 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Timeseries-aware Uncertainty Wrappers for Uncertainty Quantification of Information-Fusion-Enhanced AI Models based on Machine Learning
May 24, 2023
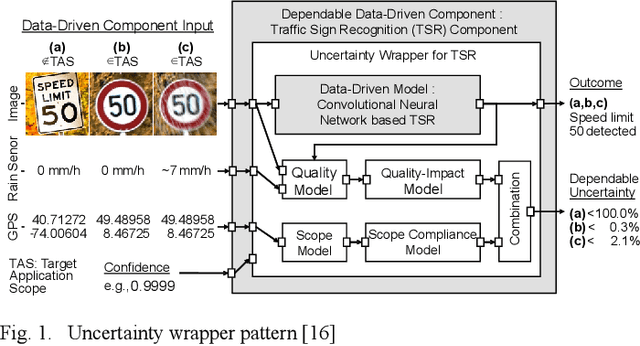
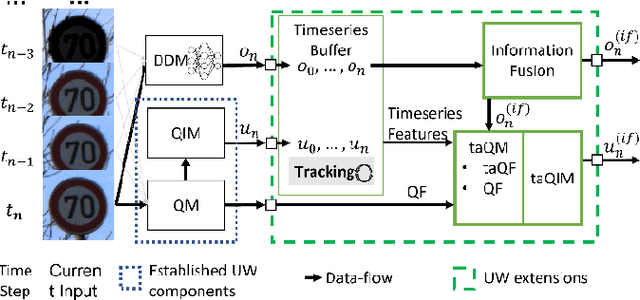
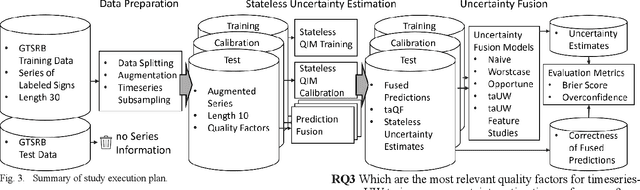
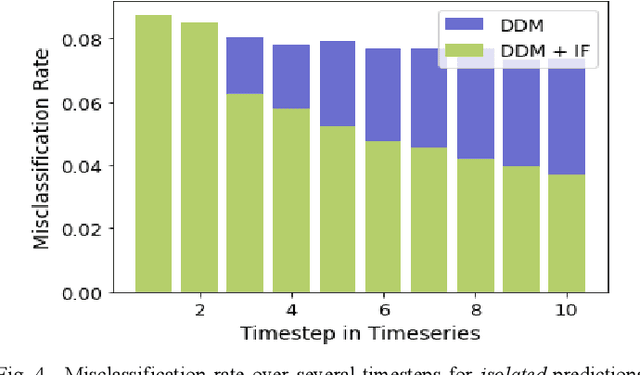
As the use of Artificial Intelligence (AI) components in cyber-physical systems is becoming more common, the need for reliable system architectures arises. While data-driven models excel at perception tasks, model outcomes are usually not dependable enough for safety-critical applications. In this work,we present a timeseries-aware uncertainty wrapper for dependable uncertainty estimates on timeseries data. The uncertainty wrapper is applied in combination with information fusion over successive model predictions in time. The application of the uncertainty wrapper is demonstrated with a traffic sign recognition use case. We show that it is possible to increase model accuracy through information fusion and additionally increase the quality of uncertainty estimates through timeseries-aware input quality features.
Revisiting Event-based Video Frame Interpolation
Jul 24, 2023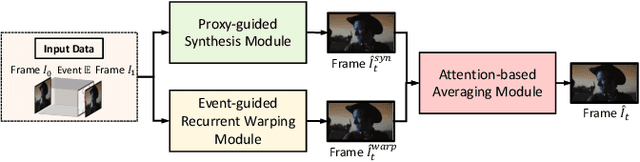
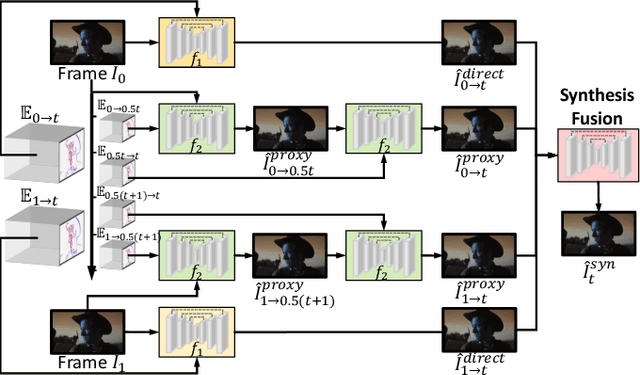
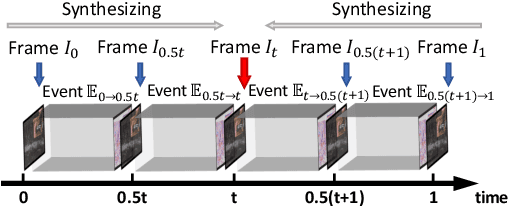
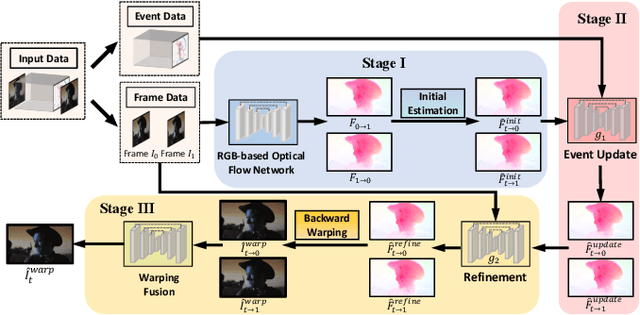
Dynamic vision sensors or event cameras provide rich complementary information for video frame interpolation. Existing state-of-the-art methods follow the paradigm of combining both synthesis-based and warping networks. However, few of those methods fully respect the intrinsic characteristics of events streams. Given that event cameras only encode intensity changes and polarity rather than color intensities, estimating optical flow from events is arguably more difficult than from RGB information. We therefore propose to incorporate RGB information in an event-guided optical flow refinement strategy. Moreover, in light of the quasi-continuous nature of the time signals provided by event cameras, we propose a divide-and-conquer strategy in which event-based intermediate frame synthesis happens incrementally in multiple simplified stages rather than in a single, long stage. Extensive experiments on both synthetic and real-world datasets show that these modifications lead to more reliable and realistic intermediate frame results than previous video frame interpolation methods. Our findings underline that a careful consideration of event characteristics such as high temporal density and elevated noise benefits interpolation accuracy.
Multi-View Vertebra Localization and Identification from CT Images
Jul 24, 2023
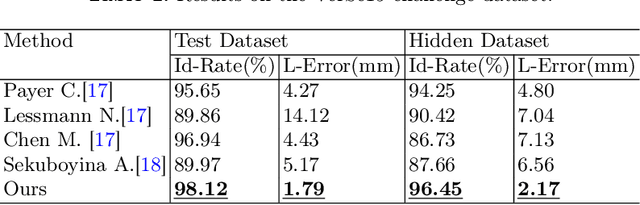
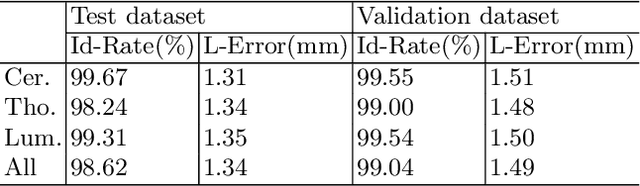
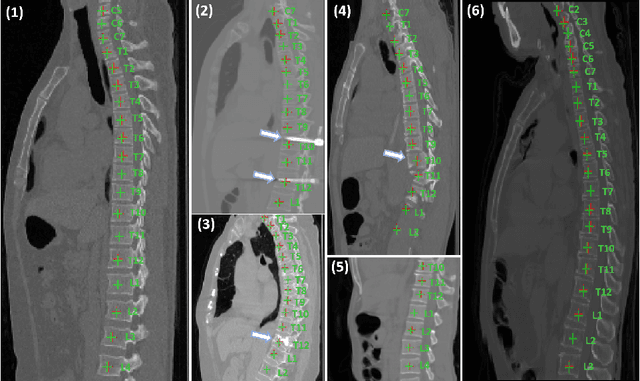
Accurately localizing and identifying vertebrae from CT images is crucial for various clinical applications. However, most existing efforts are performed on 3D with cropping patch operation, suffering from the large computation costs and limited global information. In this paper, we propose a multi-view vertebra localization and identification from CT images, converting the 3D problem into a 2D localization and identification task on different views. Without the limitation of the 3D cropped patch, our method can learn the multi-view global information naturally. Moreover, to better capture the anatomical structure information from different view perspectives, a multi-view contrastive learning strategy is developed to pre-train the backbone. Additionally, we further propose a Sequence Loss to maintain the sequential structure embedded along the vertebrae. Evaluation results demonstrate that, with only two 2D networks, our method can localize and identify vertebrae in CT images accurately, and outperforms the state-of-the-art methods consistently. Our code is available at https://github.com/ShanghaiTech-IMPACT/Multi-View-Vertebra-Localization-and-Identification-from-CT-Images.
Fairness Under Demographic Scarce Regime
Jul 24, 2023Most existing works on fairness assume the model has full access to demographic information. However, there exist scenarios where demographic information is partially available because a record was not maintained throughout data collection or due to privacy reasons. This setting is known as demographic scarce regime. Prior research have shown that training an attribute classifier to replace the missing sensitive attributes (proxy) can still improve fairness. However, the use of proxy-sensitive attributes worsens fairness-accuracy trade-offs compared to true sensitive attributes. To address this limitation, we propose a framework to build attribute classifiers that achieve better fairness-accuracy trade-offs. Our method introduces uncertainty awareness in the attribute classifier and enforces fairness on samples with demographic information inferred with the lowest uncertainty. We show empirically that enforcing fairness constraints on samples with uncertain sensitive attributes is detrimental to fairness and accuracy. Our experiments on two datasets showed that the proposed framework yields models with significantly better fairness-accuracy trade-offs compared to classic attribute classifiers. Surprisingly, our framework outperforms models trained with constraints on the true sensitive attributes.
Successive Pose Estimation and Beam Tracking for mmWave Vehicular Communication Systems
Jul 30, 2023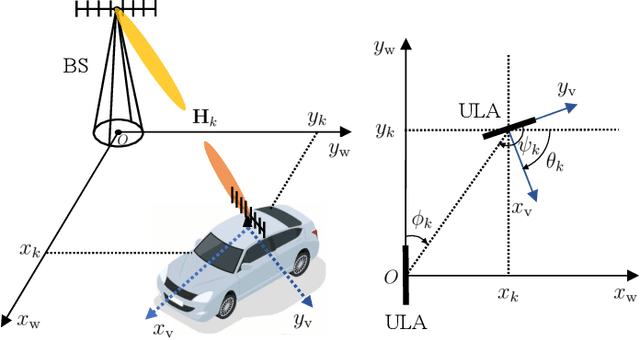

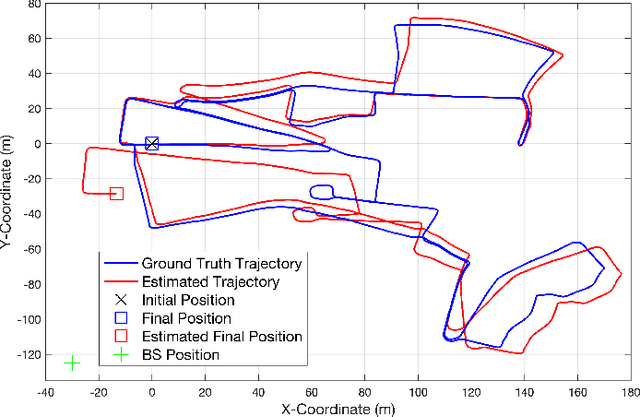
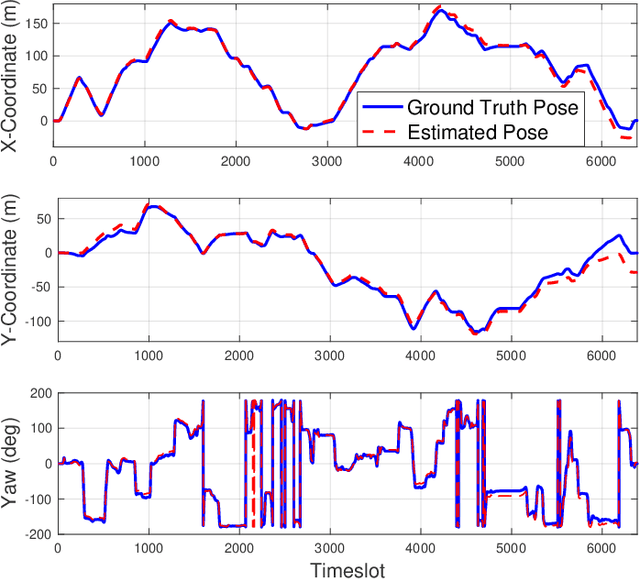
The millimeter wave (mmWave) radar sensing-aided communications in vehicular mobile communication systems is investigated. To alleviate the beam training overhead under high mobility scenarios, a successive pose estimation and beam tracking (SPEBT) scheme is proposed to facilitate mmWave communications with the assistance of mmWave radar sensing. The proposed SPEBT scheme first resorts to a Fast Conservative Filtering for Efficient and Accurate Radar odometry (Fast-CFEAR) approach to estimate the vehicle pose consisting of 2-dimensional position and yaw from radar point clouds collected by mmWave radar sensor. Then, the pose estimation information is fed into an extend Kalman filter to perform beam tracking for the line-of-sight channel. Owing to the intrinsic robustness of mmWave radar sensing, the proposed SPEBT scheme is capable of operating reliably under extreme weather/illumination conditions and large-scale global navigation satellite systems (GNSS)-denied environments. The practical deployment of the SPEBT scheme is verified through rigorous testing on a real-world sensing dataset. Simulation results demonstrate that the proposed SPEBT scheme is capable of providing precise pose estimation information and accurate beam tracking output, while reducing the proportion of beam training overhead to less than 5% averagely.
YOLIC: An Efficient Method for Object Localization and Classification on Edge Devices
Jul 30, 2023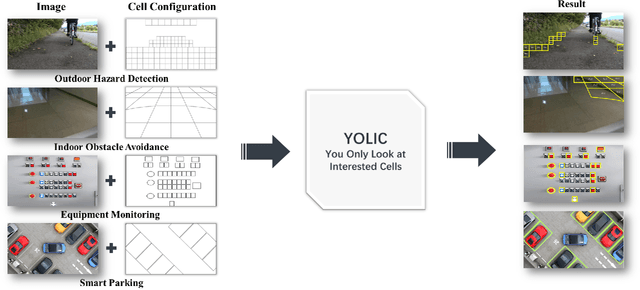
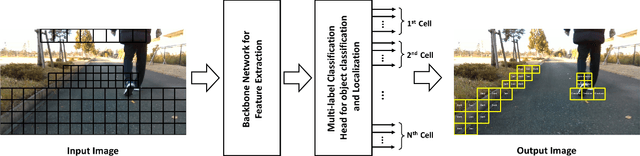


In the realm of Tiny AI, we introduce ``You Only Look at Interested Cells" (YOLIC), an efficient method for object localization and classification on edge devices. Through seamlessly blending the strengths of semantic segmentation and object detection, YOLIC offers superior computational efficiency and precision. By adopting Cells of Interest for classification instead of individual pixels, YOLIC encapsulates relevant information, reduces computational load, and enables rough object shape inference. Importantly, the need for bounding box regression is obviated, as YOLIC capitalizes on the predetermined cell configuration that provides information about potential object location, size, and shape. To tackle the issue of single-label classification limitations, a multi-label classification approach is applied to each cell for effectively recognizing overlapping or closely situated objects. This paper presents extensive experiments on multiple datasets to demonstrate that YOLIC achieves detection performance comparable to the state-of-the-art YOLO algorithms while surpassing in speed, exceeding 30fps on a Raspberry Pi 4B CPU. All resources related to this study, including datasets, cell designer, image annotation tool, and source code, have been made publicly available on our project website at https://kai3316.github.io/yolic.github.io
What Can an Accent Identifier Learn? Probing Phonetic and Prosodic Information in a Wav2vec2-based Accent Identification Model
Jun 10, 2023
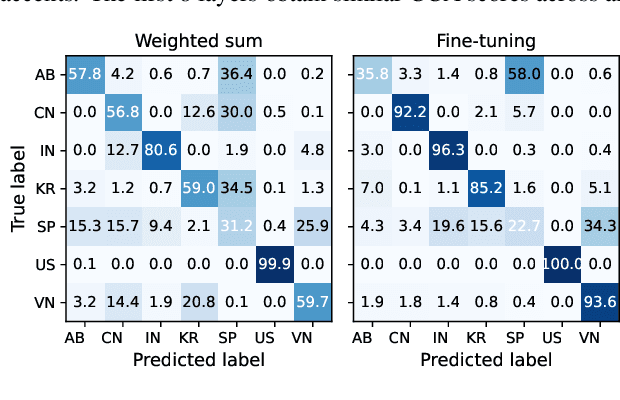
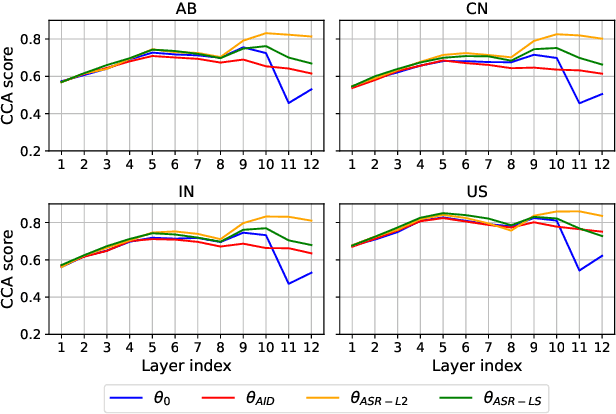
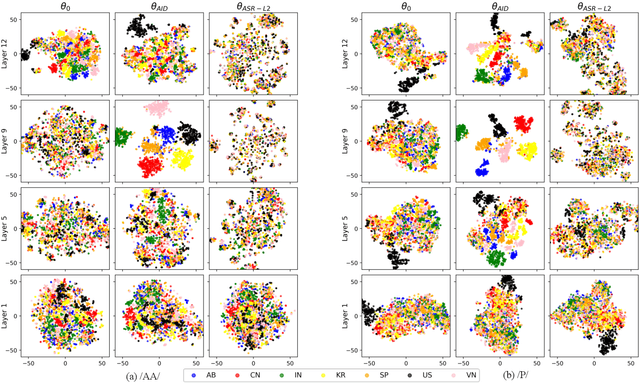
This study is focused on understanding and quantifying the change in phoneme and prosody information encoded in the Self-Supervised Learning (SSL) model, brought by an accent identification (AID) fine-tuning task. This problem is addressed based on model probing. Specifically, we conduct a systematic layer-wise analysis of the representations of the Transformer layers on a phoneme correlation task, and a novel word-level prosody prediction task. We compare the probing performance of the pre-trained and fine-tuned SSL models. Results show that the AID fine-tuning task steers the top 2 layers to learn richer phoneme and prosody representation. These changes share some similarities with the effects of fine-tuning with an Automatic Speech Recognition task. In addition, we observe strong accent-specific phoneme representations in layer 9. To sum up, this study provides insights into the understanding of SSL features and their interactions with fine-tuning tasks.
Identification of the Relevance of Comments in Codes Using Bag of Words and Transformer Based Models
Aug 11, 2023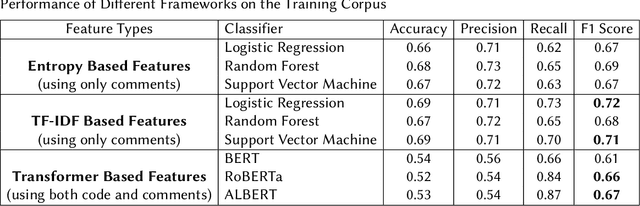
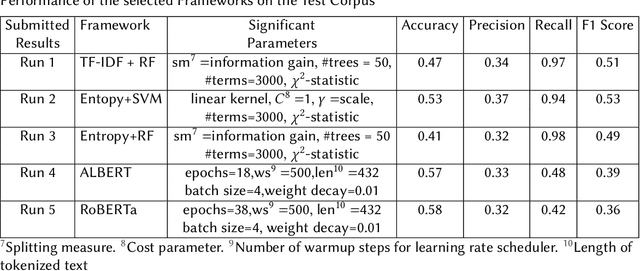
The Forum for Information Retrieval (FIRE) started a shared task this year for classification of comments of different code segments. This is binary text classification task where the objective is to identify whether comments given for certain code segments are relevant or not. The BioNLP-IISERB group at the Indian Institute of Science Education and Research Bhopal (IISERB) participated in this task and submitted five runs for five different models. The paper presents the overview of the models and other significant findings on the training corpus. The methods involve different feature engineering schemes and text classification techniques. The performance of the classical bag of words model and transformer-based models were explored to identify significant features from the given training corpus. We have explored different classifiers viz., random forest, support vector machine and logistic regression using the bag of words model. Furthermore, the pre-trained transformer based models like BERT, RoBERT and ALBERT were also used by fine-tuning them on the given training corpus. The performance of different such models over the training corpus were reported and the best five models were implemented on the given test corpus. The empirical results show that the bag of words model outperforms the transformer based models, however, the performance of our runs are not reasonably well in both training and test corpus. This paper also addresses the limitations of the models and scope for further improvement.
Learning Energy-Efficient Hardware Configurations for Massive MIMO Beamforming
Aug 11, 2023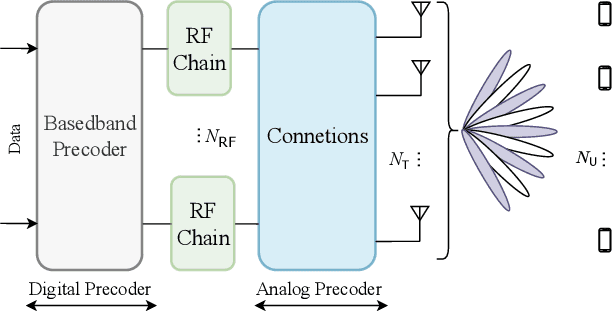
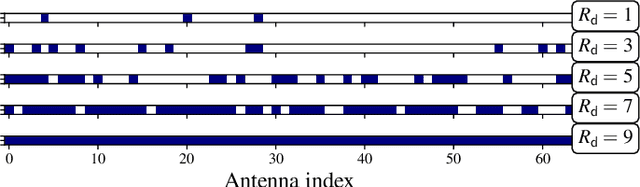
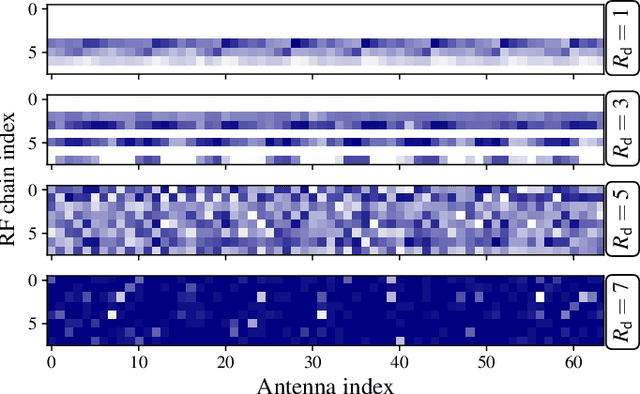

Hybrid beamforming (HBF) and antenna selection are promising techniques for improving the energy efficiency~(EE) of massive multiple-input multiple-output~(mMIMO) systems. However, the transmitter architecture may contain several parameters that need to be optimized, such as the power allocated to the antennas and the connections between the antennas and the radio frequency chains. Therefore, finding the optimal transmitter architecture requires solving a non-convex mixed integer problem in a large search space. In this paper, we consider the problem of maximizing the EE of fully digital precoder~(FDP) and hybrid beamforming~(HBF) transmitters. First, we propose an energy model for different beamforming structures. Then, based on the proposed energy model, we develop an unsupervised deep learning method to maximize the EE by designing the transmitter configuration for FDP and HBF. The proposed deep neural networks can provide different trade-offs between spectral efficiency and energy consumption while adapting to different numbers of active users. Finally, to ensure that the proposed method can be implemented in practice, we investigate the ability of the model to be trained exclusively using imperfect channel state information~(CSI), both for the input to the deep learning model and for the calculation of the loss function. Simulation results show that the proposed solutions can outperform conventional methods in terms of EE while being trained with imperfect CSI. Furthermore, we show that the proposed solutions are less complex and more robust to noise than conventional methods.
Revolutionizing Space Health (Swin-FSR): Advancing Super-Resolution of Fundus Images for SANS Visual Assessment Technology
Aug 11, 2023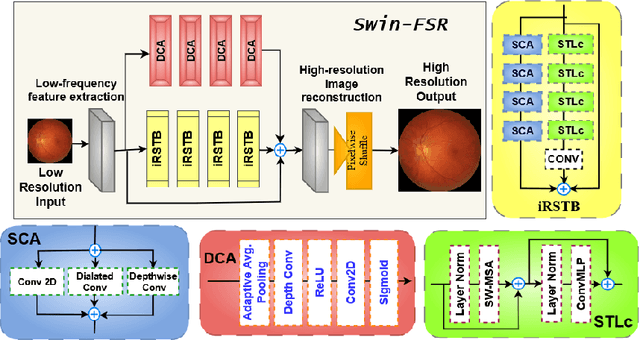
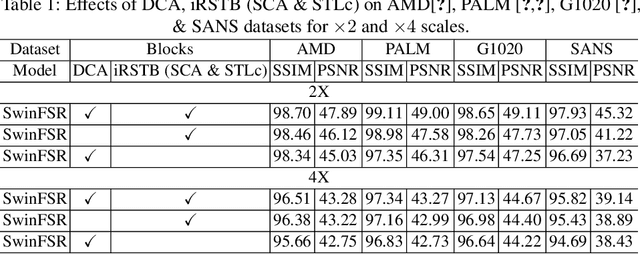
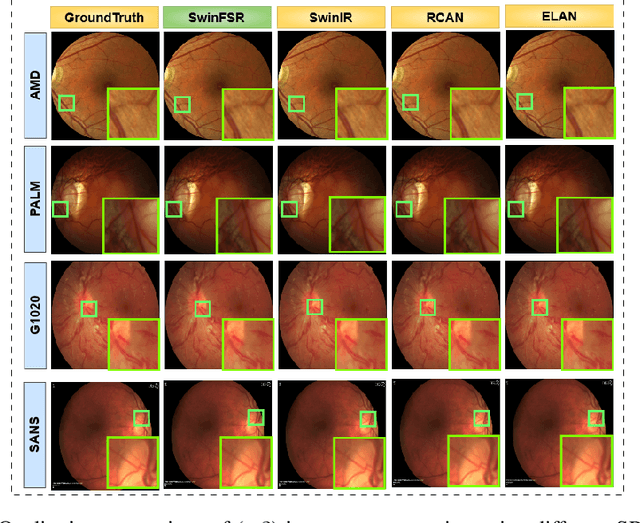
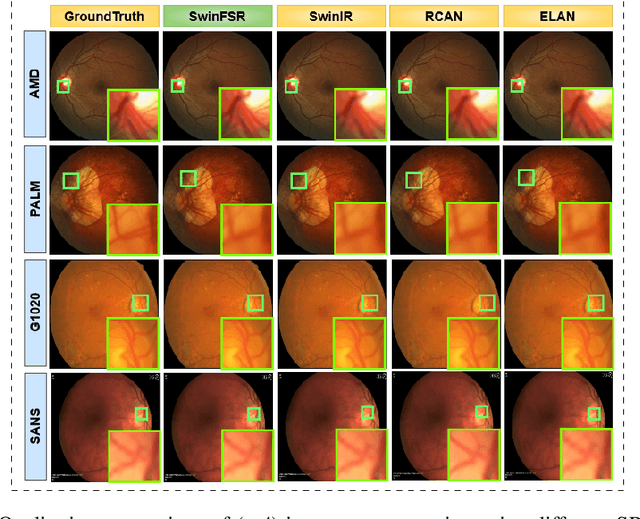
The rapid accessibility of portable and affordable retinal imaging devices has made early differential diagnosis easier. For example, color funduscopy imaging is readily available in remote villages, which can help to identify diseases like age-related macular degeneration (AMD), glaucoma, or pathological myopia (PM). On the other hand, astronauts at the International Space Station utilize this camera for identifying spaceflight-associated neuro-ocular syndrome (SANS). However, due to the unavailability of experts in these locations, the data has to be transferred to an urban healthcare facility (AMD and glaucoma) or a terrestrial station (e.g, SANS) for more precise disease identification. Moreover, due to low bandwidth limits, the imaging data has to be compressed for transfer between these two places. Different super-resolution algorithms have been proposed throughout the years to address this. Furthermore, with the advent of deep learning, the field has advanced so much that x2 and x4 compressed images can be decompressed to their original form without losing spatial information. In this paper, we introduce a novel model called Swin-FSR that utilizes Swin Transformer with spatial and depth-wise attention for fundus image super-resolution. Our architecture achieves Peak signal-to-noise-ratio (PSNR) of 47.89, 49.00 and 45.32 on three public datasets, namely iChallenge-AMD, iChallenge-PM, and G1020. Additionally, we tested the model's effectiveness on a privately held dataset for SANS provided by NASA and achieved comparable results against previous architectures.