 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Where's the Liability in Harmful AI Speech?
Aug 09, 2023
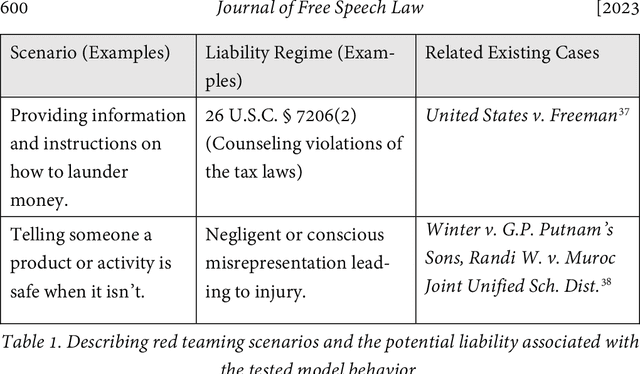


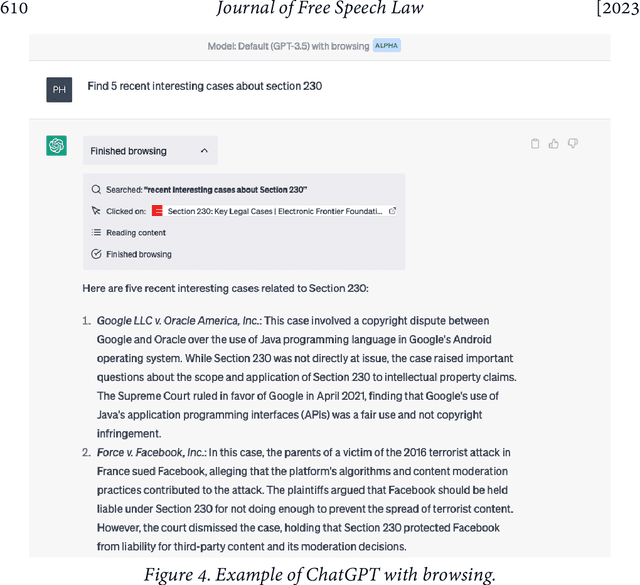
Generative AI, in particular text-based "foundation models" (large models trained on a huge variety of information including the internet), can generate speech that could be problematic under a wide range of liability regimes. Machine learning practitioners regularly "red team" models to identify and mitigate such problematic speech: from "hallucinations" falsely accusing people of serious misconduct to recipes for constructing an atomic bomb. A key question is whether these red-teamed behaviors actually present any liability risk for model creators and deployers under U.S. law, incentivizing investments in safety mechanisms. We examine three liability regimes, tying them to common examples of red-teamed model behaviors: defamation, speech integral to criminal conduct, and wrongful death. We find that any Section 230 immunity analysis or downstream liability analysis is intimately wrapped up in the technical details of algorithm design. And there are many roadblocks to truly finding models (and their associated parties) liable for generated speech. We argue that AI should not be categorically immune from liability in these scenarios and that as courts grapple with the already fine-grained complexities of platform algorithms, the technical details of generative AI loom above with thornier questions. Courts and policymakers should think carefully about what technical design incentives they create as they evaluate these issues.
Spatial Gated Multi-Layer Perceptron for Land Use and Land Cover Mapping
Aug 09, 2023
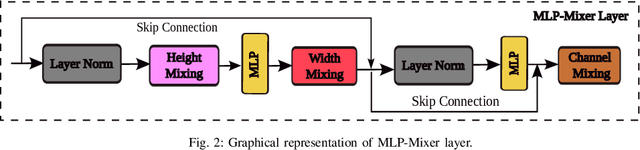

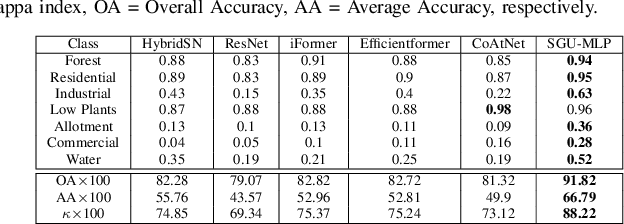
Convolutional Neural Networks (CNNs) are models that are utilized extensively for the hierarchical extraction of features. Vision transformers (ViTs), through the use of a self-attention mechanism, have recently achieved superior modeling of global contextual information compared to CNNs. However, to realize their image classification strength, ViTs require substantial training datasets. Where the available training data are limited, current advanced multi-layer perceptrons (MLPs) can provide viable alternatives to both deep CNNs and ViTs. In this paper, we developed the SGU-MLP, a learning algorithm that effectively uses both MLPs and spatial gating units (SGUs) for precise land use land cover (LULC) mapping. Results illustrated the superiority of the developed SGU-MLP classification algorithm over several CNN and CNN-ViT-based models, including HybridSN, ResNet, iFormer, EfficientFormer and CoAtNet. The proposed SGU-MLP algorithm was tested through three experiments in Houston, USA, Berlin, Germany and Augsburg, Germany. The SGU-MLP classification model was found to consistently outperform the benchmark CNN and CNN-ViT-based algorithms. For example, for the Houston experiment, SGU-MLP significantly outperformed HybridSN, CoAtNet, Efficientformer, iFormer and ResNet by approximately 15%, 19%, 20%, 21%, and 25%, respectively, in terms of average accuracy. The code will be made publicly available at https://github.com/aj1365/SGUMLP
Sudowoodo: a Chinese Lyric Imitation System with Source Lyrics
Aug 09, 2023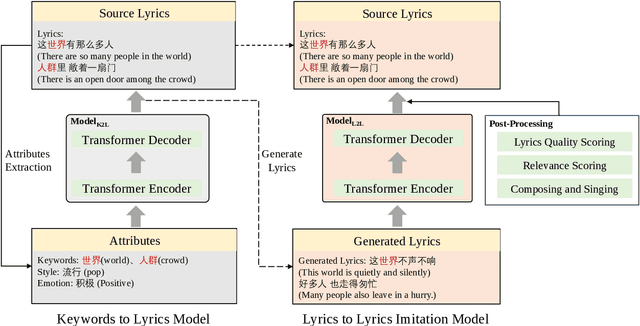

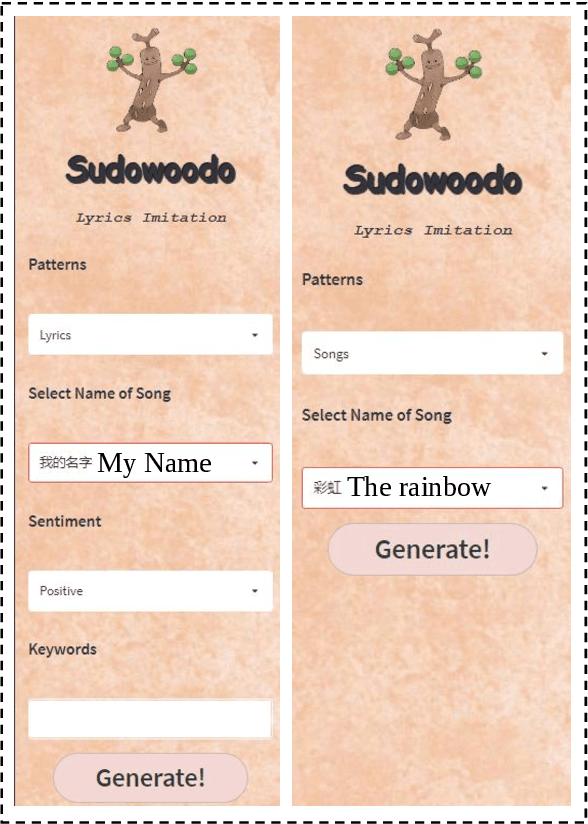

Lyrics generation is a well-known application in natural language generation research, with several previous studies focusing on generating accurate lyrics using precise control such as keywords, rhymes, etc. However, lyrics imitation, which involves writing new lyrics by imitating the style and content of the source lyrics, remains a challenging task due to the lack of a parallel corpus. In this paper, we introduce \textbf{\textit{Sudowoodo}}, a Chinese lyrics imitation system that can generate new lyrics based on the text of source lyrics. To address the issue of lacking a parallel training corpus for lyrics imitation, we propose a novel framework to construct a parallel corpus based on a keyword-based lyrics model from source lyrics. Then the pairs \textit{(new lyrics, source lyrics)} are used to train the lyrics imitation model. During the inference process, we utilize a post-processing module to filter and rank the generated lyrics, selecting the highest-quality ones. We incorporated audio information and aligned the lyrics with the audio to form the songs as a bonus. The human evaluation results show that our framework can perform better lyric imitation. Meanwhile, the \textit{Sudowoodo} system and demo video of the system is available at \href{https://Sudowoodo.apps-hp.danlu.netease.com/}{Sudowoodo} and \href{https://youtu.be/u5BBT_j1L5M}{https://youtu.be/u5BBT\_j1L5M}.
Invalid Logic, Equivalent Gains: The Bizarreness of Reasoning in Language Model Prompting
Jul 23, 2023
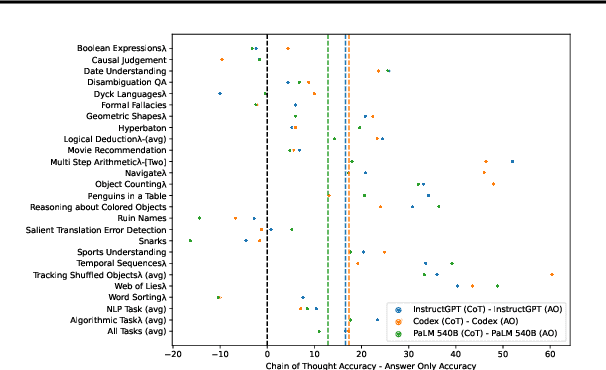
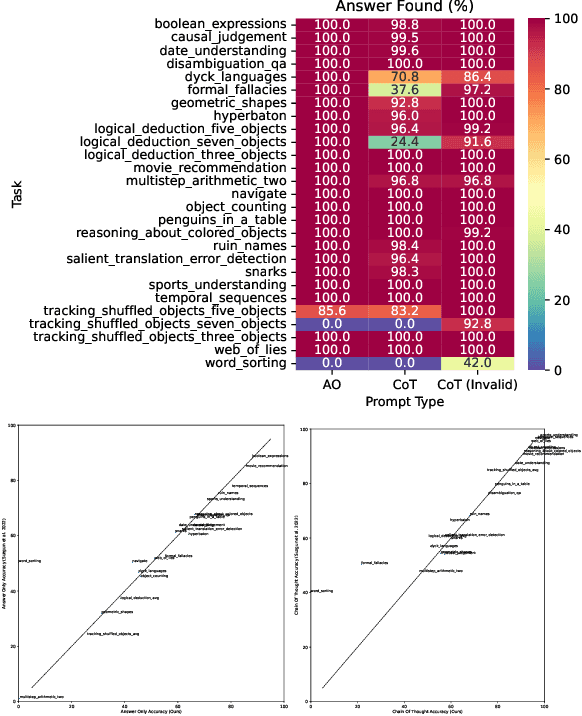
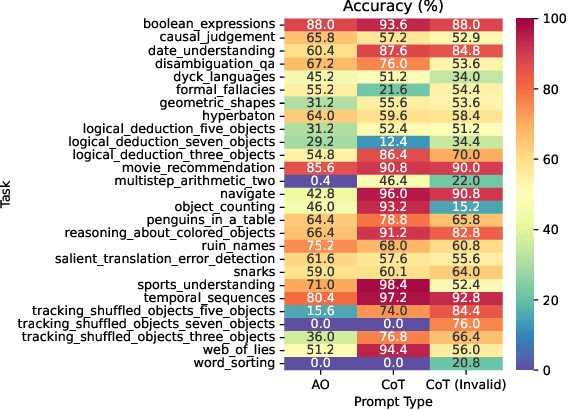
Language models can be prompted to reason through problems in a manner that significantly improves performance. However, \textit{why} such prompting improves performance is unclear. Recent work showed that using logically \textit{invalid} Chain-of-Thought (CoT) prompting improves performance almost as much as logically \textit{valid} CoT prompting, and that editing CoT prompts to replace problem-specific information with abstract information or out-of-distribution information typically doesn't harm performance. Critics have responded that these findings are based on too few and too easily solved tasks to draw meaningful conclusions. To resolve this dispute, we test whether logically invalid CoT prompts offer the same level of performance gains as logically valid prompts on the hardest tasks in the BIG-Bench benchmark, termed BIG-Bench Hard (BBH). We find that the logically \textit{invalid} reasoning prompts do indeed achieve similar performance gains on BBH tasks as logically valid reasoning prompts. We also discover that some CoT prompts used by previous works contain logical errors. This suggests that covariates beyond logically valid reasoning are responsible for performance improvements.
Leveraging Semantic Information for Efficient Self-Supervised Emotion Recognition with Audio-Textual Distilled Models
May 30, 2023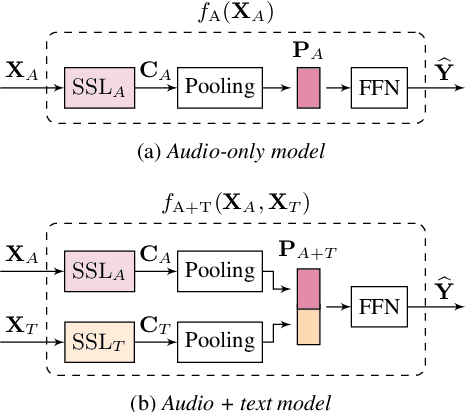
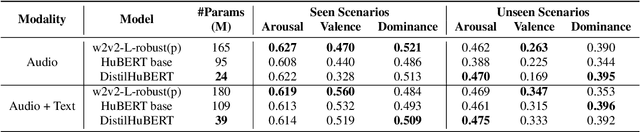
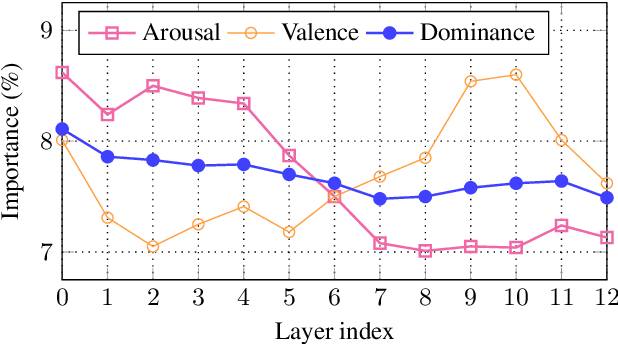

In large part due to their implicit semantic modeling, self-supervised learning (SSL) methods have significantly increased the performance of valence recognition in speech emotion recognition (SER) systems. Yet, their large size may often hinder practical implementations. In this work, we take HuBERT as an example of an SSL model and analyze the relevance of each of its layers for SER. We show that shallow layers are more important for arousal recognition while deeper layers are more important for valence. This observation motivates the importance of additional textual information for accurate valence recognition, as the distilled framework lacks the depth of its large-scale SSL teacher. Thus, we propose an audio-textual distilled SSL framework that, while having only ~20% of the trainable parameters of a large SSL model, achieves on par performance across the three emotion dimensions (arousal, valence, dominance) on the MSP-Podcast v1.10 dataset.
Adversarial Self-Attack Defense and Spatial-Temporal Relation Mining for Visible-Infrared Video Person Re-Identification
Jul 17, 2023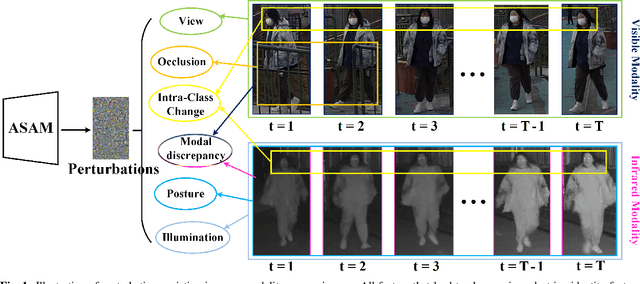
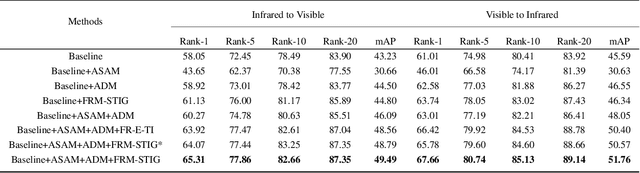
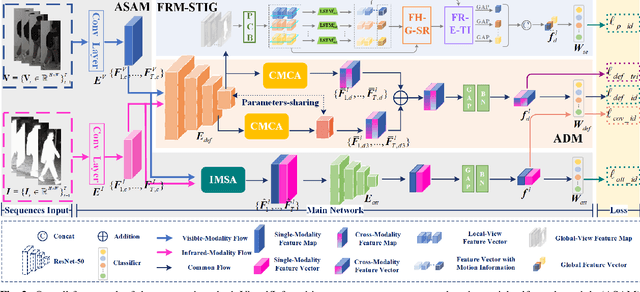
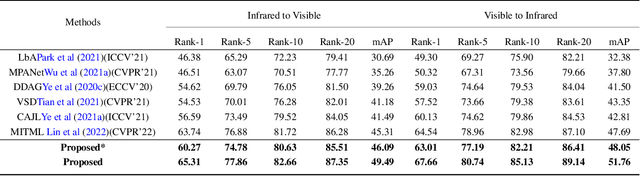
In visible-infrared video person re-identification (re-ID), extracting features not affected by complex scenes (such as modality, camera views, pedestrian pose, background, etc.) changes, and mining and utilizing motion information are the keys to solving cross-modal pedestrian identity matching. To this end, the paper proposes a new visible-infrared video person re-ID method from a novel perspective, i.e., adversarial self-attack defense and spatial-temporal relation mining. In this work, the changes of views, posture, background and modal discrepancy are considered as the main factors that cause the perturbations of person identity features. Such interference information contained in the training samples is used as an adversarial perturbation. It performs adversarial attacks on the re-ID model during the training to make the model more robust to these unfavorable factors. The attack from the adversarial perturbation is introduced by activating the interference information contained in the input samples without generating adversarial samples, and it can be thus called adversarial self-attack. This design allows adversarial attack and defense to be integrated into one framework. This paper further proposes a spatial-temporal information-guided feature representation network to use the information in video sequences. The network cannot only extract the information contained in the video-frame sequences but also use the relation of the local information in space to guide the network to extract more robust features. The proposed method exhibits compelling performance on large-scale cross-modality video datasets. The source code of the proposed method will be released at https://github.com/lhf12278/xxx.
Reconfigurable Intelligent Surfaces Assisted Communication Under Different CSI Assumptions
Aug 08, 2023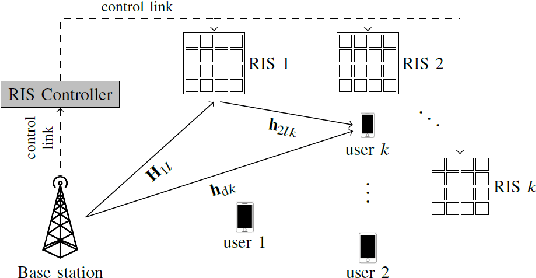
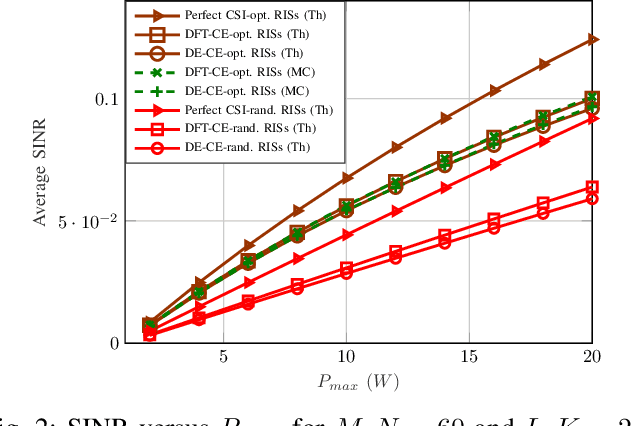
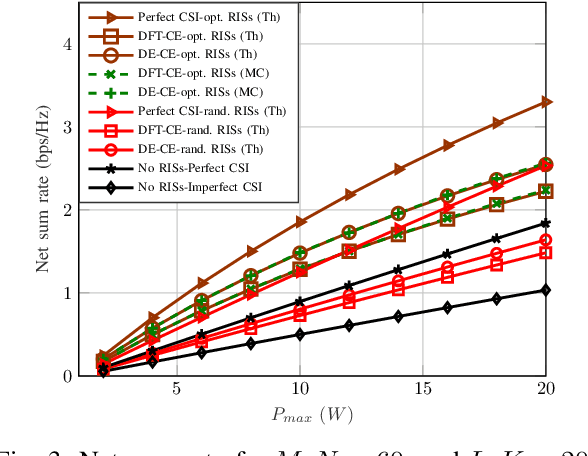
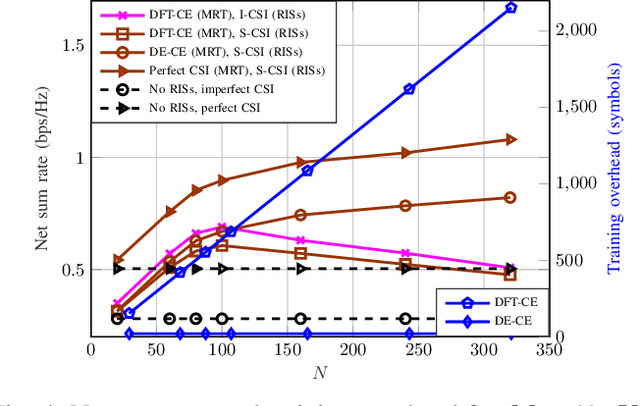
This work studies the net sum-rate performance of a distributed reconfigurable intelligent surfaces (RISs)-assisted multi-user multiple-input-single-output (MISO) downlink communication system under imperfect instantaneous-channel state information (I-CSI) to implement precoding at the base station (BS) and statistical-CSI (S-CSI) to design the RISs phase-shifts. Two channel estimation (CE) protocols are considered for I-CSI acquisition: (i) a full CE protocol that estimates all direct and RISs-assisted channels over multiple training sub-phases, and (ii) a low-overhead direct estimation (DE) protocol that estimates the end-to-end channel in a single sub-phase. We derive the asymptotic equivalents of signal-to-interference-plus-noise ratio (SINR) and ergodic net sum-rate under both protocols for given RISs phase-shifts, which are then optimized based on S-CSI. Simulation results reveal that the low-complexity DE protocol yields better net sum-rate than the full CE protocol when used to obtain CSI for precoding. A benchmark full I-CSI based RISs design is also outlined and shown to yield higher SINR but lower net sum-rate than the S-CSI based RISs design.
Balancing Privacy and Progress in Artificial Intelligence: Anonymization in Histopathology for Biomedical Research and Education
Aug 08, 2023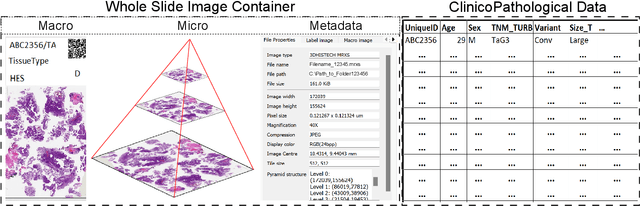
The advancement of biomedical research heavily relies on access to large amounts of medical data. In the case of histopathology, Whole Slide Images (WSI) and clinicopathological information are valuable for developing Artificial Intelligence (AI) algorithms for Digital Pathology (DP). Transferring medical data "as open as possible" enhances the usability of the data for secondary purposes but poses a risk to patient privacy. At the same time, existing regulations push towards keeping medical data "as closed as necessary" to avoid re-identification risks. Generally, these legal regulations require the removal of sensitive data but do not consider the possibility of data linkage attacks due to modern image-matching algorithms. In addition, the lack of standardization in DP makes it harder to establish a single solution for all formats of WSIs. These challenges raise problems for bio-informatics researchers in balancing privacy and progress while developing AI algorithms. This paper explores the legal regulations and terminologies for medical data-sharing. We review existing approaches and highlight challenges from the histopathological perspective. We also present a data-sharing guideline for histological data to foster multidisciplinary research and education.
Boosting Few-shot 3D Point Cloud Segmentation via Query-Guided Enhancement
Aug 08, 2023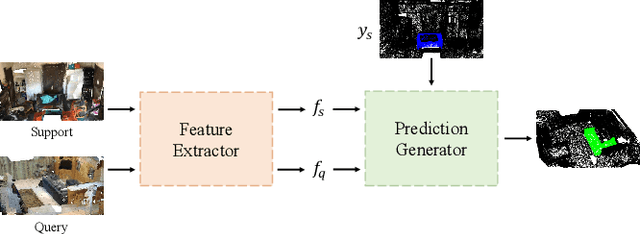

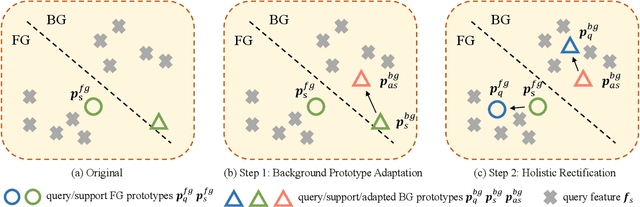

Although extensive research has been conducted on 3D point cloud segmentation, effectively adapting generic models to novel categories remains a formidable challenge. This paper proposes a novel approach to improve point cloud few-shot segmentation (PC-FSS) models. Unlike existing PC-FSS methods that directly utilize categorical information from support prototypes to recognize novel classes in query samples, our method identifies two critical aspects that substantially enhance model performance by reducing contextual gaps between support prototypes and query features. Specifically, we (1) adapt support background prototypes to match query context while removing extraneous cues that may obscure foreground and background in query samples, and (2) holistically rectify support prototypes under the guidance of query features to emulate the latter having no semantic gap to the query targets. Our proposed designs are agnostic to the feature extractor, rendering them readily applicable to any prototype-based methods. The experimental results on S3DIS and ScanNet demonstrate notable practical benefits, as our approach achieves significant improvements while still maintaining high efficiency. The code for our approach is available at https://github.com/AaronNZH/Boosting-Few-shot-3D-Point-Cloud-Segmentation-via-Query-Guided-Enhancement
Copy Number Variation Informs fMRI-based Prediction of Autism Spectrum Disorder
Aug 08, 2023The multifactorial etiology of autism spectrum disorder (ASD) suggests that its study would benefit greatly from multimodal approaches that combine data from widely varying platforms, e.g., neuroimaging, genetics, and clinical characterization. Prior neuroimaging-genetic analyses often apply naive feature concatenation approaches in data-driven work or use the findings from one modality to guide posthoc analysis of another, missing the opportunity to analyze the paired multimodal data in a truly unified approach. In this paper, we develop a more integrative model for combining genetic, demographic, and neuroimaging data. Inspired by the influence of genotype on phenotype, we propose using an attention-based approach where the genetic data guides attention to neuroimaging features of importance for model prediction. The genetic data is derived from copy number variation parameters, while the neuroimaging data is from functional magnetic resonance imaging. We evaluate the proposed approach on ASD classification and severity prediction tasks, using a sex-balanced dataset of 228 ASD and typically developing subjects in a 10-fold cross-validation framework. We demonstrate that our attention-based model combining genetic information, demographic data, and functional magnetic resonance imaging results in superior prediction performance compared to other multimodal approaches.