 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Model Checking Time Window Temporal Logic for Hyperproperties
Aug 02, 2023
Hyperproperties extend trace properties to express properties of sets of traces, and they are increasingly popular in specifying various security and performance-related properties in domains such as cyber-physical systems, smart grids, and automotive. This paper introduces a model checking algorithm for a new formalism, HyperTWTL, which extends Time Window Temporal Logic (TWTL) -- a domain-specific formal specification language for robotics, by allowing explicit and simultaneous quantification over multiple execution traces. We present HyperTWTL with both \emph{synchronous} and \emph{asynchronous} semantics, based on the alignment of the timestamps in the traces. Consequently, we demonstrate the application of HyperTWTL in formalizing important information-flow security policies and concurrency for robotics applications. Finally, we propose a model checking algorithm for verifying fragments of HyperTWTL by reducing the problem to a TWTL model checking problem.
Conditional Graph Information Bottleneck for Molecular Relational Learning
Apr 29, 2023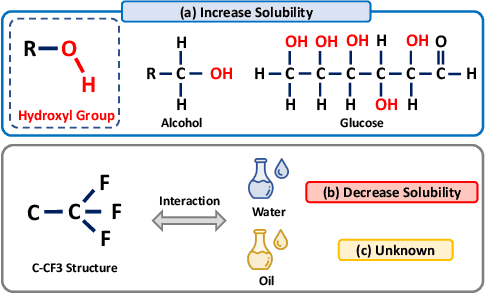
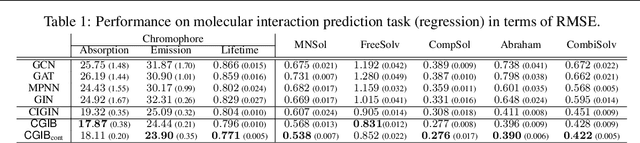
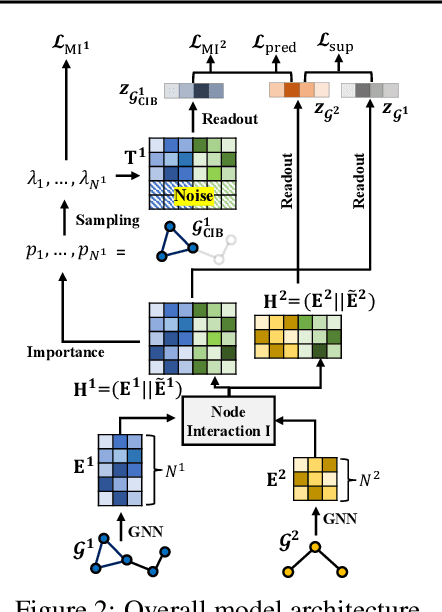
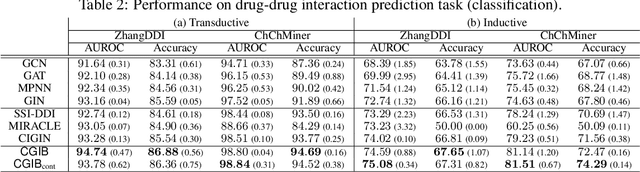
Molecular relational learning, whose goal is to learn the interaction behavior between molecular pairs, got a surge of interest in molecular sciences due to its wide range of applications. Recently, graph neural networks have recently shown great success in molecular relational learning by modeling a molecule as a graph structure, and considering atom-level interactions between two molecules. Despite their success, existing molecular relational learning methods tend to overlook the nature of chemistry, i.e., a chemical compound is composed of multiple substructures such as functional groups that cause distinctive chemical reactions. In this work, we propose a novel relational learning framework, called CGIB, that predicts the interaction behavior between a pair of graphs by detecting core subgraphs therein. The main idea is, given a pair of graphs, to find a subgraph from a graph that contains the minimal sufficient information regarding the task at hand conditioned on the paired graph based on the principle of conditional graph information bottleneck. We argue that our proposed method mimics the nature of chemical reactions, i.e., the core substructure of a molecule varies depending on which other molecule it interacts with. Extensive experiments on various tasks with real-world datasets demonstrate the superiority of CGIB over state-of-the-art baselines. Our code is available at https://github.com/Namkyeong/CGIB.
Age of Incorrect Information in Semantic Communications for NOMA Aided XR Applications
May 16, 2023
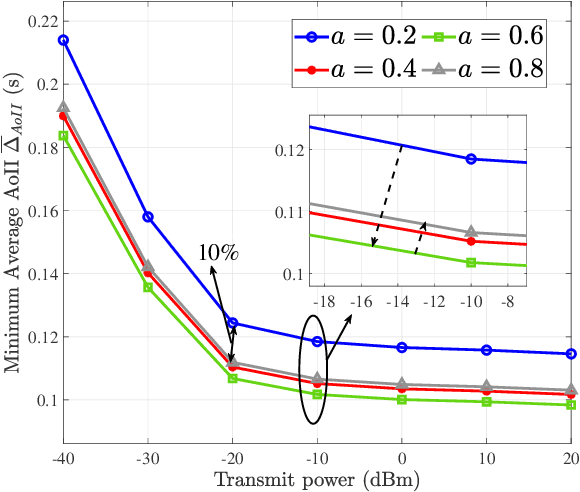
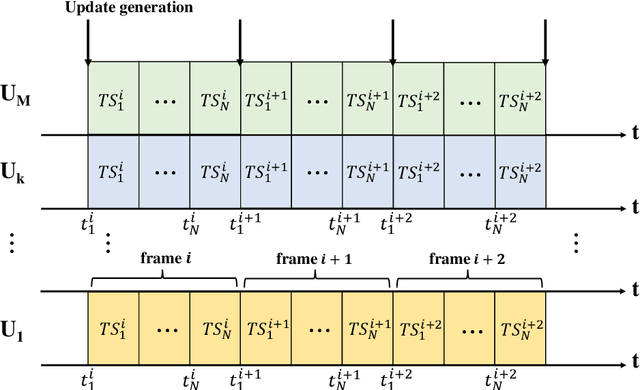
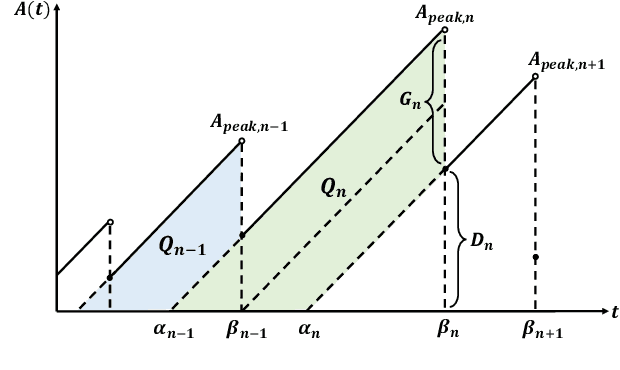
As an evolving successor to the mobile Internet, the extended reality (XR) devices can generate a fully digital immersive environment similar to the real world, integrating integrating virtual and real-world elements. However, in addition to the difficulties encountered in traditional communications, there emerge a range of new challenges such as ultra-massive access, real-time synchronization as well as unprecedented amount of multi-modal data transmission and processing. To address these challenges, semantic communications might be harnessed in support of XR applications, whereas it lacks a practical and effective performance metric. For broadening a new path for evaluating semantic communications, in this paper, we construct a multi-user uplink non-orthogonal multiple access (NOMA) system to analyze its transmission performance by harnessing a novel metric called age of incorrect information (AoII). First, we derive the average semantic similarity of all the users based on DeepSC and obtain the closed-form expressions for the packets' age of information (AoI) relying on queue theory. Besides, we formulate a non-convex optimization problem for the proposed AoII which combines both error-and AoI-based performance under the constraints of semantic rate, transmit power and status update rate. Finally, in order to solve the problem, we apply an exact linear search based algorithm for finding the optimal policy. Simulation results show that the AoII metric can beneficially evaluate both the error- and AoI-based transmission performance simultaneously.
How Curvature Enhance the Adaptation Power of Framelet GCNs
Jul 19, 2023
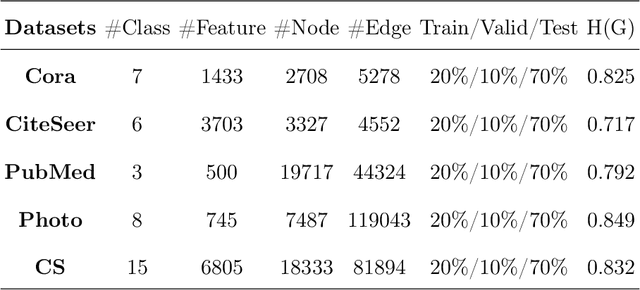
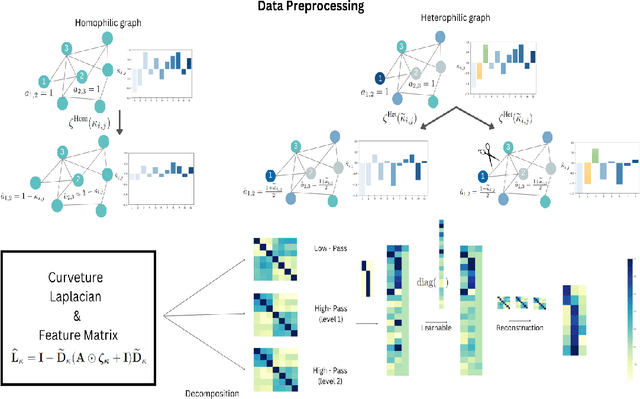
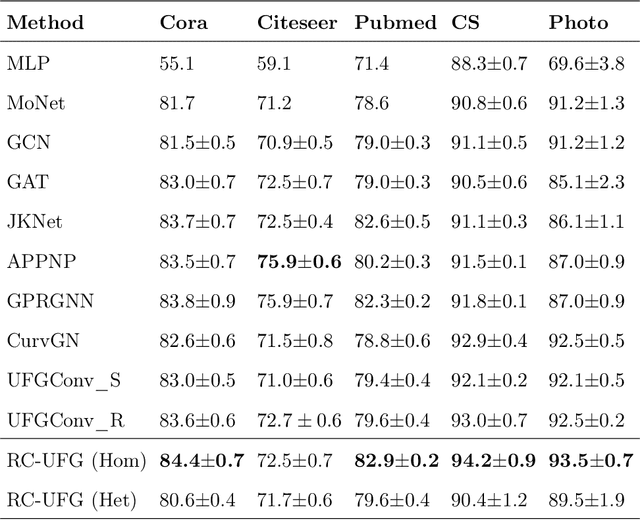
Graph neural network (GNN) has been demonstrated powerful in modeling graph-structured data. However, despite many successful cases of applying GNNs to various graph classification and prediction tasks, whether the graph geometrical information has been fully exploited to enhance the learning performance of GNNs is not yet well understood. This paper introduces a new approach to enhance GNN by discrete graph Ricci curvature. Specifically, the graph Ricci curvature defined on the edges of a graph measures how difficult the information transits on one edge from one node to another based on their neighborhoods. Motivated by the geometric analogy of Ricci curvature in the graph setting, we prove that by inserting the curvature information with different carefully designed transformation function $\zeta$, several known computational issues in GNN such as over-smoothing can be alleviated in our proposed model. Furthermore, we verified that edges with very positive Ricci curvature (i.e., $\kappa_{i,j} \approx 1$) are preferred to be dropped to enhance model's adaption to heterophily graph and one curvature based graph edge drop algorithm is proposed. Comprehensive experiments show that our curvature-based GNN model outperforms the state-of-the-art baselines in both homophily and heterophily graph datasets, indicating the effectiveness of involving graph geometric information in GNNs.
Machine Learning Applications In Healthcare: The State Of Knowledge and Future Directions
Jul 26, 2023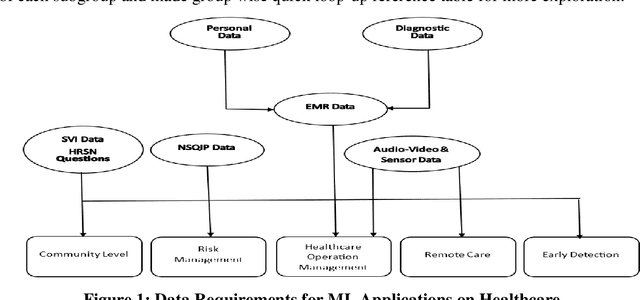


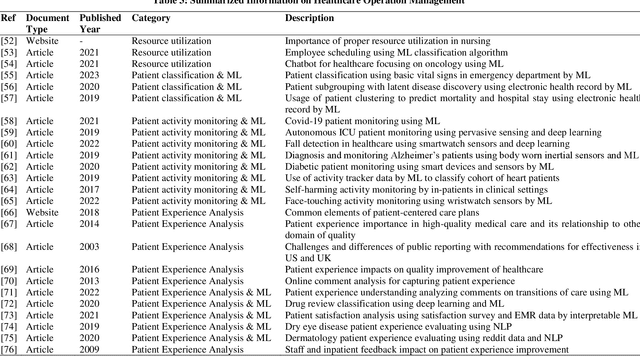
Detection of easily missed hidden patterns with fast processing power makes machine learning (ML) indispensable to today's healthcare system. Though many ML applications have already been discovered and many are still under investigation, only a few have been adopted by current healthcare systems. As a result, there exists an enormous opportunity in healthcare system for ML but distributed information, scarcity of properly arranged and easily explainable documentation in related sector are major impede which are making ML applications difficult to healthcare professionals. This study aimed to gather ML applications in different areas of healthcare concisely and more effectively so that necessary information can be accessed immediately with relevant references. We divided our study into five major groups: community level work, risk management/ preventive care, healthcare operation management, remote care, and early detection. Dividing these groups into subgroups, we provided relevant references with description in tabular form for quick access. Our objective is to inform people about ML applicability in healthcare industry, reduce the knowledge gap of clinicians about the ML applications and motivate healthcare professionals towards more machine learning based healthcare system.
HyperFed: Hyperbolic Prototypes Exploration with Consistent Aggregation for Non-IID Data in Federated Learning
Jul 26, 2023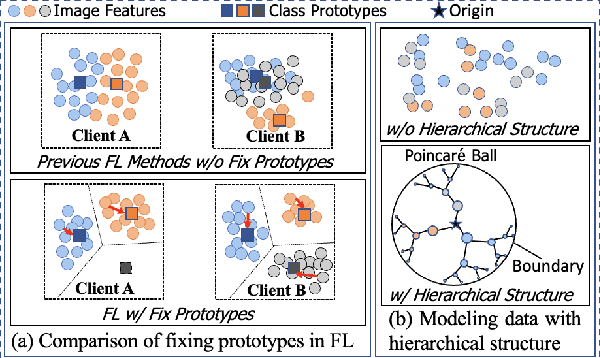
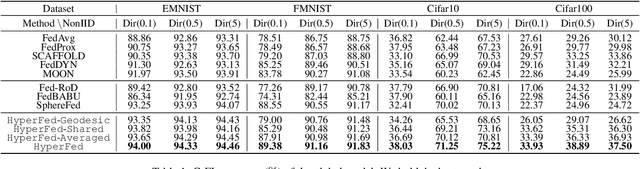
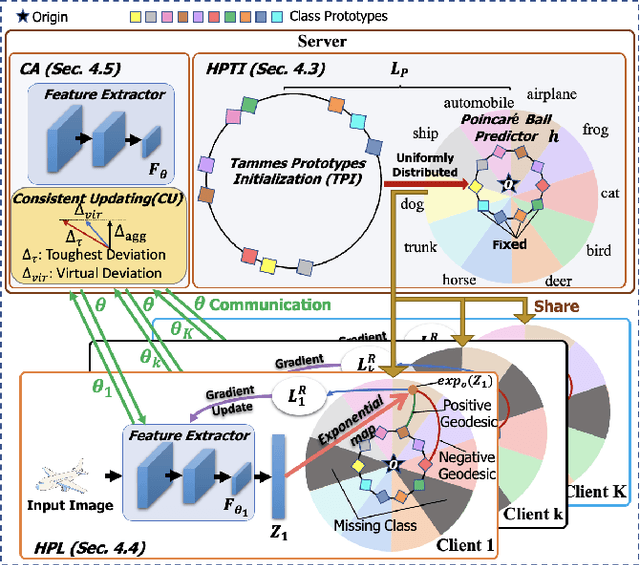
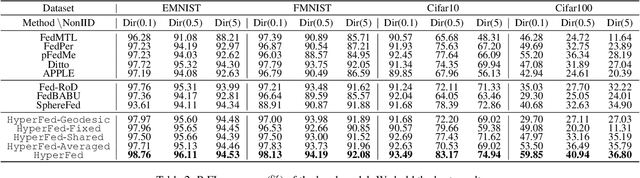
Federated learning (FL) collaboratively models user data in a decentralized way. However, in the real world, non-identical and independent data distributions (non-IID) among clients hinder the performance of FL due to three issues, i.e., (1) the class statistics shifting, (2) the insufficient hierarchical information utilization, and (3) the inconsistency in aggregating clients. To address the above issues, we propose HyperFed which contains three main modules, i.e., hyperbolic prototype Tammes initialization (HPTI), hyperbolic prototype learning (HPL), and consistent aggregation (CA). Firstly, HPTI in the server constructs uniformly distributed and fixed class prototypes, and shares them with clients to match class statistics, further guiding consistent feature representation for local clients. Secondly, HPL in each client captures the hierarchical information in local data with the supervision of shared class prototypes in the hyperbolic model space. Additionally, CA in the server mitigates the impact of the inconsistent deviations from clients to server. Extensive studies of four datasets prove that HyperFed is effective in enhancing the performance of FL under the non-IID set.
Comparison of Point Cloud and Image-based Models for Calorimeter Fast Simulation
Jul 31, 2023
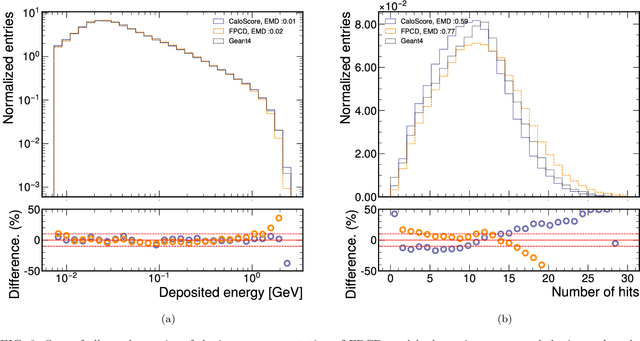
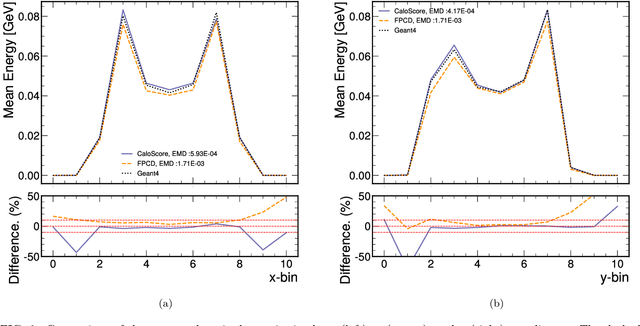
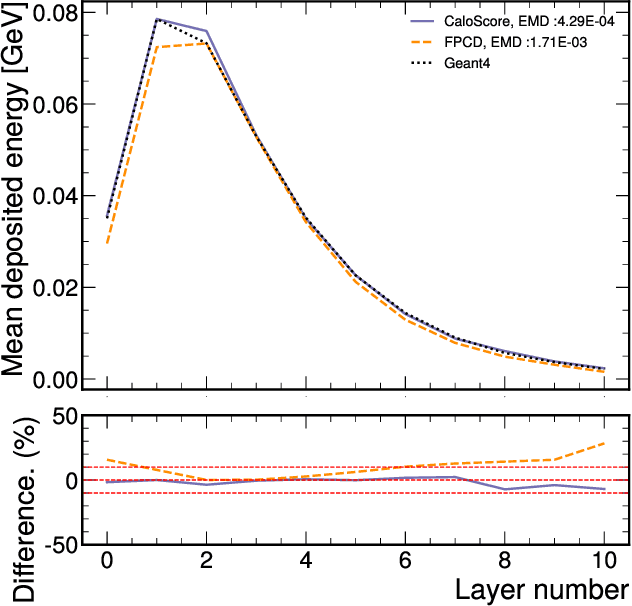
Score based generative models are a new class of generative models that have been shown to accurately generate high dimensional calorimeter datasets. Recent advances in generative models have used images with 3D voxels to represent and model complex calorimeter showers. Point clouds, however, are likely a more natural representation of calorimeter showers, particularly in calorimeters with high granularity. Point clouds preserve all of the information of the original simulation, more naturally deal with sparse datasets, and can be implemented with more compact models and data files. In this work, two state-of-the-art score based models are trained on the same set of calorimeter simulation and directly compared.
Occupancy Grid Map to Pose Graph-based Map: Robust BIM-based 2D-LiDAR Localization for Lifelong Indoor Navigation in Changing and Dynamic Environments
Aug 10, 2023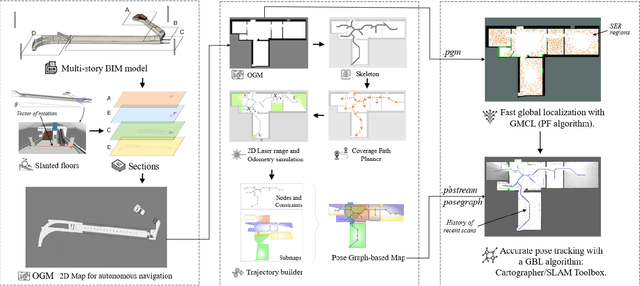

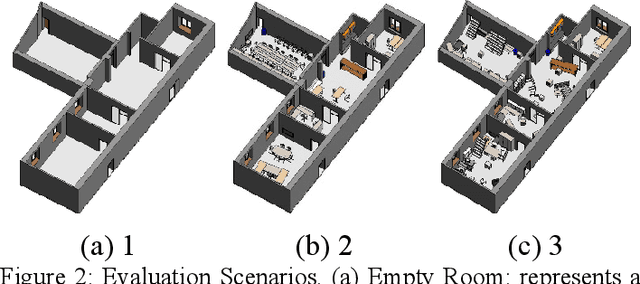
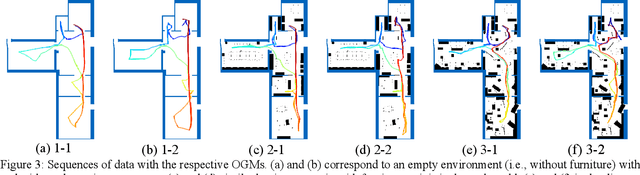
Several studies rely on the de facto standard Adaptive Monte Carlo Localization (AMCL) method to localize a robot in an Occupancy Grid Map (OGM) extracted from a building information model (BIM model). However, most of these studies assume that the BIM model precisely represents the real world, which is rarely true. Discrepancies between the reference BIM model and the real world (Scan-BIM deviations) are not only due to furniture or clutter but also the usual as-planned and as-built deviations that exist with any model created in the design phase. These deviations affect the accuracy of AMCL drastically. This paper proposes an open-source method to generate appropriate Pose Graph-based maps from BIM models for robust 2D-LiDAR localization in changing and dynamic environments. First, 2D OGMs are automatically generated from complex BIM models. These OGMs only represent structural elements allowing indoor autonomous robot navigation. Then, an efficient technique converts these 2D OGMs into Pose Graph-based maps enabling more accurate robot pose tracking. Finally, we leverage the different map representations for accurate, robust localization with a combination of state-of-the-art algorithms. Moreover, we provide a quantitative comparison of various state-of-the-art localization algorithms in three simulated scenarios with varying levels of Scan-BIM deviations and dynamic agents. More precisely, we compare two Particle Filter (PF) algorithms: AMCL and General Monte Carlo Localization (GMCL); and two Graph-based Localization (GBL) methods: Google's Cartographer and SLAM Toolbox, solving the global localization and pose tracking problems. The numerous experiments demonstrate that the proposed method contributes to a robust localization with an as-designed BIM model or a sparse OGM in changing and dynamic environments, outperforming the conventional AMCL in accuracy and robustness.
Preemptive Detection of Fake Accounts on Social Networks via Multi-Class Preferential Attachment Classifiers
Aug 10, 2023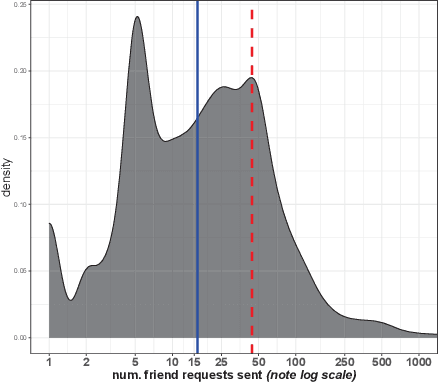
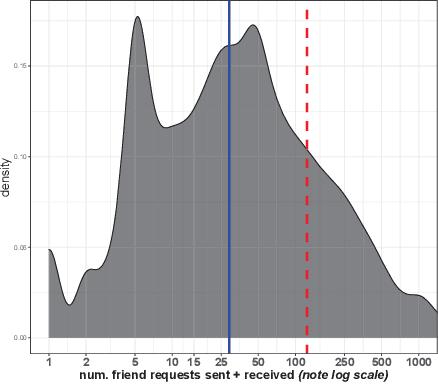
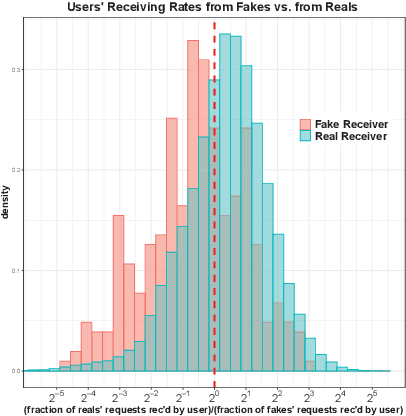
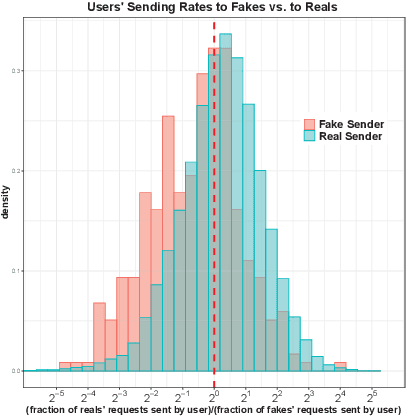
In this paper, we describe a new algorithm called Preferential Attachment k-class Classifier (PreAttacK) for detecting fake accounts in a social network. Recently, several algorithms have obtained high accuracy on this problem. However, they have done so by relying on information about fake accounts' friendships or the content they share with others--the very things we seek to prevent. PreAttacK represents a significant departure from these approaches. We provide some of the first detailed distributional analyses of how new fake (and real) accounts first attempt to request friends after joining a major network (Facebook). We show that even before a new account has made friends or shared content, these initial friend request behaviors evoke a natural multi-class extension of the canonical Preferential Attachment model of social network growth. We use this model to derive a new algorithm, PreAttacK. We prove that in relevant problem instances, PreAttacK near-optimally approximates the posterior probability that a new account is fake under this multi-class Preferential Attachment model of new accounts' (not-yet-answered) friend requests. These are the first provable guarantees for fake account detection that apply to new users, and that do not require strong homophily assumptions. This principled approach also makes PreAttacK the only algorithm with provable guarantees that obtains state-of-the-art performance on new users on the global Facebook network, where it converges to AUC=0.9 after new users send + receive a total of just 20 not-yet-answered friend requests. For comparison, state-of-the-art benchmarks do not obtain this AUC even after observing additional data on new users' first 100 friend requests. Thus, unlike mainstream algorithms, PreAttacK converges before the median new fake account has made a single friendship (accepted friend request) with a human.
Degeneration-Tuning: Using Scrambled Grid shield Unwanted Concepts from Stable Diffusion
Aug 08, 2023
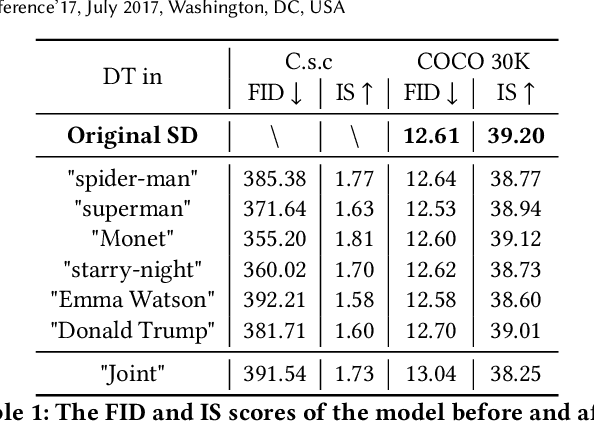

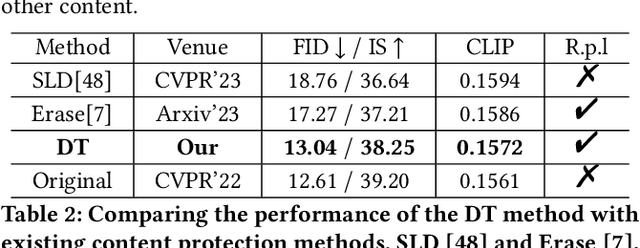
Owing to the unrestricted nature of the content in the training data, large text-to-image diffusion models, such as Stable Diffusion (SD), are capable of generating images with potentially copyrighted or dangerous content based on corresponding textual concepts information. This includes specific intellectual property (IP), human faces, and various artistic styles. However, Negative Prompt, a widely used method for content removal, frequently fails to conceal this content due to inherent limitations in its inference logic. In this work, we propose a novel strategy named \textbf{Degeneration-Tuning (DT)} to shield contents of unwanted concepts from SD weights. By utilizing Scrambled Grid to reconstruct the correlation between undesired concepts and their corresponding image domain, we guide SD to generate meaningless content when such textual concepts are provided as input. As this adaptation occurs at the level of the model's weights, the SD, after DT, can be grafted onto other conditional diffusion frameworks like ControlNet to shield unwanted concepts. In addition to qualitatively showcasing the effectiveness of our DT method in protecting various types of concepts, a quantitative comparison of the SD before and after DT indicates that the DT method does not significantly impact the generative quality of other contents. The FID and IS scores of the model on COCO-30K exhibit only minor changes after DT, shifting from 12.61 and 39.20 to 13.04 and 38.25, respectively, which clearly outperforms the previous methods.