 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Encode-Store-Retrieve: Enhancing Memory Augmentation through Language-Encoded Egocentric Perception
Aug 10, 2023
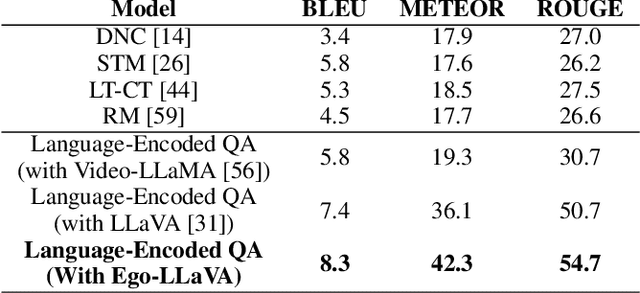
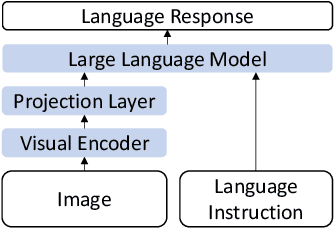
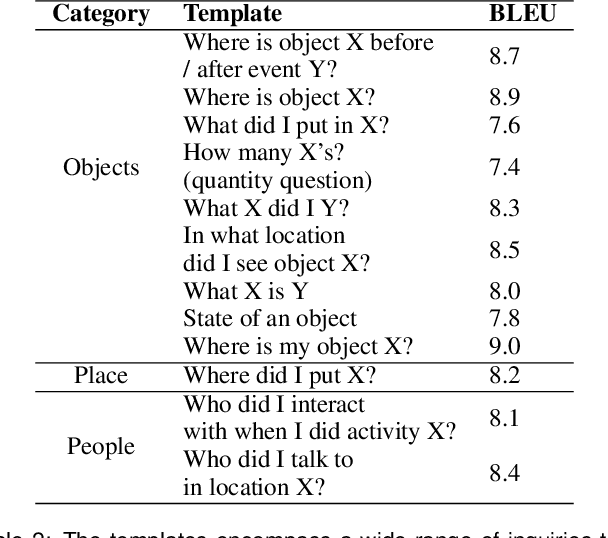
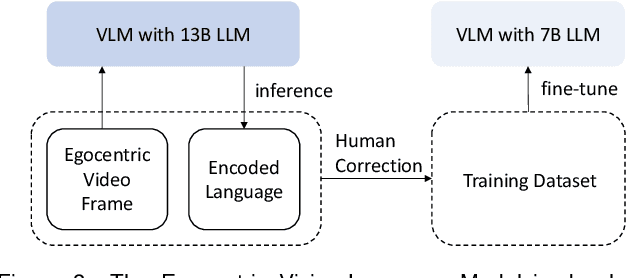
We depend on our own memory to encode, store, and retrieve our experiences. However, memory lapses can occur. One promising avenue for achieving memory augmentation is through the use of augmented reality head-mounted displays to capture and preserve egocentric videos, a practice commonly referred to as life logging. However, a significant challenge arises from the sheer volume of video data generated through life logging, as the current technology lacks the capability to encode and store such large amounts of data efficiently. Further, retrieving specific information from extensive video archives requires substantial computational power, further complicating the task of quickly accessing desired content. To address these challenges, we propose a memory augmentation system that involves leveraging natural language encoding for video data and storing them in a vector database. This approach harnesses the power of large vision language models to perform the language encoding process. Additionally, we propose using large language models to facilitate natural language querying. Our system underwent extensive evaluation using the QA-Ego4D dataset and achieved state-of-the-art results with a BLEU score of 8.3, outperforming conventional machine learning models that scored between 3.4 and 5.8. Additionally, in a user study, our system received a higher mean response score of 4.13/5 compared to the human participants' score of 2.46/5 on real-life episodic memory tasks.
Deep Richardson-Lucy Deconvolution for Low-Light Image Deblurring
Aug 10, 2023
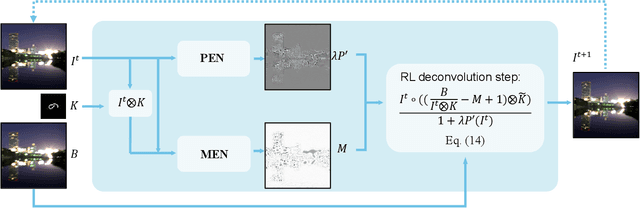

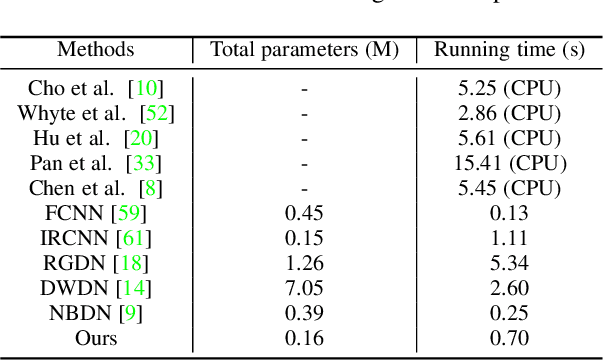
Images taken under the low-light condition often contain blur and saturated pixels at the same time. Deblurring images with saturated pixels is quite challenging. Because of the limited dynamic range, the saturated pixels are usually clipped in the imaging process and thus cannot be modeled by the linear blur model. Previous methods use manually designed smooth functions to approximate the clipping procedure. Their deblurring processes often require empirically defined parameters, which may not be the optimal choices for different images. In this paper, we develop a data-driven approach to model the saturated pixels by a learned latent map. Based on the new model, the non-blind deblurring task can be formulated into a maximum a posterior (MAP) problem, which can be effectively solved by iteratively computing the latent map and the latent image. Specifically, the latent map is computed by learning from a map estimation network (MEN), and the latent image estimation process is implemented by a Richardson-Lucy (RL)-based updating scheme. To estimate high-quality deblurred images without amplified artifacts, we develop a prior estimation network (PEN) to obtain prior information, which is further integrated into the RL scheme. Experimental results demonstrate that the proposed method performs favorably against state-of-the-art algorithms both quantitatively and qualitatively on synthetic and real-world images.
Exploring Deep Learning Approaches to Predict Person and Vehicle Trips: An Analysis of NHTS Data
Aug 10, 2023
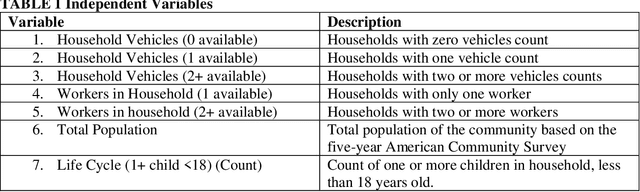
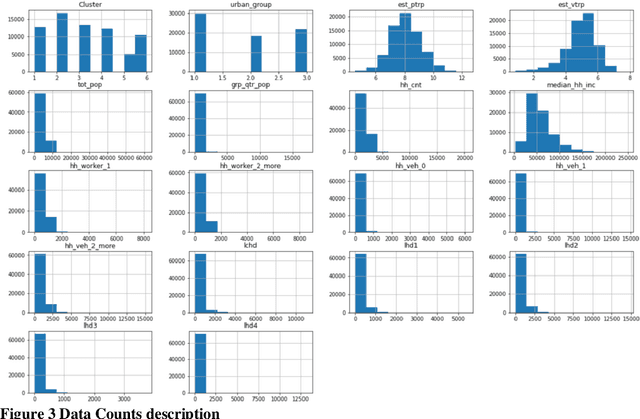
Modern transportation planning relies heavily on accurate predictions of person and vehicle trips. However, traditional planning models often fail to account for the intricacies and dynamics of travel behavior, leading to less-than-optimal accuracy in these predictions. This study explores the potential of deep learning techniques to transform the way we approach trip predictions, and ultimately, transportation planning. Utilizing a comprehensive dataset from the National Household Travel Survey (NHTS), we developed and trained a deep learning model for predicting person and vehicle trips. The proposed model leverages the vast amount of information in the NHTS data, capturing complex, non-linear relationships that were previously overlooked by traditional models. As a result, our deep learning model achieved an impressive accuracy of 98% for person trip prediction and 96% for vehicle trip estimation. This represents a significant improvement over the performances of traditional transportation planning models, thereby demonstrating the power of deep learning in this domain. The implications of this study extend beyond just more accurate predictions. By enhancing the accuracy and reliability of trip prediction models, planners can formulate more effective, data-driven transportation policies, infrastructure, and services. As such, our research underscores the need for the transportation planning field to embrace advanced techniques like deep learning. The detailed methodology, along with a thorough discussion of the results and their implications, are presented in the subsequent sections of this paper.
Timeseries-aware Uncertainty Wrappers for Uncertainty Quantification of Information-Fusion-Enhanced AI Models based on Machine Learning
May 24, 2023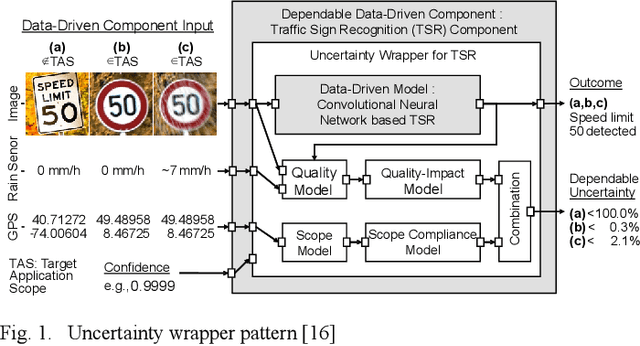
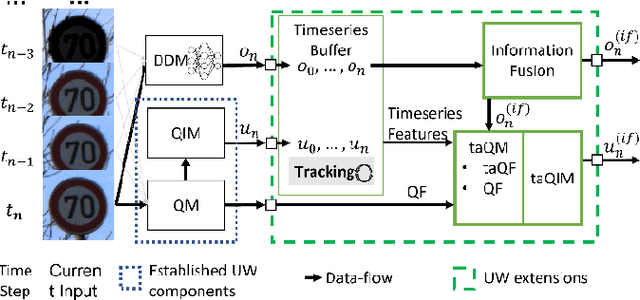
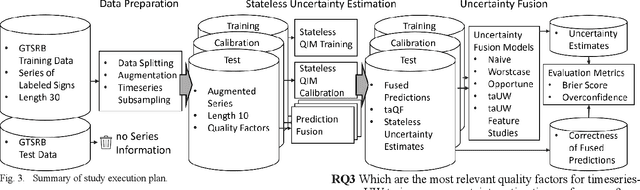
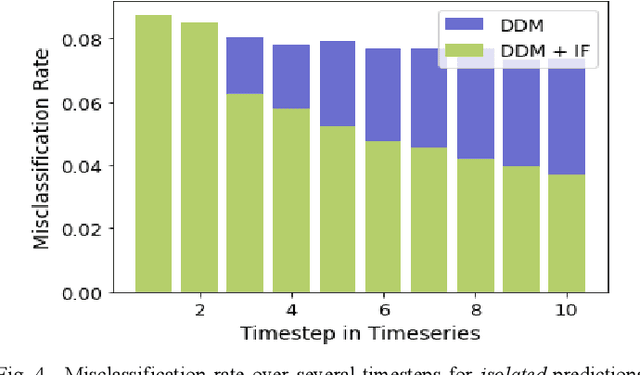
As the use of Artificial Intelligence (AI) components in cyber-physical systems is becoming more common, the need for reliable system architectures arises. While data-driven models excel at perception tasks, model outcomes are usually not dependable enough for safety-critical applications. In this work,we present a timeseries-aware uncertainty wrapper for dependable uncertainty estimates on timeseries data. The uncertainty wrapper is applied in combination with information fusion over successive model predictions in time. The application of the uncertainty wrapper is demonstrated with a traffic sign recognition use case. We show that it is possible to increase model accuracy through information fusion and additionally increase the quality of uncertainty estimates through timeseries-aware input quality features.
Legal Summarisation through LLMs: The PRODIGIT Project
Aug 04, 2023
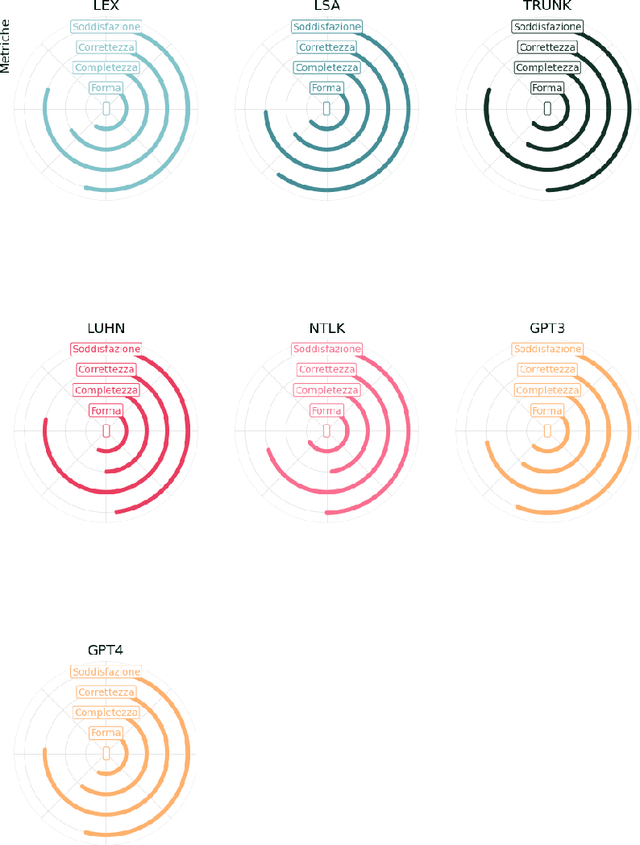
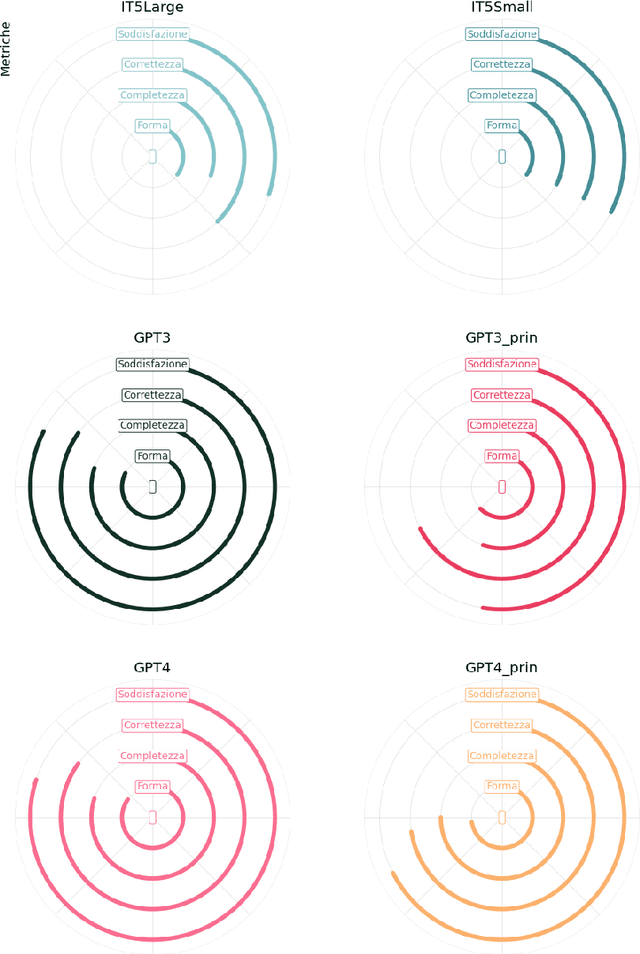
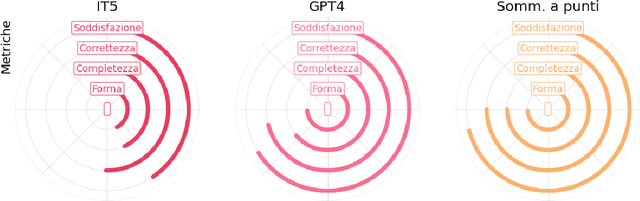
We present some initial results of a large-scale Italian project called PRODIGIT which aims to support tax judges and lawyers through digital technology, focusing on AI. We have focused on generation of summaries of judicial decisions and on the extraction of related information, such as the identification of legal issues and decision-making criteria, and the specification of keywords. To this end, we have deployed and evaluated different tools and approaches to extractive and abstractive summarisation. We have applied LLMs, and particularly on GPT4, which has enabled us to obtain results that proved satisfactory, according to an evaluation by expert tax judges and lawyers. On this basis, a prototype application is being built which will be made publicly available.
Bounding the Invertibility of Privacy-preserving Instance Encoding using Fisher Information
May 06, 2023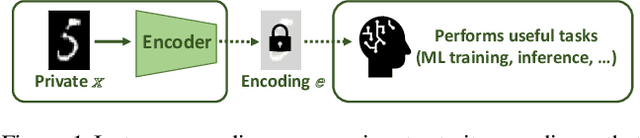
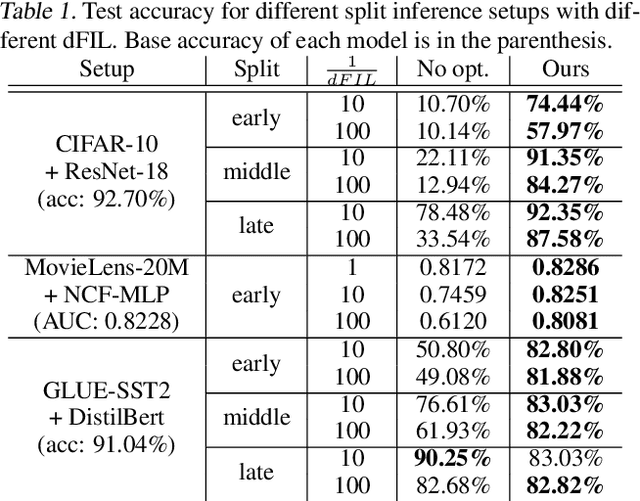
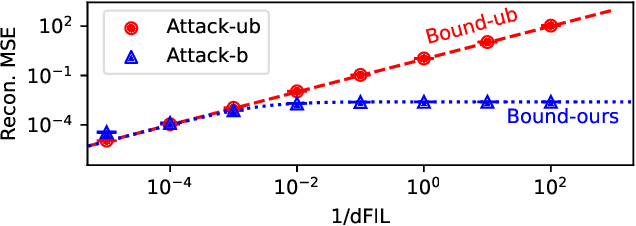
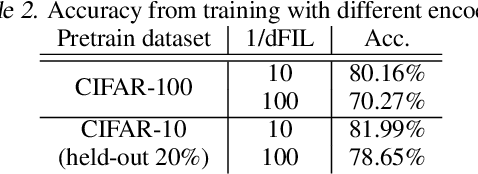
Privacy-preserving instance encoding aims to encode raw data as feature vectors without revealing their privacy-sensitive information. When designed properly, these encodings can be used for downstream ML applications such as training and inference with limited privacy risk. However, the vast majority of existing instance encoding schemes are based on heuristics and their privacy-preserving properties are only validated empirically against a limited set of attacks. In this paper, we propose a theoretically-principled measure for the privacy of instance encoding based on Fisher information. We show that our privacy measure is intuitive, easily applicable, and can be used to bound the invertibility of encodings both theoretically and empirically.
Answering Unseen Questions With Smaller Language Models Using Rationale Generation and Dense Retrieval
Aug 12, 2023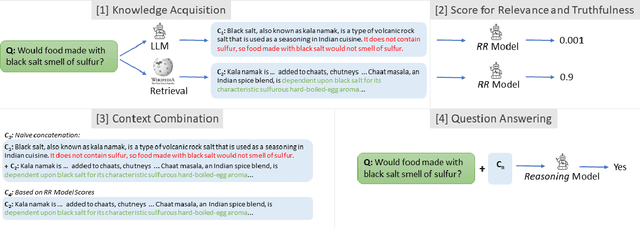
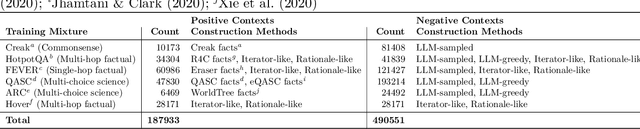
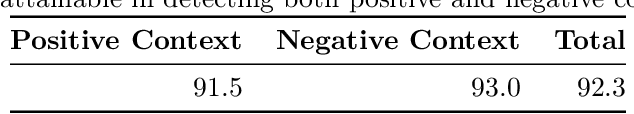
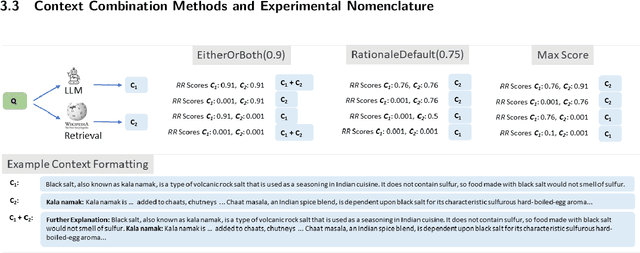
When provided with sufficient explanatory context, smaller Language Models have been shown to exhibit strong reasoning ability on challenging short-answer question-answering tasks where the questions are unseen in training. We evaluate two methods for further improvement in this setting. Both methods focus on combining rationales generated by a larger Language Model with longer contexts created from a multi-hop dense retrieval system. The first method ($\textit{RR}$) involves training a Rationale Ranking model to score both generated rationales and retrieved contexts with respect to relevance and truthfulness. We then use the scores to derive combined contexts from both knowledge sources using a number of combinatory strategies. For the second method ($\textit{RATD}$) we train a smaller Reasoning model using retrieval-augmented training datasets such that it becomes proficient at utilising relevant information from longer text sequences that may be only partially evidential and frequently contain many irrelevant sentences. Generally we find that both methods are effective but that the $\textit{RATD}$ method is more straightforward to apply and produces the strongest results in the unseen setting on which we focus. Our single best Reasoning model using only 440 million parameters materially improves upon strong comparable prior baselines for unseen evaluation datasets (StrategyQA 58.9 $\rightarrow$ 61.7 acc., CommonsenseQA 63.6 $\rightarrow$ 72.7 acc., ARC-DA 31.6 $\rightarrow$ 52.1 F1, IIRC 25.5 $\rightarrow$ 27.3 F1) and a version utilising our prior knowledge of each type of question in selecting a context combination strategy does even better. Our proposed models also generally outperform direct prompts against much larger models (BLOOM 175B and StableVicuna 13B) in both few-shot chain-of-thought and few-shot answer-only settings.
Person Re-Identification without Identification via Event Anonymization
Aug 09, 2023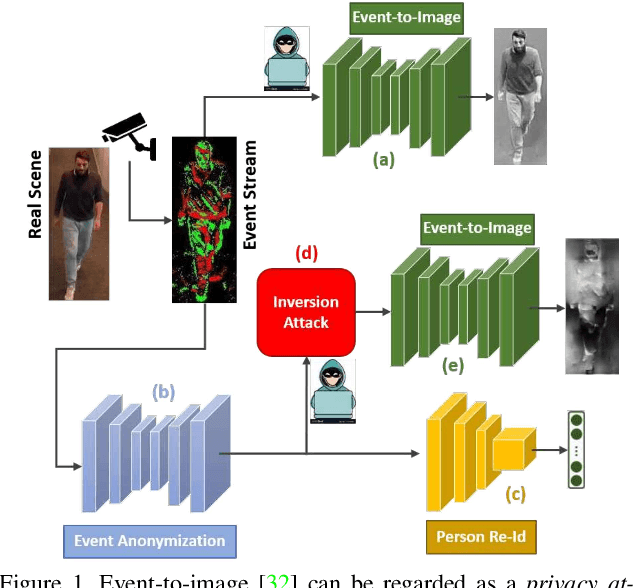


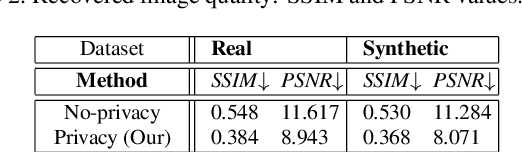
Wide-scale use of visual surveillance in public spaces puts individual privacy at stake while increasing resource consumption (energy, bandwidth, and computation). Neuromorphic vision sensors (event-cameras) have been recently considered a valid solution to the privacy issue because they do not capture detailed RGB visual information of the subjects in the scene. However, recent deep learning architectures have been able to reconstruct images from event cameras with high fidelity, reintroducing a potential threat to privacy for event-based vision applications. In this paper, we aim to anonymize event-streams to protect the identity of human subjects against such image reconstruction attacks. To achieve this, we propose an end-to-end network architecture jointly optimized for the twofold objective of preserving privacy and performing a downstream task such as person ReId. Our network learns to scramble events, enforcing the degradation of images recovered from the privacy attacker. In this work, we also bring to the community the first ever event-based person ReId dataset gathered to evaluate the performance of our approach. We validate our approach with extensive experiments and report results on the synthetic event data simulated from the publicly available SoftBio dataset and our proposed Event-ReId dataset.
Deep Learning for Morphological Identification of Extended Radio Galaxies using Weak Labels
Aug 09, 2023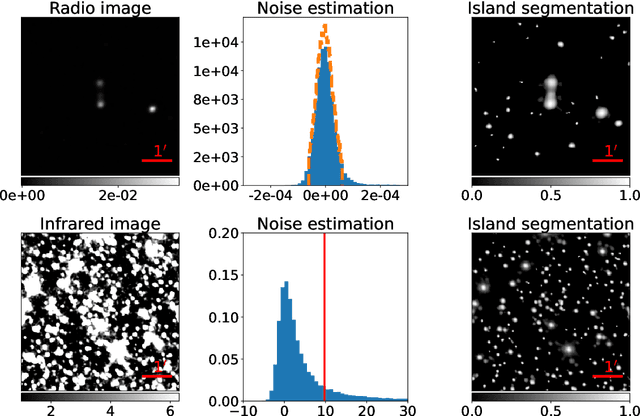
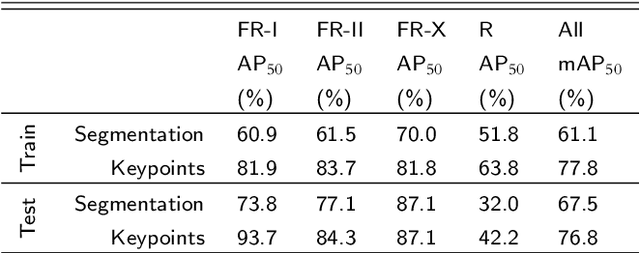
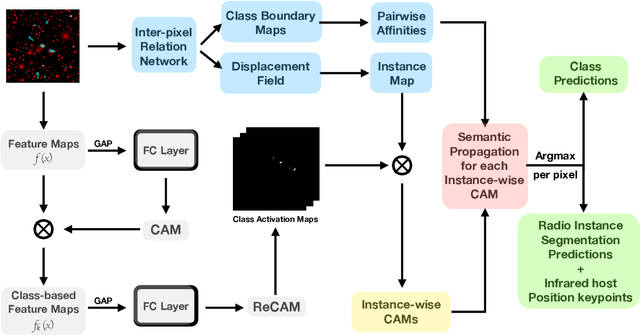
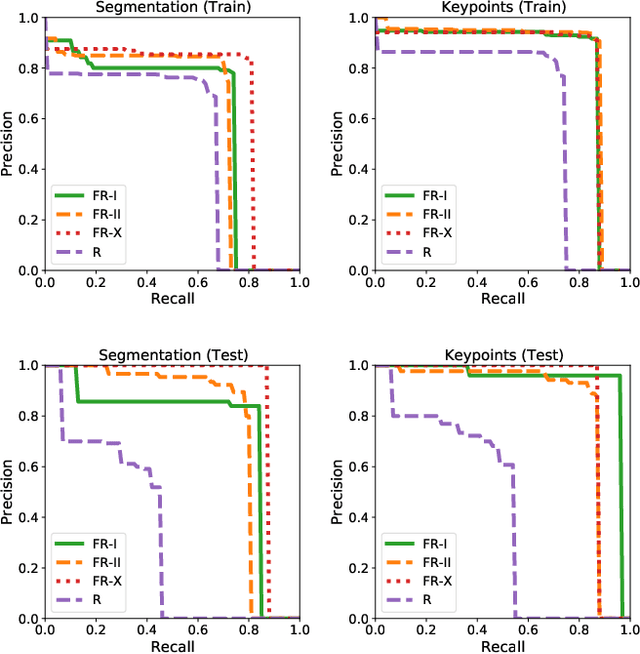
The present work discusses the use of a weakly-supervised deep learning algorithm that reduces the cost of labelling pixel-level masks for complex radio galaxies with multiple components. The algorithm is trained on weak class-level labels of radio galaxies to get class activation maps (CAMs). The CAMs are further refined using an inter-pixel relations network (IRNet) to get instance segmentation masks over radio galaxies and the positions of their infrared hosts. We use data from the Australian Square Kilometre Array Pathfinder (ASKAP) telescope, specifically the Evolutionary Map of the Universe (EMU) Pilot Survey, which covered a sky area of 270 square degrees with an RMS sensitivity of 25-35 $\mu$Jy/beam. We demonstrate that weakly-supervised deep learning algorithms can achieve high accuracy in predicting pixel-level information, including masks for the extended radio emission encapsulating all galaxy components and the positions of the infrared host galaxies. We evaluate the performance of our method using mean Average Precision (mAP) across multiple classes at a standard intersection over union (IoU) threshold of 0.5. We show that the model achieves a mAP$_{50}$ of 67.5\% and 76.8\% for radio masks and infrared host positions, respectively. The network architecture can be found at the following link: https://github.com/Nikhel1/Gal-CAM
LayoutLLM-T2I: Eliciting Layout Guidance from LLM for Text-to-Image Generation
Aug 09, 2023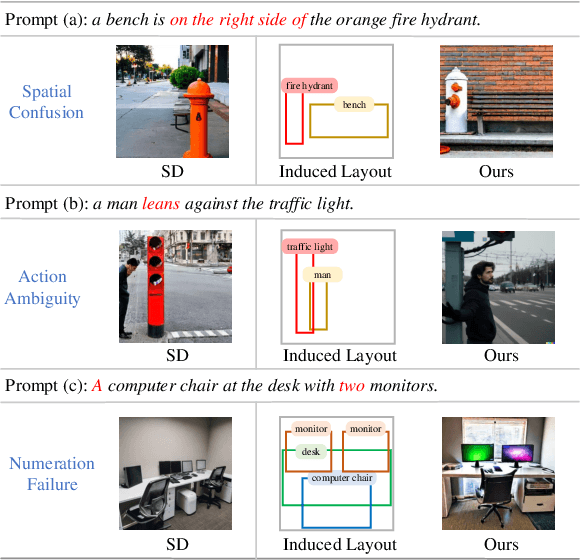
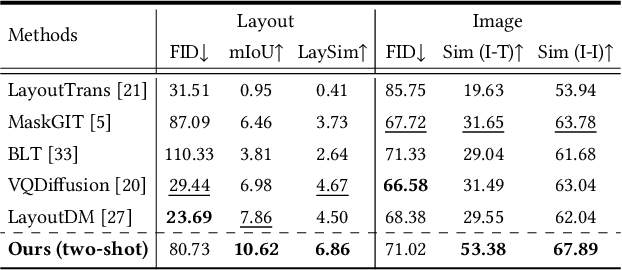
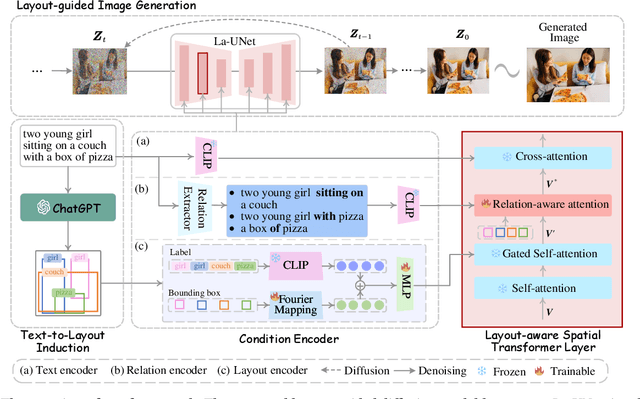

In the text-to-image generation field, recent remarkable progress in Stable Diffusion makes it possible to generate rich kinds of novel photorealistic images. However, current models still face misalignment issues (e.g., problematic spatial relation understanding and numeration failure) in complex natural scenes, which impedes the high-faithfulness text-to-image generation. Although recent efforts have been made to improve controllability by giving fine-grained guidance (e.g., sketch and scribbles), this issue has not been fundamentally tackled since users have to provide such guidance information manually. In this work, we strive to synthesize high-fidelity images that are semantically aligned with a given textual prompt without any guidance. Toward this end, we propose a coarse-to-fine paradigm to achieve layout planning and image generation. Concretely, we first generate the coarse-grained layout conditioned on a given textual prompt via in-context learning based on Large Language Models. Afterward, we propose a fine-grained object-interaction diffusion method to synthesize high-faithfulness images conditioned on the prompt and the automatically generated layout. Extensive experiments demonstrate that our proposed method outperforms the state-of-the-art models in terms of layout and image generation. Our code and settings are available at \url{https://layoutllm-t2i.github.io}.