 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
VideoControlNet: A Motion-Guided Video-to-Video Translation Framework by Using Diffusion Model with ControlNet
Jul 26, 2023
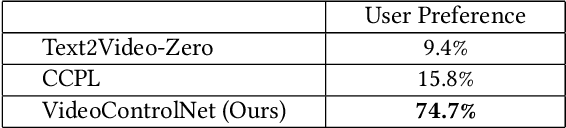
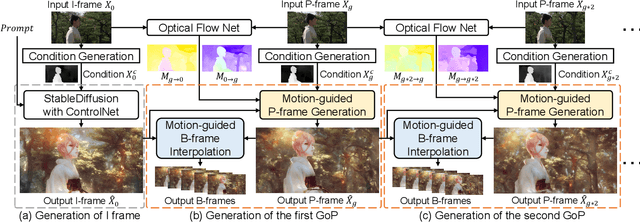

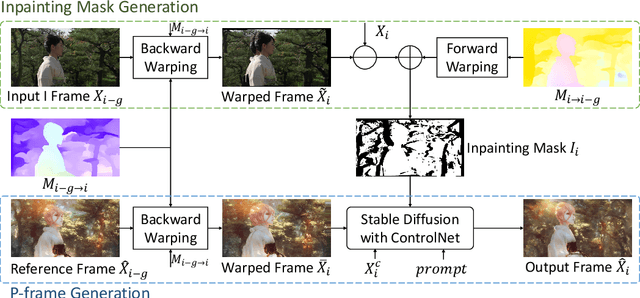
Recently, diffusion models like StableDiffusion have achieved impressive image generation results. However, the generation process of such diffusion models is uncontrollable, which makes it hard to generate videos with continuous and consistent content. In this work, by using the diffusion model with ControlNet, we proposed a new motion-guided video-to-video translation framework called VideoControlNet to generate various videos based on the given prompts and the condition from the input video. Inspired by the video codecs that use motion information for reducing temporal redundancy, our framework uses motion information to prevent the regeneration of the redundant areas for content consistency. Specifically, we generate the first frame (i.e., the I-frame) by using the diffusion model with ControlNet. Then we generate other key frames (i.e., the P-frame) based on the previous I/P-frame by using our newly proposed motion-guided P-frame generation (MgPG) method, in which the P-frames are generated based on the motion information and the occlusion areas are inpainted by using the diffusion model. Finally, the rest frames (i.e., the B-frame) are generated by using our motion-guided B-frame interpolation (MgBI) module. Our experiments demonstrate that our proposed VideoControlNet inherits the generation capability of the pre-trained large diffusion model and extends the image diffusion model to the video diffusion model by using motion information. More results are provided at our project page.
NewsDialogues: Towards Proactive News Grounded Conversation
Aug 12, 2023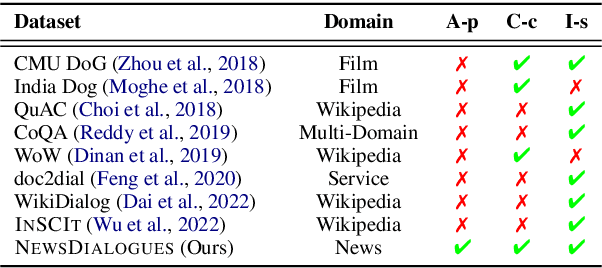

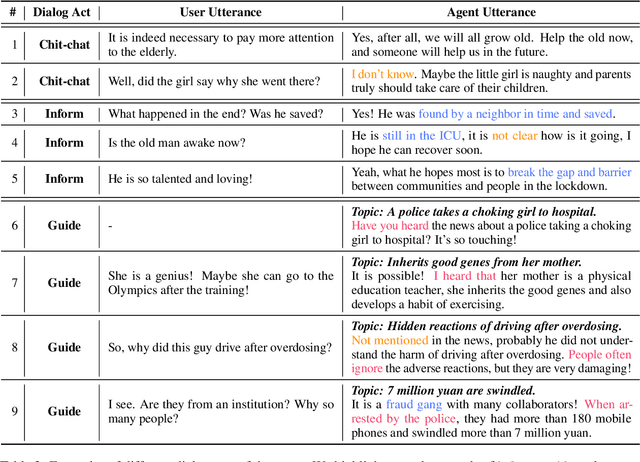
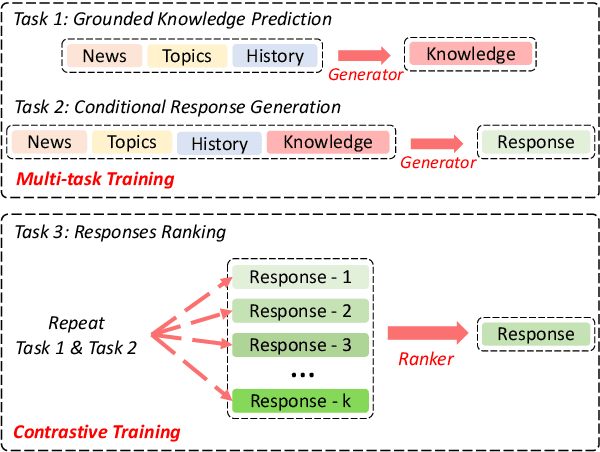
Hot news is one of the most popular topics in daily conversations. However, news grounded conversation has long been stymied by the lack of well-designed task definition and scarce data. In this paper, we propose a novel task, Proactive News Grounded Conversation, in which a dialogue system can proactively lead the conversation based on some key topics of the news. In addition, both information-seeking and chit-chat scenarios are included realistically, where the user may ask a series of questions about the news details or express their opinions and be eager to chat. To further develop this novel task, we collect a human-to-human Chinese dialogue dataset \ts{NewsDialogues}, which includes 1K conversations with a total of 14.6K utterances and detailed annotations for target topics and knowledge spans. Furthermore, we propose a method named Predict-Generate-Rank, consisting of a generator for grounded knowledge prediction and response generation, and a ranker for the ranking of multiple responses to alleviate the exposure bias. We conduct comprehensive experiments to demonstrate the effectiveness of the proposed method and further present several key findings and challenges to prompt future research.
Simple Model Also Works: A Novel Emotion Recognition Network in Textual Conversation Based on Curriculum Learning Strategy
Aug 12, 2023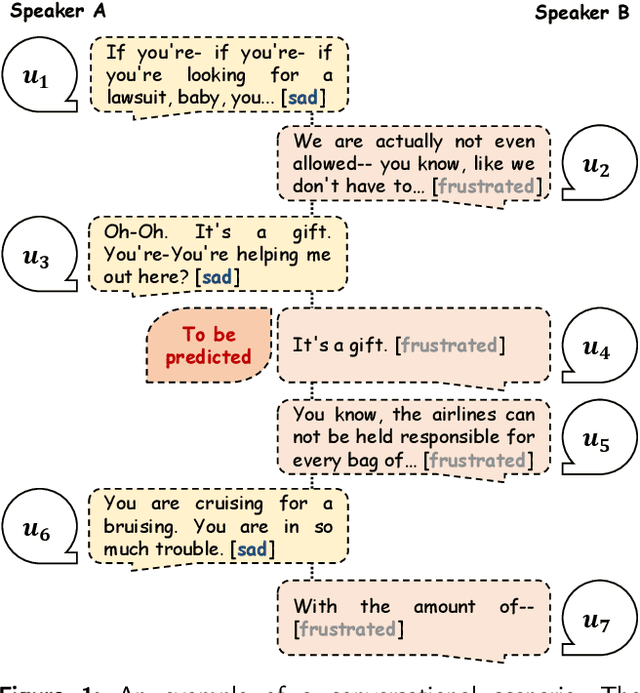
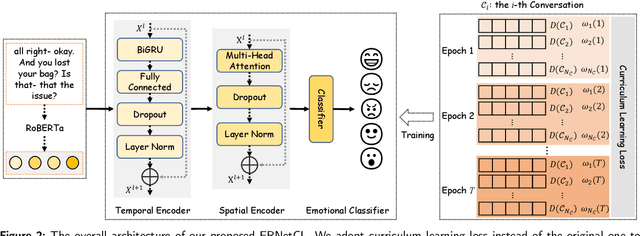
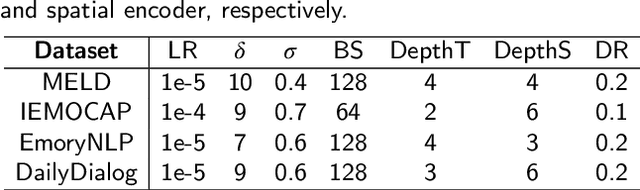
Emotion Recognition in Conversation (ERC) has emerged as a research hotspot in domains such as conversational robots and question-answer systems. How to efficiently and adequately retrieve contextual emotional cues has been one of the key challenges in the ERC task. Existing efforts do not fully model the context and employ complex network structures, resulting in excessive computational resource overhead without substantial performance improvement. In this paper, we propose a novel Emotion Recognition Network based on Curriculum Learning strategy (ERNetCL). The proposed ERNetCL primarily consists of Temporal Encoder (TE), Spatial Encoder (SE), and Curriculum Learning (CL) loss. We utilize TE and SE to combine the strengths of previous methods in a simplistic manner to efficiently capture temporal and spatial contextual information in the conversation. To simulate the way humans learn curriculum from easy to hard, we apply the idea of CL to the ERC task to progressively optimize the network parameters of ERNetCL. At the beginning of training, we assign lower learning weights to difficult samples. As the epoch increases, the learning weights for these samples are gradually raised. Extensive experiments on four datasets exhibit that our proposed method is effective and dramatically beats other baseline models.
Multi Agent Navigation in Unconstrained Environments using a Centralized Attention based Graphical Neural Network Controller
Aug 10, 2023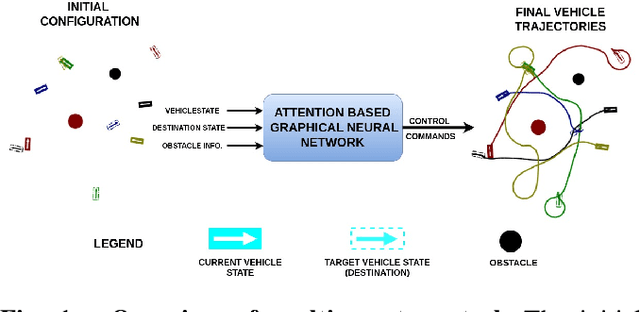
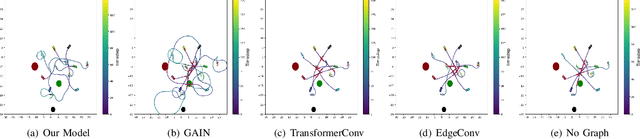
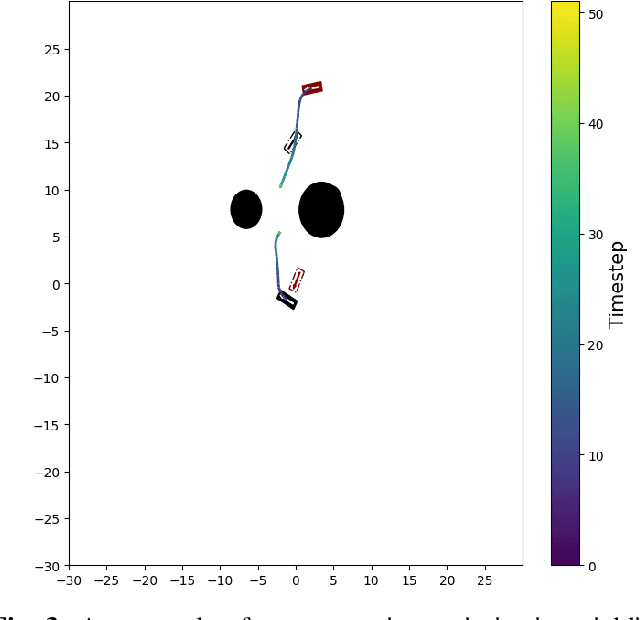
In this work, we propose a learning based neural model that provides both the longitudinal and lateral control commands to simultaneously navigate multiple vehicles. The goal is to ensure that each vehicle reaches a desired target state without colliding with any other vehicle or obstacle in an unconstrained environment. The model utilizes an attention based Graphical Neural Network paradigm that takes into consideration the state of all the surrounding vehicles to make an informed decision. This allows each vehicle to smoothly reach its destination while also evading collision with the other agents. The data and corresponding labels for training such a network is obtained using an optimization based procedure. Experimental results demonstrates that our model is powerful enough to generalize even to situations with more vehicles than in the training data. Our method also outperforms comparable graphical neural network architectures. Project page which includes the code and supplementary information can be found at https://yininghase.github.io/multi-agent-control/
Towards General and Fast Video Derain via Knowledge Distillation
Aug 10, 2023As a common natural weather condition, rain can obscure video frames and thus affect the performance of the visual system, so video derain receives a lot of attention. In natural environments, rain has a wide variety of streak types, which increases the difficulty of the rain removal task. In this paper, we propose a Rain Review-based General video derain Network via knowledge distillation (named RRGNet) that handles different rain streak types with one pre-training weight. Specifically, we design a frame grouping-based encoder-decoder network that makes full use of the temporal information of the video. Further, we use the old task model to guide the current model in learning new rain streak types while avoiding forgetting. To consolidate the network's ability to derain, we design a rain review module to play back data from old tasks for the current model. The experimental results show that our developed general method achieves the best results in terms of running speed and derain effect.
Test-Time Selection for Robust Skin Lesion Analysis
Aug 10, 2023Skin lesion analysis models are biased by artifacts placed during image acquisition, which influence model predictions despite carrying no clinical information. Solutions that address this problem by regularizing models to prevent learning those spurious features achieve only partial success, and existing test-time debiasing techniques are inappropriate for skin lesion analysis due to either making unrealistic assumptions on the distribution of test data or requiring laborious annotation from medical practitioners. We propose TTS (Test-Time Selection), a human-in-the-loop method that leverages positive (e.g., lesion area) and negative (e.g., artifacts) keypoints in test samples. TTS effectively steers models away from exploiting spurious artifact-related correlations without retraining, and with less annotation requirements. Our solution is robust to a varying availability of annotations, and different levels of bias. We showcase on the ISIC2019 dataset (for which we release a subset of annotated images) how our model could be deployed in the real-world for mitigating bias.
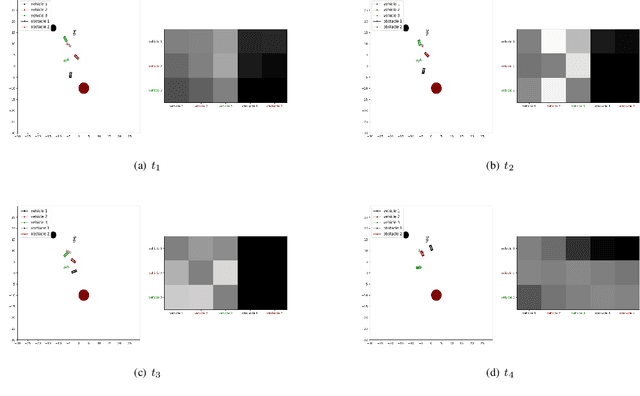
Ensemble Modeling for Multimodal Visual Action Recognition
Aug 10, 2023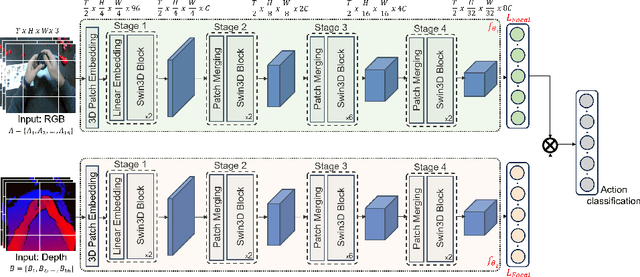
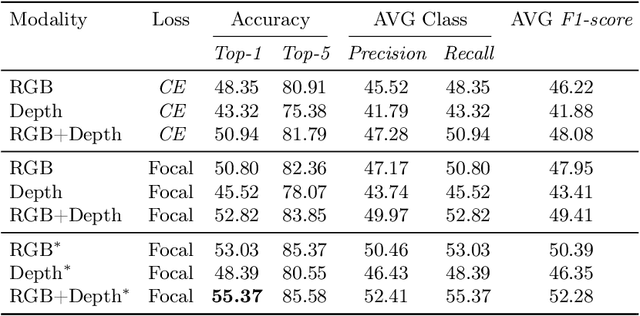
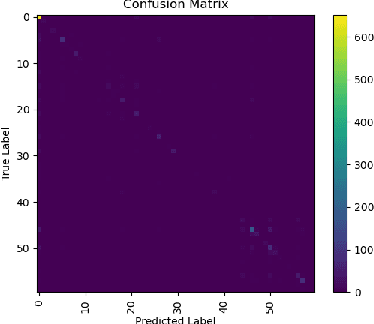
In this work, we propose an ensemble modeling approach for multimodal action recognition. We independently train individual modality models using a variant of focal loss tailored to handle the long-tailed distribution of the MECCANO [21] dataset. Based on the underlying principle of focal loss, which captures the relationship between tail (scarce) classes and their prediction difficulties, we propose an exponentially decaying variant of focal loss for our current task. It initially emphasizes learning from the hard misclassified examples and gradually adapts to the entire range of examples in the dataset. This annealing process encourages the model to strike a balance between focusing on the sparse set of hard samples, while still leveraging the information provided by the easier ones. Additionally, we opt for the late fusion strategy to combine the resultant probability distributions from RGB and Depth modalities for final action prediction. Experimental evaluations on the MECCANO dataset demonstrate the effectiveness of our approach.
TextPainter: Multimodal Text Image Generation withVisual-harmony and Text-comprehension for Poster Design
Aug 10, 2023
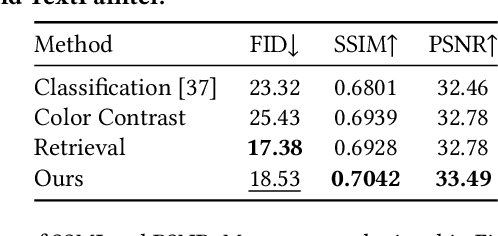
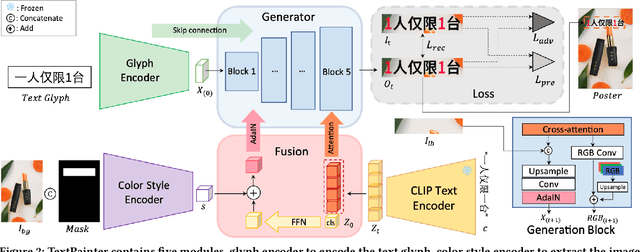
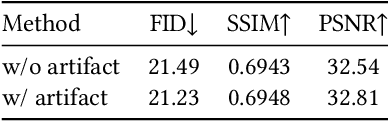
Text design is one of the most critical procedures in poster design, as it relies heavily on the creativity and expertise of humans to design text images considering the visual harmony and text-semantic. This study introduces TextPainter, a novel multimodal approach that leverages contextual visual information and corresponding text semantics to generate text images. Specifically, TextPainter takes the global-local background image as a hint of style and guides the text image generation with visual harmony. Furthermore, we leverage the language model and introduce a text comprehension module to achieve both sentence-level and word-level style variations. Besides, we construct the PosterT80K dataset, consisting of about 80K posters annotated with sentence-level bounding boxes and text contents. We hope this dataset will pave the way for further research on multimodal text image generation. Extensive quantitative and qualitative experiments demonstrate that TextPainter can generate visually-and-semantically-harmonious text images for posters.
Deep Fusion Transformer Network with Weighted Vector-Wise Keypoints Voting for Robust 6D Object Pose Estimation
Aug 10, 2023
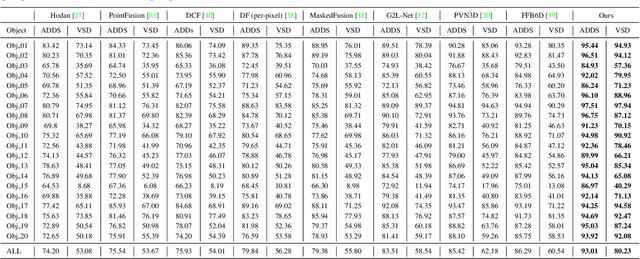
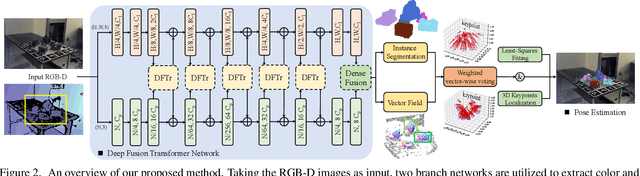
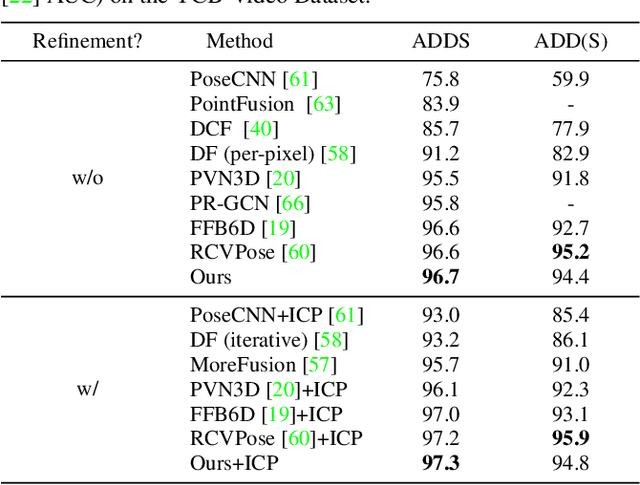
One critical challenge in 6D object pose estimation from a single RGBD image is efficient integration of two different modalities, i.e., color and depth. In this work, we tackle this problem by a novel Deep Fusion Transformer~(DFTr) block that can aggregate cross-modality features for improving pose estimation. Unlike existing fusion methods, the proposed DFTr can better model cross-modality semantic correlation by leveraging their semantic similarity, such that globally enhanced features from different modalities can be better integrated for improved information extraction. Moreover, to further improve robustness and efficiency, we introduce a novel weighted vector-wise voting algorithm that employs a non-iterative global optimization strategy for precise 3D keypoint localization while achieving near real-time inference. Extensive experiments show the effectiveness and strong generalization capability of our proposed 3D keypoint voting algorithm. Results on four widely used benchmarks also demonstrate that our method outperforms the state-of-the-art methods by large margins.
OpenProteinSet: Training data for structural biology at scale
Aug 10, 2023
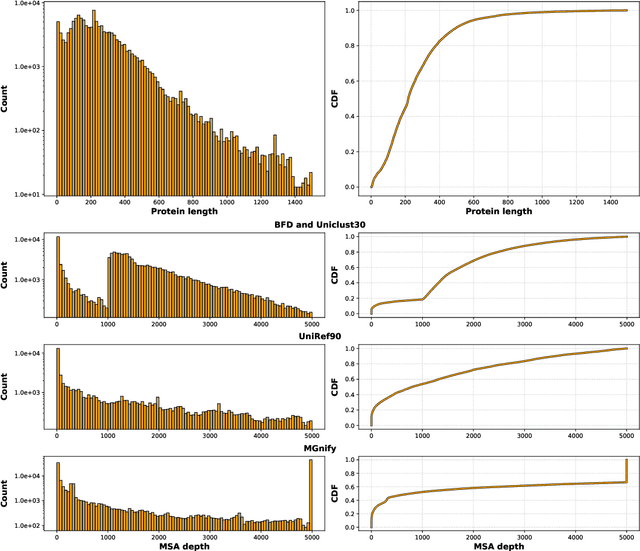
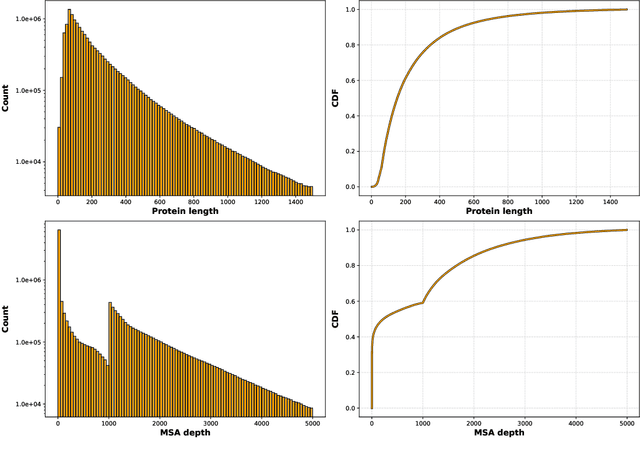
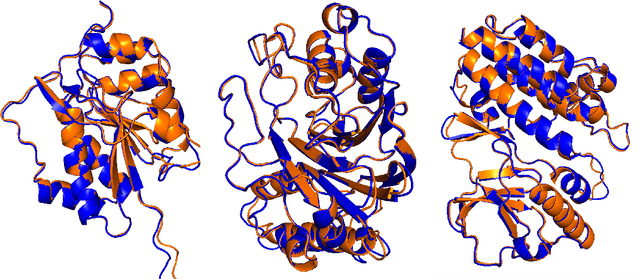
Multiple sequence alignments (MSAs) of proteins encode rich biological information and have been workhorses in bioinformatic methods for tasks like protein design and protein structure prediction for decades. Recent breakthroughs like AlphaFold2 that use transformers to attend directly over large quantities of raw MSAs have reaffirmed their importance. Generation of MSAs is highly computationally intensive, however, and no datasets comparable to those used to train AlphaFold2 have been made available to the research community, hindering progress in machine learning for proteins. To remedy this problem, we introduce OpenProteinSet, an open-source corpus of more than 16 million MSAs, associated structural homologs from the Protein Data Bank, and AlphaFold2 protein structure predictions. We have previously demonstrated the utility of OpenProteinSet by successfully retraining AlphaFold2 on it. We expect OpenProteinSet to be broadly useful as training and validation data for 1) diverse tasks focused on protein structure, function, and design and 2) large-scale multimodal machine learning research.