 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DANCER: Entity Description Augmented Named Entity Corrector for Automatic Speech Recognition
Mar 28, 2024
End-to-end automatic speech recognition (E2E ASR) systems often suffer from mistranscription of domain-specific phrases, such as named entities, sometimes leading to catastrophic failures in downstream tasks. A family of fast and lightweight named entity correction (NEC) models for ASR have recently been proposed, which normally build on phonetic-level edit distance algorithms and have shown impressive NEC performance. However, as the named entity (NE) list grows, the problems of phonetic confusion in the NE list are exacerbated; for example, homophone ambiguities increase substantially. In view of this, we proposed a novel Description Augmented Named entity CorrEctoR (dubbed DANCER), which leverages entity descriptions to provide additional information to facilitate mitigation of phonetic confusion for NEC on ASR transcription. To this end, an efficient entity description augmented masked language model (EDA-MLM) comprised of a dense retrieval model is introduced, enabling MLM to adapt swiftly to domain-specific entities for the NEC task. A series of experiments conducted on the AISHELL-1 and Homophone datasets confirm the effectiveness of our modeling approach. DANCER outperforms a strong baseline, the phonetic edit-distance-based NEC model (PED-NEC), by a character error rate (CER) reduction of about 7% relatively on AISHELL-1 for named entities. More notably, when tested on Homophone that contain named entities of high phonetic confusion, DANCER offers a more pronounced CER reduction of 46% relatively over PED-NEC for named entities.
Bespoke Large Language Models for Digital Triage Assistance in Mental Health Care
Mar 28, 2024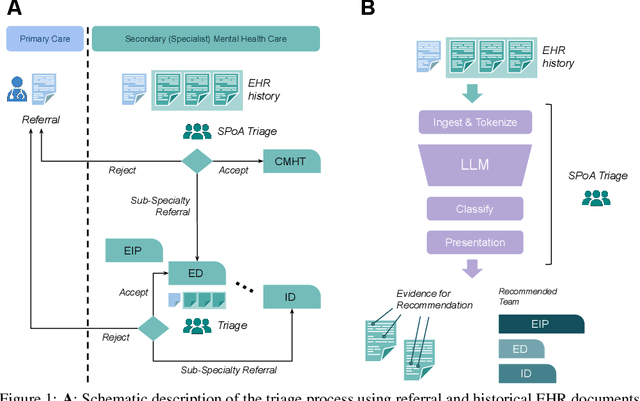

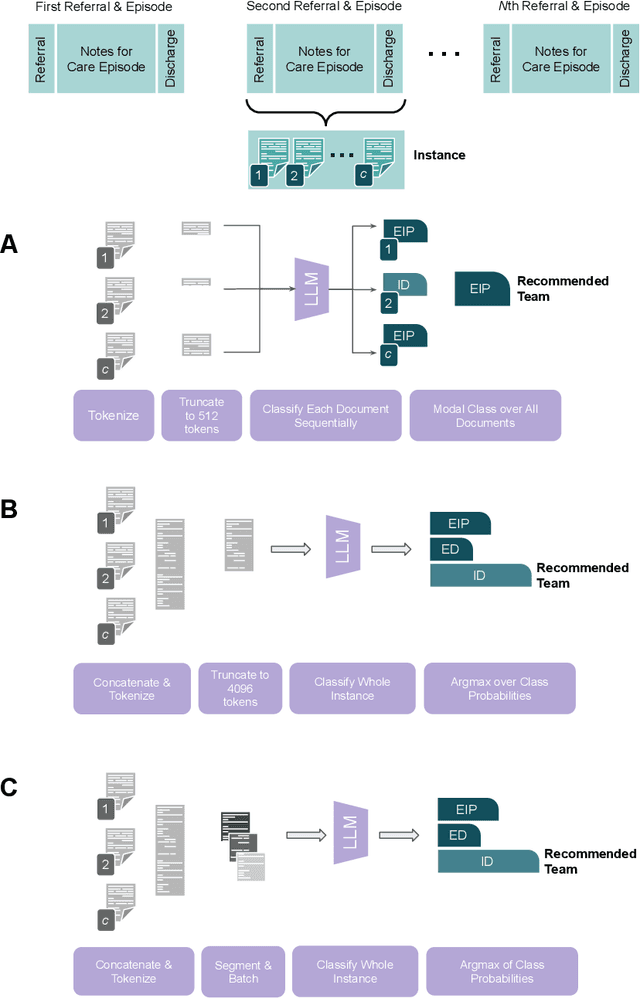

Contemporary large language models (LLMs) may have utility for processing unstructured, narrative free-text clinical data contained in electronic health records (EHRs) -- a particularly important use-case for mental health where a majority of routinely-collected patient data lacks structured, machine-readable content. A significant problem for the the United Kingdom's National Health Service (NHS) are the long waiting lists for specialist mental healthcare. According to NHS data, in each month of 2023, there were between 370,000 and 470,000 individual new referrals into secondary mental healthcare services. Referrals must be triaged by clinicians, using clinical information contained in the patient's EHR to arrive at a decision about the most appropriate mental healthcare team to assess and potentially treat these patients. The ability to efficiently recommend a relevant team by ingesting potentially voluminous clinical notes could help services both reduce referral waiting times and with the right technology, improve the evidence available to justify triage decisions. We present and evaluate three different approaches for LLM-based, end-to-end ingestion of variable-length clinical EHR data to assist clinicians when triaging referrals. Our model is able to deliver triage recommendations consistent with existing clinical practices and it's architecture was implemented on a single GPU, making it practical for implementation in resource-limited NHS environments where private implementations of LLM technology will be necessary to ensure confidential clinical data is appropriately controlled and governed.
Gegenbauer Graph Neural Networks for Time-varying Signal Reconstruction
Mar 28, 2024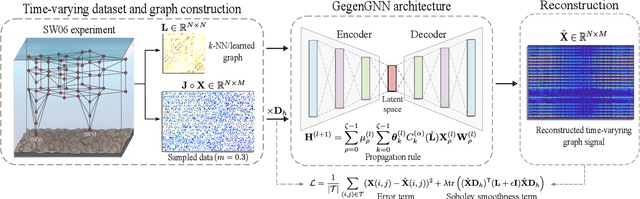
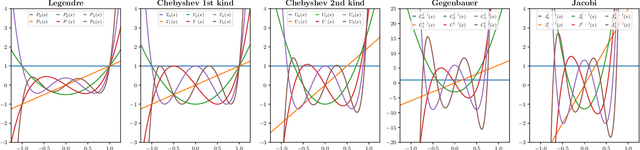
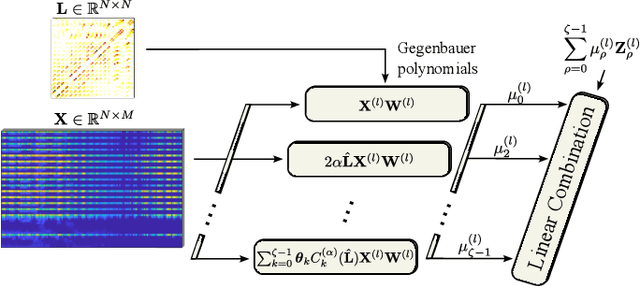
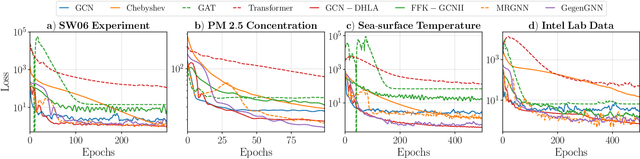
Reconstructing time-varying graph signals (or graph time-series imputation) is a critical problem in machine learning and signal processing with broad applications, ranging from missing data imputation in sensor networks to time-series forecasting. Accurately capturing the spatio-temporal information inherent in these signals is crucial for effectively addressing these tasks. However, existing approaches relying on smoothness assumptions of temporal differences and simple convex optimization techniques have inherent limitations. To address these challenges, we propose a novel approach that incorporates a learning module to enhance the accuracy of the downstream task. To this end, we introduce the Gegenbauer-based graph convolutional (GegenConv) operator, which is a generalization of the conventional Chebyshev graph convolution by leveraging the theory of Gegenbauer polynomials. By deviating from traditional convex problems, we expand the complexity of the model and offer a more accurate solution for recovering time-varying graph signals. Building upon GegenConv, we design the Gegenbauer-based time Graph Neural Network (GegenGNN) architecture, which adopts an encoder-decoder structure. Likewise, our approach also utilizes a dedicated loss function that incorporates a mean squared error component alongside Sobolev smoothness regularization. This combination enables GegenGNN to capture both the fidelity to ground truth and the underlying smoothness properties of the signals, enhancing the reconstruction performance. We conduct extensive experiments on real datasets to evaluate the effectiveness of our proposed approach. The experimental results demonstrate that GegenGNN outperforms state-of-the-art methods, showcasing its superior capability in recovering time-varying graph signals.
Text Data-Centric Image Captioning with Interactive Prompts
Mar 28, 2024Supervised image captioning approaches have made great progress, but it is challenging to collect high-quality human-annotated image-text data. Recently, large-scale vision and language models (e.g., CLIP) and large-scale generative language models (e.g., GPT-2) have shown strong performances in various tasks, which also provide some new solutions for image captioning with web paired data, unpaired data or even text-only data. Among them, the mainstream solution is to project image embeddings into the text embedding space with the assistance of consistent representations between image-text pairs from the CLIP model. However, the current methods still face several challenges in adapting to the diversity of data configurations in a unified solution, accurately estimating image-text embedding bias, and correcting unsatisfactory prediction results in the inference stage. This paper proposes a new Text data-centric approach with Interactive Prompts for image Captioning, named TIPCap. 1) We consider four different settings which gradually reduce the dependence on paired data. 2) We construct a mapping module driven by multivariate Gaussian distribution to mitigate the modality gap, which is applicable to the above four different settings. 3) We propose a prompt interaction module that can incorporate optional prompt information before generating captions. Extensive experiments show that our TIPCap outperforms other weakly or unsupervised image captioning methods and achieves a new state-of-the-art performance on two widely used datasets, i.e., MS-COCO and Flickr30K.
OV-Uni3DETR: Towards Unified Open-Vocabulary 3D Object Detection via Cycle-Modality Propagation
Mar 28, 2024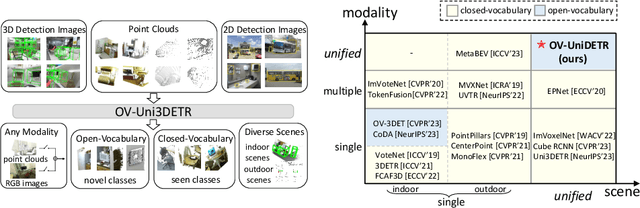
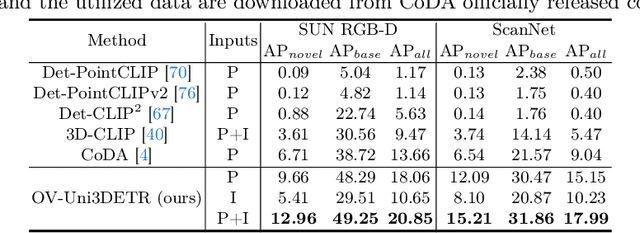
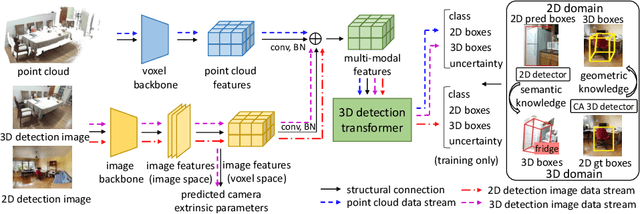
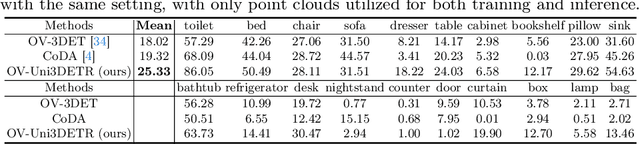
In the current state of 3D object detection research, the severe scarcity of annotated 3D data, substantial disparities across different data modalities, and the absence of a unified architecture, have impeded the progress towards the goal of universality. In this paper, we propose \textbf{OV-Uni3DETR}, a unified open-vocabulary 3D detector via cycle-modality propagation. Compared with existing 3D detectors, OV-Uni3DETR offers distinct advantages: 1) Open-vocabulary 3D detection: During training, it leverages various accessible data, especially extensive 2D detection images, to boost training diversity. During inference, it can detect both seen and unseen classes. 2) Modality unifying: It seamlessly accommodates input data from any given modality, effectively addressing scenarios involving disparate modalities or missing sensor information, thereby supporting test-time modality switching. 3) Scene unifying: It provides a unified multi-modal model architecture for diverse scenes collected by distinct sensors. Specifically, we propose the cycle-modality propagation, aimed at propagating knowledge bridging 2D and 3D modalities, to support the aforementioned functionalities. 2D semantic knowledge from large-vocabulary learning guides novel class discovery in the 3D domain, and 3D geometric knowledge provides localization supervision for 2D detection images. OV-Uni3DETR achieves the state-of-the-art performance on various scenarios, surpassing existing methods by more than 6\% on average. Its performance using only RGB images is on par with or even surpasses that of previous point cloud based methods. Code and pre-trained models will be released later.
Manufacturing Service Capability Prediction with Graph Neural Networks
Mar 25, 2024In the current landscape, the predominant methods for identifying manufacturing capabilities from manufacturers rely heavily on keyword matching and semantic matching. However, these methods often fall short by either overlooking valuable hidden information or misinterpreting critical data. Consequently, such approaches result in an incomplete identification of manufacturers' capabilities. This underscores the pressing need for data-driven solutions to enhance the accuracy and completeness of manufacturing capability identification. To address the need, this study proposes a Graph Neural Network-based method for manufacturing service capability identification over a knowledge graph. To enhance the identification performance, this work introduces a novel approach that involves aggregating information from the graph nodes' neighborhoods as well as oversampling the graph data, which can be effectively applied across a wide range of practical scenarios. Evaluations conducted on a Manufacturing Service Knowledge Graph and subsequent ablation studies demonstrate the efficacy and robustness of the proposed approach. This study not only contributes a innovative method for inferring manufacturing service capabilities but also significantly augments the quality of Manufacturing Service Knowledge Graphs.
Multiple-Source Localization from a Single-Snapshot Observation Using Graph Bayesian Optimization
Mar 25, 2024Due to the significance of its various applications, source localization has garnered considerable attention as one of the most important means to confront diffusion hazards. Multi-source localization from a single-snapshot observation is especially relevant due to its prevalence. However, the inherent complexities of this problem, such as limited information, interactions among sources, and dependence on diffusion models, pose challenges to resolution. Current methods typically utilize heuristics and greedy selection, and they are usually bonded with one diffusion model. Consequently, their effectiveness is constrained. To address these limitations, we propose a simulation-based method termed BOSouL. Bayesian optimization (BO) is adopted to approximate the results for its sample efficiency. A surrogate function models uncertainty from the limited information. It takes sets of nodes as the input instead of individual nodes. BOSouL can incorporate any diffusion model in the data acquisition process through simulations. Empirical studies demonstrate that its performance is robust across graph structures and diffusion models. The code is available at https://github.com/XGraph-Team/BOSouL.
Text-IF: Leveraging Semantic Text Guidance for Degradation-Aware and Interactive Image Fusion
Mar 25, 2024Image fusion aims to combine information from different source images to create a comprehensively representative image. Existing fusion methods are typically helpless in dealing with degradations in low-quality source images and non-interactive to multiple subjective and objective needs. To solve them, we introduce a novel approach that leverages semantic text guidance image fusion model for degradation-aware and interactive image fusion task, termed as Text-IF. It innovatively extends the classical image fusion to the text guided image fusion along with the ability to harmoniously address the degradation and interaction issues during fusion. Through the text semantic encoder and semantic interaction fusion decoder, Text-IF is accessible to the all-in-one infrared and visible image degradation-aware processing and the interactive flexible fusion outcomes. In this way, Text-IF achieves not only multi-modal image fusion, but also multi-modal information fusion. Extensive experiments prove that our proposed text guided image fusion strategy has obvious advantages over SOTA methods in the image fusion performance and degradation treatment. The code is available at https://github.com/XunpengYi/Text-IF.
Learning Action-based Representations Using Invariance
Mar 25, 2024Robust reinforcement learning agents using high-dimensional observations must be able to identify relevant state features amidst many exogeneous distractors. A representation that captures controllability identifies these state elements by determining what affects agent control. While methods such as inverse dynamics and mutual information capture controllability for a limited number of timesteps, capturing long-horizon elements remains a challenging problem. Myopic controllability can capture the moment right before an agent crashes into a wall, but not the control-relevance of the wall while the agent is still some distance away. To address this we introduce action-bisimulation encoding, a method inspired by the bisimulation invariance pseudometric, that extends single-step controllability with a recursive invariance constraint. By doing this, action-bisimulation learns a multi-step controllability metric that smoothly discounts distant state features that are relevant for control. We demonstrate that action-bisimulation pretraining on reward-free, uniformly random data improves sample efficiency in several environments, including a photorealistic 3D simulation domain, Habitat. Additionally, we provide theoretical analysis and qualitative results demonstrating the information captured by action-bisimulation.
CRS-Diff: Controllable Generative Remote Sensing Foundation Model
Mar 25, 2024
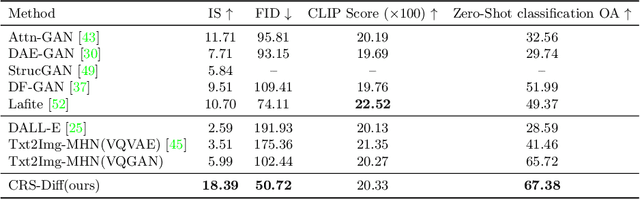
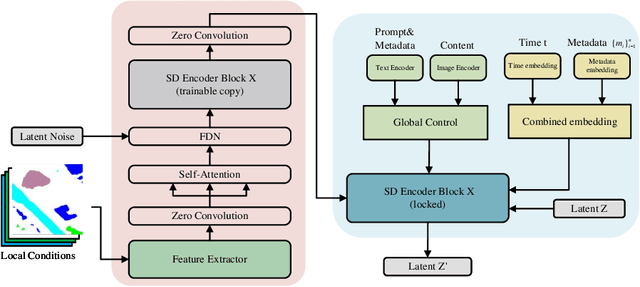
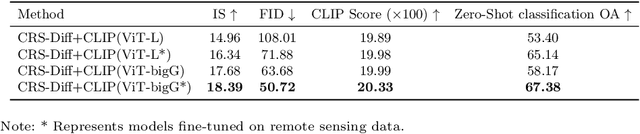
The emergence of diffusion models has revolutionized the field of image generation, providing new methods for creating high-quality, high-resolution images across various applications. However, the potential of these models for generating domain-specific images, particularly remote sensing (RS) images, remains largely untapped. RS images that are notable for their high resolution, extensive coverage, and rich information content, bring new challenges that general diffusion models may not adequately address. This paper proposes CRS-Diff, a pioneering diffusion modeling framework specifically tailored for generating remote sensing imagery, leveraging the inherent advantages of diffusion models while integrating advanced control mechanisms to ensure that the imagery is not only visually clear but also enriched with geographic and temporal information. The model integrates global and local control inputs, enabling precise combinations of generation conditions to refine the generation process. A comprehensive evaluation of CRS-Diff has demonstrated its superior capability to generate RS imagery both in a single condition and multiple conditions compared with previous methods in terms of image quality and diversity.