 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Explicit Estimation of Magnitude and Phase Spectra in Parallel for High-Quality Speech Enhancement
Aug 17, 2023
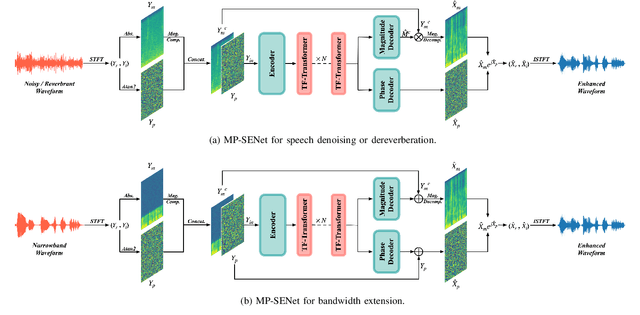
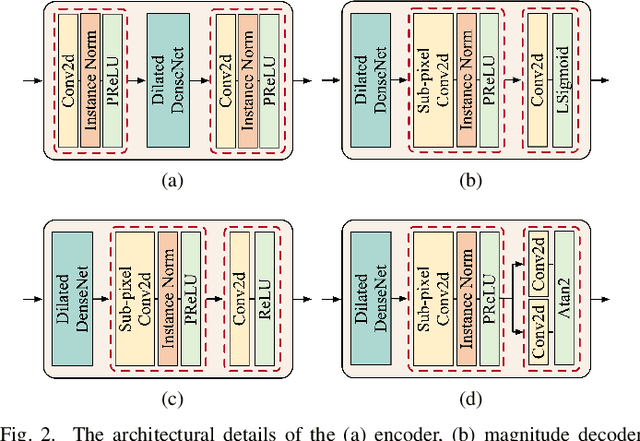
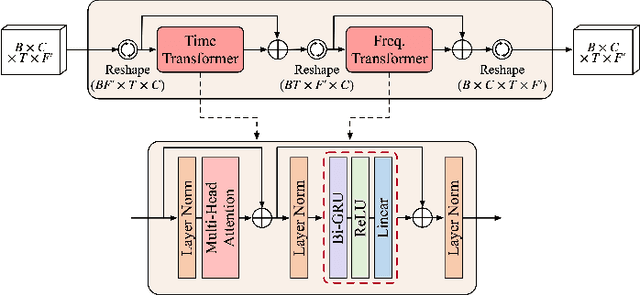
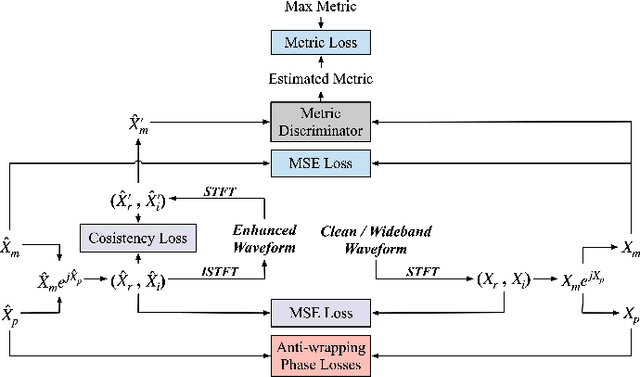
Phase information has a significant impact on speech perceptual quality and intelligibility. However, existing speech enhancement methods encounter limitations in explicit phase estimation due to the non-structural nature and wrapping characteristics of the phase, leading to a bottleneck in enhanced speech quality. To overcome the above issue, in this paper, we proposed MP-SENet, a novel Speech Enhancement Network which explicitly enhances Magnitude and Phase spectra in parallel. The proposed MP-SENet adopts a codec architecture in which the encoder and decoder are bridged by time-frequency Transformers along both time and frequency dimensions. The encoder aims to encode time-frequency representations derived from the input distorted magnitude and phase spectra. The decoder comprises dual-stream magnitude and phase decoders, directly enhancing magnitude and wrapped phase spectra by incorporating a magnitude estimation architecture and a phase parallel estimation architecture, respectively. To train the MP-SENet model effectively, we define multi-level loss functions, including mean square error and perceptual metric loss of magnitude spectra, anti-wrapping loss of phase spectra, as well as mean square error and consistency loss of short-time complex spectra. Experimental results demonstrate that our proposed MP-SENet excels in high-quality speech enhancement across multiple tasks, including speech denoising, dereverberation, and bandwidth extension. Compared to existing phase-aware speech enhancement methods, it successfully avoids the bidirectional compensation effect between the magnitude and phase, leading to a better harmonic restoration. Notably, for the speech denoising task, the MP-SENet yields a state-of-the-art performance with a PESQ of 3.60 on the public VoiceBank+DEMAND dataset.
Don't lose the message while paraphrasing: A study on content preserving style transfer
Aug 17, 2023Text style transfer techniques are gaining popularity in natural language processing allowing paraphrasing text in the required form: from toxic to neural, from formal to informal, from old to the modern English language, etc. Solving the task is not sufficient to generate some neural/informal/modern text, but it is important to preserve the original content unchanged. This requirement becomes even more critical in some applications such as style transfer of goal-oriented dialogues where the factual information shall be kept to preserve the original message, e.g. ordering a certain type of pizza to a certain address at a certain time. The aspect of content preservation is critical for real-world applications of style transfer studies, but it has received little attention. To bridge this gap we perform a comparison of various style transfer models on the example of the formality transfer domain. To perform a study of the content preservation abilities of various style transfer methods we create a parallel dataset of formal vs. informal task-oriented dialogues. The key difference between our dataset and the existing ones like GYAFC [17] is the presence of goal-oriented dialogues with predefined semantic slots essential to be kept during paraphrasing, e.g. named entities. This additional annotation allowed us to conduct a precise comparative study of several state-of-the-art techniques for style transfer. Another result of our study is a modification of the unsupervised method LEWIS [19] which yields a substantial improvement over the original method and all evaluated baselines on the proposed task.
Secure Deep-JSCC Against Multiple Eavesdroppers
Aug 05, 2023In this paper, a generalization of deep learning-aided joint source channel coding (Deep-JSCC) approach to secure communications is studied. We propose an end-to-end (E2E) learning-based approach for secure communication against multiple eavesdroppers over complex-valued fading channels. Both scenarios of colluding and non-colluding eavesdroppers are studied. For the colluding strategy, eavesdroppers share their logits to collaboratively infer private attributes based on ensemble learning method, while for the non-colluding setup they act alone. The goal is to prevent eavesdroppers from inferring private (sensitive) information about the transmitted images, while delivering the images to a legitimate receiver with minimum distortion. By generalizing the ideas of privacy funnel and wiretap channel coding, the trade-off between the image recovery at the legitimate node and the information leakage to the eavesdroppers is characterized. To solve this secrecy funnel framework, we implement deep neural networks (DNNs) to realize a data-driven secure communication scheme, without relying on a specific data distribution. Simulations over CIFAR-10 dataset verifies the secrecy-utility trade-off. Adversarial accuracy of eavesdroppers are also studied over Rayleigh fading, Nakagami-m, and AWGN channels to verify the generalization of the proposed scheme. Our experiments show that employing the proposed secure neural encoding can decrease the adversarial accuracy by 28%.
Towards Top-Down Stereoscopic Image Quality Assessment via Stereo Attention
Aug 08, 2023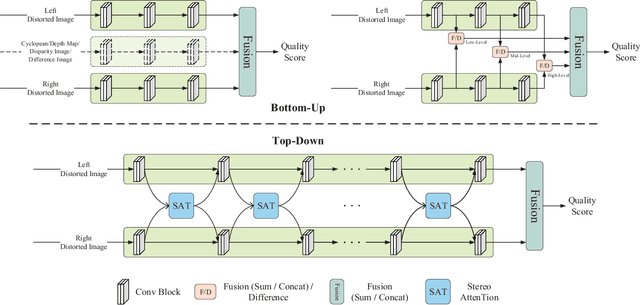
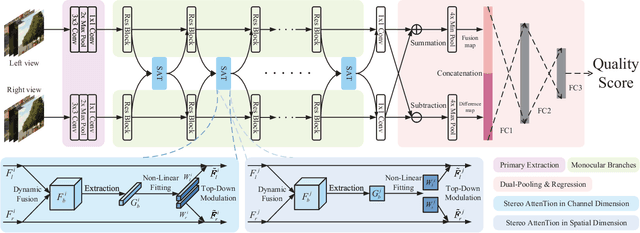
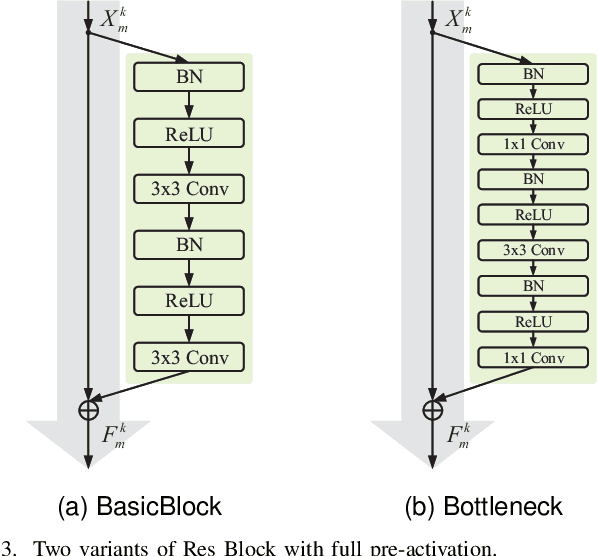
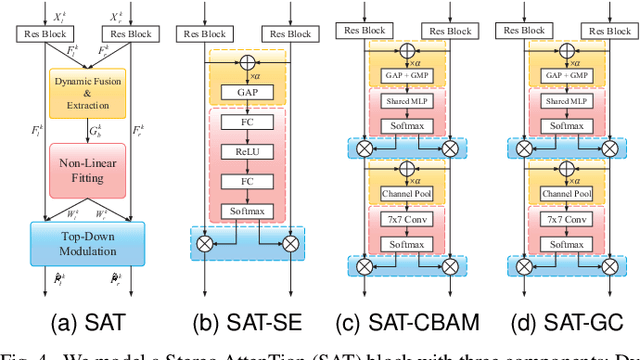
Stereoscopic image quality assessment (SIQA) plays a crucial role in evaluating and improving the visual experience of 3D content. Existing binocular properties and attention-based methods for SIQA have achieved promising performance. However, these bottom-up approaches are inadequate in exploiting the inherent characteristics of the human visual system (HVS). This paper presents a novel network for SIQA via stereo attention, employing a top-down perspective to guide the quality assessment process. Our proposed method realizes the guidance from high-level binocular signals down to low-level monocular signals, while the binocular and monocular information can be calibrated progressively throughout the processing pipeline. We design a generalized Stereo AttenTion (SAT) block to implement the top-down philosophy in stereo perception. This block utilizes the fusion-generated attention map as a high-level binocular modulator, influencing the representation of two low-level monocular features. Additionally, we introduce an Energy Coefficient (EC) to account for recent findings indicating that binocular responses in the primate primary visual cortex are less than the sum of monocular responses. The adaptive EC can tune the magnitude of binocular response flexibly, thus enhancing the formation of robust binocular features within our framework. To extract the most discriminative quality information from the summation and subtraction of the two branches of monocular features, we utilize a dual-pooling strategy that applies min-pooling and max-pooling operations to the respective branches. Experimental results highlight the superiority of our top-down method in simulating the property of visual perception and advancing the state-of-the-art in the SIQA field. The code of this work is available at https://github.com/Fanning-Zhang/SATNet.
Multi-goal Audio-visual Navigation using Sound Direction Map
Aug 01, 2023Over the past few years, there has been a great deal of research on navigation tasks in indoor environments using deep reinforcement learning agents. Most of these tasks use only visual information in the form of first-person images to navigate to a single goal. More recently, tasks that simultaneously use visual and auditory information to navigate to the sound source and even navigation tasks with multiple goals instead of one have been proposed. However, there has been no proposal for a generalized navigation task combining these two types of tasks and using both visual and auditory information in a situation where multiple sound sources are goals. In this paper, we propose a new framework for this generalized task: multi-goal audio-visual navigation. We first define the task in detail, and then we investigate the difficulty of the multi-goal audio-visual navigation task relative to the current navigation tasks by conducting experiments in various situations. The research shows that multi-goal audio-visual navigation has the difficulty of the implicit need to separate the sources of sound. Next, to mitigate the difficulties in this new task, we propose a method named sound direction map (SDM), which dynamically localizes multiple sound sources in a learning-based manner while making use of past memories. Experimental results show that the use of SDM significantly improves the performance of multiple baseline methods, regardless of the number of goals.
MVFlow: Deep Optical Flow Estimation of Compressed Videos with Motion Vector Prior
Aug 04, 2023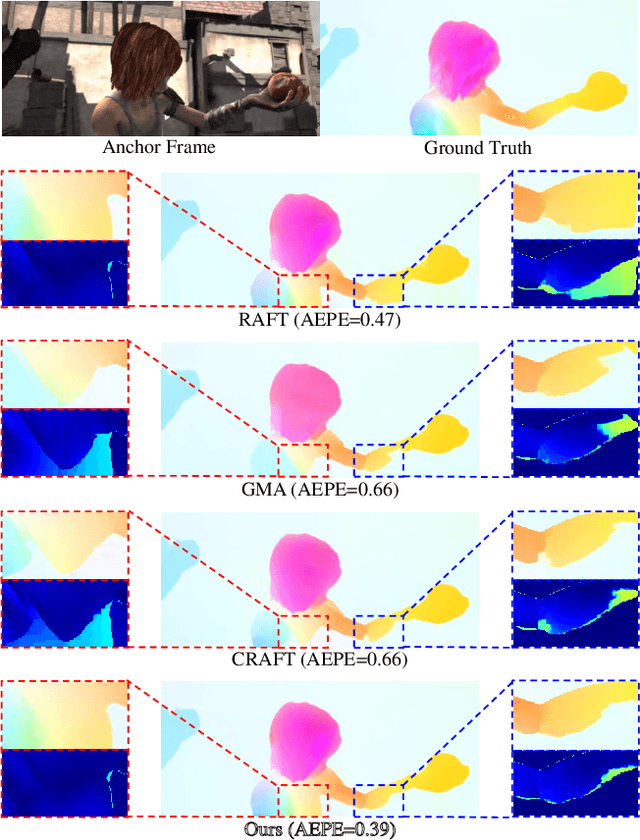
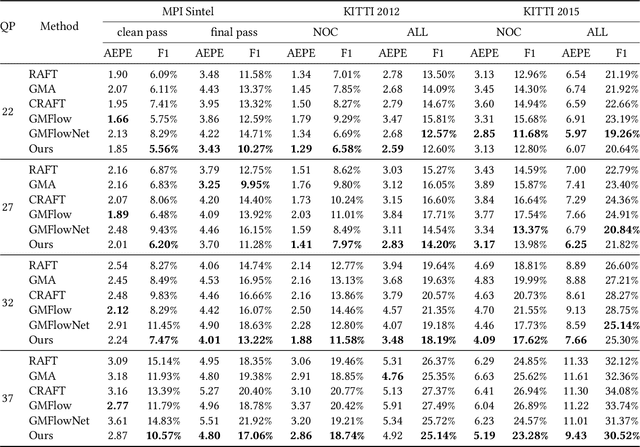
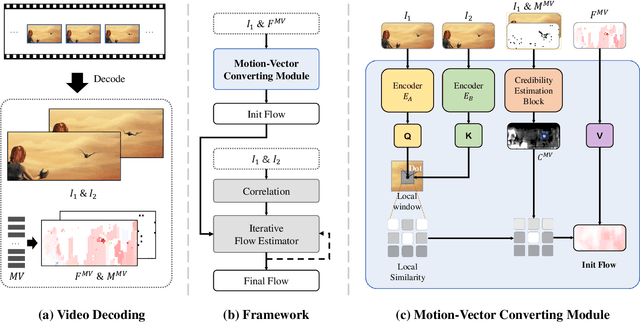
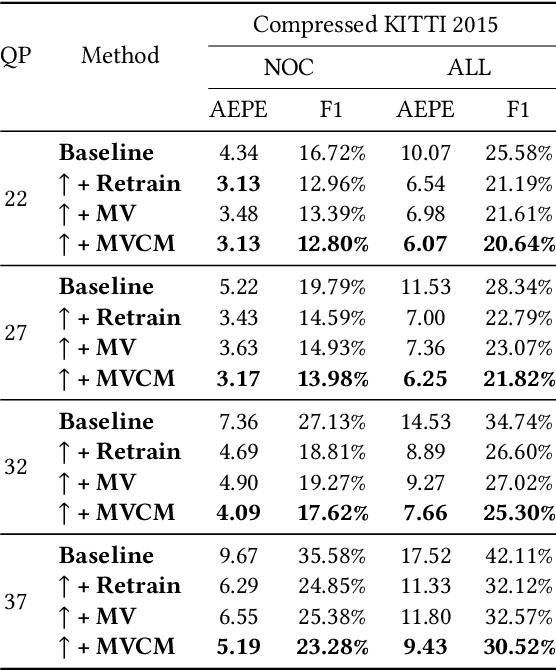
In recent years, many deep learning-based methods have been proposed to tackle the problem of optical flow estimation and achieved promising results. However, they hardly consider that most videos are compressed and thus ignore the pre-computed information in compressed video streams. Motion vectors, one of the compression information, record the motion of the video frames. They can be directly extracted from the compression code stream without computational cost and serve as a solid prior for optical flow estimation. Therefore, we propose an optical flow model, MVFlow, which uses motion vectors to improve the speed and accuracy of optical flow estimation for compressed videos. In detail, MVFlow includes a key Motion-Vector Converting Module, which ensures that the motion vectors can be transformed into the same domain of optical flow and then be utilized fully by the flow estimation module. Meanwhile, we construct four optical flow datasets for compressed videos containing frames and motion vectors in pairs. The experimental results demonstrate the superiority of our proposed MVFlow, which can reduce the AEPE by 1.09 compared to existing models or save 52% time to achieve similar accuracy to existing models.
Model Checking Time Window Temporal Logic for Hyperproperties
Aug 10, 2023Hyperproperties extend trace properties to express properties of sets of traces, and they are increasingly popular in specifying various security and performance-related properties in domains such as cyber-physical systems, smart grids, and automotive. This paper introduces a model checking algorithm for a new formalism, HyperTWTL, which extends Time Window Temporal Logic (TWTL) -- a domain-specific formal specification language for robotics, by allowing explicit and simultaneous quantification over multiple execution traces. We present HyperTWTL with both \emph{synchronous} and \emph{asynchronous} semantics, based on the alignment of the timestamps in the traces. Consequently, we demonstrate the application of HyperTWTL in formalizing important information-flow security policies and concurrency for robotics applications. Finally, we propose a model checking algorithm for verifying fragments of HyperTWTL by reducing the problem to a TWTL model checking problem.
LiDAR-Camera Panoptic Segmentation via Geometry-Consistent and Semantic-Aware Alignment
Aug 03, 2023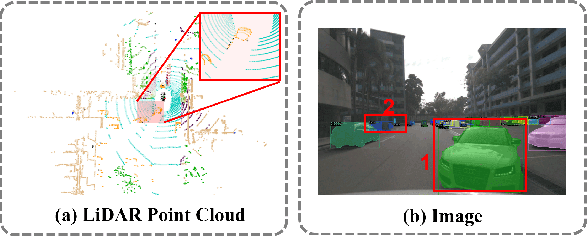
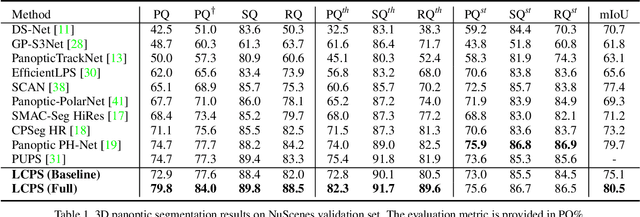
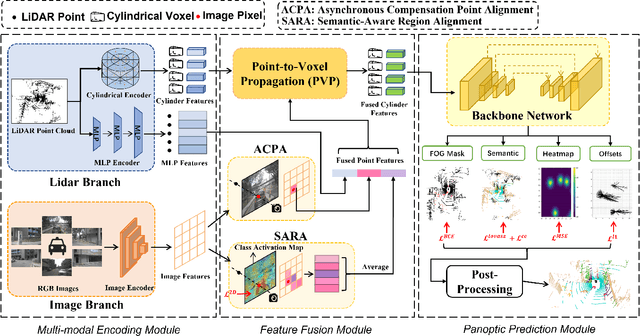
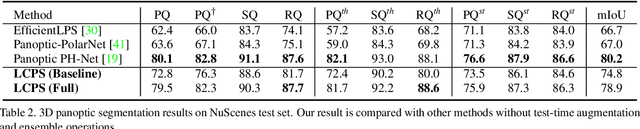
3D panoptic segmentation is a challenging perception task that requires both semantic segmentation and instance segmentation. In this task, we notice that images could provide rich texture, color, and discriminative information, which can complement LiDAR data for evident performance improvement, but their fusion remains a challenging problem. To this end, we propose LCPS, the first LiDAR-Camera Panoptic Segmentation network. In our approach, we conduct LiDAR-Camera fusion in three stages: 1) an Asynchronous Compensation Pixel Alignment (ACPA) module that calibrates the coordinate misalignment caused by asynchronous problems between sensors; 2) a Semantic-Aware Region Alignment (SARA) module that extends the one-to-one point-pixel mapping to one-to-many semantic relations; 3) a Point-to-Voxel feature Propagation (PVP) module that integrates both geometric and semantic fusion information for the entire point cloud. Our fusion strategy improves about 6.9% PQ performance over the LiDAR-only baseline on NuScenes dataset. Extensive quantitative and qualitative experiments further demonstrate the effectiveness of our novel framework. The code will be released at https://github.com/zhangzw12319/lcps.git.
Promise and Limitations of Supervised Optimal Transport-Based Graph Summarization via Information Theoretic Measures
May 11, 2023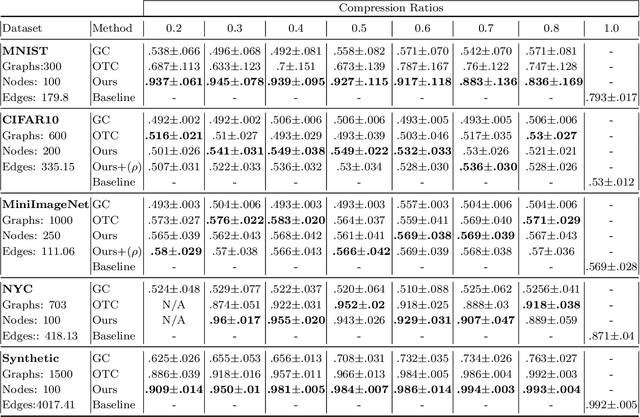
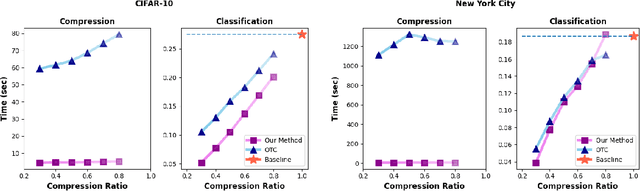
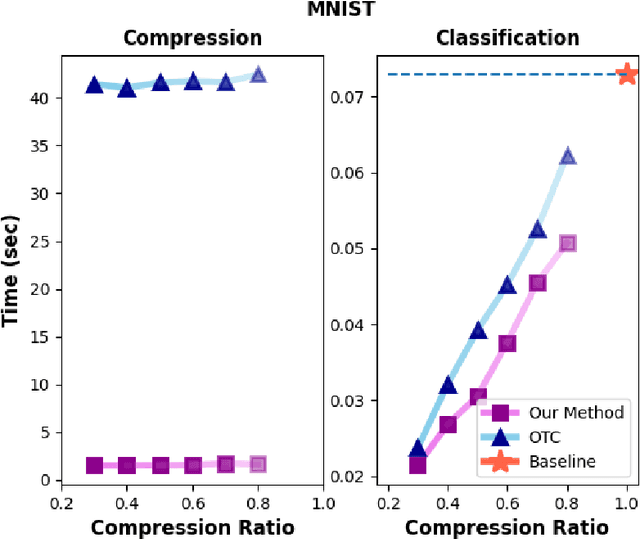

Graph summarization is the problem of producing smaller graph representations of an input graph dataset, in such a way that the smaller compressed graphs capture relevant structural information for downstream tasks. There is a recent graph summarization method that formulates an optimal transport-based framework that allows prior information about node, edge, and attribute importance (never defined in that work) to be incorporated into the graph summarization process. However, very little is known about the statistical properties of this framework. To elucidate this question, we consider the problem of supervised graph summarization, wherein by using information theoretic measures we seek to preserve relevant information about a class label. To gain a theoretical perspective on the supervised summarization problem itself, we first formulate it in terms of maximizing the Shannon mutual information between the summarized graph and the class label. We show an NP-hardness of approximation result for this problem, thereby constraining what one should expect from proposed solutions. We then propose a summarization method that incorporates mutual information estimates between random variables associated with sample graphs and class labels into the optimal transport compression framework. We empirically show performance improvements over previous works in terms of classification accuracy and time on synthetic and certain real datasets. We also theoretically explore the limitations of the optimal transport approach for the supervised summarization problem and we show that it fails to satisfy a certain desirable information monotonicity property.
LiDAR Meta Depth Completion
Aug 16, 2023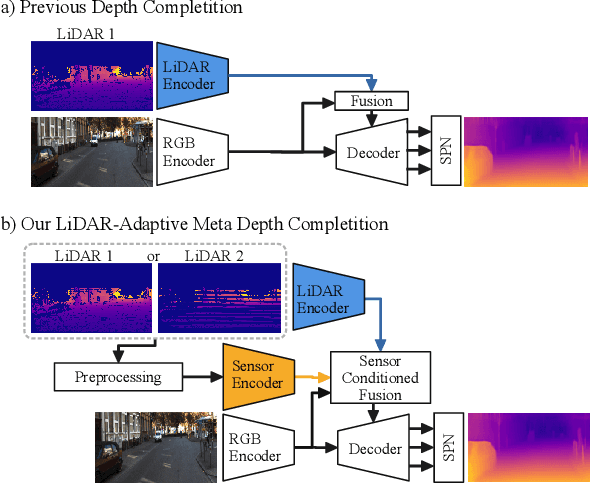

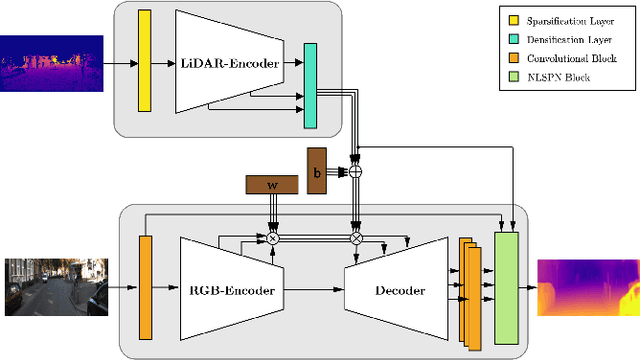
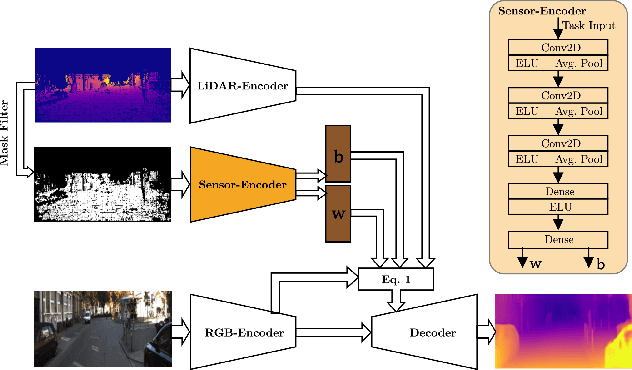
Depth estimation is one of the essential tasks to be addressed when creating mobile autonomous systems. While monocular depth estimation methods have improved in recent times, depth completion provides more accurate and reliable depth maps by additionally using sparse depth information from other sensors such as LiDAR. However, current methods are specifically trained for a single LiDAR sensor. As the scanning pattern differs between sensors, every new sensor would require re-training a specialized depth completion model, which is computationally inefficient and not flexible. Therefore, we propose to dynamically adapt the depth completion model to the used sensor type enabling LiDAR adaptive depth completion. Specifically, we propose a meta depth completion network that uses data patterns derived from the data to learn a task network to alter weights of the main depth completion network to solve a given depth completion task effectively. The method demonstrates a strong capability to work on multiple LiDAR scanning patterns and can also generalize to scanning patterns that are unseen during training. While using a single model, our method yields significantly better results than a non-adaptive baseline trained on different LiDAR patterns. It outperforms LiDAR-specific expert models for very sparse cases. These advantages allow flexible deployment of a single depth completion model on different sensors, which could also prove valuable to process the input of nascent LiDAR technology with adaptive instead of fixed scanning patterns.