 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph-Structured Kernel Design for Power Flow Learning using Gaussian Processes
Aug 15, 2023
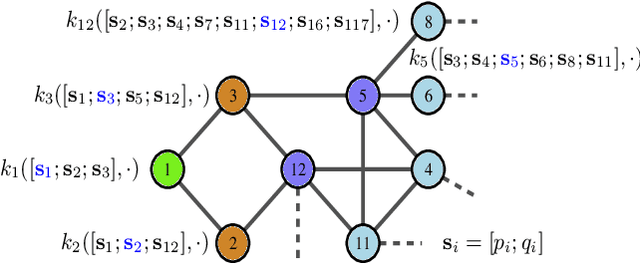
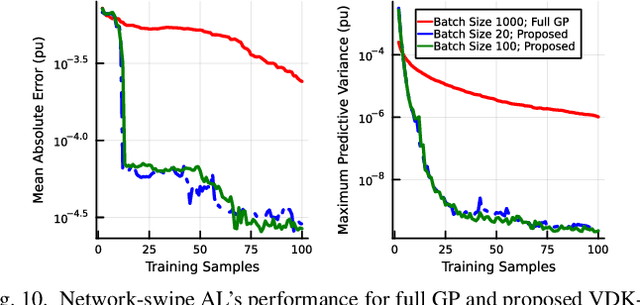
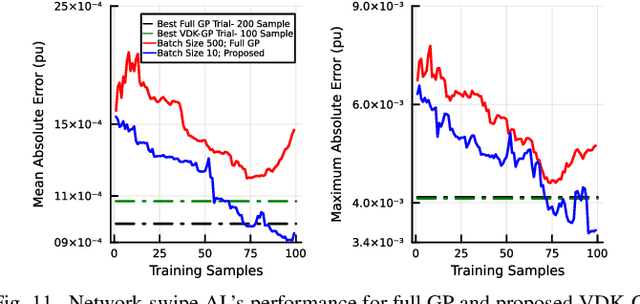
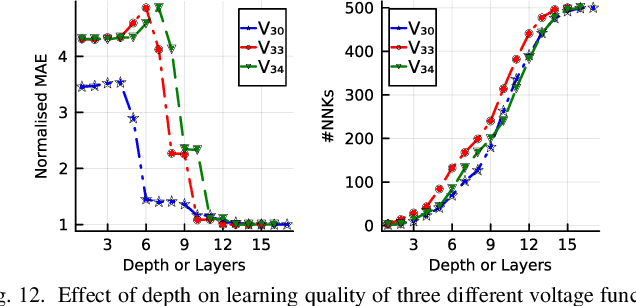
This paper presents a physics-inspired graph-structured kernel designed for power flow learning using Gaussian Process (GP). The kernel, named the vertex-degree kernel (VDK), relies on latent decomposition of voltage-injection relationship based on the network graph or topology. Notably, VDK design avoids the need to solve optimization problems for kernel search. To enhance efficiency, we also explore a graph-reduction approach to obtain a VDK representation with lesser terms. Additionally, we propose a novel network-swipe active learning scheme, which intelligently selects sequential training inputs to accelerate the learning of VDK. Leveraging the additive structure of VDK, the active learning algorithm performs a block-descent type procedure on GP's predictive variance, serving as a proxy for information gain. Simulations demonstrate that the proposed VDK-GP achieves more than two fold sample complexity reduction, compared to full GP on medium scale 500-Bus and large scale 1354-Bus power systems. The network-swipe algorithm outperforms mean performance of 500 random trials on test predictions by two fold for medium-sized 500-Bus systems and best performance of 25 random trials for large-scale 1354-Bus systems by 10%. Moreover, we demonstrate that the proposed method's performance for uncertainty quantification applications with distributionally shifted testing data sets.
ICAFusion: Iterative Cross-Attention Guided Feature Fusion for Multispectral Object Detection
Aug 15, 2023
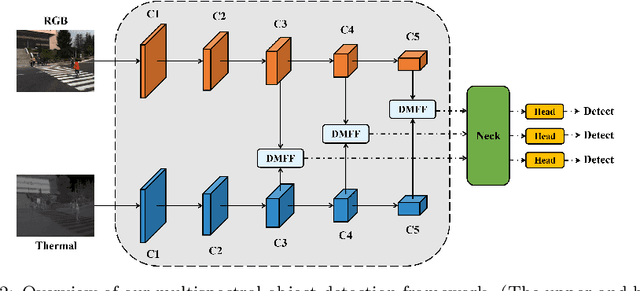
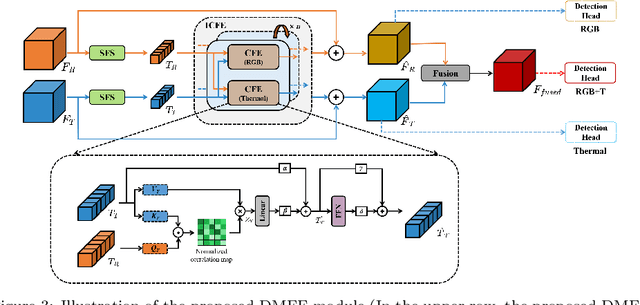
Effective feature fusion of multispectral images plays a crucial role in multi-spectral object detection. Previous studies have demonstrated the effectiveness of feature fusion using convolutional neural networks, but these methods are sensitive to image misalignment due to the inherent deffciency in local-range feature interaction resulting in the performance degradation. To address this issue, a novel feature fusion framework of dual cross-attention transformers is proposed to model global feature interaction and capture complementary information across modalities simultaneously. This framework enhances the discriminability of object features through the query-guided cross-attention mechanism, leading to improved performance. However, stacking multiple transformer blocks for feature enhancement incurs a large number of parameters and high spatial complexity. To handle this, inspired by the human process of reviewing knowledge, an iterative interaction mechanism is proposed to share parameters among block-wise multimodal transformers, reducing model complexity and computation cost. The proposed method is general and effective to be integrated into different detection frameworks and used with different backbones. Experimental results on KAIST, FLIR, and VEDAI datasets show that the proposed method achieves superior performance and faster inference, making it suitable for various practical scenarios. Code will be available at https://github.com/chanchanchan97/ICAFusion.
Data Encoding For Healthcare Data Democratisation and Information Leakage Prevention
May 05, 2023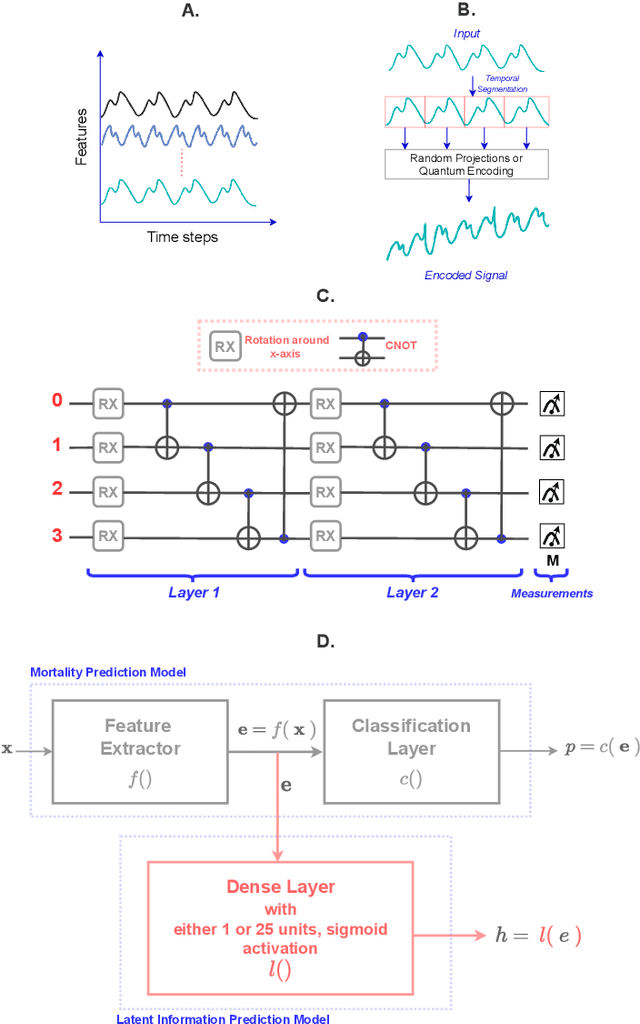

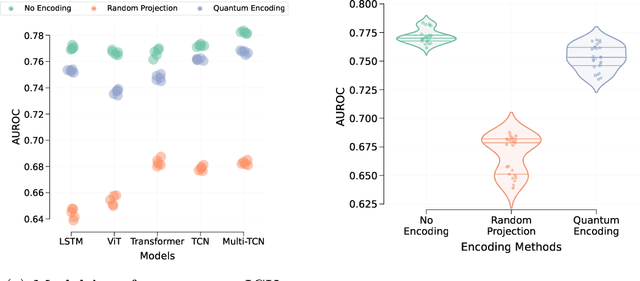
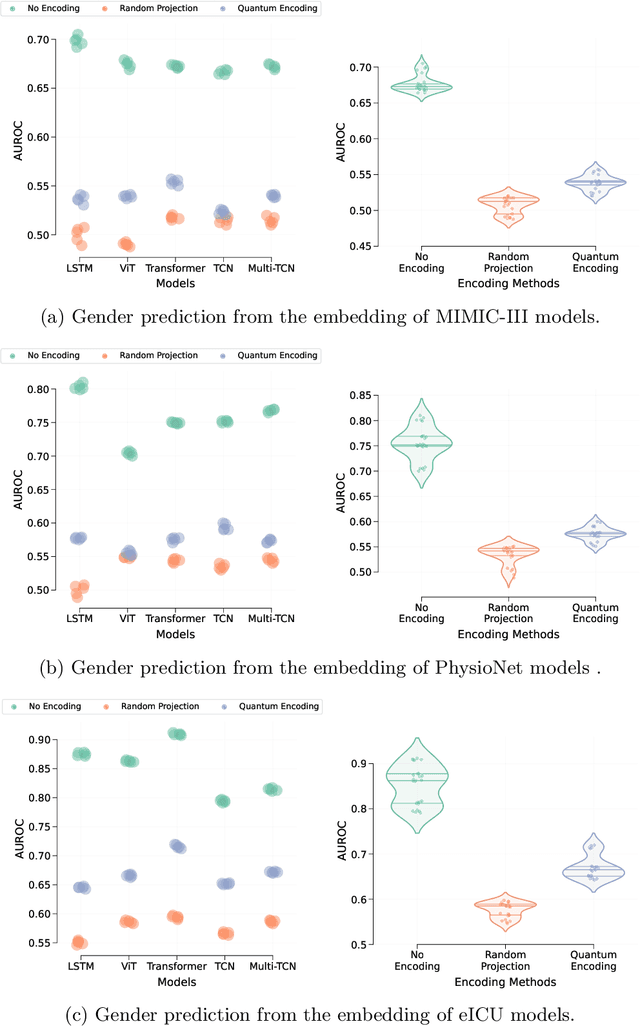
The lack of data democratization and information leakage from trained models hinder the development and acceptance of robust deep learning-based healthcare solutions. This paper argues that irreversible data encoding can provide an effective solution to achieve data democratization without violating the privacy constraints imposed on healthcare data and clinical models. An ideal encoding framework transforms the data into a new space where it is imperceptible to a manual or computational inspection. However, encoded data should preserve the semantics of the original data such that deep learning models can be trained effectively. This paper hypothesizes the characteristics of the desired encoding framework and then exploits random projections and random quantum encoding to realize this framework for dense and longitudinal or time-series data. Experimental evaluation highlights that models trained on encoded time-series data effectively uphold the information bottleneck principle and hence, exhibit lesser information leakage from trained models.
Assessing Guest Nationality Composition from Hotel Reviews
Aug 11, 2023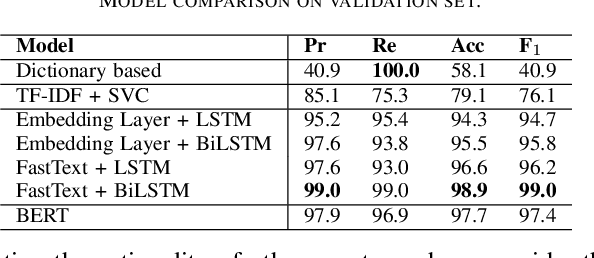

Many hotels target guest acquisition efforts to specific markets in order to best anticipate individual preferences and needs of their guests. Likewise, such strategic positioning is a prerequisite for efficient marketing budget allocation. Official statistics report on the number of visitors from different countries, but no fine-grained information on the guest composition of individual businesses exists. There is, however, growing interest in such data from competitors, suppliers, researchers and the general public. We demonstrate how machine learning can be leveraged to extract references to guest nationalities from unstructured text reviews in order to dynamically assess and monitor the dynamics of guest composition of individual businesses. In particular, we show that a rather simple architecture of pre-trained embeddings and stacked LSTM layers provides a better performance-runtime tradeoff than more complex state-of-the-art language models.
FLAIR #2: textural and temporal information for semantic segmentation from multi-source optical imagery
May 23, 2023

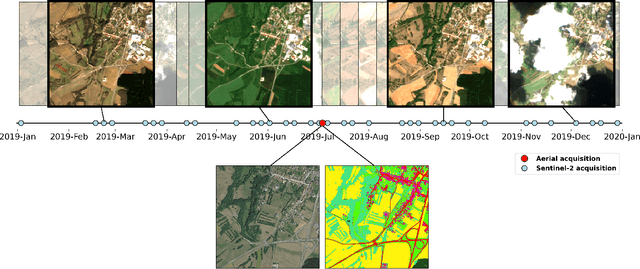

The FLAIR #2 dataset hereby presented includes two very distinct types of data, which are exploited for a semantic segmentation task aimed at mapping land cover. The data fusion workflow proposes the exploitation of the fine spatial and textural information of very high spatial resolution (VHR) mono-temporal aerial imagery and the temporal and spectral richness of high spatial resolution (HR) time series of Copernicus Sentinel-2 satellite images. The French National Institute of Geographical and Forest Information (IGN), in response to the growing availability of high-quality Earth Observation (EO) data, is actively exploring innovative strategies to integrate these data with heterogeneous characteristics. IGN is therefore offering this dataset to promote innovation and improve our knowledge of our territories.
Deep Q-Network for Stochastic Process Environments
Aug 07, 2023Reinforcement learning is a powerful approach for training an optimal policy to solve complex problems in a given system. This project aims to demonstrate the application of reinforcement learning in stochastic process environments with missing information, using Flappy Bird and a newly developed stock trading environment as case studies. We evaluate various structures of Deep Q-learning networks and identify the most suitable variant for the stochastic process environment. Additionally, we discuss the current challenges and propose potential improvements for further work in environment-building and reinforcement learning techniques.
Digital Twin of the Radio Environment: A Novel Approach for Anomaly Detection in Wireless Networks
Aug 14, 2023The increasing relevance of resilience in wireless connectivity for Industry 4.0 stems from the growing complexity and interconnectivity of industrial systems, where a single point of failure can disrupt the entire network, leading to significant downtime and productivity losses. It is thus essential to constantly monitor the network and identify any anomaly such as a jammer. Hereby, technologies envisioned to be integrated in 6G, in particular joint communications and sensing (JCAS) and accurate indoor positioning of transmitters, open up the possibility to build a digital twin (DT) of the radio environment. This paper proposes a new approach for anomaly detection in wireless networks enabled by such a DT which allows to integrate contextual information on the network in the anomaly detection procedure. The basic approach is thereby to compare expected received signal strengths (RSSs) from the DT with measurements done by distributed sensing units (SUs). Employing simulations, different algorithms are compared regarding their ability to infer from the comparison on the presence or absence of an anomaly, particular a jammer. Overall, the feasibility of anomaly detection using the proposed approach is demonstrated which integrates in the ongoing research on employing DTs for comprehensive monitoring of wireless networks.
Context-Aware Planning and Environment-Aware Memory for Instruction Following Embodied Agents
Aug 14, 2023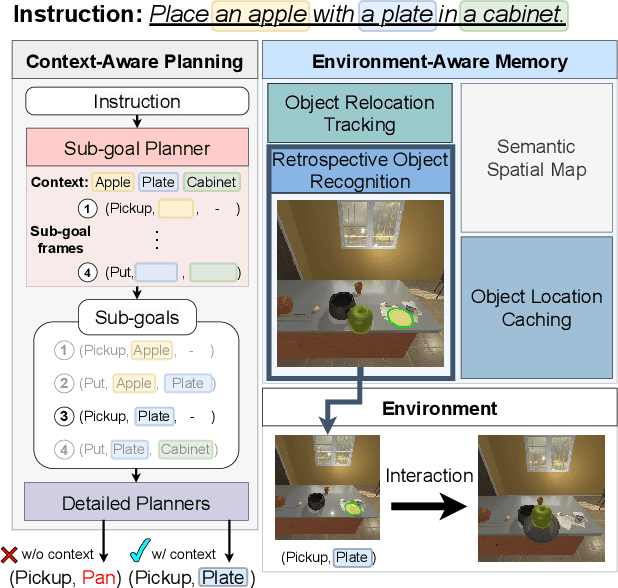
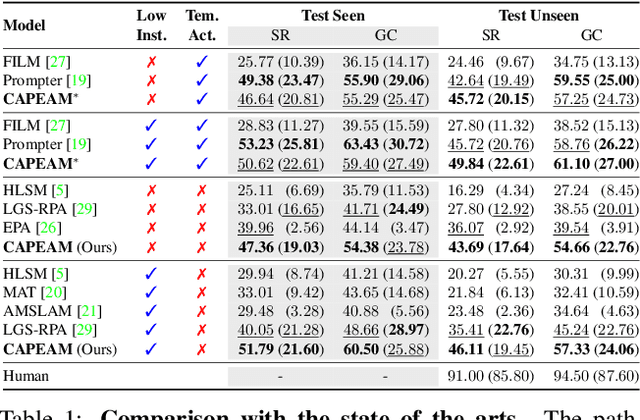

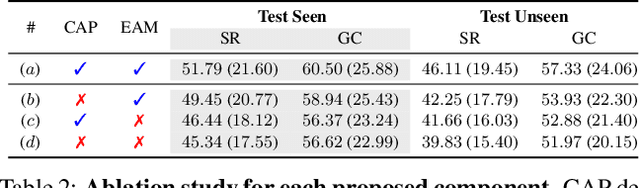
Accomplishing household tasks such as 'bringing a cup of water' requires planning step-by-step actions by maintaining knowledge about the spatial arrangement of objects and the consequences of previous actions. Perception models of the current embodied AI agents, however, often make mistakes due to a lack of such knowledge but rely on imperfect learning of imitating agents or an algorithmic planner without knowledge about the changed environment by the previous actions. To address the issue, we propose CPEM (Context-aware Planner and Environment-aware Memory) to incorporate the contextual information of previous actions for planning and maintaining spatial arrangement of objects with their states (e.g., if an object has been moved or not) in an environment to the perception model for improving both visual navigation and object interaction. We observe that CPEM achieves state-of-the-art task success performance in various metrics using a challenging interactive instruction following benchmark both in seen and unseen environments by large margins (up to +10.70% in unseen env.). CPEM with the templated actions, named ECLAIR, also won the 1st generalist language grounding agents challenge at Embodied AI Workshop in CVPR'23.
Accurate Eye Tracking from Dense 3D Surface Reconstructions using Single-Shot Deflectometry
Aug 14, 2023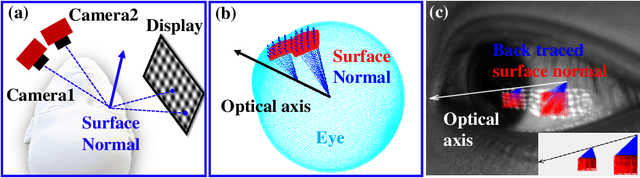

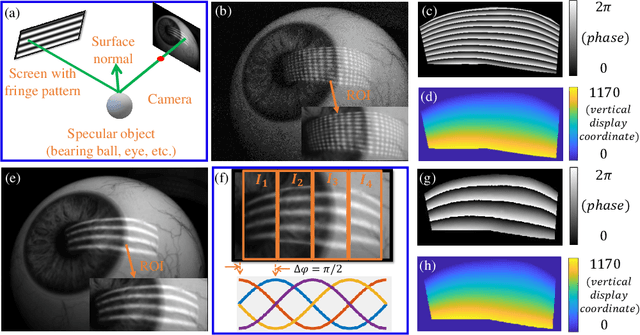
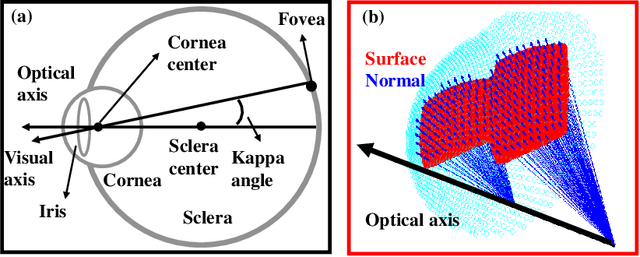
Eye-tracking plays a crucial role in the development of virtual reality devices, neuroscience research, and psychology. Despite its significance in numerous applications, achieving an accurate, robust, and fast eye-tracking solution remains a considerable challenge for current state-of-the-art methods. While existing reflection-based techniques (e.g., "glint tracking") are considered the most accurate, their performance is limited by their reliance on sparse 3D surface data acquired solely from the cornea surface. In this paper, we rethink the way how specular reflections can be used for eye tracking: We propose a novel method for accurate and fast evaluation of the gaze direction that exploits teachings from single-shot phase-measuring-deflectometry (PMD). In contrast to state-of-the-art reflection-based methods, our method acquires dense 3D surface information of both cornea and sclera within only one single camera frame (single-shot). Improvements in acquired reflection surface points("glints") of factors $>3300 \times$ are easily achievable. We show the feasibility of our approach with experimentally evaluated gaze errors of only $\leq 0.25^\circ$ demonstrating a significant improvement over the current state-of-the-art.
A Unified Masked Autoencoder with Patchified Skeletons for Motion Synthesis
Aug 14, 2023The synthesis of human motion has traditionally been addressed through task-dependent models that focus on specific challenges, such as predicting future motions or filling in intermediate poses conditioned on known key-poses. In this paper, we present a novel task-independent model called UNIMASK-M, which can effectively address these challenges using a unified architecture. Our model obtains comparable or better performance than the state-of-the-art in each field. Inspired by Vision Transformers (ViTs), our UNIMASK-M model decomposes a human pose into body parts to leverage the spatio-temporal relationships existing in human motion. Moreover, we reformulate various pose-conditioned motion synthesis tasks as a reconstruction problem with different masking patterns given as input. By explicitly informing our model about the masked joints, our UNIMASK-M becomes more robust to occlusions. Experimental results show that our model successfully forecasts human motion on the Human3.6M dataset. Moreover, it achieves state-of-the-art results in motion inbetweening on the LaFAN1 dataset, particularly in long transition periods. More information can be found on the project website https://sites.google.com/view/estevevallsmascaro/publications/unimask-m.