 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Audio-Visual Segmentation with Bidirectional Generation
Aug 16, 2023
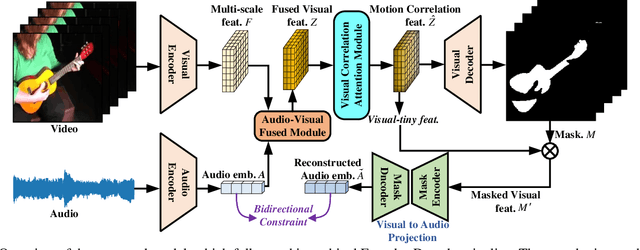
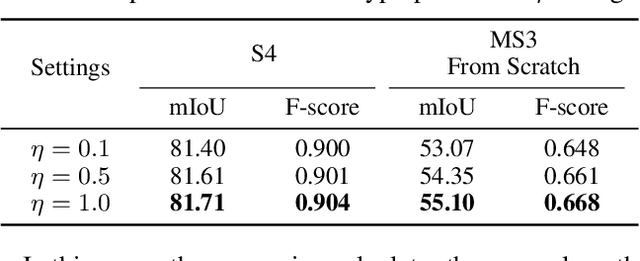
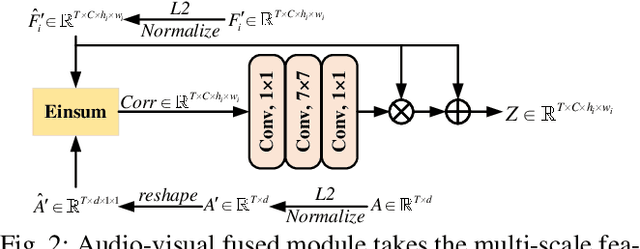
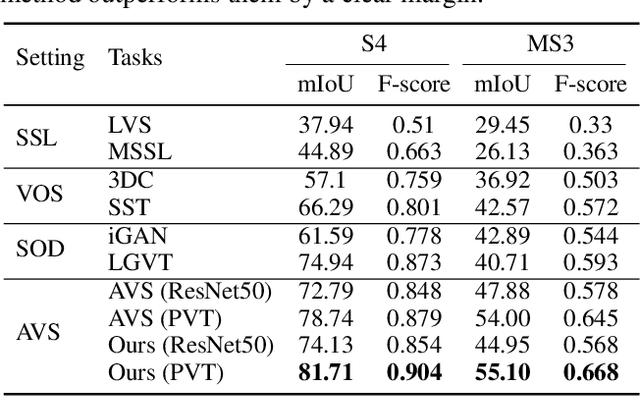
The aim of audio-visual segmentation (AVS) is to precisely differentiate audible objects within videos down to the pixel level. Traditional approaches often tackle this challenge by combining information from various modalities, where the contribution of each modality is implicitly or explicitly modeled. Nevertheless, the interconnections between different modalities tend to be overlooked in audio-visual modeling. In this paper, inspired by the human ability to mentally simulate the sound of an object and its visual appearance, we introduce a bidirectional generation framework. This framework establishes robust correlations between an object's visual characteristics and its associated sound, thereby enhancing the performance of AVS. To achieve this, we employ a visual-to-audio projection component that reconstructs audio features from object segmentation masks and minimizes reconstruction errors. Moreover, recognizing that many sounds are linked to object movements, we introduce an implicit volumetric motion estimation module to handle temporal dynamics that may be challenging to capture using conventional optical flow methods. To showcase the effectiveness of our approach, we conduct comprehensive experiments and analyses on the widely recognized AVSBench benchmark. As a result, we establish a new state-of-the-art performance level in the AVS benchmark, particularly excelling in the challenging MS3 subset which involves segmenting multiple sound sources. To facilitate reproducibility, we plan to release both the source code and the pre-trained model.
Radio2Text: Streaming Speech Recognition Using mmWave Radio Signals
Aug 16, 2023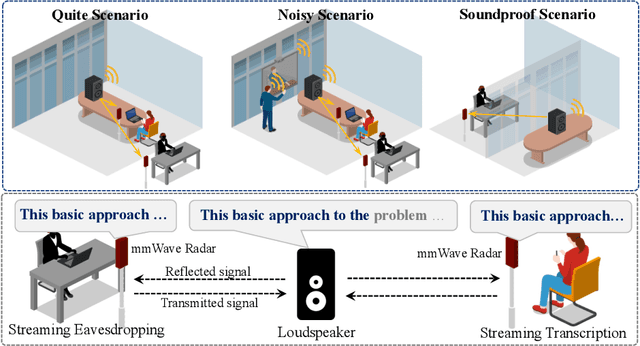
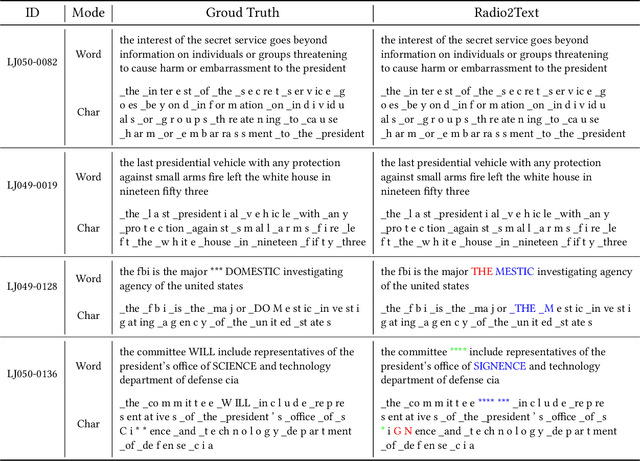


Millimeter wave (mmWave) based speech recognition provides more possibility for audio-related applications, such as conference speech transcription and eavesdropping. However, considering the practicality in real scenarios, latency and recognizable vocabulary size are two critical factors that cannot be overlooked. In this paper, we propose Radio2Text, the first mmWave-based system for streaming automatic speech recognition (ASR) with a vocabulary size exceeding 13,000 words. Radio2Text is based on a tailored streaming Transformer that is capable of effectively learning representations of speech-related features, paving the way for streaming ASR with a large vocabulary. To alleviate the deficiency of streaming networks unable to access entire future inputs, we propose the Guidance Initialization that facilitates the transfer of feature knowledge related to the global context from the non-streaming Transformer to the tailored streaming Transformer through weight inheritance. Further, we propose a cross-modal structure based on knowledge distillation (KD), named cross-modal KD, to mitigate the negative effect of low quality mmWave signals on recognition performance. In the cross-modal KD, the audio streaming Transformer provides feature and response guidance that inherit fruitful and accurate speech information to supervise the training of the tailored radio streaming Transformer. The experimental results show that our Radio2Text can achieve a character error rate of 5.7% and a word error rate of 9.4% for the recognition of a vocabulary consisting of over 13,000 words.
It Ain't That Bad: Understanding the Mysterious Performance Drop in OOD Generalization for Generative Transformer Models
Aug 16, 2023Generative Transformer-based models have achieved remarkable proficiency on solving diverse problems. However, their generalization ability is not fully understood and not always satisfying. Researchers take basic mathematical tasks like n-digit addition or multiplication as important perspectives for investigating their generalization behaviors. Curiously, it is observed that when training on n-digit operations (e.g., additions) in which both input operands are n-digit in length, models generalize successfully on unseen n-digit inputs (in-distribution (ID) generalization), but fail miserably and mysteriously on longer, unseen cases (out-of-distribution (OOD) generalization). Studies try to bridge this gap with workarounds such as modifying position embedding, fine-tuning, and priming with more extensive or instructive data. However, without addressing the essential mechanism, there is hardly any guarantee regarding the robustness of these solutions. We bring this unexplained performance drop into attention and ask whether it is purely from random errors. Here we turn to the mechanistic line of research which has notable successes in model interpretability. We discover that the strong ID generalization stems from structured representations, while behind the unsatisfying OOD performance, the models still exhibit clear learned algebraic structures. Specifically, these models map unseen OOD inputs to outputs with equivalence relations in the ID domain. These highlight the potential of the models to carry useful information for improved generalization.
BarlowRL: Barlow Twins for Data-Efficient Reinforcement Learning
Aug 08, 2023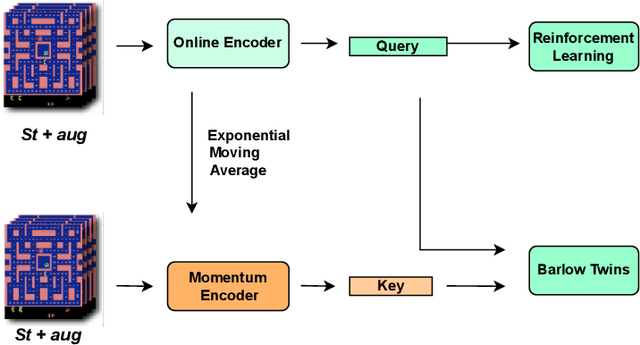
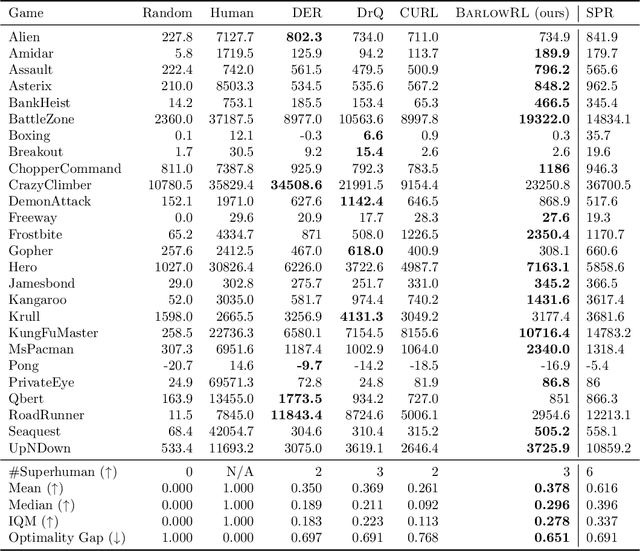


This paper introduces BarlowRL, a data-efficient reinforcement learning agent that combines the Barlow Twins self-supervised learning framework with DER (Data-Efficient Rainbow) algorithm. BarlowRL outperforms both DER and its contrastive counterpart CURL on the Atari 100k benchmark. BarlowRL avoids dimensional collapse by enforcing information spread to the whole space. This helps RL algorithms to utilize uniformly spread state representation that eventually results in a remarkable performance. The integration of Barlow Twins with DER enhances data efficiency and achieves superior performance in the RL tasks. BarlowRL demonstrates the potential of incorporating self-supervised learning techniques to improve RL algorithms.
UniEX: An Effective and Efficient Framework for Unified Information Extraction via a Span-extractive Perspective
May 22, 2023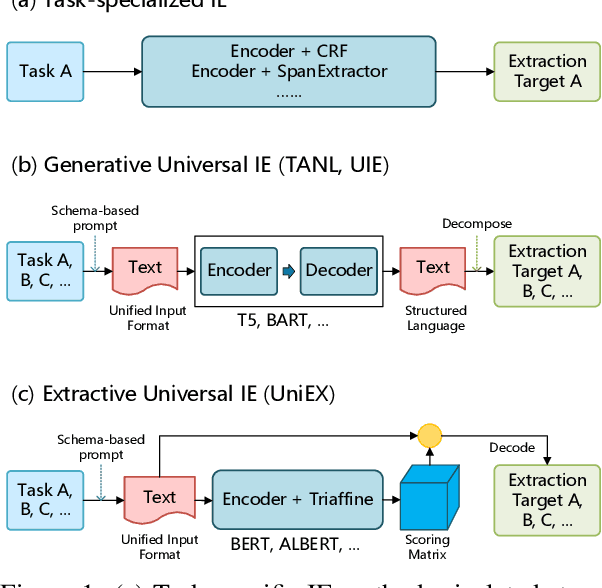
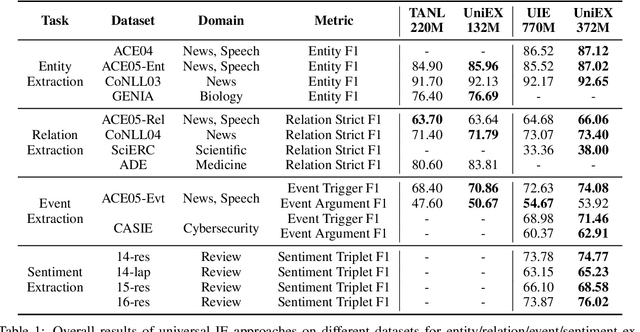

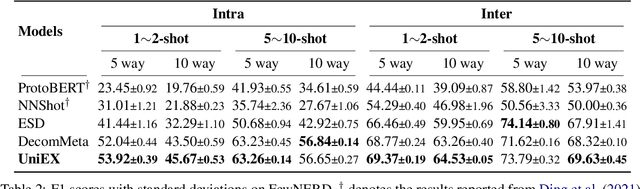
We propose a new paradigm for universal information extraction (IE) that is compatible with any schema format and applicable to a list of IE tasks, such as named entity recognition, relation extraction, event extraction and sentiment analysis. Our approach converts the text-based IE tasks as the token-pair problem, which uniformly disassembles all extraction targets into joint span detection, classification and association problems with a unified extractive framework, namely UniEX. UniEX can synchronously encode schema-based prompt and textual information, and collaboratively learn the generalized knowledge from pre-defined information using the auto-encoder language models. We develop a traffine attention mechanism to integrate heterogeneous factors including tasks, labels and inside tokens, and obtain the extraction target via a scoring matrix. Experiment results show that UniEX can outperform generative universal IE models in terms of performance and inference-speed on $14$ benchmarks IE datasets with the supervised setting. The state-of-the-art performance in low-resource scenarios also verifies the transferability and effectiveness of UniEX.
Can ultrasound confidence maps predict sonographers' labeling variability?
Aug 18, 2023
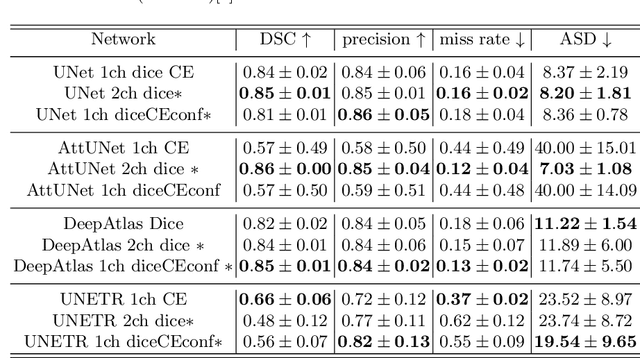
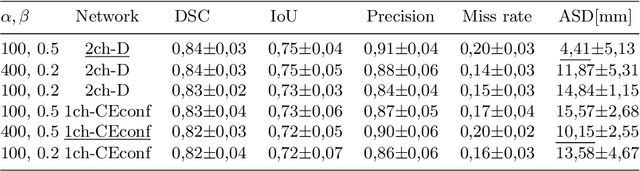

Measuring cross-sectional areas in ultrasound images is a standard tool to evaluate disease progress or treatment response. Often addressed today with supervised deep-learning segmentation approaches, existing solutions highly depend upon the quality of experts' annotations. However, the annotation quality in ultrasound is anisotropic and position-variant due to the inherent physical imaging principles, including attenuation, shadows, and missing boundaries, commonly exacerbated with depth. This work proposes a novel approach that guides ultrasound segmentation networks to account for sonographers' uncertainties and generate predictions with variability similar to the experts. We claim that realistic variability can reduce overconfident predictions and improve physicians' acceptance of deep-learning cross-sectional segmentation solutions. Our method provides CM's certainty for each pixel for minimal computational overhead as it can be precalculated directly from the image. We show that there is a correlation between low values in the confidence maps and expert's label uncertainty. Therefore, we propose to give the confidence maps as additional information to the networks. We study the effect of the proposed use of ultrasound CMs in combination with four state-of-the-art neural networks and in two configurations: as a second input channel and as part of the loss. We evaluate our method on 3D ultrasound datasets of the thyroid and lower limb muscles. Our results show ultrasound CMs increase the Dice score, improve the Hausdorff and Average Surface Distances, and decrease the number of isolated pixel predictions. Furthermore, our findings suggest that ultrasound CMs improve the penalization of uncertain areas in the ground truth data, thereby improving problematic interpolations. Our code and example data will be made public at https://github.com/IFL-CAMP/Confidence-segmentation.
SwinJSCC: Taming Swin Transformer for Deep Joint Source-Channel Coding
Aug 18, 2023
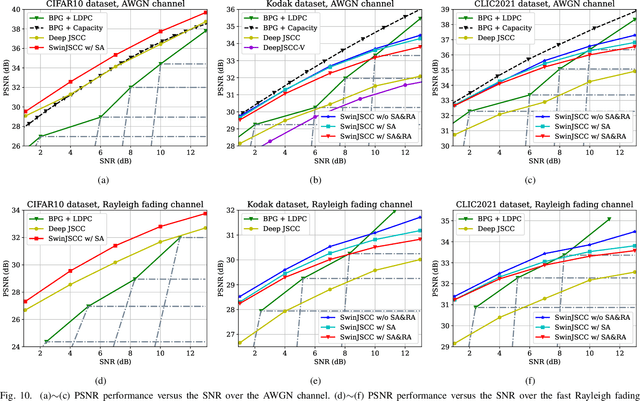
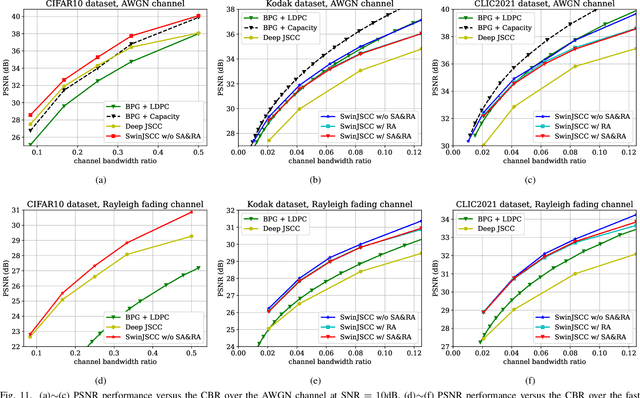
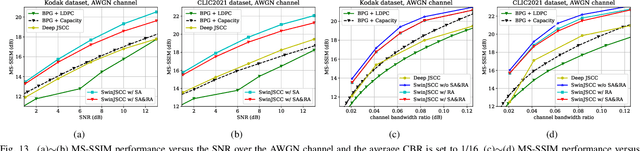
As one of the key techniques to realize semantic communications, end-to-end optimized neural joint source-channel coding (JSCC) has made great progress over the past few years. A general trend in many recent works pushing the model adaptability or the application diversity of neural JSCC is based on the convolutional neural network (CNN) backbone, whose model capacity is yet limited, inherently leading to inferior system coding gain against traditional coded transmission systems. In this paper, we establish a new neural JSCC backbone that can also adapt flexibly to diverse channel conditions and transmission rates within a single model, our open-source project aims to promote the research in this field. Specifically, we show that with elaborate design, neural JSCC codec built on the emerging Swin Transformer backbone achieves superior performance than conventional neural JSCC codecs built upon CNN, while also requiring lower end-to-end processing latency. Paired with two spatial modulation modules that scale latent representations based on the channel state information and target transmission rate, our baseline SwinJSCC can further upgrade to a versatile version, which increases its capability to adapt to diverse channel conditions and rate configurations. Extensive experimental results show that our SwinJSCC achieves better or comparable performance versus the state-of-the-art engineered BPG + 5G LDPC coded transmission system with much faster end-to-end coding speed, especially for high-resolution images, in which case traditional CNN-based JSCC yet falls behind due to its limited model capacity. \emph{Our open-source code and model are available at \href{https://github.com/semcomm/SwinJSCC}{https://github.com/semcomm/SwinJSCC}.}
KESDT: knowledge enhanced shallow and deep Transformer for detecting adverse drug reactions
Aug 18, 2023
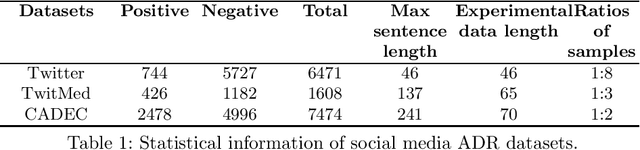
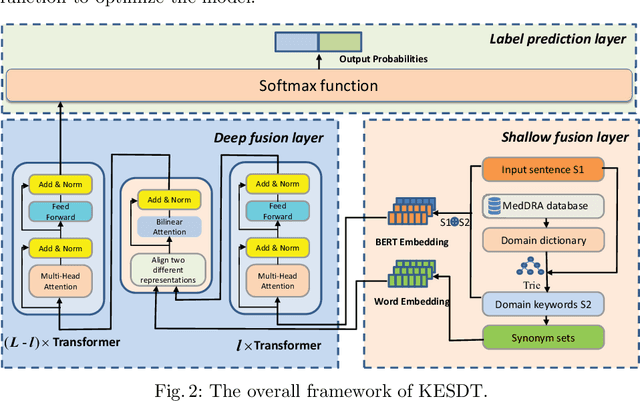
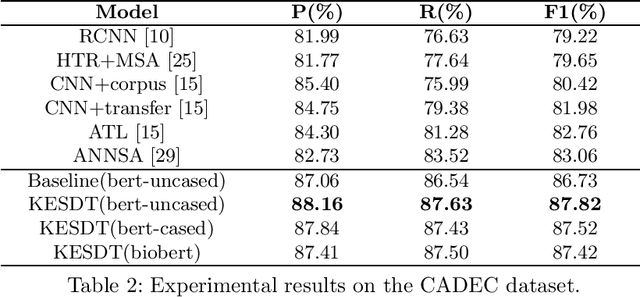
Adverse drug reaction (ADR) detection is an essential task in the medical field, as ADRs have a gravely detrimental impact on patients' health and the healthcare system. Due to a large number of people sharing information on social media platforms, an increasing number of efforts focus on social media data to carry out effective ADR detection. Despite having achieved impressive performance, the existing methods of ADR detection still suffer from three main challenges. Firstly, researchers have consistently ignored the interaction between domain keywords and other words in the sentence. Secondly, social media datasets suffer from the challenges of low annotated data. Thirdly, the issue of sample imbalance is commonly observed in social media datasets. To solve these challenges, we propose the Knowledge Enhanced Shallow and Deep Transformer(KESDT) model for ADR detection. Specifically, to cope with the first issue, we incorporate the domain keywords into the Transformer model through a shallow fusion manner, which enables the model to fully exploit the interactive relationships between domain keywords and other words in the sentence. To overcome the low annotated data, we integrate the synonym sets into the Transformer model through a deep fusion manner, which expands the size of the samples. To mitigate the impact of sample imbalance, we replace the standard cross entropy loss function with the focal loss function for effective model training. We conduct extensive experiments on three public datasets including TwiMed, Twitter, and CADEC. The proposed KESDT outperforms state-of-the-art baselines on F1 values, with relative improvements of 4.87%, 47.83%, and 5.73% respectively, which demonstrates the effectiveness of our proposed KESDT.
Data Encoding For Healthcare Data Democratisation and Information Leakage Prevention
May 05, 2023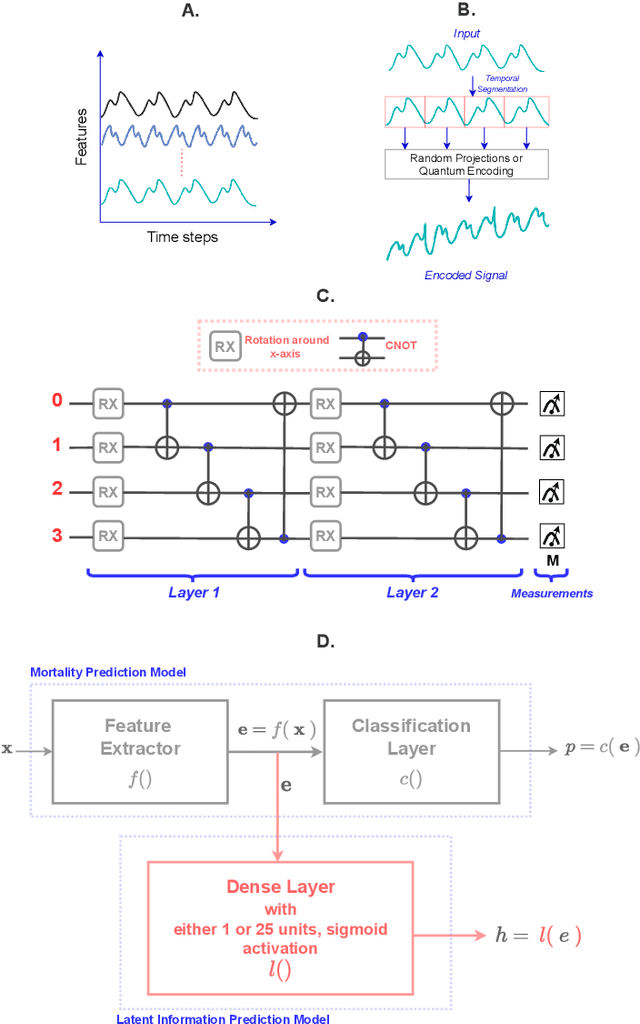

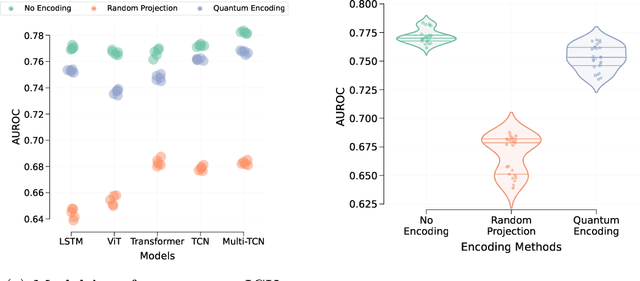
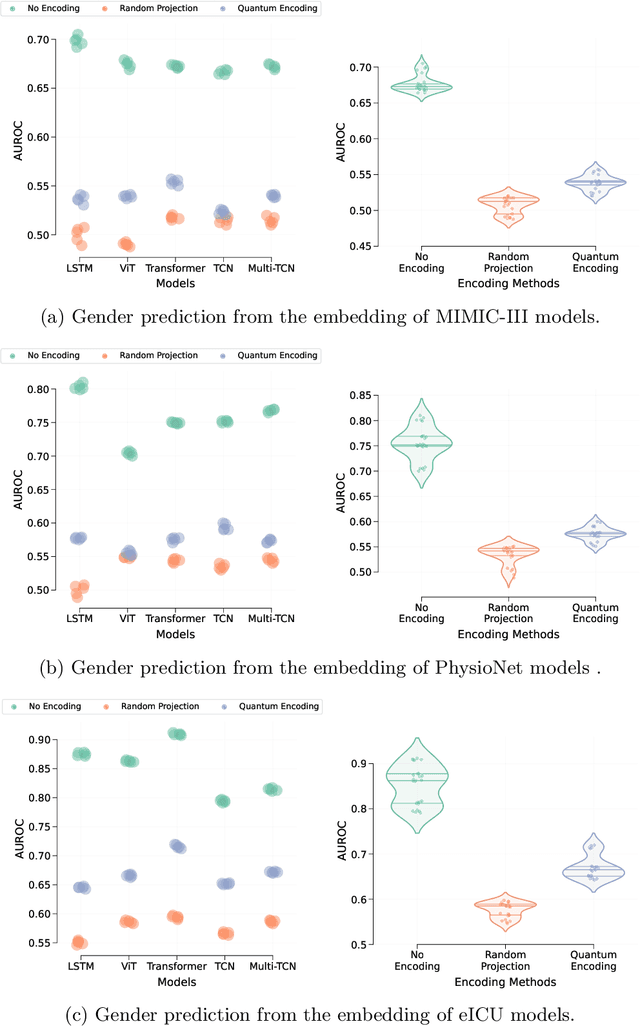
The lack of data democratization and information leakage from trained models hinder the development and acceptance of robust deep learning-based healthcare solutions. This paper argues that irreversible data encoding can provide an effective solution to achieve data democratization without violating the privacy constraints imposed on healthcare data and clinical models. An ideal encoding framework transforms the data into a new space where it is imperceptible to a manual or computational inspection. However, encoded data should preserve the semantics of the original data such that deep learning models can be trained effectively. This paper hypothesizes the characteristics of the desired encoding framework and then exploits random projections and random quantum encoding to realize this framework for dense and longitudinal or time-series data. Experimental evaluation highlights that models trained on encoded time-series data effectively uphold the information bottleneck principle and hence, exhibit lesser information leakage from trained models.
FLAIR #2: textural and temporal information for semantic segmentation from multi-source optical imagery
May 23, 2023

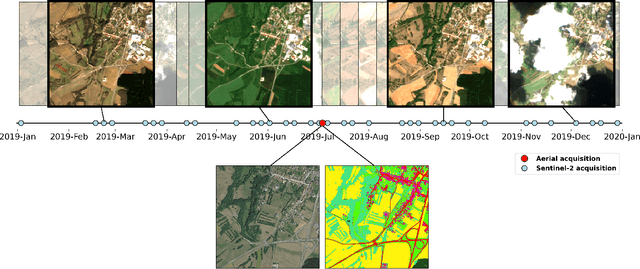

The FLAIR #2 dataset hereby presented includes two very distinct types of data, which are exploited for a semantic segmentation task aimed at mapping land cover. The data fusion workflow proposes the exploitation of the fine spatial and textural information of very high spatial resolution (VHR) mono-temporal aerial imagery and the temporal and spectral richness of high spatial resolution (HR) time series of Copernicus Sentinel-2 satellite images. The French National Institute of Geographical and Forest Information (IGN), in response to the growing availability of high-quality Earth Observation (EO) data, is actively exploring innovative strategies to integrate these data with heterogeneous characteristics. IGN is therefore offering this dataset to promote innovation and improve our knowledge of our territories.