 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Bayesian Networks with Heterogeneous Agronomic Data Sets via Mixed-Effect Models and Hierarchical Clustering
Aug 11, 2023
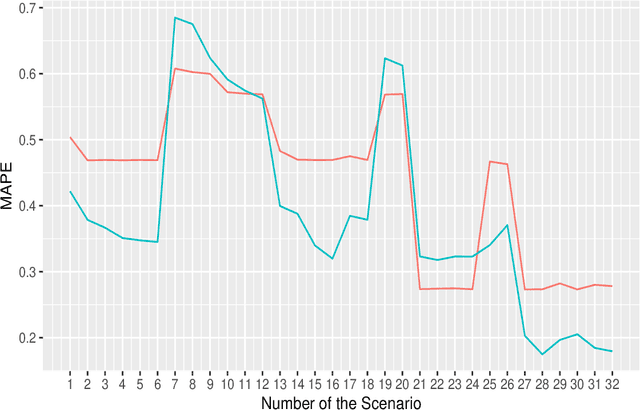
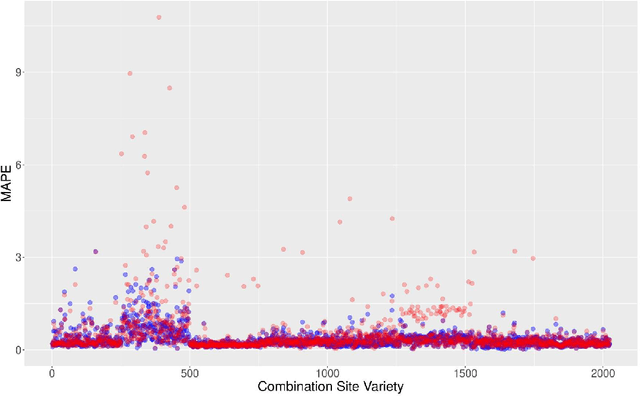
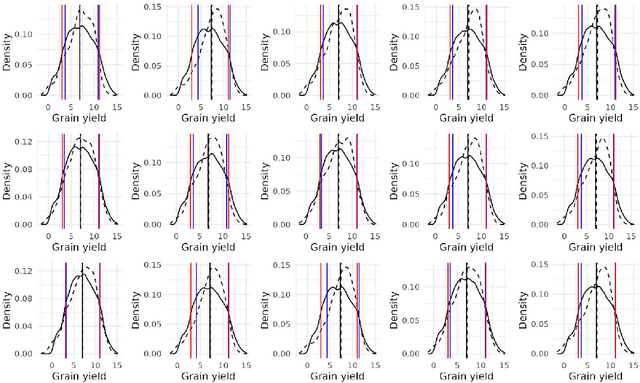
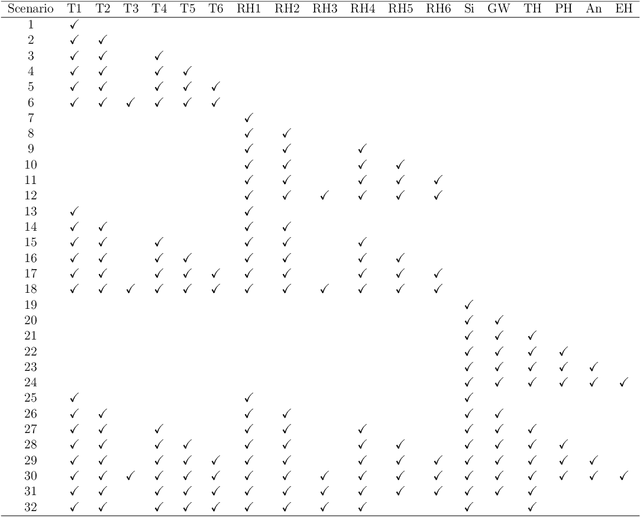
Research involving diverse but related data sets, where associations between covariates and outcomes may vary, is prevalent in various fields including agronomic studies. In these scenarios, hierarchical models, also known as multilevel models, are frequently employed to assimilate information from different data sets while accommodating their distinct characteristics. However, their structure extend beyond simple heterogeneity, as variables often form complex networks of causal relationships. Bayesian networks (BNs) provide a powerful framework for modelling such relationships using directed acyclic graphs to illustrate the connections between variables. This study introduces a novel approach that integrates random effects into BN learning. Rooted in linear mixed-effects models, this approach is particularly well-suited for handling hierarchical data. Results from a real-world agronomic trial suggest that employing this approach enhances structural learning, leading to the discovery of new connections and the improvement of improved model specification. Furthermore, we observe a reduction in prediction errors from 28\% to 17\%. By extending the applicability of BNs to complex data set structures, this approach contributes to the effective utilisation of BNs for hierarchical agronomic data. This, in turn, enhances their value as decision-support tools in the field.
PETformer: Long-term Time Series Forecasting via Placeholder-enhanced Transformer
Aug 09, 2023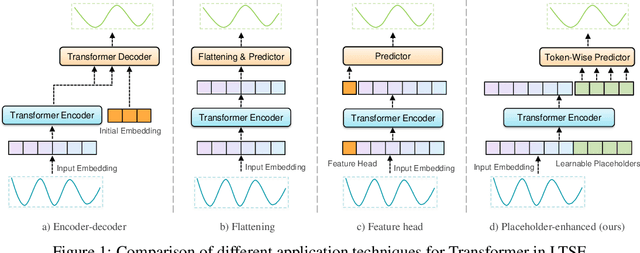
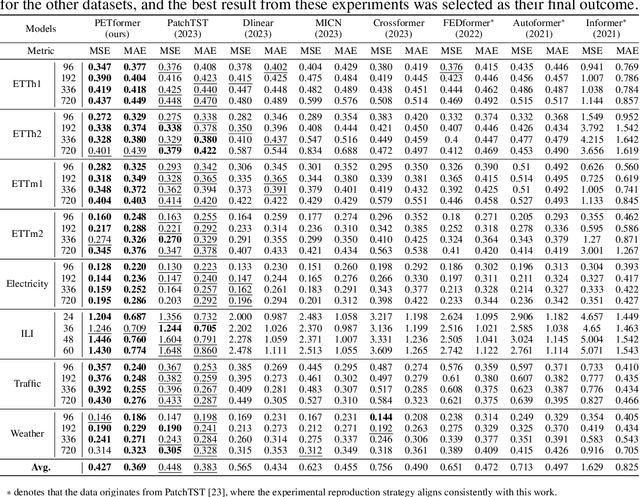
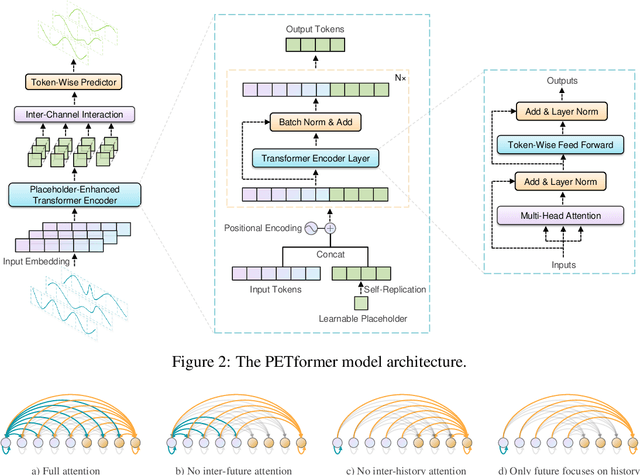
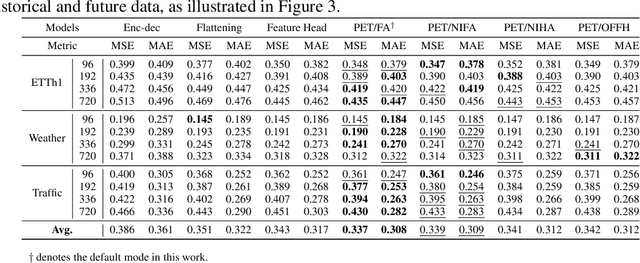
Recently, Transformer-based models have shown remarkable performance in long-term time series forecasting (LTSF) tasks due to their ability to model long-term dependencies. However, the validity of Transformers for LTSF tasks remains debatable, particularly since recent work has shown that simple linear models can outperform numerous Transformer-based approaches. This suggests that there are limitations to the application of Transformer in LTSF. Therefore, this paper investigates three key issues when applying Transformer to LTSF: temporal continuity, information density, and multi-channel relationships. Accordingly, we propose three innovative solutions, including Placeholder Enhancement Technique (PET), Long Sub-sequence Division (LSD), and Multi-channel Separation and Interaction (MSI), which together form a novel model called PETformer. These three key designs introduce prior biases suitable for LTSF tasks. Extensive experiments have demonstrated that PETformer achieves state-of-the-art (SOTA) performance on eight commonly used public datasets for LTSF, outperforming all other models currently available. This demonstrates that Transformer still possesses powerful capabilities in LTSF.
Pseudo-label Alignment for Semi-supervised Instance Segmentation
Aug 10, 2023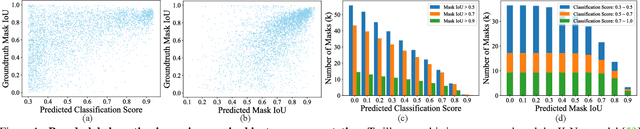
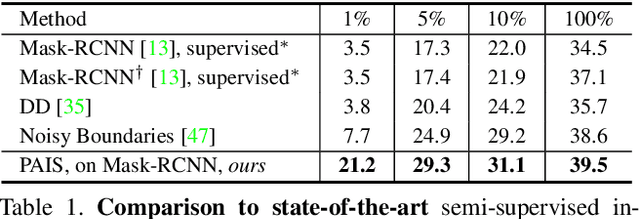
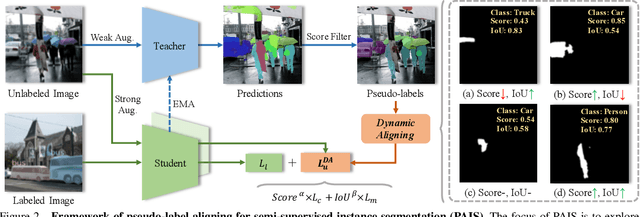
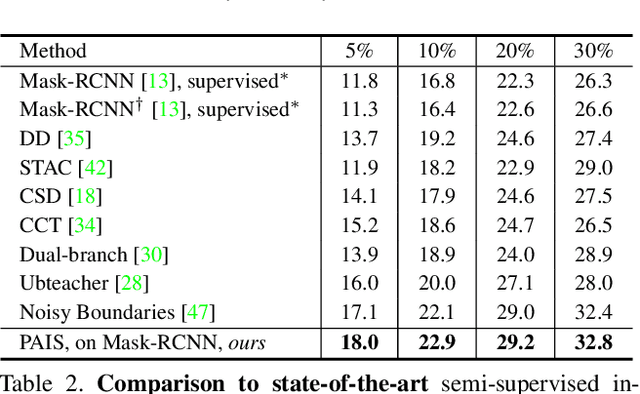
Pseudo-labeling is significant for semi-supervised instance segmentation, which generates instance masks and classes from unannotated images for subsequent training. However, in existing pipelines, pseudo-labels that contain valuable information may be directly filtered out due to mismatches in class and mask quality. To address this issue, we propose a novel framework, called pseudo-label aligning instance segmentation (PAIS), in this paper. In PAIS, we devise a dynamic aligning loss (DALoss) that adjusts the weights of semi-supervised loss terms with varying class and mask score pairs. Through extensive experiments conducted on the COCO and Cityscapes datasets, we demonstrate that PAIS is a promising framework for semi-supervised instance segmentation, particularly in cases where labeled data is severely limited. Notably, with just 1\% labeled data, PAIS achieves 21.2 mAP (based on Mask-RCNN) and 19.9 mAP (based on K-Net) on the COCO dataset, outperforming the current state-of-the-art model, \ie, NoisyBoundary with 7.7 mAP, by a margin of over 12 points. Code is available at: \url{https://github.com/hujiecpp/PAIS}.
Enhancing Low-light Light Field Images with A Deep Compensation Unfolding Network
Aug 10, 2023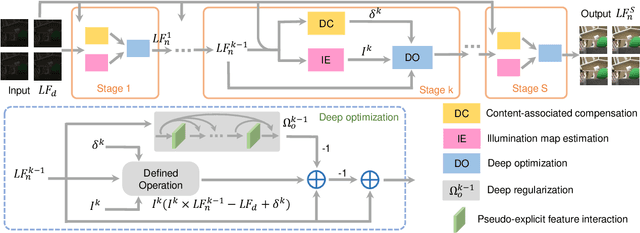


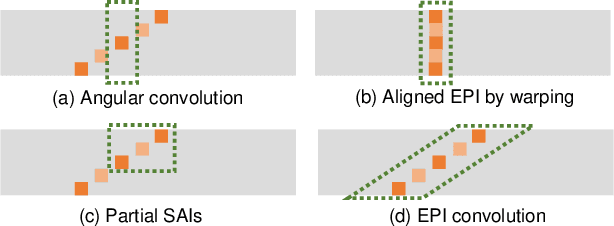
This paper presents a novel and interpretable end-to-end learning framework, called the deep compensation unfolding network (DCUNet), for restoring light field (LF) images captured under low-light conditions. DCUNet is designed with a multi-stage architecture that mimics the optimization process of solving an inverse imaging problem in a data-driven fashion. The framework uses the intermediate enhanced result to estimate the illumination map, which is then employed in the unfolding process to produce a new enhanced result. Additionally, DCUNet includes a content-associated deep compensation module at each optimization stage to suppress noise and illumination map estimation errors. To properly mine and leverage the unique characteristics of LF images, this paper proposes a pseudo-explicit feature interaction module that comprehensively exploits redundant information in LF images. The experimental results on both simulated and real datasets demonstrate the superiority of our DCUNet over state-of-the-art methods, both qualitatively and quantitatively. Moreover, DCUNet preserves the essential geometric structure of enhanced LF images much better. The code will be publicly available at https://github.com/lyuxianqiang/LFLL-DCU.
A Homomorphic Encryption Framework for Privacy-Preserving Spiking Neural Networks
Aug 10, 2023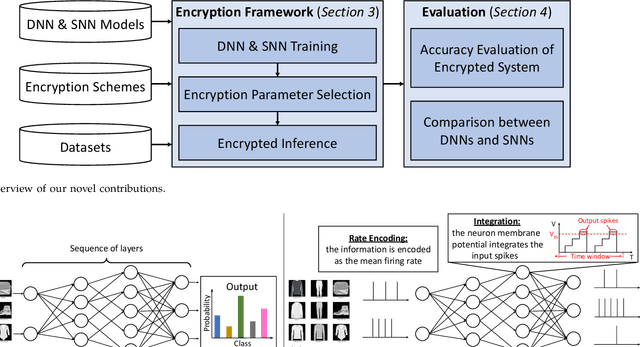
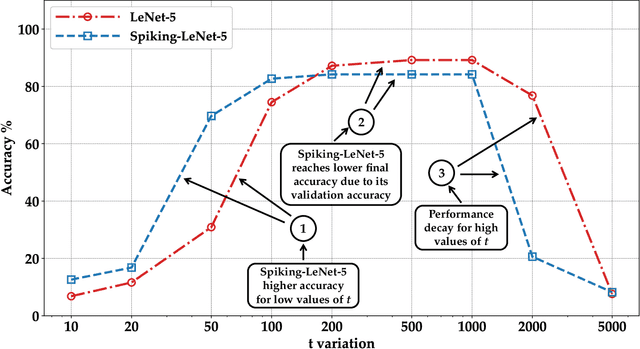
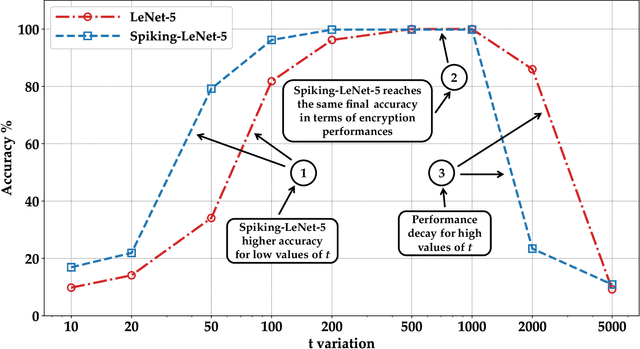
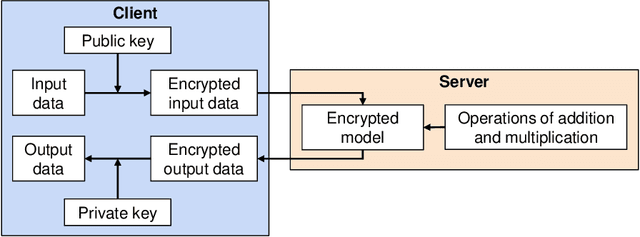
Machine learning (ML) is widely used today, especially through deep neural networks (DNNs), however, increasing computational load and resource requirements have led to cloud-based solutions. To address this problem, a new generation of networks called Spiking Neural Networks (SNN) has emerged, which mimic the behavior of the human brain to improve efficiency and reduce energy consumption. These networks often process large amounts of sensitive information, such as confidential data, and thus privacy issues arise. Homomorphic encryption (HE) offers a solution, allowing calculations to be performed on encrypted data without decrypting it. This research compares traditional DNNs and SNNs using the Brakerski/Fan-Vercauteren (BFV) encryption scheme. The LeNet-5 model, a widely-used convolutional architecture, is used for both DNN and SNN models based on the LeNet-5 architecture, and the networks are trained and compared using the FashionMNIST dataset. The results show that SNNs using HE achieve up to 40% higher accuracy than DNNs for low values of the plaintext modulus t, although their execution time is longer due to their time-coding nature with multiple time-steps.
Collaborative filtering to capture AI user's preferences as norms
Aug 10, 2023Customising AI technologies to each user's preferences is fundamental to them functioning well. Unfortunately, current methods require too much user involvement and fail to capture their true preferences. In fact, to avoid the nuisance of manually setting preferences, users usually accept the default settings even if these do not conform to their true preferences. Norms can be useful to regulate behaviour and ensure it adheres to user preferences but, while the literature has thoroughly studied norms, most proposals take a formal perspective. Indeed, while there has been some research on constructing norms to capture a user's privacy preferences, these methods rely on domain knowledge which, in the case of AI technologies, is difficult to obtain and maintain. We argue that a new perspective is required when constructing norms, which is to exploit the large amount of preference information readily available from whole systems of users. Inspired by recommender systems, we believe that collaborative filtering can offer a suitable approach to identifying a user's norm preferences without excessive user involvement.
Fine-Grained Self-Supervised Learning with Jigsaw Puzzles for Medical Image Classification
Aug 10, 2023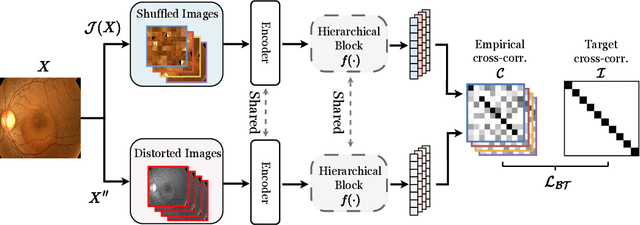
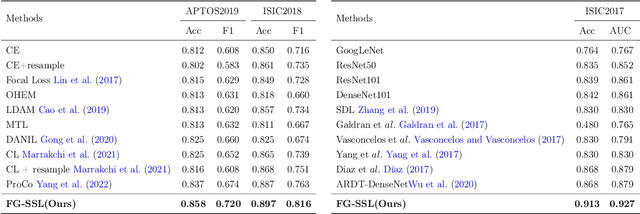
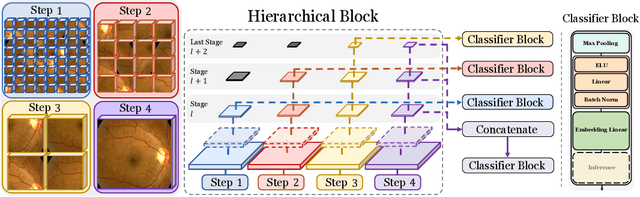
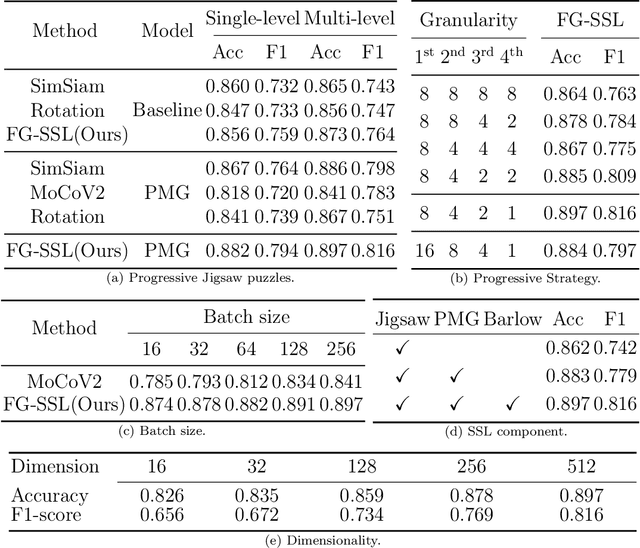
Classifying fine-grained lesions is challenging due to minor and subtle differences in medical images. This is because learning features of fine-grained lesions with highly minor differences is very difficult in training deep neural networks. Therefore, in this paper, we introduce Fine-Grained Self-Supervised Learning(FG-SSL) method for classifying subtle lesions in medical images. The proposed method progressively learns the model through hierarchical block such that the cross-correlation between the fine-grained Jigsaw puzzle and regularized original images is close to the identity matrix. We also apply hierarchical block for progressive fine-grained learning, which extracts different information in each step, to supervised learning for discovering subtle differences. Our method does not require an asymmetric model, nor does a negative sampling strategy, and is not sensitive to batch size. We evaluate the proposed fine-grained self-supervised learning method on comprehensive experiments using various medical image recognition datasets. In our experiments, the proposed method performs favorably compared to existing state-of-the-art approaches on the widely-used ISIC2018, APTOS2019, and ISIC2017 datasets.
High-efficient deep learning-based DTI reconstruction with flexible diffusion gradient encoding scheme
Aug 02, 2023
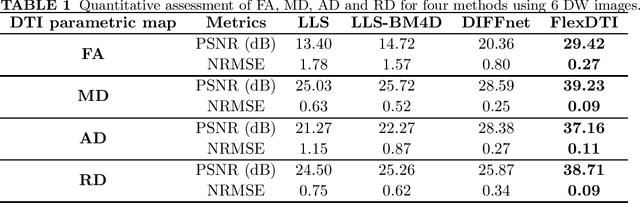
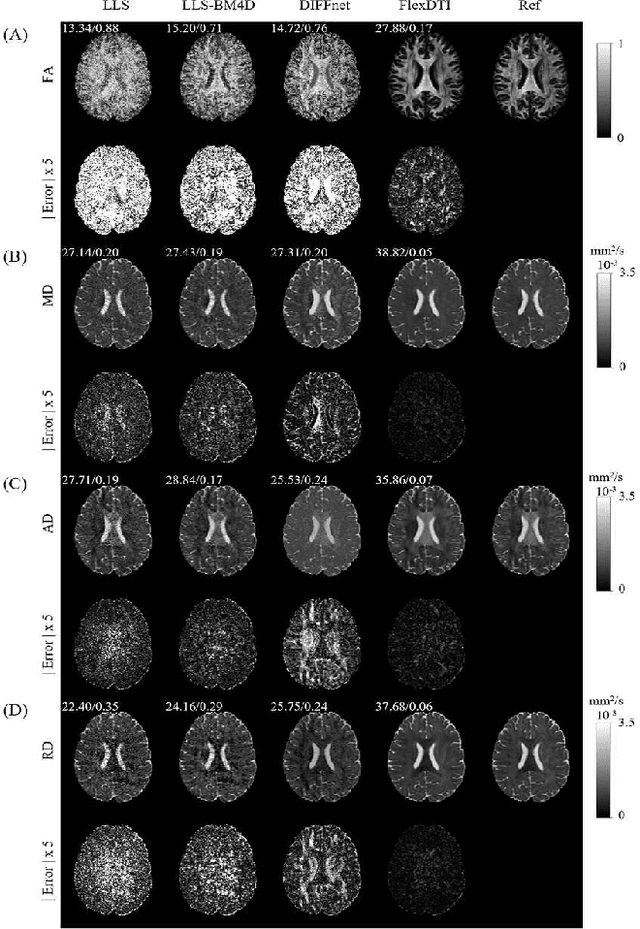

Purpose: To develop and evaluate a novel dynamic-convolution-based method called FlexDTI for high-efficient diffusion tensor reconstruction with flexible diffusion encoding gradient schemes. Methods: FlexDTI was developed to achieve high-quality DTI parametric mapping with flexible number and directions of diffusion encoding gradients. The proposed method used dynamic convolution kernels to embed diffusion gradient direction information into feature maps of the corresponding diffusion signal. Besides, our method realized the generalization of a flexible number of diffusion gradient directions by setting the maximum number of input channels of the network. The network was trained and tested using data sets from the Human Connectome Project and a local hospital. Results from FlexDTI and other advanced tensor parameter estimation methods were compared. Results: Compared to other methods, FlexDTI successfully achieves high-quality diffusion tensor-derived variables even if the number and directions of diffusion encoding gradients are variable. It increases peak signal-to-noise ratio (PSNR) by about 10 dB on Fractional Anisotropy (FA) and Mean Diffusivity (MD), compared with the state-of-the-art deep learning method with flexible diffusion encoding gradient schemes. Conclusion: FlexDTI can well learn diffusion gradient direction information to achieve generalized DTI reconstruction with flexible diffusion gradient schemes. Both flexibility and reconstruction quality can be taken into account in this network.
BRNES: Enabling Security and Privacy-aware Experience Sharing in Multiagent Robotic and Autonomous Systems
Aug 02, 2023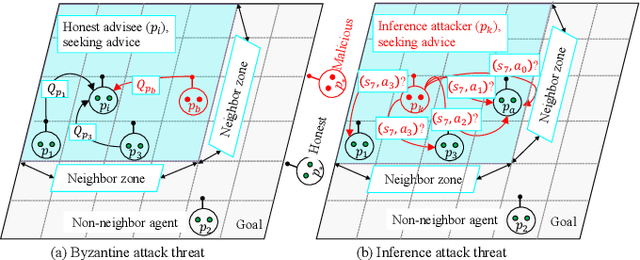
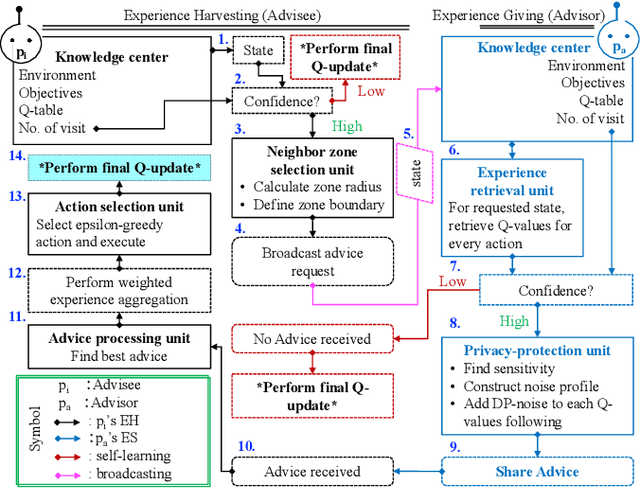
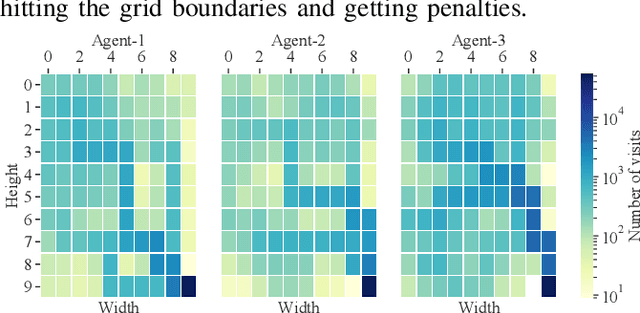
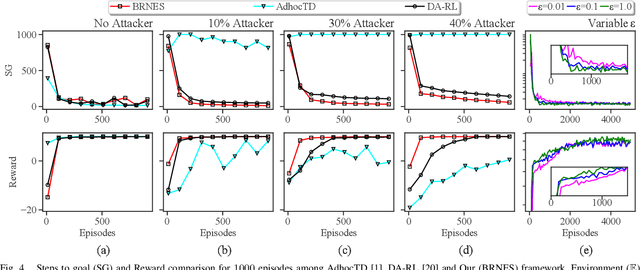
Although experience sharing (ES) accelerates multiagent reinforcement learning (MARL) in an advisor-advisee framework, attempts to apply ES to decentralized multiagent systems have so far relied on trusted environments and overlooked the possibility of adversarial manipulation and inference. Nevertheless, in a real-world setting, some Byzantine attackers, disguised as advisors, may provide false advice to the advisee and catastrophically degrade the overall learning performance. Also, an inference attacker, disguised as an advisee, may conduct several queries to infer the advisors' private information and make the entire ES process questionable in terms of privacy leakage. To address and tackle these issues, we propose a novel MARL framework (BRNES) that heuristically selects a dynamic neighbor zone for each advisee at each learning step and adopts a weighted experience aggregation technique to reduce Byzantine attack impact. Furthermore, to keep the agent's private information safe from adversarial inference attacks, we leverage the local differential privacy (LDP)-induced noise during the ES process. Our experiments show that our framework outperforms the state-of-the-art in terms of the steps to goal, obtained reward, and time to goal metrics. Particularly, our evaluation shows that the proposed framework is 8.32x faster than the current non-private frameworks and 1.41x faster than the private frameworks in an adversarial setting.
Insurance pricing on price comparison websites via reinforcement learning
Aug 14, 2023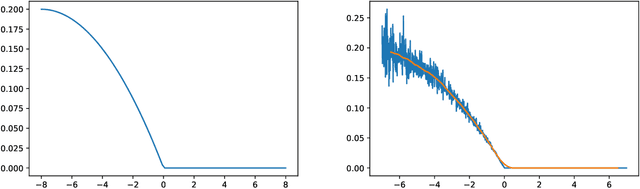
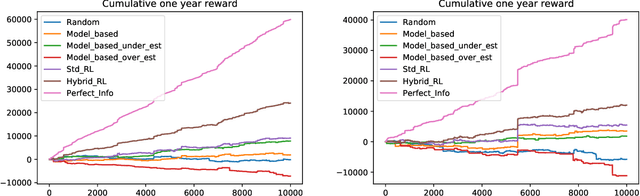
The emergence of price comparison websites (PCWs) has presented insurers with unique challenges in formulating effective pricing strategies. Operating on PCWs requires insurers to strike a delicate balance between competitive premiums and profitability, amidst obstacles such as low historical conversion rates, limited visibility of competitors' actions, and a dynamic market environment. In addition to this, the capital intensive nature of the business means pricing below the risk levels of customers can result in solvency issues for the insurer. To address these challenges, this paper introduces reinforcement learning (RL) framework that learns the optimal pricing policy by integrating model-based and model-free methods. The model-based component is used to train agents in an offline setting, avoiding cold-start issues, while model-free algorithms are then employed in a contextual bandit (CB) manner to dynamically update the pricing policy to maximise the expected revenue. This facilitates quick adaptation to evolving market dynamics and enhances algorithm efficiency and decision interpretability. The paper also highlights the importance of evaluating pricing policies using an offline dataset in a consistent fashion and demonstrates the superiority of the proposed methodology over existing off-the-shelf RL/CB approaches. We validate our methodology using synthetic data, generated to reflect private commercially available data within real-world insurers, and compare against 6 other benchmark approaches. Our hybrid agent outperforms these benchmarks in terms of sample efficiency and cumulative reward with the exception of an agent that has access to perfect market information which would not be available in a real-world set-up.