 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EasyNet: An Easy Network for 3D Industrial Anomaly Detection
Aug 07, 2023
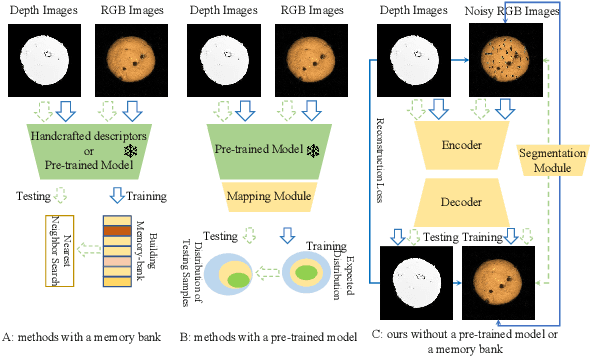
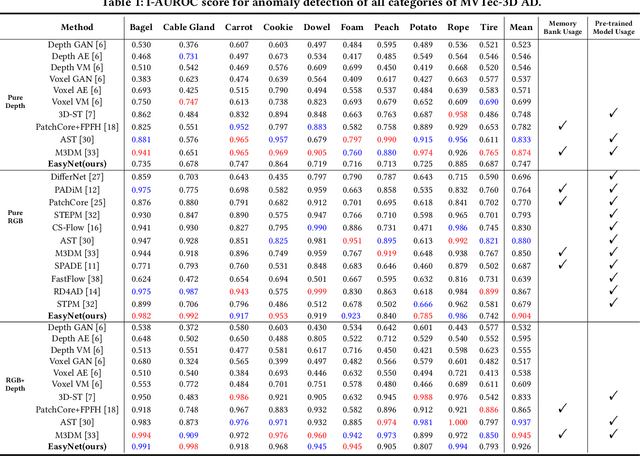
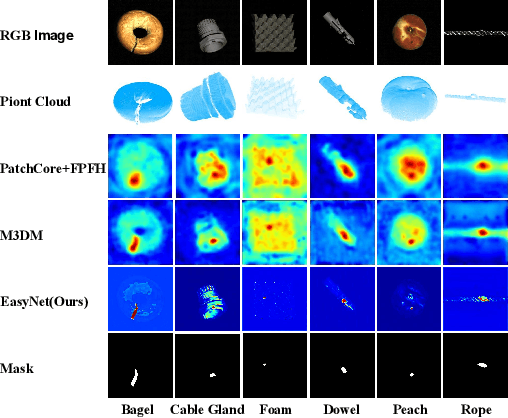
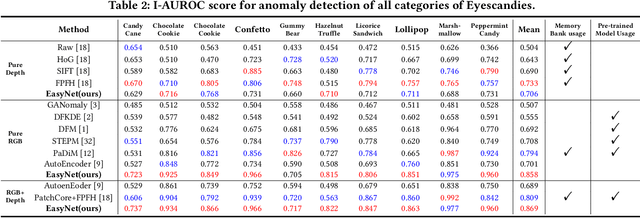
3D anomaly detection is an emerging and vital computer vision task in industrial manufacturing (IM). Recently many advanced algorithms have been published, but most of them cannot meet the needs of IM. There are several disadvantages: i) difficult to deploy on production lines since their algorithms heavily rely on large pre-trained models; ii) hugely increase storage overhead due to overuse of memory banks; iii) the inference speed cannot be achieved in real-time. To overcome these issues, we propose an easy and deployment-friendly network (called EasyNet) without using pre-trained models and memory banks: firstly, we design a multi-scale multi-modality feature encoder-decoder to accurately reconstruct the segmentation maps of anomalous regions and encourage the interaction between RGB images and depth images; secondly, we adopt a multi-modality anomaly segmentation network to achieve a precise anomaly map; thirdly, we propose an attention-based information entropy fusion module for feature fusion during inference, making it suitable for real-time deployment. Extensive experiments show that EasyNet achieves an anomaly detection AUROC of 92.6% without using pre-trained models and memory banks. In addition, EasyNet is faster than existing methods, with a high frame rate of 94.55 FPS on a Tesla V100 GPU.
Implicit Graph Neural Diffusion Based on Constrained Dirichlet Energy Minimization
Aug 07, 2023

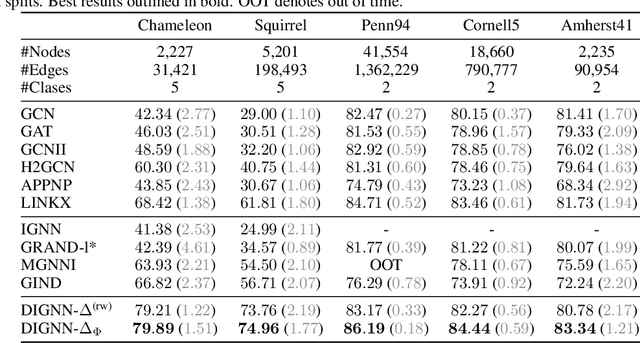
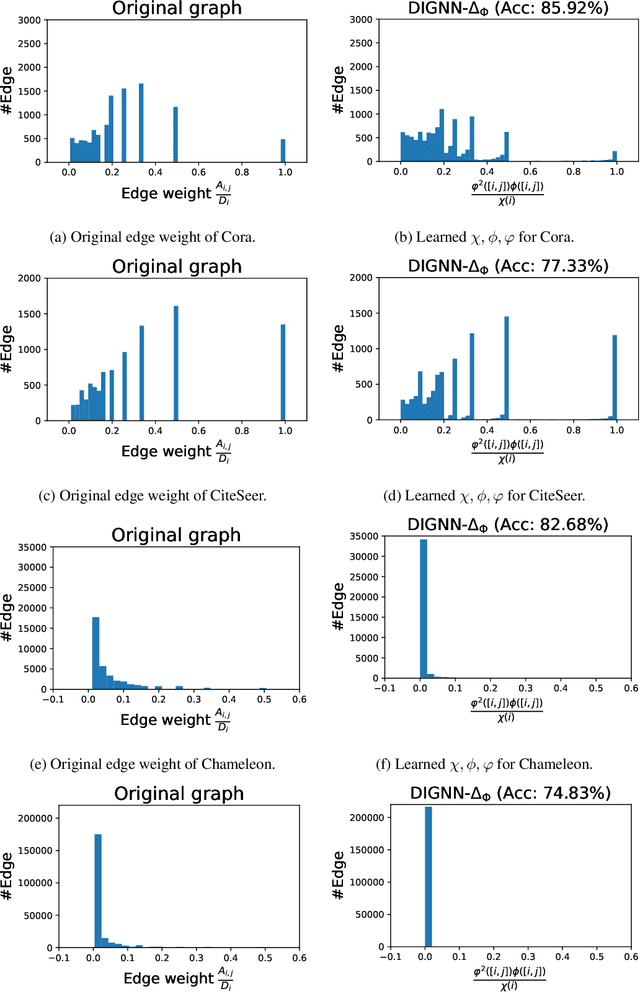
Implicit graph neural networks (GNNs) have emerged as a potential approach to enable GNNs to capture long-range dependencies effectively. However, poorly designed implicit GNN layers can experience over-smoothing or may have limited adaptability to learn data geometry, potentially hindering their performance in graph learning problems. To address these issues, we introduce a geometric framework to design implicit graph diffusion layers based on a parameterized graph Laplacian operator. Our framework allows learning the geometry of vertex and edge spaces, as well as the graph gradient operator from data. We further show how implicit GNN layers can be viewed as the fixed-point solution of a Dirichlet energy minimization problem and give conditions under which it may suffer from over-smoothing. To overcome the over-smoothing problem, we design our implicit graph diffusion layer as the solution of a Dirichlet energy minimization problem with constraints on vertex features, enabling it to trade off smoothing with the preservation of node feature information. With an appropriate hyperparameter set to be larger than the largest eigenvalue of the parameterized graph Laplacian, our framework guarantees a unique equilibrium and quick convergence. Our models demonstrate better performance than leading implicit and explicit GNNs on benchmark datasets for node and graph classification tasks, with substantial accuracy improvements observed for some datasets.
Imperceptible Physical Attack against Face Recognition Systems via LED Illumination Modulation
Aug 07, 2023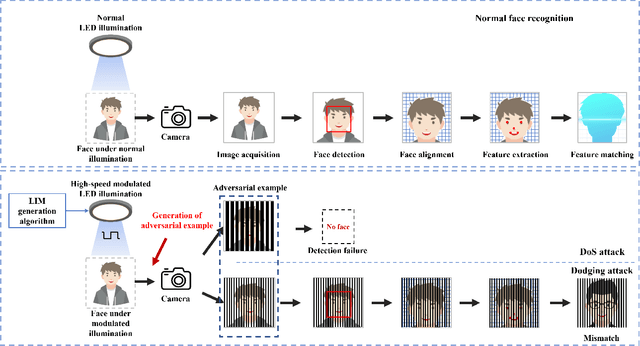
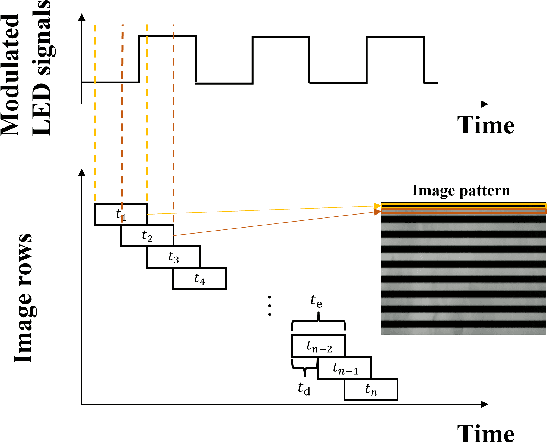
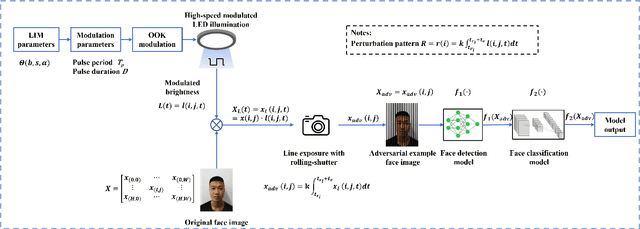

Although face recognition starts to play an important role in our daily life, we need to pay attention that data-driven face recognition vision systems are vulnerable to adversarial attacks. However, the current two categories of adversarial attacks, namely digital attacks and physical attacks both have drawbacks, with the former ones impractical and the latter one conspicuous, high-computational and inexecutable. To address the issues, we propose a practical, executable, inconspicuous and low computational adversarial attack based on LED illumination modulation. To fool the systems, the proposed attack generates imperceptible luminance changes to human eyes through fast intensity modulation of scene LED illumination and uses the rolling shutter effect of CMOS image sensors in face recognition systems to implant luminance information perturbation to the captured face images. In summary,we present a denial-of-service (DoS) attack for face detection and a dodging attack for face verification. We also evaluate their effectiveness against well-known face detection models, Dlib, MTCNN and RetinaFace , and face verification models, Dlib, FaceNet,and ArcFace.The extensive experiments show that the success rates of DoS attacks against face detection models reach 97.67%, 100%, and 100%, respectively, and the success rates of dodging attacks against all face verification models reach 100%.
A Comprehensive Evaluation and Analysis Study for Chinese Spelling Check
Jul 25, 2023


With the development of pre-trained models and the incorporation of phonetic and graphic information, neural models have achieved high scores in Chinese Spelling Check (CSC). However, it does not provide a comprehensive reflection of the models' capability due to the limited test sets. In this study, we abstract the representative model paradigm, implement it with nine structures and experiment them on comprehensive test sets we constructed with different purposes. We perform a detailed analysis of the results and find that: 1) Fusing phonetic and graphic information reasonably is effective for CSC. 2) Models are sensitive to the error distribution of the test set, which reflects the shortcomings of models and reveals the direction we should work on. 3) Whether or not the errors and contexts have been seen has a significant impact on models. 4) The commonly used benchmark, SIGHAN, can not reliably evaluate models' performance.
Fast Slate Policy Optimization: Going Beyond Plackett-Luce
Aug 03, 2023
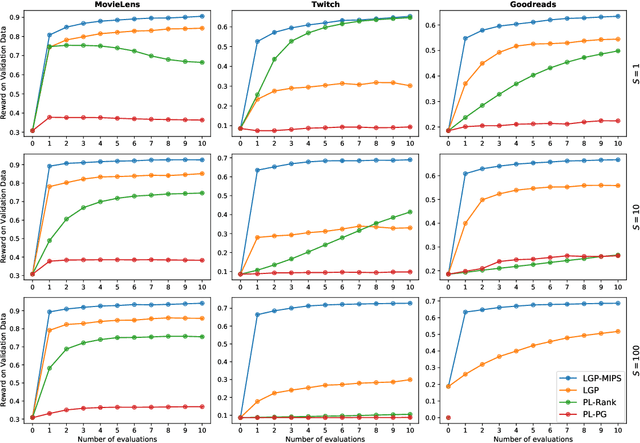
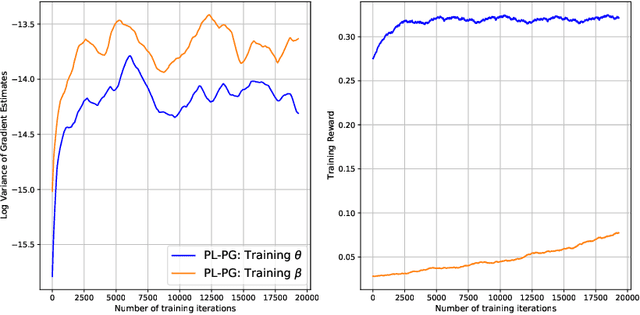
An increasingly important building block of large scale machine learning systems is based on returning slates; an ordered lists of items given a query. Applications of this technology include: search, information retrieval and recommender systems. When the action space is large, decision systems are restricted to a particular structure to complete online queries quickly. This paper addresses the optimization of these large scale decision systems given an arbitrary reward function. We cast this learning problem in a policy optimization framework and propose a new class of policies, born from a novel relaxation of decision functions. This results in a simple, yet efficient learning algorithm that scales to massive action spaces. We compare our method to the commonly adopted Plackett-Luce policy class and demonstrate the effectiveness of our approach on problems with action space sizes in the order of millions.
Mani-GPT: A Generative Model for Interactive Robotic Manipulation
Aug 03, 2023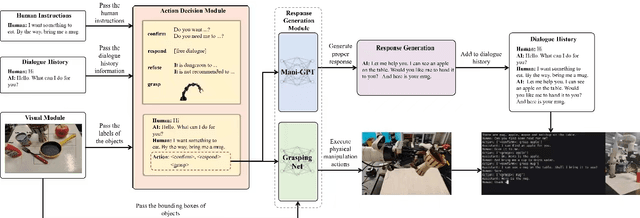

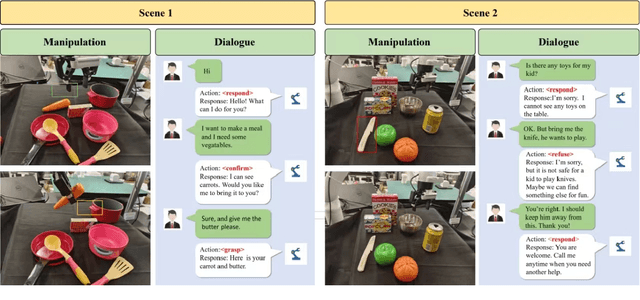
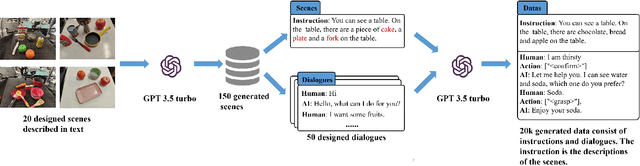
In real-world scenarios, human dialogues are multi-round and diverse. Furthermore, human instructions can be unclear and human responses are unrestricted. Interactive robots face difficulties in understanding human intents and generating suitable strategies for assisting individuals through manipulation. In this article, we propose Mani-GPT, a Generative Pre-trained Transformer (GPT) for interactive robotic manipulation. The proposed model has the ability to understand the environment through object information, understand human intent through dialogues, generate natural language responses to human input, and generate appropriate manipulation plans to assist the human. This makes the human-robot interaction more natural and humanized. In our experiment, Mani-GPT outperforms existing algorithms with an accuracy of 84.6% in intent recognition and decision-making for actions. Furthermore, it demonstrates satisfying performance in real-world dialogue tests with users, achieving an average response accuracy of 70%.
Audio-Visual Segmentation by Exploring Cross-Modal Mutual Semantics
Aug 01, 2023

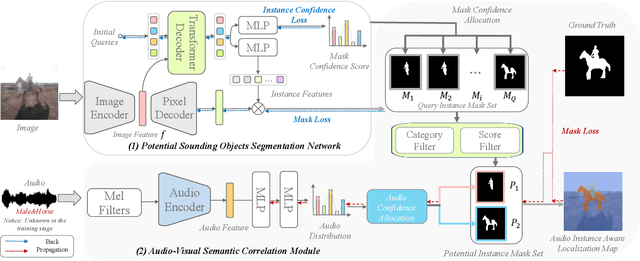

The audio-visual segmentation (AVS) task aims to segment sounding objects from a given video. Existing works mainly focus on fusing audio and visual features of a given video to achieve sounding object masks. However, we observed that prior arts are prone to segment a certain salient object in a video regardless of the audio information. This is because sounding objects are often the most salient ones in the AVS dataset. Thus, current AVS methods might fail to localize genuine sounding objects due to the dataset bias. In this work, we present an audio-visual instance-aware segmentation approach to overcome the dataset bias. In a nutshell, our method first localizes potential sounding objects in a video by an object segmentation network, and then associates the sounding object candidates with the given audio. We notice that an object could be a sounding object in one video but a silent one in another video. This would bring ambiguity in training our object segmentation network as only sounding objects have corresponding segmentation masks. We thus propose a silent object-aware segmentation objective to alleviate the ambiguity. Moreover, since the category information of audio is unknown, especially for multiple sounding sources, we propose to explore the audio-visual semantic correlation and then associate audio with potential objects. Specifically, we attend predicted audio category scores to potential instance masks and these scores will highlight corresponding sounding instances while suppressing inaudible ones. When we enforce the attended instance masks to resemble the ground-truth mask, we are able to establish audio-visual semantics correlation. Experimental results on the AVS benchmarks demonstrate that our method can effectively segment sounding objects without being biased to salient objects.
Local Consensus Enhanced Siamese Network with Reciprocal Loss for Two-view Correspondence Learning
Aug 06, 2023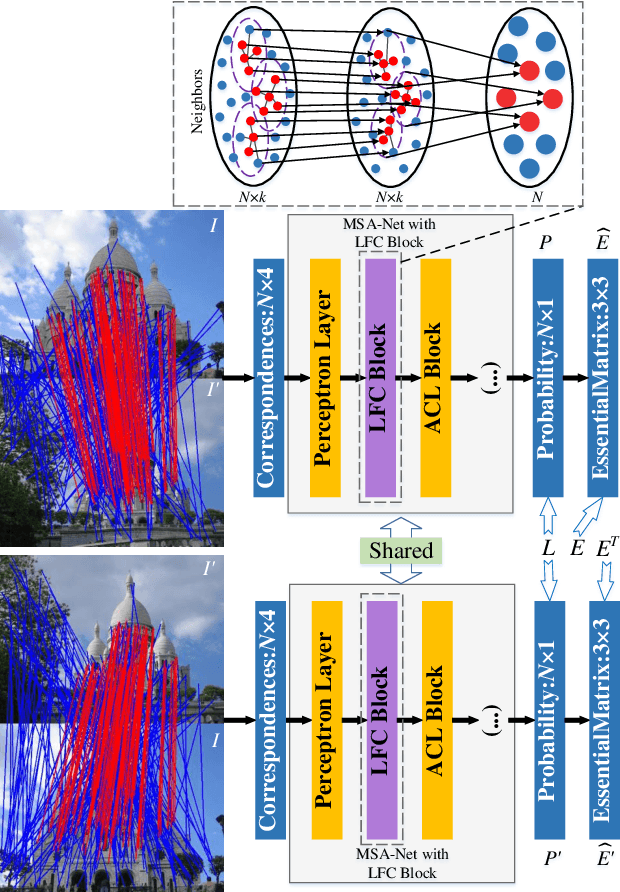
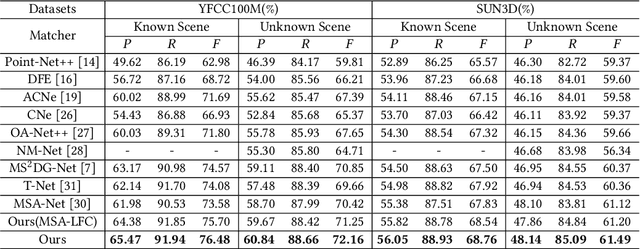
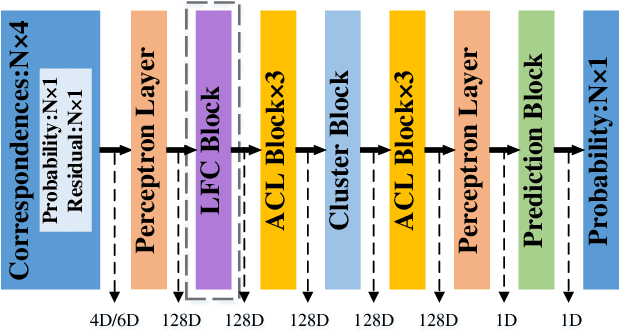
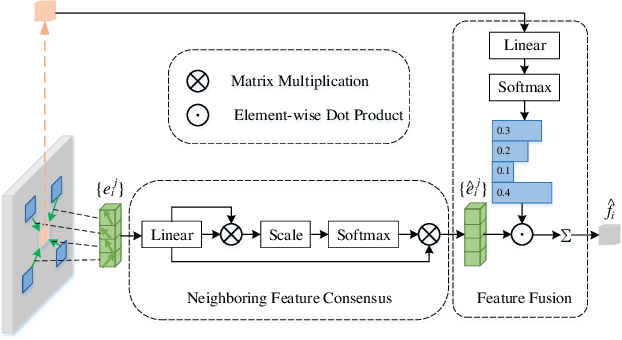
Recent studies of two-view correspondence learning usually establish an end-to-end network to jointly predict correspondence reliability and relative pose. We improve such a framework from two aspects. First, we propose a Local Feature Consensus (LFC) plugin block to augment the features of existing models. Given a correspondence feature, the block augments its neighboring features with mutual neighborhood consensus and aggregates them to produce an enhanced feature. As inliers obey a uniform cross-view transformation and share more consistent learned features than outliers, feature consensus strengthens inlier correlation and suppresses outlier distraction, which makes output features more discriminative for classifying inliers/outliers. Second, existing approaches supervise network training with the ground truth correspondences and essential matrix projecting one image to the other for an input image pair, without considering the information from the reverse mapping. We extend existing models to a Siamese network with a reciprocal loss that exploits the supervision of mutual projection, which considerably promotes the matching performance without introducing additional model parameters. Building upon MSA-Net, we implement the two proposals and experimentally achieve state-of-the-art performance on benchmark datasets.
High-Resolution Vision Transformers for Pixel-Level Identification of Structural Components and Damage
Aug 06, 2023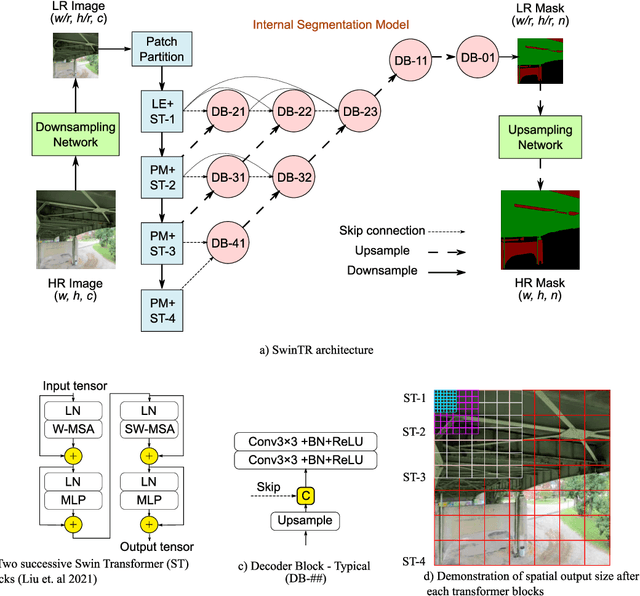
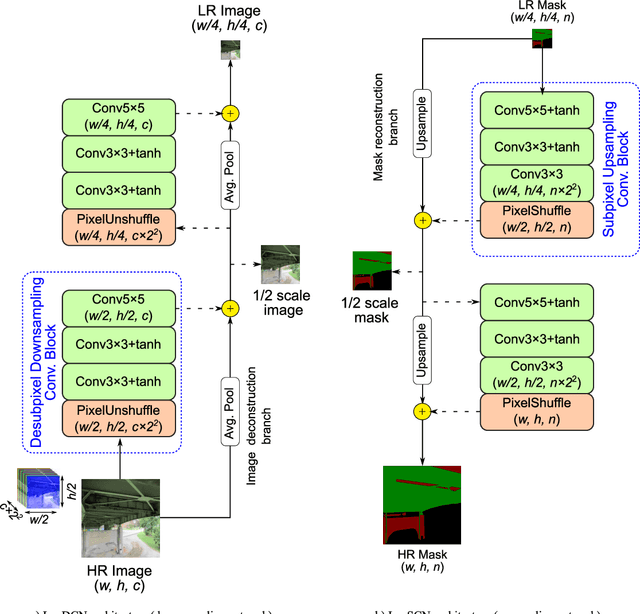


Visual inspection is predominantly used to evaluate the state of civil structures, but recent developments in unmanned aerial vehicles (UAVs) and artificial intelligence have increased the speed, safety, and reliability of the inspection process. In this study, we develop a semantic segmentation network based on vision transformers and Laplacian pyramids scaling networks for efficiently parsing high-resolution visual inspection images. The massive amounts of collected high-resolution images during inspections can slow down the investigation efforts. And while there have been extensive studies dedicated to the use of deep learning models for damage segmentation, processing high-resolution visual data can pose major computational difficulties. Traditionally, images are either uniformly downsampled or partitioned to cope with computational demands. However, the input is at risk of losing local fine details, such as thin cracks, or global contextual information. Inspired by super-resolution architectures, our vision transformer model learns to resize high-resolution images and masks to retain both the valuable local features and the global semantics without sacrificing computational efficiency. The proposed framework has been evaluated through comprehensive experiments on a dataset of bridge inspection report images using multiple metrics for pixel-wise materials detection.
Boosting Few-shot 3D Point Cloud Segmentation via Query-Guided Enhancement
Aug 06, 2023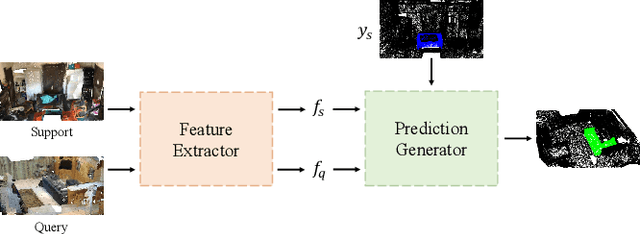

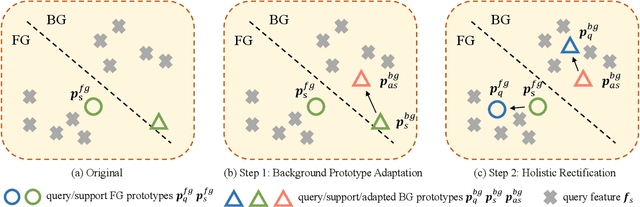

Although extensive research has been conducted on 3D point cloud segmentation, effectively adapting generic models to novel categories remains a formidable challenge. This paper proposes a novel approach to improve point cloud few-shot segmentation (PC-FSS) models. Unlike existing PC-FSS methods that directly utilize categorical information from support prototypes to recognize novel classes in query samples, our method identifies two critical aspects that substantially enhance model performance by reducing contextual gaps between support prototypes and query features. Specifically, we (1) adapt support background prototypes to match query context while removing extraneous cues that may obscure foreground and background in query samples, and (2) holistically rectify support prototypes under the guidance of query features to emulate the latter having no semantic gap to the query targets. Our proposed designs are agnostic to the feature extractor, rendering them readily applicable to any prototype-based methods. The experimental results on S3DIS and ScanNet demonstrate notable practical benefits, as our approach achieves significant improvements while still maintaining high efficiency. The code for our approach is available at https://github.com/AaronNZH/Boosting-Few-shot-3D-Point-Cloud-Segmentation-via-Query-Guided-Enhancement