 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-View Vertebra Localization and Identification from CT Images
Jul 24, 2023

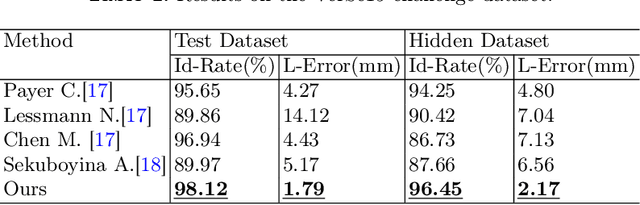
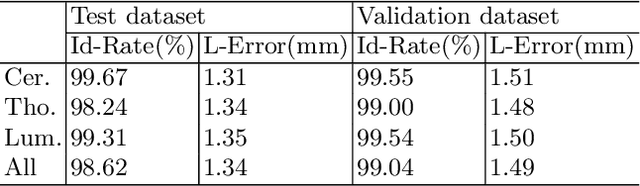
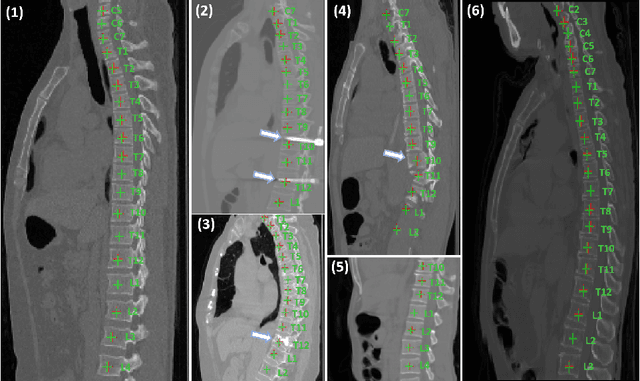
Accurately localizing and identifying vertebrae from CT images is crucial for various clinical applications. However, most existing efforts are performed on 3D with cropping patch operation, suffering from the large computation costs and limited global information. In this paper, we propose a multi-view vertebra localization and identification from CT images, converting the 3D problem into a 2D localization and identification task on different views. Without the limitation of the 3D cropped patch, our method can learn the multi-view global information naturally. Moreover, to better capture the anatomical structure information from different view perspectives, a multi-view contrastive learning strategy is developed to pre-train the backbone. Additionally, we further propose a Sequence Loss to maintain the sequential structure embedded along the vertebrae. Evaluation results demonstrate that, with only two 2D networks, our method can localize and identify vertebrae in CT images accurately, and outperforms the state-of-the-art methods consistently. Our code is available at https://github.com/ShanghaiTech-IMPACT/Multi-View-Vertebra-Localization-and-Identification-from-CT-Images.
Fairness Under Demographic Scarce Regime
Jul 24, 2023Most existing works on fairness assume the model has full access to demographic information. However, there exist scenarios where demographic information is partially available because a record was not maintained throughout data collection or due to privacy reasons. This setting is known as demographic scarce regime. Prior research have shown that training an attribute classifier to replace the missing sensitive attributes (proxy) can still improve fairness. However, the use of proxy-sensitive attributes worsens fairness-accuracy trade-offs compared to true sensitive attributes. To address this limitation, we propose a framework to build attribute classifiers that achieve better fairness-accuracy trade-offs. Our method introduces uncertainty awareness in the attribute classifier and enforces fairness on samples with demographic information inferred with the lowest uncertainty. We show empirically that enforcing fairness constraints on samples with uncertain sensitive attributes is detrimental to fairness and accuracy. Our experiments on two datasets showed that the proposed framework yields models with significantly better fairness-accuracy trade-offs compared to classic attribute classifiers. Surprisingly, our framework outperforms models trained with constraints on the true sensitive attributes.
Feature Matching Data Synthesis for Non-IID Federated Learning
Aug 09, 2023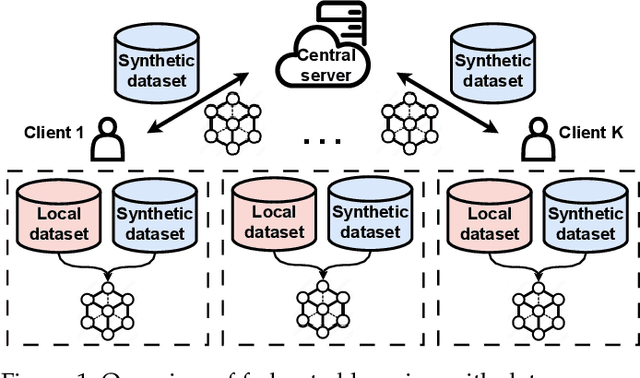

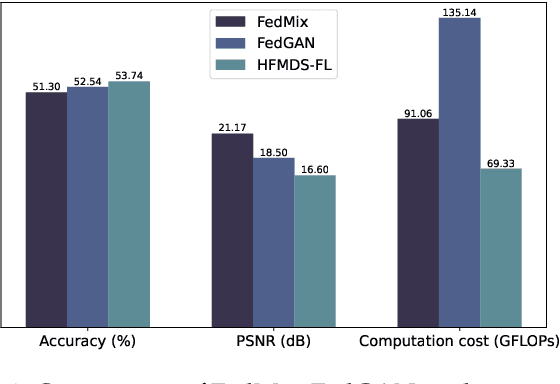
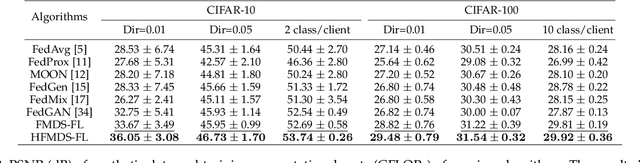
Federated learning (FL) has emerged as a privacy-preserving paradigm that trains neural networks on edge devices without collecting data at a central server. However, FL encounters an inherent challenge in dealing with non-independent and identically distributed (non-IID) data among devices. To address this challenge, this paper proposes a hard feature matching data synthesis (HFMDS) method to share auxiliary data besides local models. Specifically, synthetic data are generated by learning the essential class-relevant features of real samples and discarding the redundant features, which helps to effectively tackle the non-IID issue. For better privacy preservation, we propose a hard feature augmentation method to transfer real features towards the decision boundary, with which the synthetic data not only improve the model generalization but also erase the information of real features. By integrating the proposed HFMDS method with FL, we present a novel FL framework with data augmentation to relieve data heterogeneity. The theoretical analysis highlights the effectiveness of our proposed data synthesis method in solving the non-IID challenge. Simulation results further demonstrate that our proposed HFMDS-FL algorithm outperforms the baselines in terms of accuracy, privacy preservation, and computational cost on various benchmark datasets.
An Integrated Visual Analytics System for Studying Clinical Carotid Artery Plaques
Aug 09, 2023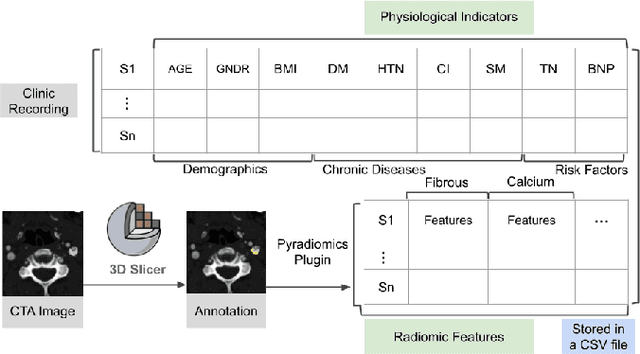
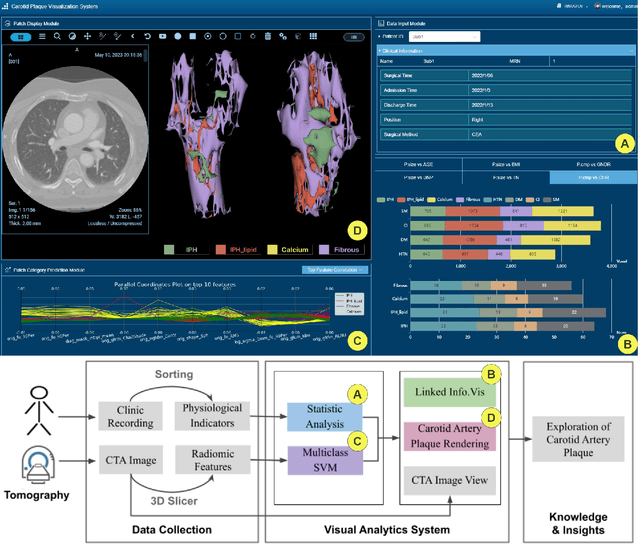
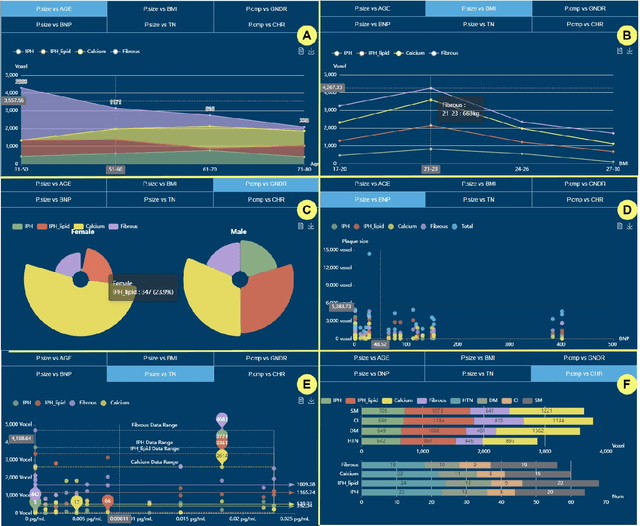
Carotid artery plaques can cause arterial vascular diseases such as stroke and myocardial infarction, posing a severe threat to human life. However, the current clinical examination mainly relies on a direct assessment by physicians of patients' clinical indicators and medical images, lacking an integrated visualization tool for analyzing the influencing factors and composition of carotid artery plaques. We have designed an intelligent carotid artery plaque visual analysis system for vascular surgery experts to comprehensively analyze the clinical physiological and imaging indicators of carotid artery diseases. The system mainly includes two functions: First, it displays the correlation between carotid artery plaque and various factors through a series of information visualization methods and integrates the analysis of patient physiological indicator data. Second, it enhances the interface guidance analysis of the inherent correlation between the components of carotid artery plaque through machine learning and displays the spatial distribution of the plaque on medical images. Additionally, we conducted two case studies on carotid artery plaques using real data obtained from a hospital, and the results indicate that our designed carotid analysis system can effectively provide clinical diagnosis and treatment guidance for vascular surgeons.
DELFlow: Dense Efficient Learning of Scene Flow for Large-Scale Point Clouds
Aug 09, 2023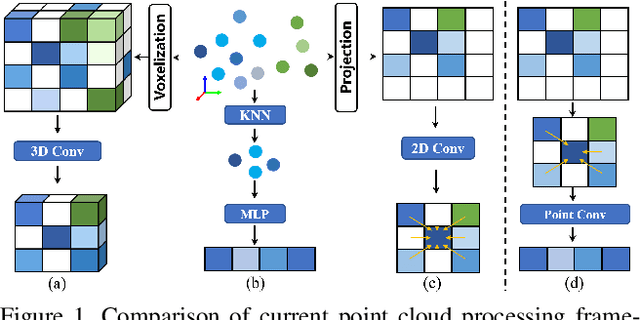
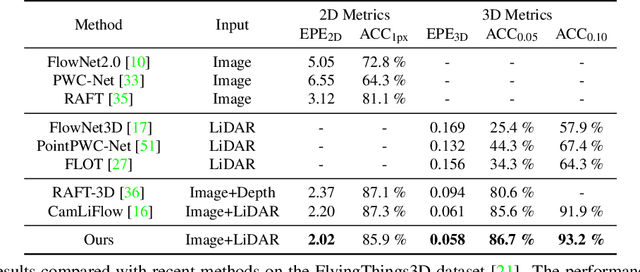
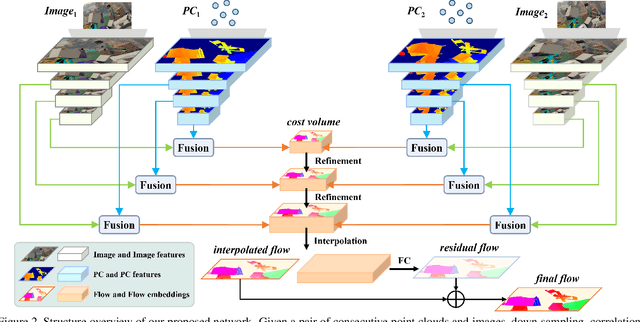
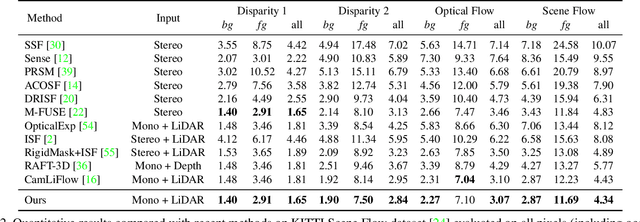
Point clouds are naturally sparse, while image pixels are dense. The inconsistency limits feature fusion from both modalities for point-wise scene flow estimation. Previous methods rarely predict scene flow from the entire point clouds of the scene with one-time inference due to the memory inefficiency and heavy overhead from distance calculation and sorting involved in commonly used farthest point sampling, KNN, and ball query algorithms for local feature aggregation. To mitigate these issues in scene flow learning, we regularize raw points to a dense format by storing 3D coordinates in 2D grids. Unlike the sampling operation commonly used in existing works, the dense 2D representation 1) preserves most points in the given scene, 2) brings in a significant boost of efficiency, and 3) eliminates the density gap between points and pixels, allowing us to perform effective feature fusion. We also present a novel warping projection technique to alleviate the information loss problem resulting from the fact that multiple points could be mapped into one grid during projection when computing cost volume. Sufficient experiments demonstrate the efficiency and effectiveness of our method, outperforming the prior-arts on the FlyingThings3D and KITTI dataset.
Transferable Models for Bioacoustics with Human Language Supervision
Aug 09, 2023Passive acoustic monitoring offers a scalable, non-invasive method for tracking global biodiversity and anthropogenic impacts on species. Although deep learning has become a vital tool for processing this data, current models are inflexible, typically cover only a handful of species, and are limited by data scarcity. In this work, we propose BioLingual, a new model for bioacoustics based on contrastive language-audio pretraining. We first aggregate bioacoustic archives into a language-audio dataset, called AnimalSpeak, with over a million audio-caption pairs holding information on species, vocalization context, and animal behavior. After training on this dataset to connect language and audio representations, our model can identify over a thousand species' calls across taxa, complete bioacoustic tasks zero-shot, and retrieve animal vocalization recordings from natural text queries. When fine-tuned, BioLingual sets a new state-of-the-art on nine tasks in the Benchmark of Animal Sounds. Given its broad taxa coverage and ability to be flexibly queried in human language, we believe this model opens new paradigms in ecological monitoring and research, including free-text search on the world's acoustic monitoring archives. We open-source our models, dataset, and code.
LoLep: Single-View View Synthesis with Locally-Learned Planes and Self-Attention Occlusion Inference
Aug 09, 2023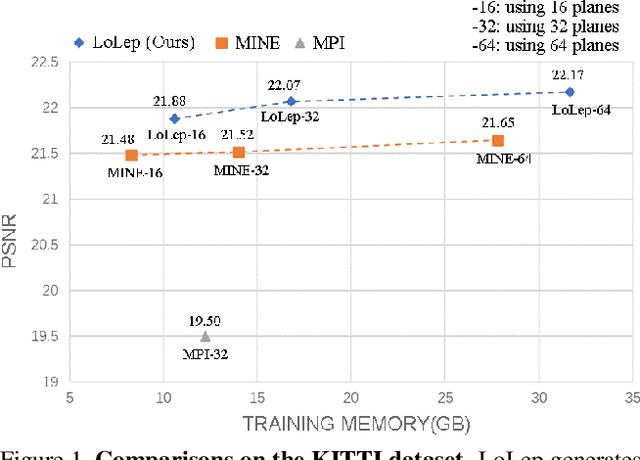

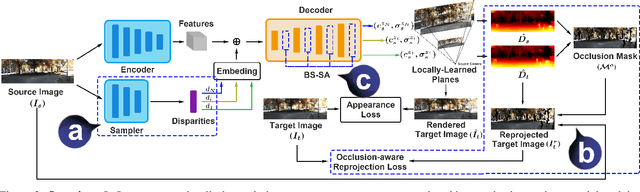
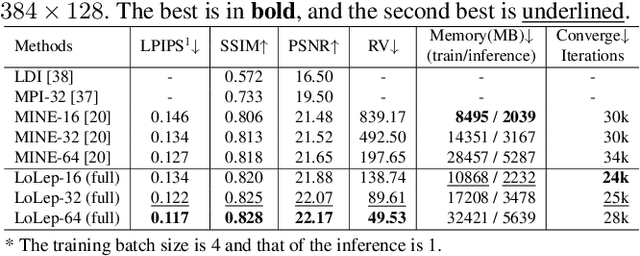
We propose a novel method, LoLep, which regresses Locally-Learned planes from a single RGB image to represent scenes accurately, thus generating better novel views. Without the depth information, regressing appropriate plane locations is a challenging problem. To solve this issue, we pre-partition the disparity space into bins and design a disparity sampler to regress local offsets for multiple planes in each bin. However, only using such a sampler makes the network not convergent; we further propose two optimizing strategies that combine with different disparity distributions of datasets and propose an occlusion-aware reprojection loss as a simple yet effective geometric supervision technique. We also introduce a self-attention mechanism to improve occlusion inference and present a Block-Sampling Self-Attention (BS-SA) module to address the problem of applying self-attention to large feature maps. We demonstrate the effectiveness of our approach and generate state-of-the-art results on different datasets. Compared to MINE, our approach has an LPIPS reduction of 4.8%-9.0% and an RV reduction of 73.9%-83.5%. We also evaluate the performance on real-world images and demonstrate the benefits.
Event Abstraction for Enterprise Collaboration Systems to Support Social Process Mining
Aug 09, 2023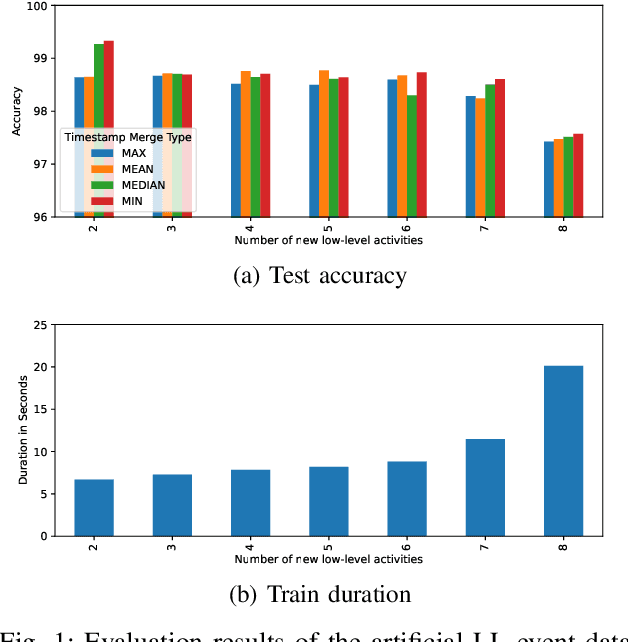
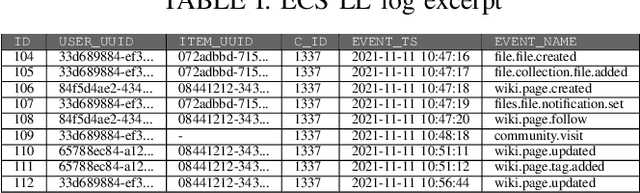
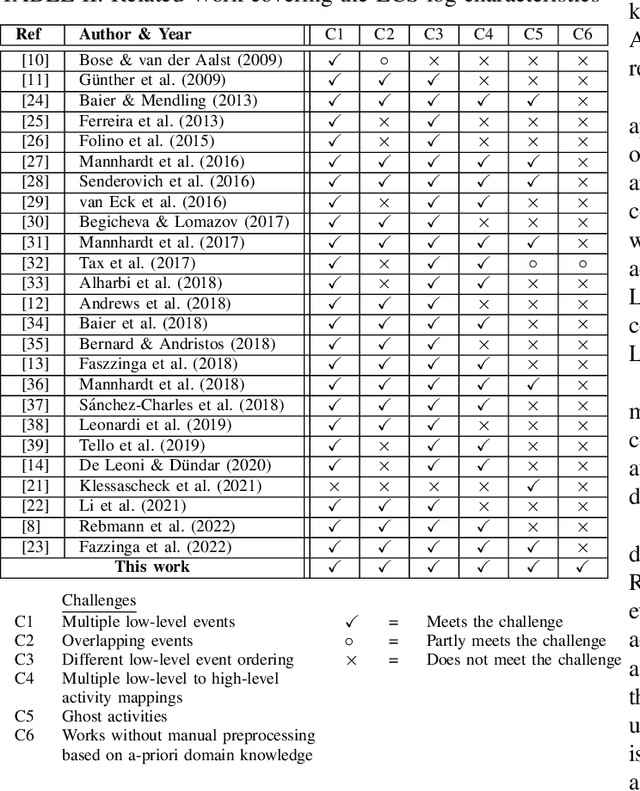
One aim of Process Mining (PM) is the discovery of process models from event logs of information systems. PM has been successfully applied to process-oriented enterprise systems but is less suited for communication- and document-oriented Enterprise Collaboration Systems (ECS). ECS event logs are very fine-granular and PM applied to their logs results in spaghetti models. A common solution for this is event abstraction, i.e., converting low-level logs into more abstract high-level logs before running discovery algorithms. ECS logs come with special characteristics that have so far not been fully addressed by existing event abstraction approaches. We aim to close this gap with a tailored ECS event abstraction (ECSEA) approach that trains a model by comparing recorded actual user activities (high-level traces) with the system-generated low-level traces (extracted from the ECS). The model allows us to automatically convert future low-level traces into an abstracted high-level log that can be used for PM. Our evaluation shows that the algorithm produces accurate results. ECSEA is a preprocessing method that is essential for the interpretation of collaborative work activity in ECS, which we call Social Process Mining.
Leveraging the Edge and Cloud for V2X-Based Real-Time Object Detection in Autonomous Driving
Aug 09, 2023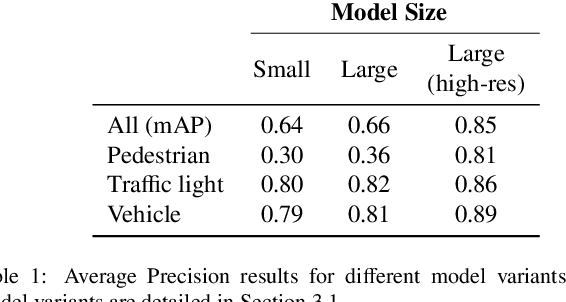
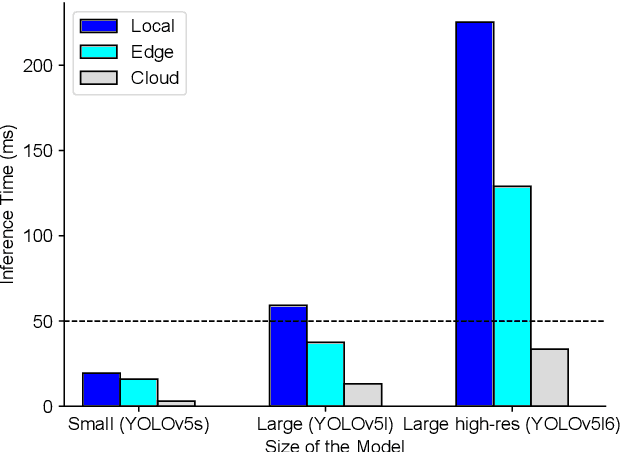
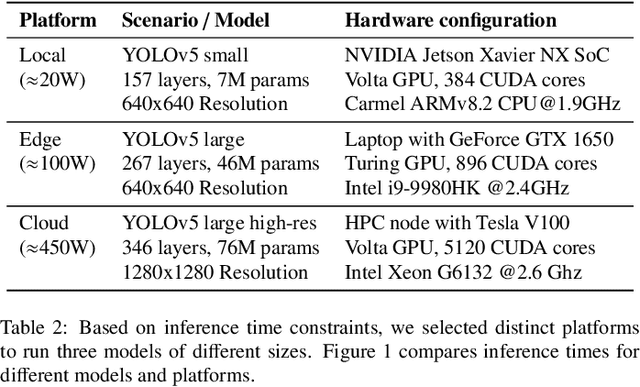
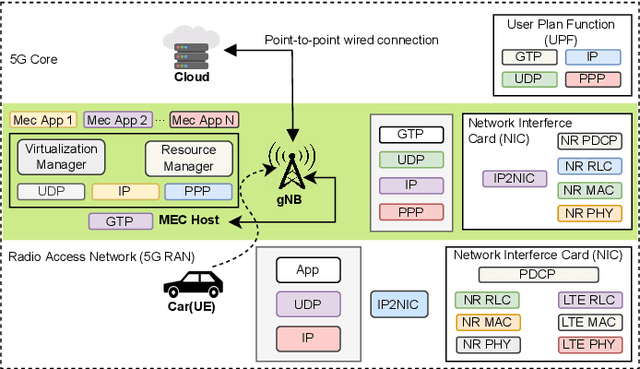
Environmental perception is a key element of autonomous driving because the information received from the perception module influences core driving decisions. An outstanding challenge in real-time perception for autonomous driving lies in finding the best trade-off between detection quality and latency. Major constraints on both computation and power have to be taken into account for real-time perception in autonomous vehicles. Larger object detection models tend to produce the best results, but are also slower at runtime. Since the most accurate detectors cannot run in real-time locally, we investigate the possibility of offloading computation to edge and cloud platforms, which are less resource-constrained. We create a synthetic dataset to train object detection models and evaluate different offloading strategies. Using real hardware and network simulations, we compare different trade-offs between prediction quality and end-to-end delay. Since sending raw frames over the network implies additional transmission delays, we also explore the use of JPEG and H.265 compression at varying qualities and measure their impact on prediction metrics. We show that models with adequate compression can be run in real-time on the cloud while outperforming local detection performance.
Tweet Insights: A Visualization Platform to Extract Temporal Insights from Twitter
Aug 04, 2023
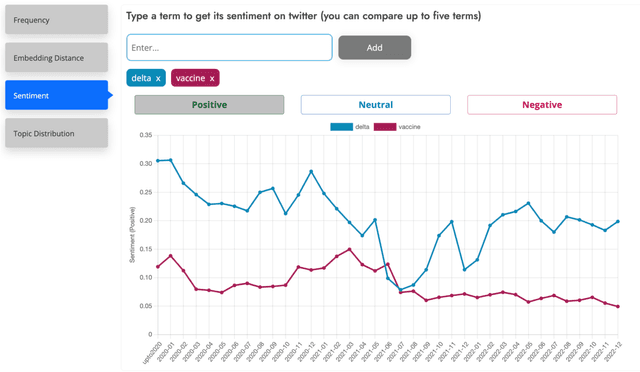
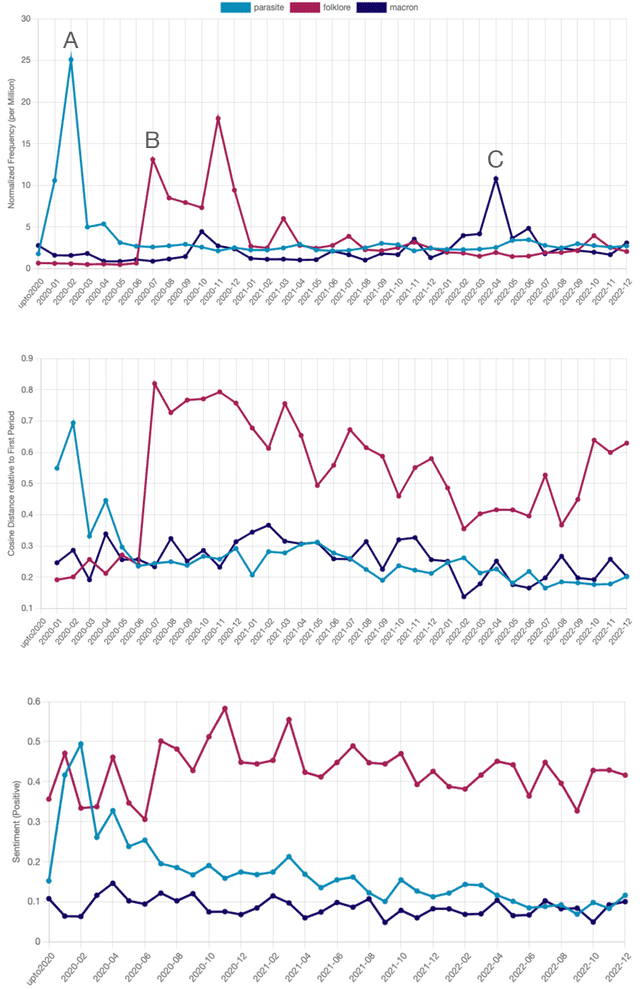
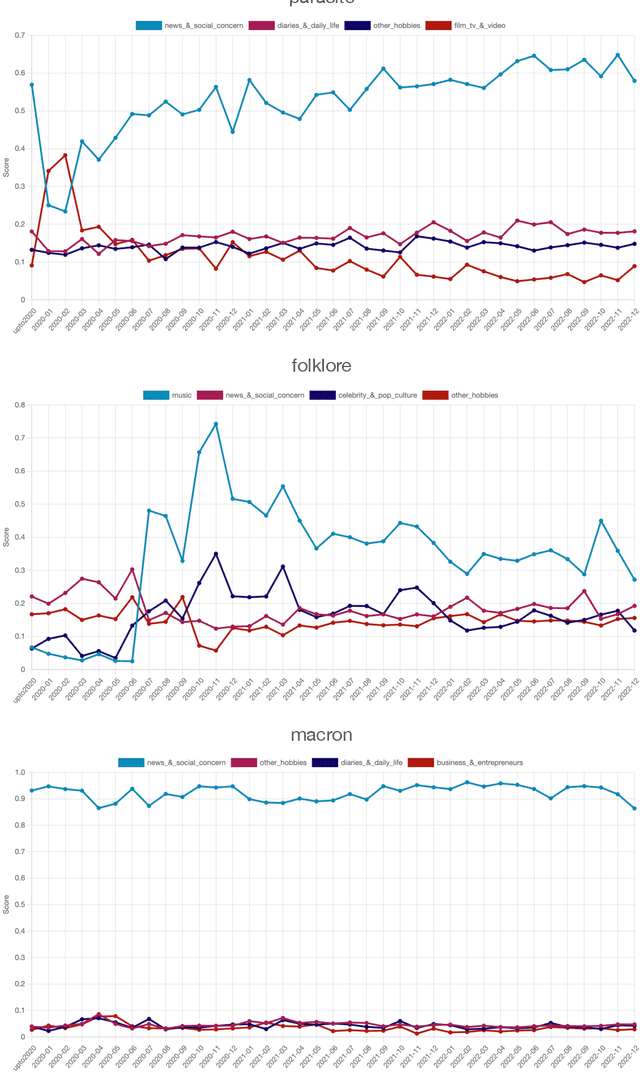
This paper introduces a large collection of time series data derived from Twitter, postprocessed using word embedding techniques, as well as specialized fine-tuned language models. This data comprises the past five years and captures changes in n-gram frequency, similarity, sentiment and topic distribution. The interface built on top of this data enables temporal analysis for detecting and characterizing shifts in meaning, including complementary information to trending metrics, such as sentiment and topic association over time. We release an online demo for easy experimentation, and we share code and the underlying aggregated data for future work. In this paper, we also discuss three case studies unlocked thanks to our platform, showcasing its potential for temporal linguistic analysis.