 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Motion-Corrected Moving Average: Including Post-Hoc Temporal Information for Improved Video Segmentation
Mar 05, 2024
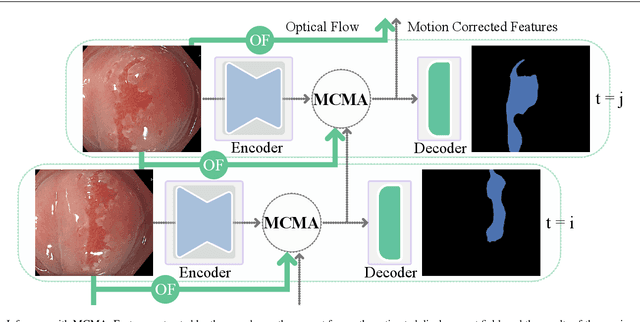
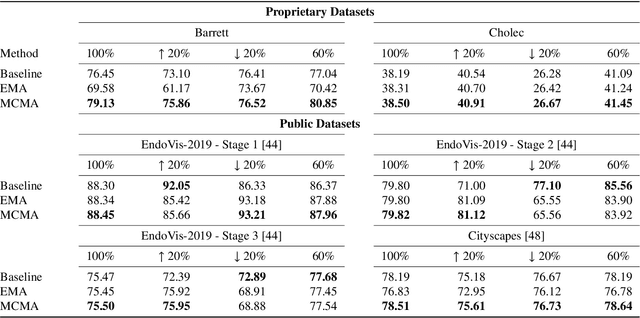
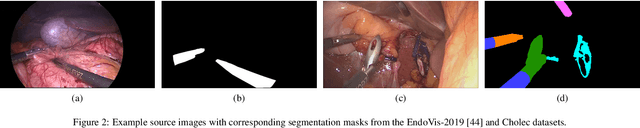
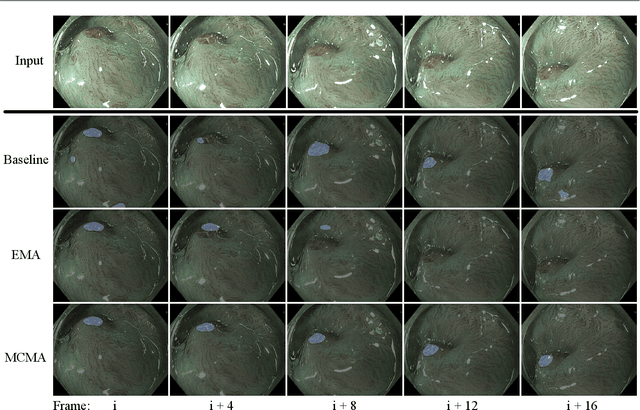
Real-time computational speed and a high degree of precision are requirements for computer-assisted interventions. Applying a segmentation network to a medical video processing task can introduce significant inter-frame prediction noise. Existing approaches can reduce inconsistencies by including temporal information but often impose requirements on the architecture or dataset. This paper proposes a method to include temporal information in any segmentation model and, thus, a technique to improve video segmentation performance without alterations during training or additional labeling. With Motion-Corrected Moving Average, we refine the exponential moving average between the current and previous predictions. Using optical flow to estimate the movement between consecutive frames, we can shift the prior term in the moving-average calculation to align with the geometry of the current frame. The optical flow calculation does not require the output of the model and can therefore be performed in parallel, leading to no significant runtime penalty for our approach. We evaluate our approach on two publicly available segmentation datasets and two proprietary endoscopic datasets and show improvements over a baseline approach.
S2LIC: Learned Image Compression with the SwinV2 Block, Adaptive Channel-wise and Global-inter Attention Context
Mar 21, 2024
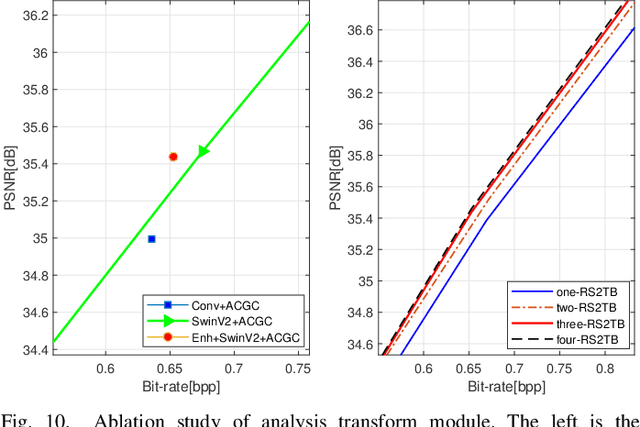


Recently, deep learning technology has been successfully applied in the field of image compression, leading to superior rate-distortion performance. It is crucial to design an effective and efficient entropy model to estimate the probability distribution of the latent representation. However, the majority of entropy models primarily focus on one-dimensional correlation processing between channel and spatial information. In this paper, we propose an Adaptive Channel-wise and Global-inter attention Context (ACGC) entropy model, which can efficiently achieve dual feature aggregation in both inter-slice and intraslice contexts. Specifically, we divide the latent representation into different slices and then apply the ACGC model in a parallel checkerboard context to achieve faster decoding speed and higher rate-distortion performance. In order to capture redundant global features across different slices, we utilize deformable attention in adaptive global-inter attention to dynamically refine the attention weights based on the actual spatial relationships and context. Furthermore, in the main transformation structure, we propose a high-performance S2LIC model. We introduce the residual SwinV2 Transformer model to capture global feature information and utilize a dense block network as the feature enhancement module to improve the nonlinear representation of the image within the transformation structure. Experimental results demonstrate that our method achieves faster encoding and decoding speeds and outperforms VTM-17.1 and some recent learned image compression methods in both PSNR and MS-SSIM metrics.
Less but Better: Enabling Generalized Zero-shot Learning Towards Unseen Domains by Intrinsic Learning from Redundant LLM Semantics
Mar 21, 2024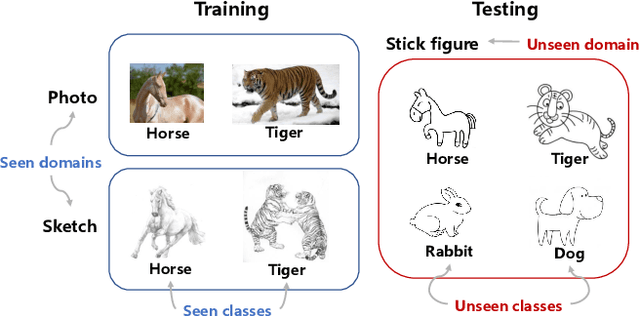
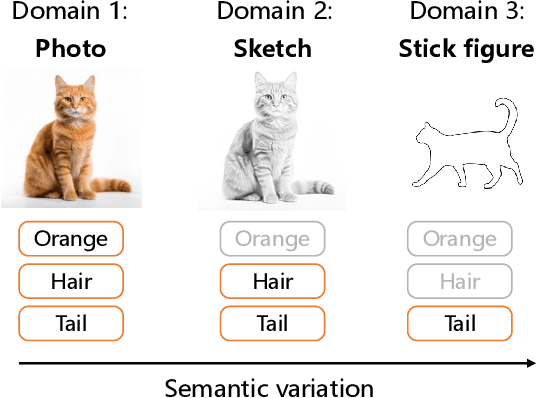
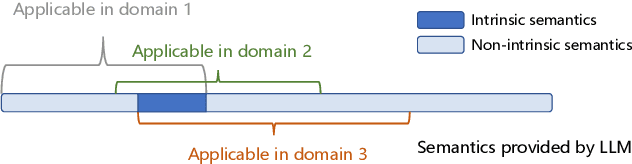
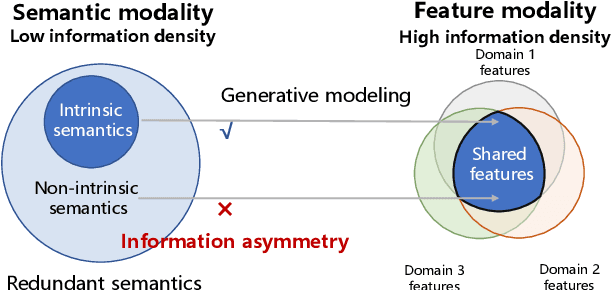
Generalized zero-shot learning (GZSL) focuses on recognizing seen and unseen classes against domain shift problem (DSP) where data of unseen classes may be misclassified as seen classes. However, existing GZSL is still limited to seen domains. In the current work, we pioneer cross-domain GZSL (CDGZSL) which addresses GZSL towards unseen domains. Different from existing GZSL methods which alleviate DSP by generating features of unseen classes with semantics, CDGZSL needs to construct a common feature space across domains and acquire the corresponding intrinsic semantics shared among domains to transfer from seen to unseen domains. Considering the information asymmetry problem caused by redundant class semantics annotated with large language models (LLMs), we present Meta Domain Alignment Semantic Refinement (MDASR). Technically, MDASR consists of two parts: Inter-class Similarity Alignment (ISA), which eliminates the non-intrinsic semantics not shared across all domains under the guidance of inter-class feature relationships, and Unseen-class Meta Generation (UMG), which preserves intrinsic semantics to maintain connectivity between seen and unseen classes by simulating feature generation. MDASR effectively aligns the redundant semantic space with the common feature space, mitigating the information asymmetry in CDGZSL. The effectiveness of MDASR is demonstrated on the Office-Home and Mini-DomainNet, and we have shared the LLM-based semantics for these datasets as the benchmark.
WEEP: A method for spatial interpretation of weakly supervised CNN models in computational pathology
Mar 22, 2024Deep learning enables the modelling of high-resolution histopathology whole-slide images (WSI). Weakly supervised learning of tile-level data is typically applied for tasks where labels only exist on the patient or WSI level (e.g. patient outcomes or histological grading). In this context, there is a need for improved spatial interpretability of predictions from such models. We propose a novel method, Wsi rEgion sElection aPproach (WEEP), for model interpretation. It provides a principled yet straightforward way to establish the spatial area of WSI required for assigning a particular prediction label. We demonstrate WEEP on a binary classification task in the area of breast cancer computational pathology. WEEP is easy to implement, is directly connected to the model-based decision process, and offers information relevant to both research and diagnostic applications.
MIntRec2.0: A Large-scale Benchmark Dataset for Multimodal Intent Recognition and Out-of-scope Detection in Conversations
Mar 20, 2024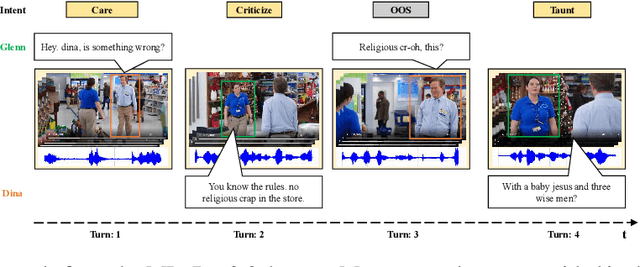
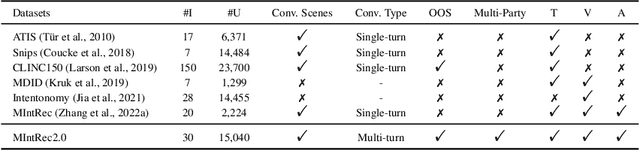
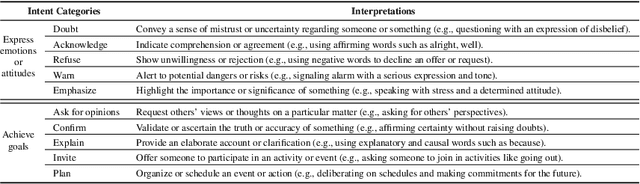
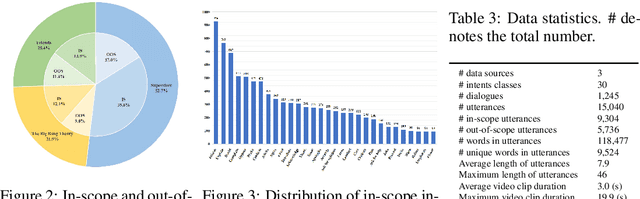
Multimodal intent recognition poses significant challenges, requiring the incorporation of non-verbal modalities from real-world contexts to enhance the comprehension of human intentions. Existing benchmark datasets are limited in scale and suffer from difficulties in handling out-of-scope samples that arise in multi-turn conversational interactions. We introduce MIntRec2.0, a large-scale benchmark dataset for multimodal intent recognition in multi-party conversations. It contains 1,245 dialogues with 15,040 samples, each annotated within a new intent taxonomy of 30 fine-grained classes. Besides 9,304 in-scope samples, it also includes 5,736 out-of-scope samples appearing in multi-turn contexts, which naturally occur in real-world scenarios. Furthermore, we provide comprehensive information on the speakers in each utterance, enriching its utility for multi-party conversational research. We establish a general framework supporting the organization of single-turn and multi-turn dialogue data, modality feature extraction, multimodal fusion, as well as in-scope classification and out-of-scope detection. Evaluation benchmarks are built using classic multimodal fusion methods, ChatGPT, and human evaluators. While existing methods incorporating nonverbal information yield improvements, effectively leveraging context information and detecting out-of-scope samples remains a substantial challenge. Notably, large language models exhibit a significant performance gap compared to humans, highlighting the limitations of machine learning methods in the cognitive intent understanding task. We believe that MIntRec2.0 will serve as a valuable resource, providing a pioneering foundation for research in human-machine conversational interactions, and significantly facilitating related applications. The full dataset and codes are available at https://github.com/thuiar/MIntRec2.0.
Leveraging Large Language Models for Preliminary Security Risk Analysis: A Mission-Critical Case Study
Mar 23, 2024Preliminary security risk analysis (PSRA) provides a quick approach to identify, evaluate and propose remeditation to potential risks in specific scenarios. The extensive expertise required for an effective PSRA and the substantial ammount of textual-related tasks hinder quick assessments in mission-critical contexts, where timely and prompt actions are essential. The speed and accuracy of human experts in PSRA significantly impact response time. A large language model can quickly summarise information in less time than a human. To our knowledge, no prior study has explored the capabilities of fine-tuned models (FTM) in PSRA. Our case study investigates the proficiency of FTM to assist practitioners in PSRA. We manually curated 141 representative samples from over 50 mission-critical analyses archived by the industrial context team in the last five years.We compared the proficiency of the FTM versus seven human experts. Within the industrial context, our approach has proven successful in reducing errors in PSRA, hastening security risk detection, and minimizing false positives and negatives. This translates to cost savings for the company by averting unnecessary expenses associated with implementing unwarranted countermeasures. Therefore, experts can focus on more comprehensive risk analysis, leveraging LLMs for an effective preliminary assessment within a condensed timeframe.
Optimisic Information Directed Sampling
Feb 23, 2024We study the problem of online learning in contextual bandit problems where the loss function is assumed to belong to a known parametric function class. We propose a new analytic framework for this setting that bridges the Bayesian theory of information-directed sampling due to Russo and Van Roy (2018) and the worst-case theory of Foster, Kakade, Qian, and Rakhlin (2021) based on the decision-estimation coefficient. Drawing from both lines of work, we propose a algorithmic template called Optimistic Information-Directed Sampling and show that it can achieve instance-dependent regret guarantees similar to the ones achievable by the classic Bayesian IDS method, but with the major advantage of not requiring any Bayesian assumptions. The key technical innovation of our analysis is introducing an optimistic surrogate model for the regret and using it to define a frequentist version of the Information Ratio of Russo and Van Roy (2018), and a less conservative version of the Decision Estimation Coefficient of Foster et al. (2021). Keywords: Contextual bandits, information-directed sampling, decision estimation coefficient, first-order regret bounds.
AUD-TGN: Advancing Action Unit Detection with Temporal Convolution and GPT-2 in Wild Audiovisual Contexts
Mar 20, 2024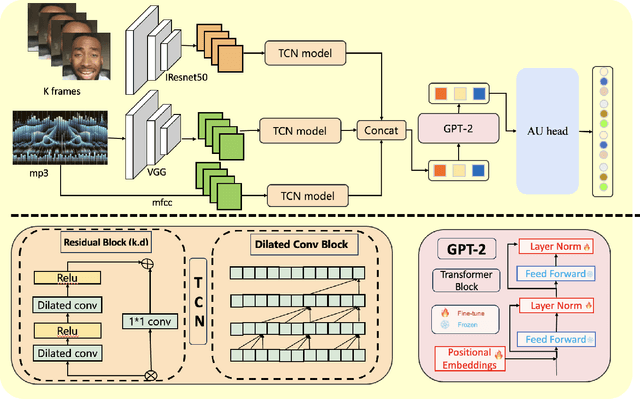
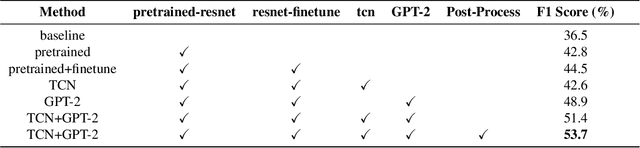
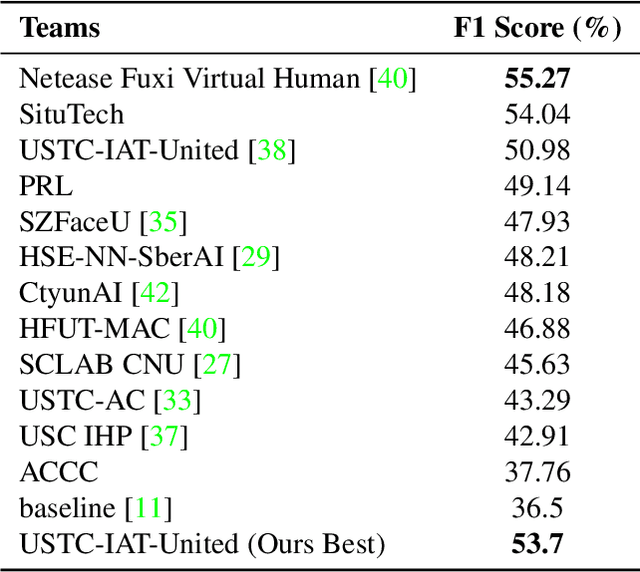
Leveraging the synergy of both audio data and visual data is essential for understanding human emotions and behaviors, especially in in-the-wild setting. Traditional methods for integrating such multimodal information often stumble, leading to less-than-ideal outcomes in the task of facial action unit detection. To overcome these shortcomings, we propose a novel approach utilizing audio-visual multimodal data. This method enhances audio feature extraction by leveraging Mel Frequency Cepstral Coefficients (MFCC) and Log-Mel spectrogram features alongside a pre-trained VGGish network. Moreover, this paper adaptively captures fusion features across modalities by modeling the temporal relationships, and ultilizes a pre-trained GPT-2 model for sophisticated context-aware fusion of multimodal information. Our method notably improves the accuracy of AU detection by understanding the temporal and contextual nuances of the data, showcasing significant advancements in the comprehension of intricate scenarios. These findings underscore the potential of integrating temporal dynamics and contextual interpretation, paving the way for future research endeavors.
AdaTrans: Feature-wise and Sample-wise Adaptive Transfer Learning for High-dimensional Regression
Mar 20, 2024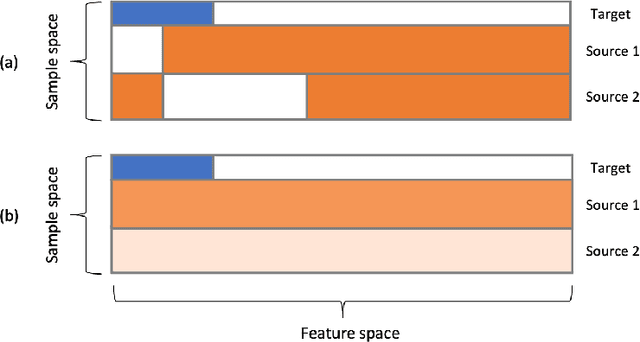
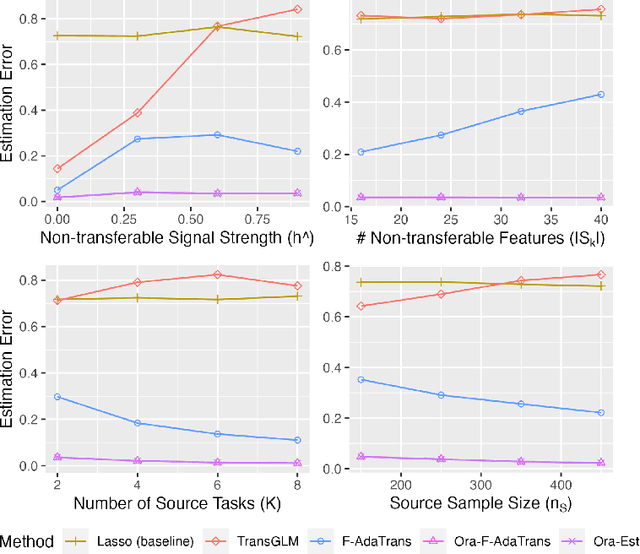
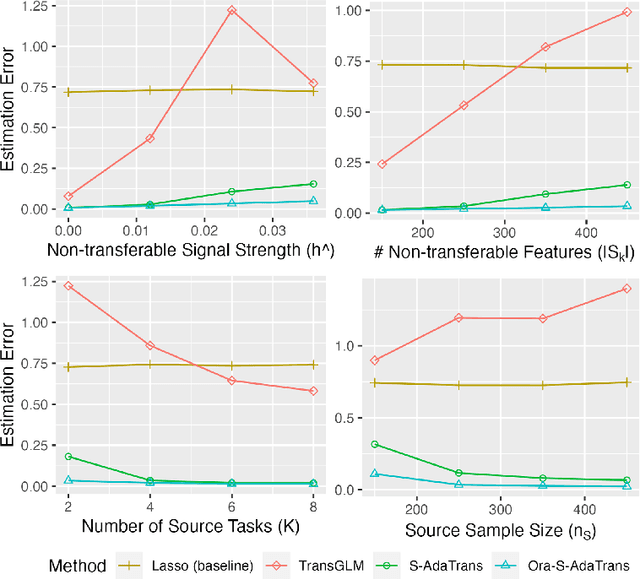
We consider the transfer learning problem in the high dimensional setting, where the feature dimension is larger than the sample size. To learn transferable information, which may vary across features or the source samples, we propose an adaptive transfer learning method that can detect and aggregate the feature-wise (F-AdaTrans) or sample-wise (S-AdaTrans) transferable structures. We achieve this by employing a novel fused-penalty, coupled with weights that can adapt according to the transferable structure. To choose the weight, we propose a theoretically informed, data-driven procedure, enabling F-AdaTrans to selectively fuse the transferable signals with the target while filtering out non-transferable signals, and S-AdaTrans to obtain the optimal combination of information transferred from each source sample. The non-asymptotic rates are established, which recover existing near-minimax optimal rates in special cases. The effectiveness of the proposed method is validated using both synthetic and real data.
Six Levels of Privacy: A Framework for Financial Synthetic Data
Mar 20, 2024Synthetic Data is increasingly important in financial applications. In addition to the benefits it provides, such as improved financial modeling and better testing procedures, it poses privacy risks as well. Such data may arise from client information, business information, or other proprietary sources that must be protected. Even though the process by which Synthetic Data is generated serves to obscure the original data to some degree, the extent to which privacy is preserved is hard to assess. Accordingly, we introduce a hierarchy of ``levels'' of privacy that are useful for categorizing Synthetic Data generation methods and the progressively improved protections they offer. While the six levels were devised in the context of financial applications, they may also be appropriate for other industries as well. Our paper includes: A brief overview of Financial Synthetic Data, how it can be used, how its value can be assessed, privacy risks, and privacy attacks. We close with details of the ``Six Levels'' that include defenses against those attacks.