 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Independent Distribution Regularization for Private Graph Embedding
Aug 16, 2023
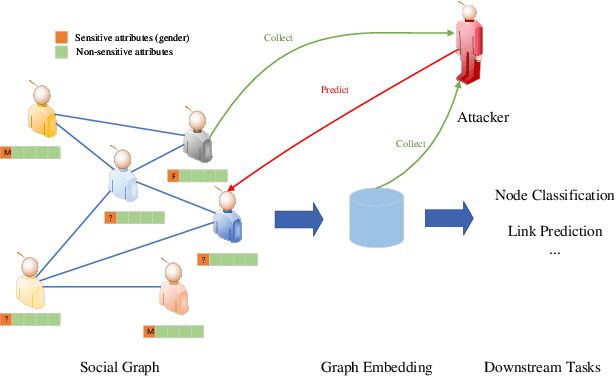
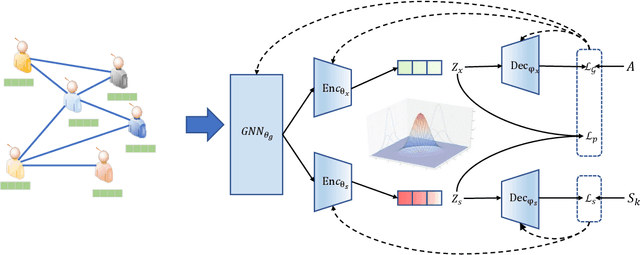
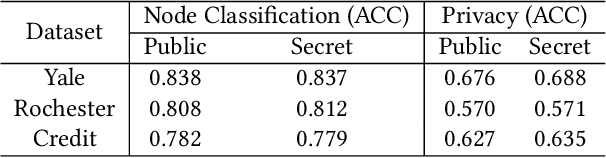
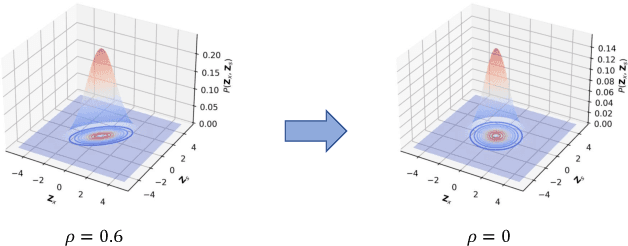
Learning graph embeddings is a crucial task in graph mining tasks. An effective graph embedding model can learn low-dimensional representations from graph-structured data for data publishing benefiting various downstream applications such as node classification, link prediction, etc. However, recent studies have revealed that graph embeddings are susceptible to attribute inference attacks, which allow attackers to infer private node attributes from the learned graph embeddings. To address these concerns, privacy-preserving graph embedding methods have emerged, aiming to simultaneously consider primary learning and privacy protection through adversarial learning. However, most existing methods assume that representation models have access to all sensitive attributes in advance during the training stage, which is not always the case due to diverse privacy preferences. Furthermore, the commonly used adversarial learning technique in privacy-preserving representation learning suffers from unstable training issues. In this paper, we propose a novel approach called Private Variational Graph AutoEncoders (PVGAE) with the aid of independent distribution penalty as a regularization term. Specifically, we split the original variational graph autoencoder (VGAE) to learn sensitive and non-sensitive latent representations using two sets of encoders. Additionally, we introduce a novel regularization to enforce the independence of the encoders. We prove the theoretical effectiveness of regularization from the perspective of mutual information. Experimental results on three real-world datasets demonstrate that PVGAE outperforms other baselines in private embedding learning regarding utility performance and privacy protection.
LiDAR-Camera Panoptic Segmentation via Geometry-Consistent and Semantic-Aware Alignment
Aug 03, 2023
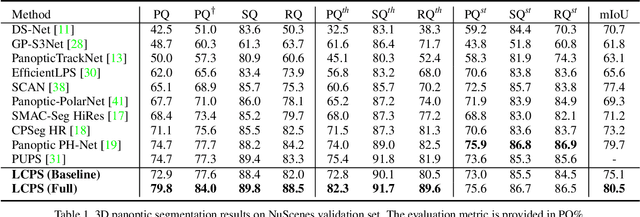
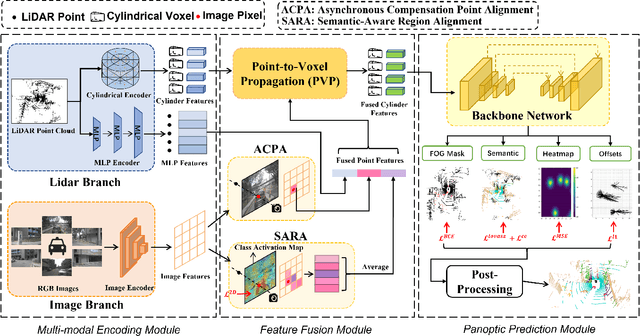
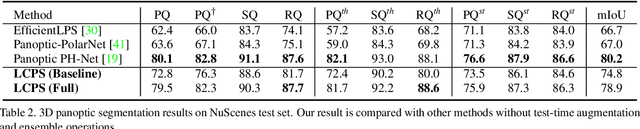
3D panoptic segmentation is a challenging perception task that requires both semantic segmentation and instance segmentation. In this task, we notice that images could provide rich texture, color, and discriminative information, which can complement LiDAR data for evident performance improvement, but their fusion remains a challenging problem. To this end, we propose LCPS, the first LiDAR-Camera Panoptic Segmentation network. In our approach, we conduct LiDAR-Camera fusion in three stages: 1) an Asynchronous Compensation Pixel Alignment (ACPA) module that calibrates the coordinate misalignment caused by asynchronous problems between sensors; 2) a Semantic-Aware Region Alignment (SARA) module that extends the one-to-one point-pixel mapping to one-to-many semantic relations; 3) a Point-to-Voxel feature Propagation (PVP) module that integrates both geometric and semantic fusion information for the entire point cloud. Our fusion strategy improves about 6.9% PQ performance over the LiDAR-only baseline on NuScenes dataset. Extensive quantitative and qualitative experiments further demonstrate the effectiveness of our novel framework. The code will be released at https://github.com/zhangzw12319/lcps.git.
Promise and Limitations of Supervised Optimal Transport-Based Graph Summarization via Information Theoretic Measures
May 11, 2023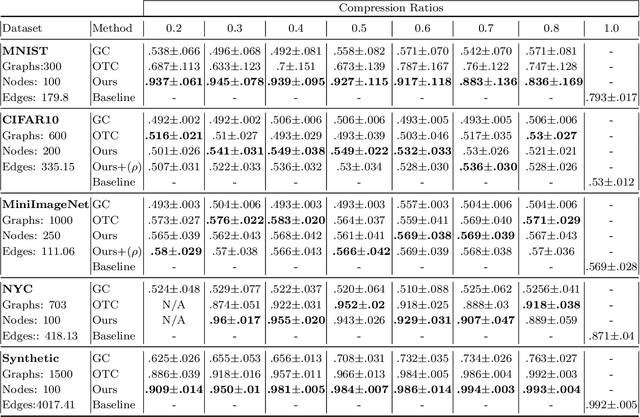
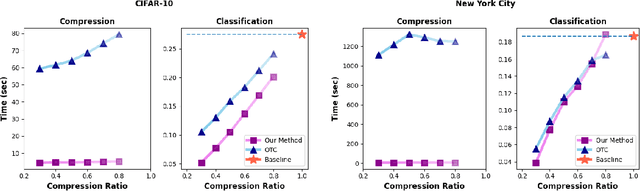
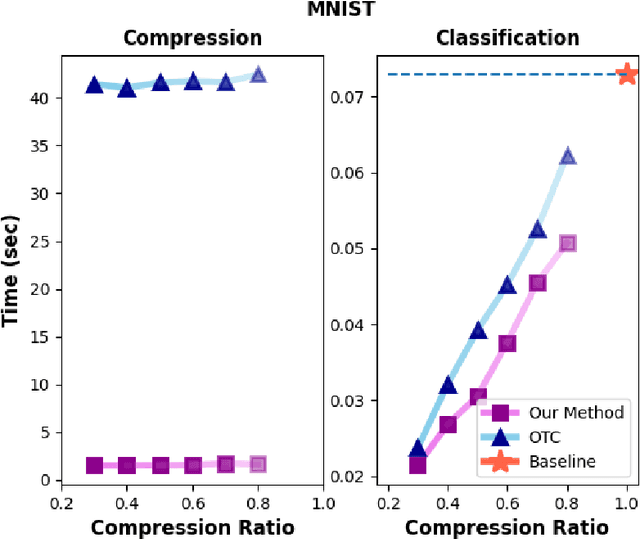

Graph summarization is the problem of producing smaller graph representations of an input graph dataset, in such a way that the smaller compressed graphs capture relevant structural information for downstream tasks. There is a recent graph summarization method that formulates an optimal transport-based framework that allows prior information about node, edge, and attribute importance (never defined in that work) to be incorporated into the graph summarization process. However, very little is known about the statistical properties of this framework. To elucidate this question, we consider the problem of supervised graph summarization, wherein by using information theoretic measures we seek to preserve relevant information about a class label. To gain a theoretical perspective on the supervised summarization problem itself, we first formulate it in terms of maximizing the Shannon mutual information between the summarized graph and the class label. We show an NP-hardness of approximation result for this problem, thereby constraining what one should expect from proposed solutions. We then propose a summarization method that incorporates mutual information estimates between random variables associated with sample graphs and class labels into the optimal transport compression framework. We empirically show performance improvements over previous works in terms of classification accuracy and time on synthetic and certain real datasets. We also theoretically explore the limitations of the optimal transport approach for the supervised summarization problem and we show that it fails to satisfy a certain desirable information monotonicity property.
Fundamental Tradeoffs in Learning with Prior Information
Apr 26, 2023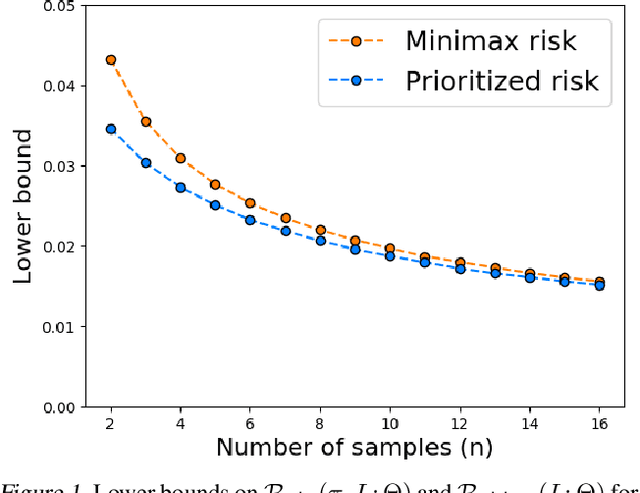
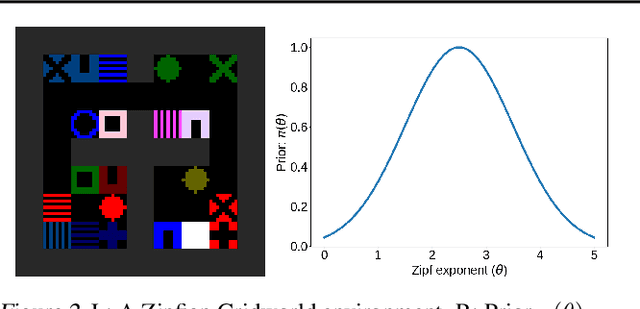
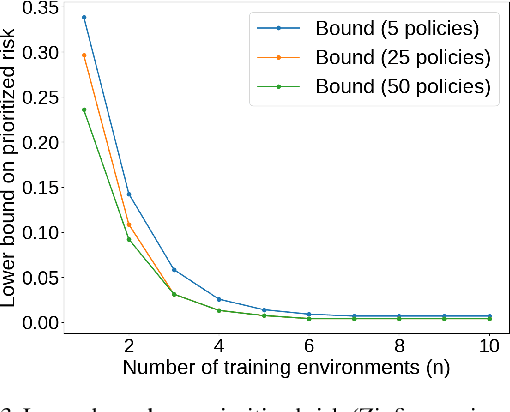
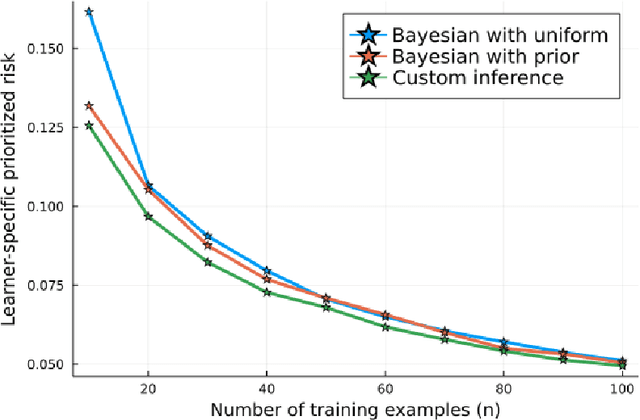
We seek to understand fundamental tradeoffs between the accuracy of prior information that a learner has on a given problem and its learning performance. We introduce the notion of prioritized risk, which differs from traditional notions of minimax and Bayes risk by allowing us to study such fundamental tradeoffs in settings where reality does not necessarily conform to the learner's prior. We present a general reduction-based approach for extending classical minimax lower-bound techniques in order to lower bound the prioritized risk for statistical estimation problems. We also introduce a novel generalization of Fano's inequality (which may be of independent interest) for lower bounding the prioritized risk in more general settings involving unbounded losses. We illustrate the ability of our framework to provide insights into tradeoffs between prior information and learning performance for problems in estimation, regression, and reinforcement learning.
A Graph Encoder-Decoder Network for Unsupervised Anomaly Detection
Aug 15, 2023A key component of many graph neural networks (GNNs) is the pooling operation, which seeks to reduce the size of a graph while preserving important structural information. However, most existing graph pooling strategies rely on an assignment matrix obtained by employing a GNN layer, which is characterized by trainable parameters, often leading to significant computational complexity and a lack of interpretability in the pooling process. In this paper, we propose an unsupervised graph encoder-decoder model to detect abnormal nodes from graphs by learning an anomaly scoring function to rank nodes based on their degree of abnormality. In the encoding stage, we design a novel pooling mechanism, named LCPool, which leverages locality-constrained linear coding for feature encoding to find a cluster assignment matrix by solving a least-squares optimization problem with a locality regularization term. By enforcing locality constraints during the coding process, LCPool is designed to be free from learnable parameters, capable of efficiently handling large graphs, and can effectively generate a coarser graph representation while retaining the most significant structural characteristics of the graph. In the decoding stage, we propose an unpooling operation, called LCUnpool, to reconstruct both the structure and nodal features of the original graph. We conduct empirical evaluations of our method on six benchmark datasets using several evaluation metrics, and the results demonstrate its superiority over state-of-the-art anomaly detection approaches.
Exploring Transfer Learning in Medical Image Segmentation using Vision-Language Models
Aug 15, 2023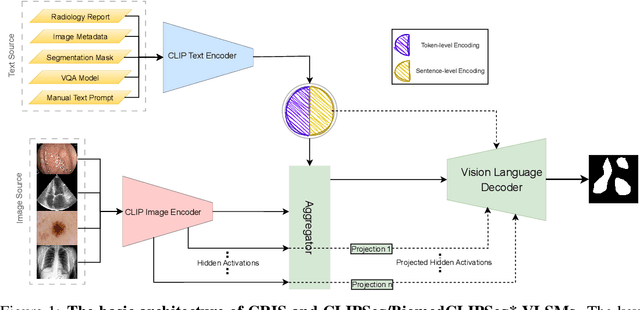


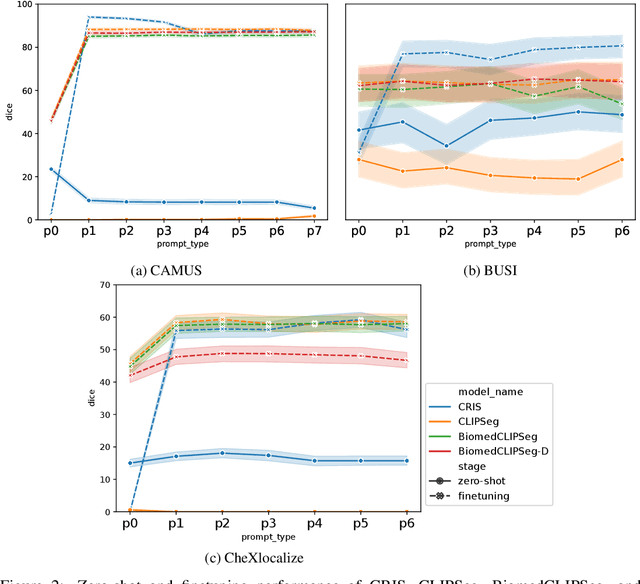
Medical Image Segmentation is crucial in various clinical applications within the medical domain. While state-of-the-art segmentation models have proven effective, integrating textual guidance to enhance visual features for this task remains an area with limited progress. Existing segmentation models that utilize textual guidance are primarily trained on open-domain images, raising concerns about their direct applicability in the medical domain without manual intervention or fine-tuning. To address these challenges, we propose using multimodal vision-language models for capturing semantic information from image descriptions and images, enabling the segmentation of diverse medical images. This study comprehensively evaluates existing vision language models across multiple datasets to assess their transferability from the open domain to the medical field. Furthermore, we introduce variations of image descriptions for previously unseen images in the dataset, revealing notable variations in model performance based on the generated prompts. Our findings highlight the distribution shift between the open-domain images and the medical domain and show that the segmentation models trained on open-domain images are not directly transferrable to the medical field. But their performance can be increased by finetuning them in the medical datasets. We report the zero-shot and finetuned segmentation performance of 4 Vision Language Models (VLMs) on 11 medical datasets using 9 types of prompts derived from 14 attributes.
Prompt Switch: Efficient CLIP Adaptation for Text-Video Retrieval
Aug 15, 2023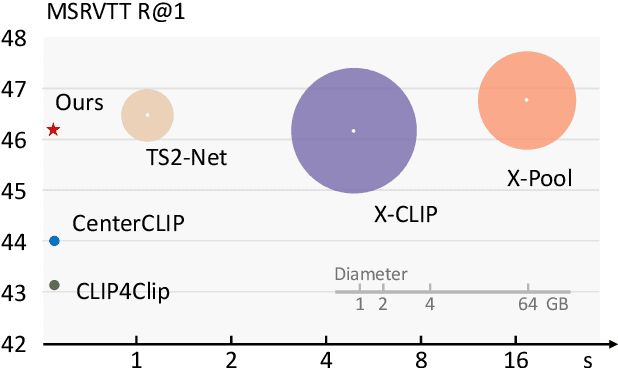
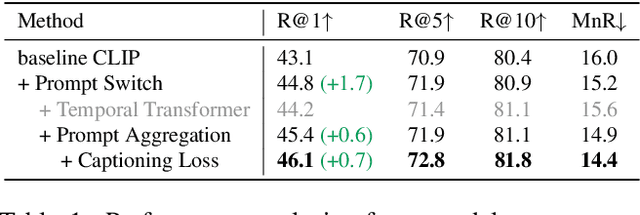
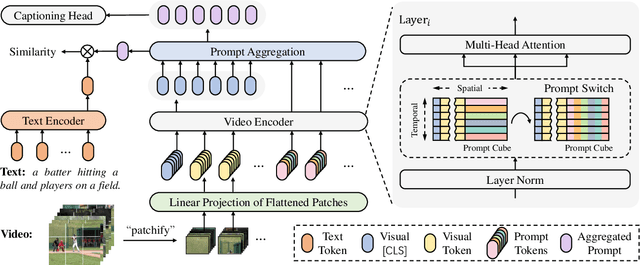
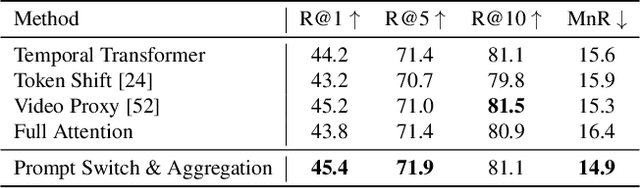
In text-video retrieval, recent works have benefited from the powerful learning capabilities of pre-trained text-image foundation models (e.g., CLIP) by adapting them to the video domain. A critical problem for them is how to effectively capture the rich semantics inside the video using the image encoder of CLIP. To tackle this, state-of-the-art methods adopt complex cross-modal modeling techniques to fuse the text information into video frame representations, which, however, incurs severe efficiency issues in large-scale retrieval systems as the video representations must be recomputed online for every text query. In this paper, we discard this problematic cross-modal fusion process and aim to learn semantically-enhanced representations purely from the video, so that the video representations can be computed offline and reused for different texts. Concretely, we first introduce a spatial-temporal "Prompt Cube" into the CLIP image encoder and iteratively switch it within the encoder layers to efficiently incorporate the global video semantics into frame representations. We then propose to apply an auxiliary video captioning objective to train the frame representations, which facilitates the learning of detailed video semantics by providing fine-grained guidance in the semantic space. With a naive temporal fusion strategy (i.e., mean-pooling) on the enhanced frame representations, we obtain state-of-the-art performances on three benchmark datasets, i.e., MSR-VTT, MSVD, and LSMDC.
AttMOT: Improving Multiple-Object Tracking by Introducing Auxiliary Pedestrian Attributes
Aug 15, 2023


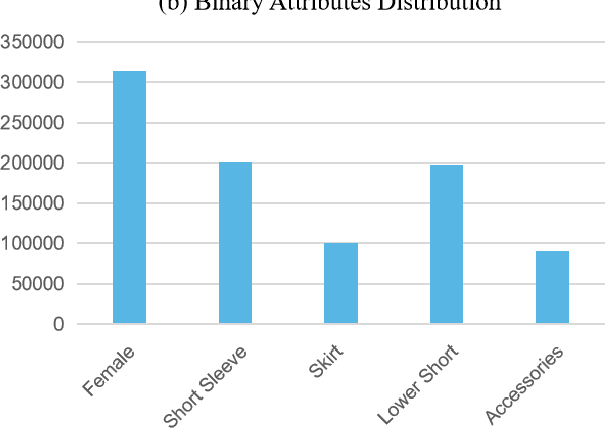
Multi-object tracking (MOT) is a fundamental problem in computer vision with numerous applications, such as intelligent surveillance and automated driving. Despite the significant progress made in MOT, pedestrian attributes, such as gender, hairstyle, body shape, and clothing features, which contain rich and high-level information, have been less explored. To address this gap, we propose a simple, effective, and generic method to predict pedestrian attributes to support general Re-ID embedding. We first introduce AttMOT, a large, highly enriched synthetic dataset for pedestrian tracking, containing over 80k frames and 6 million pedestrian IDs with different time, weather conditions, and scenarios. To the best of our knowledge, AttMOT is the first MOT dataset with semantic attributes. Subsequently, we explore different approaches to fuse Re-ID embedding and pedestrian attributes, including attention mechanisms, which we hope will stimulate the development of attribute-assisted MOT. The proposed method AAM demonstrates its effectiveness and generality on several representative pedestrian multi-object tracking benchmarks, including MOT17 and MOT20, through experiments on the AttMOT dataset. When applied to state-of-the-art trackers, AAM achieves consistent improvements in MOTA, HOTA, AssA, IDs, and IDF1 scores. For instance, on MOT17, the proposed method yields a +1.1 MOTA, +1.7 HOTA, and +1.8 IDF1 improvement when used with FairMOT. To encourage further research on attribute-assisted MOT, we will release the AttMOT dataset.
Multimodal Dataset Distillation for Image-Text Retrieval
Aug 15, 2023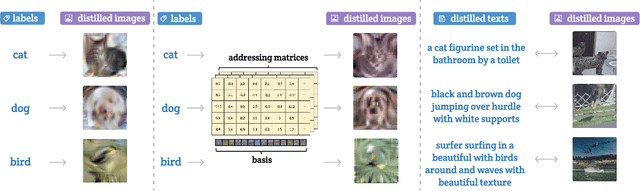
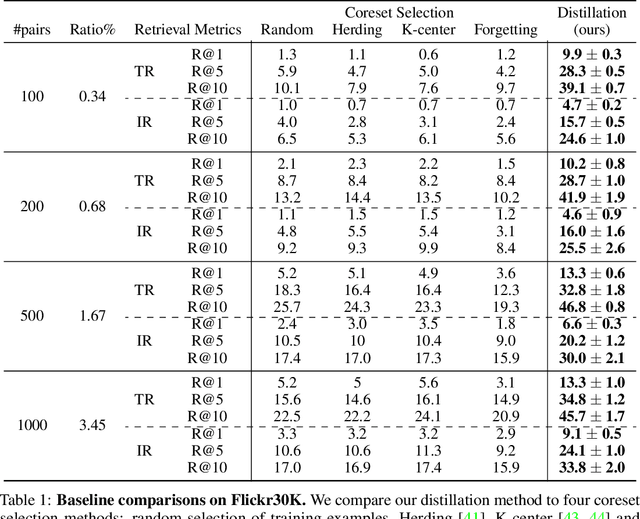
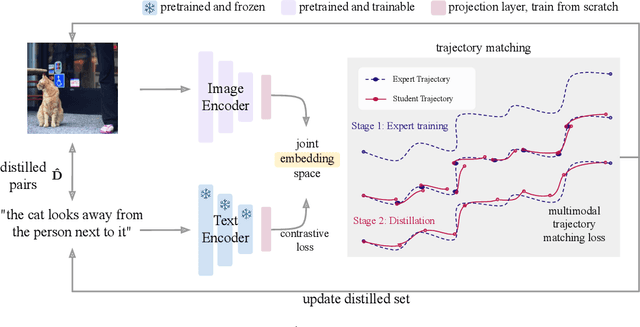
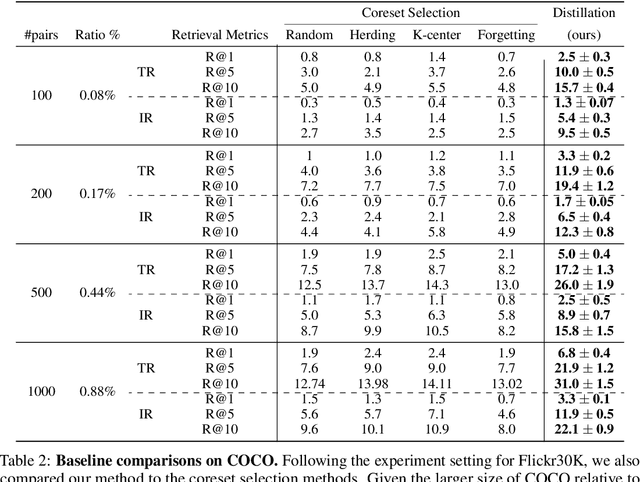
Dataset distillation methods offer the promise of reducing a large-scale dataset down to a significantly smaller set of (potentially synthetic) training examples, which preserve sufficient information for training a new model from scratch. So far dataset distillation methods have been developed for image classification. However, with the rise in capabilities of vision-language models, and especially given the scale of datasets necessary to train these models, the time is ripe to expand dataset distillation methods beyond image classification. In this work, we take the first steps towards this goal by expanding on the idea of trajectory matching to create a distillation method for vision-language datasets. The key challenge is that vision-language datasets do not have a set of discrete classes. To overcome this, our proposed multimodal dataset distillation method jointly distill the images and their corresponding language descriptions in a contrastive formulation. Since there are no existing baselines, we compare our approach to three coreset selection methods (strategic subsampling of the training dataset), which we adapt to the vision-language setting. We demonstrate significant improvements on the challenging Flickr30K and COCO retrieval benchmark: the best coreset selection method which selects 1000 image-text pairs for training is able to achieve only 5.6% image-to-text retrieval accuracy (recall@1); in contrast, our dataset distillation approach almost doubles that with just 100 (an order of magnitude fewer) training pairs.
Heterogeneous Knowledge Fusion: A Novel Approach for Personalized Recommendation via LLM
Aug 07, 2023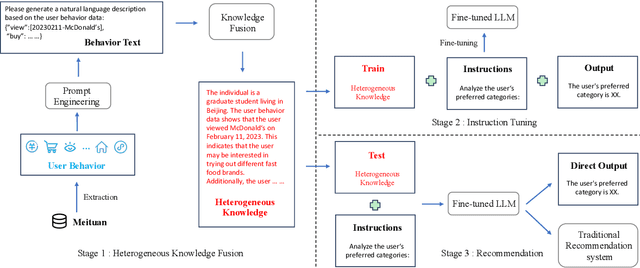
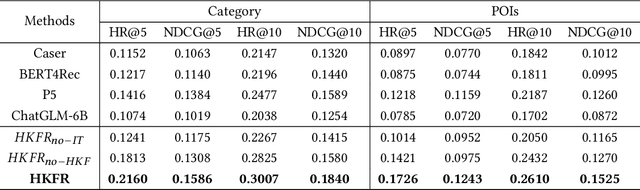
The analysis and mining of user heterogeneous behavior are of paramount importance in recommendation systems. However, the conventional approach of incorporating various types of heterogeneous behavior into recommendation models leads to feature sparsity and knowledge fragmentation issues. To address this challenge, we propose a novel approach for personalized recommendation via Large Language Model (LLM), by extracting and fusing heterogeneous knowledge from user heterogeneous behavior information. In addition, by combining heterogeneous knowledge and recommendation tasks, instruction tuning is performed on LLM for personalized recommendations. The experimental results demonstrate that our method can effectively integrate user heterogeneous behavior and significantly improve recommendation performance.