 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SafeSteps: Learning Safer Footstep Planning Policies for Legged Robots via Model-Based Priors
Jul 24, 2023
We present a footstep planning policy for quadrupedal locomotion that is able to directly take into consideration a-priori safety information in its decisions. At its core, a learning process analyzes terrain patches, classifying each landing location by its kinematic feasibility, shin collision, and terrain roughness. This information is then encoded into a small vector representation and passed as an additional state to the footstep planning policy, which furthermore proposes only safe footstep location by applying a masked variant of the Proximal Policy Optimization (PPO) algorithm. The performance of the proposed approach is shown by comparative simulations on an electric quadruped robot walking in different rough terrain scenarios. We show that violations of the above safety conditions are greatly reduced both during training and the successive deployment of the policy, resulting in an inherently safer footstep planner. Furthermore, we show how, as a byproduct, fewer reward terms are needed to shape the behavior of the policy, which in return is able to achieve both better final performances and sample efficiency
A General Framework for Visualizing Embedding Spaces of Neural Survival Analysis Models Based on Angular Information
May 11, 2023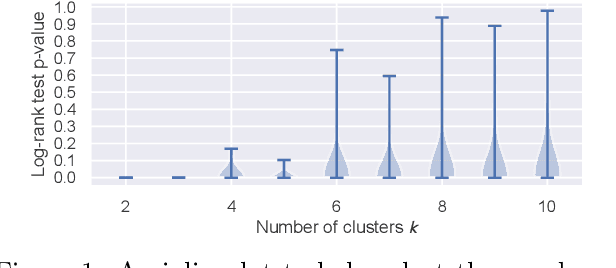

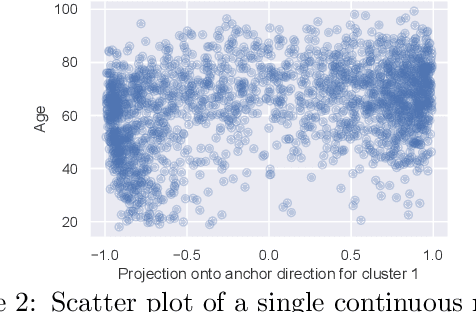
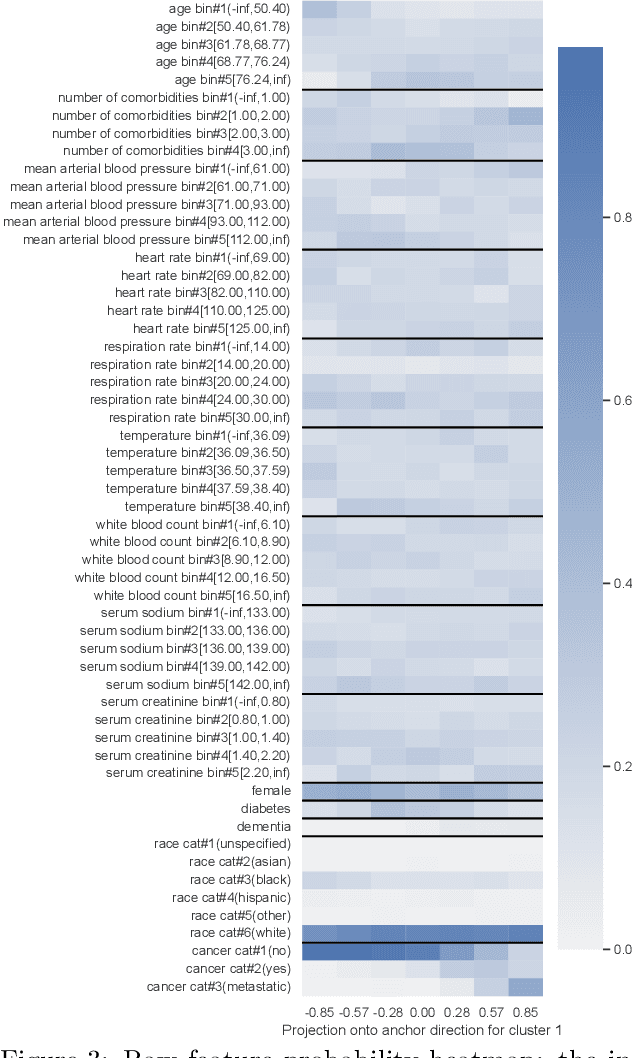
We propose a general framework for visualizing any intermediate embedding representation used by any neural survival analysis model. Our framework is based on so-called anchor directions in an embedding space. We show how to estimate these anchor directions using clustering or, alternatively, using user-supplied "concepts" defined by collections of raw inputs (e.g., feature vectors all from female patients could encode the concept "female"). For tabular data, we present visualization strategies that reveal how anchor directions relate to raw clinical features and to survival time distributions. We then show how these visualization ideas extend to handling raw inputs that are images. Our framework is built on looking at angles between vectors in an embedding space, where there could be "information loss" by ignoring magnitude information. We show how this loss results in a "clumping" artifact that appears in our visualizations, and how to reduce this information loss in practice.
ELiOT : End-to-end Lidar Odometry using Transformer Framework
Jul 31, 2023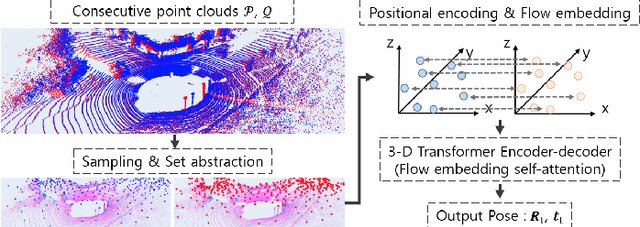
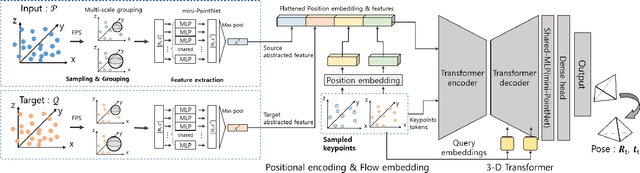
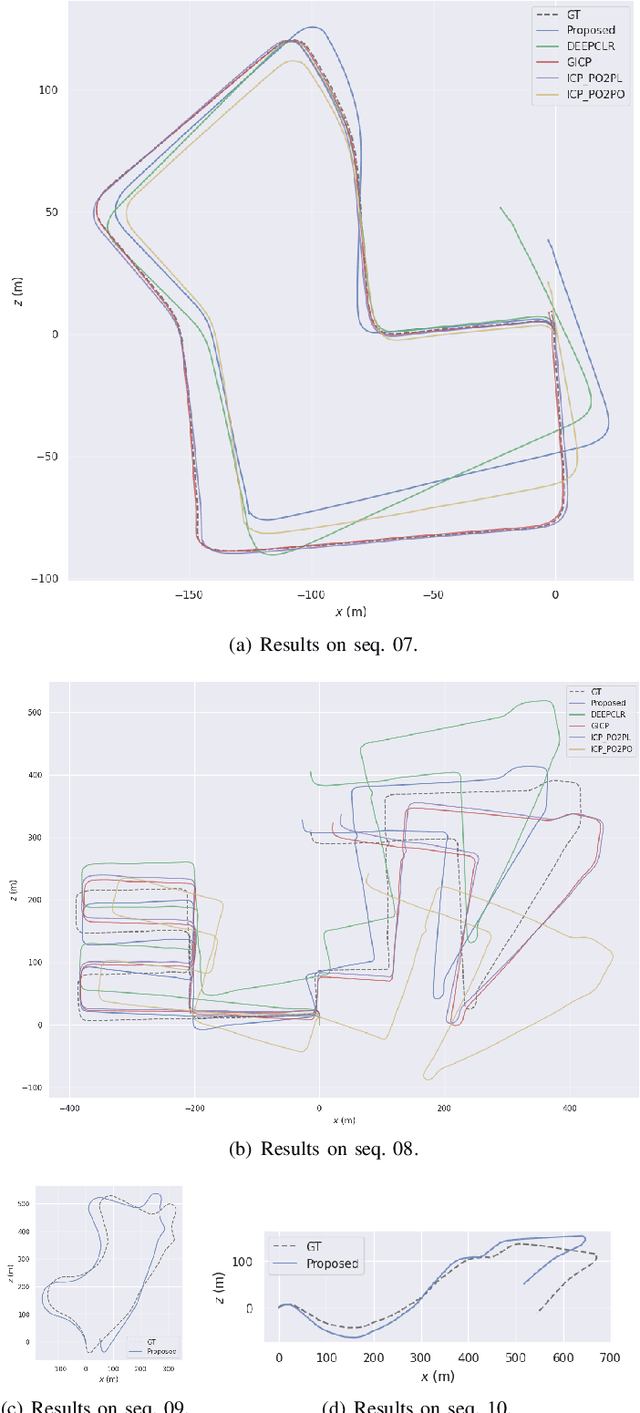
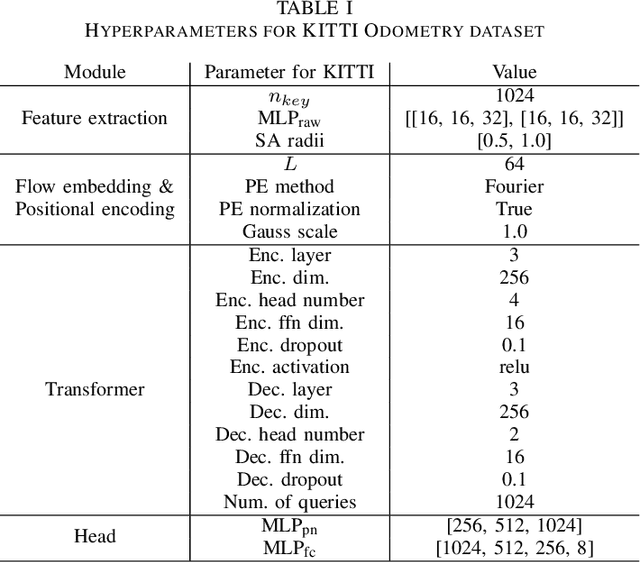
In recent years, deep-learning-based point cloud registration methods have shown significant promise. Furthermore, learning-based 3D detectors have demonstrated their effectiveness in encoding semantic information from LiDAR data. In this paper, we introduce ELiOT, an end-to-end LiDAR odometry framework built on a transformer architecture. Our proposed Self-attention flow embedding network implicitly represents the motion of sequential LiDAR scenes, bypassing the need for 3D-2D projections traditionally used in such tasks. The network pipeline, composed of a 3D transformer encoder-decoder, has shown effectiveness in predicting poses on urban datasets. In terms of translational and rotational errors, our proposed method yields encouraging results, with 7.59% and 2.67% respectively on the KITTI odometry dataset. This is achieved with an end-to-end approach that foregoes the need for conventional geometric concepts.
Improving Semantic Similarity Measure Within a Recommender System Based-on RDF Graphs
Jul 20, 2023In today's era of information explosion, more users are becoming more reliant upon recommender systems to have better advice, suggestions, or inspire them. The measure of the semantic relatedness or likeness between terms, words, or text data plays an important role in different applications dealing with textual data, as in a recommender system. Over the past few years, many ontologies have been developed and used as a form of structured representation of knowledge bases for information systems. The measure of semantic similarity from ontology has developed by several methods. In this paper, we propose and carry on an approach for the improvement of semantic similarity calculations within a recommender system based-on RDF graphs.
Brighten-and-Colorize: A Decoupled Network for Customized Low-Light Image Enhancement
Aug 06, 2023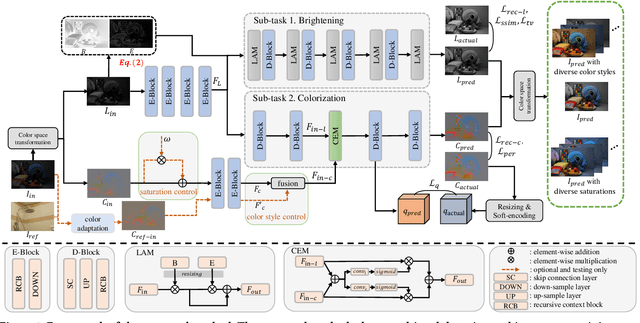

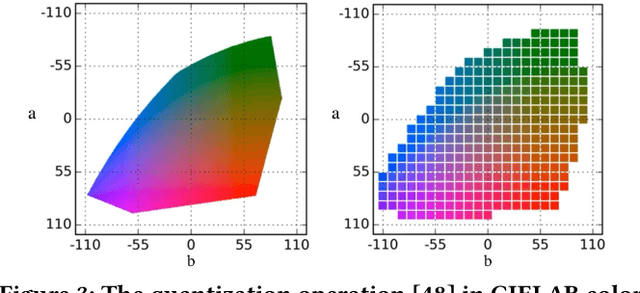
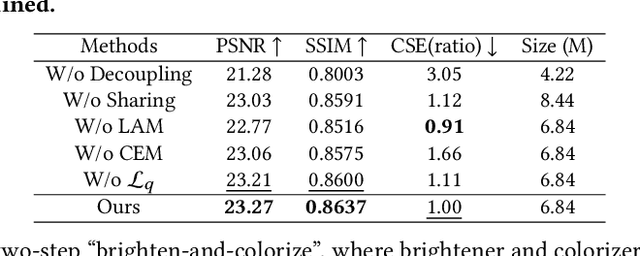
Low-Light Image Enhancement (LLIE) aims to improve the perceptual quality of an image captured in low-light conditions. Generally, a low-light image can be divided into lightness and chrominance components. Recent advances in this area mainly focus on the refinement of the lightness, while ignoring the role of chrominance. It easily leads to chromatic aberration and, to some extent, limits the diverse applications of chrominance in customized LLIE. In this work, a ``brighten-and-colorize'' network (called BCNet), which introduces image colorization to LLIE, is proposed to address the above issues. BCNet can accomplish LLIE with accurate color and simultaneously enables customized enhancement with varying saturations and color styles based on user preferences. Specifically, BCNet regards LLIE as a multi-task learning problem: brightening and colorization. The brightening sub-task aligns with other conventional LLIE methods to get a well-lit lightness. The colorization sub-task is accomplished by regarding the chrominance of the low-light image as color guidance like the user-guide image colorization. Upon completion of model training, the color guidance (i.e., input low-light chrominance) can be simply manipulated by users to acquire customized results. This customized process is optional and, due to its decoupled nature, does not compromise the structural and detailed information of lightness. Extensive experiments on the commonly used LLIE datasets show that the proposed method achieves both State-Of-The-Art (SOTA) performance and user-friendly customization.
Recurrent Spike-based Image Restoration under General Illumination
Aug 06, 2023Spike camera is a new type of bio-inspired vision sensor that records light intensity in the form of a spike array with high temporal resolution (20,000 Hz). This new paradigm of vision sensor offers significant advantages for many vision tasks such as high speed image reconstruction. However, existing spike-based approaches typically assume that the scenes are with sufficient light intensity, which is usually unavailable in many real-world scenarios such as rainy days or dusk scenes. To unlock more spike-based application scenarios, we propose a Recurrent Spike-based Image Restoration (RSIR) network, which is the first work towards restoring clear images from spike arrays under general illumination. Specifically, to accurately describe the noise distribution under different illuminations, we build a physical-based spike noise model according to the sampling process of the spike camera. Based on the noise model, we design our RSIR network which consists of an adaptive spike transformation module, a recurrent temporal feature fusion module, and a frequency-based spike denoising module. Our RSIR can process the spike array in a recursive manner to ensure that the spike temporal information is well utilized. In the training process, we generate the simulated spike data based on our noise model to train our network. Extensive experiments on real-world datasets with different illuminations demonstrate the effectiveness of the proposed network. The code and dataset are released at https://github.com/BIT-Vision/RSIR.
Communication-Free Distributed GNN Training with Vertex Cut
Aug 06, 2023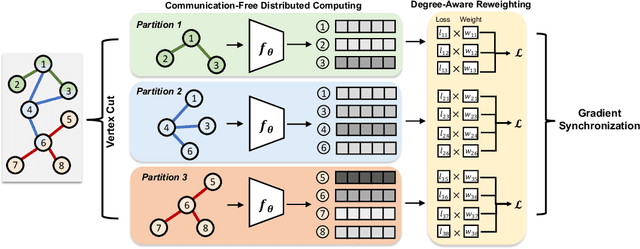
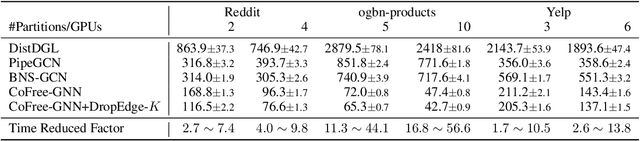
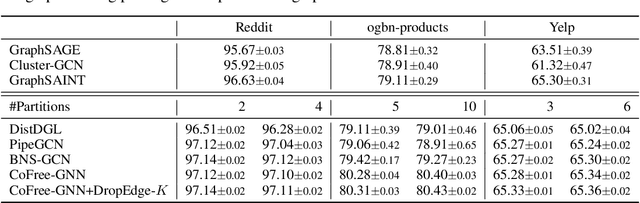

Training Graph Neural Networks (GNNs) on real-world graphs consisting of billions of nodes and edges is quite challenging, primarily due to the substantial memory needed to store the graph and its intermediate node and edge features, and there is a pressing need to speed up the training process. A common approach to achieve speed up is to divide the graph into many smaller subgraphs, which are then distributed across multiple GPUs in one or more machines and processed in parallel. However, existing distributed methods require frequent and substantial cross-GPU communication, leading to significant time overhead and progressively diminishing scalability. Here, we introduce CoFree-GNN, a novel distributed GNN training framework that significantly speeds up the training process by implementing communication-free training. The framework utilizes a Vertex Cut partitioning, i.e., rather than partitioning the graph by cutting the edges between partitions, the Vertex Cut partitions the edges and duplicates the node information to preserve the graph structure. Furthermore, the framework maintains high model accuracy by incorporating a reweighting mechanism to handle a distorted graph distribution that arises from the duplicated nodes. We also propose a modified DropEdge technique to further speed up the training process. Using an extensive set of experiments on real-world networks, we demonstrate that CoFree-GNN speeds up the GNN training process by up to 10 times over the existing state-of-the-art GNN training approaches.
Vision Meets Definitions: Unsupervised Visual Word Sense Disambiguation Incorporating Gloss Information
May 02, 2023
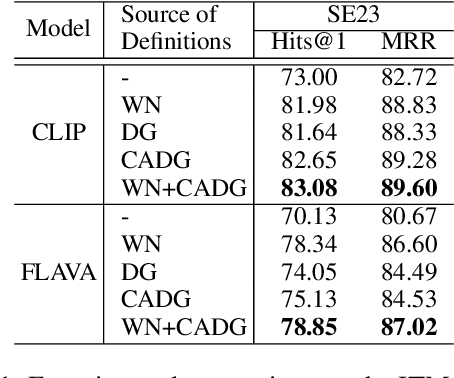
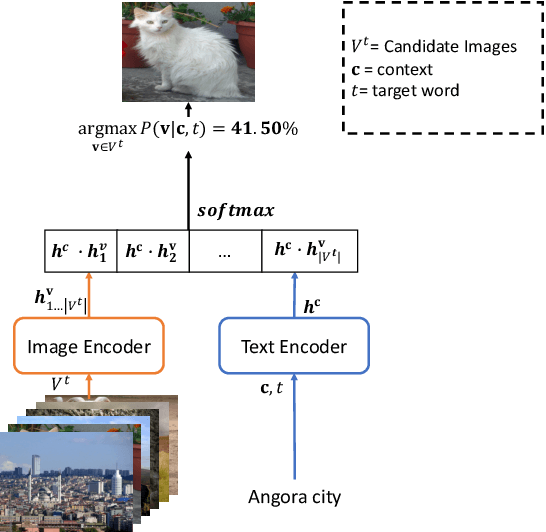
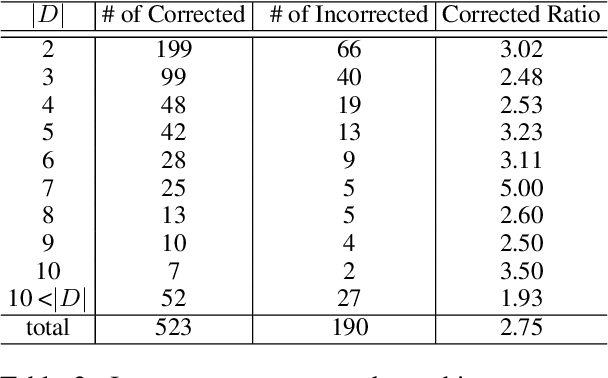
Visual Word Sense Disambiguation (VWSD) is a task to find the image that most accurately depicts the correct sense of the target word for the given context. Previously, image-text matching models often suffered from recognizing polysemous words. This paper introduces an unsupervised VWSD approach that uses gloss information of an external lexical knowledge-base, especially the sense definitions. Specifically, we suggest employing Bayesian inference to incorporate the sense definitions when sense information of the answer is not provided. In addition, to ameliorate the out-of-dictionary (OOD) issue, we propose a context-aware definition generation with GPT-3. Experimental results show that the VWSD performance significantly increased with our Bayesian inference-based approach. In addition, our context-aware definition generation achieved prominent performance improvement in OOD examples exhibiting better performance than the existing definition generation method. We will publish source codes as soon as possible.
Diverse Offline Imitation via Fenchel Duality
Jul 21, 2023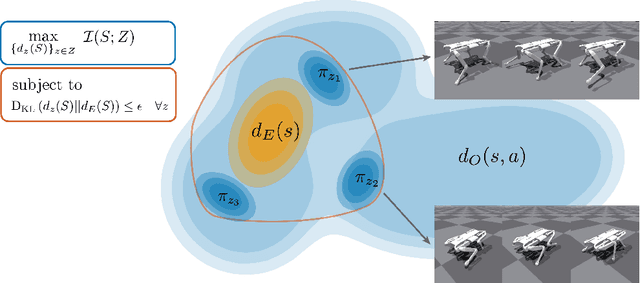

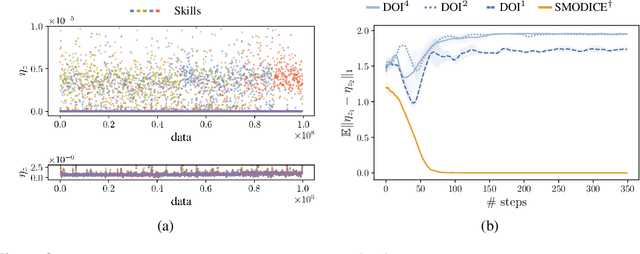
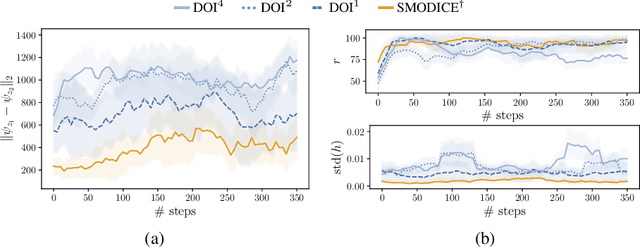
There has been significant recent progress in the area of unsupervised skill discovery, with various works proposing mutual information based objectives, as a source of intrinsic motivation. Prior works predominantly focused on designing algorithms that require online access to the environment. In contrast, we develop an \textit{offline} skill discovery algorithm. Our problem formulation considers the maximization of a mutual information objective constrained by a KL-divergence. More precisely, the constraints ensure that the state occupancy of each skill remains close to the state occupancy of an expert, within the support of an offline dataset with good state-action coverage. Our main contribution is to connect Fenchel duality, reinforcement learning and unsupervised skill discovery, and to give a simple offline algorithm for learning diverse skills that are aligned with an expert.
Iterative Graph Filtering Network for 3D Human Pose Estimation
Aug 07, 2023
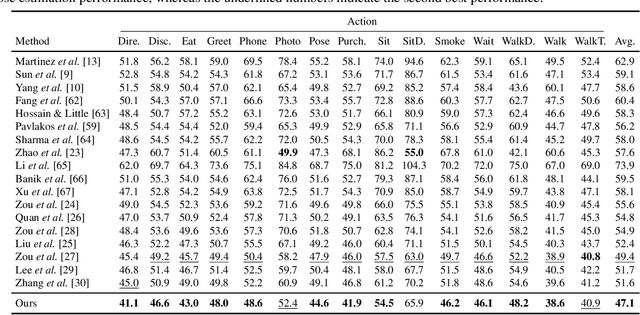

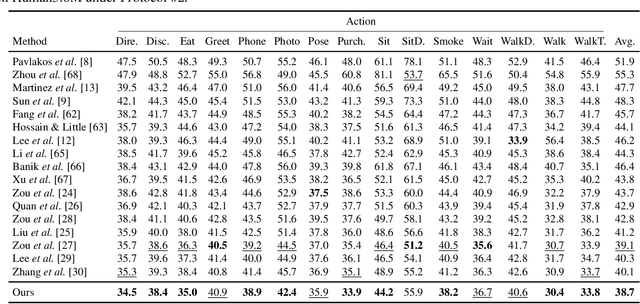
Graph convolutional networks (GCNs) have proven to be an effective approach for 3D human pose estimation. By naturally modeling the skeleton structure of the human body as a graph, GCNs are able to capture the spatial relationships between joints and learn an efficient representation of the underlying pose. However, most GCN-based methods use a shared weight matrix, making it challenging to accurately capture the different and complex relationships between joints. In this paper, we introduce an iterative graph filtering framework for 3D human pose estimation, which aims to predict the 3D joint positions given a set of 2D joint locations in images. Our approach builds upon the idea of iteratively solving graph filtering with Laplacian regularization via the Gauss-Seidel iterative method. Motivated by this iterative solution, we design a Gauss-Seidel network (GS-Net) architecture, which makes use of weight and adjacency modulation, skip connection, and a pure convolutional block with layer normalization. Adjacency modulation facilitates the learning of edges that go beyond the inherent connections of body joints, resulting in an adjusted graph structure that reflects the human skeleton, while skip connections help maintain crucial information from the input layer's initial features as the network depth increases. We evaluate our proposed model on two standard benchmark datasets, and compare it with a comprehensive set of strong baseline methods for 3D human pose estimation. Our experimental results demonstrate that our approach outperforms the baseline methods on both datasets, achieving state-of-the-art performance. Furthermore, we conduct ablation studies to analyze the contributions of different components of our model architecture and show that the skip connection and adjacency modulation help improve the model performance.