 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
KITLM: Domain-Specific Knowledge InTegration into Language Models for Question Answering
Aug 07, 2023
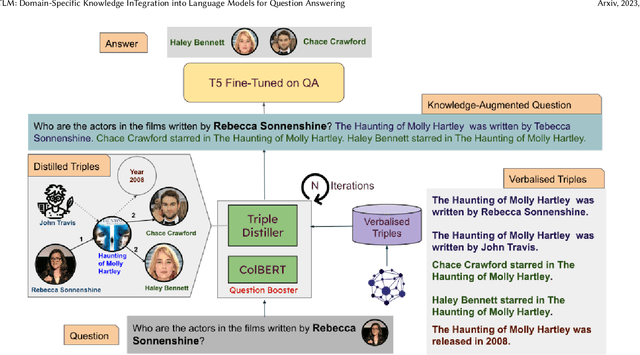



Large language models (LLMs) have demonstrated remarkable performance in a wide range of natural language tasks. However, as these models continue to grow in size, they face significant challenges in terms of computational costs. Additionally, LLMs often lack efficient domain-specific understanding, which is particularly crucial in specialized fields such as aviation and healthcare. To boost the domain-specific understanding, we propose, KITLM, a novel knowledge base integration approach into language model through relevant information infusion. By integrating pertinent knowledge, not only the performance of the language model is greatly enhanced, but the model size requirement is also significantly reduced while achieving comparable performance. Our proposed knowledge-infused model surpasses the performance of both GPT-3.5-turbo and the state-of-the-art knowledge infusion method, SKILL, achieving over 1.5 times improvement in exact match scores on the MetaQA. KITLM showed a similar performance boost in the aviation domain with AeroQA. The drastic performance improvement of KITLM over the existing methods can be attributed to the infusion of relevant knowledge while mitigating noise. In addition, we release two curated datasets to accelerate knowledge infusion research in specialized fields: a) AeroQA, a new benchmark dataset designed for multi-hop question-answering within the aviation domain, and b) Aviation Corpus, a dataset constructed from unstructured text extracted from the National Transportation Safety Board reports. Our research contributes to advancing the field of domain-specific language understanding and showcases the potential of knowledge infusion techniques in improving the performance of language models on question-answering.
ROFusion: Efficient Object Detection using Hybrid Point-wise Radar-Optical Fusion
Jul 17, 2023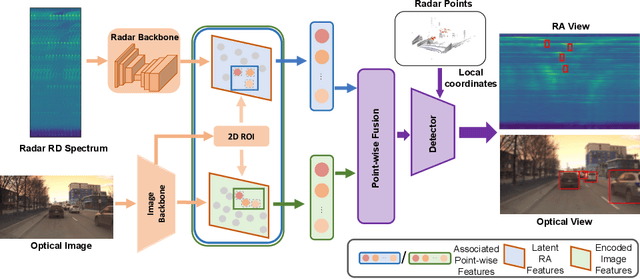
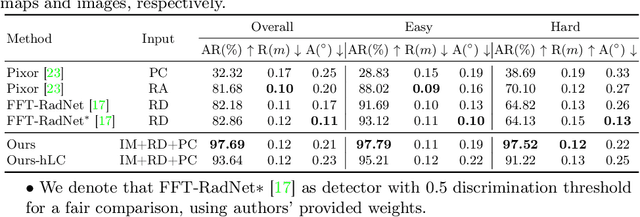
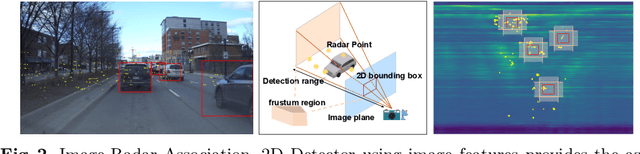
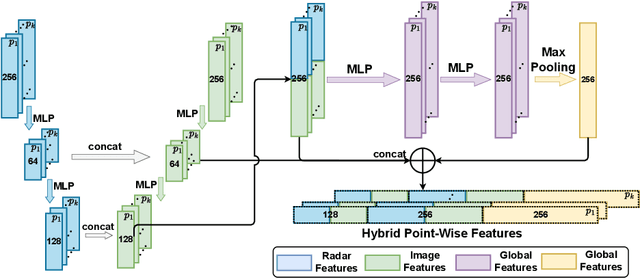
Radars, due to their robustness to adverse weather conditions and ability to measure object motions, have served in autonomous driving and intelligent agents for years. However, Radar-based perception suffers from its unintuitive sensing data, which lack of semantic and structural information of scenes. To tackle this problem, camera and Radar sensor fusion has been investigated as a trending strategy with low cost, high reliability and strong maintenance. While most recent works explore how to explore Radar point clouds and images, rich contextual information within Radar observation are discarded. In this paper, we propose a hybrid point-wise Radar-Optical fusion approach for object detection in autonomous driving scenarios. The framework benefits from dense contextual information from both the range-doppler spectrum and images which are integrated to learn a multi-modal feature representation. Furthermore, we propose a novel local coordinate formulation, tackling the object detection task in an object-centric coordinate. Extensive results show that with the information gained from optical images, we could achieve leading performance in object detection (97.69\% recall) compared to recent state-of-the-art methods FFT-RadNet (82.86\% recall). Ablation studies verify the key design choices and practicability of our approach given machine generated imperfect detections. The code will be available at https://github.com/LiuLiu-55/ROFusion.
Transferability of Graph Neural Networks using Graphon and Sampling Theories
Jul 25, 2023Graph neural networks (GNNs) have become powerful tools for processing graph-based information in various domains. A desirable property of GNNs is transferability, where a trained network can swap in information from a different graph without retraining and retain its accuracy. A recent method of capturing transferability of GNNs is through the use of graphons, which are symmetric, measurable functions representing the limit of large dense graphs. In this work, we contribute to the application of graphons to GNNs by presenting an explicit two-layer graphon neural network (WNN) architecture. We prove its ability to approximate bandlimited signals within a specified error tolerance using a minimal number of network weights. We then leverage this result, to establish the transferability of an explicit two-layer GNN over all sufficiently large graphs in a sequence converging to a graphon. Our work addresses transferability between both deterministic weighted graphs and simple random graphs and overcomes issues related to the curse of dimensionality that arise in other GNN results. The proposed WNN and GNN architectures offer practical solutions for handling graph data of varying sizes while maintaining performance guarantees without extensive retraining.
FDCT: Fast Depth Completion for Transparent Objects
Jul 25, 2023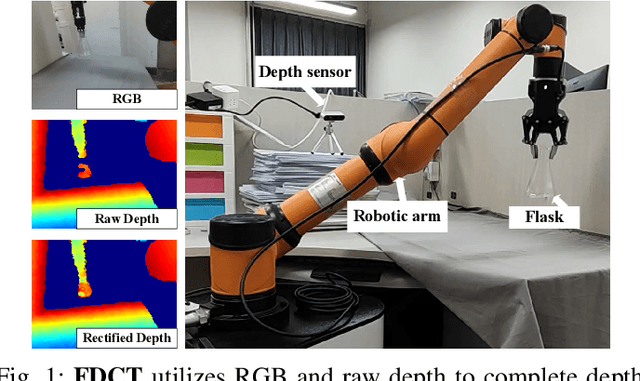
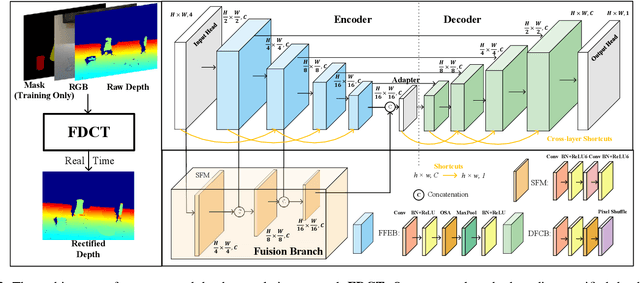
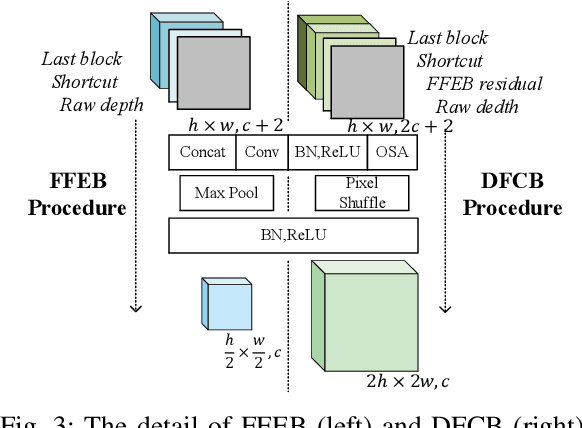
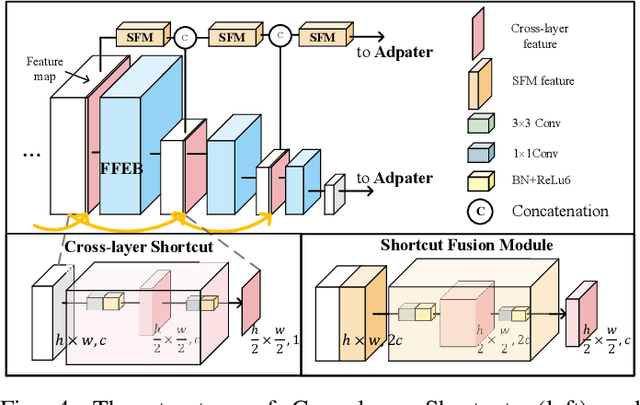
Depth completion is crucial for many robotic tasks such as autonomous driving, 3-D reconstruction, and manipulation. Despite the significant progress, existing methods remain computationally intensive and often fail to meet the real-time requirements of low-power robotic platforms. Additionally, most methods are designed for opaque objects and struggle with transparent objects due to the special properties of reflection and refraction. To address these challenges, we propose a Fast Depth Completion framework for Transparent objects (FDCT), which also benefits downstream tasks like object pose estimation. To leverage local information and avoid overfitting issues when integrating it with global information, we design a new fusion branch and shortcuts to exploit low-level features and a loss function to suppress overfitting. This results in an accurate and user-friendly depth rectification framework which can recover dense depth estimation from RGB-D images alone. Extensive experiments demonstrate that FDCT can run about 70 FPS with a higher accuracy than the state-of-the-art methods. We also demonstrate that FDCT can improve pose estimation in object grasping tasks. The source code is available at https://github.com/Nonmy/FDCT
* 9pages,7figures
DeepMem: ML Models as storage channels and their (mis-)applications
Jul 24, 2023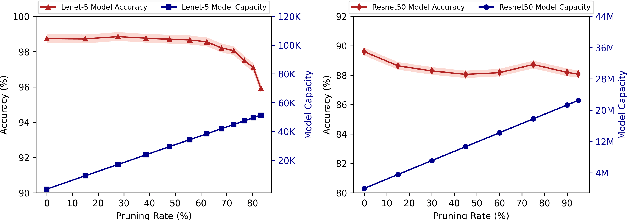
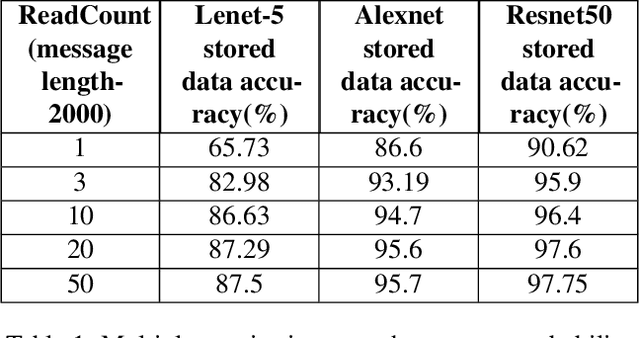
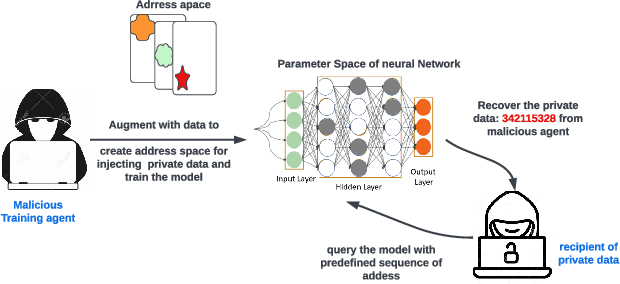
Machine learning (ML) models are overparameterized to support generality and avoid overfitting. Prior works have shown that these additional parameters can be used for both malicious (e.g., hiding a model covertly within a trained model) and beneficial purposes (e.g., watermarking a model). In this paper, we propose a novel information theoretic perspective of the problem; we consider the ML model as a storage channel with a capacity that increases with overparameterization. Specifically, we consider a sender that embeds arbitrary information in the model at training time, which can be extracted by a receiver with a black-box access to the deployed model. We derive an upper bound on the capacity of the channel based on the number of available parameters. We then explore black-box write and read primitives that allow the attacker to: (i) store data in an optimized way within the model by augmenting the training data at the transmitter side, and (ii) to read it by querying the model after it is deployed. We also analyze the detectability of the writing primitive and consider a new version of the problem which takes information storage covertness into account. Specifically, to obtain storage covertness, we introduce a new constraint such that the data augmentation used for the write primitives minimizes the distribution shift with the initial (baseline task) distribution. This constraint introduces a level of "interference" with the initial task, thereby limiting the channel's effective capacity. Therefore, we develop optimizations to improve the capacity in this case, including a novel ML-specific substitution based error correction protocol. We believe that the proposed modeling of the problem offers new tools to better understand and mitigate potential vulnerabilities of ML, especially in the context of increasingly large models.
Discreetly Exploiting Inter-session Information for Session-based Recommendation
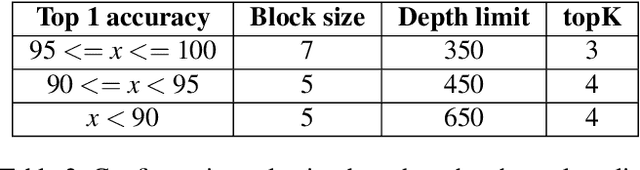
Apr 18, 2023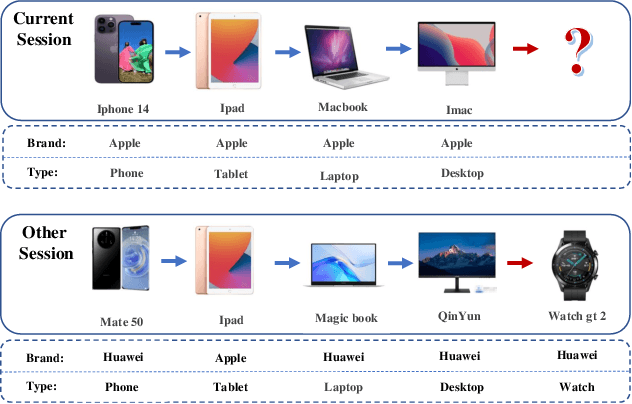
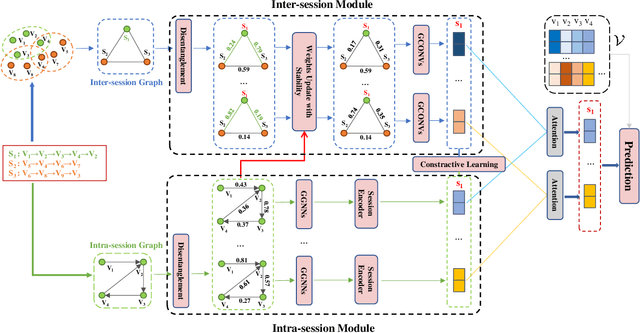
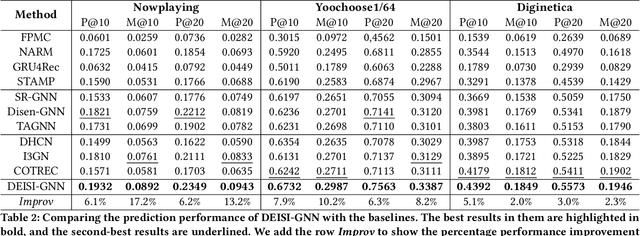
Limited intra-session information is the performance bottleneck of the early GNN based SBR models. Therefore, some GNN based SBR models have evolved to introduce additional inter-session information to facilitate the next-item prediction. However, we found that the introduction of inter-session information may bring interference to these models. The possible reasons are twofold. First, inter-session dependencies are not differentiated at the factor-level. Second, measuring inter-session weight by similarity is not enough. In this paper, we propose DEISI to solve the problems. For the first problem, DEISI differentiates the types of inter-session dependencies at the factor-level with the help of DRL technology. For the second problem, DEISI introduces stability as a new metric for weighting inter-session dependencies together with the similarity. Moreover, CL is used to improve the robustness of the model. Extensive experiments on three datasets show the superior performance of the DEISI model compared with the state-of-the-art models.
H2TNE: Temporal Heterogeneous Information Network Embedding in Hyperbolic Spaces
Apr 18, 2023Temporal heterogeneous information network (temporal HIN) embedding, aiming to represent various types of nodes of different timestamps into low dimensional spaces while preserving structural and semantic information, is of vital importance in diverse real-life tasks. Researchers have made great efforts on temporal HIN embedding in Euclidean spaces and got some considerable achievements. However, there is always a fundamental conflict that many real-world networks show hierarchical property and power-law distribution, and are not isometric of Euclidean spaces. Recently, representation learning in hyperbolic spaces has been proved to be valid for data with hierarchical and power-law structure. Inspired by this character, we propose a hyperbolic heterogeneous temporal network embedding (H2TNE) model for temporal HINs. Specifically, we leverage a temporally and heterogeneously double-constrained random walk strategy to capture the structural and semantic information, and then calculate the embedding by exploiting hyperbolic distance in proximity measurement. Experimental results show that our method has superior performance on temporal link prediction and node classification compared with SOTA models.
EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge: Mixed Sequences Prediction
Jul 24, 2023
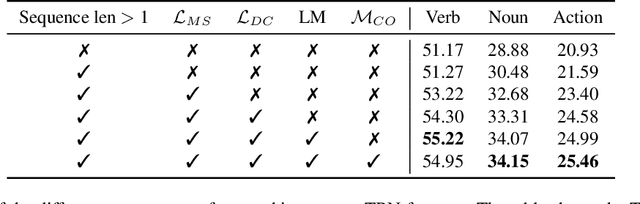
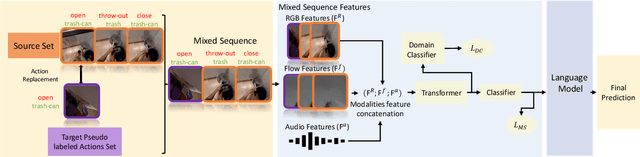
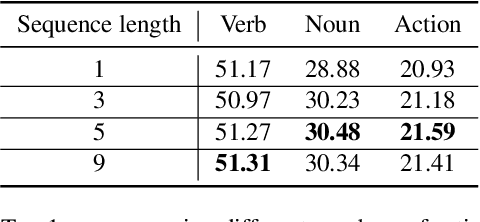
This report presents the technical details of our approach for the EPIC-Kitchens-100 Unsupervised Domain Adaptation (UDA) Challenge in Action Recognition. Our approach is based on the idea that the order in which actions are performed is similar between the source and target domains. Based on this, we generate a modified sequence by randomly combining actions from the source and target domains. As only unlabelled target data are available under the UDA setting, we use a standard pseudo-labeling strategy for extracting action labels for the target. We then ask the network to predict the resulting action sequence. This allows to integrate information from both domains during training and to achieve better transfer results on target. Additionally, to better incorporate sequence information, we use a language model to filter unlikely sequences. Lastly, we employed a co-occurrence matrix to eliminate unseen combinations of verbs and nouns. Our submission, labeled as 'sshayan', can be found on the leaderboard, where it currently holds the 2nd position for 'verb' and the 4th position for both 'noun' and 'action'.
SafeSteps: Learning Safer Footstep Planning Policies for Legged Robots via Model-Based Priors
Jul 24, 2023We present a footstep planning policy for quadrupedal locomotion that is able to directly take into consideration a-priori safety information in its decisions. At its core, a learning process analyzes terrain patches, classifying each landing location by its kinematic feasibility, shin collision, and terrain roughness. This information is then encoded into a small vector representation and passed as an additional state to the footstep planning policy, which furthermore proposes only safe footstep location by applying a masked variant of the Proximal Policy Optimization (PPO) algorithm. The performance of the proposed approach is shown by comparative simulations on an electric quadruped robot walking in different rough terrain scenarios. We show that violations of the above safety conditions are greatly reduced both during training and the successive deployment of the policy, resulting in an inherently safer footstep planner. Furthermore, we show how, as a byproduct, fewer reward terms are needed to shape the behavior of the policy, which in return is able to achieve both better final performances and sample efficiency
ELiOT : End-to-end Lidar Odometry using Transformer Framework
Jul 31, 2023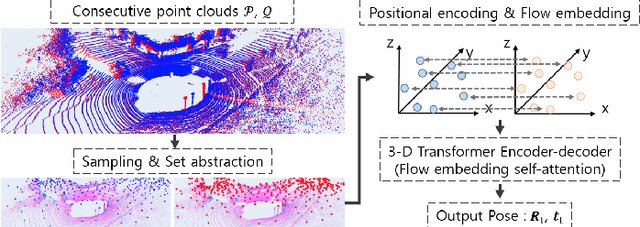
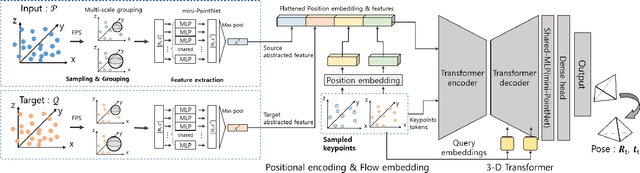
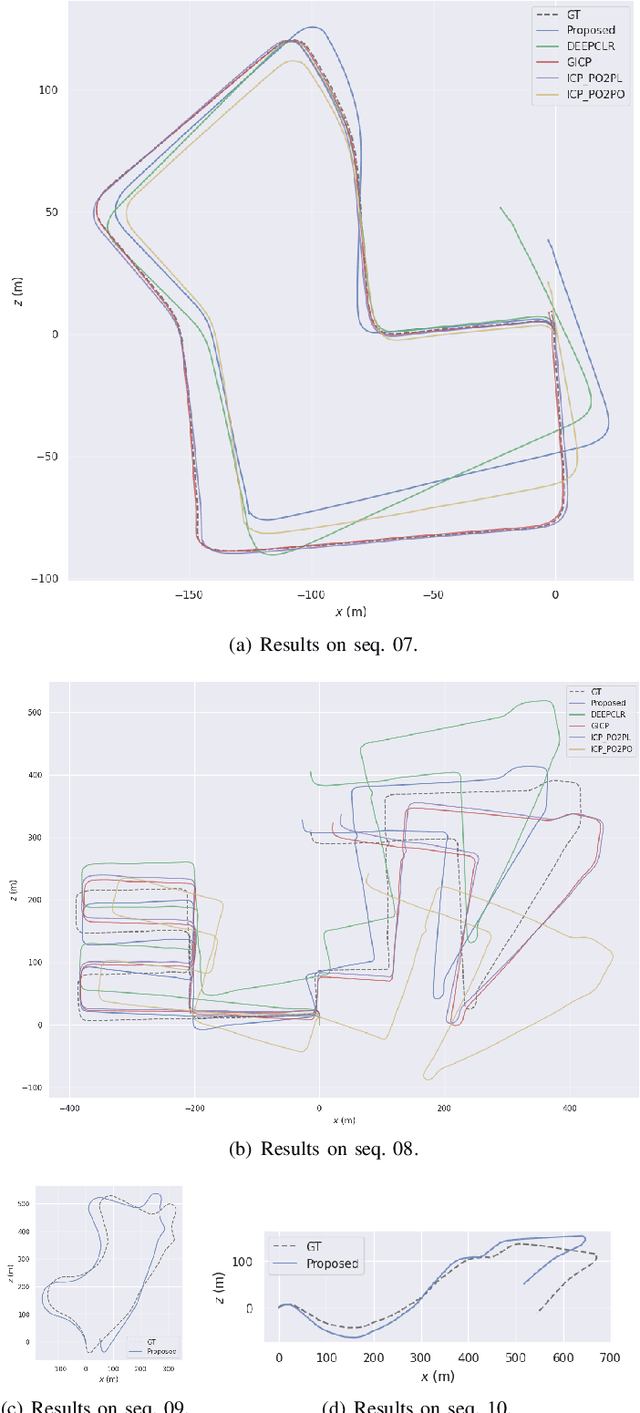
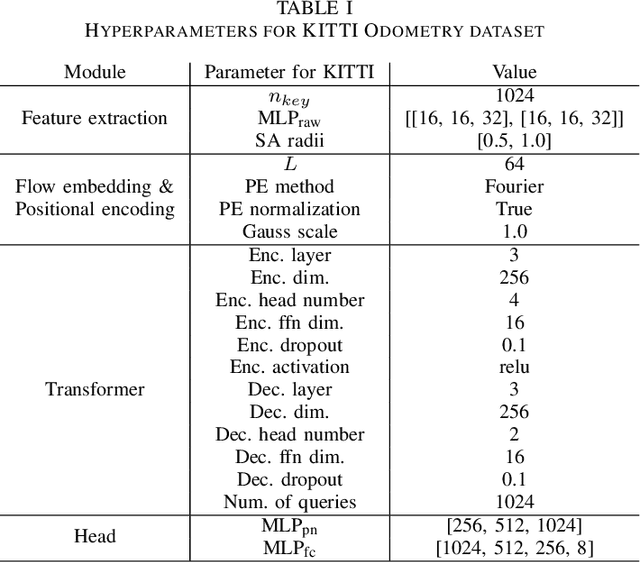
In recent years, deep-learning-based point cloud registration methods have shown significant promise. Furthermore, learning-based 3D detectors have demonstrated their effectiveness in encoding semantic information from LiDAR data. In this paper, we introduce ELiOT, an end-to-end LiDAR odometry framework built on a transformer architecture. Our proposed Self-attention flow embedding network implicitly represents the motion of sequential LiDAR scenes, bypassing the need for 3D-2D projections traditionally used in such tasks. The network pipeline, composed of a 3D transformer encoder-decoder, has shown effectiveness in predicting poses on urban datasets. In terms of translational and rotational errors, our proposed method yields encouraging results, with 7.59% and 2.67% respectively on the KITTI odometry dataset. This is achieved with an end-to-end approach that foregoes the need for conventional geometric concepts.