 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Weakly-supervised 3D Pose Transfer with Keypoints
Jul 25, 2023

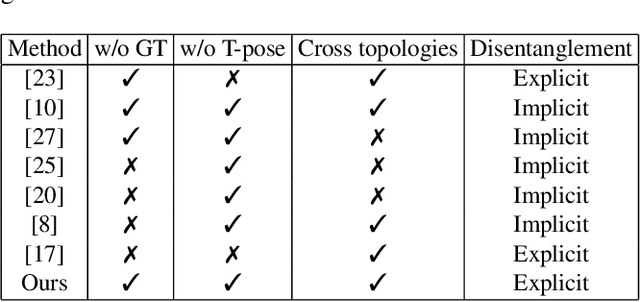
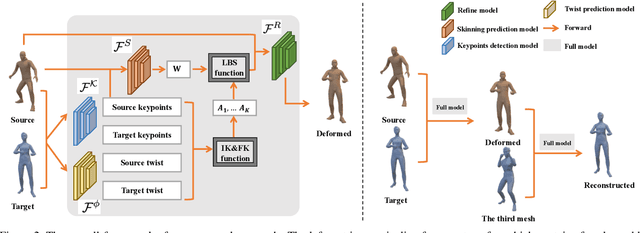

The main challenges of 3D pose transfer are: 1) Lack of paired training data with different characters performing the same pose; 2) Disentangling pose and shape information from the target mesh; 3) Difficulty in applying to meshes with different topologies. We thus propose a novel weakly-supervised keypoint-based framework to overcome these difficulties. Specifically, we use a topology-agnostic keypoint detector with inverse kinematics to compute transformations between the source and target meshes. Our method only requires supervision on the keypoints, can be applied to meshes with different topologies and is shape-invariant for the target which allows extraction of pose-only information from the target meshes without transferring shape information. We further design a cycle reconstruction to perform self-supervised pose transfer without the need for ground truth deformed mesh with the same pose and shape as the target and source, respectively. We evaluate our approach on benchmark human and animal datasets, where we achieve superior performance compared to the state-of-the-art unsupervised approaches and even comparable performance with the fully supervised approaches. We test on the more challenging Mixamo dataset to verify our approach's ability in handling meshes with different topologies and complex clothes. Cross-dataset evaluation further shows the strong generalization ability of our approach.
Person Re-Identification without Identification via Event Anonymization
Aug 09, 2023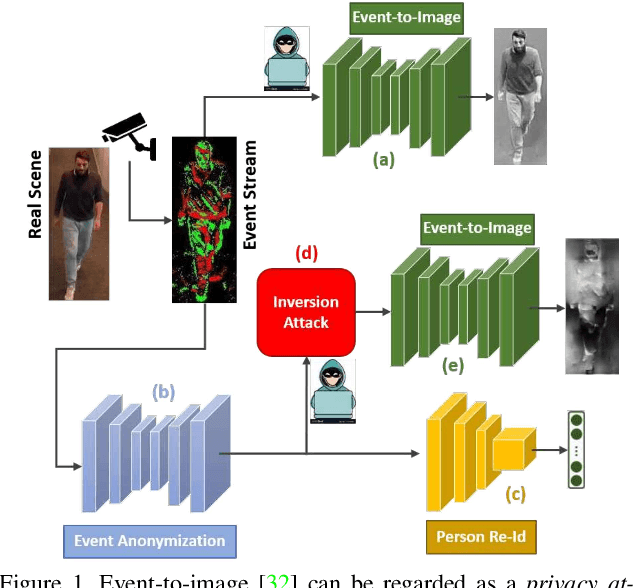


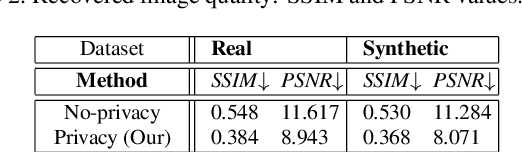
Wide-scale use of visual surveillance in public spaces puts individual privacy at stake while increasing resource consumption (energy, bandwidth, and computation). Neuromorphic vision sensors (event-cameras) have been recently considered a valid solution to the privacy issue because they do not capture detailed RGB visual information of the subjects in the scene. However, recent deep learning architectures have been able to reconstruct images from event cameras with high fidelity, reintroducing a potential threat to privacy for event-based vision applications. In this paper, we aim to anonymize event-streams to protect the identity of human subjects against such image reconstruction attacks. To achieve this, we propose an end-to-end network architecture jointly optimized for the twofold objective of preserving privacy and performing a downstream task such as person ReId. Our network learns to scramble events, enforcing the degradation of images recovered from the privacy attacker. In this work, we also bring to the community the first ever event-based person ReId dataset gathered to evaluate the performance of our approach. We validate our approach with extensive experiments and report results on the synthetic event data simulated from the publicly available SoftBio dataset and our proposed Event-ReId dataset.
Deep Learning for Morphological Identification of Extended Radio Galaxies using Weak Labels
Aug 09, 2023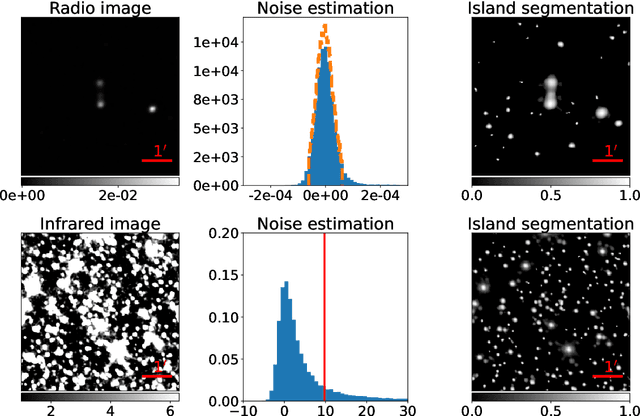
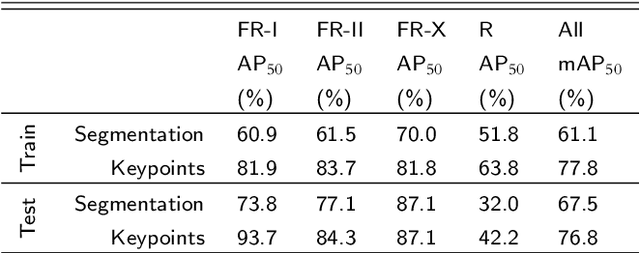
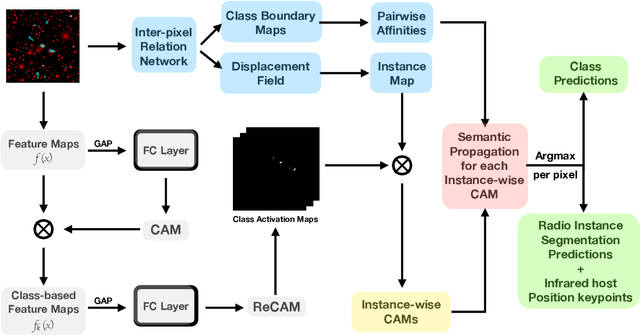
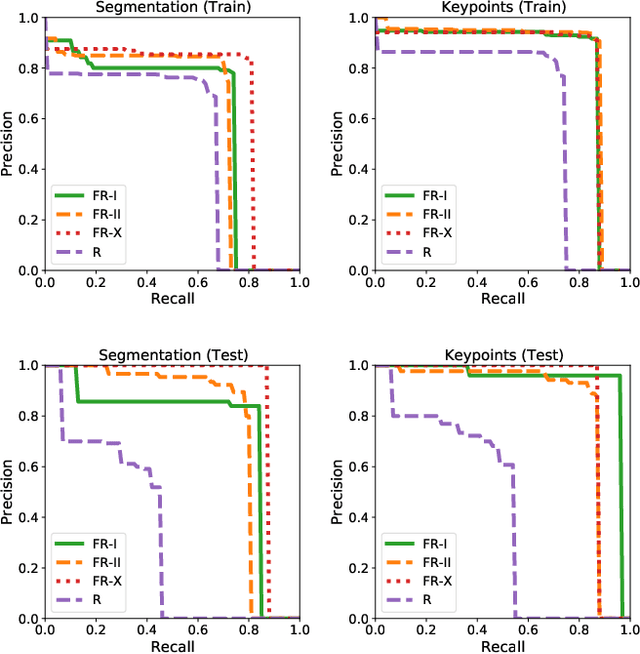
The present work discusses the use of a weakly-supervised deep learning algorithm that reduces the cost of labelling pixel-level masks for complex radio galaxies with multiple components. The algorithm is trained on weak class-level labels of radio galaxies to get class activation maps (CAMs). The CAMs are further refined using an inter-pixel relations network (IRNet) to get instance segmentation masks over radio galaxies and the positions of their infrared hosts. We use data from the Australian Square Kilometre Array Pathfinder (ASKAP) telescope, specifically the Evolutionary Map of the Universe (EMU) Pilot Survey, which covered a sky area of 270 square degrees with an RMS sensitivity of 25-35 $\mu$Jy/beam. We demonstrate that weakly-supervised deep learning algorithms can achieve high accuracy in predicting pixel-level information, including masks for the extended radio emission encapsulating all galaxy components and the positions of the infrared host galaxies. We evaluate the performance of our method using mean Average Precision (mAP) across multiple classes at a standard intersection over union (IoU) threshold of 0.5. We show that the model achieves a mAP$_{50}$ of 67.5\% and 76.8\% for radio masks and infrared host positions, respectively. The network architecture can be found at the following link: https://github.com/Nikhel1/Gal-CAM
LayoutLLM-T2I: Eliciting Layout Guidance from LLM for Text-to-Image Generation
Aug 09, 2023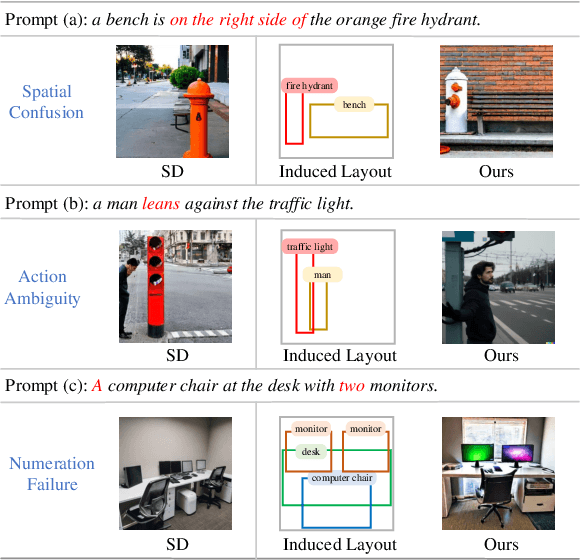
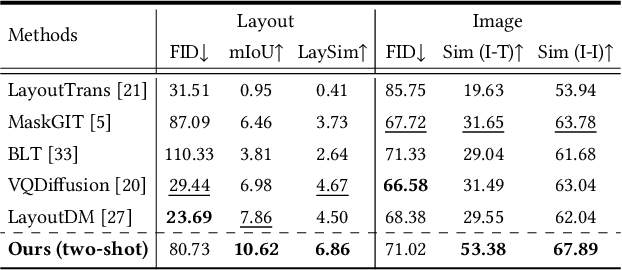
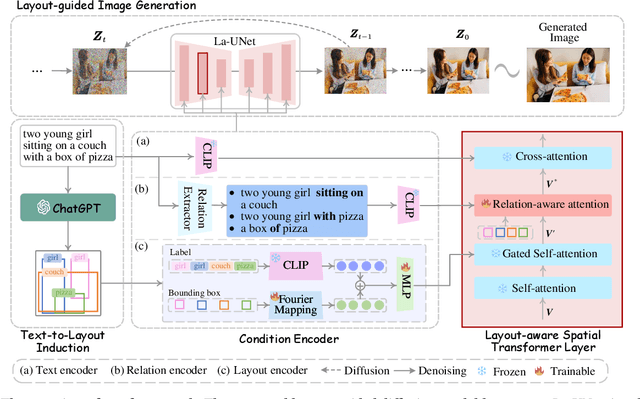

In the text-to-image generation field, recent remarkable progress in Stable Diffusion makes it possible to generate rich kinds of novel photorealistic images. However, current models still face misalignment issues (e.g., problematic spatial relation understanding and numeration failure) in complex natural scenes, which impedes the high-faithfulness text-to-image generation. Although recent efforts have been made to improve controllability by giving fine-grained guidance (e.g., sketch and scribbles), this issue has not been fundamentally tackled since users have to provide such guidance information manually. In this work, we strive to synthesize high-fidelity images that are semantically aligned with a given textual prompt without any guidance. Toward this end, we propose a coarse-to-fine paradigm to achieve layout planning and image generation. Concretely, we first generate the coarse-grained layout conditioned on a given textual prompt via in-context learning based on Large Language Models. Afterward, we propose a fine-grained object-interaction diffusion method to synthesize high-faithfulness images conditioned on the prompt and the automatically generated layout. Extensive experiments demonstrate that our proposed method outperforms the state-of-the-art models in terms of layout and image generation. Our code and settings are available at \url{https://layoutllm-t2i.github.io}.
Training neural networks with end-to-end optical backpropagation
Aug 09, 2023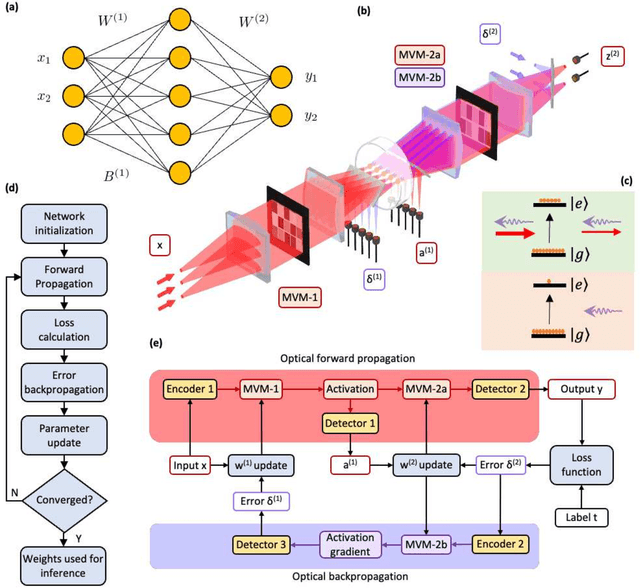
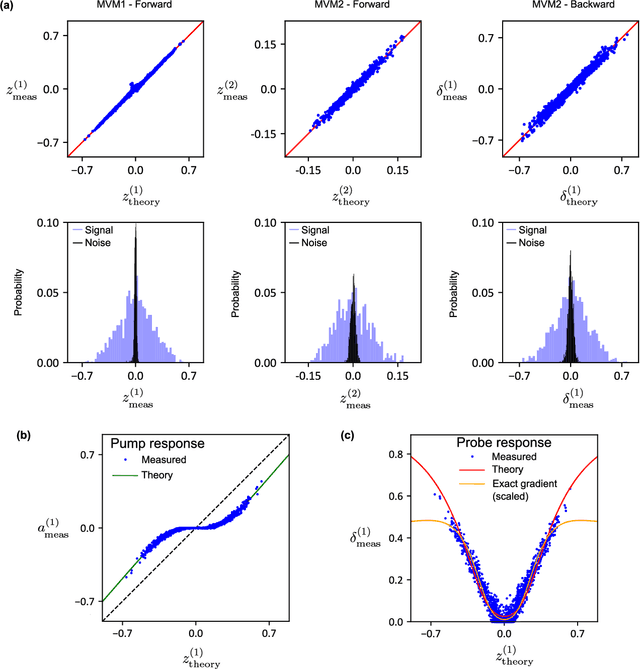
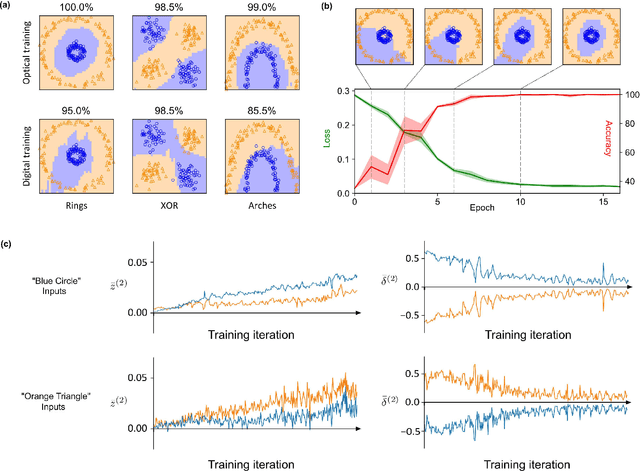
Optics is an exciting route for the next generation of computing hardware for machine learning, promising several orders of magnitude enhancement in both computational speed and energy efficiency. However, to reach the full capacity of an optical neural network it is necessary that the computing not only for the inference, but also for the training be implemented optically. The primary algorithm for training a neural network is backpropagation, in which the calculation is performed in the order opposite to the information flow for inference. While straightforward in a digital computer, optical implementation of backpropagation has so far remained elusive, particularly because of the conflicting requirements for the optical element that implements the nonlinear activation function. In this work, we address this challenge for the first time with a surprisingly simple and generic scheme. Saturable absorbers are employed for the role of the activation units, and the required properties are achieved through a pump-probe process, in which the forward propagating signal acts as the pump and backward as the probe. Our approach is adaptable to various analog platforms, materials, and network structures, and it demonstrates the possibility of constructing neural networks entirely reliant on analog optical processes for both training and inference tasks.
Where's the Liability in Harmful AI Speech?
Aug 09, 2023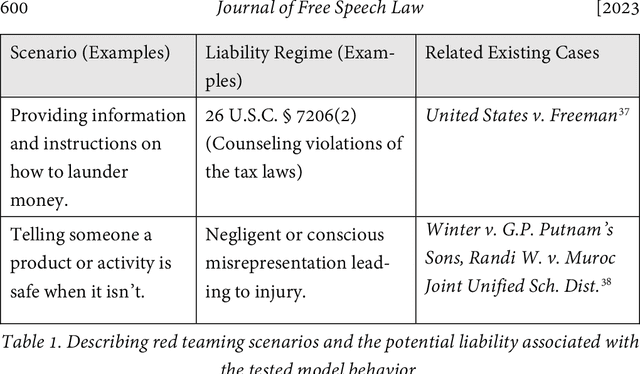


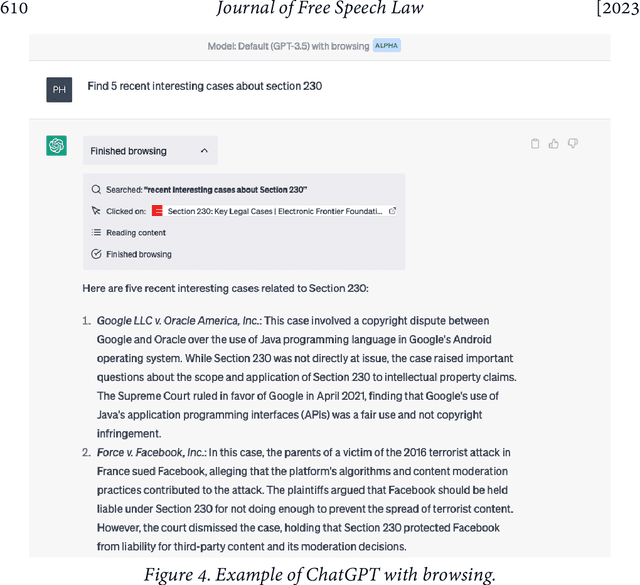
Generative AI, in particular text-based "foundation models" (large models trained on a huge variety of information including the internet), can generate speech that could be problematic under a wide range of liability regimes. Machine learning practitioners regularly "red team" models to identify and mitigate such problematic speech: from "hallucinations" falsely accusing people of serious misconduct to recipes for constructing an atomic bomb. A key question is whether these red-teamed behaviors actually present any liability risk for model creators and deployers under U.S. law, incentivizing investments in safety mechanisms. We examine three liability regimes, tying them to common examples of red-teamed model behaviors: defamation, speech integral to criminal conduct, and wrongful death. We find that any Section 230 immunity analysis or downstream liability analysis is intimately wrapped up in the technical details of algorithm design. And there are many roadblocks to truly finding models (and their associated parties) liable for generated speech. We argue that AI should not be categorically immune from liability in these scenarios and that as courts grapple with the already fine-grained complexities of platform algorithms, the technical details of generative AI loom above with thornier questions. Courts and policymakers should think carefully about what technical design incentives they create as they evaluate these issues.
Spatial Gated Multi-Layer Perceptron for Land Use and Land Cover Mapping
Aug 09, 2023
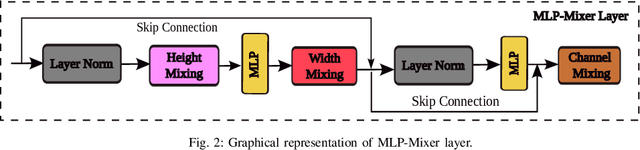

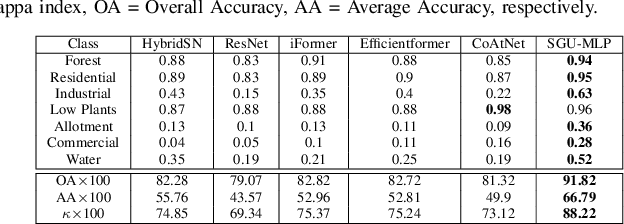
Convolutional Neural Networks (CNNs) are models that are utilized extensively for the hierarchical extraction of features. Vision transformers (ViTs), through the use of a self-attention mechanism, have recently achieved superior modeling of global contextual information compared to CNNs. However, to realize their image classification strength, ViTs require substantial training datasets. Where the available training data are limited, current advanced multi-layer perceptrons (MLPs) can provide viable alternatives to both deep CNNs and ViTs. In this paper, we developed the SGU-MLP, a learning algorithm that effectively uses both MLPs and spatial gating units (SGUs) for precise land use land cover (LULC) mapping. Results illustrated the superiority of the developed SGU-MLP classification algorithm over several CNN and CNN-ViT-based models, including HybridSN, ResNet, iFormer, EfficientFormer and CoAtNet. The proposed SGU-MLP algorithm was tested through three experiments in Houston, USA, Berlin, Germany and Augsburg, Germany. The SGU-MLP classification model was found to consistently outperform the benchmark CNN and CNN-ViT-based algorithms. For example, for the Houston experiment, SGU-MLP significantly outperformed HybridSN, CoAtNet, Efficientformer, iFormer and ResNet by approximately 15%, 19%, 20%, 21%, and 25%, respectively, in terms of average accuracy. The code will be made publicly available at https://github.com/aj1365/SGUMLP
Sudowoodo: a Chinese Lyric Imitation System with Source Lyrics
Aug 09, 2023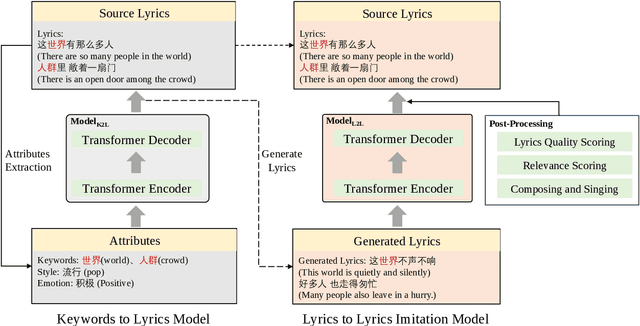


Lyrics generation is a well-known application in natural language generation research, with several previous studies focusing on generating accurate lyrics using precise control such as keywords, rhymes, etc. However, lyrics imitation, which involves writing new lyrics by imitating the style and content of the source lyrics, remains a challenging task due to the lack of a parallel corpus. In this paper, we introduce \textbf{\textit{Sudowoodo}}, a Chinese lyrics imitation system that can generate new lyrics based on the text of source lyrics. To address the issue of lacking a parallel training corpus for lyrics imitation, we propose a novel framework to construct a parallel corpus based on a keyword-based lyrics model from source lyrics. Then the pairs \textit{(new lyrics, source lyrics)} are used to train the lyrics imitation model. During the inference process, we utilize a post-processing module to filter and rank the generated lyrics, selecting the highest-quality ones. We incorporated audio information and aligned the lyrics with the audio to form the songs as a bonus. The human evaluation results show that our framework can perform better lyric imitation. Meanwhile, the \textit{Sudowoodo} system and demo video of the system is available at \href{https://Sudowoodo.apps-hp.danlu.netease.com/}{Sudowoodo} and \href{https://youtu.be/u5BBT_j1L5M}{https://youtu.be/u5BBT\_j1L5M}.
A Multimodal Supervised Machine Learning Approach for Satellite-based Wildfire Identification in Europe
Jul 27, 2023The increasing frequency of catastrophic natural events, such as wildfires, calls for the development of rapid and automated wildfire detection systems. In this paper, we propose a wildfire identification solution to improve the accuracy of automated satellite-based hotspot detection systems by leveraging multiple information sources. We cross-reference the thermal anomalies detected by the Moderate-resolution Imaging Spectroradiometer (MODIS) and the Visible Infrared Imaging Radiometer Suite (VIIRS) hotspot services with the European Forest Fire Information System (EFFIS) database to construct a large-scale hotspot dataset for wildfire-related studies in Europe. Then, we propose a novel multimodal supervised machine learning approach to disambiguate hotspot detections, distinguishing between wildfires and other events. Our methodology includes the use of multimodal data sources, such as the ERSI annual Land Use Land Cover (LULC) and the Copernicus Sentinel-3 data. Experimental results demonstrate the effectiveness of our approach in the task of wildfire identification.
Topological Estimation of Number of Sources in Linear Monocomponent Mixtures
Aug 05, 2023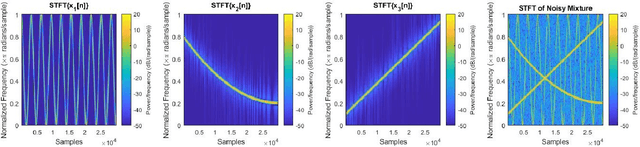
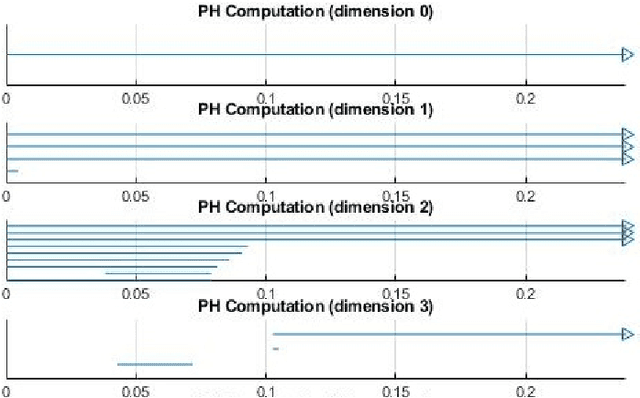
Estimation of the number of sources in a linear mixture is a critical preprocessing step in the separation and analysis of the sources for many applications. Historically, statistical methods, such as the minimum description length and Akaike information criterion, have been used to estimate the number of sources based on the autocorrelation matrix of the received mixture. In this paper, we introduce an alternative, topology-based method to compute the number of source signals present in a linear mixture for the class of constant-amplitude, monocomponent source signals. As a proof-of-concept, we include an example of three such source signals that overlap at multiple points in time and frequency, which the method correctly identifies from a set of eight redundant measurements. These preliminary results are promising and encourage further investigation into applications of topological data analysis to signal processing problems.