 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
S3IM: Stochastic Structural SIMilarity and Its Unreasonable Effectiveness for Neural Fields
Aug 14, 2023

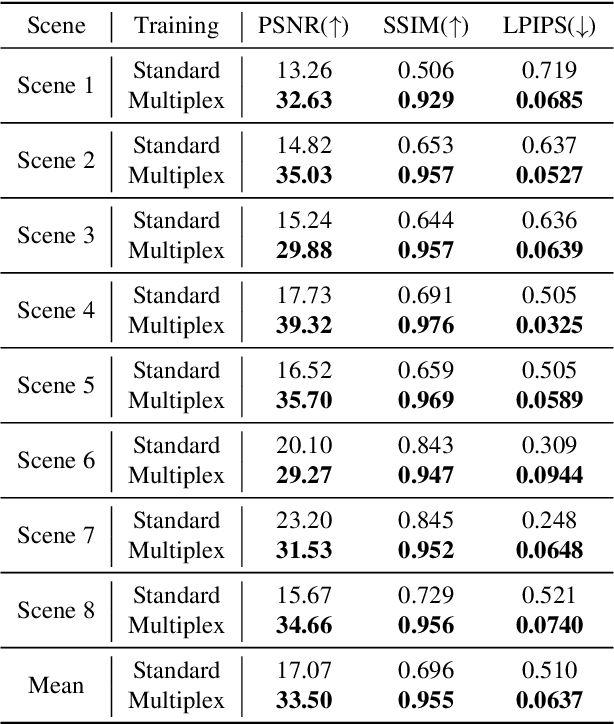
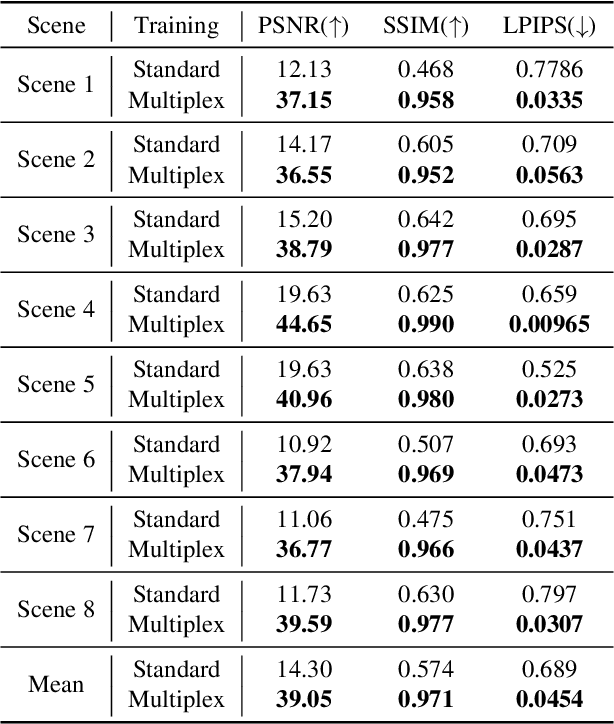

Recently, Neural Radiance Field (NeRF) has shown great success in rendering novel-view images of a given scene by learning an implicit representation with only posed RGB images. NeRF and relevant neural field methods (e.g., neural surface representation) typically optimize a point-wise loss and make point-wise predictions, where one data point corresponds to one pixel. Unfortunately, this line of research failed to use the collective supervision of distant pixels, although it is known that pixels in an image or scene can provide rich structural information. To the best of our knowledge, we are the first to design a nonlocal multiplex training paradigm for NeRF and relevant neural field methods via a novel Stochastic Structural SIMilarity (S3IM) loss that processes multiple data points as a whole set instead of process multiple inputs independently. Our extensive experiments demonstrate the unreasonable effectiveness of S3IM in improving NeRF and neural surface representation for nearly free. The improvements of quality metrics can be particularly significant for those relatively difficult tasks: e.g., the test MSE loss unexpectedly drops by more than 90% for TensoRF and DVGO over eight novel view synthesis tasks; a 198% F-score gain and a 64% Chamfer $L_{1}$ distance reduction for NeuS over eight surface reconstruction tasks. Moreover, S3IM is consistently robust even with sparse inputs, corrupted images, and dynamic scenes.
Natural Language is All a Graph Needs
Aug 14, 2023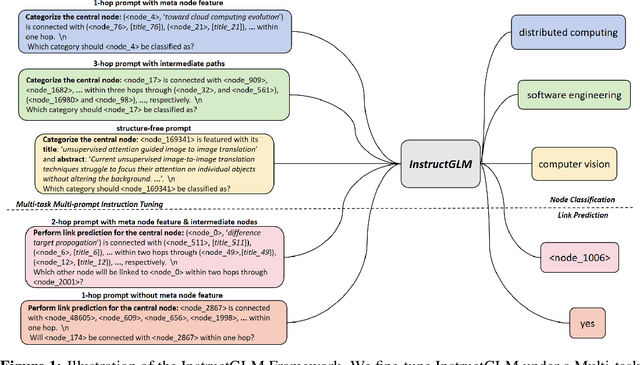
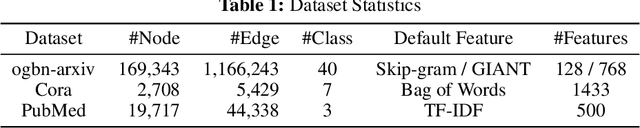
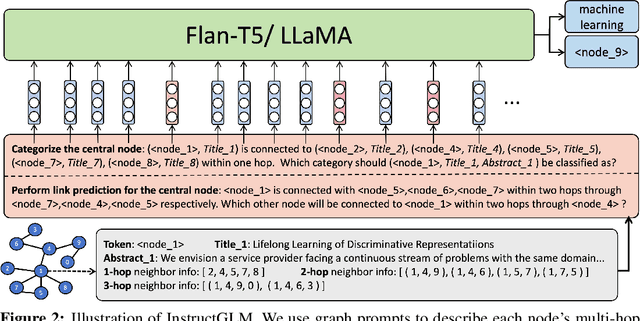
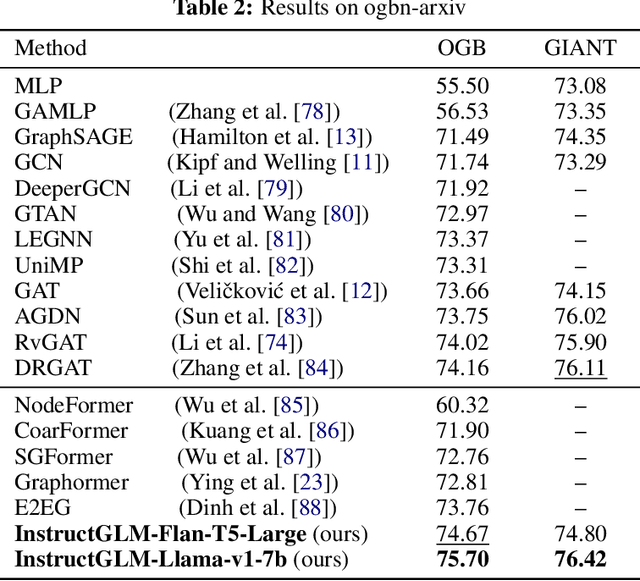
The emergence of large-scale pre-trained language models, such as ChatGPT, has revolutionized various research fields in artificial intelligence. Transformers-based large language models (LLMs) have gradually replaced CNNs and RNNs to unify fields of computer vision and natural language processing. Compared with the data that exists relatively independently such as images, videos or texts, graph is a type of data that contains rich structural and relational information. Meanwhile, natural language, as one of the most expressive mediums, excels in describing complex structures. However, existing work on incorporating graph learning problems into the generative language modeling framework remains very limited. As the importance of language models continues to grow, it becomes essential to explore whether LLMs can also replace GNNs as the foundational model for graphs. In this paper, we propose InstructGLM (Instruction-finetuned Graph Language Model), systematically design highly scalable prompts based on natural language instructions, and use natural language to describe the geometric structure and node features of the graph for instruction tuning an LLMs to perform learning and inference on graphs in a generative manner. Our method exceeds all competitive GNN baselines on ogbn-arxiv, Cora and PubMed datasets, which demonstrates the effectiveness of our method and sheds light on generative language models replacing GNNs as the foundation model for graph machine learning.
PGT-Net: Progressive Guided Multi-task Neural Network for Small-area Wet Fingerprint Denoising and Recognition
Aug 14, 2023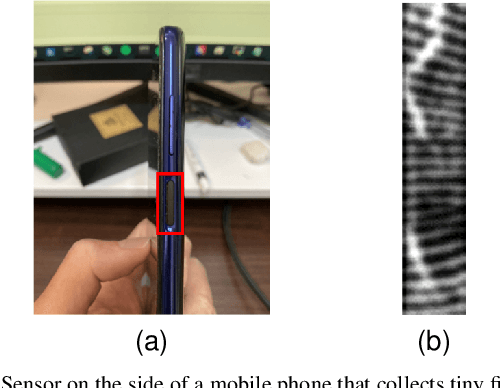

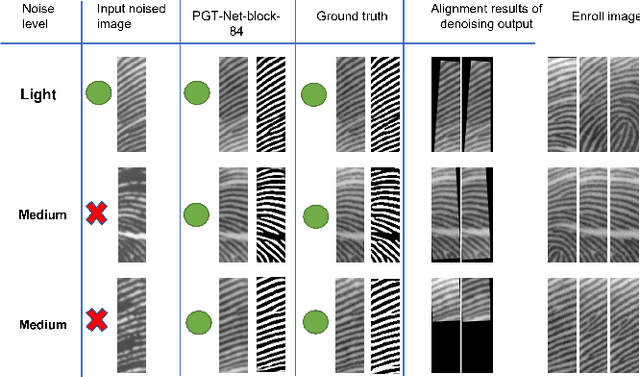

Fingerprint recognition on mobile devices is an important method for identity verification. However, real fingerprints usually contain sweat and moisture which leads to poor recognition performance. In addition, for rolling out slimmer and thinner phones, technology companies reduce the size of recognition sensors by embedding them with the power button. Therefore, the limited size of fingerprint data also increases the difficulty of recognition. Denoising the small-area wet fingerprint images to clean ones becomes crucial to improve recognition performance. In this paper, we propose an end-to-end trainable progressive guided multi-task neural network (PGT-Net). The PGT-Net includes a shared stage and specific multi-task stages, enabling the network to train binary and non-binary fingerprints sequentially. The binary information is regarded as guidance for output enhancement which is enriched with the ridge and valley details. Moreover, a novel residual scaling mechanism is introduced to stabilize the training process. Experiment results on the FW9395 and FT-lightnoised dataset provided by FocalTech shows that PGT-Net has promising performance on the wet-fingerprint denoising and significantly improves the fingerprint recognition rate (FRR). On the FT-lightnoised dataset, the FRR of fingerprint recognition can be declined from 17.75% to 4.47%. On the FW9395 dataset, the FRR of fingerprint recognition can be declined from 9.45% to 1.09%.
Downstream-agnostic Adversarial Examples
Aug 14, 2023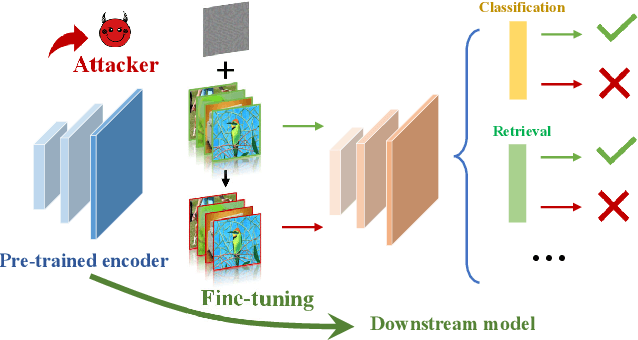
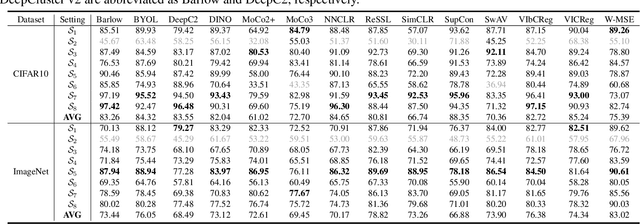
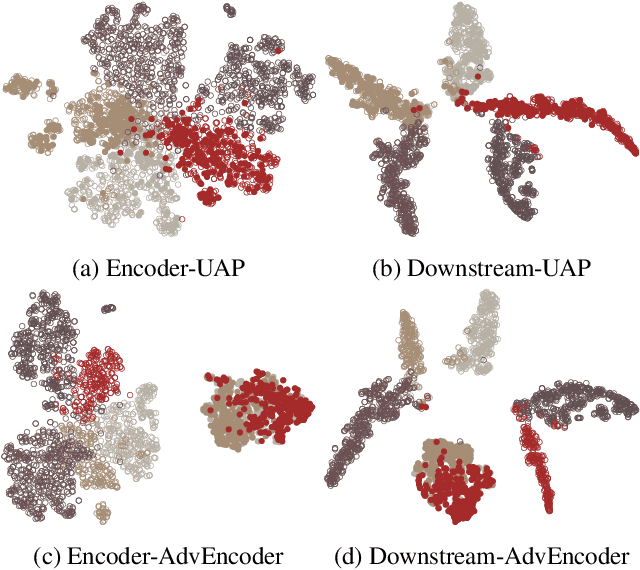
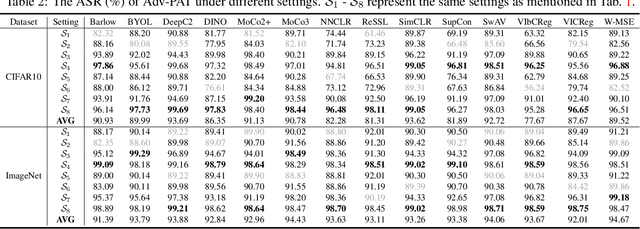
Self-supervised learning usually uses a large amount of unlabeled data to pre-train an encoder which can be used as a general-purpose feature extractor, such that downstream users only need to perform fine-tuning operations to enjoy the benefit of "large model". Despite this promising prospect, the security of pre-trained encoder has not been thoroughly investigated yet, especially when the pre-trained encoder is publicly available for commercial use. In this paper, we propose AdvEncoder, the first framework for generating downstream-agnostic universal adversarial examples based on the pre-trained encoder. AdvEncoder aims to construct a universal adversarial perturbation or patch for a set of natural images that can fool all the downstream tasks inheriting the victim pre-trained encoder. Unlike traditional adversarial example works, the pre-trained encoder only outputs feature vectors rather than classification labels. Therefore, we first exploit the high frequency component information of the image to guide the generation of adversarial examples. Then we design a generative attack framework to construct adversarial perturbations/patches by learning the distribution of the attack surrogate dataset to improve their attack success rates and transferability. Our results show that an attacker can successfully attack downstream tasks without knowing either the pre-training dataset or the downstream dataset. We also tailor four defenses for pre-trained encoders, the results of which further prove the attack ability of AdvEncoder.
Accurate, Explainable, and Private Models: Providing Recourse While Minimizing Training Data Leakage
Aug 08, 2023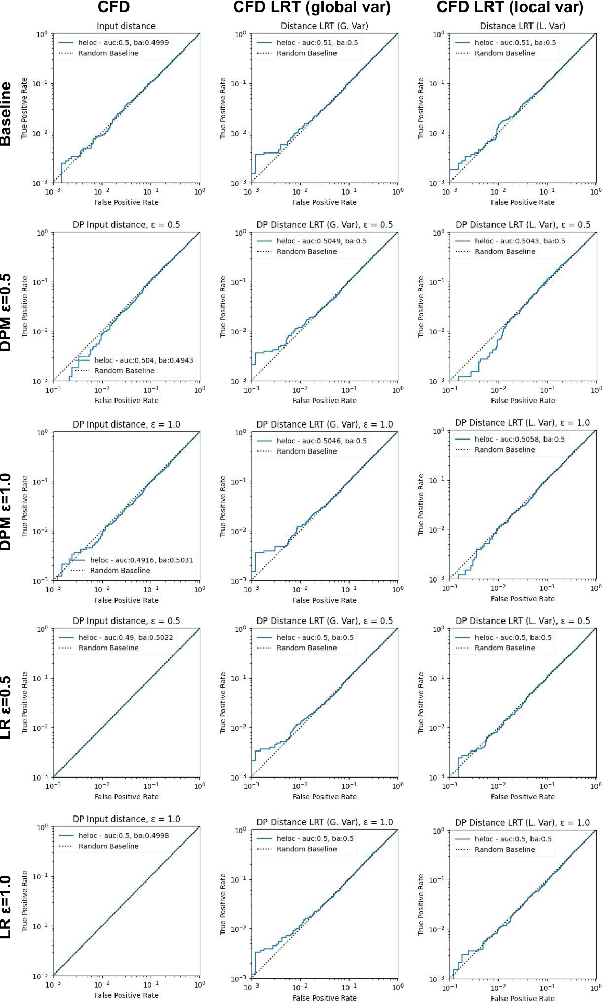
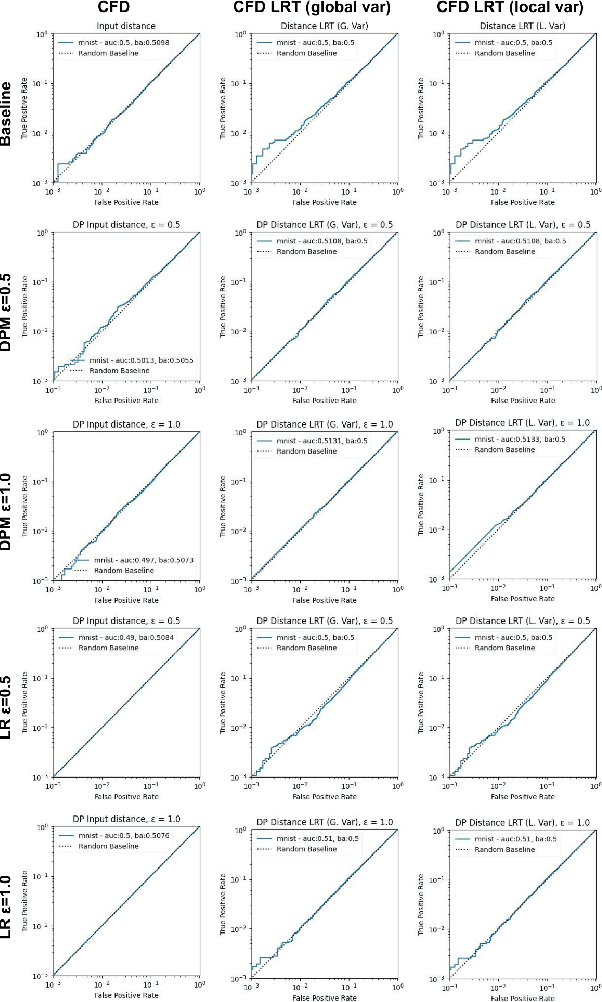
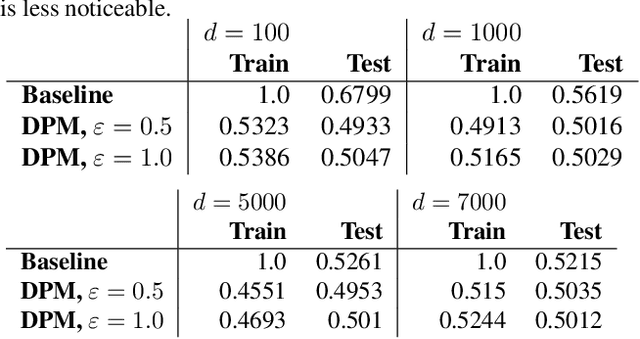
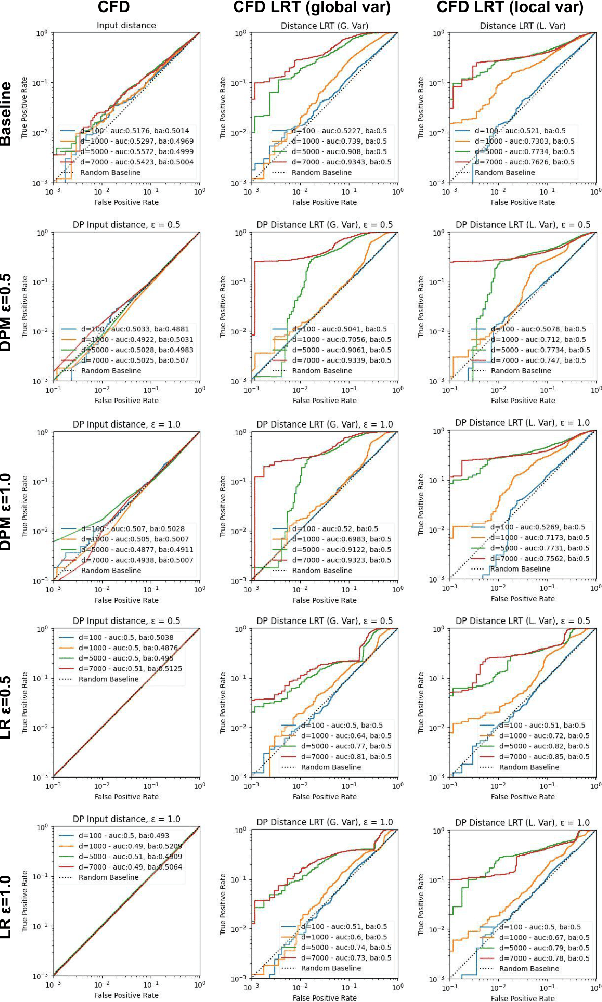
Machine learning models are increasingly utilized across impactful domains to predict individual outcomes. As such, many models provide algorithmic recourse to individuals who receive negative outcomes. However, recourse can be leveraged by adversaries to disclose private information. This work presents the first attempt at mitigating such attacks. We present two novel methods to generate differentially private recourse: Differentially Private Model (DPM) and Laplace Recourse (LR). Using logistic regression classifiers and real world and synthetic datasets, we find that DPM and LR perform well in reducing what an adversary can infer, especially at low FPR. When training dataset size is large enough, we find particular success in preventing privacy leakage while maintaining model and recourse accuracy with our novel LR method.
Fusing VHR Post-disaster Aerial Imagery and LiDAR Data for Roof Classification in the Caribbean using CNNs
Jul 30, 2023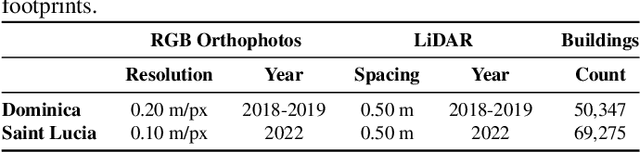

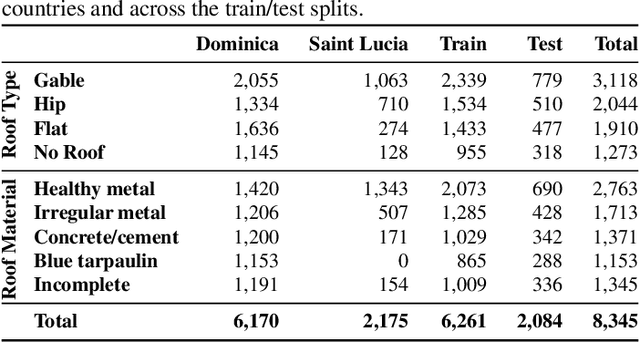

Accurate and up-to-date information on building characteristics is essential for vulnerability assessment; however, the high costs and long timeframes associated with conducting traditional field surveys can be an obstacle to obtaining critical exposure datasets needed for disaster risk management. In this work, we leverage deep learning techniques for the automated classification of roof characteristics from very high-resolution orthophotos and airborne LiDAR data obtained in Dominica following Hurricane Maria in 2017. We demonstrate that the fusion of multimodal earth observation data performs better than using any single data source alone. Using our proposed methods, we achieve F1 scores of 0.93 and 0.92 for roof type and roof material classification, respectively. This work is intended to help governments produce more timely building information to improve resilience and disaster response in the Caribbean.
Time Travel in LLMs: Tracing Data Contamination in Large Language Models
Aug 16, 2023Data contamination, i.e., the presence of test data from downstream tasks in the training data of large language models (LLMs), is a potential major issue in understanding LLMs' effectiveness on other tasks. We propose a straightforward yet effective method for identifying data contamination within LLMs. At its core, our approach starts by identifying potential contamination in individual instances that are drawn from a small random sample; using this information, our approach then assesses if an entire dataset partition is contaminated. To estimate contamination of individual instances, we employ "guided instruction:" a prompt consisting of the dataset name, partition type, and the initial segment of a reference instance, asking the LLM to complete it. An instance is flagged as contaminated if the LLM's output either exactly or closely matches the latter segment of the reference. To understand if an entire partition is contaminated, we propose two ideas. The first idea marks a dataset partition as contaminated if the average overlap score with the reference instances (as measured by ROUGE or BLEURT) is statistically significantly better with the guided instruction vs. a general instruction that does not include the dataset and partition name. The second idea marks a dataset as contaminated if a classifier based on GPT-4 with in-context learning prompting marks multiple instances as contaminated. Our best method achieves an accuracy between 92% and 100% in detecting if an LLM is contaminated with seven datasets, containing train and test/validation partitions, when contrasted with manual evaluation by human expert. Further, our findings indicate that GPT-4 is contaminated with AG News, WNLI, and XSum datasets.
Microstructure-Empowered Stock Factor Extraction and Utilization
Aug 16, 2023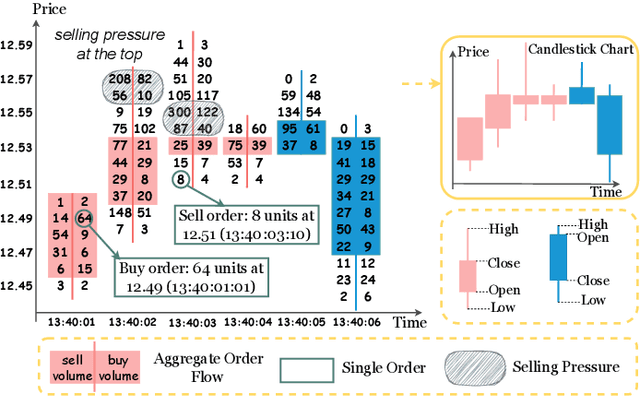
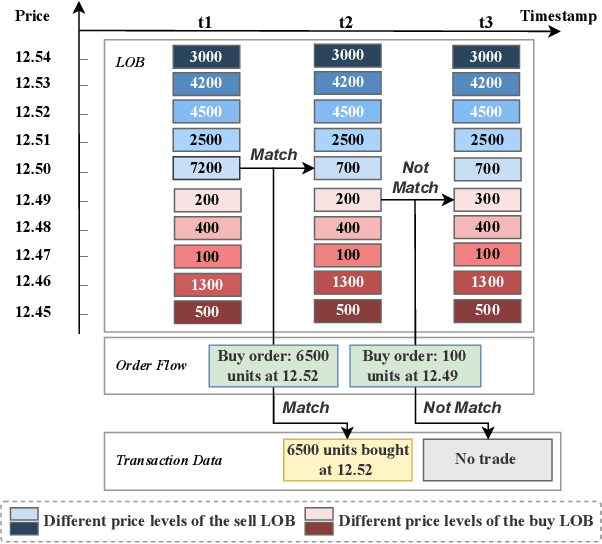
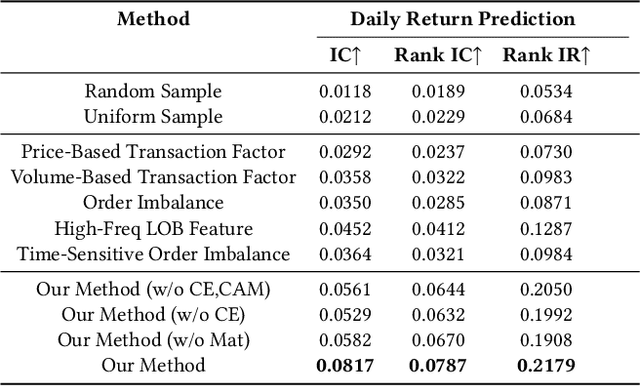
High-frequency quantitative investment is a crucial aspect of stock investment. Notably, order flow data plays a critical role as it provides the most detailed level of information among high-frequency trading data, including comprehensive data from the order book and transaction records at the tick level. The order flow data is extremely valuable for market analysis as it equips traders with essential insights for making informed decisions. However, extracting and effectively utilizing order flow data present challenges due to the large volume of data involved and the limitations of traditional factor mining techniques, which are primarily designed for coarser-level stock data. To address these challenges, we propose a novel framework that aims to effectively extract essential factors from order flow data for diverse downstream tasks across different granularities and scenarios. Our method consists of a Context Encoder and an Factor Extractor. The Context Encoder learns an embedding for the current order flow data segment's context by considering both the expected and actual market state. In addition, the Factor Extractor uses unsupervised learning methods to select such important signals that are most distinct from the majority within the given context. The extracted factors are then utilized for downstream tasks. In empirical studies, our proposed framework efficiently handles an entire year of stock order flow data across diverse scenarios, offering a broader range of applications compared to existing tick-level approaches that are limited to only a few days of stock data. We demonstrate that our method extracts superior factors from order flow data, enabling significant improvement for stock trend prediction and order execution tasks at the second and minute level.
Multispectral Quantitative Phase Imaging Using a Diffractive Optical Network
Aug 05, 2023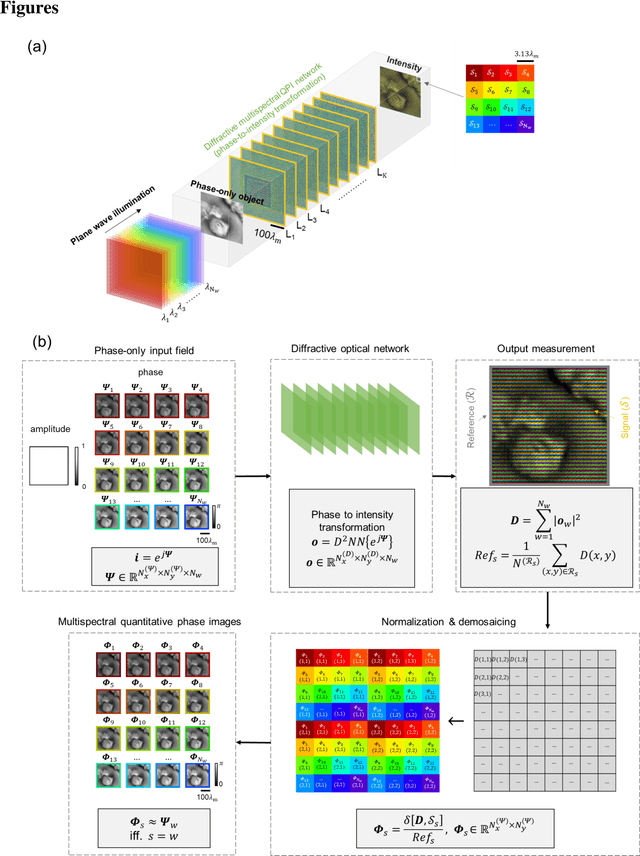
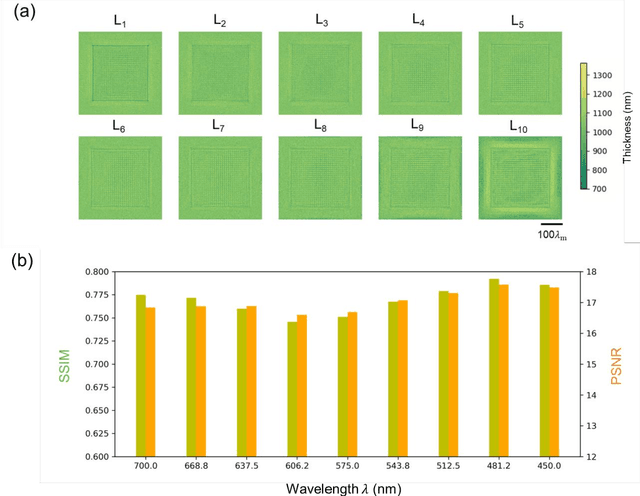
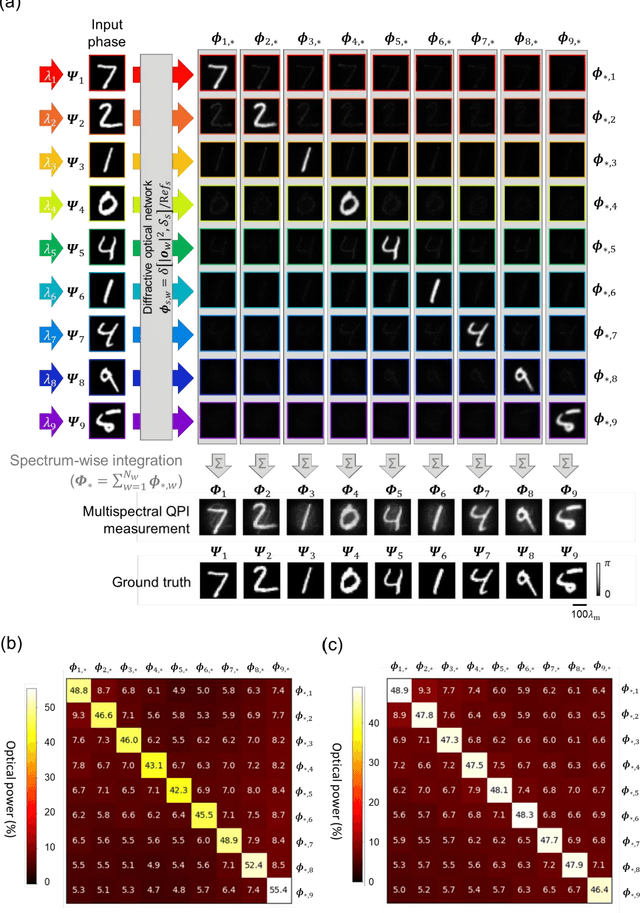
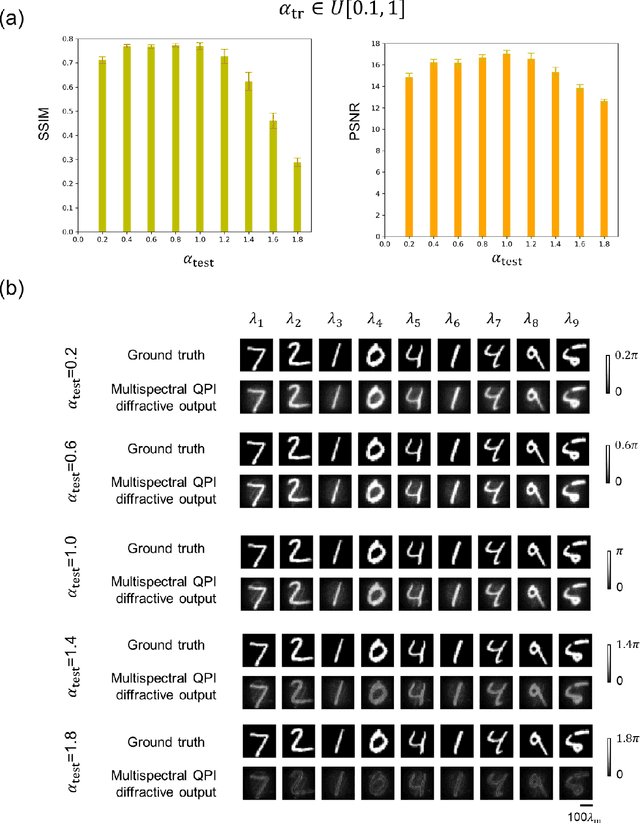
As a label-free imaging technique, quantitative phase imaging (QPI) provides optical path length information of transparent specimens for various applications in biology, materials science, and engineering. Multispectral QPI measures quantitative phase information across multiple spectral bands, permitting the examination of wavelength-specific phase and dispersion characteristics of samples. Here, we present the design of a diffractive processor that can all-optically perform multispectral quantitative phase imaging of transparent phase-only objects in a snapshot. Our design utilizes spatially engineered diffractive layers, optimized through deep learning, to encode the phase profile of the input object at a predetermined set of wavelengths into spatial intensity variations at the output plane, allowing multispectral QPI using a monochrome focal plane array. Through numerical simulations, we demonstrate diffractive multispectral processors to simultaneously perform quantitative phase imaging at 9 and 16 target spectral bands in the visible spectrum. These diffractive multispectral processors maintain uniform performance across all the wavelength channels, revealing a decent QPI performance at each target wavelength. The generalization of these diffractive processor designs is validated through numerical tests on unseen objects, including thin Pap smear images. Due to its all-optical processing capability using passive dielectric diffractive materials, this diffractive multispectral QPI processor offers a compact and power-efficient solution for high-throughput quantitative phase microscopy and spectroscopy. This framework can operate at different parts of the electromagnetic spectrum and be used for a wide range of phase imaging and sensing applications.
MeMOTR: Long-Term Memory-Augmented Transformer for Multi-Object Tracking
Jul 31, 2023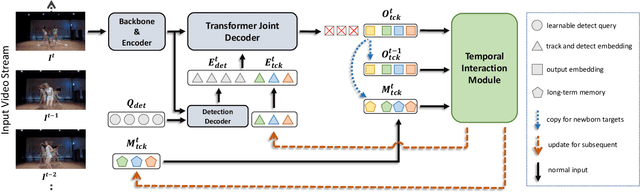
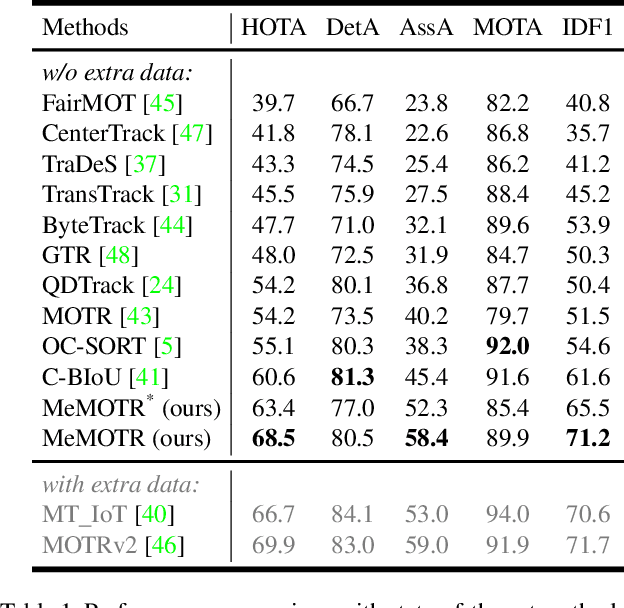
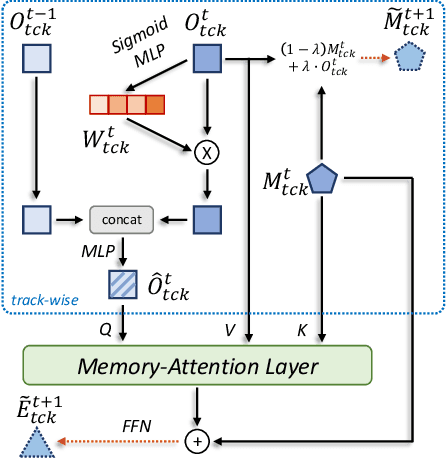
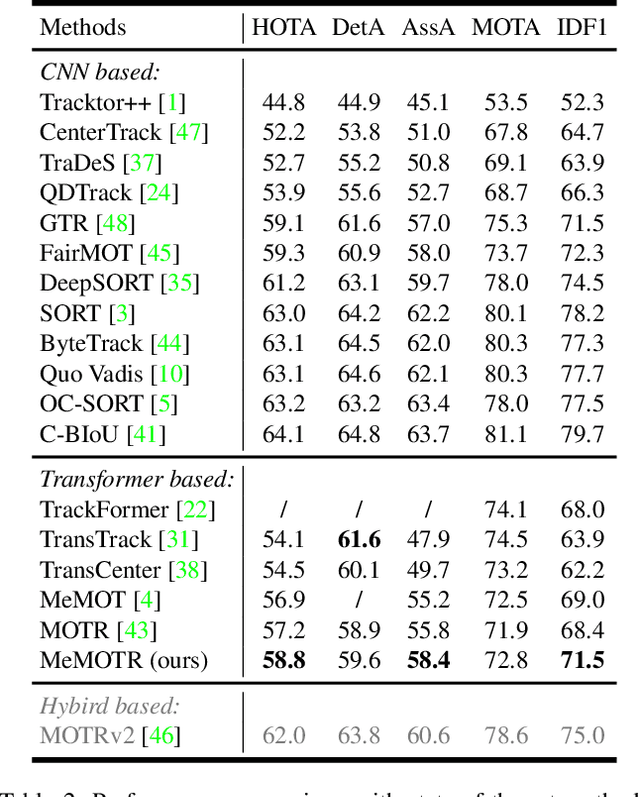
As a video task, Multiple Object Tracking (MOT) is expected to capture temporal information of targets effectively. Unfortunately, most existing methods only explicitly exploit the object features between adjacent frames, while lacking the capacity to model long-term temporal information. In this paper, we propose MeMOTR, a long-term memory-augmented Transformer for multi-object tracking. Our method is able to make the same object's track embedding more stable and distinguishable by leveraging long-term memory injection with a customized memory-attention layer. This significantly improves the target association ability of our model. Experimental results on DanceTrack show that MeMOTR impressively surpasses the state-of-the-art method by 7.9% and 13.0% on HOTA and AssA metrics, respectively. Furthermore, our model also outperforms other Transformer-based methods on association performance on MOT17 and generalizes well on BDD100K. Code is available at https://github.com/MCG-NJU/MeMOTR.