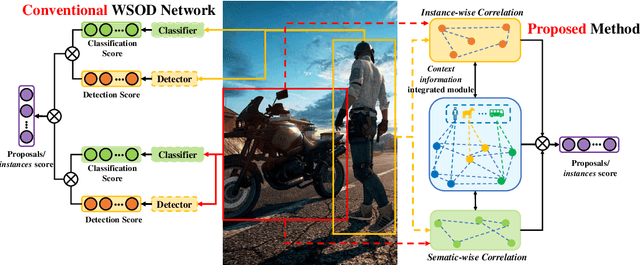
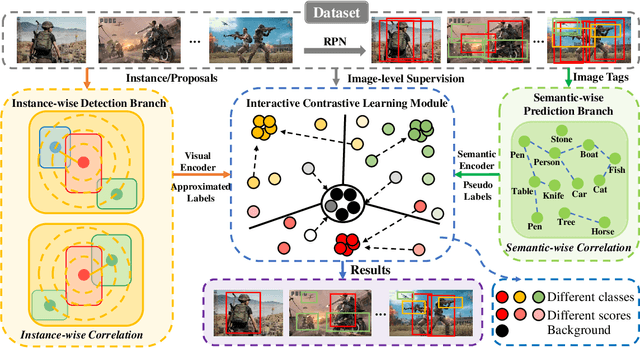
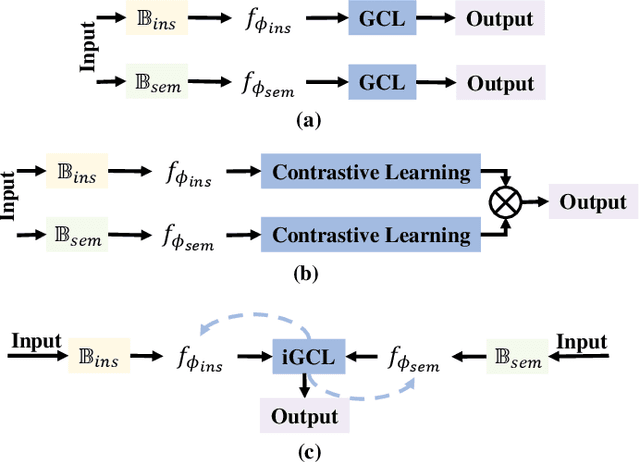

Weakly supervised object detection (WSOD) aims at learning precise object detectors with only image-level tags. In spite of intensive research on deep learning (DL) approaches over the past few years, there is still a significant performance gap between WSOD and fully supervised object detection. In fact, most existing WSOD methods only consider the visual appearance of each region proposal but ignore employing the useful context information in the image. To this end, this paper proposes an interactive end-to-end WSDO framework called JLWSOD with two innovations: i) two types of WSOD-specific context information (i.e., instance-wise correlation andsemantic-wise correlation) are proposed and introduced into WSOD framework; ii) an interactive graph contrastive learning (iGCL) mechanism is designed to jointly optimize the visual appearance and context information for better WSOD performance. Specifically, the iGCL mechanism takes full advantage of the complementary interpretations of the WSOD, namely instance-wise detection and semantic-wise prediction tasks, forming a more comprehensive solution. Extensive experiments on the widely used PASCAL VOC and MS COCO benchmarks verify the superiority of JLWSOD over alternative state-of-the-art approaches and baseline models (improvement of 3.6%~23.3% on mAP and 3.4%~19.7% on CorLoc, respectively).
Improving Text Semantic Similarity Modeling through a 3D Siamese Network
Jul 18, 2023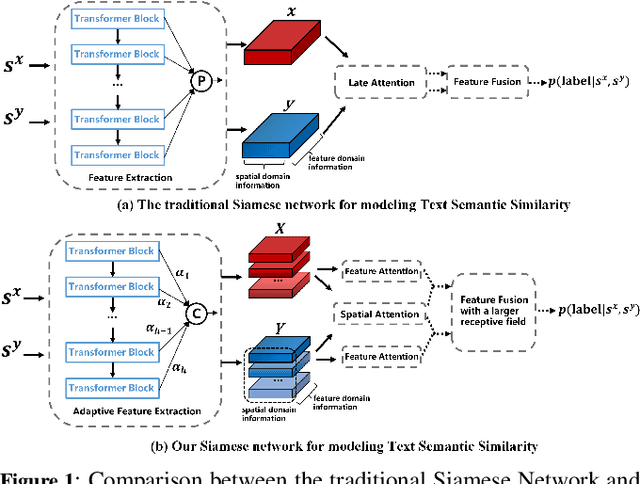
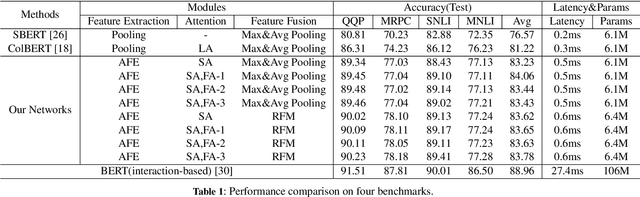
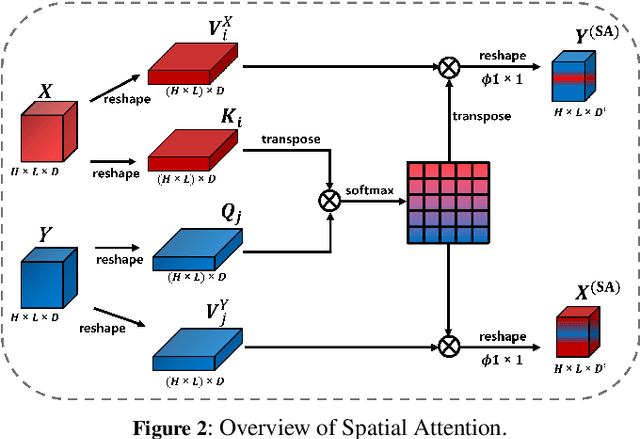
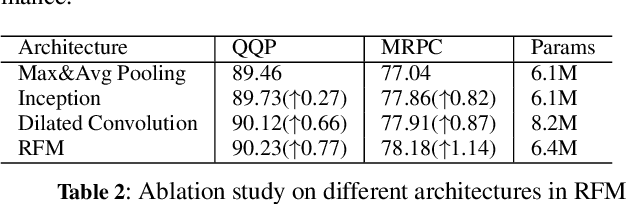
Siamese networks have gained popularity as a method for modeling text semantic similarity. Traditional methods rely on pooling operation to compress the semantic representations from Transformer blocks in encoding, resulting in two-dimensional semantic vectors and the loss of hierarchical semantic information from Transformer blocks. Moreover, this limited structure of semantic vectors is akin to a flattened landscape, which restricts the methods that can be applied in downstream modeling, as they can only navigate this flat terrain. To address this issue, we propose a novel 3D Siamese network for text semantic similarity modeling, which maps semantic information to a higher-dimensional space. The three-dimensional semantic tensors not only retains more precise spatial and feature domain information but also provides the necessary structural condition for comprehensive downstream modeling strategies to capture them. Leveraging this structural advantage, we introduce several modules to reinforce this 3D framework, focusing on three aspects: feature extraction, attention, and feature fusion. Our extensive experiments on four text semantic similarity benchmarks demonstrate the effectiveness and efficiency of our 3D Siamese Network.
LOIS: Looking Out of Instance Semantics for Visual Question Answering
Jul 26, 2023
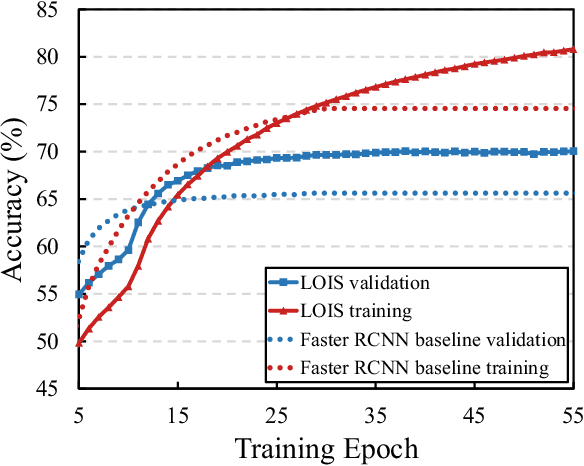

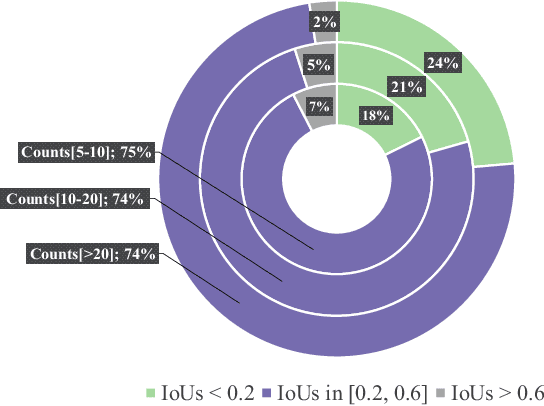
Visual question answering (VQA) has been intensively studied as a multimodal task that requires effort in bridging vision and language to infer answers correctly. Recent attempts have developed various attention-based modules for solving VQA tasks. However, the performance of model inference is largely bottlenecked by visual processing for semantics understanding. Most existing detection methods rely on bounding boxes, remaining a serious challenge for VQA models to understand the causal nexus of object semantics in images and correctly infer contextual information. To this end, we propose a finer model framework without bounding boxes in this work, termed Looking Out of Instance Semantics (LOIS) to tackle this important issue. LOIS enables more fine-grained feature descriptions to produce visual facts. Furthermore, to overcome the label ambiguity caused by instance masks, two types of relation attention modules: 1) intra-modality and 2) inter-modality, are devised to infer the correct answers from the different multi-view features. Specifically, we implement a mutual relation attention module to model sophisticated and deeper visual semantic relations between instance objects and background information. In addition, our proposed attention model can further analyze salient image regions by focusing on important word-related questions. Experimental results on four benchmark VQA datasets prove that our proposed method has favorable performance in improving visual reasoning capability.
Unite-Divide-Unite: Joint Boosting Trunk and Structure for High-accuracy Dichotomous Image Segmentation
Jul 26, 2023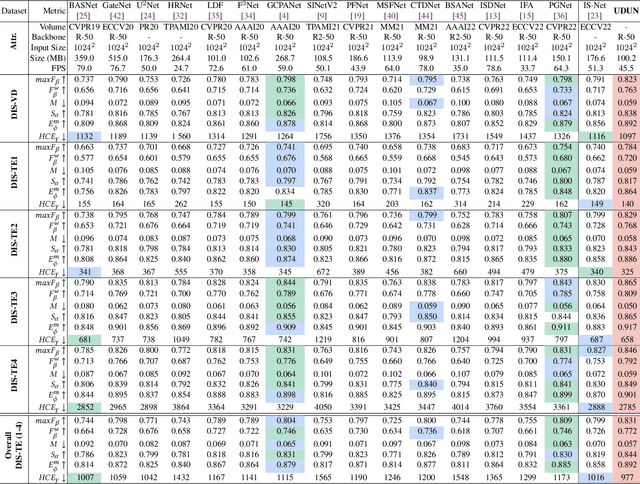
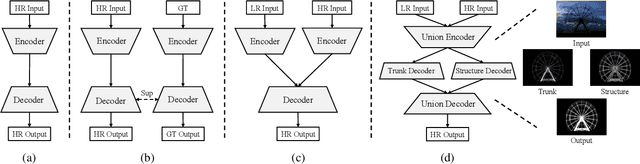

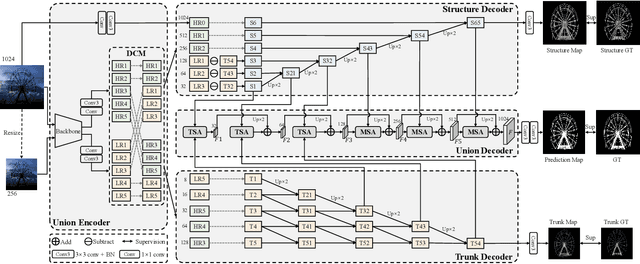
High-accuracy Dichotomous Image Segmentation (DIS) aims to pinpoint category-agnostic foreground objects from natural scenes. The main challenge for DIS involves identifying the highly accurate dominant area while rendering detailed object structure. However, directly using a general encoder-decoder architecture may result in an oversupply of high-level features and neglect the shallow spatial information necessary for partitioning meticulous structures. To fill this gap, we introduce a novel Unite-Divide-Unite Network (UDUN} that restructures and bipartitely arranges complementary features to simultaneously boost the effectiveness of trunk and structure identification. The proposed UDUN proceeds from several strengths. First, a dual-size input feeds into the shared backbone to produce more holistic and detailed features while keeping the model lightweight. Second, a simple Divide-and-Conquer Module (DCM) is proposed to decouple multiscale low- and high-level features into our structure decoder and trunk decoder to obtain structure and trunk information respectively. Moreover, we design a Trunk-Structure Aggregation module (TSA) in our union decoder that performs cascade integration for uniform high-accuracy segmentation. As a result, UDUN performs favorably against state-of-the-art competitors in all six evaluation metrics on overall DIS-TE, i.e., achieving 0.772 weighted F-measure and 977 HCE. Using 1024*1024 input, our model enables real-time inference at 65.3 fps with ResNet-18.
Multilingual context-based pronunciation learning for Text-to-Speech
Jul 31, 2023



Phonetic information and linguistic knowledge are an essential component of a Text-to-speech (TTS) front-end. Given a language, a lexicon can be collected offline and Grapheme-to-Phoneme (G2P) relationships are usually modeled in order to predict the pronunciation for out-of-vocabulary (OOV) words. Additionally, post-lexical phonology, often defined in the form of rule-based systems, is used to correct pronunciation within or between words. In this work we showcase a multilingual unified front-end system that addresses any pronunciation related task, typically handled by separate modules. We evaluate the proposed model on G2P conversion and other language-specific challenges, such as homograph and polyphones disambiguation, post-lexical rules and implicit diacritization. We find that the multilingual model is competitive across languages and tasks, however, some trade-offs exists when compared to equivalent monolingual solutions.
MobileVidFactory: Automatic Diffusion-Based Social Media Video Generation for Mobile Devices from Text
Jul 31, 2023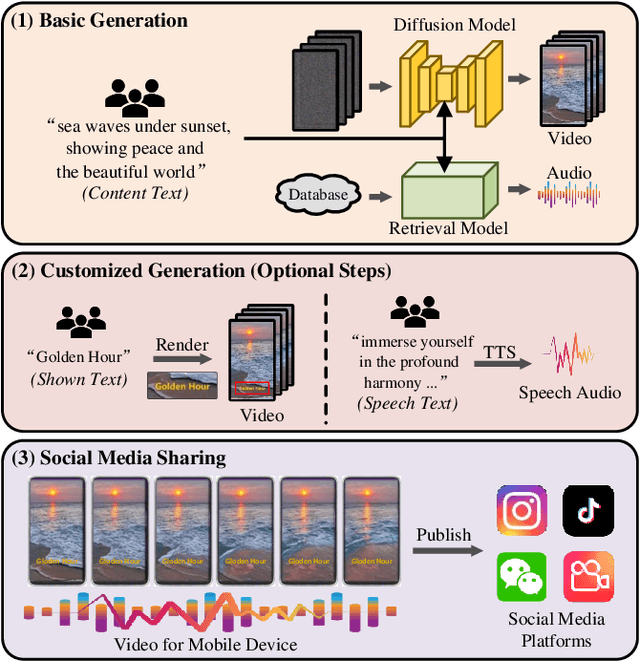

Videos for mobile devices become the most popular access to share and acquire information recently. For the convenience of users' creation, in this paper, we present a system, namely MobileVidFactory, to automatically generate vertical mobile videos where users only need to give simple texts mainly. Our system consists of two parts: basic and customized generation. In the basic generation, we take advantage of the pretrained image diffusion model, and adapt it to a high-quality open-domain vertical video generator for mobile devices. As for the audio, by retrieving from our big database, our system matches a suitable background sound for the video. Additionally to produce customized content, our system allows users to add specified screen texts to the video for enriching visual expression, and specify texts for automatic reading with optional voices as they like.
Gaussian Graph with Prototypical Contrastive Learning in E-Commerce Bundle Recommendation
Jul 25, 2023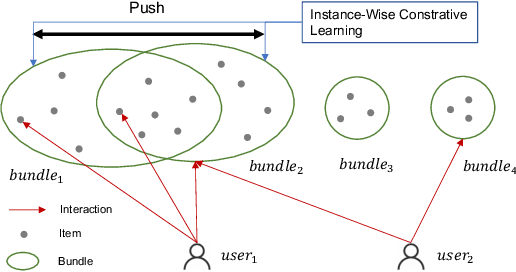
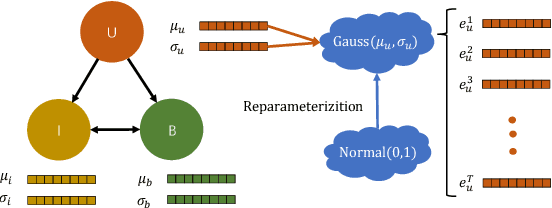

Bundle recommendation aims to provide a bundle of items to satisfy the user preference on e-commerce platform. Existing successful solutions are based on the contrastive graph learning paradigm where graph neural networks (GNNs) are employed to learn representations from user-level and bundle-level graph views with a contrastive learning module to enhance the cooperative association between different views. Nevertheless, they ignore the uncertainty issue which has a significant impact in real bundle recommendation scenarios due to the lack of discriminative information caused by highly sparsity or diversity. We further suggest that their instancewise contrastive learning fails to distinguish the semantically similar negatives (i.e., sampling bias issue), resulting in performance degradation. In this paper, we propose a novel Gaussian Graph with Prototypical Contrastive Learning (GPCL) framework to overcome these challenges. In particular, GPCL embeds each user/bundle/item as a Gaussian distribution rather than a fixed vector. We further design a prototypical contrastive learning module to capture the contextual information and mitigate the sampling bias issue. Extensive experiments demonstrate that benefiting from the proposed components, we achieve new state-of-the-art performance compared to previous methods on several public datasets. Moreover, GPCL has been deployed on real-world e-commerce platform and achieved substantial improvements.
An Intent Taxonomy of Legal Case Retrieval
Jul 25, 2023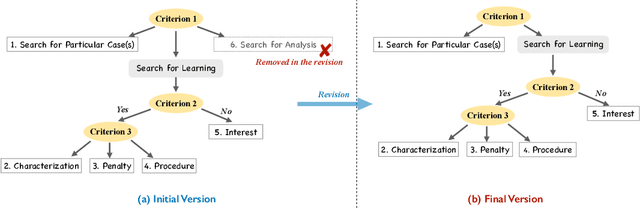
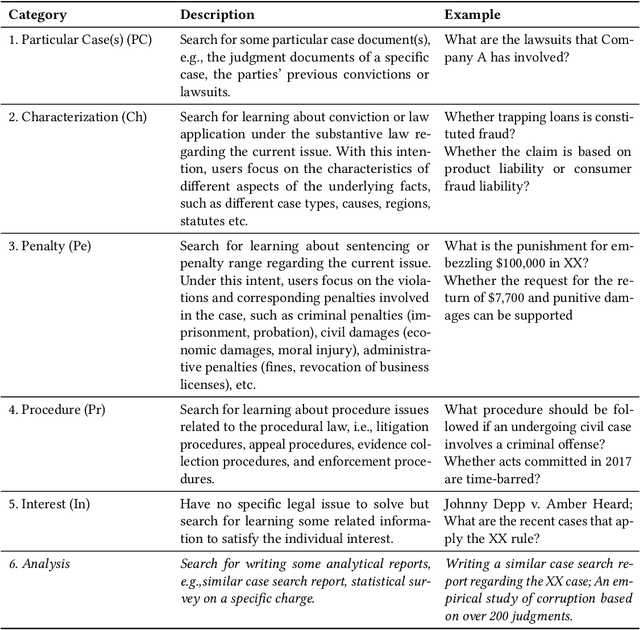
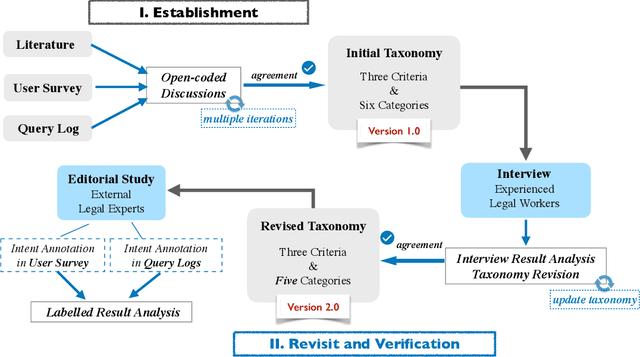

Legal case retrieval is a special Information Retrieval~(IR) task focusing on legal case documents. Depending on the downstream tasks of the retrieved case documents, users' information needs in legal case retrieval could be significantly different from those in Web search and traditional ad-hoc retrieval tasks. While there are several studies that retrieve legal cases based on text similarity, the underlying search intents of legal retrieval users, as shown in this paper, are more complicated than that yet mostly unexplored. To this end, we present a novel hierarchical intent taxonomy of legal case retrieval. It consists of five intent types categorized by three criteria, i.e., search for Particular Case(s), Characterization, Penalty, Procedure, and Interest. The taxonomy was constructed transparently and evaluated extensively through interviews, editorial user studies, and query log analysis. Through a laboratory user study, we reveal significant differences in user behavior and satisfaction under different search intents in legal case retrieval. Furthermore, we apply the proposed taxonomy to various downstream legal retrieval tasks, e.g., result ranking and satisfaction prediction, and demonstrate its effectiveness. Our work provides important insights into the understanding of user intents in legal case retrieval and potentially leads to better retrieval techniques in the legal domain, such as intent-aware ranking strategies and evaluation methodologies.
Towards Personalized Prompt-Model Retrieval for Generative Recommendation
Aug 04, 2023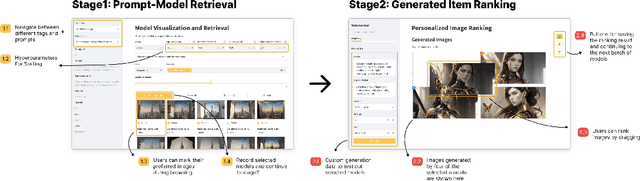

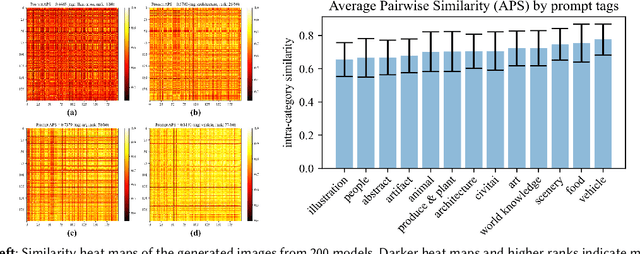
Recommender Systems are built to retrieve relevant items to satisfy users' information needs. The candidate corpus usually consists of a finite set of items that are ready to be served, such as videos, products, or articles. With recent advances in Generative AI such as GPT and Diffusion models, a new form of recommendation task is yet to be explored where items are to be created by generative models with personalized prompts. Taking image generation as an example, with a single prompt from the user and access to a generative model, it is possible to generate hundreds of new images in a few minutes. How shall we attain personalization in the presence of "infinite" items? In this preliminary study, we propose a two-stage framework, namely Prompt-Model Retrieval and Generated Item Ranking, to approach this new task formulation. We release GEMRec-18K, a prompt-model interaction dataset with 18K images generated by 200 publicly-available generative models paired with a diverse set of 90 textual prompts. Our findings demonstrate the promise of generative model recommendation as a novel personalization problem and the limitations of existing evaluation metrics. We highlight future directions for the RecSys community to advance towards generative recommender systems. Our code and dataset are available at https://github.com/MAPS-research/GEMRec.