 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CEmb-SAM: Segment Anything Model with Condition Embedding for Joint Learning from Heterogeneous Datasets
Aug 14, 2023
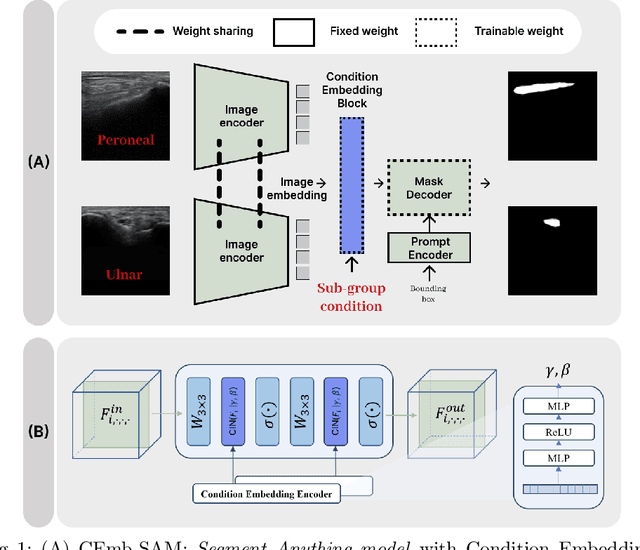

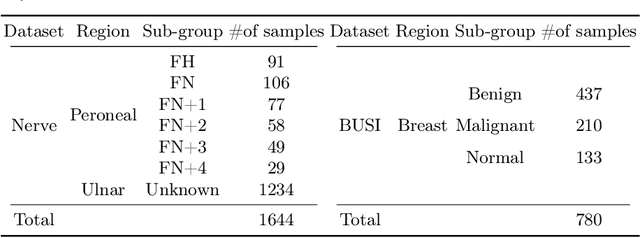

Automated segmentation of ultrasound images can assist medical experts with diagnostic and therapeutic procedures. Although using the common modality of ultrasound, one typically needs separate datasets in order to segment, for example, different anatomical structures or lesions with different levels of malignancy. In this paper, we consider the problem of jointly learning from heterogeneous datasets so that the model can improve generalization abilities by leveraging the inherent variability among datasets. We merge the heterogeneous datasets into one dataset and refer to each component dataset as a subgroup. We propose to train a single segmentation model so that the model can adapt to each sub-group. For robust segmentation, we leverage recently proposed Segment Anything model (SAM) in order to incorporate sub-group information into the model. We propose SAM with Condition Embedding block (CEmb-SAM) which encodes sub-group conditions and combines them with image embeddings from SAM. The conditional embedding block effectively adapts SAM to each image sub-group by incorporating dataset properties through learnable parameters for normalization. Experiments show that CEmb-SAM outperforms the baseline methods on ultrasound image segmentation for peripheral nerves and breast cancer. The experiments highlight the effectiveness of Cemb-SAM in learning from heterogeneous datasets in medical image segmentation tasks.
A Hybrid Deep Spatio-Temporal Attention-Based Model for Parkinson's Disease Diagnosis Using Resting State EEG Signals
Aug 14, 2023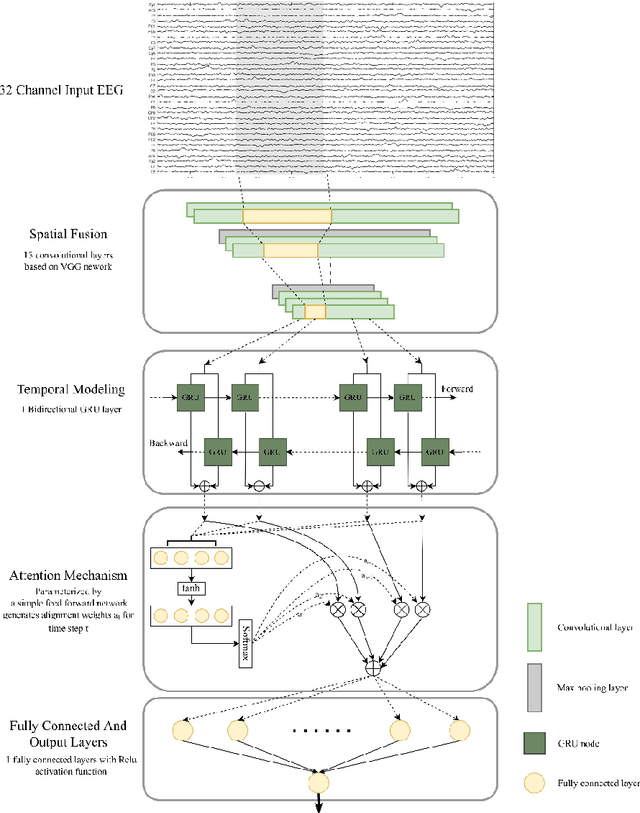
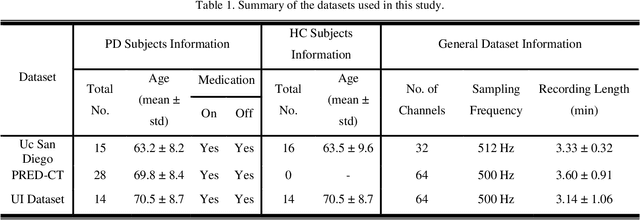
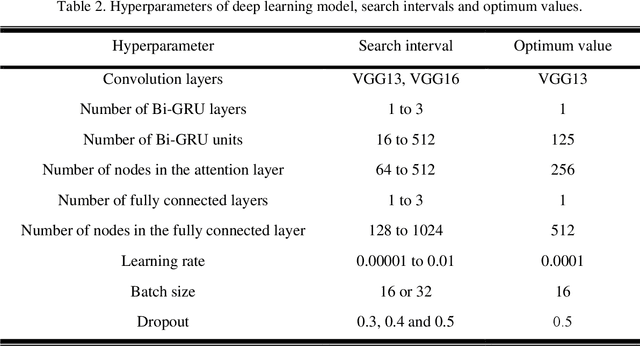
Parkinson's disease (PD), a severe and progressive neurological illness, affects millions of individuals worldwide. For effective treatment and management of PD, an accurate and early diagnosis is crucial. This study presents a deep learning-based model for the diagnosis of PD using resting state electroencephalogram (EEG) signal. The objective of the study is to develop an automated model that can extract complex hidden nonlinear features from EEG and demonstrate its generalizability on unseen data. The model is designed using a hybrid model, consists of convolutional neural network (CNN), bidirectional gated recurrent unit (Bi-GRU), and attention mechanism. The proposed method is evaluated on three public datasets (Uc San Diego Dataset, PRED-CT, and University of Iowa (UI) dataset), with one dataset used for training and the other two for evaluation. The results show that the proposed model can accurately diagnose PD with high performance on both the training and hold-out datasets. The model also performs well even when some part of the input information is missing. The results of this work have significant implications for patient treatment and for ongoing investigations into the early detection of Parkinson's disease. The suggested model holds promise as a non-invasive and reliable technique for PD early detection utilizing resting state EEG.
Complete and separate: Conditional separation with missing target source attribute completion
Jul 27, 2023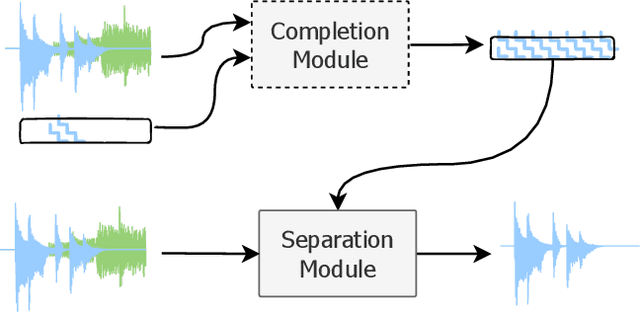
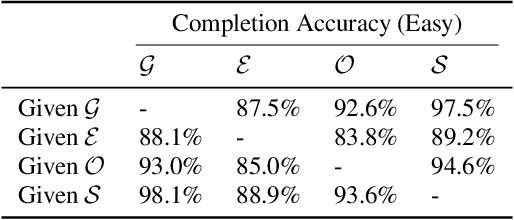
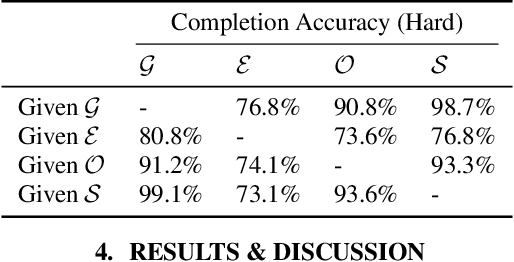
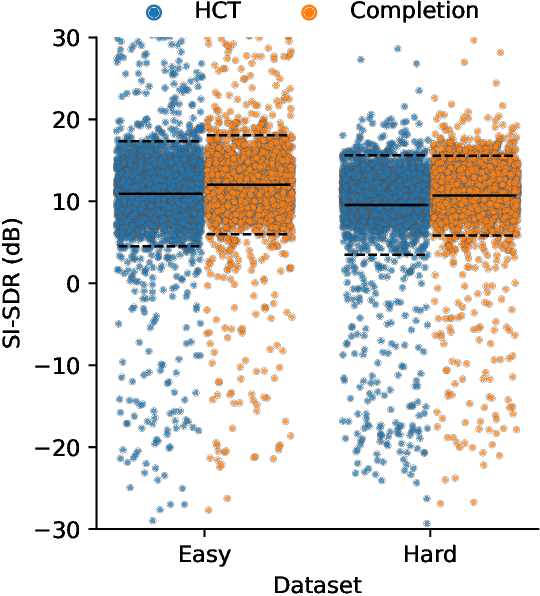
Recent approaches in source separation leverage semantic information about their input mixtures and constituent sources that when used in conditional separation models can achieve impressive performance. Most approaches along these lines have focused on simple descriptions, which are not always useful for varying types of input mixtures. In this work, we present an approach in which a model, given an input mixture and partial semantic information about a target source, is trained to extract additional semantic data. We then leverage this pre-trained model to improve the separation performance of an uncoupled multi-conditional separation network. Our experiments demonstrate that the separation performance of this multi-conditional model is significantly improved, approaching the performance of an oracle model with complete semantic information. Furthermore, our approach achieves performance levels that are comparable to those of the best performing specialized single conditional models, thus providing an easier to use alternative.
DeepGATGO: A Hierarchical Pretraining-Based Graph-Attention Model for Automatic Protein Function Prediction
Jul 24, 2023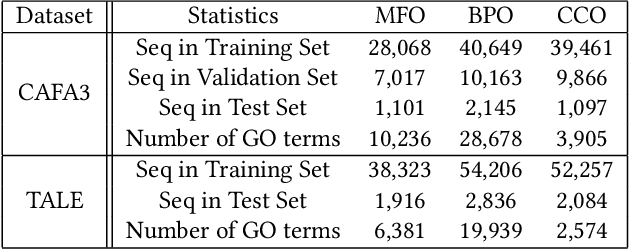
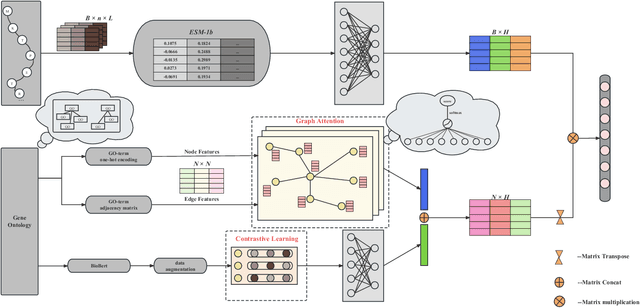
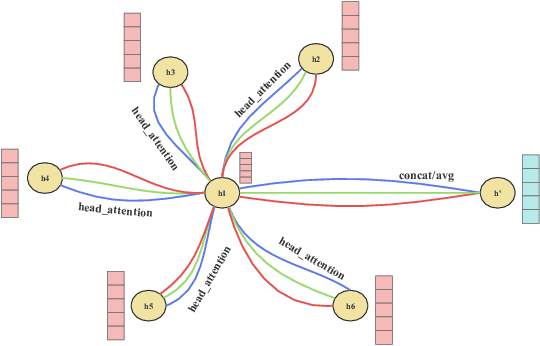
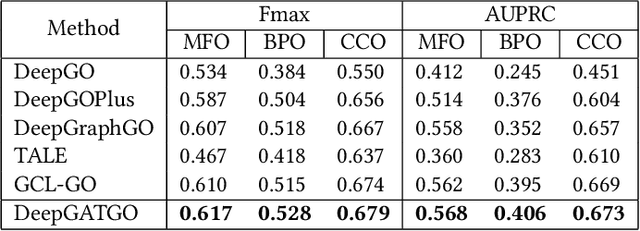
Automatic protein function prediction (AFP) is classified as a large-scale multi-label classification problem aimed at automating protein enrichment analysis to eliminate the current reliance on labor-intensive wet-lab methods. Currently, popular methods primarily combine protein-related information and Gene Ontology (GO) terms to generate final functional predictions. For example, protein sequences, structural information, and protein-protein interaction networks are integrated as prior knowledge to fuse with GO term embeddings and generate the ultimate prediction results. However, these methods are limited by the difficulty in obtaining structural information or network topology information, as well as the accuracy of such data. Therefore, more and more methods that only use protein sequences for protein function prediction have been proposed, which is a more reliable and computationally cheaper approach. However, the existing methods fail to fully extract feature information from protein sequences or label data because they do not adequately consider the intrinsic characteristics of the data itself. Therefore, we propose a sequence-based hierarchical prediction method, DeepGATGO, which processes protein sequences and GO term labels hierarchically, and utilizes graph attention networks (GATs) and contrastive learning for protein function prediction. Specifically, we compute embeddings of the sequence and label data using pre-trained models to reduce computational costs and improve the embedding accuracy. Then, we use GATs to dynamically extract the structural information of non-Euclidean data, and learn general features of the label dataset with contrastive learning by constructing positive and negative example samples. Experimental results demonstrate that our proposed model exhibits better scalability in GO term enrichment analysis on large-scale datasets.
User Feedback and Sample Weighting for Ill-Conditioned Hand-Eye Calibration
Aug 11, 2023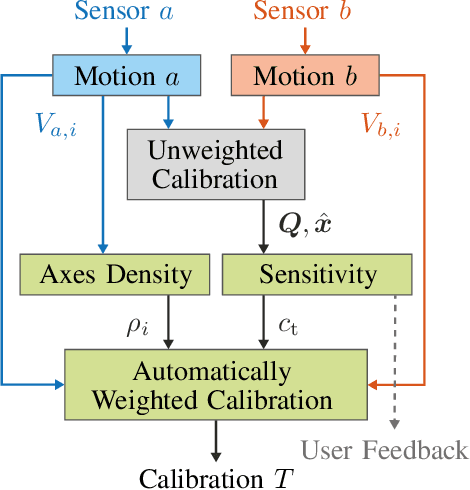
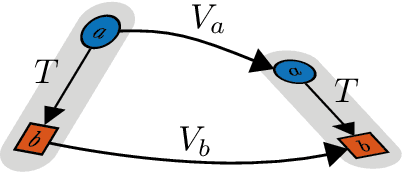
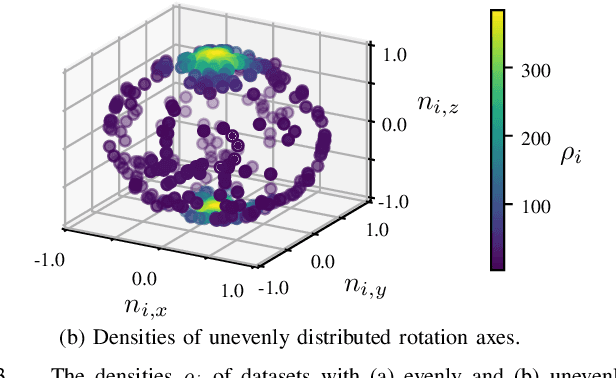
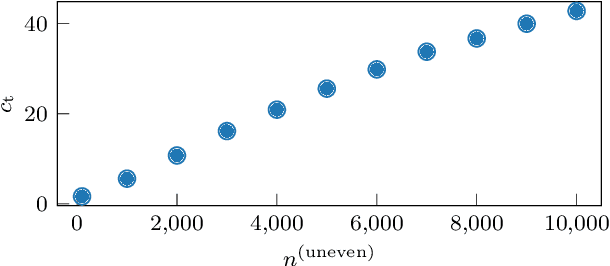
Hand-eye calibration is an important and extensively researched method for calibrating rigidly coupled sensors, solely based on estimates of their motion. Due to the geometric structure of this problem, at least two motion estimates with non-parallel rotation axes are required for a unique solution. If the majority of rotation axes are almost parallel, the resulting optimization problem is ill-conditioned. In this paper, we propose an approach to automatically weight the motion samples of such an ill-conditioned optimization problem for improving the conditioning. The sample weights are chosen in relation to the local density of all available rotation axes. Furthermore, we present an approach for estimating the sensitivity and conditioning of the cost function, separated into the translation and the rotation part. This information can be employed as user feedback when recording the calibration data to prevent ill-conditioning in advance. We evaluate and compare our approach on artificially augmented data from the KITTI odometry dataset.
Combining feature aggregation and geometric similarity for re-identification of patterned animals
Aug 11, 2023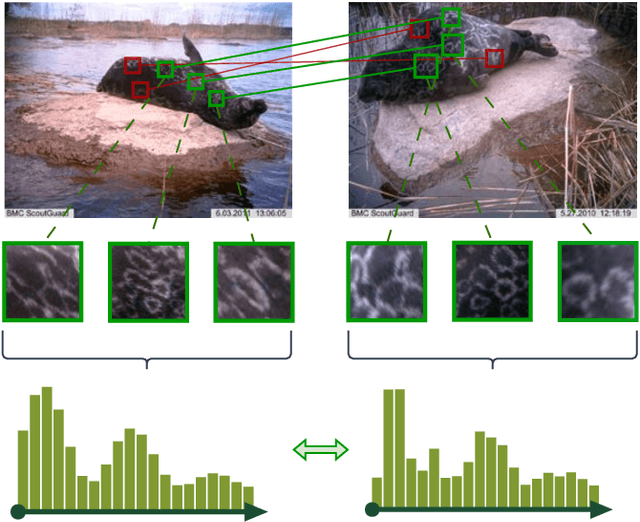
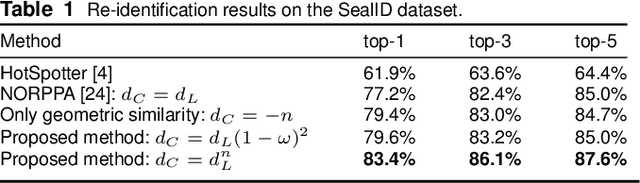
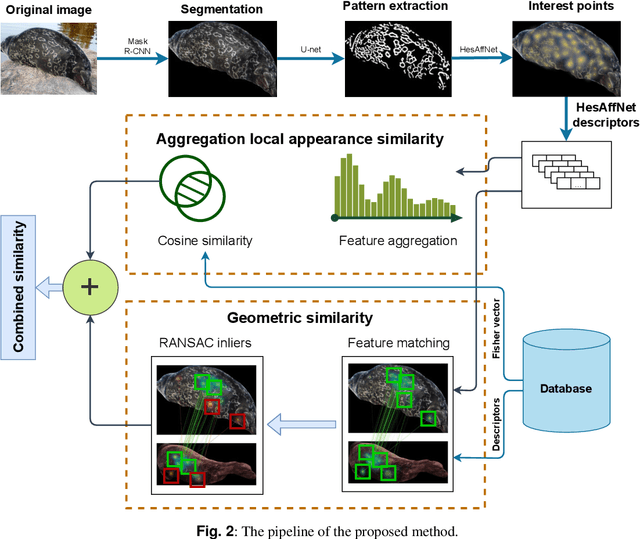
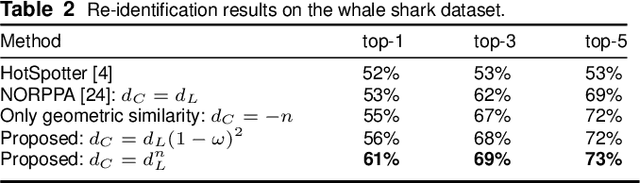
Image-based re-identification of animal individuals allows gathering of information such as migration patterns of the animals over time. This, together with large image volumes collected using camera traps and crowdsourcing, opens novel possibilities to study animal populations. For many species, the re-identification can be done by analyzing the permanent fur, feather, or skin patterns that are unique to each individual. In this paper, we address the re-identification by combining two types of pattern similarity metrics: 1) pattern appearance similarity obtained by pattern feature aggregation and 2) geometric pattern similarity obtained by analyzing the geometric consistency of pattern similarities. The proposed combination allows to efficiently utilize both the local and global pattern features, providing a general re-identification approach that can be applied to a wide variety of different pattern types. In the experimental part of the work, we demonstrate that the method achieves promising re-identification accuracies for Saimaa ringed seals and whale sharks.
Majority Vote Computation With Complementary Sequences for Distributed UAV Guidance
Aug 11, 2023This study introduces a novel non-coherent over-the-air computation (OAC) scheme aimed at achieving reliable majority vote (MV) calculations in fading channels. The proposed approach relies on modulating the amplitude of the elements of complementary sequences (CSs) based on the sign of the parameters to be aggregated. Notably, our method eliminates the reliance on channel state information at the nodes, rendering it compatible with time-varying channels. To demonstrate the efficacy of our approach, we employ it in a scenario where an unmanned aerial vehicle (UAV) is guided by distributed sensors, relying on the MV computed using our proposed scheme. The experimental results confirm the superiority of our approach, as evidenced by a significant reduction in computation error rates in fading channels, particularly with longer sequence lengths. Meanwhile, we ensure that the peak-to-mean-envelope power ratio of the transmitted orthogonal frequency division multiplexing signals remains within or below 3 dB.
Refining Obstacle Perception Safety Zones via Maneuver-Based Decomposition
Aug 11, 2023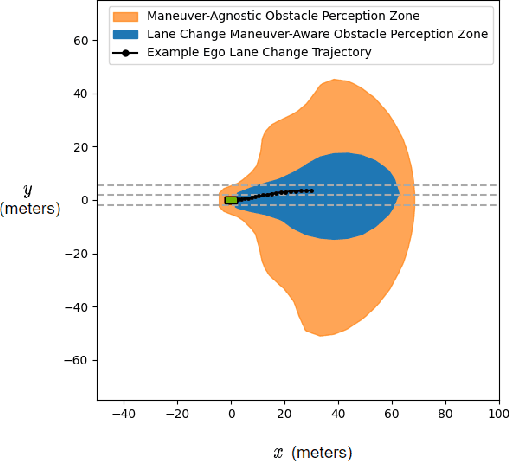
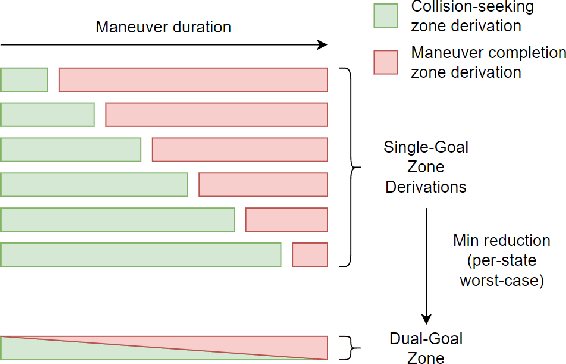
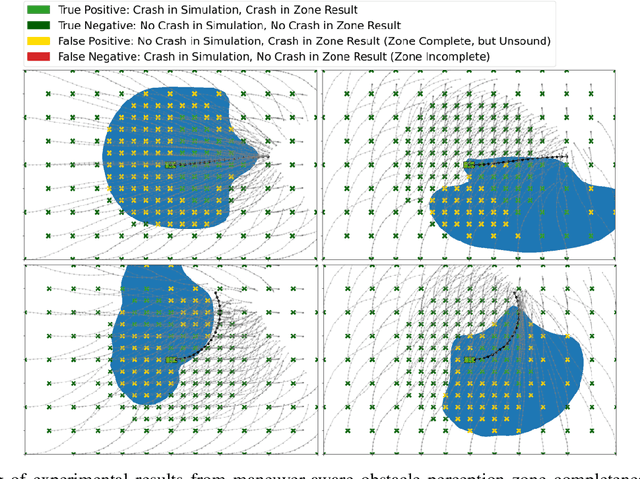
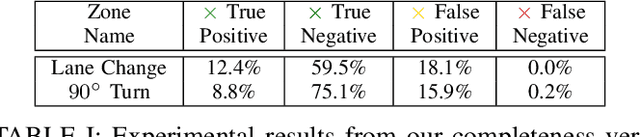
A critical task for developing safe autonomous driving stacks is to determine whether an obstacle is safety-critical, i.e., poses an imminent threat to the autonomous vehicle. Our previous work showed that Hamilton Jacobi reachability theory can be applied to compute interaction-dynamics-aware perception safety zones that better inform an ego vehicle's perception module which obstacles are considered safety-critical. For completeness, these zones are typically larger than absolutely necessary, forcing the perception module to pay attention to a larger collection of objects for the sake of conservatism. As an improvement, we propose a maneuver-based decomposition of our safety zones that leverages information about the ego maneuver to reduce the zone volume. In particular, we propose a "temporal convolution" operation that produces safety zones for specific ego maneuvers, thus limiting the ego's behavior to reduce the size of the safety zones. We show with numerical experiments that maneuver-based zones are significantly smaller (up to 76% size reduction) than the baseline while maintaining completeness.
Contrastive Learning for Cross-modal Artist Retrieval
Aug 12, 2023Music retrieval and recommendation applications often rely on content features encoded as embeddings, which provide vector representations of items in a music dataset. Numerous complementary embeddings can be derived from processing items originally represented in several modalities, e.g., audio signals, user interaction data, or editorial data. However, data of any given modality might not be available for all items in any music dataset. In this work, we propose a method based on contrastive learning to combine embeddings from multiple modalities and explore the impact of the presence or absence of embeddings from diverse modalities in an artist similarity task. Experiments on two datasets suggest that our contrastive method outperforms single-modality embeddings and baseline algorithms for combining modalities, both in terms of artist retrieval accuracy and coverage. Improvements with respect to other methods are particularly significant for less popular query artists. We demonstrate our method successfully combines complementary information from diverse modalities, and is more robust to missing modality data (i.e., it better handles the retrieval of artists with different modality embeddings than the query artist's).
Neural Latent Aligner: Cross-trial Alignment for Learning Representations of Complex, Naturalistic Neural Data
Aug 12, 2023Understanding the neural implementation of complex human behaviors is one of the major goals in neuroscience. To this end, it is crucial to find a true representation of the neural data, which is challenging due to the high complexity of behaviors and the low signal-to-ratio (SNR) of the signals. Here, we propose a novel unsupervised learning framework, Neural Latent Aligner (NLA), to find well-constrained, behaviorally relevant neural representations of complex behaviors. The key idea is to align representations across repeated trials to learn cross-trial consistent information. Furthermore, we propose a novel, fully differentiable time warping model (TWM) to resolve the temporal misalignment of trials. When applied to intracranial electrocorticography (ECoG) of natural speaking, our model learns better representations for decoding behaviors than the baseline models, especially in lower dimensional space. The TWM is empirically validated by measuring behavioral coherence between aligned trials. The proposed framework learns more cross-trial consistent representations than the baselines, and when visualized, the manifold reveals shared neural trajectories across trials.
* Accepted at ICML 2023